
Мы работаем с ИТ-продуктами в сфере логистики и e-commerce. Большинство таких проектов крупные с точки зрения архитектуры – включают в себя множество сервисов, необходимых для исправной работы целостных систем.
Поговорим о том, как организовать взаимодействие микросервисов в большом продукте-долгожителе синхронно и асинхронно.
Микросервисный подход предполагает создание микросервиса под каждую фичу внутри большого продукта. Например, микросервис, отвечающий отдельную функцию в логистических процессах:
складское хранение (сбор/размещение/перемещение товарных единиц)
сортировка грузомест
стикеровка грузомест
консолидация грузомест
и т.д.
Каждый микросервис имеет собственную кодовую базу, базу данных и API для взаимодействия с другими сервисами. Это позволяет писать их на разных языках программирования и использовать различные технологии. Все новые микросервисы пишутся на новых версиях фреймворков, все старые – постепенно мигрируются. Цель: обеспечить максимально эффективный и стандартизованный подход к обеспечению взаимодействия между микросервисами. Создание нового микросервиса и интеграция его в общую систему должна происходить максимально быстро и безболезненно, как для его разработчика, так и для разработчиков клиентов этого микросервиса.
Синхронное взаимодействие микросервисов
Синхронное взаимодействие – это взаимодействие, при котором одна система отправляет сообщение другой и ожидает подтверждения или ответа, прежде чем продолжить. Этот тип взаимодействия является обычным, когда первой запрашивающей системе требуется информация для того, чтобы продолжить выполнять какое-либо свое действие. Для организации такого взаимодействия есть множество протоколов, таких как (g)RPC, SOAP, также широко применяется архитектурный стиль REST.
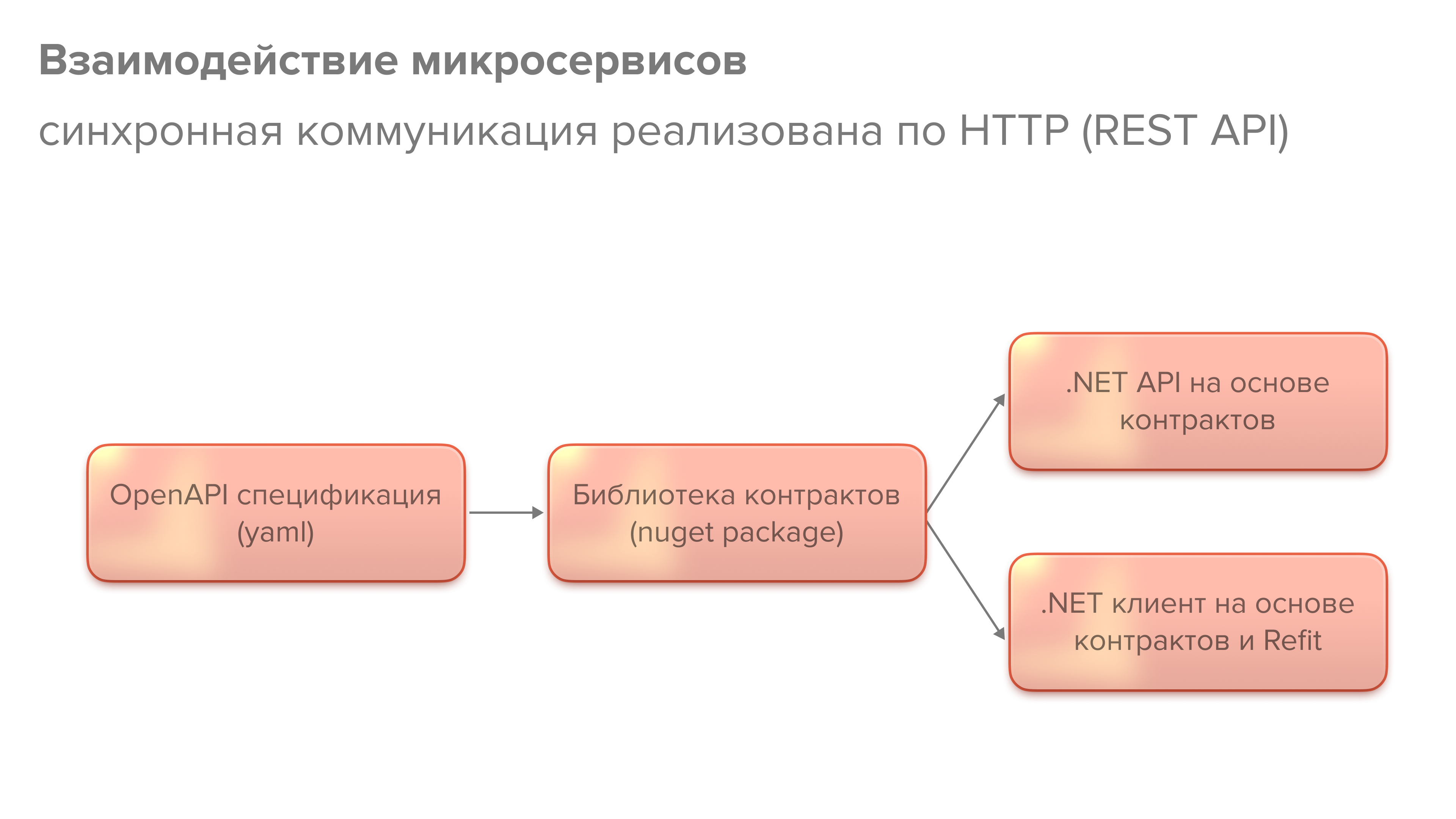
На схеме крупными мазками изображен подход к разработке API нового микросервиса. Сначала мы создаем спецификацию API в формате OpenAPI, утверждаем её с отделом архитектуры, а на ее основе создаем библиотеку контрактов, содержащую интерфейсы и структуры данных API . После этого на ее основе можно создавать API и клиентов, которые будут пользоваться этим API. Для разработки клиентов мы применяем библиотеку Refit.

