
Бывают ситуации, когда к разработке firmware надо подключить новых людей. Как объяснить им архитектуру нынешнего ПО?
Глобально в каждом Firmware репозитории весь код можно отсортировать на такие мега-части как sensitivity, connectivity, control, computing , security и storage.

Код из каждой части может быть как-то связан с частями из других программных компонентов. В программировании микроконтроллеров программы по-хорошему должны строятся иерархично. То есть один программный компонент вызывает функции из другого программного компонента. Например драйверу чтения SD‑карты нужны функции от драйвера SPI, драйвера GPIO, компонента CRC7, CRC16. Как бы представить эту взаимосвязь для каждой конкретной сборки прошивки? Очевидно, что надо нарисовать граф. То есть картинку, где стрелочки и прямоугольники покажут как всё взаимно связано. И тут-то на помощь нам приходит язык разметки графов Graphviz.
Для кода на языке Graphviz можно сделать полуавтоматический кодо генератор. Надо обязать программиста, чтобы в папке каждого программного компонента был крохотный файлик *.gvi для явного указания высокоуровневых зависимостей. Для простоты поддержки этот *.gvi файл надо называть так же как имя папки в которой лежит *.gvi.
Смотришь в *.c код, примерно видишь, что там подключается #include «*.h», что вызывается в самих функциях и отражаешь это в *.gvi файле рядом. Вот примерное содержимое для pdm.gvi. PDM — это программный компонент для записи звука из MEMS микрофонов.
GPIO->PDM
NVIC->PDM
REG->PDM
DFT->PDM
RAM->PDM
AUDIO->PDM
DMA->PDM
В этом *.gvi файле надо вручную прописать какие у данного программного компонента есть зависимости от других программных компонентов. Сделать это можно на простеньком текстовом языке Graphviz. По факту, всё что понадобится из синтаксиса языка Graphviz — это оператор стрелка «->»
Также нужен корневой файл main.gvi в который будет всё вставляться утилитой препроцессором (cpp.exe).
strict digraph graphname {
rankdir=LR;
splines=ortho
node [shape="box"];
#ifdef HAS_BSP
#include "bsp.gvi"
#endif
#ifdef HAS_THIRD_PARTY
#include "third_party.gvi"
#endif
#ifdef HAS_PROTOCOLS
#include "protocols.gvi"
#endif
#ifdef HAS_ADT
#include "adt.gvi"
#endif
#ifdef HAS_ASICS
#include "asics.gvi"
#endif
#ifdef HAS_MCU
#include "mcu.gvi"
#endif
#ifdef HAS_COMMON
#include "common.gvi"
#endif
#include "components.gvi"
#ifdef HAS_UTILS
#include "utils.gvi"
#endif
#ifdef HAS_CORE
#include "core.gvi"
#endif
#ifdef HAS_DRIVERS
#include "drivers.gvi"
#endif
#ifdef HAS_INTERFACES
#include "interfaces.gvi"
#endif
}
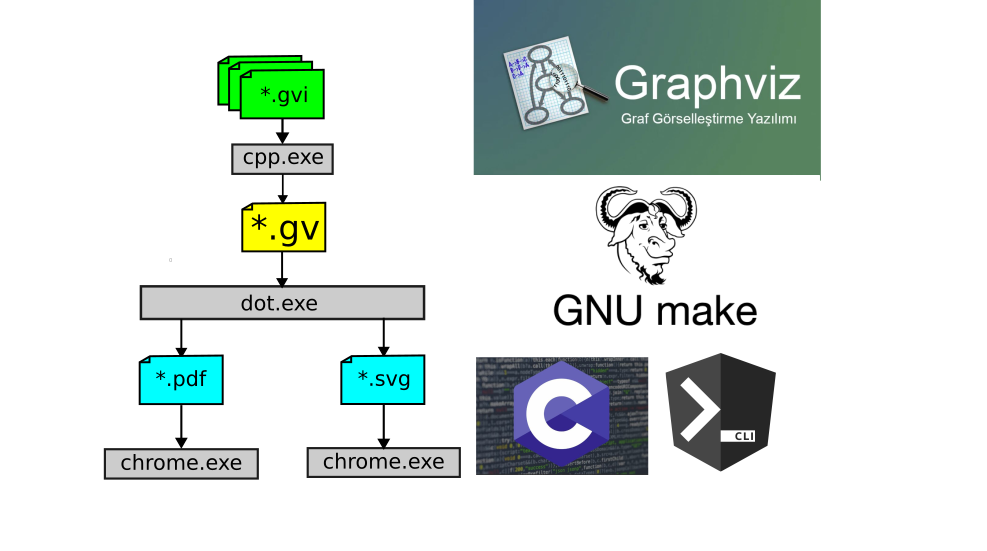
Также нужен makefile скрипт, который будет собирать все отдельные файлы с зависимостями в один единый файл на языке Graphviz. План такой. Надо организовать вот такой программный конвейер.
