
Мультимодальное обучение — это процесс изучения представлений разных типов данных для разных модальностей, т. е. каналов восприятия информации, внутри одной модели. У разных модальностей — разные статистические характеристики. В контексте машинного обучения входными данными разных модальностей могут быть изображения, текст, аудио и т. д. В этой статье мы разберем только изображения и текст в качестве входных данных и рассмотрим построение визуально-языковых моделей (VL-моделей).

I. Задачи визуально-языковых моделей
Популярность визуально-языковых моделей резко увеличилась за последние годы благодаря росту возможностей их применения. Задачи можно условно разделить на 3 группы. Опишем их подробнее.
1. Задачи генерирования
Визуальный ответ на вопрос (VQA, Visual Question Answering) — это процесс, где ответ на вопрос генерируется с учетом визуальных входных данных (изображений или видео).
Подпись к визуальным данным (VC, Visual Captioning) — это процесс, где генерируется описание к визуальным входным данным.
Понимание визуальных данных (VCR, Visual Commonsense Reasoning) — процесс, где визуальные данные интерпретируются с точки зрения общего понимания и когнитивного восприятия.
Генерирование изображений (VG, Visual Generation) — процесс, при котором визуальные данные создаются на основе текстового запроса, как показано на изображении.

Источник: блог OpenAI
2. Задачи классификации
Мультимодальные эмоциональные вычисления (MAC, Multimodal Affective Computing) — интерпретация визуальных эмоциональных проявлений на основе визуальных и текстовых данных или, в некотором смысле, мультимодальный анализ настроения.
Естественный язык в оценке визуальных данных (NLVR, Natural Language for Visual Reasoning) — оценка истинности того или иного утверждения о визуальных входных данных.
3. Задачи поиска
Поиск визуальных данных (VR, Visual Retrieval) — сбор изображений исключительно на основании текстового описания.
Визуально-языковая навигация (VLN, Vision-Language Navigation) — движение в пространстве, которым программа управляет на основе текстовых инструкций.
Мультимодальный машинный перевод (MMT, Multimodal Machine Translation) — перевод описания с одного языка на другой с учетом дополнительной визуальной информации.

Таксономия наиболее частых задач моделей языка
За последние несколько лет предлагались разные модели, различающиеся в зависимости от поставленной задачи. В статье мы рассмотрим самые распространенные.
II. Модели типа BERT
С распространением трансформеров в NLP, попытки применить их в задачах VL были неизбежны. В большинстве работ использовалась одна из версий BERT, в результате чего резко возросло количество аналогичных моделей: VisualBERT, ViLBERT, Pixel-BERT, ImageBERT, VL-BERT, VD-BERT, LXMERT, UNITER.
В их основе лежит один и тот же принцип: одновременная обработка и текста, и изображений через модели трансформеров. Такие модели обычно делятся на двухпотоковые и однопотоковые.
1. Двухпотоковые модели: ViLBERT
«Двухпотоковая модель» обозначает VL-модели, где текст и изображения обрабатываются в двух отдельных модулях. В эту категорию входят ViLBERT и LXMERT.
При обучении ViLBERT используются пары «изображение + текст». Текст кодируется через токены и позиционные эмбеддинги — стандартные для трансформеров процессы. Затем он обрабатывается в модуле внутреннего внимания (self-attention) трансформера. Изображение декомпозируется до отдельных, неперекрывающих друг друга фрагментов, которые затем представляются в виде векторов, подобно эмбеддингам фрагментов из визуальных трансформеров.
Для обучения с использованием пар «изображение + текст» используется модуль co-attention — он определяет значения важности по обоим эмбеддингам — изображений, и текста.
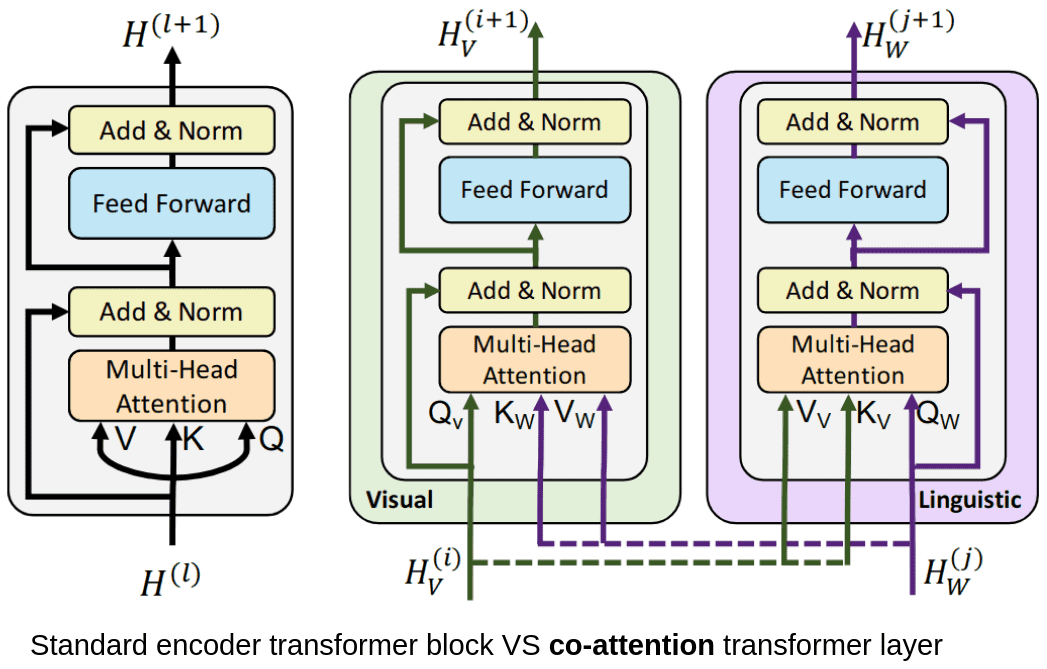
Стандартный self-attention VS co-attention, вычисленный через VilBERT
Можно сказать, эта модель изучает соответствия между словами и областями изображения. Для большей точности добавляется еще один модуль трансформера. Кроме того, блок «трансформер/co-attention» может повторяться многократно.

