
Начало предисловия.
Как переводчик-редактор, я интересуюсь темой NLP и автоматизации рутины бюро переводов. Изучая вопрос того, как смысл слов превращается в векторы, наткнулся на эту обзорную статью. Статья мне показалась изложенной доступно, поэтому я перевел ее для удобства других коллег. Работоспособность большей части кода проверял, вроде работает (ссылка на Jupiter Notebook). Надеюсь, будет полезно.
Конец предисловия.
Технологии NLP — Natural Language Processing, обработки естественного языка — позволяют компьютерам обрабатывать человеческий язык, понимать его значение и контекст, а также связанные с ним эмоциональную окраску и намерения, и далее, использовать эти данные для создания чего-то нового.
NLP объединяет вычислительную лингвистику с моделями машинного обучения на базе статистических методов, и в конечном счете с глубоким обучением.
Но как сделать слова понятными для компьютеров? Используется векторизация.
Что такое векторизация?
Векторизация – это термин, обозначающий классический подход к преобразованию входных данных из их исходного формата (например, текста) в векторы действительных чисел, которые понятны моделям машинного обучения. Подход в целом не нов, много где используется со времени создания компьютеров, поэтому логично, что сейчас он используется в NLP.
В машинном обучении векторизация является шагом в извлечении признаков. Идея заключается в получении некоторых отличительных признаков из текста для обучения модели путем преобразования текста в числовые векторы.
Существует множество техник векторизации, как мы скоро увидим, начиная от реализаций с использованием наивных бинарных признаков частоты употребления термина до техник с использованием признаков, учитывающих сложный контекст. В зависимости от конкретной ситуации и модели, любая из этих техник может быть способна выполнять необходимую задачу.
1. Мешок слов
Самая простая из всех существующих техник. Она включает в себя три операции:
Токенизация
Сначала входной текст разбивается на токены. Предложение представляется в виде списка его составляющих слов, и это делается для всех входных предложений.
Создание словаря
Из всех полученных токенизированных слов выбираются только уникальные слова, которые затем сортируются в алфавитном порядке.
Создание вектора
Наконец, из показателей частоты слов получившегося словаря создается разреженная матрица в качестве входных данных. В этой разреженной матрице каждая строка представляет вектор предложения, длина которого (количество столбцов в матрице) равна размеру словаря.
Посмотрим, как это выглядит на практике, с использованием библиотеки Sklearn.
Сначала импортируем библиотеки.
from sklearn.feature_extraction.text import CountVectorizer
Пусть у нас будет такой список «документов»:
sents = ['coronavirus is a highly infectious disease',
'coronavirus affects older people the most',
'older people are at high risk due to this disease']
Сделаем экземпляр объекта CountVectorizer:
cv = CountVectorizer()
Теперь давайте выполним векторизацию наших входных данных и преобразуем их в массив NumPy для просмотра.
X = cv.fit_transform(sents)
X = X.toarray()
Вот так будут выглядеть наши векторы:
array([[0, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 0, 0],
[0, 1, 1, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 1, 1]])
Выведем наш словарь:
sorted(cv.vocabulary_.keys())
['affects',
'are',
'at',
'coronavirus',
'disease',
'due',
'high',
'highly',
'infectious',
'is',
'most',
'older',
'people',
'risk',
'the',
'this',
'to']
Видно, что каждая строка является соответствующим эмбеддингом, т.е. векторным представлением соответствующих предложений в списке
sents.Длина каждого вектора равна длине словаря.
Каждый элемент списка представляет собой частоту соответствующего слова в отсортированном словаре.
В приведенном выше примере мы учли в качестве признаков только отдельные слова, как видно в ключах словаря, т.е. это униграмное представление. Однако это представление можно перенастроить и для n-граммных признаков.
Допустим, мы хотим сформировать биграммное представление нашего ввода. Это можно сделать, просто изменив аргумент по умолчанию при создании объекта CountVectorizer:
cv = CountVectorizer(ngram_range=(2,2))
X = cv.fit_transform(sents)
X = X.toarray()
И в таком случае наши векторы и словарь будут выглядеть так:
array([[0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0],
[0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 0, 1, 0, 1, 1]])
sorted(cv.vocabulary_.keys())
['affects older',
'are at',
'at high',
'coronavirus affects',
'coronavirus is',
'due to',
'high risk',
'highly infectious',
'infectious disease',
'is highly',
'older people',
'people are',
'people the',
'risk due',
'the most',
'this disease',
'to this']
Таким образом, признаками можно манипулировать и делать пространство признаков по своему усмотрению — из униграмм, биграмм, триграмм и т. д.
