
Всем привет! Недавно мне выпала возможность разработать шаблон сервиса, который можно было бы использовать как для монолитной, так и для микро-сервисной архитектуры. Шаблон должен был придерживаться принципов Domain-Driven Design (DDD). В этом процессе, я столкнулся с двумя интересными проблемами:
Проблема 1: Сложности обеспечения транзакционности базы данных
При разработке сервисов, часто возникает неотъемлемая потребность в использовании транзакций базы данных для обеспечения целостности данных. Однако, при попытке интегрировать транзакционную логику в традиционные подходы, столкнулся с трудностями. Связывание транзакционной логики с логикой слоя базы данных оказалось нетривиальным и привело к нарушению принципов разделения ответственности. Это, в свою очередь, сказалось на тестировании и поддержке кода.
Проблема 2: Нарушение изолированности слоя
В попытке решить первую проблему, некоторые разработчики переносят работу с транзакциями на уровень слоя приложения, чтобы избежать прямой зависимости от базы данных. Однако, такой подход, несмотря на его обоснование, может нарушить изолированность слоев и противоречить принципам DDD и чистой архитектуры. Это, в конечном итоге, затрудняет поддержку приложения и усложняет его масштабирование.
Эти две проблемы стали отправной точкой для исследования применения паттерна Unit of Work и его роли в обеспечении надежности и консистентности данных в контексте Golang и DDD.
В статье я расскажу о своем подходе к решению этих задач.
В мире современной разработки, одним из важных и популярных архитектурных подходов является чистая архитектура, также известная как гексагональная. Этот метод дает четкие ответы на ряд архитектурных вопросов и идеально подходит для сервисов как с малой так и довольно большой кодовой базой. Еще одним преимуществом чистой архитектуры является ее совместимость с применением Domain-Driven Design (DDD) — два подхода идеально дополняют друг друга.
Такой подход выделяет отдельные слои, адаптеры и компоненты очень четко, и в то же время непринужденно интегрируется в мир разработчиков на Go и имеет ряд преимуществ. Он не требует сложных абстракций или запутанных паттернов, что делает такой подход согласованным с идиоматикой языка Go, известной как "Go way".
Однако, существует небольшая проблема, с которой многие команды сталкиваются при внедрении гексагональной архитектуры, и с которой я сам лично столкнулся — это управление транзакциями базы данных.
Следует понимать, что чистая архитектура делает явное разделение между внутренними компонентами приложения и внешними адаптерами, что включает в себя работу с базой данных. Иногда возникает необходимость выполнять операции с базой данных в рамках одной транзакции, чтобы гарантировать целостность данных. И вот тут многие разработчики отходят от принципов чистой архитектуры и допускают некоторые послабления. В результате получают либо протекание слоя базы данных в слой приложения, либо выносят бизнес-логику на уровень базы данных.
В этой статье я поделюсь своим опытом и расскажу, как я сам успешно решил эту проблему.
Углубимся в проблему сложных абстракций
Прежде чем мы перейдем к основным аспектам этой темы, давайте более детально рассмотрим чистую архитектуру и принципы Domain-Driven Design (DDD). Это позволит нам понять, почему так важно соблюдать четкое разделение слоев и не перемещать бизнес-логику приложения из его доменной части.
Гексагональная архитектура строится на принципе инверсии зависимостей, где центральным элементом является доменная модель данных, а вокруг нее располагаются другие слои - доменная логика, слой логики сервиса и адаптеры (транспорт приложения, работа с базой данных, подключения к брокерам сообщений и.т.д ). Зависимости в этой архитектуре идут от центра к периферии, что делает ее очень гибкой и модульной.
Другими словами - ваше приложение не должно зависеть от конкретной базы данных или выбранного вами вида транспорта. Всегда должна быть возможность легко и безболезненно их заменить. А так как каждый слой отделен от другого набором интерфейсов - это позволяет легко тестировать все слои приложения и использовать моки.