Вот так выглядит OpenAPI спецификация. В IDE Rider есть плагин, который позволяет ее редактировать и как Swagger генерирует описание спецификации. Тут описаны все методы этого API, структуры запросов и ответов. Когда эта спецификация утверждена, приступаем к разработке библиотеки контрактов.
Библиотека контрактов
Библиотека контрактов – это Nuget пакет на основе спецификации. Он содержит:
Интерфейсы каждого API контроллера
Интерфейс клиента, который по сути является объединением всех интерфейсов контроллеров
Модели запросов/ответов, используемые в контроллерах

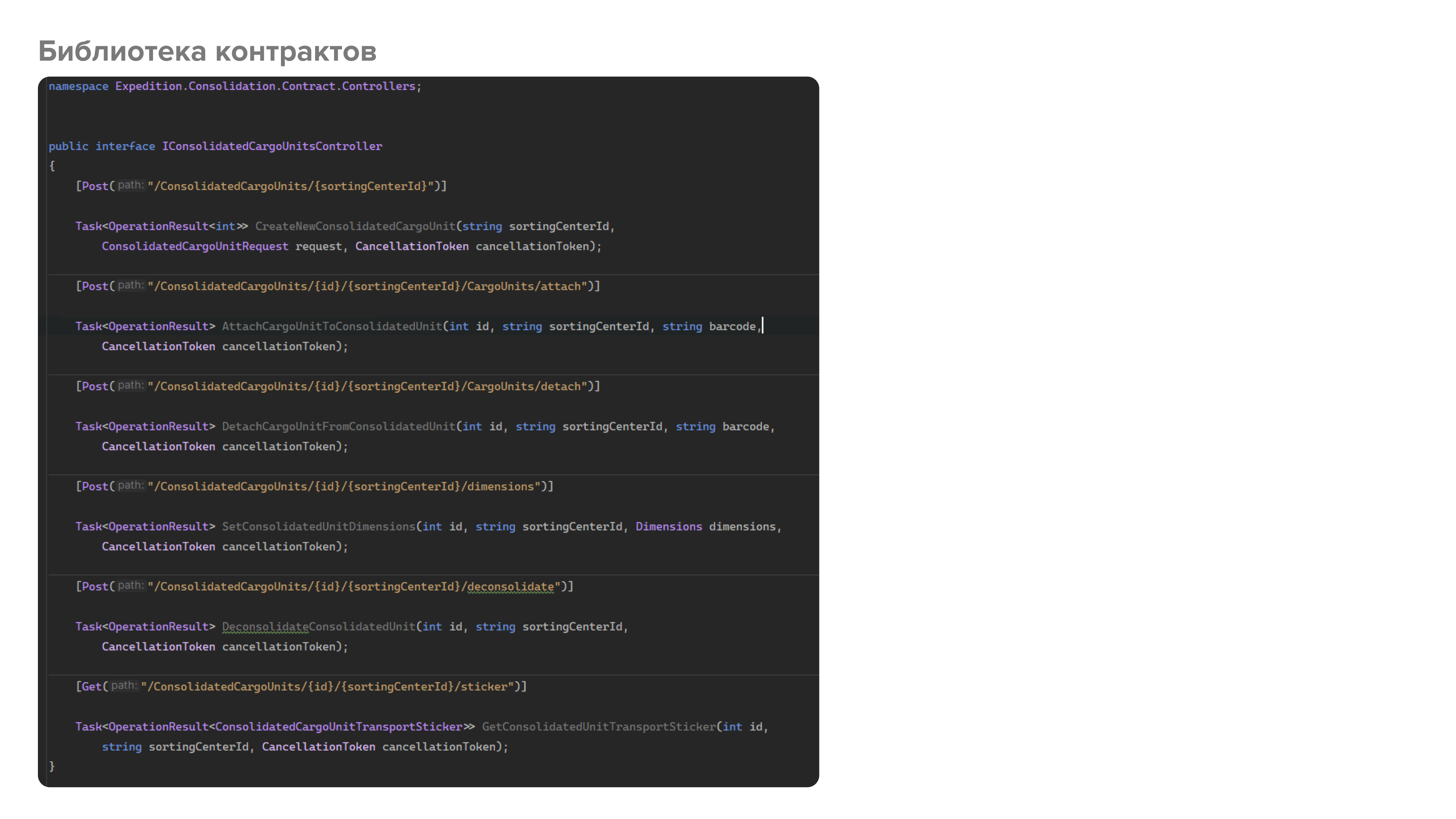
Например, в одной из библиотек у нас есть два интерфейса - ITaskController и IConsolidationCargoUnitsController. В них определены все необходимые методы, которые в дальнейшем будут реализованы как соответствующими контроллерами, так и клиентами. Поскольку для генерации клиентов мы используем библиотеку Refit, то здесь мы дополнительно определяем типы запросов и их маршруты с помощью атрибутов [Get(...)], [Post(...)] и т.д. Важно заметить, что это не ASP.NET атрибуты, а Refit. Соответственно, наша библиотека контрактов вообще может не иметь зависимости от ASP.NET.