Хотя здесь мы использовали библиотеку sklearn для создания модели «мешка слов», ее можно реализовать разными способами, с использованием библиотек, таких как Keras, Gensim и других. Вы также можете легко написать свою собственную реализацию «мешка слов».
Это простой, но эффективный метод кодирования текста, который вполне может являться решением некоторых задач.
TF-IDF
TF-IDF (Term Frequency-Inverse Document Frequency) — это числовой статистический показатель, который отражает важность слова для документа. И хотя эта методика тоже основана на частотности, как и «мешок слов», она использует более сложные расчеты.
В чем TF-IDF лучше «мешка слов»?
В «мешке слов» мы видели, как векторизация сводилась только к показателям частотности слов из словаря по данному документу. В результате, артикли, предлоги и союзы, вклад которых в общий смысл предложения не так важен, получают такой же вес, как, например, и прилагательные.
Механика TF-IDF решает эту проблему — и слова, которые повторяются слишком часто, не зашумляют другие, менее частотные, но тем не менее важные слова.
Алгоритм состоит состоит из двух частей:
TF
TF означает Term Frequency (частотность термина), то есть нормализованный показатель частоты. Он вычисляется по следующей формуле:
TF = Frequency of word in a document / Total number of words in the document
то есть
TF = Частотность термина в документе / Общее количество слов в документе
Таким образом, можно исходить из того, что это число всегда будет ≤ 1, и с этим учетом уже оценивать, насколько часто слово встречается в контексте всех слов в документе.
###IDF
IDF означает Inversed Document Frequency (обратная частота документа aka инверсия частотности). Чтобы понять, что это такое, надо сначала разобраться с тем, что такое DF - частотой документа.
Частоту документа определяют по следующей формуле:
DF = Documents containing word W / Total number of documents
то есть
DF = Количество документов со словом W / Общее количество документов
Частота документа (DF) говорит нам о доле документов, содержащих определенное слово. Соответственно, IDF — это число обратное DF, и в конечном итоге его значение рассчитывается по формуле:
IDF = log(Общее количество документов/количество документов со словом W)
Зачем его делать обратным?
Как уже обсуждалось выше, основное предположение состоит в том, что чем больше распространено слово во всех документах, тем меньше его значение для текущего документа.
Логарифм берется для сглаживания эффекта IDF в окончательном расчете.
Окончательное значение TF - IDF рассчитывается по формуле:
TF - IDF = TF * IDF
Таким образом, показатель TF-IDF учитывает значимость слова — чем выше показатель, тем важнее слово.
Разберемся как TF-IDF используется на практике.
Для этого примера так же как для «мешка слов» воспользуемся библиотекой Sklearn.
Импортируем необходимые модули:
from sklearn.feature_extraction.text import TfidfVectorizer
Воспользуемся теми же предложениями (документами):
sents = ['coronavirus is a highly infectious disease',
'coronavirus affects older people the most',
'older people are at high risk due to this disease']
Создадим экземпляр объекта TfidfVectorizer():
tfidf = TfidfVectorizer()
Преобразуем наши данные:
transformed = tfidf.fit_transform(sents)
Посмотрим, какие признаки важны, а какие бесполезны. Для упрощения интерпретации воспользуемся библиотекой Pandas, чтобы получить более наглядное представление о показателях признаков.
Импортируем необходимые модули:
import pandas as pd
Создаем таблицу данных с названиями признаков, то есть со словами (в столбце индекса), отсортированными по показателям TF-IDF (в столбце показателей):
df = pd.DataFrame(transformed[0].T.todense(),
index=tfidf.get_feature_names_out(), columns=["TF-IDF"])
df = df.sort_values('TF-IDF', ascending=False)
print(df)
TF-IDF
infectious 0.490479
highly 0.490479
is 0.490479
coronavirus 0.373022
disease 0.373022
older 0.000000
this 0.000000
the 0.000000
risk 0.000000
people 0.000000
affects 0.000000
most 0.000000
are 0.000000
high 0.000000
due 0.000000
at 0.000000
to 0.000000
Поскольку преобразованная матрица признаков TF-IDF изначально была представлена в виде разреженной матрицы Scipy Compressed Sparse Row, которую неудобно смотреть в исходной форме, мы преобразовали ее в итоге в массив Numpy, используя метод todense(). Таким же образом мы получаем полный словарь токенизированных слов с помощью функции get_feature_names_out().
Таким образом, согласно TF-IDF, слово infectious — самый важный признак, в то время как многие другие слова, которые обычно использовались для создания признаков в наивном подходе, типа «мешка слов», здесь просто равны нулю. То, что нужно.
Несколько соображений о TF-IDF:
Здесь вполне применима также концепция n-грамм. В частности, мы можем комбинировать слова в группы по 2, 3, 4 и более слов, чтобы сгенерировать окончательный набор признаков.