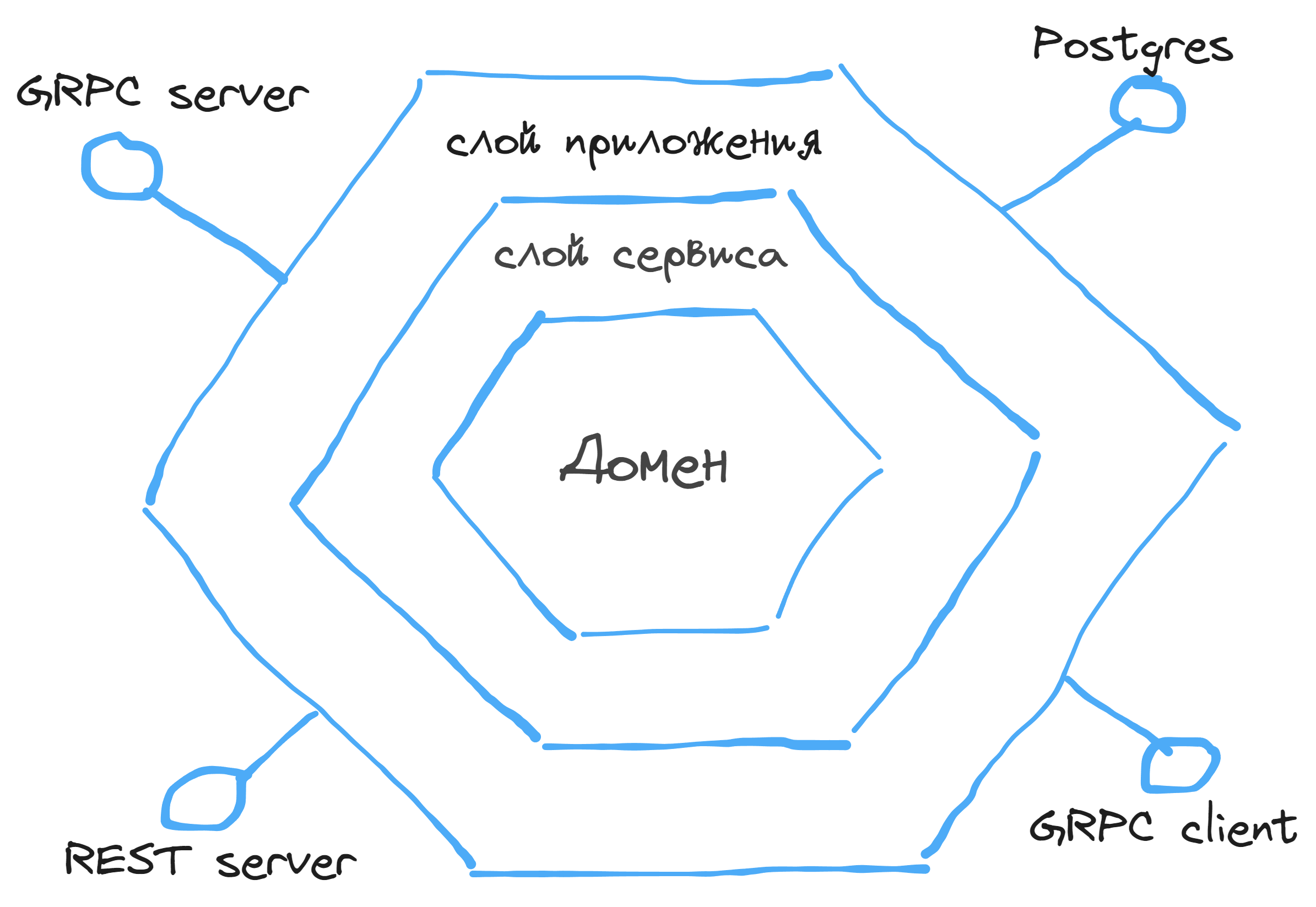
Однако, с этой гибкостью приходят и некоторые проблемы. Одной из них является сложность управления слоями абстракций. Каждый слой имеет свои особенности и ответственности, и иногда может быть сложно определить, где должна заканчиваться одна абстракция и начинаться другая. Это может привести к излишней сложности и путанице в архитектуре приложения. Тут то и кроются основные сложности реализации.
Один из таких случаев мы сейчас и рассмотрим.
На примере реализации приложения
Переходя к теме моей статьи - давайте посмотрим как может выглядеть реализация слоя базы данных для небольшого приложения для создания и редактирования заметок.
Представьте, что у вас есть база данных с двумя таблицами:
Таблица "Заметки" (Notes), где хранятся сами заметки, каждая заметка имеет уникальный идентификатор и текстовое содержание.
Таблица "История изменений" (ChangeHistory), которая отслеживает историю изменений заметок. Она содержит записи о каждом изменении, включая идентификатор изменения, идентификатор заметки, старое содержание и новое содержание, а также дату и время изменения.
Реализация слоя базы данных отделенного интерфейсами методом, могла бы выглядеть следующим образом.
