

Привет, Хабр! Меня зовут Максим, я работаю тестировщиком оборудования в Selectel Lab. В лаборатории мы занимаемся тестированием нового оборудования для дата-центров. О том, как мы измеряли производительность PostgreSQL на разных конфигурациях — под катом!
В предыдущей статье я приводил сравнение производительности железа (конфигураций серверов Selectel) в разных БД. Теперь мы пошли дальше, решив углубиться в тестирование на разных аппаратных платформах, а также доработав существующие тесты.
Как и раньше, одной из ключевых целей исследования является предоставление полезных данных, благодаря которым вы сможете подобрать конфигурации под различные БД. Еще одно применение результатов — улучшение внутренних процессов Selectel, например, в сфере облачных баз данных.
Результаты исследований уже помогают нашим клиентам выбрать готовое оборудование, подходящее под нагрузки их сервиса.
Используйте навигацию, если не хотите читать текст полностью:
→ Конфигурации серверов
→ Подготовка к тестированию
→ Автоматизация теста pgbench
→ Парсинг результатов в Google-таблицу
→ Результаты тестирования
→ Заключение
Конфигурации серверов
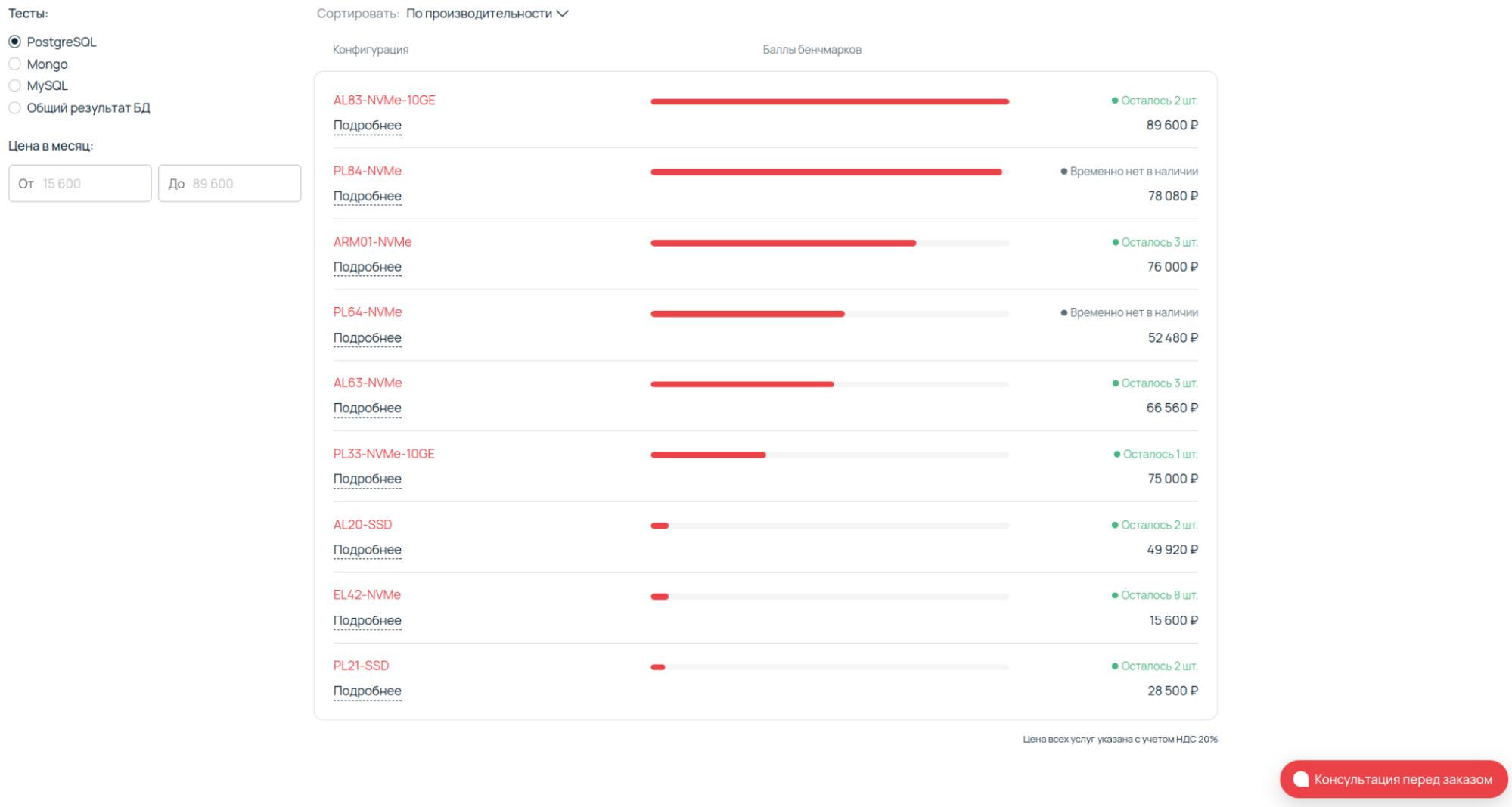
Список выбранных конфигураций почти не отличается от предыдущего тестирования, но в этот раз в сравнении не участвуют кастомные решения. Были выбраны наиболее популярные выделенные серверы Selectel. Так как в сравнительной таблице присутствует ARM-платформа с большим количеством ядер и потоков, остальные платформы были выбраны с максимальным приближением к этим показателям.