VilBERT обрабатывает изображения и текст по двум параллельным потокам, которые взаимодействуют через co-attention
Оба потока модели инициализируются раздельно. Для текстового потока (фиолетовый) веса устанавливаются на этапе предобучения модели на стандартном корпусе текстов, а для потока изображений (зеленый) используется Faster R-CNN. Набор данных, на котором обучается модель, — это пары «изображение + текст», а конечная цель модели — уметь соотностить текст и изображения. Затем предобученную модель можно донастроить под конкретные задачи VL.
2. Однопотоковые модели
Модели типа VisualBERT, VL-BERT, UNITER работают иначе — они с обеими модальностями работают внутри одного модуля. Например, в VisualBERT используется трансформер, который объединяет области изображения с текстом и обнаруживает соответствия между ними. То есть к стандартной модели BERT добавляются эмбеддинги визуальных данных. В состав эмбеддинга входят:
представление визуальных характеристик области изображения, генерируется через CNN;
эмбеддинг фрагмента, который позволяет отличать эмбеддинг изображения от эмбеддинга текста;
позиционный эмбеддинг, который устанавливает соответствие между областью изображения и словами, если они есть во входных данных.

VisualBERT объединяет области изображения и текст через трансформер
III. Предобучение и тонкая настройка
Своей высокой производительностью эти модели отчасти обязаны предобучению на огромных наборах данных. Визуальные модели на базе BERT обычно предобучаются на основе наборов данных из пар «изображение + текст» общей выборки данных. Затем, используя более специализированные наборы входных данных, модели донастраивают под конкретные задачи, типа визуальных ответов на вопрос (VQA) и др.
Разберем самые частые стратегии предобучения.
1. Стратегии предобучения
Маскированное языковое моделирование (Masked Language Modeling) часто применяется, когда трансформер обучается только на тексте. Токены входного текста маскируются рандомно. Модель учится предугадывать значения замаскированных токенов (слов). В случае с BERT, модель может использовать соседние токены в качестве контекста благодаря двунаправленному обучению.
Прогнозирование следующего предложения (Next Sequence Prediction) тоже применимо только для текста в качестве входных данных; здесь оценивается, подходит ли то или иное предложение в качестве продолжения входного. Обучаясь на верных и ложных предложениях, модель может выявлять долгосрочные зависимости.
Маскированное моделирование области (Masked Region Modeling): аналогично маскированному языковому моделированию, здесь маскируются области изображения. Модель учится предугадывать характеристики замаскированной области.
Сопоставление изображения и текста (Image-Text Matching): модель учится прогнозировать, подойдет ли предложение для конкретного изображения.
Соотношение слова и области (Word-Region Alignment): модель ищет соответствия между словами и областями изображения.
Маскированная классификация областей (Masked Region Classification): модель предугадывает класс объекта на каждой замаскированной области изображения.
Регрессия признаков замаскированной области (Masked Region Feature Regression): модель связывает замаскированную область изображения с ее визуальными признаками.
Например, VisualBERT предобучается на парах «изображение + подпись» через маскированное языковое моделирование и сопоставление изображений и текстов.
Упомянутые методы используются в задачах для обучения с учителем. Метки или выводятся из входных данных (с самоконтролем), или используется набор уже размеченных данных (обычно это пары «изображение + текст»).
Однако есть и другие варианты. Перечисленные ниже методы используются в VL-моделировании как по отдельности, так и совместно.