// Reader - методы для извлечения данных из БД
type Reader interface {
GetNoteByUUID(*dbo.NoteReq) (*dbo.NoteRes, error)
GetAllNotes() ([]dbo.NoteRes, error)
}
// Writer - методы для сохранения данных в БД
type Writer interface {
CreateNote(*dbo.Note) error
UpdateNoteByUUID(*dbo.Note) error
}Со стороны слоя приложения, где обычно реализуется только инфраструктурная логика код обновления заметки мог бы выглядеть следующим образом.
// UpdateNoteUseCase --
type UpdateNoteUseCase struct {
log log.Logger
writer port.Writer
}
...
// Execute - usecase обновляет запись в заметке
func (ths UpdateNoteUseCase) Execute(req *dto.UpdateNoteRequest) (error) {
...
err := ths.writer.UpdateNoteByUUID(&dbo.Note)
if err != nil {
log.Error("Unable update note %s\n",err.Error())
}
...
} Этот код довольно прост и содержит элементарный пример с атомарной операцией обновления. И тут нет никаких проблем. Однако часто возникает надобность выполнить несколько операций в рамках одной транзакции базы данных.
Представьте, что в вашем приложении для хранения заметок вы хотите реализовать функциональность редактирования заметок с возможностью просмотра истории изменений.
Это могло бы выглядеть так:
Пользователь выбирает заметку для редактирования.
Приложение начинает транзакцию, чтобы обеспечить целостность данных и избежать проблем с параллельным доступом.
При редактировании заметки, приложение создает новую запись в таблице «История изменений», сохраняя старое содержание заметки, новое содержание и другие метаданные, такие как идентификатор заметки и дату и время изменения. Эта запись в истории изменений будет содержать информацию о том, что было изменено и кем.
Затем приложение обновляет саму заметку в таблице «Заметки» с новым текстовым содержанием, сохраняя тем самым текущее состояние заметки.
После успешного редактирования заметки и записи в истории изменений, приложение завершает транзакцию, подтверждая все операции.
В таком случае к интерфейсам методов базы данных мы бы добавили пару новых методов для работы с историей.
// Reader - методы для извлечения данных из БД
type Reader interface {
...
GetChangeHistoryByNoteUUID(*dbo.ChangeHistoryReq)([]dbo.ChangeHistoryRes)
}
// Writer - методы для сохранения данных в БД
type Writer interface {
...
UpdateChangeHistoryByNoteUUID(*dbo.ChangeHistory) error
}Казалось бы, ничего сложного - для того, чтобы вызвать два атомарных метода в составе транзакции БД достаточно обернуть их в стандартные вызовы Begin, Rollback, Commit. Давайте попробуем это реализовать - однако для этого придется добавить зависимость от базы данных в слой приложения.
// UpdateNoteUseCase _
type UpdateNoteUseCase struct {
log log.Logger
writer port.Writer
db *gorm.DB
}
...
// Execute - usecase обновляет запись в заметке
func (ths UpdateNoteUseCase) Execute(req *dto.UpdateNoteRequest) (error) {
tx := ths.db.Begin()
// обновление заметки
...
// добавление записи в историю изменений
...
if err != nil {
tx.Rollback()
log.Error("Unable update note %s, Rollback \n",err.Error())
} else {
tx.Commit()
}
}Но это то как раз тот случай, когда нарушается принцип изоляции, и слой базы данных “проливается” в слой приложения.
Недостатки переноса транзакционной логики на уровень приложения
Одним из главных недостатков этого подхода является нарушение изоляции слоя приложения от деталей реализации базы данных. Это не позволяет свободно изменять и оптимизировать структуру базы данных без влияния на бизнес-логику.
Нарушение принципа единственной ответственности: Перенос транзакционной логики на уровень приложения может привести к тому, что слой приложения начинает нести ответственность не только за бизнес-логику, но и за управление транзакциями. Это усложняет структуру кода и затрудняет его поддержку.
Усложнение тестирования: Вместо того чтобы иметь четко выделенный слой доступа к данным, внутри которого можно тестировать операции базы данных, транзакционная логика становится частью слоя приложения. Это усложняет юнит-тестирование и может повлечь за собой необходимость создания более сложных сценариев для проверки.
Перенос бизнес-логики на уровень базы данных
Еще один способ решения проблемы состоит в том, чтобы реализовать отдельный метод на уровне базы данных, который будет содержать в себе все необходимые манипуляции. Вот так мы могли бы расширить интерфейсы методов в слое базы данных:
// Reader - методы для извлечения данных из БД
type Reader interface {
...
}
// Writer - методы для сохранения данных в БД
type Writer interface {
...