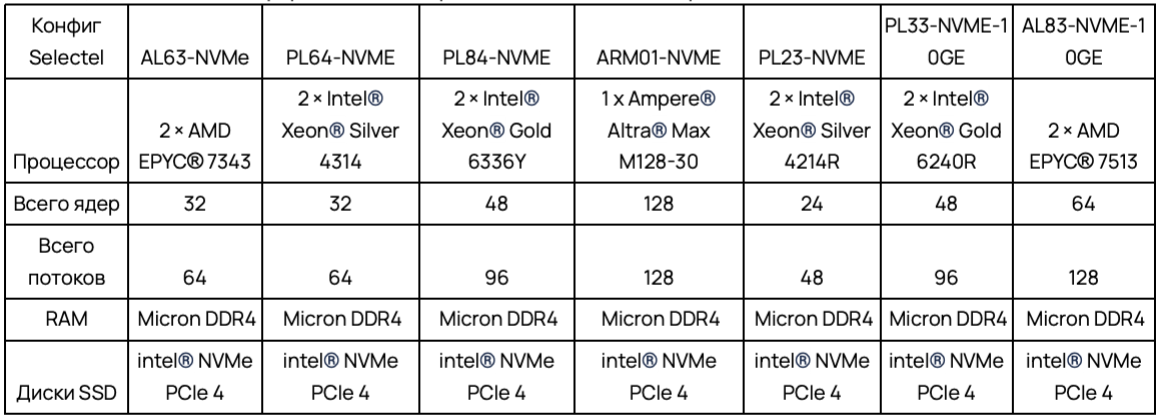
Исходя из предыдущих результатов тестирования, нашим фаворитом является ARM01-NVME с одним сокетом. За свою стоимость он составляет отличную конкуренцию двухсокетным системам.
Отмечу, что у участников сравнения используется RAM DDR4 одного производителя, а также одинаковые SSD-диски с поддержкой NVMe и PCIe Gen 4.
Все рассматриваемые серверы — фиксированной конфигурации. Это означает, что их можно использовать в рабочих задачах уже через несколько минут после аренды. Собрать любое решение, в том числе кастомное, можно в конфигураторе выделенных серверов.

Подготовка к тестированию
Выбор ОС и версии PostgreSQL
Операционную систему установили на SSD-диски. Использовали Ubuntu 22.04 LTS.
Причина выбора PostgreSQL проста — это одна из самых популярных БД среди наших пользователей. Напомню, что в предыдущем тесте мы использовали PostgreSQL 14:
PostgreSQL взял самую свежую — 14 версию. Выбрал ее из-за повышенной производительности. В ряде тестов она показала двукратный рост в сравнении с 12 версией БД.
В этот раз мы будем сравнивать Postgres Pro Enterprise 15-16 и PostgreSQL 15-16.
Настройка BIOS
BIOS и ОС настроены в performance режиме. Рассмотрим ключевые настройки BIOS, которые могут влиять на максимальную производительность сервера. Далее я покажу наиболее распространенные настройки для платформ на базе процессоров Intel®, AMD® и Ampere®.
Intel®
Включаем Hyper-Threading
Благодаря технологии Intel® Hyper-Threading, каждое ядро процессора может выполнять сразу два потока. Это позволяет увеличить количество одновременно обрабатываемых задач и повысить эффективность использования ресурсов процессора.
Включение Hyper-Threading может значительно улучшить производительность в многопоточных приложениях и средах, где в один момент времени выполняется множество задач. Например, в серверах виртуализации.
Включаем Turbo Boost
Если условия теплового пакета и энергопотребления позволяют, то Intel® Turbo Boost Technology динамически повышает частоту работы ядер процессора выше базовой.
Включение настройки может значительно улучшить производительность для кратковременных высоконагруженных задач. При этом будет обеспечено эффективное энергопотребление в периоды простоя.
Включаем Power Management (C-States, P-States) на P0 и С0
C-States позволяют процессору переходить в состояние пониженного энергопотребления при простое. P-States регулируют производительность процессора, изменяя его частоту и напряжение в зависимости от текущей нагрузки.
Правильная конфигурация состояний поможет достичь оптимального баланса между производительностью и энергоэффективностью. Особенно это актуально для сред с переменной нагрузкой.
В Memory Configuration включаем максимальную частоту и используем двухканальный режим
Таким образом мы открываем доступ к таким настройкам, как выбор режима работы памяти (single, dual, channel и т. д.) и ручной конфигурации времени ее задержки.
Оптимизация настроек может значительно улучшить пропускную способность и скорость доступа к памяти, что критически важно для производительности вычислительных систем.