Предобучение VL-модели без учителя обычно предполагает, что модель предобучается на входных данных одной модальности, то есть без подготовленных пар «изображение + текст». Но затем, уже при тонкой настройке, она полноценно «доучивается с учителем».
Многозадачное обучение — модель обучается на нескольких задачах одновременно, чтобы изученное в рамках одной задачи применялось в другой.
Контрастное обучение применяется, чтобы модель в полуавтоматическом режиме изучала эмбеддинги визуально-семантических данных. Основная идея — изучить пространство эмбеддингов, где схожие пары располагаются близко друг к другу, а непохожие — далеко.
Zero-shot learning (обучение с нуля) — в момент вывода данных модель обобщает информацию и применяет ее к еще незнакомым классам.
Перейдем к самым распространенным моделям.
2. Генеративные модели VL
DALL-E
DALL-E используется для визуальной генерации (VG) и создает точные изображения на основе текстового описания. Обучение также производится на основе пар «изображение + текст».
DALL-E использует скрытый вариационный автоэнкодер (dVAE), чтобы преобразовывать изображения в токены. В отличие от стандартного VAE, dVAE в основном использует скрытое пространство. Текст токенизируется через кодирование пар байтов. Токены изображения и текста объединяются и обрабатываются как единый поток данных.

Конвейер обучения DALL-E mini, немного отличный от DALL-e
DALL-E использует авторегрессионный трансформер для обработки потока данных, чтобы смоделировать общее распределение текста и изображений. В декодере трансформера любое изображение может соотноситься со всеми токенами текста. В момент вывода данных токенизированная подпись объединяется с данными из dVAE, а поток данных перенаправляется в авторегрессионный декодер, который и генерирует новое токенизированное изображение.
DALL-E показывает выдающиеся результаты, как видно на картинке ниже (хотя изображения иногда получаются несколько мультяшными).

DALL-E создает реалистичные изображения по текстовому описанию.
Источник: DALL·E: Creating Images from Text
GLIDE
Как и DALL-E, GLIDE — это еще одна генеративная модель, но по производительности она превосходит предыдущие. GLIDE — это, по свой структуре, диффузионная модель.

Диффузионные модели состоят из нескольких этапов диффузии, где к данным постепенно добавляется случайный шум. Модели учатся обращать диффузию обратно и конструировать изображения, избавляя данные от шума. Источник: lilianweng
В общих чертах, диффузионные модели последовательно добавляют к данным случайный шум (по формуле цепи Маркова). Затем они учатся перенаправлять процесс в обратную сторону, чтобы на основе шума создавать новые данные. Таким образом, вместо выборки из исходно неизвестных данных, они могут делать выборку из известных данных, полученных после нескольких этапов диффузии. Можно доказать, что при добавлении гауссовского шума конечное (предельное) распределение данных будет нормальным.
Диффузионная модель получает на вход изображения и генерирует новые. При этом ей можно ставить условия в форме текстовой информации, чтобы генерируемые изображения соотносились с конкретным входным текстом. Именно так и работает GLIDE, применяя различные методы, чтобы «направлять» модели диффузии.
С математической точки зрения, можно построить следующую формулу процесса диффузии. Если взять некое значение  из распределения данных
из распределения данных  , можно построить цепь Маркова со скрытыми переменными
, можно построить цепь Маркова со скрытыми переменными  , постепенно добавляя гауссовский шум амплитудой
, постепенно добавляя гауссовский шум амплитудой  :
:

Таким образом, можно определить последующее  и приблизительно вычислить его по модели
и приблизительно вычислить его по модели  .
.

