
В предыдущей статье про микросервисную архитектуру на основе событий с использованием Kafka Streams достаточно поверхностно был упомянут io.confluent.connect.jdbc.JdbcSourceConnector, который использовался для вычитания данных из SQLite и отправки их в топик Kafka. Сейчас я бы хотел более подробно разобрать технологию Kafka Connect на примере io.debezium.connector.postgresql.PostgresConnector. Как и в прошлый раз, я реализовал небольшой демо проект, код которого доступен на GitHub. В проекте кода совсем немного, однако чтобы понять все настройки, примененные в коннекторе, придется достаточно подробно пройтись по теоретической части. Итак, приступим.
Что такое Kafka Connect
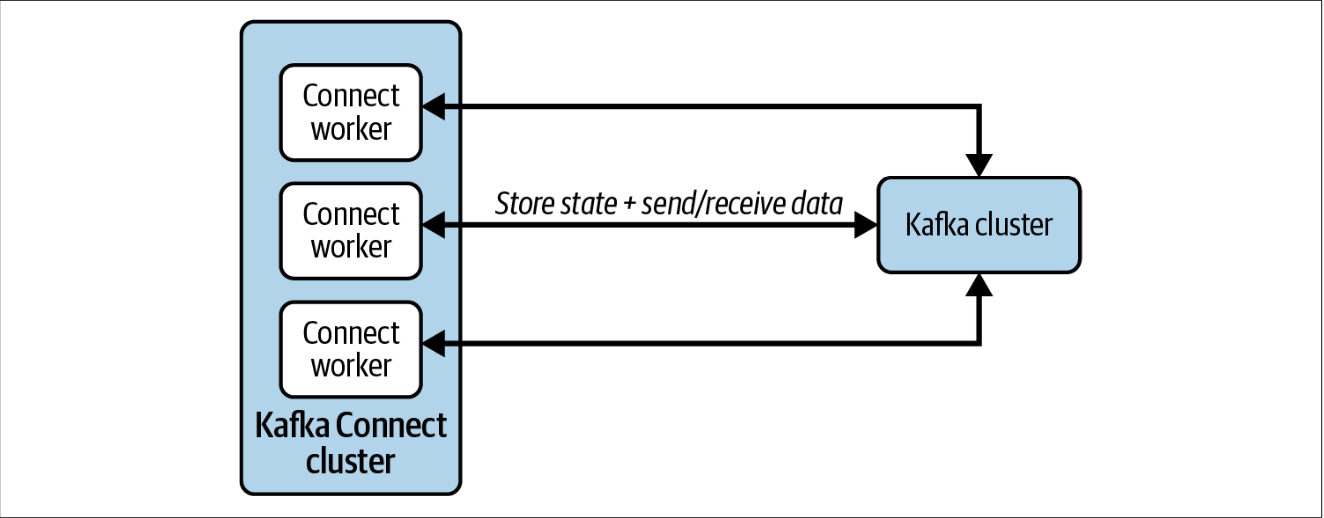
Если кратко, то Kafka Connect - система, позволяющая надежно вычитывать данные из внешних систем в Kafka и отправлять данные из топиков Kafka во внешние системы. Kafka Connect можно развернуть в двух режимах:
standalone - один процесс работает на одной машине
распределенный - создается кластер из нескольких Worker процессов с одинаковым
group.id, эти процессы координируют работу коннекторов и перераспределяют задачи в случае добавления или удаления Worker-ов.
Основные концепции Kafka Connect
Коннекторы (Connectors)
Задачи (Tasks)
Рабочие процессы (Workers)
Конвертеры (Converters)
Преобразователи (Transformers)
Connectors
Kafka Connect поддерживает 2 типа коннекторов: Source Connectors и Sink Connectors. По сути коннекторы определяют логику копирования данных в/из Kafka. Классы, реализующие данную логику определены в плагинах (connector plugins). Существует множество уже написанных плагинов, однако при желании можно написать свой.