AMD®
Включаем SMT (Simultaneous Multithreading)
Аналогично Intel® Hyper-Threading, SMT® увеличивает количество потоков, которое может обрабатывать каждое ядро. Таким образом улучшается общая производительность системы в многопоточных приложениях.
Включаем Core Performance Boost
Технология AMD® Core Performance Boost аналогична Intel® Turbo Boost. Она позволяет процессорам повышать свою частоту выше базовой в зависимости от условий тепловыделения и энергопотребления.
Включение настройки обеспечивает дополнительную производительность для задач, требующих высокой вычислительной мощности. При этом поддерживается энергоэффективность в менее интенсивных режимах.
Отключаем Power Management (Cool'n'Quiet, Global C-state Control)
Настройки помогают управлять энергопотреблением процессора, регулируя его частоту и напряжение в зависимости от текущей нагрузки.
Оптимизация Power Management обеспечивает баланс между производительностью и энергоэффективностью, снижая энергопотребление в периоды низкой нагрузки.
Включаем Memory Interleaving
Настройка позволяет оптимизировать доступ к памяти, распределяя обращения к данным по ее различным каналам.
Включение Memory Interleaving может значительно улучшить пропускную способность и время доступа к памяти. Особенно важно для приложений, интенсивно использующих память.
Ampere® (серверные ARM-процессоры)
В Frequency Scaling включаем max_perfomance
Настройка позволяет динамически изменять частоту процессора в зависимости от текущей рабочей нагрузки, оптимизируя тем самым энергопотребление и производительность.
Это обеспечивает баланс между необходимой вычислительной мощностью и энергоэффективностью (благодаря адаптации к изменениям в рабочей нагрузке).
В Memory Configuration включаем максимальную частоту памяти
Открывает доступ к настройкам таймингов и конфигурациям памяти, направленным на оптимизацию ее скорости и пропускной способности.
Отмечу, что правильная настройка памяти критически важна для обеспечения высокой производительности системы. Особенно актуально для задач с интенсивным использованием памяти.
Отключаем Energy Efficiency Modes
Настройки режимов энергоэффективности позволяют выбирать оптимальный баланс между производительностью и потреблением энергии.
Адаптация к различным рабочим условиям позволяет максимизировать производительность при минимальном энергопотреблении. Особенно важно для долгосрочной работы серверов.
Общие настройки для всех платформ
Memory Timing. Настройка таймингов памяти влияет на скорость обработки данных. Установка меньших значений задержек (CAS Latency, tRCD, tRP, tRAS) может повысить производительность.
NUMA (Non-Uniform Memory Access) Configuration. Настройка использования памяти в мультипроцессорных системах может существенно повысить производительность приложений, чувствительных к задержкам доступа к памяти.
Специфические настройки для Intel®
SpeedStep/EIST (Enhanced Intel SpeedStep® Technology). Технология, позволяющая изменять частоту процессора в зависимости от нагрузки. Необходима для оптимизации потребления энергии и производительности.
Intel® UPI Link Configuration. Настройка скорости взаимодействия CPU между собой по протоколу Intel® Ultra Path Interconnect, соединяющего процессоры в многосокетных системах. Влияет на производительность системы и памяти.
Специфические настройки для AMD®
Memory Access Mode. Настройка режима доступа к памяти (Distributed или Local). Используется для оптимизации производительности под характер рабочей нагрузки.
Специфические настройки для Ampere®
Core Frequency Scaling. Динамическая настройка частоты ядер в зависимости от нагрузки. С ее помощью возможно получить баланс между производительностью и энергопотреблением.
Configurable TDP (Thermal Design Power). Настройка максимальной мощности, которую может потреблять процессор. Позволяет управлять балансом между производительностью и тепловым режимом.
При настройке BIOS важно помнить о возможном влиянии на стабильность и надежность системы. Рекомендуется провести тестирование после применения изменений.
Настройка ОС
В ОС отключаем политики энергосбережения и включаем режим perfomance. Напомню, что мы используем Ubuntu 22.04.
echo performance | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governorВ тестах используем максимальную рабочую частоту процессоров и памяти. Охлаждение тоже устанавливается на максимум. В двухсокетных системах NUMA настроена на равномерное распределение памяти между CPU.
Устанавливаем количество подключений (MAX connection) и адреса расположения БД. В нашем случае тесты проводятся локально, чтобы исключить дополнительные точки отказа и сетевые задержки. Остальные настройки БД оставляем по умолчанию.
Стандартные настройки PostgreSQL используем по причине того, что мы не знаем профиль нагрузки пользователя на систему и нам нужна точка отсчета производительности.
Выбор режима тестирования
Используем встроенный бенчмарк pgbench, предназначенный для запуска тестов на PostgreSQL. Он выполняет одну и ту же последовательность SQL-команд, а затем вычисляет среднюю скорость транзакций (количество транзакций в секунду, TPS).
По умолчанию pgbench тестирует сценарий, основанный на TPC-B. Он включает пять команд SELECT, UPDATE и INSERT для каждой транзакции. Мы использовали метод по умолчанию и модификации теста.
Выбрали ключи (режимы) тестирования:
- pgbench –– (смешаные запросы),
- pgbench –S –T (SELECT ONLY),
- pgbench –N –T (UPDATE).