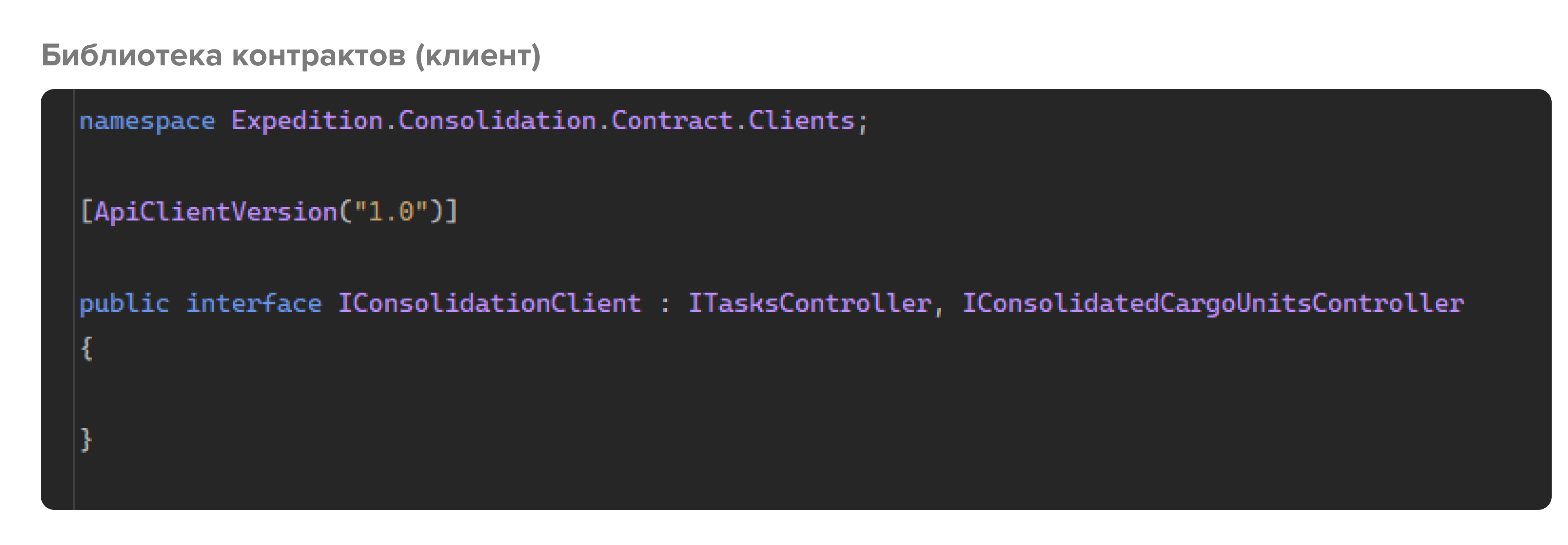
Далее описываем интерфейс клиента, который не содержит своих методов, а просто наследует все интерфейсы контроллеров, и помечаем его специальным атрибутом, реализующим версионность. Имплементация этого интерфейса (с помощью библиотеки Refit) и будет являться клиентом, которым пользуются внешние системы, чтобы взаимодействовать с ним.
