

Часто проведение ML-экспериментов сводится к долгому поиску и загрузке нужных датасетов и моделей, скрупулезной настройке гиперпараметров с целью проверки гипотез. Но что делать, когда времени мало, а за ночь нужно зафайнтюнить ламу? Давайте это и узнаем.
Статья написана по мотивам доклада Ефима Головина, MLOps-инженера в отделе Data- и ML-продуктов Selectel.
Используйте навигацию, если не хотите читать текст целиком:
→ Типичная ML-задача: когда нужны ML-эксперименты
→ Работа с датасетами
→ Работа с моделями
→ Деплой модели
→ Как организовывать эксперименты без навыков MLOps
Типичная ML-задача: когда нужны ML-эксперименты
Любая ML-задача может быть описана с помощью схемы CRISP-ML, которая объединяет три крупных этапа:
- Понимание данных. Вам нужно разобраться в том, с какими данными вы работаете, какие в них есть недостатки, нужно ли (и можно ли) их «обогатить». А после — собрать датасет.
- Построение модели. Набор данных готов, есть задача — вы начинаете ее решать: проверять гипотезы по различным классам моделей, гиперпараметрам, а также разнообразным «эвристикам», которые можно применить при построении модели.
- Доведение модели до потребителя. Все гипотезы отработаны, модели проверены, вы нашли устраивающий вас вариант. Далее нужно довести модель до конечного потребителя — сделать нечто, что временами называют «продуктивизацией модели».

На каждом из этапов вы можете столкнуться в ворохом процессных и технических аспектов, которые могут как ускорить, так и замедлить выполнение ML-экспериментов. Что это за аспекты и с чем их едят — разберемся на примере LLM.
Тюнинг ламы на тикетах
В общих чертах рассмотрим кейс с проведением ML-экспериментов на примере языковой модели LLama 2:

Модель берем с платформы Hugging Face, а предварительно подготовленный датасет с тикетами — из ClearML. Далее в Jupyter пишем прототип (код эксперимента) и после отладки — запускаем его в ClearML. Поскольку гиперпараметры были предварительно закреплены за кодом с помощью ClearML SDK, мы можем удобно с ними экспериментировать — изменять количество эпох, learning rate или batch size и сравнивать результаты.
На выходе мы получаем несколько версий дообученной LLama 2 и лучшую отправляем в KServe — serving engine (виртуальную среду, в которой модель будет сервиться). Готово!
Кажется, что все просто, но на практике могут возникнуть проблемы. Рассмотрим каждый этап эксперимента подробнее.

Работа с датасетами
Проблема в работе с данными нередко заключается в том, что вы не знаете:
- общих фактов по датасету — например, автора или объема данных,
- базовых статистик по признакам, целевой переменной и другим метрикам,
- какие трансформации были проведены с датасетом,
- как работать с датасетом — как при помощи сущности, описывающей датасет, выгрузить данные с внешнего источника (например, с S3 или SFS) и перевести их в нужный формат для работы с PyTorch, TensorFlow или Transformers,
- откуда появился датасет — например, из каких данных был собран, где и кем использовался,
- как менялся датасет.
Все это вносит неопределенность при работе с данными: может элементарно отсутствовать понимание, какие параметры действительно важны, а какие нет. На подобные разбирательства, как правило, времени уходит много.
Как ускорить работу с датасетами
Рассмотрим в качестве примеров два сервиса, с помощью которых можно ускорить работу с датасетами.
Пример 1: Hugging Face
Разработчики Hugging Face позаботились о том, чтобы авторы могли указывать при загрузке данных всю необходимую информацию.

В результате любой пользователь может изучить библиотеку датасетов, найти необходимый тип данных для своей задачи, предварительно оценить его по объему. Кроме того, в Hugging Face есть понятные примеры с кодом — бери и используй — и версионирование. Последнее напоминает GitHub: вы можете открыть один из старых коммитов и склонировать именно его.
Мы уже писали статью о том, как автоматизировать сбор, анализ и сравнение датасетов из Hugging Face — читайте по ссылке.
Пример 2: ClearML
ClearML также существенно упрощает работу с датасетами и сводит ее к графическому интерфейсу. Например, внутри отдельной вкладки с датасетами вы можете группировать их по папкам:

Как и в Hugging Face, пользователь ClearML отображает метаинформацию о датасетах, позволяет настроить разделение данных по типу, задаче и любой другой категории. А также — изучить базовую информацию о составе загруженных датасетов.

