
Немного о Mojo
В середине октября этого года на LLVM 2023 Developer Meeting был презентован новый язык программирования Mojo, предназначенный для программирования задач, связанных с AI/ML (кстати, кроме блог поста рекомендую к просмотру запись самой презентации). Я не буду вдаваться в вопрос зачем нужен yet another язык программирования в 2023 году, и попрошу читателей ознакомиться с главой "Why Mojo" из документации языка прежде чем оставлять комментарий такого рода. Скажу лишь, что этот компилируемый язык предназначен для того, чтобы задействовать все возможности современных акселераторов вычислений вроде GPU, TPU, различного рода AI ASICов без погружения в дебри платформо-специфичного ассемблера. Это язык как бы является естественным продолжением экосистемы MLIR, созданным для упрощения взаимодействия с MLIR в задачах, связанных с высокопроизводительными вычислениями. Для лучшего понимания предмета нашего эксперимента приведу пример многопоточной реализации фрактала Мандельброта на Mojo:
from complex import ComplexSIMD, ComplexFloat64
from math import iota
from algorithm import parallelize, vectorize
from tensor import Tensor
alias float_type = DType.float64
alias simd_width = 2 * simdwidthof[float_type]()
alias width = 960
alias height = 960
alias MAX_ITERS = 200
alias min_x = -2.0
alias max_x = 0.6
alias min_y = -1.5
alias max_y = 1.5
fn mandelbrot_kernel_SIMD[
simd_width: Int
](c: ComplexSIMD[float_type, simd_width]) -> SIMD[float_type, simd_width]:
"""A vectorized implementation of the inner mandelbrot computation."""
let cx = c.re
let cy = c.im
var x = SIMD[float_type, simd_width](0)
var y = SIMD[float_type, simd_width](0)
var y2 = SIMD[float_type, simd_width](0)
var iters = SIMD[float_type, simd_width](0)
var t: SIMD[DType.bool, simd_width] = True
for i in range(MAX_ITERS):
if not t.reduce_or():
break
y2 = y * y
y = x.fma(y + y, cy)
t = x.fma(x, y2) <= 4
x = x.fma(x, cx - y2)
iters = t.select(iters + 1, iters)
return iters
fn main() raises:
let t = Tensor[float_type](height, width)
@parameter
fn worker(row: Int):
let scale_x = (max_x - min_x) / width
let scale_y = (max_y - min_y) / height
@parameter
fn compute_vector[simd_width: Int](col: Int):
"""Each time we operate on a `simd_width` vector of pixels."""
let cx = min_x + (col + iota[float_type, simd_width]()) * scale_x
let cy = min_y + row * scale_y
let c = ComplexSIMD[float_type, simd_width](cx, cy)
t.data().simd_store[simd_width](
row * width + col, mandelbrot_kernel_SIMD[simd_width](c)
)
# Vectorize the call to compute_vector where call gets a chunk of pixels.
vectorize[simd_width, compute_vector](width)
parallelize[worker](height, height)
Как видно, язык имеет Python-подобный синтаксис и предоставляет высокоуровневые примитивы для ускорения вычислений: SIMD (со встроенным методом fma - fuse multiply-add), ComplexSIMD , vectorize, parallelize и т.д.
На текущий момент времени язык находится в стадии closed source (с планом открытия исходного кода после окончания начальной стадии разработки) и разрабатывается компанией Modular, основанной Крисом Латтнером - одним из создателей LLVM, MLIR, компилятора Clang и языка Swift. Про Mojo уже есть пара статей на Хабре, с одной из которых я рекомендую ознакомиться тем, кому интересен обзор языка в целом.
О чем пойдет речь
Изучая сайт Modular, я наткнулся на статью с кричащим заголовком "The world's fastest unified matrix multiplication", в котором описывается как Modular AI Engine бьет по производительности библиотеки Intel MKL, OneDNN и Eigen в задаче GEMM (general matrix multiply - умножение матрицы на матрицу). Далее я ознакомился со статьей в их же блоге "AI’s compute fragmentation: what matrix multiplication teaches us" (TL DR: GEMM - фундамент современных нейронных сетей, SOTA-реализации - это километры сложнейшего кода на различных ассемблерах, и этот подход не масштабируется из-за привязки к платформе и трудоемкости разработки, поэтому нужно что-то менять, т.е. переходить на Mojo) и пришел к главе документации, которая описывает написание и оптимизацию GEMM на Mojo: используя встроенные средства языка, начинаем с наивной реализации, и постепенно улучшаем ее, добавляя векторизацию, параллелизм, тайлинг и т.п. В целом, судя по истории изменений этого конкретного примера из документации, его можно назвать условно оптимальным, так как достаточно много людей (в т.ч. разработчиков языка) языка приложило руку к его оптимизации. Учитывая все вышесказанное, мы просто обязаны сами погонять этот код и сравнить его производительность со стандартами индустрии!