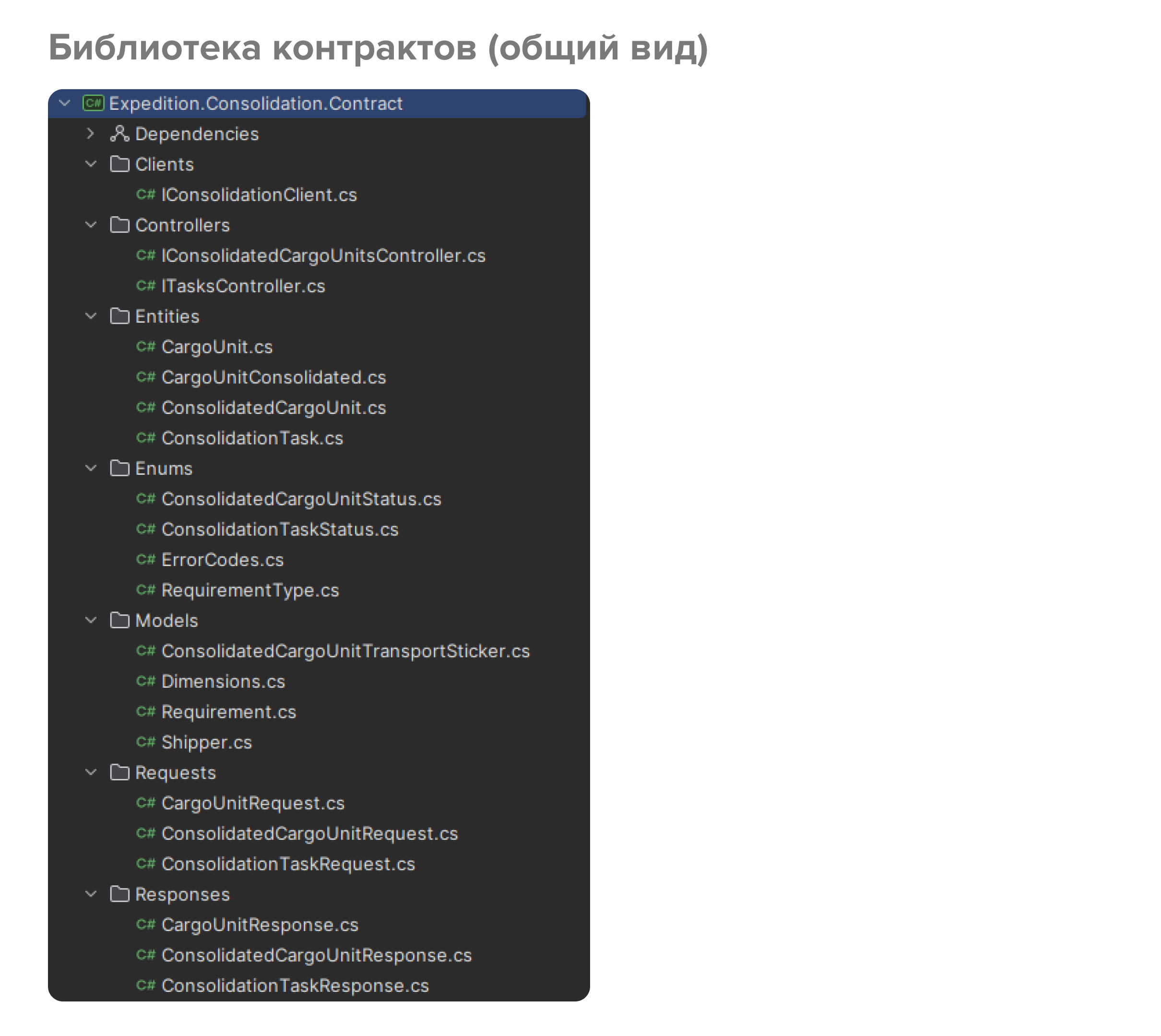
Вот так в итоге выглядит библиотека контрактов: один интерфейс клиента, несколько интерфейсов контроллеров, модели данных. Все это полностью основано на спецификации. По завершении разработки библиотеки контрактов мы публикуем nuget-пакет. Как только пакет опубликован, можно приступать к реализации непосредственно API, а также клиента к этому API. Поскольку спецификация уже утверждена, а библиотека контрактов опубликована, разработку API и клиента можно выполнять параллельно.
Разработка API
Вот так выглядит класс API-контроллера, в котором мы реализуем интерфейс контроллера с необходимой бизнес-логикой. Здесь стоит заметить, что используются ASP.NET атрибуты, и это один из недостатков подхода – приходится дублировать маршруты как в библиотеке контрактов, так и в самих контроллерах. Для простых случаев, когда это маршруты без ограничений (например, {id}/{sortingCenterId}), их можно вынести в константы и переиспользовать, но когда в маршруты закладываются ограничения (например, {id:int}/{sortingCenterId}),а т.к. семантика, заложенная в ASP.NET не поддерживается Refit’ом (и наоборот), то такие маршруты приходится дублировать.

Разработка клиента
Клиент для API реализуется с помощью библиотеки Refit. Мы написали следующий extension-метод для регистрации API-клиента. В этот метод передаем интерфейс клиента из библиотеки контрактов, а также конфигурационные аргументы, в результате чего в DI контейнере для этого интерфейса регистрируется динамически сгенерированный Refit-ом класс, содержащий вызовы HTTP-клиента.