Любой датасет в ClearML (как любой эксперимент или пайплайн) создается, изменяется и используется в рамках «задачи» определенного типа — за подробностями рекомендую покопаться в коде. То есть вся функциональность по работе с экспериментами доступна и для датасетов.
Рассмотрим пример. Вы загрузили в ClearML датасет, подчистили его с помощью регулярных выражений и передали коллеге. Он загружает данные и видит статистики по трансформациям: какие выражения к каким записям были применены и т. д. Результат: человек «понимает датасет», у него есть необходимая информация для работы с ним, а вы сэкономили время обеих сторон.

Пример 3: кэширование данных
Еще один способ ускорить работу с датасетами — настроить кэширование в файловое хранилище. Загрузив данные один раз, вам не придется с нуля подгружать датасеты и веса при каждом запуске эксперимента. Это особенно актуально, если вы работаете с большими моделями вроде LLama 2, веса которой занимают свыше 100 ГБ памяти (файлы модели Llama-2-70b-chat-hf суммарно занимают ~138 ГБ).
Эта фича уже имплементирована в ML-платформу Selectel. Вы можете кэшировать датасеты и веса, чтобы сократить время на подгрузке данных. Вся инфраструктура уже настроена за вас.
Аспекты ускорения
Примеры рассмотрели — какой можно сделать вывод? Вернемся к техническим и процессным аспектам: зарезюмируем, какие в работе с датасетами через ClearML с кэшированием данных.
Технические аспекты
- Все собрано в одной унифицированной платформе.
- Можно повторно использовать код для создания новых версий датасета.
- Не нужно каждый раз тратить время на загрузку данных, все подгружается из кэша.
Процессные аспекты
- Описания датасетов приведены к единому формату.
- Данные сопровождаются подробными инструкциями.
Работа с моделями
Проблема в работе с моделями напоминает ситуацию с датасетами. Нередко вы не знаете:
- кто, где, когда учил или валидиновал модель,,
- класс модели — например, какой структурой она является: нейросетью, деревом или лесом.
- какие данные нужно подавать на вход, что получается на выходе,
- из чего модель состоит — например, сколько у нее слоев или функций активации,
- как работать с моделью — как при помощи сущности, описывающей модель, выгрузить данные с внешнего источника (например, с S3 или SFS) и перевести их в нужный формат для работы с PyTorch, TensorFlow или Transformers,
- полный набор гиперпараметров модели,
- отличия модели от предшественников.
Как ускорить работу с моделями
Рассмотрим в качестве примеров два сервиса, с помощью которых можно ускорить работу с моделями.
Пример 1: Hugging Face
Как в случае с датасетами, модели в Hugging Face разделены по задачам и типам данных, у них есть описания и авторы. Точно так же можно посмотреть, как менялась модель, изучить детали по работе с ней.

Пример 2: Jupyter и ClearML
Поскольку нам нужно не только хранить информацию о моделях, но и дообучать их, нужна «рабочая станция» с помощью которой мы подгрузим веса и начнем с ними работать. Приемлемый вариант — использовать связку Jupyter и ClearML. Она уже имплементирована в нашу ML-платформу.
Пользователю не нужно настраивать среду разработки и работу с GPU, все уже готово. Вся информация об экспериментах собрана в ClearML. Можно посмотреть автора модели, сохранять логи и другие данные по экспериментам.

Кроме того, все параметры модели можно легко переносить из Jupyter в ClearML, а после — использовать для проверок гипотез: варьировать значения и смотреть на результаты.

Перенос параметров модели из Jupyter в ClearML.
После дообучения ClearML автоматически выведет информацию по утилизации ресурсов GPU и процессу обучения (последнее приходится логировать в Tensorboard-логи, но на этом все — ClearML сам подтягивает данные в свою панель):

