

Уверен, небольшие pet-проекты полезны не только для прокачивания навыков, но и для отвлечения от рабочей рутины и - нередко - для решения небольших практических задач.
Курс рубля, как водится, - всегда актуальная тема. И на естественное желание быть в курсе курса рубля, лично у меня, возникает такое же естественное желание реализовать pet-проект. И естественно, это нужно сделать в виде телеграм-бота.
Здесь вы можете посмотреть пример моего бота. Почти такой же вы можете запустить и сами, пользуясь исходниками. Именно с этим и поможет данная статья.
Про использование Python понятно из сабжа, ну а добиться максимально быстрого запуска нам позволят встроенные CI/CD процессы от Amvera, которые буквально из кода соберут работающий сервис.
Функциональность и архитектура бота
Количество строк кода вышло внушительным, так что не будем разбирать их детально в статье. Тем не менее, для понимания заложенной функциональности, опишу в данном разделе как бот проектировался.
Чтобы все выглядело чисто и SOLID’но, естественно нужно начать с проектирования решения.
Забегая вперед, получилось не так SOLID’но, как хотелось бы - расценивайте это как возможность похоливарить и предложить схему получше.
Вот что я накидал в draw.io думая о боте и пытаясь решить о возможных расширениях функциональности в дальнейшем:

Основные используемые библиотеки:
PTB (Python Telegram Bot)
APS (Advanced Python Scheduler) - на самом деле в рамках python-telegram-bot[job-queue]
Что можно сразу заметить: на схеме нет инфраструктурных компонентов. “А как же PostrgreSQL?”, справедливо спросите вы. В нашем случае PostgreSQL нужен для хранения джобов на расписании - а это реализуется в рамках упомянутого выше APS, внутри которого эти слои и имплементированы.
Итак, что же может делать бот:
-
Конвертировать заданную сумму и валюту в рубли
Курс на основе официального курса ЦБ РФ
Простейшие математические операции (сложение, вычитание, умножение и деление)
-
Подписаться на регулярные уведомления по запрошенной конвертации
И, конечно, отписаться от этих уведомлений
Кажется, достаточно для минимально необходимой пользы: и друзей не стыдно пригласить пользоваться своим ботом.
Если не нужны регулярные уведомления
Если хочется запустить бот, но без уведомлений и (как следствие) без использования PostgreSQL, то - как водится в SOLID'ной архитектуре - можно буквально в одной строке это скорректировать:
#вместо:
subscriber = PTBScheduler()
#сделать:
subscriber = NoneНу а теперь переходим к самому интересному - развертыванию бота.
Развертывание бота в Amvera Cloud
Как упомянуто в начале статьи, для развертывания будем использовать сервис Amvera Cloud, который избавит от оверхеда, связанного с деплоем приложений.
1. Пререквизиты
Перед стартом проверьте пререквизиты:
У вас есть аккаунт в Amvera Cloud
-
На вашей машине установлен Git
Если нет - можете воспользоваться официальной инструкцией
Предполагаются базовые знания и навыки в следующих топиках:
Git
Docker
Python
2. Предварительная подготовка
Выделены следующие этапы подготовки:
Создание бота в ТГ (через BotFather)
Запуск и проверка PostgreSQL
Итак, поехали.
2.1. Создание бота в ТГ
Достаточно стандартный набор шагов - можно воспользоваться буквально первым попавшимся туториалом из гугла яндекса, например таким или таким.
В коде предусмотрена возможность работы в inline-режиме, но его нужно активировать с помощью того же BotFather. Для этого:
1. Выберите своего бота из списка в BotFather
2. Нажмите ‘Bot Settings’:

3. Нажмите ‘Inline Mode’:

4. По умолчанию, режим выключен, для его включения необходимо воспользоваться верхней кнопкой:

Там же можно настроить placeholder - то что будет отображаться в inline-режиме, например:

2.2. Запуск и проверка PostgreSQL
Полноценное описание о запуске PostgreSQL в Amvera есть в соответствующем детальном гайде.
Достаточно просто настраивается запуск самой БД:

А уже в отдельном проекте - pgAdmin - можно к ней подключиться:
1. Создать новый сервер:

2. Ввести данные БД для подключения:

Помните, что адрес подключения (хост) можно найти в настройках проекта с PostgreSQL:

После успешного подключения в интерфейсе будет видна БД:

3. Развертывание бота
Для развертывания бота мы пройдем следующие шаги:
Скачать репозиторий с кодом
Создать проект в Amvera
-
Загрузить исходники в Amvera
Загрузка через Git (рекомендуемый способ)
Загрузка файлов на сайте
Проверка бота
Итак, поехали.
3.1. Скачать репозиторий с кодом
Доступны 2 варианта:
С использованием командной строки
Без использования командной строки
Рекомендуется конечно же первый вариант.
3.1.1. С использование командной строки
Я подразумеваю, что вы воспользовались инструкцией для установки Git, которую я упоминал ранее. В этом случае использование командной строки (а нам нужна только утиллита Git) будет выглядеть одинаково для всех платформ (Linux-Windows-MacOS).
1. Открываем командную строку:

2. Я предварительно создал папку bot, в которой и будет размещен код. Создайте и перейдите в нужную вам папку:
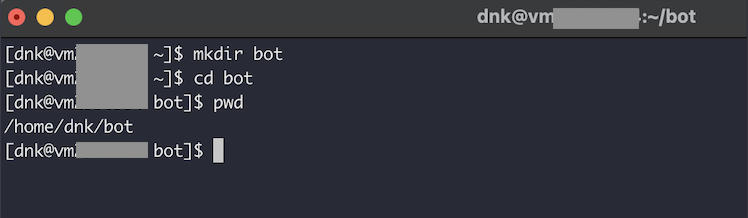
mkdir bot
cd bot
pwd3. Скопируйте ссылку на репозиторий и выполните загрузку:

Поздравляю, вы великолепны :)
3.1.2. Без использования командной строки
Без командной строки все выполняется не менее просто:
1. Создайте папку, в которой будет располагаться код
2. В браузере перейдите по ссылке на репозиторий
3. Скачайте архив с кодом:

4. Распакуйте архив в созданную на шаге 1 папку
Поздравляю, вы великолепны :)
3.2. Создать проект в Amvera
Ниже пошаговый гайд по созданию проекта:
1. Залогиньтесь в Amvera и перейдите на вкладку проектов
2. Нажмите “Создать”:

3. Заполняем общую информацию и нажимаем “Далее”:

Название - можно выбрать любое какое нравится.
Тип сервиса - приложение.
Тарифный план - самый минимальный подойдет для целей такого бота. Что удобно в Amvera - в дальнейшем можно будет расширить мощности буквально в пару кликов.
4. Шаг с загрузкой данных пропустим, просто нажав “Далее” - его можно выполнить позднее:

5. Задаем настройки конфигурации (по сути - конфигурации сборки проекта) и скачиваем amvera.yml:


Отмечу, что в репозитории с исходным кодом уже есть Dockerfile, который создает позволяет создать необходимый Docker-образ.
Выбираем:
Окружение:
dockerИнструмент:
dockerDockerfile:
Dockerfile(название файла в репозитории с кодом)persistenceMount:
/app/data
Про persistenceMount расскажу чуть подробнее несколько позже.
Окружения Amvera
У Amvera есть широкий список окружений:

Для каждого окружения есть свой инструмент, с помощью которого будет производиться сборка образа.
В случае с Python доступен де-факто стандарт: pip.
У вас может возникнуть справедливый вопрос: “почему же окружение выбрано Docker, а не Python”. На самом деле можно выбрать и Python: для этого только потребуется предварительно создать список используемых библиотек - командой:
pip freeze > requirements.txtВ моем случае использование Docker имеет с одной стороны наследственный характер (раньше не было таких сервисов как Amvera, и все равно приходилось писать Dockerfile самому), с другой - бОльший контроль над созданием образа. Это позволяет производить более тонкую настройку, и встраивать другие процессы - например, регулярную проверку образов на уязвимости (к примеру, с помощью snyk и подобных сервисов).
И последнее что важно отметить в блоке с Docker: можно использовать и уже построенный образ, размещенный на публично доступном ресурсе (тот же dockerhub).
И отдельно отмечу варианты с db:

Таким образом, установить можно далеко не только PostgreSQL, но и кучу других БД.
Безусловно не стоит забывать про вариант с Docker - там полная свобода: можно использоваться абсолютно любой публично доступный образ.
Нажимаем “Завершить” для создания проекта
6. В созданном проекте переходим на “Переменные”, предварительно определившись с их наполнением:
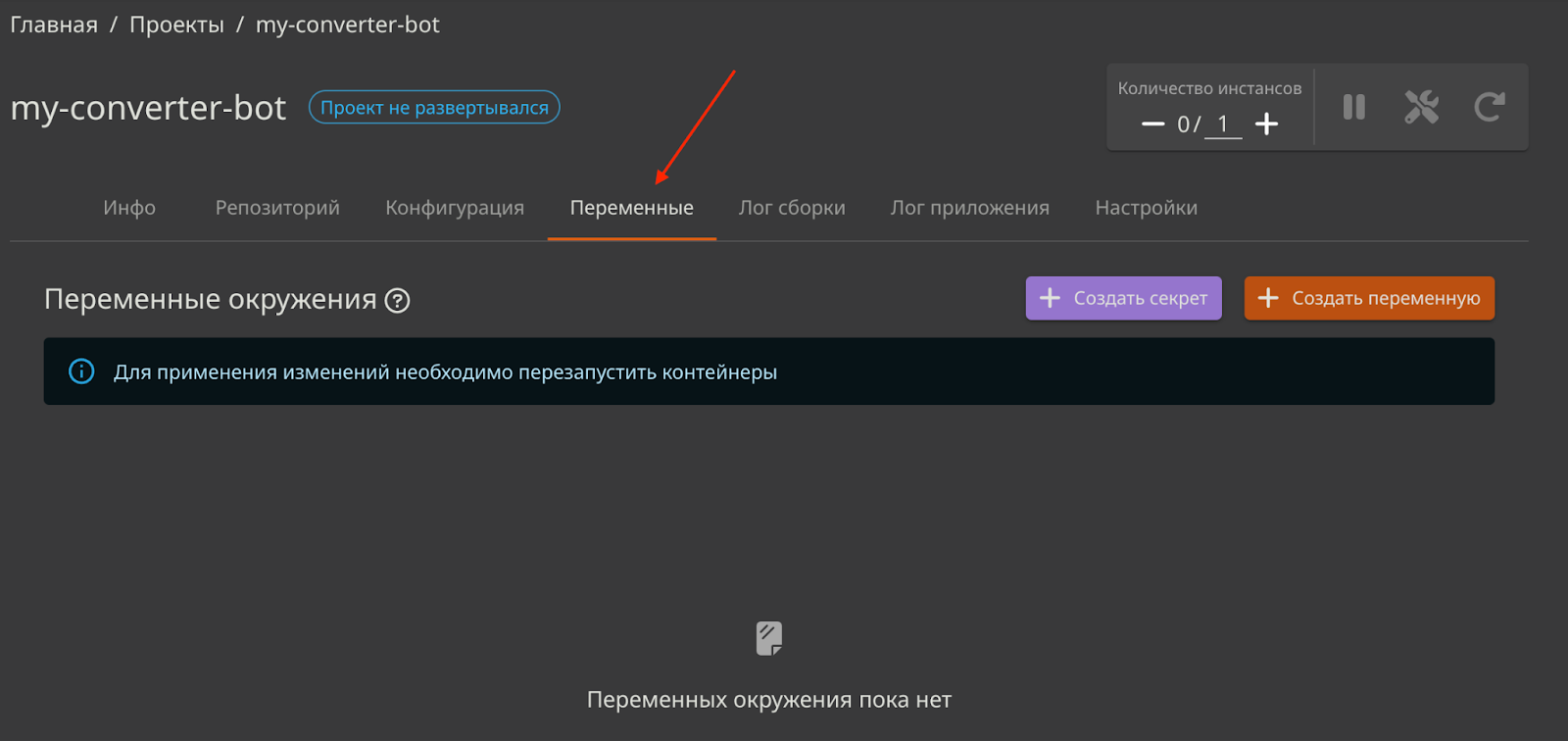
Это специальный раздел, в котором задаются переменные окружения - по сути, конфигурационные параметры. В данном исходном коде предусмотрены следующие параметры:
-
Относящиеся к боту:
BOTNAME- название бота, заданное в BotFatherTOKEN- токен, выданный ранее BotFatherSTART_MESSAGE- сообщение, которое будет выведено при вводе команды /startHELP_MESSAGE- сообщение, которое будет выведено при вводе команды /helpPERSISTENCE_FILE- путь до файла, в котором будут сохраняться промежуточные объекты для inline-клавиатуры
-
Относящиеся к расписанию:
JOB_PERSISTENCE- флаг (1 или 0), подключаем ли базу данных для хранения джобовPSQL_URL- строка подключения к базе данных
-
Относящиеся к логике разбора запросов пользователей:
REGEXP- регулярка, которая позволяет проверить корректность введенного выражения (особенно актуально, если там есть вычисления)
-
Относящиеся к парсеру источника курса валют:
URL- адрес, из которого можно забрать актуальные данные по курсу валютTIMEOUT- таймаут ожидания ответа при запросе по указанному URL (на случай неполадок в сети)
Разберем некоторые из них детальнее:
PERSISTENCE_FILE
В боте используются inline-клавиатуры, например:

Для корректной обработки нажатия в каждой кнопке необходимо передать контекст:
Какое действие будет произведено (подписка или отписка)
Если подписка - то на какое выражение (в данном примере: 1 EUR)
Если подписка - то какой тип (каждый день / каждую неделю / каждый месяц)
Этот контекст хранится в Python dict-структуре, которая сериализуется в файл. И переменная PERSISTENCE_FILE как раз указывает путь до этого файла. Если не сохранять состояние в файл, то при перезагрузке бота весь контекст по всем кнопкам потеряется.
Необходимо задать значение: data/callback_persistence.pickle
Контейнеры
Немного из базовой части Docker: важно помнить, что наше приложение запускается в виде контейнера (из образа), который существует пока приложение работает. Перезагрузка приложения = удаление контейнера и создание нового, то есть “откат” к состоянию в образе. Способы сохранения какого-либо состояния следующие:
С помощью примонтированных persistence-областей (тот самый persistenceMount),
С помощью внешних систем, выступающих в качестве Persistence Storage: например, тот же PostgreSQL.
Наличие PERSISTENCE_FILE напрямую связано с persistenceMount, который упоминался выше в конфигурации.
А теперь следите за руками:
1. В конфигурации проекта Amvera мы указали: /app/data
Это означает, что папка
/app/dataявляется примонтированной, и данные хранящиеся в ней не будут стираться вне зависимости от рестарта приложения
2. В Dockerfile в репозитории с кодом указано: WORKDIR /app
Это означает, что все команды в файловой системе (в том числе навигация из Python) производится относительно этой стартовой точки (директория /app)