Заметьте, тут работает самый обыкновенный препроцессор из программ на Си (утилита cpp). Препроцессору всё равно с каким кодом работать. Препроцессор просто вставляет и заменяет куски текста. Утилиту cpp.exe можно вообще порекомендовать писателям учебников или чертёжникам.
Далее сам скрипт generate_dependencies.mk, который определяет ToolChain для построения изображения в привычном *.pdf/*.svg файле.
$(info Generate Dependencies)
CC_DOT="C:/Program Files/Graphviz/bin/dot.exe"
RENDER="C:/Program Files/Google/Chrome/Application/chrome.exe"
MK_PATH_WIN := $(subst /cygdrive/c/,C:/, $(MK_PATH))
ARTEFACTS_DIR=$(MK_PATH_WIN)$(BUILD_DIR)
$(info ARTEFACTS_DIR=$(ARTEFACTS_DIR))
SOURCES_DOT=$(WORKSPACE_LOC)main.gvi
$(info SOURCES_DOT=$(SOURCES_DOT))
SOURCES_DOT:=$(subst /cygdrive/c/,C:/, $(SOURCES_DOT))
$(info SOURCES_DOT=$(SOURCES_DOT))
SOURCES_DOT_RES += $(ARTEFACTS_DIR)/$(TARGET)_dep.gv
$(info SOURCES_DOT_RES=$(SOURCES_DOT_RES))
ART_SVG = $(ARTEFACTS_DIR)/$(TARGET)_res.svg
ART_PDF = $(ARTEFACTS_DIR)/$(TARGET)_res.pdf
$(info ART_SVG=$(ART_SVG) )
$(info ART_PDF=$(ART_PDF) )
CPP_GV_OPT += -undef
CPP_GV_OPT += -P
CPP_GV_OPT += -E
CPP_GV_OPT += -nostdinc
CPP_GV_OPT += $(OPT)
DOT_OPT +=-Tsvg
LAYOUT_ENGINE = -Kdot
preproc_graphviz:$(SOURCES_DOT)
$(info Preproc...)
mkdir $(ARTEFACTS_DIR)
cpp $(SOURCES_DOT) $(CPP_GV_OPT) $(INCDIR) -E -o $(SOURCES_DOT_RES)
generate_dep_pdf: preproc_graphviz
$(info route graph...)
$(CC_DOT) -V
$(CC_DOT) -Tpdf $(LAYOUT_ENGINE) $(SOURCES_DOT_RES) -o $(ARTEFACTS_DIR)/$(TARGET).pdf
generate_dep_svg: preproc_graphviz
$(info route graph...)
