
Привет всем! Мы в Surf очень любим мобильные приложения и считаем, что за ними будущее. Cегодня Сергей Лазарев, наш инженер по автоматизированному тестированию, расскажет о важной, востребованной бизнесом функциональности приложения, и о том, как мы можем обеспечить уверенность в её качестве с помощью автотестов.
Содержание
1. Что такое события аналитики в мобильном приложении и как с ними работать
2. Автоматизированное тестирование отдельного события
3. Структура сценариев и переиспользование кода
4. Алгоритм полного покрытия всех событий и элементов
5. Преимущества и недостатки описанного алгоритма
6. Сравнение затрат времени на ручное и автоматизированное тестирование аналитики
7. Сравнительный анализ ручного и автоматизированного тестирования аналитики
8. Выводы
Что такое события аналитики в мобильном приложении и как с ними работать
Мобильное приложение — мощный канал продаж и продвижения товаров и услуг. Чтобы повысить его эффективность, компаниям необходима информация о действиях пользователя внутри приложения. Удобно собирать и быстро обрабатывать эту информацию позволяют системы аналитики, в основе которых лежат «события». Они добавляются в код приложения, и когда пользователь выполняет операцию, на сервер аналитики отправляется информация о совершенном действии и его параметрах.
Собрав достаточное количество подобных данных, можно узнать, какой товар чаще заказывают, какие экраны посещают, на каком этапе «отваливаются» покупатели и так далее.
Например, при добавлении товара в корзину отправляется событие «в корзину был добавлен товар с id{product_id}», а при оформлении заказа — «был оформлен заказ №{order_number}, в составе которого есть товар {product_id}». Получив такие данные о всех заказах за определенный период, компания, например, может понять, какой товар чаще других кладут в корзину, но в итоге не заказывают. Примеров — бесконечно много.
Это действительно мощный инструмент, поэтому логично, что его популярность растет. В больших мобильных приложениях количество таких событий может исчисляться сотнями. Как и любая другая функциональность, отправка событий аналитики нуждается в тестировании, которое чаще всего осуществляется manual QA-инженерами. У нас это происходит следующим образом:
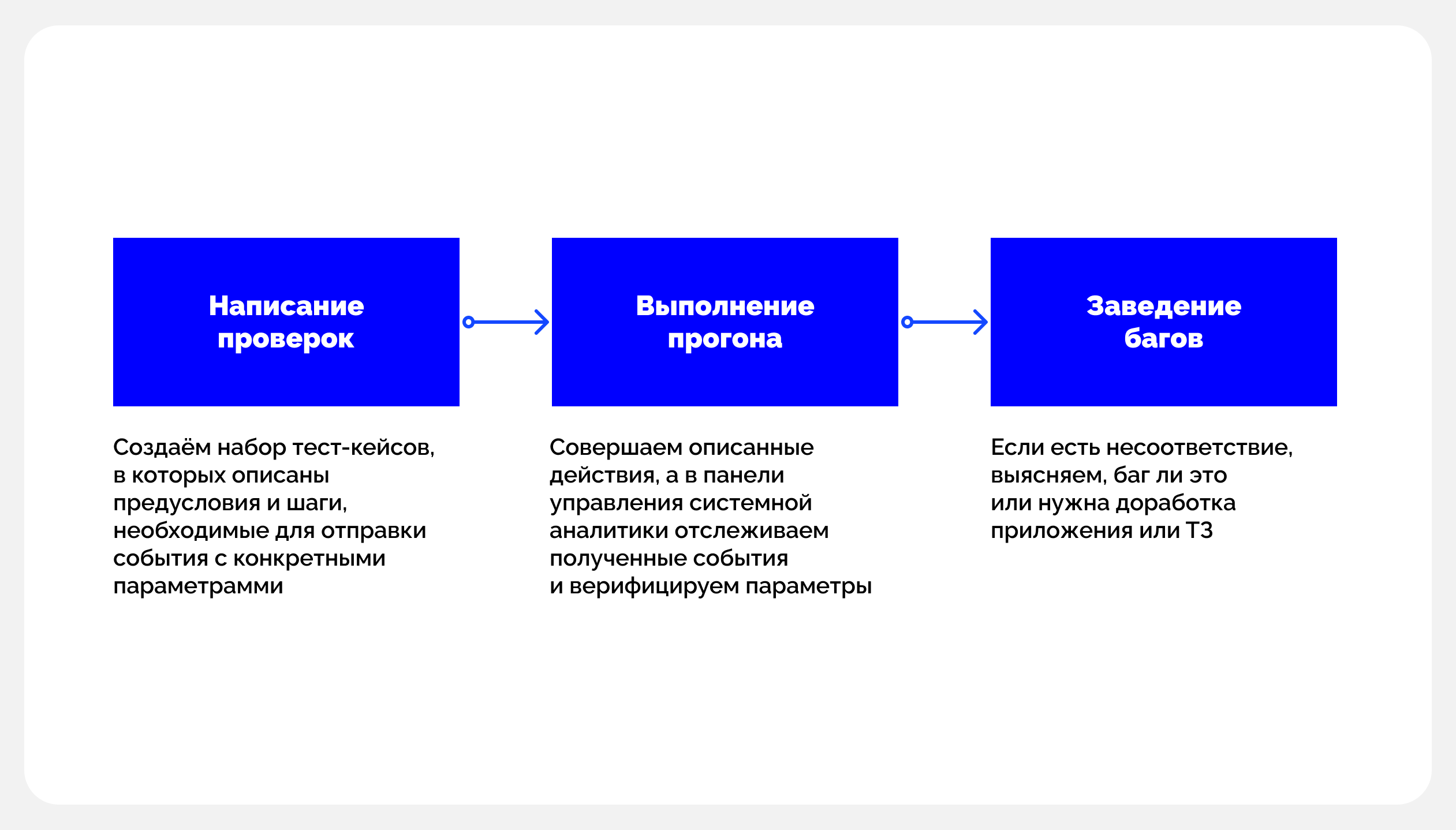
С учетом количества событий и сложности «получения» некоторых из них такое тестирование может занимать немало времени. Кроме того, иногда оно бывает достаточно рутинным для QA-инженера (о том, насколько трудозатратным может быть такое тестирование, расскажем чуть позже). А какой лучший способ победить рутину? Правильно, всё автоматизировать. Так мы и поступили в одном из разрабатываемых Flutter-приложений.