Автоматизация теста pgbench
Уже в процессе проведения первых тестов стало понятно, что делать это вручную будет долго и тяжело. Вдобавок, при получении первых результатов была обнаружена погрешность, обусловленная работой железа.
Для исключения погрешности было решено проводить тест три раза подряд с подсчетом средних значений. Ниже приведена смысловая часть кода.
CORES=$((CPU_THREADS))
HOST="127.0.0.1"
TIME="600"
# Создаем базу данных генерим таблицы
pgbench --username=root -h "${HOST}" test -i -s 10000
# Считаем кол-во потоков и подключенных пользователей
THREADS=(1 2 $(echo "scale=0; $CORES * 20 / 100" | bc -l) \
$(echo "scale=0; $CORES * 40 / 100" | bc -l) \
$(echo "scale=0; $CORES * 60 / 100" | bc -l) \
$(echo "scale=0; $CORES * 80 / 100" | bc -l) \
$(echo "scale=0; $CORES * 99.9 / 100" | bc -l))
echo "pgbench --username=root -h ${HOST} test ${PARAM} -T ${TIME}" >> "${FILE}"
pgbench --username=root -h "${HOST}" test ${PARAM} -T "${TIME}" >> "${FILE}"
echo "pgbench --username=root -h ${HOST} test ${PARAM} -S -T ${TIME}" >> "${FILE}"
pgbench --username=root -h "${HOST}" test ${PARAM} -S -T "${TIME}" >> "${FILE}"
echo "pgbench --username=root -h ${HOST} test ${PARAM} -N -T ${TIME}" >> "${FILE}"
pgbench --username=root -h "${HOST}" test ${PARAM} -N -T "${TIME}" >> "${FILE}"
done
Здесь мы получаем количество ядер и рассчитываем количество потоков в конкретной системе. Далее — указываем HOST, что БД будет располагаться локально на машине, устанавливаем время тестирования в секундах (TIME), после чего создаем БД test и задаем количество строк. В нашем тестировании создавался миллиард строк, которые занимают примерно 250 ГБ.
Как вы можете видеть, в pgbench-тесте используется три ключа для тестирования:
- «-» — смешанные SQL-запросы (Select, Update),
- «-S -T» — упорядоченная последовательность SQL-запросов (Select only),
- «-N -T» — режим простых SQL запросов (Update only).
pgbench --username=admin -h 127.0.0.1 test -c 52 -j 26 -T 600
pgbench (14.6 (Ubuntu 14.6-0ubuntu0.22.04.1))
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10000
query mode: simple
number of clients: 52
number of threads: 26
duration: 600 s
number of transactions actually processed: 22881325
latency average = 1.363 ms
initial connection time = 235.470 ms
tps = 38150.347817 (without initial connection time)Парсинг результатов в Google-таблицу
В результате каждого теста у нас создавался .txt-файл, в котором были зарыты нужные числа и результаты. Вот пример скрипта, с помощью которого я собирал данные и заносил их в Google-таблицу:
#!/usr/bin/awk -f
BEGIN {
# Параметры таблицы, выравнивание
client_width = 10
thread_width = 12
tps_width = 20
trans_width = 20
latency_width = 20
init_conn_width = 25
# Вывод столбцов
printf "%-s%-s%-s%-s%-s%-s\n", "Num Clients", "Num Threads", "TPS", "Num Transactions", "Latency Average", "Initial Connection Time"
}
# Извлечение нужных значений из строки запуска pgbench
match($0, /-j\s+([0-9]+)/, arr) {
num_clients = arr[1]
}
match($0, /-c\s+([0-9]+)/, arr) {
num_threads = arr[1]
}
# Поиск по строкам нужных значений
/number of transactions actually processed:/ {
num_transactions = $NF
}
/latency average/ {
latency_average = $(NF-1) " " $NF
}
/initial connection time.*[0-9]+\.[0-9]+/ {
# Извлечение только числовых значений
for (i = 1; i <= NF; i++) {
if ($i ~ /^[0-9]+\.[0-9]+$/) {
init_conn_time = $i " " $(i+1)
break
}
}
}
/tps/ {
# Извлечение всех знаков (if present)
for (i = 1; i <= NF; i++) {
if ($i == "tps") {
tps = $(i+2)
gsub(/[()]/, "", tps) # Удаление TPS знач
break
}
}
# Вывод
printf "%-*s%-*s%-*s%-*s%-*s%-*s\n", client_width, num_clients, thread_width, num_threads, tps_width, tps, trans_width, num_transactions, latency_width, latency_average, init_conn_width, init_conn_time
}После выполнения скрипта в терминале выводятся колонки с нужными данными.