$(CC_DOT) -V
$(CC_DOT) $(DOT_OPT) $(SOURCES_DOT_RES) -o $(ARTEFACTS_DIR)/$(TARGET).svg
generate_dep: generate_dep_svg generate_dep_pdf
$(info All)
print_dep: generate_dep
$(info print_svg)
$(RENDER) -open $(ARTEFACTS_DIR)/$(TARGET).svg
$(RENDER) -open $(ARTEFACTS_DIR)/$(TARGET).pdf
Скрипт generate_dependencies.mk следует условно подключить к основному скрипту сборки проекта rules.mk
ifeq ($(DEPENDENCIES_GRAPHVIZ), Y)
include $(WORKSPACE_LOC)/generate_dependencies.mk
endifдалее в основном make файле определить переменную окружения DEPENDENCIES_GRAPHVIZ=Y
MK_PATH:=$(dir $(realpath $(lastword $(MAKEFILE_LIST))))
#@echo $(error MK_PATH=$(MK_PATH))
WORKSPACE_LOC:=$(MK_PATH)../../
INCDIR += -I$(MK_PATH)
INCDIR += -I$(WORKSPACE_LOC)
DEBUG=Y
TARGET=board_name_build_name
DEPENDENCIES_GRAPHVIZ=Y
include $(MK_PATH)config.mk
ifeq ($(CLI),Y)
include $(MK_PATH)cli_config.mk
endif
ifeq ($(DIAG),Y)
include $(MK_PATH)diag_config.mk
endif
ifeq ($(UNIT_TEST),Y)
include $(MK_PATH)test_config.mk
endif
include $(WORKSPACE_LOC)code_base.mk
include $(WORKSPACE_LOC)rules.mk