Что и как будем сравнивать
Мы будем сравнивать производительность слегка модифицированного примера Matmul на Mojo 0.6.0, C/C++ библиотек Intel MKL 2020.4.304, OpenBLAS 0.3.25 и Eigen 3.4.0, а также наивной реализации умножения матриц на C++.
Сравнение будем проводить на CPU (в текущей версии Mojo 0.6.0 CPU - это единственный доступный таргет компиляции) Intel Xeon Platinum 8124M (16 ядер, инстанс
c5.4xlargeAWS EC2) на ОС Ubuntu 22.04.Для бенчмарков возьмем размеры матриц использованные самими Modular в их публикации. Сравним мы производительность как однопоточных версий кода, так и многопоточных.
Для компиляции бенчмарков на C++ будем использовать компилятор Clang с флагами
-O3 -march=native- последний флаг означает, что наша наивная реализация автоматически становится векторизованной.Сравнивать мы будем GFLOPS (Giga Floating Point Operations Per Second), рассчитывая их по формуле
GLOPS = 2 * M * N * K / time / 1e9, гдеM,N,K- размеры матриц (MxN=MxK*KxN), аtime- время в секундах, затраченное на выполнение операции умножения матрицы на матрицу.
Весь использованный код с инструкциями по запуску доступен в этом репозитории.
Сравнение
Многопоточная версия
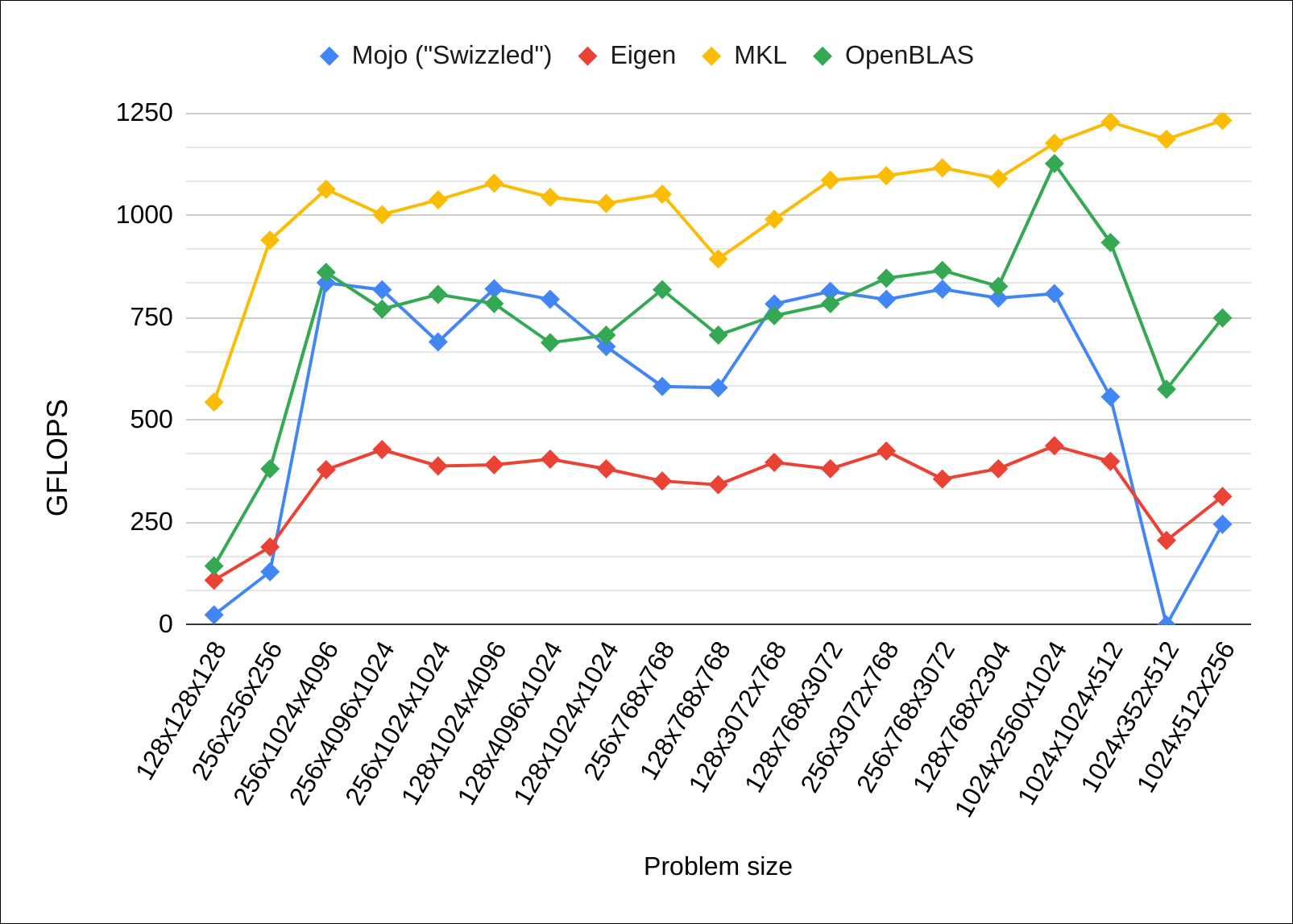
Problem size |
Mojo ("Swizzled") |
Eigen |
MKL |
OpenBLAS |
|---|---|---|---|---|
128x128x128 |
24.4 |
109.0 |
543.8 |
143.6 |
256x256x256 |
129.6 |
190.3 |
939.5 |
380.9 |
256x1024x4096 |
835.4 |
378.8 |
1063.6 |
860.6 |
256x4096x1024 |
818.0 |
428.0 |
1001.6 |
770.9 |
256x1024x1024 |
690.8 |
387.8 |
1037.7 |
806.8 |
128x1024x4096 |
820.5 |
390.8 |
1078.6 |
784.4 |
128x4096x1024 |
795.0 |
404.6 |
1044.2 |
688.9 |
128x1024x1024 |
679.6 |
380.9 |
1028.9 |
707.4 |
256x768x768 |
582.2 |
351.1 |
1051.7 |
818.5 |
128x768x768 |
579.0 |
342.1 |
893.4 |
707.5 |
128x3072x768 |
783.4 |
396.7 |
990.2 |
755.0 |
128x768x3072 |
814.3 |
381.2 |
1085.7 |
784.2 |