Аспекты ускорения
Технические аспекты
→ Не нужно тратить время на воссоздание рабочего окружения.
→ Код можно повторно использовать для дообучения модели.
Процессные аспекты
→ Информация по экспериментам организована и сведена в одну точку.
Деплой модели
Датасет загрузили, проверили гипотезы и дообучили модель — осталось довести ее до конечного пользователя. То есть поднять некий сервис, через который наши друзья, коллеги и простые незнакомцы смогут общаться с моделью.
Проблемы:
- писать веб-обвязку для модели может быть затруднительно,
- нужно настроить логирование,
- модели должны масштабироваться под нагрузкой и обновляться до актуальных версий.
Как ускорить деплой
Для начала посмотрим, какими средствами можно упростить и ускорить деплой в Hugging Face.
Пример 1: Hugging Face
Прямо внутри платформы вы можете создать свой спейс, набросать пользовательский интерфейс и расшарить к нему доступ. Так пользователи смогут общаться с инференс-инстансом вашей модели.
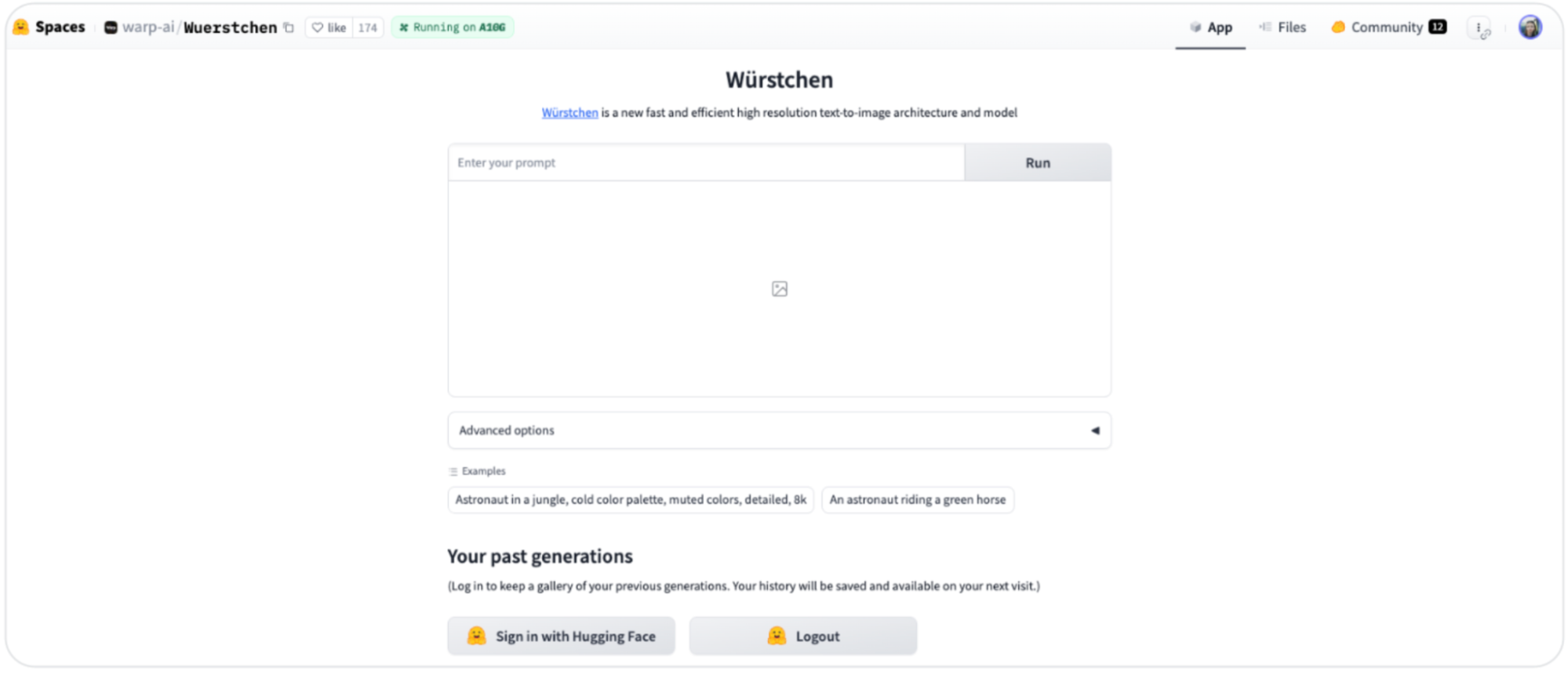
Hugging Face, форма создания спейса.
Эта фича доступна для всех пользователей Hugging Face — посмотреть готовые варианты можно по ссылке.