Теперь достаточно просто открыть консоль и набрать make all и вместе с артефактами с прошивкой у Вас рядом появится и файлы документации с изображением зависимостей. Скрипт сборки сгенерирует вот такой финальный Graphviz код
strict digraph graphname {
rankdir=LR;
splines=ortho
node [shape="box"];
REG->ADC
NVIC->ADC
REG->FLASH
REG->GPIO
REG->TIMER
TIMER->TIME
REG->I2S
NVIC->I2S
SW_DAC->I2S
NVIC->I2C
GPIO->I2C
REG->I2C
FLASH->NVS
GPIO->PDM
NVIC->PDM
REG->PDM
DFT->PDM
RAM->PDM
AUDIO->PDM
DMA->PDM
GPIO->SPI
NVIC->SPI
SYSTICK->TIME
GPIO->UART
UART->LOG
LOG->CLI
CLI->PROTOCOL
CRC8->TBFP
RAM->ARRAY
SPI->DW1000
GPIO->DW1000
TIME->DW1000
DW1000->DWM1000
CRC7->SD_CARD
CRC16->SD_CARD
SPI->SD_CARD
GPIO->SD_CARD
TIME->SD_CARD
DW1000->DECADRIVER
TIME->DECADRIVER
GPIP->DECADRIVER
SPI->DECADRIVER
I2S->MAX98357
GPIO->MAX98357
SD_DAC->MAX98357
NVIC->CORTEX_M33
SYSTICK->CORTEX_M33
}
В качеств примера у Вас получится примерно вот такой граф зависимостей.
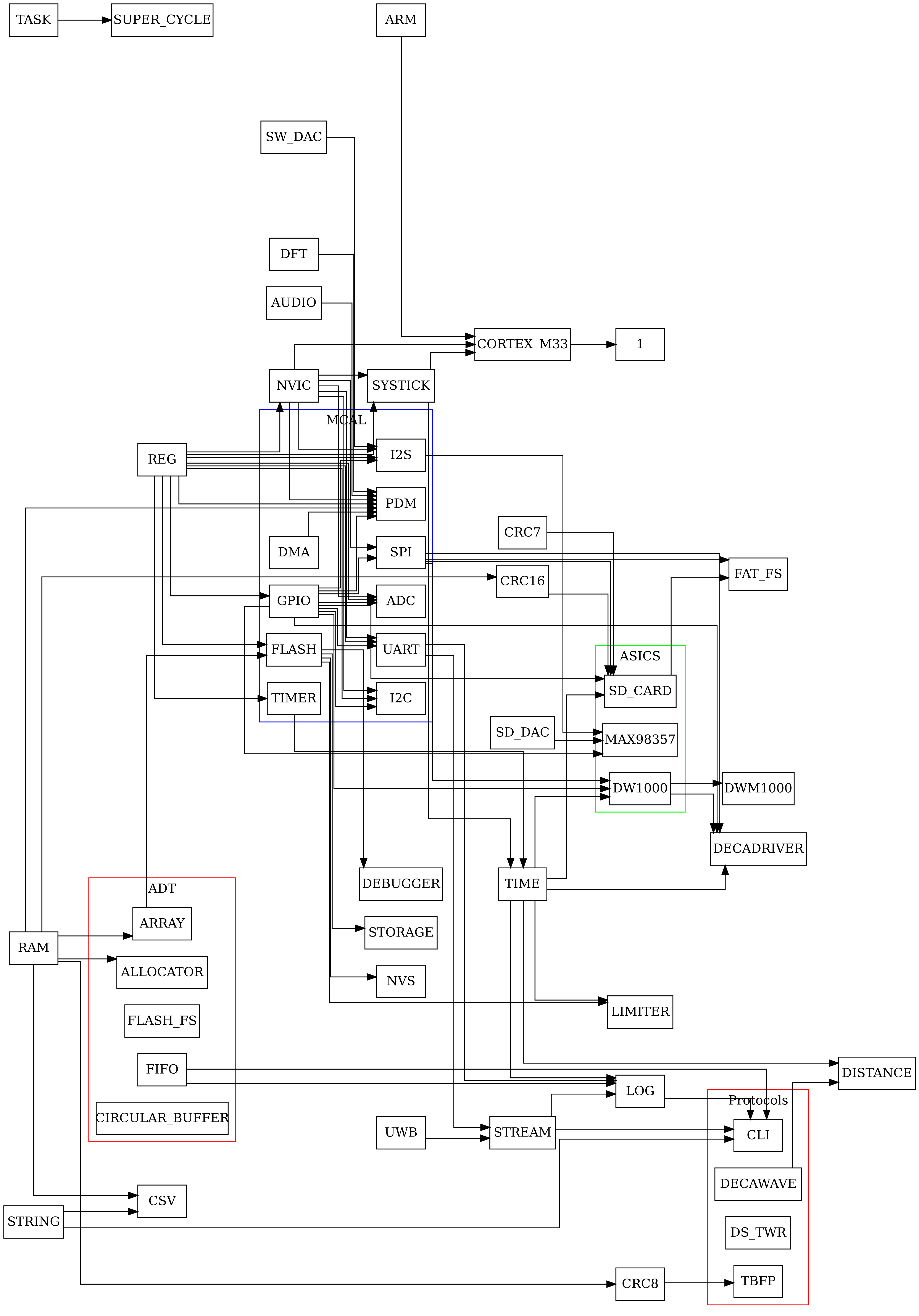
Для расширения детализации дерева зависимостей надо просто добавлять новые *.gvi файлы. Их будет много (десятки) но они простые как правило по 3-6 строчек в каждом. В каждой папке с кодом должен лежать один *.gvi файл.