Автоматизированное тестирование отдельного события
Дисклеймер: о том, как пишем автотесты для Flutter, мы уже рассказывали. С момента написания этой статьи прошло почти два года. В чём-то мы усовершенствовали процесс, но основные подходы и наша удовлетворенность нативной автоматизацией на Flutter не претерпели существенных изменений. Поэтому будет здорово, если вам удастся сначала прочесть эту статью.
Если коротко, под капотом у нас нативные widget- и e2e-тесты, Gherkin для задания структуры сценариев, студийная библиотека surf_flutter_test и Cucumber для отчетов. Этого достаточно для эффективной реализации практически любого e2e-сценария, в том числе полностью на моковых данных. Кроме того, для автоматизации тестирования аналитики мы подключили две дополнительные библиотеки — mocktail для полноценного мокирования и определения вызова метода конкретного события и equatable для удобства сравнения вызванных событий.
Мы осознанно не останавливаемся подробно на создании тестовой «обвязки», мокировании внутренней логики и прочих «подготовительных» этапах. Потому что это достаточно объемно, сложно и заслуживает отдельной статьи. И скорее всего, конкретная реализация будет очень вариативна для каждого проекта в зависимости от используемых сервисов, внутренней структуры проекта и других факторов.
Поэтому для раскрытия темы ограничимся таким описанием —- мы получили возможность в любой момент просматривать все события, вызванные в рамках текущего сценария, имеем доступ к их параметрам и можем сравнивать их с «эталонными» событиями.
Но хватит теории, давайте смотреть, как это выглядит в коде. Вот пример шага, который проверяет отправку одного события:
final analyticsStepDefinitions = [
testerThen<ContextualWorld>(
RegExp(r'I succeed with sending analytic event orderCardOpened$'),
(context, tester) async {
await tester.pumpUntilVisible(ordersListTestScreen.trait);
await tester.implicitTap(firstOrderCard);
await tester.pumpUntilVisible(orderCardTestScreen.trait);
final analytics = context.world.container.read(mockAnalyticsProvider);
verify(() => analytics.logEvent(AnalyticsEvent.orderCardOpened(
orderId: '12345678',
store: 'Test store',
))).called(1);
},
),
];Как это происходит:
1. Двигаемся к целевому действию, которое вызывает отправку события, и совершаем его:
// Ждем открытия экрана со списком заказов.
await tester.pumpUntilVisible(ordersListTestScreen.trait);
// Тапаем на первый заказ в списке.
await tester.implicitTap(firstOrderCard);
// Ждем открытия карточки заказа.