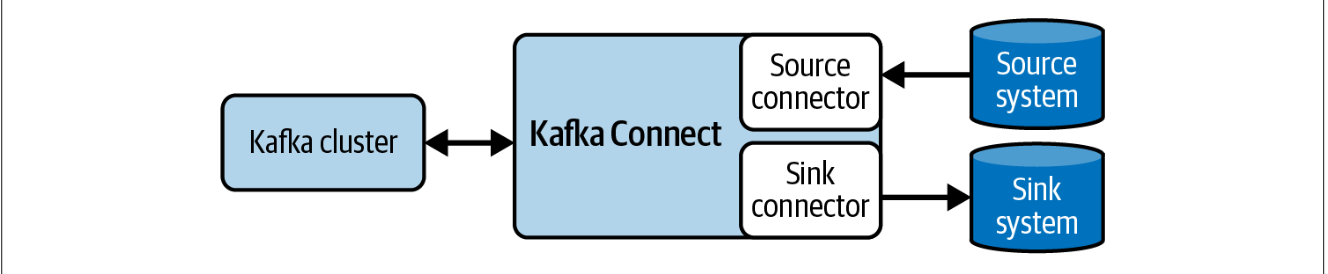
Tasks
Task - это основной актор в модели данных Kafka Connect. Каждый инстанс коннектора координирует набор Tasks, которые занимаются копированием данных. Сами Tasks не имеют состояния - оно хранится в служебных топиках Kafka config.storage.topic и status.storage.topic.

При первом подключении коннектора к кластеру Kafka Connect происходит ребалансировка задач - они равномерно распределяются между всеми процессами-воркерами. Также ребалансировка происходит при изменении конфигурации коннектора, когда указывается, что ему требуется большее количество Tasks для выполнения работы. Еще одной причиной для ребалансировки является падение процесса-воркера. Однако при падении самой Task, ребалансировка не происходит,так как это считается исключительным случаем, поэтому перезапуск Task должен осуществляться через REST API.

Workers
Коннекторы и задачи - логические элементы, которые исполняются в процессах-воркерах.
Converters
Конвертеры - обязательный элемент системы, который необходим для того, чтобы данные были корректно сериализованы / десериализованы при копировании в / из Kafka. По умолчанию доступны следующие конвертеры:
- org.apache.kafka.connect.json.JsonConverter
- org.apache.kafka.connect.storage.StringConverter
- org.apache.kafka.connect.converters.ByteArrayConverter
- org.apache.kafka.connect.converters.DoubleConverter
- org.apache.kafka.connect.converters.FloatConverter
- org.apache.kafka.connect.converters.IntegerConverter
- org.apache.kafka.connect.converters.LongConverter
- org.apache.kafka.connect.converters.ShortConverter
Также можно настроить и другие конвертеры:
io.confluent.connect.avro.AvroConverterio.confluent.connect.protobuf.ProtobufConverterio.confluent.connect.json.JsonSchemaConverter
Transformers
К каждому сообщению, обрабатываемому конвертером можно применить одну или несколько несложных трансформаций, так называемых Single Message Transformation (SMT). Это опциональный элемент в пайплайне Kafka Connect. Например, можно изменить тип данных, добавить поле к записи или удалить поле, изменить название топика, в который отправляется сообщение. Для Source Connector, трансформации применяются после конвертера, а для Sink Connector - до конвертера.


Debezium PostgresConnector
В проекте используется опенсорсный коннектор Debezium для вычитывания изменений в базе данных PostgreSQL.
Debezium PostgreSQL source Connector вычитывает журнал предварительной записи Write Ahead Log (WAL). Стоит отметить, что перед внесением любых изменений в таблицы БД Postgres записывает все транзакции и изменения данных в WAL. Основная цель использования WAL - гарантировать, что даже в случае сбоя системы все транзакции будут либо полностью выполнены, либо полностью отменены, это обеспечивает свойства атомарности (Atomicity) и долговечности (Durability) в ACID модели транзакций. В случае сбоя Postgres использует WAL для восстановления данных. В Postgres WAL реализован в виде последовательности файлов в каталоге данных сервера. Эти файлы хранятся в директории pg_wal. Записи в WAL добавляются в позицию, указываемую Log Sequence Number (LSN). LSN - монотонно возрастающий идентификатор, который используется для определения точки в WAL, где были записаны определенные данные. В контексте репликации данных и восстановления после сбоев LSN играет критическую роль. Репликационные системы и механизмы восстановления используют LSN для определения того, какие данные необходимо синхронизировать или восстановить, а также для гарантии того, что все изменения применяются в правильном порядке. Debezium использует LSN для контроля за уже обработанными данными.
После первого подключения к серверу или кластеру БД коннектор делает снимок состояния схем, а затем постоянно вычитывает изменения в БД. Коннектор генерирует записи с изменениями данных (data change records) и отправляет их в топики Kafka.