Вот, например, граф зависимости программных компонентов для прошивки хранителя паролей Pas~ r1.1
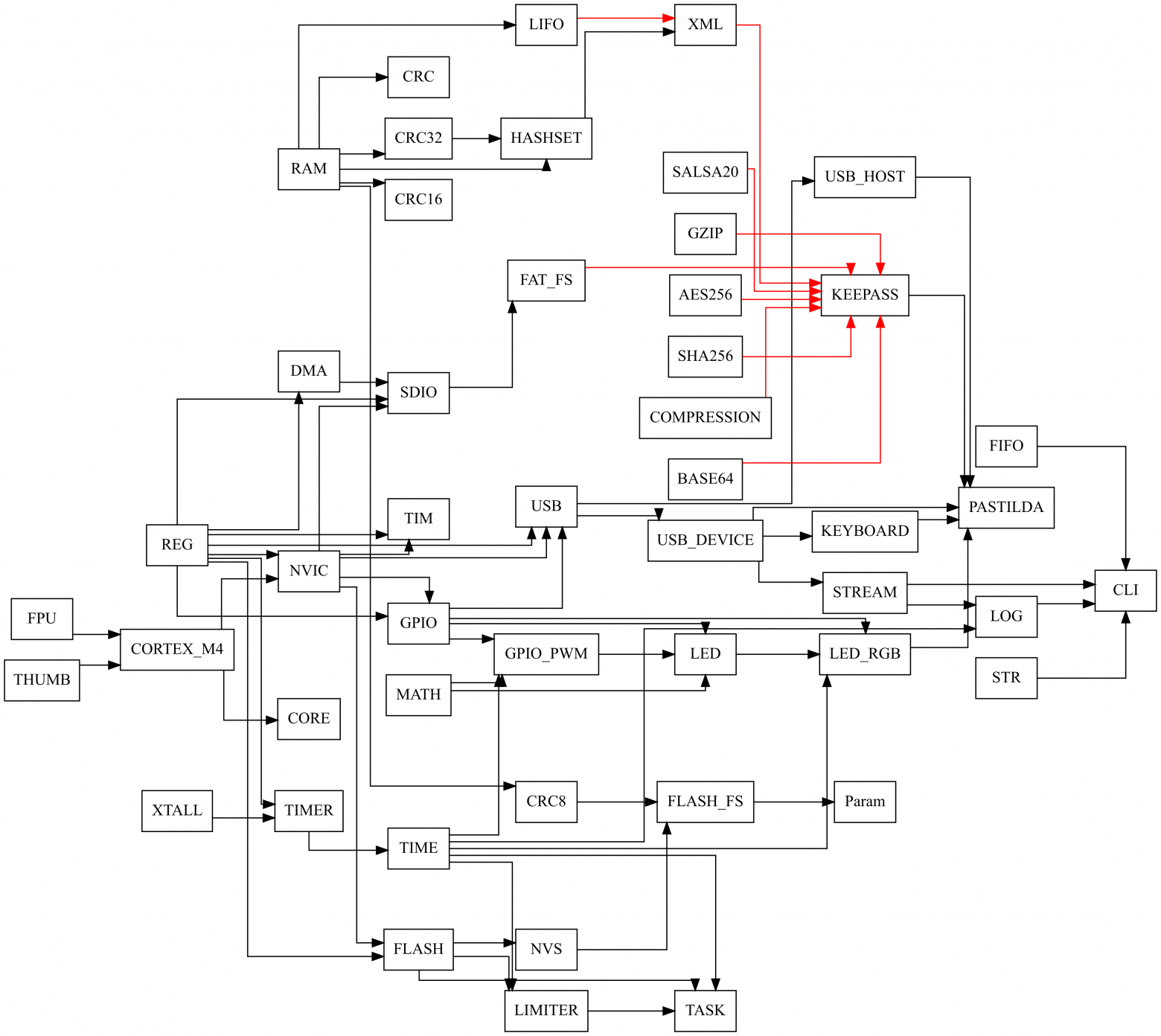
Достоинства графа зависимостей
Хорошая схема зависимостей программных компонентов поможет быстро ввести в курс дела новых людей. Прежде всего программистов.
Граф зависимостей позволит выявить паразитные зависимости и оптимизировать архитектуру всей программы.
Автогенератор зависимостей легко встраивается в сборку, если система сборки предварительно написана на make скриптах, так как утилита make она, в сущности, всеядная. Утилите make.exe как и cpp.exe всё равно для какого языка программирования Вы её вызвали. Make.exe — это просто дирижёр программного конвейера.
Для каждой отдельной сборки строится её собственный граф зависимостей. Лишний код из соседней папки не участвует.
Граф строится автоматически по коду из *.gv файла. Мышка тут абсолютно не нужна.
Недостатки графа зависимостей
Надо писать makefile надо освоить спецификацию GNU make (т. е. просмотреть по диагонали 200 страниц). Если Вы всё еще в 2023м собираете прошивки из GUI‑IDE, то могу Вам только посоветовать позвонить в техподдержку вашей IDE.
Надо вручную прописать *.gvi файл для каждого программного компонента.