await tester.pumpUntilVisible(orderCardTestScreen.trait);2. Читаем из контекста наш замокированный провайдер mockAnalyticsProvider, который отвечает за отправку событий аналитики:
context.world.container.read(mockAnalyticsProvider);3. Вызываем метод verify() из библиотеки mocktail, передаем в него ожидаемое событие вместе с параметрами и количество вызовов:
verify(() => analytics.logEvent(AnalyticsEvent.orderCardOpened(
orderId: '12345678',
store: 'Test store',
))).called(1);Дальше мы пока не нужны — verify() проверяет нужный вызов и равенство двух объектов-событий — что оказалось удобно реализовать благодаря использованию наследования от класса Equatable одноименной библиотеки. Если класс события, его параметры и количество вызовов совпали, двигаемся дальше, если нет — сценарий завершается и помечается как упавший.
Структура сценариев и переиспользование кода
Стоит сразу отметить еще один момент. Перед тем как получить возможность совершить целевое действие, сначала необходимо «прийти» на нужный экран. Чтобы не переписывать заново весь код, который это сделает, можно использовать стандартные шаги из e2e-сценариев: написать лишь «специальный» шаг, который выполняет только проверку события, описанную выше. Более того, в большинстве случаев можно просто переписать имеющийся шаг из е2е сценария или же дополнить уже существующий нужными проверками.
В примере выше у нас был шаг, который просто проверял открытие экрана карточки заказа. После этого мы добавили в него чтение события из контекста и вызов verify() с передачей в него события. Нужно учитывать, что для возможности и дальше по ходу сценария переиспользовать готовые e2e-шаги, в «специальном» шаге мы должны «остановиться» на том же «месте». Поэтому после проверки события иногда придется совершать еще какие-то действия, напрямую не относящиеся к тестированию аналитики, например, закрыть карточку заказа.
Может показаться, что мы почти закончили — осталось просто пройти по экранам и проверить события. Мы тоже так сначала подумали, но потом поняли, что с такой схемой тестирования можем обеспечить только очень узкое покрытие — отправку корректного события до момента вызова verify().
Что же мы не увидим при использовании такой схемы:
Целевое событие с корректными параметрами будет вызвано до целевого действия.
Метод verify() может только проверить, было ли на момент его вызова отправлено переданное событие или нет. Самостоятельно определить, что именно целевое действие вызвало отправку события, он не способен, а значит, и мы не можем быть уверены, что событие «висит» на нужном элементе.
Целевое событие будет отправлено второй раз, но с неверными параметрами.
Неважно, произойдет это до целевого действия или будет вызвано непосредственно им, verify() будет искать событие только с переданными параметрами. Поэтому если вместе с целевым событием с корректными параметрами отправится то же событие без параметров — тест будет пройден успешно.
В ходе сценария будут отправлены непредусмотренные, а значит, некорректные события.
Перед вызовом verify() мы читаем из контекста все события, которые были вызваны в текущем сценарии, но ищем среди них только нужное нам целевое событие. Все остальные события остаются без верификации, как по общему количеству, так и по типу.
Целевое действие вместе с корректным событием вызовет отправку непредусмотренного события.
После выполнения целевого действия мы следим только за отправкой корректного события, не проверяя, были ли вызваны какие-то ещё незапланированные события.
Поэтому простая проверка вызова целевого события показалась нам неэффективной, и, по-большому счету, практически не применимой — эта схема тестирования не позволяет быть уверенным в точности данных, попадающих в систему аналитики. Поэтому мы решили доработать ее и добавить дополнительные проверки, которые позволили бы устранить «слепые зоны». И вот, что у нас получилось.
Алгоритм полного покрытия всех событий и элементов
Для начала мы сделали общую функцию, которая может обрабатывать любое событие.
/// Function to check analytics event.
Future<void> checkAnalyticsEvent(
MockAnalyticsService analytics,
Future<void> Function() actionToCallEvent,
AnalyticsEvent event,
int eventsCalled,
) async {
verifyNever(() => analytics.logEvent(event));
if (eventsCalled == 0) {
verifyNever(() => analytics.logEvent(any()));
} else {
verify(() => analytics.logEvent(any())).called(eventsCalled);
}
await actionToCallEvent();
verify(() => analytics.logEvent(event)).called(1);
verifyNever(() => analytics.logEvent(any()));
}В функцию в виде параметров мы передаем:
analytics— замокированный сервис аналитики, откуда будем «доставать» вызванные события;функцию
actionToCallEvent— шаги, необходимые для непосредственного вызова события, своеобразный «триггер»;event— целевое событие, которое проверяем;eventsCalled— количество событий, помимо целевого, которые должны быть отправлены между текущим и предыдущим вызовом данной функции.