Коннектор содержит две основные части, которые обеспечивают вычитывание и обработку изменений в БД:
-
Плагин logical decoding output plug-in. Для его использования необходимо настроить репликационный слот. Можно установить следующие плагины:
decoderbufs основан на Protobuf и поддерживается коммьюнити Debezium
pgoutputстандартный плагин, который входит в состав PostgreSQL 10+.
Java код (сам коннектор) который вычитывает данные, сгенерированные плагином. Он использует протокол потоковой репликации данных PostgreSQL (Streaming Replication Protocol) через JDBC драйвер.
Пару слов про репликационный слот
Это механизм, который используется для управления потоковой репликацией данных. Он играет ключевую роль в поддержании целостности данных при репликации между основным сервером (primary) и репликой (replica) в PostgreSQL. Репликационные слоты гарантируют, что сервер PostgreSQL сохраняет все необходимые данные в WAL, пока подписанный на него клиент (например, репликационный сервер или инструмент мониторинга изменений, как Debezium) не подтвердит их обработку. Это предотвращает потерю данных, которые могли бы быть удалены из журнала транзакций до их репликации.
Начиная с PostgreSQL 12 логические репликационные слоты могут быть только на основных
серверах кластера, это означает, что Debezium коннектор может взаимодействовать только
с primary сервером. В случае падения основного сервера выбирается другой primary, и на этом сервере должен быть установлен плагин logical decoding output plug-in, а также репликационный слот, настроенный для работы с плагином, плюс база данных, изменения которой необходимо отслеживать. Только после этого можно стартовать коннектор, указав ему путь для связи с новым сервером.
Названия топиков
По умолчанию коннектор использует следующую конвенцию:
topicPrefix.schemaName.tableName
topicPrefix - определяется конфигурацией
topic.prefixschemaName - название схемы в БД
tableName - название таблицы
Data Change Events (События изменения данных)
События изменения данных генерируются коннектором для каждого INSERT, UPDATE иDELETE. Каждое событие содержит ключ и значение. Структура ключа и значения зависит от измененной таблицы.
Следующий шаблон содержит основные элементы change event:
{
"schema": { // 1 описывает схему ключа
...
},
"payload": { // 2 сам ключ
...
},
"schema": { // 3 описывает значение
...
},
"payload": { // 4 само значение
...
},
}Change Event Key
Описывает Primary Key таблицы на момент создания события. Например, есть таблица в public схеме БД:
CREATE TABLE customers (
id SERIAL,
first_name VARCHAR(255) NOT NULL,
last_name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
PRIMARY KEY(id)
);Если topic.prefix = PostgreSQL_server, то каждое событие изменения таблицы будет выглядеть так (в части касающейся ключа):
{
"schema": {
"type": "struct",
"name": "PostgreSQL_server.public.customers.Key",
"optional": false,
"fields": [
{
"name": "id",
"index": "0",
"schema": {
"type": "INT32",
"optional": "false"
}
}
]
},
"payload": {
"id": "1"
}
}NB. Несмотря не то, что конфигурации column.exclude.list и column.include.list
позволяют контролировать, что будет включено в запись, данные о Primary Key всегда включаются.
Change Event Value
Состав сообщения зависит от настройки REPLICA IDENTITY.
REPLICA IDENTITY - специфичная для PostgreSQL настройка уровня таблицы, которая
контролирует, какая информация о предыдущих значениях будет доступна logical decoding
plug-in для событий типа UPDATE и DELETE .
Существует 4 возможных REPLICA IDENTITY значения:
DEFAULT- доступна информация о первичных ключах. Для события типаUPDATE- только если первичный ключ изменился.NOTHING- события не содержат информацию о предыдущих значенияхFULL- события содержат информацию о всех предыдущих значенияхINDEXindex-name - события содержат информацию о предыдущих значениях только для столбцов с указанными индексами
Пример для Create Event:
{
"schema": { // 1 Схема значения
"type": "struct",
"fields": [
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
},
{
"type": "string",
"optional": false,
"field": "first_name"
},
{
"type": "string",
"optional": false,
"field": "last_name"
},
{
"type": "string",
"optional": false,
"field": "email"
}
],
"optional": true,
"name": "PostgreSQL_server.inventory.customers.Value", // 2 Название схемы для полей before и after
"field": "before"
},
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
},
{
"type": "string",
"optional": false,
"field": "first_name"
},
{
"type": "string",
"optional": false,
"field": "last_name"
},
{
"type": "string",
"optional": false,
"field": "email"
}
],
"optional": true,
"name": "PostgreSQL_server.inventory.customers.Value",
"field": "after"
},
{
"type": "struct",
"fields": [
{
"type": "string",
"optional": false,
"field": "version"
},
{
"type": "string",
"optional": false,
"field": "connector"
},
{
"type": "string",
"optional": false,
"field": "name"
},
{
"type": "int64",
"optional": false,
"field": "ts_ms"
},
{
"type": "boolean",
"optional": true,
"default": false,
"field": "snapshot"
},
{
"type": "string",
"optional": false,
"field": "db"
},
{
"type": "string",
"optional": false,
"field": "schema"
},
{
"type": "string",
"optional": false,
"field": "table"
},
{
"type": "int64",
"optional": true,
"field": "txId"
},
{
"type": "int64",
"optional": true,
"field": "lsn"
},
{
"type": "int64",
"optional": true,
"field": "xmin"
}
],
"optional": false,
"name": "io.debezium.connector.postgresql.Source", // 3 Схема поля source . Специфична для PostgreSQL коннектора.