Вместе с n-граммами также существует ряд параметров, таких как
min_df,max_df,max_features,sublinear_tfи т.д., с которыми можно поэкспериментировать. Если грамотно их настроить, можно значительно улучшить возможности модели.
Несмотря на казалось-бы свою примитивность в плане вычисления, показатель TF-IDF широко используется в задачах с использованием поисковых технологий для определения наиболее подходящего ответа на запрос, особенно полезен в чат-ботах или при извлечении ключевых слов для определения наиболее релевантных для документа слов. Таким образом, вам часто будет попадаться на глаза старый-добрый TF-IDF.
Итак, до сих пор мы рассматривали методы кодирования текста на основе частотности слов — пришло время взглянуть на более сложные методы, которые изменили мир эмбеддингов — векторных представлений слов, - каким мы его знали, и открыли новые возможности для исследований в области обработки естественного языка.
3. Алгоритм Word2Vec
Этот подход был предложен еще аж в 2013 году исследователями Google в этой статье и тогда он встряхнул все сообщество специалистов по NLP. Если кратко, то этот подход задействует мощь простой нейронной сети для создания эмбеддингов.
Как Word2Vec повышает эффективность методов, основанных на частотности?
В «мешке слов» и при подходе TF-IDF каждое слово обрабатывалось как отдельная сущность, при этом семантика слова игнорировалась. Разработчики Word2Vec же заявили, что их эмбеддинги — судя по всему впервые — учитывают контекст.
Возможно, одним из самых известных примеров применения Word2Vec является следующее выражение:
king – man + woman = queen // т.е. король - мужчина + женщина = королева
Поскольку каждое слово представлено как n-мерный вектор, то можно представить, что все слова отображены в этом n-мерном пространстве (гиперпространстве) таким образом, что слова с похожими значениями находятся рядом друг с другом.
Есть два основных способа реализации Word2Vec, рассмотрим их по очереди:
A: Skip-Gram
Итак, первый метод - это метод Skip-Gram, в котором мы передаем какое-то слово нашей нейронной сети и просим ее предположить возможный контекст. Общая идея приведена на схеме ниже:
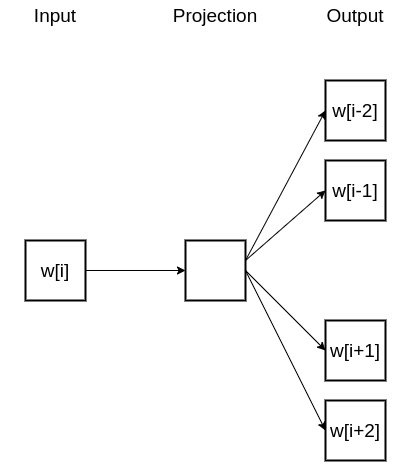
Здесь w[i] - это слово, которое передается на вход и которое находится на позиции i в предложении. На выходе результирующее выражение содержит два предшествующих слова и два последующих слова с учетом позиции i.
Технически этот подход прогнозирует вероятность того или иного слова быть контекстом для заданного слова. Показатели вероятности появления того или иного слова в результирующем выражении показывают, насколько вероятно увидеть то или иное слово из словаря рядом с входным словом.
Такая небольшая нейросеть состоит из входного слоя, одного скрытого слоя и выходного слоя. Позже мы к ним еще вернемся.
Фокус здесь состоит в том, что на самом деле никакой обученной нейросети у нас нет. Здесь другая цель — изучить веса скрытого слоя по мере того, как корректируются спрогнозированные веса окружающих слов. Эти веса и есть эмбеддинги.
Количество соседних слов, которое сеть должна спрогнозировать, определяется параметром, называемым window size. Это окно - т.е. window - расширяется в обоих направлениях от слова, то есть и влево, и вправо.
Допустим, нам надо обучить модель word2vec через skip-gram по следующему входному предложению:
“The quick brown fox jumps over the lazy dog”
На этой картинке видно, на какие тренировочные выборки нарезается входной текст при window size = 2.

Слово "The" становится первым результирующим словом, и так как оно первое слово в предложении, и слева от него нет слов, то
window size = 2расширяется только вправо, что мы и видим в приведенных тренировочных выборках.По мере того, как мы смещаем фокус нашего внимания к следующему слову, окно расширяется на
1позицию влево от изначального.Наконец, когда целевое слово находится уже где-то посередине фразы, тренировочные выборки генерируются, как задумано.
Нейросеть
Теперь давайте поговорим о нейросети, которая будет обучаться на таких выборках.
Интуиция
Если вы знаете, что такое автоэнкодер, то, наверное, обратили внимание, что логика работы этой сети тут схожая.