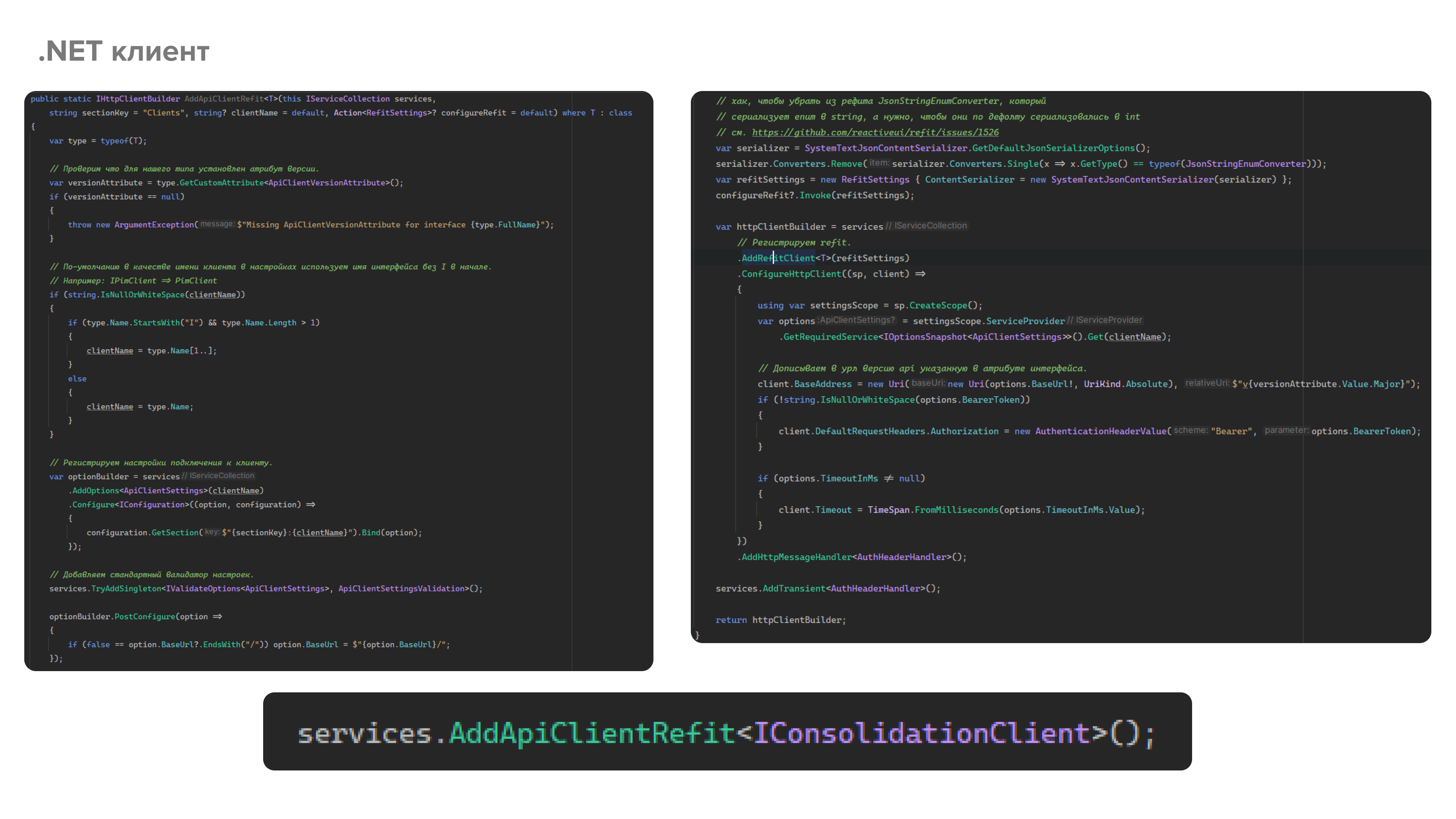
Соответственно, все что нам нужно сделать, это в одну строчку зарегистрировать интерфейс клиента из библиотеки контрактов. Дальше внедряем этот интерфейс с помощью DI в необходимые классы и обращаемся к внешним сервисам. Также, такой подход позволяет легко тестировать код, в котором имеются зависимости от API-клиента.
Асинхронное взаимодействие микросервисов
Асинхронное взаимодействие – это взаимодействие, при котором одна система отправляет сообщение другой и продолжает выполнять свою работу, не ожидая подтверждения или ответа. Ответ может быть получен позже через сообщения, или функции обратного вызова (callback). Этот тип взаимодействия является обычным, когда первой запрашивающей системе не требуется информация для того, чтобы продолжить выполнять какое-либо свое действие.
Асинхронная коммуникация микросервисов в нашем случае реализуется через Kafka (брокер сообщений). Здесь мы пишем спецификацию Async API. Это аналогичный стандарт как и OpenAPI, но для описания асинхронного протокола взаимодействия.