"field": "source"
},
{
"type": "string",
"optional": false,
"field": "op"
},
{
"type": "int64",
"optional": true,
"field": "ts_ms"
}
],
"optional": false,
"name": "PostgreSQL_server.inventory.customers.Envelope" // 4 Схема всей структуры payload-a.
},
"payload": { // 5 Сами данные value - информация предоставляемая change event.
"before": null, // 6 Опциональное поле, характеризующее состояние данных в БД до того, как событие произошло.
"after": { // 7 Опциональное поле, характеризующее состояние данных в БД после того, как событие произошло
"id": 1,
"first_name": "Anne",
"last_name": "Kretchmar",
"email": "annek@noanswer.org"
},
"source": { // 8 Обязательное поле, которое характеризует источник метаданных о событии.
"version": "2.4.1.Final", // версия Debezium
"connector": "postgresql", // название коннектора
"name": "PostgreSQL_server", // имя сервера Postgres
"ts_ms": 1559033904863, // Время события в БД
"snapshot": true, // Является ли событие частью снепшота
"db": "postgres", // название базы
"sequence": "[\"24023119\",\"24023128\"]", // приведенный к строке массив JSON с доп информацией об оффсетах. Первое значение - последний закомиченный оффсет LSN. Второе - текущий оффсет LSN.
"schema": "public", // название схемы
"table": "customers", // таблица, содержащая новую запись
"txId": 555, // ID транзакции, в которой произошла операция
"lsn": 24023128, // оффсет операции в базе данных (LSN)
"xmin": null
},
"op": "c", // 9 Обязательное поле, характеризующее тип операции: с = create, u = update, d = delete, r = read (applies only to snapshots), t = truncate, m = message
"ts_ms": 1559033904863 // 10 Опциональное поле, характеризующее время обработки события коннектором Debezium
}
}Пример Update Event (остальные поля аналогичны Create Event) для REPLICA IDENTITY DEFAULT:
{
"schema": { ... },
"payload": {
"before": {
"id": 1
},
"after": {
"id": 1,
"first_name": "Anne Marie",
"last_name": "Kretchmar",
"email": "annek@noanswer.org"
},
"source": {
"version": "2.4.1.Final",
"connector": "postgresql",
"name": "PostgreSQL_server",
"ts_ms": 1559033904863,
"snapshot": false,
"db": "postgres",
"schema": "public",
"table": "customers",
"txId": 556,
"lsn": 24023128,
"xmin": null
},
"op": "u",
"ts_ms": 1465584025523
}
}Что происходит в случае ошибок
Если система работает без сбоев, то Debezium Connector дает гарантию exactly once доставки всех изменений таблицы (insert, update, delete). В случае сбоев система не теряет события, однако во время восстановления после сбоя некоторые события могут быть доставлены более одного раза.
Ошибки конфигурации и запуска приложения
В следующих ситуациях коннектор выдаст ошибку при старте. Эта ошибка будет залогирована:
Некорректная конфигурация коннектора
Коннектор не может подключиться к PostgreSQL
Коннектор перезапускается с последнего прочитанного места в PostgreSQL WAL
(используя Log Sequence Number), однако в Postgres эта история записей более недоступна
В этих случаях сообщение об ошибке будет содержать детали проблемы и возможное решение. После исправления конфигурации или ошибки на стороне Postgres можно перезапускать коннектор.
Потеря связи с Postgres
Во время работы коннектора связь с сервером БД может быть потеряна по ряду причин. В этом случае коннектор останавливается с ошибкой. После того, как сервер вновь становится доступным, необходимо перезапустить коннектор.
Коннектор хранит данные о последнем обработанном оффсете в PostgreSQL WAL в виде LSN.