Вы берете очень большой входной вектор, сжимаете его до плотного представления в скрытом слое, и затем, вместо восстановления исходного вектора, как в случае с автоэнкодерами, вы выводите наиболее вероятные слова с учетом их показателей вероятности по каждому слову в словаре.
Ввод и вывод
Возникает вопрос — как одно слово становится большим вектором?
Ответ: через прямое кодирование (или one-hot encoding).
Допустим, в нашем словаре около 10 000 слов, и где-то там есть нужное нам слово "fox". В таком случае, мы поставим
1в позициях, где это слово есть, и 0 во всех остальных местах. Соответственно, мы получим 10 000-мерный вектор с одной единицей в качестве ввода.Аналогично, на выходе из сети мы получим 10 000-мерный вектор, в котором для каждого слова из нашего словаря будет указано значение вероятности появления этого слова в качестве контекста для исходного слова, т.е. "fox". Наша нейросеть будет выглядеть примерно так:

На схеме видно, что на вход мы передаем 10 000-мерный вектор (равный размеру нашего словаря), в котором каждая
1соответствует позиции нужного слова.В выходном слое у нас 10 000 нейронов, они активируются через функцию
softmax, и получают значение вероятности для каждого слова из нашего словаря.Таким образом, самая важная часть этой сети — скрытый слой — становится линейным слоем, то есть там не используется функция активации, и оптимизированные веса этого слоя станут выученными эмбеддингами слов.
Например, если мы заходим узнать эмбеддинги слов в этой сети, то мы будем исходить из того, что форма матрицы весов в скрытом слое будет равна
M х N, гдеM= размер словаря (в нашем случае 10 000), аN= число нейронов скрытого слоя (в нашем случае 300).Как только обучение модели закончится, окончательные эмбеддинги для нашего целевого слова будут вычисляться по формуле:
входной вектор 1×10000 * матрица 10000×300 = вектор 1×300
В своей обученной модели Google использовал 300 нейронов скрытого слоя, но поскольку это число является гиперпараметром, его можно корректировать для получения оптимальных для вас результатов.
Примерно таким образом работает skip-gram в модели word2vec. Посмотрим теперь на конкурентов.
B. CBOW
Подход CBOW расшифровывается как Continuous Bag of Words, что в переводе означает «непрерывный мешок слов». В этом подходе мы, вместо того, чтобы предугадывать контекстные слова, добавляем их в модель и просим модель вычислить текущее слово (см. общую схему на картинке):

Таким образом видно, что CBOW — это обратное отражение подхода skip-gram; даже обозначения одни и те же.
Теперь, поскольку мы уже погрузились в то, что такое skip-gram и в то, как он работает, мы не будем повторяться в общих для обоих подходов моментах. Вместо этого, мы просто расскажем о том, в чем CBOW принципиально отличается от skip-gram. Рассмотрим его архитектуру:

Размеры скрытого и выходного слоев остаются такими же, как и в skip-gram.
Однако в CBOW на вход подаются слова контекста, поэтому входные данные тут соответствуют
Сконтекстных слов, подаются они как one-hot вектор размером1xVкаждый, гдеVсоответствует размеру словаря, что делает размерность всех входных данных равнойCxV.Теперь каждый из этих векторов
Cбудет умножен на веса нашего скрытого слоя, форма которого соответствуетVxN, гдеV- размер словаря, аN- количество нейронов в скрытом слое.Очевидно, что в результате получим
Cвекторов размером1xN, и все этиCвекторов будут по очереди усреднены для итоговой активации скрытого слоя, которая будет передана в наш выходной слой с применением функции softmax.Рассчитанные таким образом веса между скрытым и выходным слоями и являются эмбеддингами вложенного слова.
Если я объяснил слишком мудрено, то поясню про CBOW вкратце:
Поскольку в контексте у нас несколько слов, их веса усредняют, чтобы получить значения весов из скрытого слоя. После такого усреднения процесс становится похожим на тот, который мы имели в skip-gram модели, и рассчитанные значения эмбеддингов извлекаются из выходного слоя, а не из скрытого.
Когда использовать модель skip-gram, а когда CBOW?
Согласно исходной публикации статье, skip-gram хорошо работает с небольшими наборами данных и может лучше представлять редкие слова.
В то же время, CBOW обучается быстрее, чем skip-gram, и может лучше представлять часто встречающиеся слова.
Следовательно, выбор между skip-gram и CBOW зависит от того, какую задачу мы пытаемся решить.
А теперь пора переходить к практике — посмотрим, как использовать word2vec для создания эмбеддингов.
В этом примере воспользуемся библиотекой gensim и импортируем ее.
from gensim import models
Теперь есть два варианта: либо мы используем предварительно обученную модель, либо обучаем новую сами. Рассмотрим один из них.