Результаты тестирования
На каждую версию PostgreSQL и Postgres Pro Enterprise мы генерировали график для оценки производительности в многопоточном режиме:
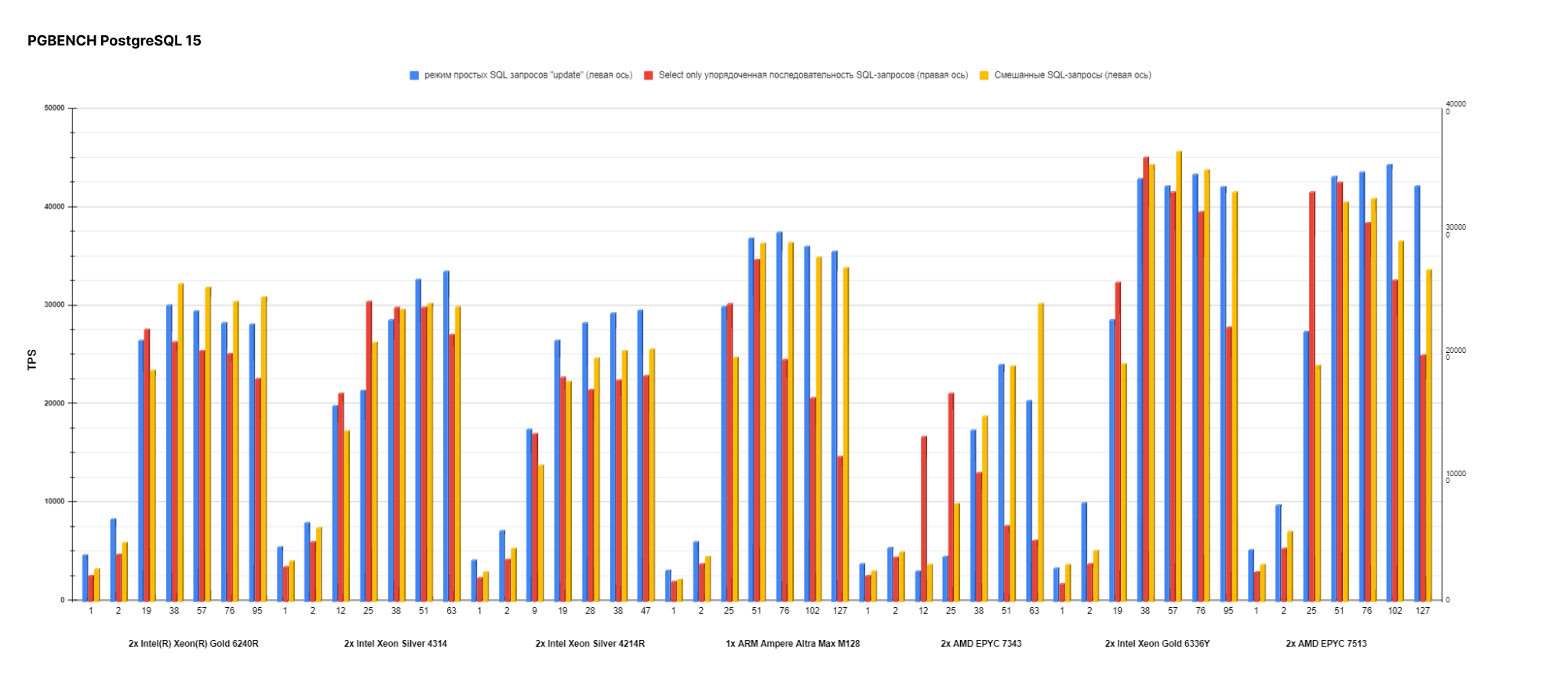
График для оценки производительности на ядро (в одном и двух потоках):

По предыдущему графику можно заметить, что процессоры второго поколения выигрывают у процессоров третьего по показателям производительности на ядро. Так что новое и дорогое решение не является оптимальным для всех сценариев.
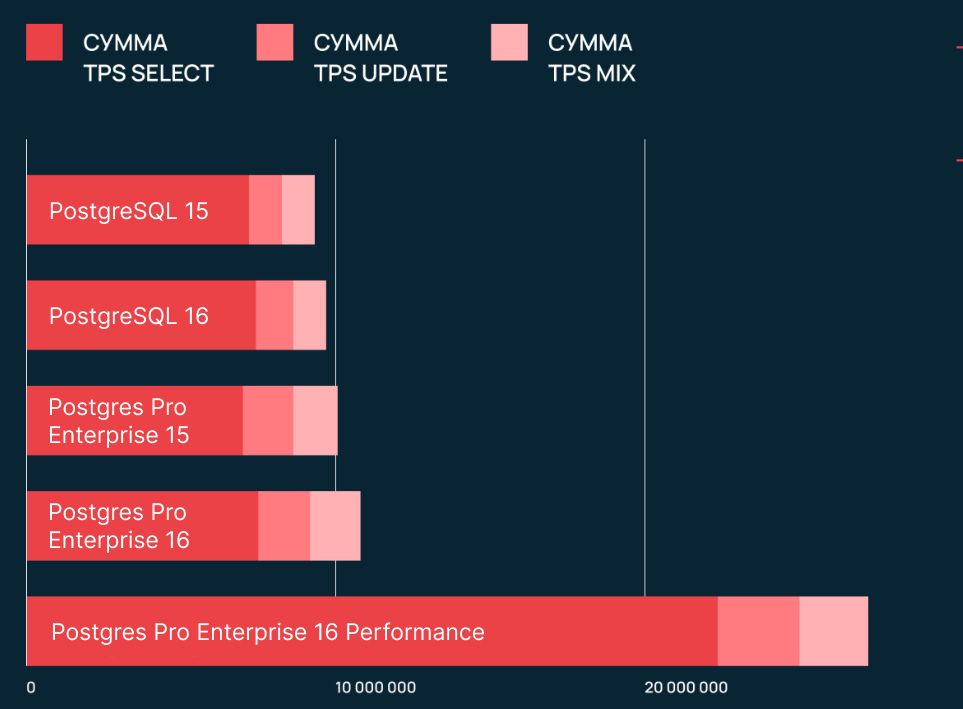
Перейдем к главной задаче — оценке общей производительности разных версий. Значения в графиках — количество операций в секунду (TPS).