3. Значение переменной окружения PERSISTENCE_FILE мы указываем: data/callback_persistence.pickle
Чтобы получить полный путь, нужно добавить стартовую точку, то есть получится:
/app/data/callback_persistence.pickleТаким образом, файл находится внутри примонтированной области, а значит он будет сохранен между рестартами приложения
JOB_PERSISTENCE
Числовой флаг (1 или 0), регулирующий хранение джобов уведомлений. Если стоит 0, то все хранится только в памяти, и между перезапусками бота весь контекст теряется.
Если возможность потерять все джобы на расписании допустима, то можно смело оставлять 0. Важное следствие: PostgreSQL в этом случае не будет использоваться.
PSQL_URL
В боте для подключения к базе данных используется SQL Alchemy - возможно, самый распространенный инструмент работы с БД из Python.
Строка подключения к PostgreSQL в этом случае должна выглядеть в следующем формате:
postgresql://<user>:<password>@<db_host>[:<db_port>]/<dbname>
Вспоминаем все настройки, которые задавали при подключении к БД из pgAdmin:
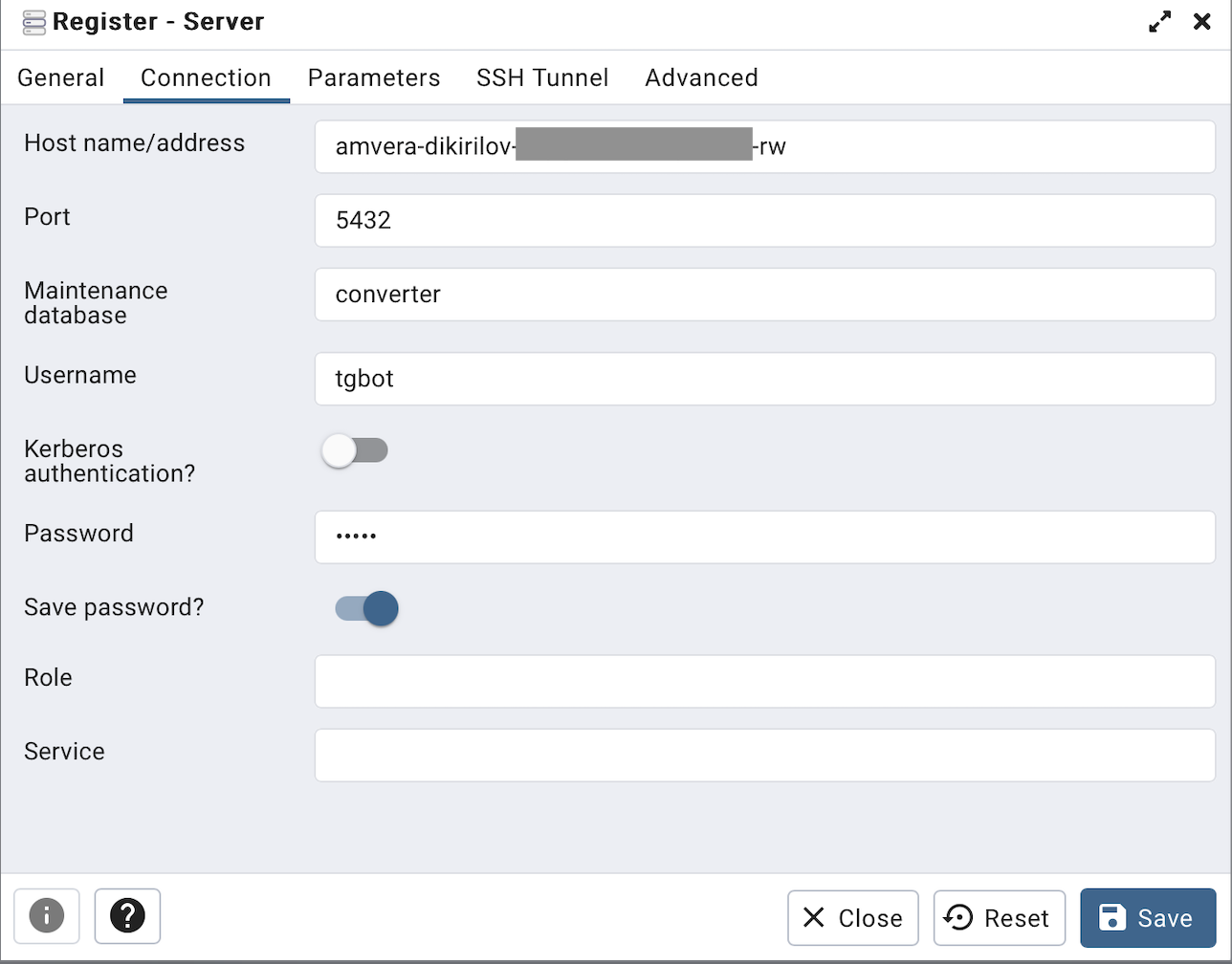
В моем случае получается так:
postgresql://tgbot:***@amvera-dikirilov-***-rw/converter
Вместо *** конечно же должны быть пароль и полный хост соответственно.
REGEXP
Это регулярное выражение призвано проверять, является ли первая часть запроса математически корректным выражением.
На текущем этапе мне не хотелось в рамках pet-проекта заниматься полноценной реализацией польской записи, поэтому было использовано простое (но привносящее уязвимости) решение: функция eval. Для минимизации уязвимости и в целом проверки, что оно сработает (если выражение неверное - Exception), нужна эта регулярка.
Даже с проверкой регуляркой я не рекомендую использовать eval() в продуктивных решениях.
Для проверки использую следующее выражение: ^([-+/]?\d+(.\d+)?)$
URL
Бот умеет парсить XML, которая любезно предоставляется ЦБ по следующему адресу:
http://www.cbr.ru/scripts/XML_daily.asp
TIMEOUT
Этот параметр скорее для возможности тюнинга в случае нетривиального доступа в сеть, но в случае с Amvera каких-либо проблем не замечено.
Я обычно выставляю значение 5 - уж точно не упремся при выгрузке ~100+ курсов валют.
7. Вносим переменные в проект
Теперь все эти переменные необходимо занести в проект в Amvera. В первый раз это немного нудно, зато в дальнейшем позволит изменять ключевые точки в приложении без необходимости изменения кода и пересборки образа (потребуется только рестарт).
В переменные окружения попадают как переменные, так и секреты:

С точки зрения приложения разницы между ними нет.
С точки зрения хранения и видимости - разница есть.
Правило очень простое: любая чувствительная информация должна быть секретом: пароли, токены, etc.
По итогу должно получиться примерно так (список конечно же прокручивается, просто только это умещается в окне 13-дюймового устройства):

3.3. Загрузка и запуск бота
Для загрузки кода в Amvera можно воспользоваться как Git, так и загрузкой непосредственно на сайте.
Рекомендуется, конечно же, вариант 1 - с него и начнем.
3.3.1. Загрузка через Git
Ранее мы уже загрузили репозиторий к себе:

Далее пошаговый гайд:
1. Подключить Amvera репозиторий как удаленный. Команду для этого можно найти на вкладке “Репозиторий” в проекте. В моем случае это выглядит так:

Обратите внимание, что в репозитории должен был появиться amvera.yml.
В командной строке:

В процессе скорее всего потребуются логин и пароль от аккаунта Amvera.
2. Выполнить merge веток в своем репозитории, для этого необходимо выполнить команды:
git pull amvera masterВ процессе откроется редактор, в котором нужно будет заполнить сообщение для коммита с мерджем. Скорее всего это будет vi(m). Меня устраивает дефолтное сообщение, поэтому просто выхожу с сохранением (набрав :wq):

Работа в редакторе vi(m) - это отдельная тема (в том числе, для шуток и мемов). Для быстрого ознакомления с минимально необходимым можно посмотреть сюда.
Мой фаворит среди мемов

Если знаете еще более "цепляющие" - кидайте в комменты
После этого произойдет мердж файлов из репозитория Amvera в наш репозиторий:

Как мы видели, кроме файла конфигурации Amvera.yml там ничего нет (папка .git есть во всех репозиториях, там служебная информация) - только этот файл и загрузился.
Возможная ошибка
Сразу стоит отметить, что если вы не настраивали Git на своей машине (как я не делал этого на удаленном сервере), то скорее всего вы получите такую ошибку:

Благо, здесь сразу представлена инструкция, что с этим делать: задать почту и имя пользователя Git с помощью команд:
git config --global user.email “you@example.com”
git config --global user.name “Your Name”Можно и без global, если эти параметры хотите задать только для этого репозитория.
3. Загрузка исходников в Amvera
А теперь мы перешли к финальному шагу, который не просто загрузит файлы в Amvera, но и запустит процесс сборки.
По сути нам нужно просто актуализировать репозиторий в Amvera, что делается одной командой:
git push remote amvera master
После выполнения команды на вкладке “Репозиторий” проекта можно увидеть новые файлы, а также автоматически запустившуюся сборку по факту коммита:

Проверим, что сборка успешна:

Последние логи (“Pushing image…” и “Pushed…”) говорят о том, что образ успешно сформирован и загружен во внутреннее хранилище образов. Далее проект автоматически запускается - на дальнейших шагах проверим, что работает сам бот.
3.3.2. Загрузка файлов на сайте
Альтернативный способ загрузки - прямо в браузере. Для этого необходимо зайти в проект на вкладку “Репозиторий” и нажимаем “Загрузить данные”:

Поскольку amvera.yml уже есть в репозитории Amvera, а при загрузке мы только добавляем файлы, а не синхронизируем как в случае с git, нам не нужно предварительно скачивать этот файл.
Появится окно, куда необходимо перенести все файлы из репозитория:

При загрузке файлов не нужно выбирать .git* папки и файлы, то есть:

Нажимаем “Готово”:

Если сборка не началась автоматически, переходим на вкладку “Конфигурация”, листаем вниз и нажимаем “Собрать”:

Проверим, что сборка успешна:

Последние логи (“Pushing image…” и “Pushed…”) говорят о том, что образ успешно сформирован и загружен во внутреннее хранилище образов. Далее проект автоматически запускается - на дальнейших шагах проверим, что работает сам бот.
3.4. Проверка бота
Для начала убедимся, что бот успешно запустился. На вкладке “Лог приложения” должны появиться строки примерно как тут:

После “Start polling” лога можно непосредственно тестировать бот:

А также в inline-режиме:


Из примечательного: как только появятся сообщения с inline-клавиатурой, в разделе с data появится наш файл, который хранит состояние с контекстом кнопок:

Помимо этого надо проверить, что и подключение к БД произошло успешно.
Для этого зайдем в pgAdmin и проверим, что появилась таблица apscheduler_jobs:

Теперь бот можно перезагружать / обновлять сколько угодно - данные о подписках не потеряются.
Вместо заключения
Часть с описанием развертывания бота может показаться достаточно длинной, но это только потому что хотелось покрыть все возможные вопросы.
Прелесть CI/CD-процесса, любезно предоставляемого Amvera, раскрывается в дальнейшей работе: сопровождении и доработках проекта. Как только изменение готово, одной командой (git push amvera master) можно сразу все раскатить и пользоваться.
One more thing
Кстати, удобно сделать как минимум 2 бота (для TEST и PROD), которые будут соответствовать 2-м разным проектам в Amvera. Оба проекта можно подключить к одному и тому же репозиторию под разными именами (например, amvera-test и amvera-prod).
Тогда для обновления тестовой версии будет достаточно выполнить команду:
git push amvera-test masterА когда все проверили - раскатить изменения на основной:
git push amvera-prod masterНо это конечно только для самых любимых pet-проектов :)
P.S. Если решите развернуть бота по этому туториалу, и по ходу дела возникнут вопросы - welcome в комменты или в личку.
kirillkosolapov
А почему PostgreSQL, а не SQLite? Кажется, с SQLite не нужно создавать отдельного проекта - будет дешевле
dikirilov Автор
Отличный вопрос!
Не скажу, что сильно долго думал на эту тему, но сходу вижу следующие причины:
SQLite поднимается локально внутри того же инстанса, в рамках которого будет работать Python. Таким образом, при рестарте мы будем терять состояния
Чтобы не терять состояния можно пробовать настроить сохранение в файлы - и даже положить их в persistenceMount в Amvera, но в контексте pet-проекта не хотелось дополнительно с этим заморачиваться
Лично для меня PostgreSQL куда более знакомый и понятный инструмент