После перезапуска коннектор продолжает считывать данные из WAL, начиная с этого оффсета. Оффсет будет доступен пока доступен репликационный слот. Ни в коем случае нельзя дропать репликационный слот на основном (primary) сервере, иначе данные будут утеряны.
Важные аспекты, на которые необходимо обращать внимание при восстановлении сервера после падения и до выполнения которых необходимо приостанавливать работу коннектора Debezium:
Должен существовать процесс, который воссоздает репликационный слот для Debezium ДО того, как клиенты БД начнут запись в новый основной сервер.
Возможно потребуется убедиться, что Debezium смог прочесть все изменения в слоте ДО падения старого основного сервера. Надежным способом проверки является восстановление бекапа упавшего сервера до точки падения и проверка репликационного слота на предмет необработанных изменений.
Процесс Kafka Connect остановлен плавно (Graceful shutdown)
В этом случае процессы (tasks) выполняющие работу коннектора переносятся на другой процесс Kafka Connect. Происходит небольшая задержка в обработке данных, однако данные обрабатываются с того же места, где была остановка.
Процесс Kafka Connect остановлен с ошибкой
В этом случае оффсеты не будут зафиксированы и после того, как Kafka Connect перераспределит задачи, коннектор продолжит обрабатывать данные с последнего зафиксированного оффсета - это значит, что возможны дубликаты событий. В каждой записи коннектор сохраняет информацию об источнике события, включая время события на сервере PostgreSQL, ID транзакции на сервере и позицию в WAL. Потребители событий могут отслеживать эту информацию, чтобы определить дубликаты.
Kafka брокер недоступен
Kafka Connect использует Kafka Producer API для записи данных в Kafka. В случае недоступности брокера, коннектор ретраит попытки достучаться до него. После восстановления связи с брокером коннектор продолжает работу с того места, где он остановился.
Коннектор остановлен на некоторое время
В этом случае можно продолжать использовать БД. После перезапуска коннектора он продолжит вычитывать изменения с того места, где он остановился.
Теперь перейдем к практике.
Сначала поднимем все необходимые контейнеры с инфраструктурой в Docker:
Zookeeper
Kafka
Schema Registry
Kafka Connect
Postgres
В комментариях привел особенности настроек контейнеров.
docker-compose up -dversion: '3'
volumes:
database:
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.5.2
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
kafka:
image: confluentinc/cp-kafka:7.5.2
hostname: kafka
container_name: kafka
depends_on:
- zookeeper
ports:
- "9092:9092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:29092,PLAINTEXT_HOST://localhost:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_CONFLUENT_SCHEMA_REGISTRY_URL: http://schema-registry:8081
schema-registry:
image: confluentinc/cp-schema-registry:7.5.2
hostname: schema-registry
container_name: schema-registry
depends_on:
- zookeeper
- kafka
ports:
- "8081:8081"
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: 'kafka:29092'
SCHEMA_REGISTRY_LISTENERS: http://0.0.0.0:8081
connect:
image: confluentinc/cp-server-connect:7.5.2
container_name: connect
ports:
- "8083:8083"
environment:
CONNECT_BOOTSTRAP_SERVERS: kafka:29092
CONNECT_GROUP_ID: "debezium-example"
CONNECT_REST_ADVERTISED_HOST_NAME: connect
# топик для хранения конфигураций
CONNECT_CONFIG_STORAGE_TOPIC: connect-demo-configs
# топик для хранения оффсетов
CONNECT_OFFSET_STORAGE_TOPIC: connect-demo-offsets
# топик для хранения статусов коннектора
CONNECT_STATUS_STORAGE_TOPIC: connect-demo-statuses
CONNECT_REPLICATION_FACTOR: 1
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1
# указываем конвертер для ключей
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.storage.StringConverter
# указываем конвертер для записей
CONNECT_VALUE_CONVERTER: io.confluent.connect.avro.AvroConverter
# так как используем Avro + Schema Registry, указываем URL для Schema Registry
CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: http://schema-registry:8081
# CLASSPATH required due to CC-2422
CLASSPATH: "/usr/share/java/monitoring-interceptors/monitoring-interceptors-7.5.2.jar"
CONNECT_PLUGIN_PATH: '/usr/share/java,/usr/share/confluent-hub-components/,/connectors/'
volumes:
- database:/opt/docker/db/data
- $PWD/stack-configs:/opt/docker/stack-configs
# Далее устанавливаем Debezium плагин из confluent hub
command:
- bash
- -c
- |
echo "Installing connector plugins"
confluent-hub install --no-prompt debezium/debezium-connector-postgresql:2.2.1
echo "Launching Kafka Connect worker"
/etc/confluent/docker/run
postgres:
image: postgres:15
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
POSTGRES_DB: productsdb
volumes:
- database:/var/lib/postgresql/data
- ./postgres/init.sql:/docker-entrypoint-initdb.d/init.sql
ports:
- "5432:5432"