}
// Trxer - методы для работы с транзакциями в БД
type Trxer interface {
UpdateNoteAndChangeHistory(*dbo.Note,*dbo.ChangeHistory) error
}Да, при таком решении изолированность слоя не будет нарушена и тестирование не пострадает, однако слой базы данных начнет "распухать", потому что придется описывать каждый конкретный случай бизнес-логики. Давайте рассмотрим преимущества и недостатки такого подхода
Преимущества
Прямой контроль над транзакциями: Перенося бизнес-логику на слой базы данных, мы получаем возможность обеспечивать транзакционность на более низком уровне. Это может быть полезно в случаях, когда требуется более тонкая настройка транзакций и управление их поведением.
Использование возможностей СУБД: Многие современные системы управления базами данных (СУБД) предоставляют расширенные функциональные возможности для работы с транзакциями. Перенос бизнес-логики на слой базы данных позволяет использовать эти возможности без дополнительных абстракций.
Недостатки
Связывание бизнес-логики с СУБД: Перенося бизнес-логику в слой базы данных, мы создаем тесную связь между бизнес-логикой и конкретной СУБД. Это делает код менее переносимым и связывает его с конкретной технологией.
Ограниченная гибкость: Бизнес-логика, находящаяся в слое базы данных, может быть менее гибкой и сложной в сопровождении, особенно в случаях, когда требуется изменить логику или масштабировать приложение.
Проблемы в тестировании
Перенос бизнес-логики на слой базы данных также вносит определенные вызовы в процесс тестирования.
Сложности в юнит-тестировании: Тестирование бизнес-логики, находящейся в слое базы данных, может быть сложным, так как она часто зависит от конкретных функций СУБД, которые не всегда легко эмулировать в юнит-тестах.
Изоляция тестов: При переносе бизнес-логики на слой базы данных, тестирование становится более зависимым от реальной базы данных, что может затруднить изоляцию тестов и создание надежных и воспроизводимых тестовых сценариев.
Решение с использованием паттерна Unit of Work
В приложениях часто используется шаблон Repository (и наш пример не исключение) для инкапсуляции логики работы с БД. Паттерн Unit of Work помогает упростить работу с различными репозиториями и дает уверенность, что все репозитории будут использовать один и тот же DbContext.
Так же использование шаблона Repository и Unit of Work позволяет создать правильную структуру для развертывания приложения и тестирования проекта:

Добавим в слой базы данных отдельный метод с одноименным названием:
// Reader - методы для извлечения данных из БД
type Reader interface {
...
}
// Writer - методы для сохранения данных в БД
type Writer interface {
UnitOfWork(func(Reader, Writer) error) (err error)
...
}Реализация функции UnitOfWork будет выглядеть так:
var _ port.Writer = (*SQLStore)(nil)
...
// SQLStore fulfills the Writer and Reader interfaces
type SQLStore struct {
db *gorm.DB
log log.Logger
}
...
// UnitOfWork --
func (ths *SQLStore) UnitOfWork(fn func(writer port.Writer) error) (err error) {
trx := ths.db.Begin()
if err != nil {
return err
}
defer func() {
if p := recover(); p != nil {
_ = trx.Rollback()
switch e := p.(type) {
case runtime.Error:
panic(e)
case error:
err = fmt.Errorf("panic err: %v", p)
return
default:
panic(e)
}
}
if err != nil {
trx.Rollback()
} else {
trx.Commit()
}
}()
newStore := &SQLStore{
db: trx,
}
return fn(newStore)
}А вот так будет выглядеть ее применение вместе с атомарными методами для внесения изменений в таблицы Notes и ChangeHistory в слое приложения.
// UpdateNoteUseCase _
type UpdateNoteUseCase struct {
log log.Logger
writer port.Writer
reader port.Reader
}
...
// Execute - usecase обновляет запись в заметке
func (ths UpdateNoteUseCase) Execute(req *dto.UpdateNoteRequest) (error) {
...
if err = ths.writer.UnitOfWork(func(rTx port.Reader, wTx port.Writer) error {
if err = wTx.UpdateNoteByUUID(&dbo.Note) ; err != nil {
return err
}
if err = wTx.UpdateChangeHistoryByNoteUUID(&dbo.ChangeHistory); err != nil {
return err
}
return nil
}); err != nil {
return nil, err
}
}Заключение
Мы рассмотрели, как этот паттерн обеспечивает изоляцию бизнес-логики от деталей работы с данными. Это позволяет нам поддерживать чистоту кода и соблюдать принципы чистой архитектуры и DDD.
Также стоит отметить, что применение паттерна Unit of Work не ограничивается только монолитными приложениями. Мы увидели, как он может быть успешно интегрирован в микро‑сервисную архитектуру, обеспечивая управление транзакциями между службами.