Cначала воспользуемся предварительно обученной моделью Google, чтобы посмотреть, в каких моментах она может быть особенно полезна. Эту модель вы можете забрать отсюда и ниже указать путь к разархивированному файлу, или получить её с помощью следующих команд Linux.
!wget -c "https://s3.amazonaws.com/dl4j-distribution/GoogleNews-vectors-negative300.bin.gz"
!gzip -d GoogleNews-vectors-negative300.bin.gz
Загрузим эту модель. Нужно учитывать, что она очень большая и простой ноутбук на ней может зависнуть.
from google.colab import drive
drive.mount('/content/gdrive/')
w2v = models.KeyedVectors.load_word2vec_format('/content/gdrive/GoogleNews-vectors-negative300.bin', binary=True)
Векторное представление для любого слова, скажем, healthy, можно получить с помощью команды:
vect = w2v['healthy']
В результате мы получаем 300-мерный вектор.
Мы также можем воспользоваться этой предобученной моделью, чтобы получить синонимы для входного слова, например, happy.
w2v.most_similar('happy')
output
[('glad', 0.7408890724182129),
('pleased', 0.6632170677185059),
('ecstatic', 0.6626912355422974),
('overjoyed', 0.6599286794662476),
('thrilled', 0.6514049172401428),
('satisfied', 0.6437949538230896),
('proud', 0.636042058467865),
('delighted', 0.627237856388092),
('disappointed', 0.6269949674606323),
('excited', 0.6247665286064148)]
Модель прекрасно справляется с задачей и в результате мы получаем список пар соответствующих слов с оценками их сходства, отсортированными в порядке убывания показателя сходства.
Напомним, что вы также можете обучить и собственную модель word2vec.
Давайте снова воспользуемся предыдущим набором предложений в качестве обучающего набора данных для нашей собственной модели word2vec.
sents = ['coronavirus is a highly infectious disease',
'coronavirus affects older people the most',
'older people are at high risk due to this disease']
Модели word2vec нужен набор данных для обучения в виде списка токенизированных предложений, поэтому мы предварительно эти предложения обработаем и преобразуем:
sents = [sent.split() for sent in sents]
Наконец, мы можем приступить к обучению нашей модели:
custom_model = models.Word2Vec(sents, min_count=1,vector_size=300,workers=4)
То, насколько хорошо будет работать наша модель зависит от нашего набора данных и от того, насколько тщательно она была обучена. Как бы то ни было, она вряд ли переплюнет предобученную модель Google.
Итак, с word2vec мы пока закончили, если хотите более наглядное представление того, как работают модели word2vec, перейдите по этой ссылке — там все довольно круто визуализировано.
4. GloVe
Метод GloVe расшифровывается как Global Vectors for word representation. Метод был разработан в Стэнфорде, публикация с его описанием находится здесь, она вышла в свет всего через год после публикации статьи про word2vec.
Подобно word2Vec, суть метода GloVe заключается в том, чтобы тоже создавать контекстные эмбеддинги, причем так же быстро, как и в word2Vec. Возникает вопрос: зачем был нужен GloVe?
В чем GloVe лучше Word2Vec?
Word2Vec - это оконный метод, где модель полагается на локальную информацию для создания эмбеддингов слов, которые в свою очередь ограничены установленными нами размерами окна.
Это означает, что семантическое поле, выученное для рассматриваемого слова, зависит только от слов, которые окружали его в исходном предложении — согласитесь, это не очень правильное использование статистики, ибо контекст можно использовать намного шире.
Таким образом, GloVe в эмбеддингах слов стал учитывать как глобальную, так и локальную статистику.
Так, ок. Что такое локальная статистика — мы видели в Word2Vec. А что такое «глобальная»?
GloVe извлекает семантику из матрицы совместной встречаемости слов. Метод учитывает тот факт, что совместная встречаемость — это важная информация, и такая статистика весьма полезна при создании векторных представлений слов. Именно таким образом GloVe удается учитывать «глобальную статистику» в конечном результате.
Если вам незнакомо понятие матрицы совместной встречаемости слов, извольте пример.
Допустим, у нас есть два документа или предложения.
Документ 1: All that glitters is not gold.
Документ 2: All is well that ends well.
Тогда, при фиксированом размере окна n = 1, наша матрица совместной встречаемости будет выглядеть так:

Посмотрев на нее, вы увидите, что строки и столбцы составлены из нашего словаря, т.е. из набора уникальных токенизированных слов, полученных из обоих документов.
Здесь метки и используются для обозначения начала и конца предложений.
Окно размером
1расходится в обе стороны от слова, и потому that и is встречаются по одному разу в пределах одного окна со словом glitters, и поэтому значение пар(that, glitters)и(is, glitters)равны1. В этом и есть основная идея таблицы.