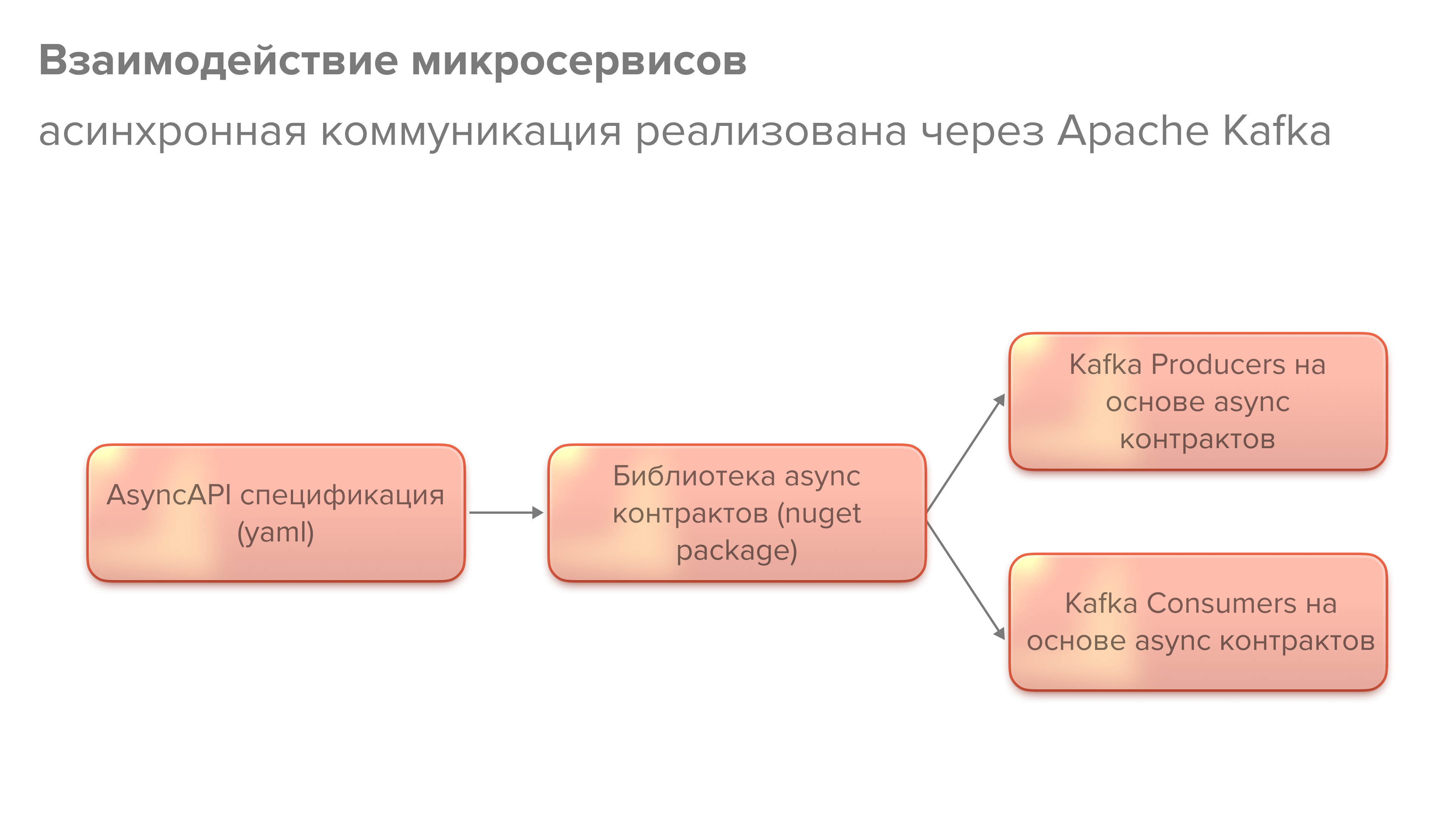
Принцип похожий. Описываем спецификацию, утверждаем, создаем библиотеку асинхронных контрактов, а дальше пишем producers, которые будут сообщения публиковать в очередь, и consumers, которые будут их читать и принимать в работу.
Спецификация немного другая — описываем не методы, а типы сообщений и каналы. В канал описываем типы сообщений, которые отправляются в соответствующие каналы.

Библиотека Async контрактов
Библиотека Async контрактов – nuget-пакет на основе спецификации. Внутри содержатся модели сообщений, которые отправляются или читаются в очередь или из нее.