Hugging Face, раздел с пользовательскими спейсами.
У Hugging Face есть также сервис Inference Endpoints, но он платный.
Пример 2: KServe
Альтернативный вариант, который мы используем в ML-платформе Selectel, — KServe. Необходимо опубликовать новую версию инференс-сервиса, закинув в KServe идентификатор дообученной модели, и пользователи смогут отправлять по ссылкам запросы, а модель — отвечать на них. Если быть технически более точным, то:
- идентификатор модели достается из ClearML-эксперимента и кладется в кастомный инференс-скрипт,
- кастомный инференс-скрипт запекается в Docker-образ,
- полное имя Docker-образа указывается в манифесте инференс-сервиса KServe,
- манифест инференс-сервиса публикуется в KServe.
Поскольку Dockerfile, манифест инференс-сервиса и сам кастомный инференс-скрипт почти что всегда остаются без изменений, на их повторном использовании можно сэкономить много времени.

KServe, ссылки для работы с инференс-инстансом модели.
Так пользователь может, например, отправить запрос модели с промтом в качестве POST-параметра. А инференс-инстанс ответит текстом или ссылкой на изображение (зависит от модели, которую вы используете). Есть разные протоколы, в соответствии с которыми формируются тела запросов, ссылки и другие «сущности». Более подробно можно прочитать в документации KServe.
Аспекты ускорения
Технические аспекты
→ Пишем только логику обработки входных-выходных данных.
→ Веб-обвязку, логирование и масштабирование забирает на себя KServe.
Процессные аспекты
→ Создание нового инференса свелось к замене идентификатора на новую модель.
Как организовывать эксперименты без навыков MLOps
Мы рассмотрели проведение ML-экспериментов от подготовки данных до деплоя инференс-инстансов. И выяснили, что ускорение экспериментов можно свести к трем пунктам:
- Введению ряда подробно описанных соглашений. Когда не только вы, но и ваши коллеги знают, как устроены датасеты и модели внутри эксперимента, какие гиперпараметры и параметры влияют на результат, проверка гипотез значительно ускоряется. Поэтому важно вводить соглашения, унифицировать типы данных и описания датасетов с моделями.
- Повторному использованию рабочих окружений и кода для подготовки данных и обучения моделей. Если вы единожды написали скрипт, который можно многократно переиспользовать для новых ML-экспериментов, меняя только параметры, вы сэкономили время. Принцип DRY работает не только в классической разработке.
- Использованию инструментов, с помощью которых можно абстрагироваться от мелких технических деталей. Конфигурирование инструментов вроде Nvidia-драйверов, CUDA Toolkit и рабочих окружений часто занимает много времени. Ситуация усложняется, когда нужно настроить шеринг ресурсов GPU, чтобы сразу несколько специалистов могли работать на одной машине. Если все сконфигурировано за вас — профит, вы сэкономили много времени.
С последним мы можем помочь. В сентябре вышла из беты ML-платформа Selectel — облачное решение с преднастроенными аппаратными и программными компонентами для обучения и развертывания ML-моделей.
Мы разворачиваем платформу индивидуально для каждого клиента и можем включить в сборку такие open source-инструменты, как ClearML или Kubeflow. В общем, все для того, чтобы вы смогли организовать полный цикл обучения и тестирования ML-моделей.
Тем, кто заинтересуется платформой, мы предоставим бесплатный двухнедельный тестовый период. В рамках тестирования вы сможете выбрать интересующие модели GPU и провести несколько экспериментов. На это время мы создадим чат в Telegram для срочных вопросов по работе платформы.
Остались вопросы? Задавайте их в комментариях, присоединяйтесь к обсуждениям, а также — смотрите полную версию доклада про ускорение ML-экспериментов.
dimnsk
"бесплатный 2х недельный период?"
на какую ЦА вы ориентируетесь? как вы придумываете время на тест-драйв?
примерный период запуска проектов в ML представляете? есть практики?
очень интересно кого это заинтересует из малых клиентов не говоря про средних
PS знаете какие кредиты давал AWS - ?
от 400-1000$ просто так
дада знаю про импортозамещение конечно
Opaspap
Ну за две недели можно понять ограничения и фичи платформы, фулфича на две нед, тем более сейчас, когда уже в целом люди наработали приемы работы с этим всем, вполне достаточно, чтобы решить вопрос "какая платформа". А вот с урезанными фичами можно и за пол года не разобраться, завязаться на обещания, начать разработку, потом заплатить, обнаружить что реклама не совпадает с ожиданиями и поносить потом сервис при каждом упоминании.
dimnsk
и за 2 недели умея выбирать "какая платформа" (т.е. уже работая где то)
вы думаете, сделают выбор в пользу ваше платформы?