При сравнении стандартных версий мы получили разницу в производительности от 2 до 7%, а также значительный разрыв по SELECT only. Перейдем к сравнению Postgres Pro Enterprise.
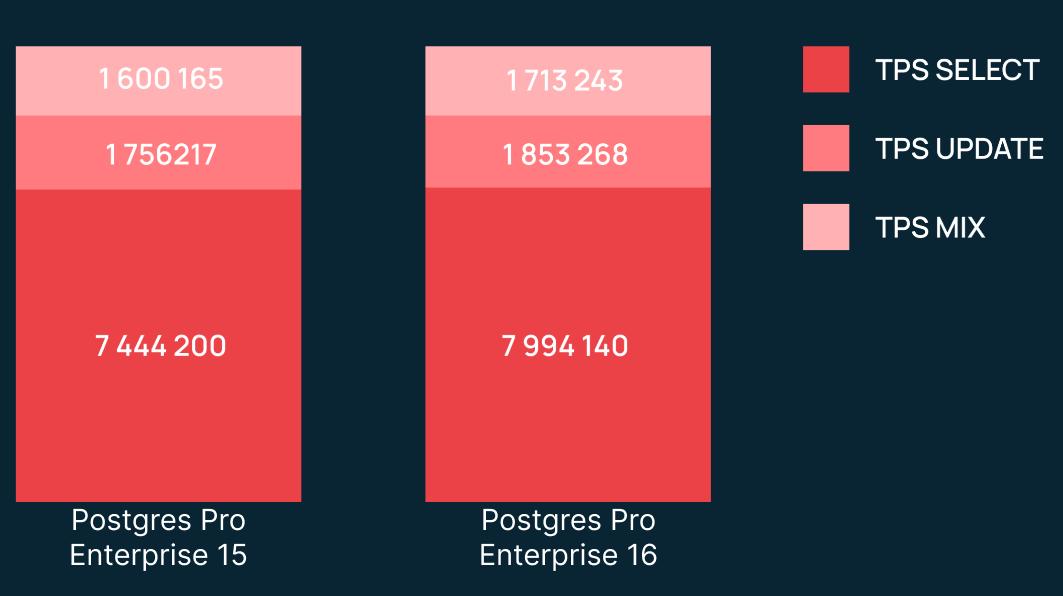
Видим, что в процентном соотношении результат схож со сравнением стандартных версий. Однако количество операций в секунду здесь гораздо больше. Теперь сравним PostgreSQL и Postgres Pro Enterprise:

Здесь видим значительную разницу в TPS MIX между стандартными и Pro-версиями. Одной из причин является автоконфигурирование Postgres Pro Enterprise, что немного «тюнит» БД для лучшей производительности (для нас это все равно дефолт, так как из коробки мы ничего не делаем).
Скорее всего, под капотом находится еще много оптимизаций, которых мы не видим как обычные пользователи БД.
Далее мы решили выжать из железа максимум. Вот что получили:
Для режима performance была произведена настройка БД, ориентированная на максимальную производительность.
- Huge Pages эффективно управляет большим объемом памяти.
- BG Writer оптимизирует фоновую запись данных на диск.
- Prefetching обеспечивает повышенную производительность при сканировании данных.
- Вынесение каталога pg_stat_tmp в RAM (tmpfs) позволяет ускорить работу с временными файлами.
- Autovacuum обеспечивает автоматическую очистку.
- Write-Ahead Logging — запись перед чтением, увеличивает размер журнала, что позволяет редко выполнять контрольные точки.
#Определить количество HugePages. Обычно их размер равен 2 МБ. Например, нам нужно 3 100 страниц.
#Прописать в /etc/sysctl.conf настройку число больших страниц:
systemctl stop postgresql
#Проверяем сколько нужно Huge page.
sudo -u postgres/opt/pgpro/ent-15/bin/postgres --shared-buffers=2GB -D /var/lib/pgpro/ent-15/data/ -C shared_memory_size_in_huge_pages
systemctl start postgresql
echo 3100 | sudo tee /proc/sys/vm/nr_hugepages
#Проверяем настройку:
cat /proc/meminfo
#Число HugePages должно быть ненулевое, а общее должно равняться 3 100.