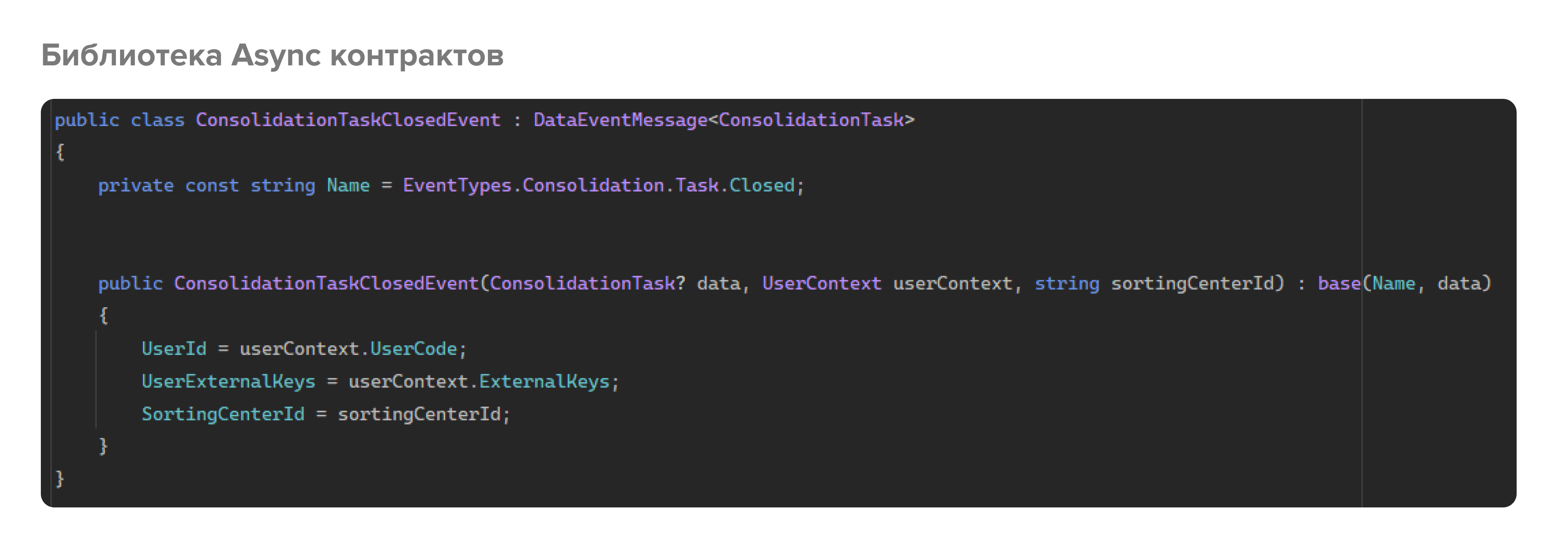
В нашем случае, все сообщения являются событиями. Событие хранит это обертка для какого-то объекта данных. Внутри события определяются необходимые параметры. Например, событие “Поставка создана” помимо информации о самом событии (идентификатор, тип, дата и время) будет содержать информацию о поставке. Получается вот такой процесс: создали библиотеку контрактов, накидали все события, которые предусмотрели спецификацией, и создаем продюсера, который будет генерировать события.
На скрине представлен кусок кода из бизнес-логики, который завершает выполнение таска. Начиная с 5 строки открывается транзакция, в рамках которой в БД микросервиса записываются данные, и дальше три строки отвечают за отправку сообщения в очередь.

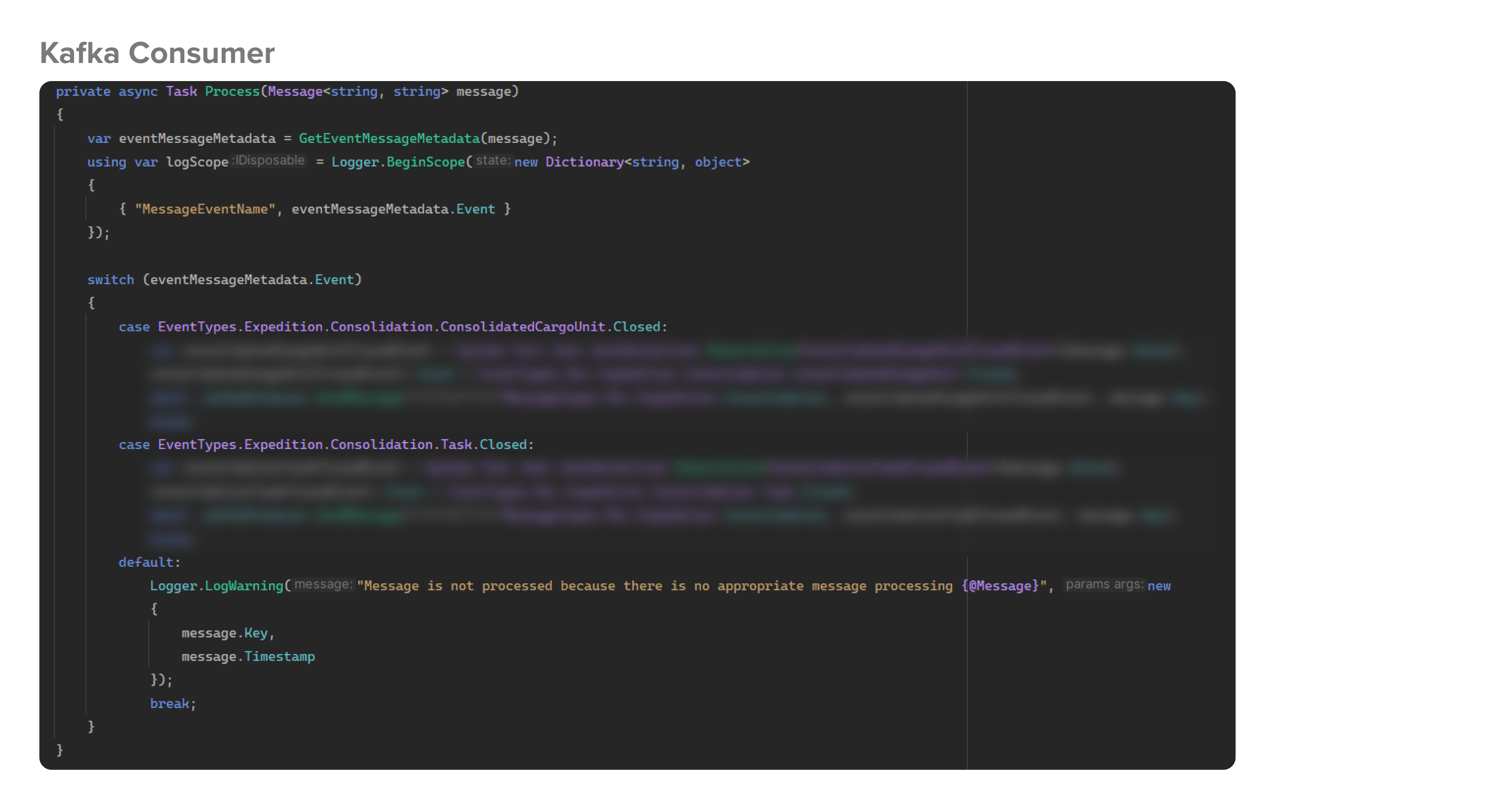
На скрине выше показан консьюмер. Это обработчик, в который приходят все сообщения: в нем есть фильтрация и обычно тут идет обработка бизнес-логики, которая должна срабатывать при получении сообщения.
При появлении нового микросервиса, подход уже отработан, и все процессы создания библиотеки контрактов и процесс работы с Kafka отлажен, поэтому все эффективно и нет разночтений в разработке, все единообразно.
Конечно, описанные в этой статье способы организации взаимодействия микросервисов – не единственно возможные. Например, еще есть gRPC, но это как говорится, уже другая история. Может, расскажем ее в другой статье на примере другого нашего проекта.
Комментарии (11)

nickname_322
15.03.2024 09:29+3Используете ли кодогенерацию, на основе разработанных спецификаций? Или пишете вручную?

artyomc Автор
15.03.2024 09:29Нет, на данном этапе всё пишется вручную, хотя идея с кодогенерацией хорошая

aftertherainbow