# обязательно устанавливаем параметр wal_level=logical, чтобы Postgres обеспечивал логическую
# репликацию данных, требуемую Debezium.
# В проекте будем использовать один коннектор, поэтому устанавливаем max_wal_senders=1
# и max_replication_slots=1
command: >
-c wal_level=logical
-c max_wal_senders=1
-c max_replication_slots=1Стоит отметить, что Debezium использует только одну Task для вычитывания WAL из PostgreSQL. Это связано с тем, как работает логическая репликация в PostgreSQL и особенностями обработки WAL.
Для примера в базе данных PostgreSQL создана таблица products:
CREATE TABLE IF NOT EXISTS products(
PRODUCT_ID BIGINT GENERATED ALWAYS AS IDENTITY,
NAME TEXT NOT NULL,
DESCRIPTION TEXT NOT NULL,
PRICE NUMERIC(100, 5),
PRIMARY KEY (PRODUCT_ID)
);
ALTER TABLE products REPLICA IDENTITY FULL;
INSERT INTO products(NAME, DESCRIPTION, PRICE)
VALUES ('Product One', 'Description One', 10.9);
CREATE PUBLICATION products_publication FOR TABLE products;
SELECT pg_create_logical_replication_slot('postgres_debezium', 'pgoutput');Как видно, в проекте будем использовать REPLICA IDENTITY FULL для того, чтобы при событияхUPDATE и DELETE в сообщениях была полная информация о предыдущем состоянии записи в БД.
Также мы создаем PUBLICATION для таблицы products - один из механизмов PostgreSQL для обеспечения логической репликации данных.
После этого создаем репликационный слот с названием postgres_debezium, который будет обрабатываться стандартным плагином pgoutput.
N.B. Сразу сохраним запись в БД, чтобы коннектор при подключении немедленно создал топик в Kafka, куда будут отправляться данные из таблицы. В настройке коннектора, которую я приведу ниже указано, что топик создается с несколькими партициями, однако если изначально база пуста, то по какой-то причине создание топика откладывается до появления в таблице данных, при этом топик создается с 1 партицией.
Теперь подробно разберем конфигурацию Debezium коннектора:
connector.class- класс используемого коннектора из установленного плагина Debeziumplugin.name- тип используемого в PostgreSQL плагина для вычитывания данных из WALtable.include.list- список таблиц, изменения которых будут отслеживаться коннекторомtopic.prefix- префикс, который будет использоваться для наименования топика в Kafkavalue.converter- тип конвертера, в нашем случае это AvroConvertervalue.converter.schema.registry.url- так как мы используем Avro + Schema Registry, нам надо указать URL schema registry.value.converter.schemas.enable- стоит ли в вообщение включать данные о его схеме, так как мы используем Schema Registry, то отключаем эту настройкуheartbeat.interval.ms- интервал между хартбитами, посылаемыми коннектором в Kafka, чтобы поддерживать связь с кластером Kafka, даже если не будет изменений в отслеживаемых таблицахslot.name- имя слота репликации, который был создан в Postgrespublication.name- имя публикации, созданной в Postgrespublication.autocreate.mode- в документации Debezium рекомендуется при использовании плагинаpgoutputустанавливать этот параметр вfiltered(если публикации в Postgres нет, то Debezium сам ее создаст только для тех таблиц, которые он отслеживает), еще один вариант -all_tables- публикация создается для всех таблиц в базеdecimal.handling.mode- конфигурирует то, как числа с плавающей точкой будут обрабатываться конвертером данных. В нашем случае мы выбираемstring, также доступные варианты:precise,doublecreation.default.partitions- конфигурирует дефолтное количество партиций при создании топиковtopic.creation.default.replication.factor- конфигурирует дефолтное количество реплик для каждой партицииtransforms- "unwrap,PartitionRouting,SetValueSchema" указываем список трансформаций, которые будут применятся к записямtransforms.unwrap.type- для трансформации unwrap используем классio.debezium.transforms.ExtractNewRecordStateкоторый извлекает из сообщения только измененные данные. Это значительно сокращает объем передаваемой по сети информации и упрощает сериализацию/десериализацию.transforms.unwrap.add.fields- добавляем к данным дополнительные поля. В нашем случае - тип операцииop, название таблицыtable, текущий LSNlsn, время транзакцииsource.ts_mstransforms.unwrap.delete.handling.mode- Определяет, как обрабатывать события удаления.rewriteгарантирует, что информация об удаленных записях будет сохранена и передана в сообщении Kafkatransforms.unwrap.drop.tombstones- не будем отправлять tombstone