#Выключаем настройку THP:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
#Устанавливаем группу для Huge Pages.
pg_group_id=$(id -g postgres)
echo "$pg_group_id" | sudo tee /proc/sys/vm/hugetlb_shm_group
sudo sed -i 's/huge_pages = try/huge_pages = on/' /var/lib/pgpro/ent-16/data/postgresql.conf
systemctl restart postgresql
sudo sed -i "s/^#bgwriter_delay =.*/bgwriter_delay = '10ms'/" /var/lib/pgpro/ent-16/data/postgresql.conf && \
sudo sed -i "s/^#bgwriter_flush_after =.*/bgwriter_flush_after = 0/" /var/lib/pgpro/ent-16/data/postgresql.conf && \
sudo sed -i "s/^#bgwriter_lru_maxpages =.*/bgwriter_lru_maxpages = 4000/" /var/lib/pgpro/ent-16/data/postgresql.conf && \
sudo sed -i "s/^#bgwriter_lru_multiplier =.*/bgwriter_lru_multiplier = 10/" /var/lib/pgpro/ent-16/data/postgresql.conf && \
sudo sed -i "s/^#checkpoint_completion_target =.*/checkpoint_completion_target = 0.9/" /var/lib/pgpro/ent-16/data/postgresql.conf && \
sudo sed -i "s/^#checkpoint_timeout =.*/checkpoint_timeout = '30min'/" /var/lib/pgpro/ent-16/data/postgresql.conf
sudo sed -i "s/^#max_wal_size =.*/max_wal_size = '32GB'/" /var/lib/pgpro/ent-16/data/postgresql.conf && \
sudo sed -i "s/^#wal_compression =.*/wal_compression = 'lz4'/" /var/lib/pgpro/ent-16/data/postgresql.conf && \
sudo sed -i "s/^#default_toast_compression =.*/default_toast_compression = 'lz4'/" /var/lib/pgpro/ent-16/data/postgresql.conf && \
sudo sed -i "s/^#lwlock_shared_limit =.*/lwlock_shared_limit = 16/" /var/lib/pgpro/ent-16/data/postgresql.conf && \
sudo sed -i "s/^#log2_num_lock_partitions =.*/log2_num_lock_partitions = 8/" /var/lib/pgpro/ent-16/data/postgresql.conf && \
sudo sed -i "s/^#slru_buffers_size_factor =.*/slru_buffers_size_factor = 6/" /var/lib/pgpro/ent-16/data/postgresql.conf && \
sudo sed -i "s/^#default_statistics_target =.*/default_statistics_target = 1000/" /var/lib/pgpro/ent-16/data/postgresql.conf && \
sudo sed -i "s/^#autoprepare_threshold =.*/autoprepare_threshold = 2/" /var/lib/pgpro/ent-16/data/postgresql.conf && \
sudo sed -i "s/^#autoprepare_for_protocol =.*/autoprepare_for_protocol = 'simple'/" /var/lib/pgpro/ent-16/data/postgresql.conf && \
sudo sed -i "s/^#generic_plan_fuzz_factor =.*/generic_plan_fuzz_factor = 0.9/" /var/lib/pgpro/ent-16/data/postgresql.conf && \
sudo sed -i "s/^#effective_io_concurrency =.*/effective_io_concurrency = 100/" /var/lib/pgpro/ent-16/data/postgresql.conf && \
sudo sed -i "s/^#autovacuum_naptime =.*/autovacuum_naptime = '1s'/" /var/lib/pgpro/ent-16/data/postgresql.conf && \
sudo sed -i "s/^#autovacuum_max_workers =.*/autovacuum_max_workers = 6/" /var/lib/pgpro/ent-16/data/postgresql.conf && \
sudo sed -i "s/^#vacuum_cost_limit =.*/vacuum_cost_limit = 2000/" /var/lib/pgpro/ent-16/data/postgresql.conf && \
sudo sed -i "s/^#autovacuum_work_mem =.*/autovacuum_work_mem = '1GB'/" /var/lib/pgpro/ent-16/data/postgresql.confСкрипт для переноса каталога pg_stat_tmp в RAM-диск:
#!/bin/bash
# Путь к RAM-диску
RAMDISK_PATH="/mnt/ramdisk"
# Размер RAM-диска (1GB)
RAMDISK_SIZE="1G"
# Путь к каталогу pg_stat_tmp
PG_STAT_TMP_PATH="/var/lib/pgpro/ent-16/data/pg_stat_tmp"
# Переменная для резервного копирования оригинального каталога
PG_STAT_TMP_BACKUP_PATH="/var/lib/pgpro/ent-16/data/pg_stat_tmp_backup"
# Создание каталога RAM-диска
sudo mkdir $RAMDISK_PATH
# Примонтирование RAM-диска
sudo mount -t tmpfs -o size=$RAMDISK_SIZE tmpfs $RAMDISK_PATH
# Копирование данных из pg_stat_tmp в RAM-диск
sudo cp -r $PG_STAT_TMP_PATH/. $RAMDISK_PATH/
# Создание символической ссылки
sudo mv $PG_STAT_TMP_PATH $PG_STAT_TMP_BACKUP_PATH
sudo ln -s $RAMDISK_PATH $PG_STAT_TMP_PATH
# Проверка создания символической ссылки
ls -l $PG_STAT_TMP_PATHЗаключение
Все оптимальные настройки производительности, о которых я рассказал в рамках статьи, уже выполнены при развитии продукта Облако для PostgreSQL. Также, у сервиса есть такие дополнительные преимущества, как:
- подбор оборудования для высокой производительности СУБД;
- установка и оптимизация параметров СУБД;
- установка, настройка и обновление ОС и служебных компонентов;
- настройка реплик отказоустойчивого кластера;
- обеспечение ресурсов для масштабирования СУБД;
- настройка локальной сети в ЦОД для высокой производительности кластера;
- мониторинг СУБД;
- Бесплатное ежедневное резервное копирование кластера (Point-in-time Recovery), глубина хранения — одна неделя;
- хранение данных по 152-ФЗ;
- соответствие основным стандартам безопасности, включая PCI DSS 3.2.1, ISO 27001, ISO 27017, ISO 27018.