Теперь пара слов об обучении. Модель GloVe - это взвешенный метод наименьших квадратов, и поэтому ее функция потерь (cost function) выглядит примерно так:

Для каждой совместно встречаемой пары слов (i,j) мы стремимся минимизировать разницу между произведением их эмбеддингов и логарифмом количества раз, когда они встречаются вместе. Выражение f(Pij) позволяет получить их взвешенную сумму и устанавливать более низкие веса для наиболее часто совместно встречаемых пар слов, тем самым подавляя их важность.
Когда лучше использовать GloVe?
Практика показала, что GloVe превосходит другие модели в задачах выявления аналогичных и схожих слов, распознавания именованных сущностей (Entity Recognition), поэтому, если вы пытаетесь решить похожую задачу — GloVe вполне подойдет.
Поскольку GloVe учитывает глобальную статистику, он также может улавливать семантику редких слов и эффективен даже на небольшом корпусе текстов.
Посмотрим, как можно использовать возможности эмбеддинги в GloVe.
Сначала скачаем файл эмбеддингов, затем создадим их словарь:
import numpy as np
embeddings_dict={}
with open('/content/gdrive/MyDrive/Colab_Notebooks/glove.6B.50d.txt','rb') as f:
for line in f:
values = line.split()
word = values[0]
vector = np.asarray(values[1:], "float32")
embeddings_dict[word] = vector
При обращении к этому словарю эмбеддингов мы получаем следующий массив:
embeddings_dict[b'test']
array([ 0.13175 , -0.25517 , -0.067915, 0.26193 , -0.26155 , 0.23569 ,
0.13077 , -0.011801, 1.7659 , 0.20781 , 0.26198 , -0.16428 ,
-0.84642 , 0.020094, 0.070176, 0.39778 , 0.15278 , -0.20213 ,
-1.6184 , -0.54327 , -0.17856 , 0.53894 , 0.49868 , -0.10171 ,
0.66265 , -1.7051 , 0.057193, -0.32405 , -0.66835 , 0.26654 ,
2.842 , 0.26844 , -0.59537 , -0.5004 , 1.5199 , 0.039641,
1.6659 , 0.99758 , -0.5597 , -0.70493 , -0.0309 , -0.28302 ,
-0.13564 , 0.6429 , 0.41491 , 1.2362 , 0.76587 , 0.97798 ,
0.58507 , -0.30176 ], dtype=float32)
Очевидно, что это 50-мерный вектор. Таким образом, получается, что мы загрузили файл glove.6B.50d.txt, чтобы получить 50-мерные эмбеддинги слов на базе модели, обученной на 6 миллиардах слов.
Кроме того, мы можем задать функцию, чтобы получать список похожих слов, опираясь на данные этой модели. Начнем, как обычно, с импорта нужных библиотек.
from scipy import spatial
Определим функцию:
def find_closest_embeddings(embedding):
return sorted(embeddings_dict.keys(), key=lambda word:
spatial.distance.euclidean(embeddings_dict[word], embedding))
Посмотрим, что происходит, когда мы в эту функцию передаем слово health:
find_closest_embeddings(embeddings_dict[b'health'])[:5]
[b'health', b'care', b'medical', b'welfare', b'prevention']
Мы получили топ-5 слов, которые модель считает наиболее похожими по смыслу для health. В целом результат неплох — видно, что контекст хорошо учитывается.
Есть еще один сценарий, в котором целесообразно использовать GloVe - преобразование нашего словаря в векторы. Для этого нам понадобится библиотека Keras — и для начала мы ее установим:
pip install keras
Мы будем использовать тот же набор документов, что и ранее, однако нам нужно будет преобразовать их в список токенов, чтобы потом векторизовать.
sents = ['coronavirus is a highly infectious disease',
'coronavirus affects older people the most',
'older people are at high risk due to this disease']
sents = [sent.split() for sent in sents]
sents
[['coronavirus', 'is', 'a', 'highly', 'infectious', 'disease'],
['coronavirus', 'affects', 'older', 'people', 'the', 'most'],
['older',
'people',
'are',
'at',
'high',
'risk',
'due',
'to',
'this',
'disease']]
Сначала нам нужно предобработать наш набор данных, а потом преобразовать его в векторы.