15.03.2024 09:29+1В чём сакральный смысл оборачивать код в роутах в одинаковые try {} catch { log.Ex(..) } вместо использования middlware?
Vitimbo
Вижу, что у вас в качестве ответа возвращается некоторый OperationResult<T>. Почему именно так, а не просто ActionResult/ActionResult<T>/IActionResult ?
artyomc Автор
Для стандартизации ответов от всех API по всем микросервисам - структура данных представляет собой, по сути, обертку над типизированным объектом данных T и bool флаг успешности выполнения операции
Vitimbo
То есть, вы не опираетесь на коды ответов сервера и он всегда, кроме аварий, должен ответить 200 и внутри будет успех и ответ/неудача? Вопрос был скорее в том, почему не опираетесь на коды ответа. В чем предпочтение?
artyomc Автор
Да, подход избрали в целом такой, чтобы в одном месте иметь всю информацию для принятия решения о результате операции и о самой операции. Коды ответа пришлось бы на уровне работы с HttpClient обрабатывать, и зависимости от успеха/фейла возвращать данные ответа дальше, а тут мы можем вернуть OperationResult сразу и в одном месте его обработать.
dopusteam
Вам же все равно коды обрабатывать нужно, никто не защитит от 500, 404, ...
grisha0088
Если успех ответа не определяется кодом ответа, то это не REST API.
VanKrock
А это и не совсем REST API, это по сути надстройка над ним, например как JsonRpc. Преимущество такого подхода в том, что разделяется обработка инфраструктурных ошибок и ошибок бизнес-логики, инфраструктурные ошибки обрабатываются по статус кодам, 404, 500 и т. д. эти ошибки как правило стандартные и обработку их можно вынести в middleware, а вот ошибки валидации, ошибки выполнения бизнес операций и т. д. всегда возвращают статус код 200, но при этом имеют свой формат, свой набор статусов, который намного шире http статусов