Помимо прочего, в тестировании мы подтвердили, что при возможности лучше всегда обновляться на новую версию PostgreSQL. Это актуально как для стандартной версии, так и для Pro. Для предварительной настройки BIOS, ОС и самой БД, вы можете воспользоваться нашими подсказками. Если нужен сервис, где все необходимые оптимизации уже применены, то это Облачные базы данных Selectel. Чтобы добиться максимальной производительности, используйте Postgres Enterprise Pro с тюнингом настроек БД.
Какие базы данных используете в своих проектах и как их настраиваете? Делитесь в комментариях, будет интересно почитать!
Комментарии (15)

paxlo
12.04.2024 19:36
khgvghv
12.04.2024 19:36+2Эта конфигурилка может быть полезной для начальной настройки, но уровень статьи гораздо выше.

bdaring
12.04.2024 19:36+2Ага, особенно монтирование pg_stat_tmp в tmpfs для postgresql 15+ наводит на мысли о "высочайшем" уровне статьи.

Maksvelis Автор
12.04.2024 19:36Можно было создать часть ram как блочное устройство и смонтировать туда но что бы это изменило? Или что вы имеете ввиду?
bdaring
12.04.2024 19:36+1Начиная с 15 версии posgresql не использует каталог pg_stat_tmp, а хранит статистики в shared memory.
Maksvelis Автор
12.04.2024 19:36в документации обратная информация https://www.postgresql.org/docs/16/storage-file-layout.html
bdaring
12.04.2024 19:36Именно в этом месте документацию не поправили. В отличие например от описания параметра stats_temp_directory, которая и задает расположение этого каталога.
Вот тут: https://www.percona.com/blog/postgresql-15-stats-collector-gone-whats-new/ хорошо описано, что там сделали с коллектором статистики, и, в частности, почему каталог pg_stat_tmp все же оставили. Кратко - для совместимости с расширениями, которые могут полагаться на наличие этого каталога.
Maksvelis Автор
12.04.2024 19:36Да вы правы, теперь процессы пишут в основную шаренную память. И в целом нагрузка на запись на pg_stat_tmp значительно уменьшилась. Но запись то всё равно есть. По поводу этого момента у нас нет чётких тестов, может уже и не стоит это делать. Но критичного в этом ничего нет на результаты тестов это не повлияет. Если у вас есть аргумент что это критически повлияло на тесты или еще на какой-то момент, с удовольствием почитаю.
paxlo
12.04.2024 19:36Настолько высокий что прописывает с потолка взятые значения без учета текущей конфигурации железа, и всё это руками в консоли. Автор явно не знаком с минимальной автоматизацией
Maksvelis Автор
12.04.2024 19:36+1Про значения с потолка я промолчу, вы явно не понимаете зачем были проведены данные тесты, про автоматизацию вы видимо пропустили или не читали статью, банально "sed" уже упрощает жизнь. Что уж там говорить про парсер данных и полную автоматизацию тестирования за исключением отрисовки графиков их да я делал руками. Расскажете как будете автоматизировать?

ZaMaZaN4iK
12.04.2024 19:36+2Если вы интересуетесь вопросами ускорения программ, то могу посоветовать пересобрать PostgreSQL с Profile-Guided Optimization (PGO): https://ru.wikipedia.org/wiki/Profile-guided_optimization . Я собираю результаты применения PGO к разным приложениям (в том числе и БД) вот тут - https://github.com/zamazan4ik/awesome-pgo , с результатами для PostgreSQL можно ознакомиться здесь - https://github.com/zamazan4ik/awesome-pgo/blob/main/postrgresql_results.md .
khgvghv
Не очевидно, что эта настройка что-то кардинально улучшит.
Portnov
так можно убедиться, что PG действительно "увидел" huge pages и стал ими пользоваться: если почему-то не получится, он упадёт на старте, а не будет молча работать в "медленном" режиме, как при try.
khgvghv
Резонно. Вот интересно, кстати, из базы же нет иного способа проверить, используются ли HP?