события в Kafka.transforms.PartitionRouting.type- используемio.debezium.transforms.partitions.PartitionRoutingдля того, чтобы настроить кастомную логику отправки сообщений по партициямtransforms.PartitionRouting.partition.payload.fields- указываем, какие поля из таблицы будут участвовать для определения партиции для отправки данных в Kafka. В нашем случае мы выбираемproduct_idtransforms.PartitionRouting.partition.topic.num- указываем количество партиций для отправки данныхtransforms.SetValueSchema.type- используемorg.apache.kafka.connect.transforms.SetSchemaMetadata$Valueдля того, чтобы "помочь" Debezium с генерацией схемы Avro на основе значения сообщения, а не всего сообщения, включающего ключ и другие поляtransforms.SetValueSchema.schema.name- указываем полное название Avro класса, который будет сгенерирован Debeziummessage.key.columns- явно указываем, какие поля будут участвовать в ключе собщения, по умолчанию участвуют всеPRIMARY KEYв таблицеtransforms.PartitionRouting.predicate- указываем предикат, который будет применяться к каждой трансформации, если запись будет удовлетворять предикату, то тогда трансформация будет применена к записи. В данном случае этот предикат необязателен, так как мы вычитываем данные только из одной таблицы и отправляем только в один топик. Приведен тут для примера.predicates- указываем список используемых предикатовpredicates.allTopic.type- для предиката allTopic используемorg.apache.kafka.connect.transforms.predicates.TopicNameMatchesдля проверки на совпадение топика, в который отправляется сообщениеpredicates.allTopic.pattern- указываем паттерн для сравнения топиковkey.converter- указываем тип конвертера для ключа сообщения. В нашем случае используемorg.apache.kafka.connect.storage.StringConverter.key.converter.schemas.enable- false, не отправляем вместе с сообщением схему данных о ключеtombstones.on.delete- указывает, нужно ли отправлять события tombstone при удалении данных из таблицы. В нашем случае мы их не отправляем.null.handling.mode- определяет, как коннектор должен обрабатывать null значения в данных.keepуказывает коннектору сохранять поля со значением null в сообщениях Kafka. Это означает, что если исходная запись содержит поля с null, эти поля будут сохранены в сообщении Kafka.
Чтобы зарегистрировать конфигурацию коннектора в Kafka Connect необходимо отправить ее по REST:
curl -s -S -XPOST -H Accept:application/json -H Content-Type:application/json http://localhost:8083/connectors/ -d @debezium-config.jsonДалее требуется сгенерировать Avro класс. Чтобы понять, какую схему сгенерировал Debezium, ее можно запросить в Schema Registry:
curl http://localhost:8081/subjects/debezium.public.products-value/versions/latestВ ответ вернется строка, из которой можно удалить все ненужные данные и составить корректный .avsc файл:
{"subject":"debezium.public.products-value","version":1,"id":1,"schema":"{\"type\":\"record\",\"name\":\"Product\",\"namespace\":\"ru.aasmc.avro\",\"fields\":[{\"name\":\"product_id\",\"type\":\"long\"},{\"name\":\"name\",\"type\":\"string\"},{\"name\":\"description\",\"type\":\"string\"},{\"name\":\"price\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"__op\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"__table\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"__lsn\",\"type\":[\"null\",\"long\"],\"default\":null},{\"name\":\"__source_ts_ms\",\"type\":[\"null\",\"long\"],\"default\":null}],\"connect.name\":\"ru.aasmc.avro.Product\"}"}Сам файл .avsc, который я обработал, расположен в директории avro:
{
"type": "record",
"name": "AvroProduct",
"namespace": "ru.aasmc.avro",
"fields": [
{
"name": "product_id",
"type": "long"
},
{
"name": "name",
"type": "string"
},
{
"name": "description",
"type": "string"
},
{
"name": "price",
"type": [
"null",
"string"
],
"default": null
},
{
"name": "__op",
"type": [
"null",
"string"
],
"default": null
},
{
"name": "__table",
"type": [
"null",
"string"
],
"default": null
},
{
"name": "__lsn",
"type": [
"null",
"long"
],
"default": null
},
{
"name": "__source_ts_ms",
"type": [
"null",
"long"
],
"default": null
}
]
}Фактически, класс AvroProduct будет выглядеть следующим образом (без дополнительного кода, сгенерированного Avro):
class AvroRecord(
val product_id: Long,
val name: String,
val description: String,
val price: String?,
val __op: String?,
val __table: String?,
val __lsn: String?,
val __source_ts_ms: Long?