256x3072x768 |
794.7 |
424.3 |
1096.7 |
846.4 |
256x768x3072 |
819.6 |
356.1 |
1116.0 |
865.4 |
128x768x2304 |
797.8 |
381.0 |
1089.7 |
826.5 |
1024x2560x1024 |
808.8 |
437.3 |
1176.1 |
1126.2 |
1024x1024x512 |
556.7 |
399.0 |
1227.9 |
933.6 |
1024x352x512 |
0.0* |
206.3 |
1185.6 |
575.1 |
1024x512x256 |
245.4 |
313.5 |
1231.7 |
749.2 |
Однопоточная версия

Problem size |
Mojo ("Vectorized") |
Eigen |
MKL |
OpenBLAS |
Naive |
|---|---|---|---|---|---|
128x128x128 |
18.6 |
67.8 |
166.9 |
98.7 |
21.1 |
256x256x256 |
20.5 |
57.1 |
149.6 |
133.5 |
19.5 |
256x1024x4096 |
10.0 |
56.0 |
136.4 |
125.4 |
11.0 |
256x4096x1024 |
8.3 |
56.5 |
138.6 |
128.0 |
11.0 |
256x1024x1024 |
11.9 |
57.7 |
152.0 |
140.5 |
13.2 |
128x1024x4096 |
10.3 |
51.0 |
80.5 |
112.3 |
11.1 |
128x4096x1024 |
8.5 |
51.0 |
77.4 |
112.3 |
10.8 |
128x1024x1024 |
11.5 |
53.4 |
91.4 |
127.9 |
13.2 |
256x768x768 |
26.0 |
58.2 |
155.0 |
151.0 |
13.1 |
128x768x768 |
12.5 |
54.6 |
163.3 |
137.7 |
13.2 |
128x3072x768 |
9.6 |
52.1 |
87.7 |
124.5 |
12.5 |
128x768x3072 |
11.2 |
51.9 |
157.2 |
134.6 |
12.6 |
256x3072x768 |
9.7 |
58.6 |
147.4 |
137.0 |
12.4 |
256x768x3072 |
12.0 |
59.6 |
148.4 |
143.3 |
12.6 |
128x768x2304 |
12.4 |
52.4 |
162.7 |
135.2 |
12.7 |
1024x2560x1024 |
10.7 |
58.8 |
160.3 |
151.9 |
12.6 |
1024x1024x512 |
11.7 |
58.1 |
163.5 |
141.8 |
13.2 |
1024x352x512 |
0.0* |
56.6 |
162.3 |
159.4 |
17.1 |
1024x512x256 |
25.6 |
57.5 |
167.7 |
143.8 |
20.3 |
* - Код на Mojo падает с сегфолтом на кейсе 1024x352x512, поэтому в этом случае для Mojo указано 0 GFLOPS
Выводы
Итак, что мы видим? Во-первых, в случае однопоточного выполнения векторизованный код на Mojo показывает ту же производительность, что и код на C++, векторизованный с помощью Clang. Это вполне ожидаемо, но не слишком интересно и впечатляюще: кому нужно однопоточное выполнение в эпоху, когда закон Мура больше не работает?