Последний параметр привел нас к необходимости добавить альтернативную обработку двух ситуаций. Она зависит от того, должны ли быть отправлены другие события, помимо целевого, между текущим и предыдущим вызовом. Необходимость ветвления вызвана тем, что verify() в силу своей реализации под капотом не способен проверить, что событие было вызвано ноль раз и для этого приходится использовать другой метод verifyNever(). То есть, вместо verify(() => analytics.logEvent(any())).called(0) нужно использовать verifyNever(() => analytics.logEvent(any())).
В остальном алгоритм для обоих кейсов совпадает, рассмотрим его для случая, когда eventsCalled != 0:
1. Проверяем, что целевое событие не было вызвано ранее в ходе сценария (и исключаем факт того, что оно может быть вызвано нецелевым действием):
verifyNever(() => analytics.logEvent(event));2. Проверяем, что общее количество нецелевых событий, которые были отправлены с момента последнего вызова функции checkEvent, совпадает с ожидаемым. Это значение мы можем определить заранее на основе логики сценария и передаем в параметре eventsCalled:
verify(() => analytics.logEvent(any())).called(eventsCalled);3. Вызываем переданную параметром функцию actionToCallEvent, которая совершает действия, необходимые для отправки целевого события:
await actionToCallEvent();4. Выполняем проверку вызова целевого события:
verify(() => analytics.logEvent(event)).called(1);5. Проверяем, что никакие другие события не были вызваны целевым действием:
verifyNever(() => analytics.logEvent(any()));Важно: все вызванные события, которые были обработаны методом
verify()по ходу сценария, автоматически помечаются какVERIFIEDи исключаются из дальнейших проверок (в рамках того же сценария).
То есть после выполнения кода verify(() => analytics.logEvent(event)).called(1) событие event больше не будет считаться «вызванным», а выполнение кода verify(() => analytics.logEvent(any())).called(eventsCalled) исключает из проверки вообще все вызванные события. Это удобно по двум причинам:
позволяет нам рассчитывать значение параметра
eventsCalledв каждом случае только на основании событий, отправленных с момента последнего вызоваcheckAnalyticsEvent, а не с начала сценария, поскольку мы можем быть уверены, что после каждого ее выполнения количество непроверенных событий равно нулю.если одно и то же событие вызывается несколькими действиями, и мы все их проверяем в одном сценарии, нам не нужно каждый раз считать, сколько раз оно было вызвано —это всегда будет 1, поскольку прошлый вызов пометил его
VERIFIEDи исключил из последующих проверок.
Теперь нам остаётся непосредственно в шагах сценария попасть на нужный экран, совершить «подготовительные» действия, вызвать нашу функцию, передав необходимые параметры, и, при необходимости, двинуться дальше к следующему шагу. Так это выглядит в коде:
testerThen<ContextualWorld>(
RegExp(r'I succeed with sending analytic event OrderCancelClicked$'),
(context, tester) async {
await tester.implicitTap(ordersTestScreen.firstOrderCard);
await tester.pumpUntilVisible(orderCardTestScreen.trait);
final AnalyticsEvent event = OrdersAnalyticsEvent.orderCancelClicked(
orderId: '12345678',
);
await tester.checkEvent(
context.world.container.read(mockAnalyticsProvider),
() async {
await tester.implicitTap(orderCardTestScreen.orderSecondaryButton);
await tester.pumpUntilVisible(generalTestScreen.actionBottomSheet);
},
event,
// Should be events LoggedIn, OrdersOpened, OrderCardOpened.
3,
);
await tester.implicitTap(generalTestScreen.alertActionPrimaryButton);
},
),Для удобства поддержки тестовых сценариев в комментарии к параметру eventsCalled можно указать наименования событий, которые должны быть вызваны и не верифицированы к моменту каждого конкретного вызова функции checkEvent.
Преимущества и недостатки описанного алгоритма
При реализации такой схемы проверки каждого события мы можем быть достаточно уверены, что:
целевое событие вызывается нужное количество раз;
целевое событие вызывается с корректными параметрами;
целевое событие вызывается именно целевым действием;
целевое действие не вызывает никакие другие события;
никакое действие, совершенное в сценарии, не вызывает незапланированные события.