Результаты GLIDE впечатляют своей реалистичностью даже больше, чем DALL-E. Однако сами авторы отмечают, что были и неудачи в случаях с необычными объектами или сюжетами. На hugging face spaces каждый может попробовать получить изображение таким образом.

Примеры изображений, сгенерированных GLIDE
3. VL-модели с контрастным обучением
CLIP
CLIP решает задачу использования естественного языка в оценке визуальных данных (NLVR, Natural Language for Visual Reasoning), и пытается соотносить изображение с конкретной меткой на основе контекста. Обычно метка — это фраза или предложение, описывающие изображение. Интересно, что классификатор умеет работать «с нуля»: его можно использовать для меток, не встречавшихся модели ранее.
Впечатляющие результаты работы «с нуля» во многом обусловлены тем, что CLIP обучается на огромном высокодиверсифицированном наборе данных (400 млн). Эти данные состоят из изображений и их текстовых описаний. Изображения кодируются сетью ResNet или трансформером; для кодирования текста также используется трансформер.
Цель обучения — найти соответствия между представлениями изображений и текста. В общих чертах, модель пытается определить, какой вектор текста больше «подходит» конкретному вектору изображения. Поэтому такое обучение называется контрастным.
В отличие от классического контрастного обучения, где используются только визуальные данные, в данном случае объединяются не разные представления одного и того же изображения, а правильные (positive) представления изображения и соответствующего ему текста, и в то же время исключаются тексты, не соответствующие изображению (negative). Следовательно, это — контрастное обучение с учителем, и для него нужны маркированные пары.
Обучив модель присваивать высокую степень сходства совпадающим парам «изображение + текст» и низкую — несовпадающим, можно применять ее в конкретных задачах, таких как распознавание изображений.

В CLIP текстовый энкодер и энкодер изображений обучаются совместно в контрастном режиме
Ниже приведен псевдокод, взятый из оригинальной работы:
# image_encoder - ResNet, или визуальный трансформер
# text_encoder - CBOW, или текстовый трансформер
# I[n, h, w, c] - мини-пакет связанных изображений
# T[n, l] - мини-пакет связанных текстов
# W_i[d_i, d_e] - изученная проекция эмбеддингов изображения
# W_t[d_t, d_e] - изученная проекция эмбеддингов текста
# t - изученное значение температуры
# полученные представления признаков данных каждой модальности
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# общий эмбеддинг мультимодальных входных данных [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# попарно масштабированные косинусные сходства [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# функция симметричных потерь
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
Результаты впечатляют и здесь, хотя есть ограничения. Так, CLIP плохо справляется с абстрактными понятиями и слабо генерализирует изображения, не охваченные данными для предобучения.

Пример прогнозирования подписи для изображения с помощью CLIP. Источник: CLIP: Connecting Text and Images
ALIGN
ALIGN схожим образом использует двойной энкодер, который учится соотносить визуальные и языковые представления пар «изображение + текст». Энкодер обучается на контрастных потерях, которые оформляются как нормализованный softmax. Если точнее, то авторы используют понятие «потери» в двух значениях:
для оценки классификации изображения относительно текста,
для классификации текста относительно изображения.
Если x и y
и y — это нормализованные эмбеддинги изображения в -той паре и текста в -той паре соответственно,
— это нормализованные эмбеддинги изображения в -той паре и текста в -той паре соответственно,  — размер пакета данных, а
— размер пакета данных, а  — температура масштабирования логитов, то функции потерь можно определить так:
— температура масштабирования логитов, то функции потерь можно определить так:


Преимущество такого метода состоит в том, что модель обучается на зашумленном наборе данных из миллиарда пар «изображение + текст». В отличие от похожих методов, где проводится затратная предварительная обработка данных, этот доказывает, что объем набора данных может компенсировать шумы.