)После этого необходимо сгенерировать Avro файлы с помощью Gradle плагина: id 'com.github.davidmc24.gradle.plugin.avro' version "1.9.1"
./gradlew clean build -x testТеперь можно запустить приложени Spring Boot. Оно каждую секунду будет сохранять в БД новый Product, также периодически будет обновляться и удалятся уже сохраненный Product.
private val log = LoggerFactory.getLogger(ProductService::class.java)
@Component
class ProductService(
private val repository: ProductRepository
) : ApplicationRunner {
val random = Random(System.currentTimeMillis())
override fun run(args: ApplicationArguments?) {
while (true) {
val product = generateRandomProduct()
val saved = repository.save(product)
log.info("Successfully saved product: {}", saved)
TimeUnit.SECONDS.sleep(1)
if (saved.id!! % 10 == 0L) {
val prev = repository.findById(saved.id!! - 1).get()
prev.description = "Updated description. Prev description: ${prev.description}"
repository.save(prev)
} else if (saved.id!! % 5 == 0L) {
repository.deleteById(saved.id!! - 1)
}
}
}
private fun generateRandomProduct(): Product {
val randomPrice = random.nextDouble()
val price = BigDecimal.valueOf(randomPrice)
val randomNum = random.nextInt()
val name = "Product $randomNum"
val description = "Description $randomNum"
return Product(name = name, description = description, price = price)
}
}Помимо этого в приложении настроен Kafka Consumer, который вычитывает данные из топика и логирует их. В консьюмере настроена concurrency = 3, чтобы продемонстрировать, что данные вычитываются из разных партиций и наша конфигурация корректна.
private val log = LoggerFactory.getLogger(DebeziumKafkaListener::class.java)
@Service
class DebeziumKafkaListener {
@KafkaListener(topics = ["debezium.public.products"], concurrency = "3")
fun consumerDebeziumRecords(
record: AvroProduct,
@Header(KafkaHeaders.RECEIVED_KEY) key: String,
@Header(KafkaHeaders.RECEIVED_PARTITION) partition: Int
) {
log.info(
"Consuming record from kafka. Key {}. Record {}. Partition: {}. Thread: {}",
key,
record,
partition,
Thread.currentThread().name
)
log.info("Value from record: {}", record)
}
}Настройки консьюмера указаны в application.yml:
kafka:
bootstrap-servers: localhost:9092
consumer:
group-id: ${spring.application.name}
bootstrap-servers: localhost:9092
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: io.confluent.kafka.serializers.KafkaAvroDeserializer
properties:
specific.avro.reader: true
schema.registry.url: http://localhost:8081
auto-offset-reset: earliest
enable-auto-commit: trueСтоит обратить внимание на конфигурацию specific.avro.reader: true, она позволяетвычитывать не GenericRecord, а конкретный класс, сгенерированный Avro.
Стек Технологий
Java 17
Kotlin
Spring Boot 3
Kafka
Avro
Confluent Schema Registry
Kafka Connect
Zookeeper
Postgres
Debezium
oxff
Спасибо за статью!
> Начиная с PostgreSQL 12 логические репликационные слоты могут быть только на основных серверах кластера, это означает, что Debezium коннектор может взаимодействовать только с primary сервером.
Начиная с Postgres 16 логические слоты можно создавать и на репликах.
https://www.postgresql.org/docs/current/release-16.html#RELEASE-16-LOGICAL
aasmc Автор
Да, действительно так и есть. Я этот момент не учел. Спасибо за замечание! Однако Debezium 2.4.0.FINAL пока еще может работать только с primary серверами Postgres. PostgreSQL 16 introduces logical replication from standby servers; however, this feature has not yet been tested by Debezium and will be a feature introduced in a later build of Debezium. For now, logical replication remains only supported via the primary. https://debezium.io/blog/2023/10/03/debezium-2-4-final-released/ Debezium версии 2.5 (еще в development) это исправит https://issues.redhat.com/browse/DBZ-7181