Куда занятнее результаты для многопоточной версии. Здесь мы видим, что:
Intel MKL ожидаемо дает фору всем остальным вариантам (ожидаемо потому, что эта библиотека для процессоров Intel разрабатывается самими Intel).
Eigen проигрывает вообще всем, кроме наивной реализации, что несколько странно и неожиданно.
Mojo показывает производительность, которая сопоставима с производительностью OpenBLAS.
Последний пункт особенно важен. Почему? А потому что OpenBLAS - это монстр, состоящий из ассемблерного кода, который годами оптимизировали красноглазые гении в подвалах под каждую существующую микроархитектуру Intel, в то время как программа на Mojo - это пара сотен строк условно-платформонезависимого питоноподобного кода, что очень впечатляет.
Заключение
Учитывая абсолютно звездный состав команды Modular, и производительность, которую код на Mojo показывает на текущем этапе, можно со сдержанным оптимизмом предположить, что Mojo успешно займет планируемую нишу: быть языком сравнительно высокого уровня для реализации кросс-плафторменных производительных ML-специфичных вычислений.
Эта статья (а скорее даже заметка), как и этот набор бенчмарков, не претендует ни на научную точность, ни на то, чтобы быть исчерпывающей, по крайней мере, по следующим причинам:
Тесты проводились на одном единственном CPU.
Mojo имеет закрытый исходный код и он удивительно нестабилен и попросту крив: просто посмотрите на обилие лежащих на поверхности багов и ошибок, которые в нем есть на данный момент.
Использовался игрушечный пример на Mojo для умножения матриц, т.е. предположение, что код оптимален, запросто может быть ошибочным.
Последнее, но от того не менее важное: возможно я где-то не дожал и/или использовал одну из библиотек не совсем правильно, поэтому производительность оказалась плачевной.
В любом случае, основной целью этой небольшой статьи (которой, она, я надеюсь, достигла) являлось рассказать сообществу еще раз о Mojo как о потенциальном будущем стандарте индустрии, которым он вполне может стать в ближайшие годы, и немного подогреть интерес русскоязычного сообщества к нему.
Комментарии (4)

Deosis
25.12.2023 23:11+1последний флаг означает, что наша наивная реализация автоматически становится векторизованной
-march=native означает, что код будет оптимизироваться под процессор, на котором собирается.
Для gcc есть флаг -fvect-cost-model=unlimited, который делает это.

errorsmissing
25.12.2023 23:11Последний пункт особенно важен. Почему? А потому что OpenBLAS - это монстр, состоящий из ассемблерного кода, который годами оптимизировали красноглазые гении в подвалах под каждую существующую микроархитектуру Intel, в то время как программа на Mojo - это пара сотен строк условно-платформонезависимого питоноподобного кода, что очень впечатляет.
А кто тогда MKL оптимизировал? Он то побыстрей будет.
Плюс OpenBLAS в том, что вендор его может замокать (например как это делает Apple).
Так что пока, Mojo смешно смотрится.

porto Автор
25.12.2023 23:11В целом согласен, но MKL - это библиотека от самого вендора CPU, то есть, например, на процессорах AMD картина для описанных бенчмарков может быть качественно другой, не говоря уже про совсем отличное от x64 железо. С OpenBLAS же такого быть не должно.
Следование спецификации BLAS действительно много где развязывает руки в плане использования более быстрых реализаций от вендоров железа (Accelerate от Apple, BLIS от AMD, ArmPL от Arm и т.д.), но, как разобрано в этом посте от Modular, подход с платформо-специфичными реализациями, которые тюнились руками, очень плохо масштабируется, особенно для нейронок. В это собственно и заключается основной вывод статьи и, собственно, главная мотивация разработчиков языка: Mojo может и отстает в моменте, но потенционально он предоставляет намного более гибкий и масштабируемый подход для реализации вычислений.
iskateli
Главное чтобы не получилось как с языком Julia: когда в экосистеме появляется слишком много багов корректности и сочетаемости