Автоматический трассировщик графа от Graphviz не всегда удачно разводит граф

Вывод
Как видите, сборка из скриптов позволяет Вам помимо получения бинарных артефактов (*.bin, *.hex, *.map, *.elf) также авто генерировать всяческую документацию. Например такую полезную схему как дерево зависимостей между программными компонентами. Это является хорошей причиной, чтобы собирать прошивки не из GUI-IDE, а из самописных скриптов.
Стоит отметить, что получившееся дерево зависимостей программных компонентов поймут скорее только программисты-микроконтроллеров нежели схемотехники. Чтобы читать дерево зависимостей надо примерно знать основы Computer Science. Надо понимать, что такое CRC, CLI, CSV, FIFO, BASE64, AES256, XLM, LIFO, DFT и прочее.
А вообще как по мне, дак самая лучшая документация к коду - это модульные тесты. https://habr.com/ru/articles/698092/
В модульных тестах сразу видно как заполнять прототипы функций и что делать с результатом работы функции.
Словарь
Акроним |
Расшифровка |
GVI |
Graphviz Include |
Links
https://dreampuf.github.io/GraphvizOnline/
Синергия Graphviz и препроцессора C/C++
Почему Важно Собирать Код из Скриптов
Тандем Cpp/Dot для Описания Сложных ToolСhain(ов)
Язык Graphviz для Автогенерации Блок-Схем Сложных Электронных Цепей
Задача про две ёмкости для жидкости
Комментарии (40)

Gorthauer87
15.10.2023 07:32+3Так можно же просто взять doxygen

aabzel Автор
15.10.2023 07:32-1Разве doxygen это про графы?
На сколько я помню doxygen он просто генерировал wiki, которая подписывает назначение аргументов функций, при этом надо было еще написать явно кучу комментариев согласно спец синтаксису, чтобы doxygen всё понял без ошибок.
И это было похоже на мартышкин труд.
kozlyuk
15.10.2023 07:32+1aabzel Автор
15.10.2023 07:32+1Если строить граф на основе каждого include(а), то такой граф будет очень перегружен. И анализировать его будет очень трудно.
kozlyuk
15.10.2023 07:32+3Согласен. Тут вопрос, какая стоит цель. Мне полученный в статье граф не кажется особо полезным, чтобы вникнуть в проект. Из хорошего: перечень используемых модулей и знание, что какие-то модули точно не связаны (если автор GVI не врёт). Может быть, модули надо инициализировать в порядке топологической сортировки, но это не точно, вдруг какие-то из стрелок как раз значат "инициализирует". Я бы рассматривал то, что показано в статье, как скелет инструментов и процессов, на который далее можно нарастить мясо из дополнительных сведений — Graphviz это позволяет.
aabzel Автор
15.10.2023 07:32-1Мне полученный в статье граф не кажется особо полезным, чтобы вникнуть в проект.
Хорошему программисту вообще и сорцов достаточно.
aabzel Автор
15.10.2023 07:32Тут вопрос, какая стоит цель.
Меня схемотехники попросили составить "документацию на ПО". Два дня не понимал, что это значит (документация на ПО) и в результате вот, я им и дал граф зависимостей между программными компонентами.
kozlyuk
15.10.2023 07:32+3Звучит как формальное решение своей задачи "дать документ, который устроит схемотехников". Непонятно, какую их проблему решит такой граф, а если нужна была какая угодно диаграмма, то и граф включений сошел бы. К чему тогда слова про подключение к проекту новых сотрудников?
Исходников достаточно только в небольших проектах. Если взаимодействует много подсистем, да еще на разных языках (это не про embedded, конечно), то очень полезно видеть, кто к кому обращается и зачем, где и какая информация доступна.
aabzel Автор
15.10.2023 07:32-2К чему тогда слова про подключение к проекту новых сотрудников?
Показалось, что схема зависимостей тоже немного поможет и в этом.
aabzel Автор
15.10.2023 07:32Звучит как формальное решение своей задачи "дать документ, который устроит схемотехников". Непонятно, какую их проблему решит такой граф, а если нужна была какая угодно диаграмма, то и граф включений сошел бы.