К сожалению, если какой-то экран, элемент или действие не задействованы ни в одном сценарии тестирования событий аналитики, на них все-таки могут «висеть» незапланированные события, а мы об этом не узнаем. Но вероятность такого невелика по двум причинам:
1. Наш опыт говорит, что если уж приложение решили «покрыть» аналитикой, то это будет не 2-3 события. Как правило, в приложение добавляется сразу несколько десятков, если не сотен, событий, поэтому таких «слепых зон», куда мы не попадем в процессе автоматизации тестирования отправки этих событий, останется совсем немного.
2. Тяжело представить, что на случайный элемент, который вообще не должен вызывать событие, волшебным образом в коде навесится функция отправки, опять же, случайного события. Теоретически это возможно, если разработчик переиспользует код этого элемента с другого экрана и не заметит, что там спряталась отправка события. Но, скорее всего, это будет замечено и исправлено сразу им самим или на код-ревью.
Подводя промежуточный итог, можно сказать, что такая схема автоматизации тестирования отправки событий аналитики позволит обеспечить достаточно высокое покрытие, а значит, и высокую точность собираемых данных. Реализация такой схемы достаточно трудоемка, особенно, когда ее выполняет автоматизатор, слабо погруженный в тонкости алгоритма и специфику конкретного проекта.
Для примера: в одном из проектов, где мы реализовали такой алгоритм, только специализированные шаги с проверкой 50 событий аналитики занимают почти 1500 строк кода. И к этому еще нужно добавить шаги Gherkin’а, override самих классов-событий, какое-то количество инфраструктурного кода и, естественно, код, необходимый для мокирования продуктового сервиса отправки событий. Другими словами, задача явно не формата «Давай, вошли и вышли, приключение на 20 минут».
И тут может возникнуть вопрос, зачем нам все это? Зачем тратить столько времени, а, значит, и средств, на автоматизацию этого процесса, если всё можно проверить «руками»? Ну потерпят ручные QA эту рутину, никуда не денутся, зато сэкономим ресурсы проекта или продукта. И нам есть, что ответить на это. И не только потому, что мы так заботимся о своих «ручниках». Дело в том, что мы в Surf обожаем цифры и стараемся считать все, что может быть посчитано, а в данном случае статистика получается достаточно интересная.
Сравнение затрат времени на ручное и автоматизированное тестирование аналитики
На самом деле, вопрос целесообразности автоматизации тестирования событий аналитики лежит в той же плоскости, что и вопрос целесообразности автоматизации тестирования вообще. И решать его нужно, естественно, на основе цифр и расчетов.
Мы собрали статистику по проектам, на которых у нас ведется тестирование аналитики, как ручное, так и автоматизированное, по описанной выше схеме. Полученные цифры нельзя считать универсальными, они могут и будут меняться для каждого отдельно взятого проекта, процесса тестирования и компании в целом, но общее представление о соотношении затрат дать могут.
Сравнение затрат времени на написание проверок/сценариев по тестированию событий аналитики (в минутах)
Ручное тестирование |
Автоматизированное тестирование |
|
Написание проверок / сценариев на 1 событие |
6.5 |
69.8 |
Прогон тестов / сценариев на 1 событие |
21.8 |
0.03 |
Вполне ожидаемо видим, что ручные проверки пишутся быстрее, но выполняются медленнее, для автотестов же ситуация обратная. Теперь посмотрим, сколько времени займет первый прогон по всем событиям. На нашем опыте среднее приложение использует в сумме около 100 событий, будем опираться на эту цифру.
Сравнение затрат времени на первый прогон по тестированию событий аналитики (в часах)
Ручное тестирование |
Автоматизированное тестирование |
|
Написание проверок / сценариев на 100 событий |
10.83 |
116.33 |
Прогон тестов / сценариев на 100 событий |
36.33 |
0.05 |
Общая длительность первого прогона |
47.16 |
116.38 |
Пока ручное тестирование выигрывает по ресурсозатратности. Но давайте теперь посмотрим, как это соотношение будет меняться в динамике. Логично предположить, что полный прогон по всем событиям есть смысл делать при каждом крупном релизе, как часть общего регресса. На нашем опыте, средняя частота релиза активного развивающегося приложения — 1 раз в месяц. Посмотрим, как будут меняться затраты на тестирование в течение года.