Этот метод может быть применен к разнообразным базам данных, которые поддерживают ACID‑транзакции, при условии, что существует общий интерфейс для выполнения запросов как внутри транзакции, так и вне ее. В случае отсутствия такой возможности в выбранной библиотеке, всегда есть возможность разработать собственную обертку.
Для более удобного понимания информации изложенной в статье — предлагаю взглянуть на репозиторий, в котором реализуется данный подход.
Приглашаю вас делиться своими идеями и мыслями в комментариях.
Комментарии (5)

hello_my_name_is_dany
30.12.2023 20:20Вы всё же реализовали просто транзакционный метод, это не Unit of Work. Тем более, что у вас Writer вдруг знает о Reader и метод этот во Writer. Что даёт забавную возможность:
ths.writer.UnitOfWork(func(rTx port.Reader, wTx port.Writer) error { wTx.UnitOfWork(func(rrTx port.Reader, wwTx port.Writer) error { wwTx.UnitOfWork(func(rrrTx port.Reader, wwwTx port.Writer) error { // и тд }) }) })Суть Unit of Work в том, чтобы там было для нескольких репозиториев ОДНО соединение к СУБД. К транзакциям он не имеет никакого отношения, это скорее приятное следствие. Если брать тот самый EF Core, из которого вы взяли понятие DbContext - именно он внутри отвечает там за транзакции.
По идее должно быть что-то типа такого:
type Repository1 struct { connection *Connection } func (r *Repository1) FindById(id int) Entity {} type Repository2 struct { connection *Connection } func (r *Repository2) FindById(id int) Entity {} type UnitOfWork struct { connection *Connection repo1 *Repository1 repo2 *Repository2 } func (u *UnitOfWork) GetRepository1() *Repository1 { if u.repo1 == nil { u.repo1 = &Repository1{u.connection} } return u.repo1 } func (u *UnitOfWork) GetRepository2() *Repository2 { if u.repo2 == nil { u.repo2 = &Repository2{u.connection} } return u.repo2 }А для транзакций делаем уже, что нам удобнее
// Транзакционный метод func (u *UnitOfWork) Transaction(fn func() error) {} // Или методы управления транзакцией func (u *UnitOfWork) BeginTransaction() *Transaction {} func (u *UnitOfWork) RollbackTransaction() {} func (u *UnitOfWork) CommitTransaction() {}И соответственно интерфейсы на уровне домена/приложения
type Repository1 interface { FindById(id int) Enity } type Repository2 interface { FindById(id int) Entity } type UnitOfWork interface { func (u *UnitOfWork) GetRepository1() *Repository1 func (u *UnitOfWork) GetRepository2() *Repository2 func (u *UnitOfWork) Transaction(fn func() error) }ну и использование
uow.Transaction(func () error { uow.GetRepository1().FindById(1024) uow.GetRepository2().FindById(1025) })

ArthurG
30.12.2023 20:20Спасибо за статью!
SQLStoreточно реализует интерфейс Writer? Мне кажется там аргумента не хватает. Могу ошибаться.А как бы вы реализовали ограничение для unit of work, сначала должны выполниться все операции чтения и только потом операции записи?


Kelbon
30.12.2023 20:20+3Статья полна бесполезных ничего не значащих слов типа "чистая архитектура", "DDD" (повторяется в статье 8 раз), "Domain-Driven Design (DDD)" (вся фраза целиком повторяется в статье 3 раза)
Своей статьёй вы же и нарушаете свои "принципы" (Do not Repeat Yourself)
разработать шаблон сервиса, который можно было бы использовать как для монолитной, так и для микро-сервисной архитектуры. Шаблон должен был придерживаться принципов Domain-Driven Design (DDD)
Монолит, микросервисы, DDD, всё это пустые слова, здесь буквально написано "мне нужно было написать шаблон программы" - это невозможно.
Все эти слова используются для описания готового приложения, чтобы легче объяснить человеку как оно работает, но невозможно следовать "принципам чистой архитектуры", так как они +- выглядят как "не делайте плохо, делайте хорошо"
В целом всю статью можно описать так:
" А давайте в интерфейс ДБ добавим методы .begin_transaction() .commit() .rollback() "error_code my_transaction(....) { auto transaction_handle = db.begin_transaction(); error_code err; on_scope_exit { if (err) transaction_handle.rollback(); else transaction_handle.commit(); }; .... }
olivera507224
А для чего здесь идёт проверка ошибки? err в данном случае объявлена как именованный результат, при входе в метод она безальтернативно будет рана nil. Код
return errв этом примере недостижим.