У меня был случай, когда в отделе РЭА ко мне пришел начальник-схемотехник и попросил, чтобы я составил документ-требования к транспортировке программного обеспечения (ПО) железнодорожными видами транспорта. Вот так и живем...
aabzel Автор
15.10.2023 07:32Непонятно, какую их проблему решит такой граф, а если нужна была какая угодно диаграмма, то и граф включений сошел бы.
Уменьшит неопределенность того, что происходит в софте. Создаст чувство контроля над ситуацией.

devprodest
15.10.2023 07:32-1После этого графа ещё больше вопросов, к сожалению.
К тому же читаемость сильно страдает из-за большого количества лишних блоков и линий связи.
Вероятно лучше сделать многоуровневую структуру и сначала показать верхние модули, а очевидно простые исключить вовсе. Сейчас это просто каша
aabzel Автор
15.10.2023 07:32Тут вопрос, какая стоит цель.
Ещё начальство отдела РЭА хочет получить какую-то абстрактную документацию по программному обеспечению firmware.
При этом смотреть код они не хотят. И что мне им предоставить?kozlyuk
15.10.2023 07:32+1Или не хочет, а только говорит. Для начала сходить узнать, что им на самом деле надо. Может быть, у них реальная проблема, но для решения которой нужно совсем другое. Может, им позарез надо выиграть пару дней под видом "программист пишет документацию", и можно делать что угодно. Может, они хотят прикрыть свой провал тем, что вы не даете им то не знаю что, и надо было эскалировать ситуацию. Может, они самодурствуют, но вы сумели извлечь из этого то, что изучили Graphviz и сделали основу для документации — без тени иронии, отличный корпоративный маневр.
aabzel Автор
15.10.2023 07:32-1О doxygen имеет смысл говорить лишь после того, как код сперва будет покрыт модульными тестами.
Gorthauer87
15.10.2023 07:32+1Хм, тогда проще просто сразу переписать на Rust.
На самом деле, не вижу тут никакой связи, документация на код вещь важная, тесты тоже, да инструменты которые позволяют делать и то и то лучше с самого начала интегрировать в проект.
Но вот использовать самодельные инструменты лучше если каким-то популярными вообще никак не решить проблему, а то иначе вместо одной проблемы их станет несколько.
aabzel Автор
15.10.2023 07:32-1Cамая лучшая документация к коду - это модульные тесты.
https://habr.com/ru/articles/698092/
В модульных тестах сразу видно как заполнять прототипы функций и что делать с результатом работы функции.
aabzel Автор
15.10.2023 07:32Так можно же просто взять doxygen
Утилита grep работающая в папке с репозиторием при определенной сноровке может выдать отличную документацию.

LAutour
15.10.2023 07:32+1В программировании микроконтроллеров программы часто строятся иерархично.
По факту чаще наблюдается повальное злоупотребление перекрестными включениями, когда вся иерархия сливается в один общий неразрывный комок.
aabzel Автор
15.10.2023 07:32По факту чаще наблюдается повальное злоупотребление перекрестными включениями, когда вся иерархия сливается в один общий неразрывный комок.
Да. К сожалению не без этого...

AlexGfr
15.10.2023 07:32+3По-моему, Doxygen выдает примерно то же самое, только сразу из *.c кода и с меньшими усилиями
aabzel Автор
15.10.2023 07:32-4Для Doxygen надо писать много комментариев в коде согласно спец. синтаксису.
Это можно замучиться писать много комментариев.AlexGfr
15.10.2023 07:32Графы включения и использования Doxygen генерирует не используя эти коментарии.
Реально замучиться можно разбираясь в коде без коментариев (есть опыт).
aabzel Автор
15.10.2023 07:32-1Doxygen будет строить монструозный граф для всей кодовой базы, а если компоновать gv из make, то для каждой отдельной сборки строится её отдельный и собственный граф зависимостей в котором нет ничего лишнего.