Продолжим импорты:
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
Через этот код присваиваем индексы словам, чтобы использовать их потом для сопоставления c эмбеддингами:
MAX_NUM_WORDS = 100
MAX_SEQUENCE_LENGTH = 20
tokenizer = Tokenizer(num_words=MAX_NUM_WORDS)
tokenizer.fit_on_texts(sents)
sequences = tokenizer.texts_to_sequences(sents)
word_index = tokenizer.word_index
data = pad_sequences(sequences, maxlen=MAX_SEQUENCE_LENGTH)
Наши данные теперь выглядят так:
data.shape
(3, 20)
data
array([[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 5,
6, 7, 8, 2],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 9,
3, 4, 10, 11],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 4, 12, 13, 14, 15,
16, 17, 18, 2]], dtype=int32)
Мы наконец-то можем преобразовать наш набор данных в эмбеддинги GloVe через простую операцию поиска по нашему только что созданному словарю эмбеддингов. Если слово в словаре есть, то мы берем его эмбеддинг, если нет — то заполняем вектор нулями.
Импортируем нужные библиотеки:
from keras.layers import Embedding
from keras.initializers import Constant
EMBEDDING_DIM = embeddings_dict.get(b'a').shape[0]
num_words = min(MAX_NUM_WORDS, len(word_index)) + 1
embedding_matrix = np.zeros((num_words, EMBEDDING_DIM))
for word, i in word_index.items():
if i > MAX_NUM_WORDS:
continue
embedding_vector = embeddings_dict.get(word.encode("utf-8"))
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
В итоге получаем такой массив (для примера выводим парочку векторов):
embedding_matrix.shape
(19, 50)
embedding_matrix[2:4]
array([[ 1.63329995, -0.19676 , -0.089766 , -0.37891999, -0.62739998,
1.73280001, 0.24982999, -0.59250998, 1.90460002, -0.38705999,
0.83570999, -0.24495 , 0.28255999, -0.91197997, 0.57435 ,
0.55039001, -0.48894 , -0.24747001, -0.31524 , 1.01680005,
-1.34080005, -0.55049002, 1.0977 , 0.07084 , 0.75312001,
-1.57050002, -0.42137 , -0.50237 , 0.20359001, 0.65403998,
2.75970006, 0.25246999, 0.60793 , -0.98095 , -0.68840998,
0.06251 , 0.37639999, 0.50467002, 0.96666998, 0.10665 ,
-0.96799999, -0.11266 , 0.42783001, 0.67264003, 2.21000004,
0.51665002, -0.033427 , -0.17797001, 0.34316 , 0.32199001],
[ 0.14872 , 0.55274999, 0.77985001, -0.79641998, 0.70256001,
1.21589994, -0.94200999, -0.91722 , -1.08010006, 0.11273 ,
0.50393999, 0.069062 , 0.63677001, -0.20201001, 0.59924001,
0.46956 , -0.70005 , 0.44506001, 0.10907 , -0.40182999,
-0.62650001, 0.29396999, -0.0071172 , 0.54157001, 0.60816002,
-0.75454003, -0.36409 , -0.92627001, 0.50558001, 0.048055 ,
2.64470005, 0.35488999, 0.56730998, -0.43171 , 1.07009995,
0.056213 , -0.10855 , 0.47887 , -0.16187 , -0.24250001,
-0.33612001, 0.17157 , 0.79386997, 0.69805002, 0.36484 ,
-0.014387 , -0.29538 , -1.12030005, -0.27845001, 0.35091001]])
Это простая матрица NumPy, в которой запись по индексу i ничто иное как вектор из предобученной модели, соответствующий слову по индексу i в словаре нашего векторизатора.
Размерность нашей матрицы векторов — 19×50, поскольку в нашем словаре было 19 уникальных слов, а у загруженной предобученной модели — 50-мерные векторы.
С размерностью можно поэкспериментировать, просто изменив файл или обучив свою собственную модель с нуля.
Эту матрицу векторов можно использовать как угодно — подавать на слой, обрабатывающий векторные представления в нейросети или использовать для задач поиска схожих слов.
Итак, с GloVe закончили, идем к следующей технике.
5. FastText
FastText был представлен Facebook-ом еще 2016 году. Идея FastText очень похожа на Word2Vec, но появился нюанс, которого не хватало в Word2Vec и GloVe.
Внимательный читатель, возможно, обратил внимание, что у Word2Vec и GloVe есть общая черта — сначала нужно загружать предварительно обученную модель, потом с ее помощью извлекать эмбеддинги. И хотя эти модели были обучены на миллиардах слов, их рабочий словарь все равно ограничен.
Как FastText решает этот вопрос?
FastText в этом вопросе работает лучше других методов благодаря тому, что умеет делать обобщения для неизвестных слов — другие методы этого не умеют.
Как это работает?
Вместо того, чтобы создавать эмбеддинги из слов, FastText спускается на уровень ниже — на уровень символов. Здесь кирпичиками становятся буквы, а не слова. Это значит, что эмбеддинги слов получаются не напрямую, а через комбинацию векторов более низкого уровня.