В ALIGN визуальное и языковое представление изучается совместно с помощью контрастного обучения
FLORENCE
Во Florence сочетаются многие из вышеупомянутых методов и предлагается новая модель сквозного обучения для решения задач VL. Авторы рассматривают Florence как одну из базовых моделей (foundation model согласно терминологии, предложенной в Стэнфордском университете командой Боммасани и др.). Florence — новейшая из моделей в данной статье. Во многих задачах она показывает отличные результаты. Ее основные плюсы:
Для предобучения используется иерархический визуальный трансформер (Swin) как энкодер изображений и модифицированный CLIP как декодер текста.
Обучение проводится на триплетах «изображение + метка + описание».
Используется единая схема обучения на базе пар «изображение + текст»; ее можно рассматривать как двунаправленное контрастное обучение. В общих чертах, под «потерями» понимаются две противоположных контрастных функции потерь: «изображение --> текст» и «текст --> изображение». Таким образом, объединяются две классические задачи обучения: сопоставление изображений с метками и присвоение описания уникальной метке.
Предобученные представления улучшаются до более тонких с помощью моделей-«адаптеров». Настройка представлений зависит от задачи: представления на уровне объектов, визуально-языковые представления, представления в видеоформате.
Таким образом, модель можно применять для различных задач. Она показывает высокую производительность в формате zero-shot и few-shot.

Иллюстрация модели Florence
4. Улучшенные векторные представления визуальных данных
Если тексты в основном кодируются модулями типа трансформеров, то кодирование визуальных данных остается полем для исследований. За несколько лет испытывались различные подходы. Изображения обрабатывались с помощью стандартного CNN, ResNet или трансформеров. В DALL-E для сжатия визуальной информации в скрытом пространстве даже использовался dVAE. Это можно сравнить с преобразованием слов в скрытый набор эмбеддингов, из которых составлялся словарь, только для фрагментов изображений. Сейчас, однако, в приоритете разработка улучшенных модулей кодирования изображений.
VinVL
С этой целью создатели VinVL, используя четыре публичных набора данных, предобучили новую модель обнаруживать объекты. Затем они добавили ветвь attribute/атрибут (=небольшое текстовое описание к изображению) и доработали ее, после чего модель научилась обнаруживать и объекты, и атрибуты.
Созданная объектно-атрибутная модель — по сути модификация модели Faster-RCNN. Ее можно использовать для получения точных представлений изображений.
SimVLM
В SimVLM, напротив, используется версия визуального трансформера (Vit). Здесь хорошо известный алгоритм проекции фрагментов изображений заменили тремя блоками ResNet, чтобы получить векторы этих фрагментов (см. этап “Conv Stage” на рисунке ниже). Эти блоки обучаются вместе со всей моделью, в отличие от других методов, где используется полностью предобученный модуль изображения.

Иллюстрация SimVLM. Аналогично языковому моделированию, модель предобучается с единой задачей и на крупных наборах слабо маркированных данных
IV. Заключение и наблюдения
Учитывая, что все приведенные модели практически новые, исследователям, вероятно, предстоит пройти еще долгий путь до создания надежных визуально-языковых моделей. Мы видели, что возникает масса команд, которые разрабатывают похожие модели, идущие по схеме предобучения или тонкой настройки крупномасштабных трансформеров. Однако мы решили не рассматривать в этой статье другие модели именно из-за множества сходств между ними.
Стоит отметить, что большинство моделей создано крупными технологическими компаниями; это явно говорит о том, что необходимы огромные массивы данных и инфраструктура.
Также очевидно, что основной метод сейчас — контрастное обучение, а ведущую роль здесь играют CLIP и ALIGN. Проблема кодирования текста выглядит более или менее решенной, но нужно еще многое доработать, чтобы представления визуальных данных получались более качественными. Кроме того, хотя генеративные модели, такие как DALL-E и GLIDE, показывают многообещающие результаты, у них все еще много ограничений. Будем следить за исследованиями.
Спасибо за внимание.
Пользуясь случаем, хочу выразить благодарность Софье Сутыгиной за помощь в подготовке и оформлении перевода этой статьи.
Andriljo
Интересный обзор, но CLIP не является декодером текста, возможно что-то не понял в формулировке "CLIP как декодер".