Лишний код из соседней папки просто не участвует.И в это весь смысл.
aabzel Автор
15.10.2023 07:32Как по мне, дак лучшая документация к коду - это модульные тесты.
https://habr.com/ru/articles/698092/
Сразу видно как заполнять прототипы функций и что делать с результатом работы функции.devprodest
15.10.2023 07:32-1Очень спорное утверждение, прям максимально спорное.
Даже кажется что в этих словах теплое и мягкое сравнивается.


devprodest
15.10.2023 07:32+1Так мы оказывается не зависимости генерируем (что бы это не значило), а граф зависимостей.
Граф не полный, куча листьев в воздухе висит: Фифо, таски, црц и др.
То есть всё в программе живёт где-то там.. а основной код (суперцикл) его не использует

olartamonov
15.10.2023 07:32Хорошая документация поможет быстро ввести в курс дела новых людей.
Хорошая — поможет.
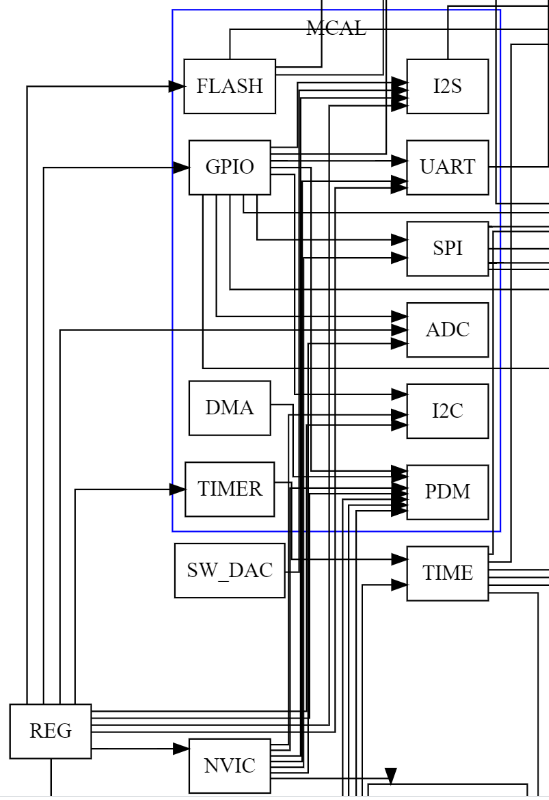
Но вот эта каша — это плохая документация. Точнее, это вообще не документация — это плохо сделанная иллюстрация к ненаписанной документации.
aabzel Автор
15.10.2023 07:32-1Если раскрасить ребра, то будет понятнее. Graphviz как раз позволяет раскрашивать ребра.
olartamonov
15.10.2023 07:32Не будет. Каша превратится в винегрет, а понятнее — не будет.
Любая автогенерируемая псевдодокументация требует серьёзной обработки руками для превращения её в настоящую документацию. Без этого — просто способ дёшево нашлёпать много картинок (текстов, etc.) плохого качества, we call this beta because its betta than nothing.
То есть, простительно, когда к тебе ворвались с криком «у нас новый человек, надо к понедельнику срочно ввести его в курс дела!», а сейчас уже четверг и до этого никто никакой документацией вообще не занимался. К вечеру ты вот такого нагенерил, в пятницу человека в это потыкал, вроде он чего-то понял.
В остальных случаях — нет, это не документация и тем более не «хорошая документация».



Sazonov
Какие преимущества у makefile перед кроссплатформенным cmake? Почему вы именно его используете?
Почему бы просто не пробежаться по исходникам и автоматически собрать граф зависимостей?
aabzel Автор
makefile инвариантен к языку программирования.
Sazonov
makefile не очень дружит с виндой, в отличие от cmake. Комментарий про инвариантность я не понял - что у него что у cmake, что практически у любого языка - свой синтаксис.
P.S. Я не минусую.
aabzel Автор
Собираю из-под Make как раз на Windows 10. Вообще никогда проблем не было.