Преимущество здесь в том, что для обучения требуется меньше данных, поскольку слово само по себе становится контекстом, а значит, из текста можно извлечь еще больше информации. Посмотрим, как FastText с этим работает.
Допустим, у нас есть слово reading, и для этого слова нужно сгенерировать n-граммы из 3-5 токенов следующим образом:

Угловые скобки обозначают начало и конец слова.
Поскольку n-грамм может быть великое множество, используется хэширование, и вместо обучения по эмбеддингу каждой уникальной n-граммы, мы обучаем по всей совокупности B-эмбеддингов, где
Bозначает bucket size (дословно - размер ведра). В исходной статье речь шла о bucket size равном 2 миллионам.Через хэширование каждая буквенная n-грамма (например,
eadi) сопоставляется с целым числом от1доB, и по этому индексу выставляется соответствующий эмбеддинг.В итоге, получается полный эмбеддинг слова через усреднение составляющих его n-граммовых эмбеддингов.
Безусловно, при таком подходе с использованием хеширования коллизии неизбежны, но он все же позволяет намного лучше контролировать размеры словаря.
Модель, используемая в FastText, похожа на ту, что мы видели в Word2Vec, и так же как и в Word2Vec, мы можем обучать FastText в двух режимах - CBOW и skip-gram, повторяться не будем. Если нужны подробности по FastText, отправляем вам к оригинальным статьям здесь - статья №1 и статья №2.
Мы же тем временем двигаемся дальше и посмотрим, что можно делать с FastText.
Сначала установим его.
pip install fasttext
Предобученную модель fasttext можно либо скачать отсюда, либо обучить свою собственную модель на базе fasttext и использовать ее в качестве классификатора текста.
Поскольку мы уже видели достаточно предобученных моделей, и здесь логика была бы такая же, мы лучше сосредоточимся на том, как создать свой собственный классификатор fasttext.
Допустим, у нас есть такой набор данных, с фразами на тему приема лекарственных препаратов. Нам нужно классифицировать эти тексты на 3 типа — по упоминаемым видам препаратов.

Для обучения модели классификатора fasttext на любом наборе данных нам нужно подготовить входные данные в таком формате:
__label__<label value><space><associated datapoint>
Сделаем это и для нашего набора данных.
all_texts = train['text'].tolist()
all_labels = train['drug type'].tolist()
prep_datapoints=[]
for i in range(len(all_texts)):
sample = '__label__'+ str(all_labels[i]) + ' '+ all_texts[i]
prep_datapoints.append(sample)
Я не стал тут расписывать всю предобработку - для наших задач это некритично, но на реальных задачах лучше, конечно, поработать на этом этапе тщательно.
Запишем эти подготовленные данные в файл .txt.
with open('train_fasttext.txt','w') as f:
for datapoint in prep_datapoints:
f.write(datapoint)
f.write('n')
f.close()
Теперь у нас есть все необходимое для обучения модели fasttext.
model = fasttext.train_supervised('train_fasttext.txt')
Таким образом мы получили модель классификации, обученную по принципу обучения с учителем.
Соответственно, мы можем делать с ее помощью прогнозы.
model.predict(all_texts[0])
(('__label__2',), array([0.73352104]))
В частности, модель выдает нам как прогноз метки, так и показатель ее вероятности.
Стоит учитывать, что производительность этой модели (как и других моделей) зависит от множества факторов, но если вам требуется по-быстрому прикинуть, на какую базовую точность прогноза можно рассчитывать, fasttext в этом смысле весьма хорош.
Итак, с fasttext мы тоже закончили.
Выводы
Мы рассмотрели основные варианты получения эмбеддингов слов, начиная от наивных методов на базе простых подсчетов, и заканчивая эмбеддингами, учитывающими контекст даже на уровне части слов. Поскольку востребованность NLP растет, весьма важно иметь представление об используемых ею кирпичиках.
Учитывая то, сколько всяких материалов имеется по этим методам, я надеюсь, вас уже не поставит в тупик вопрос о том, какую технику эмбеддинга лучше использовать конкретно для вашей задачи.
Что дальше?
Надеюсь, не надо говорить, что список рассмотренных здесь методов далеко не полный, и есть еще множество других методов, достойных внимания. Тут только основы основ.
Следующим шагом по логике было бы более глубокое изучение документации по эмбеддингам на уровне документа (предложения), поскольку здесь мы этот вопрос немного затронули. Я бы рекомендовал обратить внимание на такие вещи, как BERT от Google, Universal Sentence Encoder и т. п.
Если надумаете попробовать BERT, обратите внимание на этот проект. Он отлично задействует возможности BERT, не перегружая при этом ваш компьютер. Почитайте README и «вперёд!».
Вроде все. Спасибо за внимание.