Важно: ручные проверки и автотесты требуют регулярной актуализации из-за изменения технического задания, кодовой базы и других факторов. На дистанции в год, по нашему опыту, на это потребуется около 30% времени, затраченного на первоначальное написание. Естестественно, для каждого конкретного прогона эта цифра может как снижаться до нуля, если актуализация не потребовалась, так и расти в несколько раз, если был произведен серьезный рефакторинг. Но статистически это все равно составит около 30%. Поэтому в длительность каждого прогона мы заложили дополнительное время на актуализацию и отладку, которое в сумме за год даст те же 30% от затрат на написание проверок и тестов.
Сравнение затрат времени на тестирование событий аналитики в течение одного года
1 прогон (часов) |
2 прогона (часов) |
3 прогона (часов) |
4 прогона (часов) |
12 прогонов (часов) |
|
Ручное тестирование |
47.43 |
84.03 |
120.63 |
157.23 |
450.04 |
Автоматизированное тестирование |
119.29 |
122.25 |
125.20 |
128.16 |
151.83 |
Экономия времени при автоматизированном тестировании |
-71.86 |
-38.22 |
-4.57 |
29.07 |
298.21 |

Таким образом, уже через 3-4 месяца можно ожидать окупаемость затрат на автоматизацию процесса. А через год общая экономия составит около 2 месяцев (!) труда одного manual QA.
Важно: все расчеты приведены для тестирования только на одной платформе. Если добавить прогон для второй платформы, а также учесть, что систем аналитики может быть подключено несколько, и при ручном тестировании каждую систему придётся проверять отдельно или параллельно, тратя на прогон больше времени — то общая цифра экономии ресурсов вырастет в несколько раз. Возможна и обратная ситуация: для нативных платформ и фреймворков может потребоваться разработка двойного набора автоматизированных тестов, что увеличит срок окупаемости вложений.
Обратим внимание, цифры не абсолютные, и могут меняться в любую сторону в зависимости от многих факторов. Но общее представление о динамике соотношения затрат для каждого приложения с его стеком и особенностями они получить позволяют.
Преимущества и недостатки
А теперь давайте попробуем провести общий сравнительный анализ ручного и автоматизированного тестирования событий аналитики, чтобы понять, оправдана ли такая экономия ресурсов.
Сравнительный анализ ручного и автоматизированного тестирования событий аналитики
Критерий |
Manual |
Auto |
Скорость написания тестов |
Высокая |
Низкая |
Скорость прогона |
Низкая |
Высокая |
Скорость актуализации / отладки |
Высокая |
Низкая |
Сложность актуализации / отладки |
Низкая |
Высокая |
Покрытие в регрессе |
Зависит от подхода |
Стабильно высокое |
Вероятность ошибки |
Выше |
Низкая |
Устойчивость к изменениям |
Высокая |
Низкая |
e2e-тестирование |
Да |
Нет |
Экономическая рентабельность на стабильном и длительном проекте |
Низкая |
Высокая |
Можно сделать вывод, что ручное тестирование аналитики требует менее длительной подготовки, более стабильно и гибко с точки зрения текущей поддержки и актуализации. Однако оно не исключает ошибки из-за человеческого фактора и экономически менее рентабельно на длительной дистанции. Автоматизированное тестирование более надежно, значительно быстрее на этапе выполнения прогона, экономит ресурсы на дистанции, но требует длительной подготовки и более требовательно в поддержке и отладке.
Важно: описанная схема автоматизированного тестирования не обеспечивает полноценного end-to-end-тестирования. Мы проверяем только то, что наше приложение отправило событие, но не можем быть уверены, что эти данные в итоге попали в систему аналитики, а не были утрачены, например, из-за проблем на уровне API, «слетевших» настроек личного кабинета или других причин.
Поэтому оптимальным вариантом для организации ресурсоэффективного тестирования событий аналитики, которое при этом обеспечит действительно высокое покрытие и надежность, мы назовем следующую комбинацию: полный автоматизированный прогон по всем событиям, который дополняется небольшим ручным e2e-прогоном по нескольким основным событиям.
Выводы
Тестирование событий аналитики в мобильном приложении может быть автоматизировано без потери качества. На долгой дистанции такая практика оправдана экономически в той же степени, что и автоматизация UI-сценариев. Автотесты позволяют сократить объемы ручного тестирования аналитики на 80-90%, однако, в силу своей специфики, не могут полностью исключить его необходимость. Поэтому именно такое сочетание обоих видов тестирования позволит обеспечить надежное и широкое покрытие по адекватной цене.
Спасибо всем, кто дочитал, надеемся, вам было интересно и полезно. До новых встреч!
Для тех, кто хочет начать свой путь в автоматизации тестирования, Сергей сделал подробную дорожную карту — читайте по ссылке.