
 Привет, Хаброжители!
Привет, Хаброжители!В «Рецептах Python» используется простой, но эффективный метод освоения 63-х базовых навыков программирования на Python. Сначала формулируется вопрос, например «Как найти элементы в последовательности?» Затем приводится базовое решение на чистом понятном коде. Далее исследуются другие интересные подходы, такие как поиск подстрок или пользовательские классы. Перед переходом к следующему вопросу полученные навыки закрепляются с помощью решения задач.
Автор рассматривает все языковые средства, необходимые для уверенного владения Python. По ходу знакомства с книгой вы изучите лучшие приемы написания питонического кода. В освоении каждого инструмента помогут конкретные рекомендации и рисунки. Многочисленные перекрестные ссылки указывают на возможность повторного использования рассматриваемых средств и концепций в различных контекстах.
Для кого эта книга
Если какое-то время вы изучали Python самостоятельно, но ваши знания языка представляются вам недостаточно упорядоченными, то вы, вероятно, находитесь в процессе перехода с начального уровня на промежуточный. Эта книга написана специально для вас, потому что вам нужно подкрепить свои знания Python и обобщить их в структурированной форме. В каждой главе этой книги я выделяю несколько тем для решения общих проблем, с которыми вы можете столкнуться в процессе работы. Впрочем, изложение этих тем не ограничивается решением конкретной проблемы — материал помещается в более широкий контекст, чтобы показать, почему и насколько эта тема важна при работе над любым проектом. Таким образом, вы не ограничиваетесь конкретными приемами решения отдельных задач, а работаете над своим проектом, параллельно осваивая применение этих приемов.
Структура книги
Книга состоит из шести частей, названия которых представлены на следующей схеме («Дорожной карте»). В части 1 (главы 2–5) изучаются встроенные модели данных, включая строки, списки и словари. Эти модели данных являются структурными элементами любого проекта. В части 2 (главы 6 и 7) рассказано о том, как определяются функции. Функции считаются неотъемлемой частью любого проекта, потому что они обеспечивают обработку данных для получения нужного вывода. В части 3 (главы 8 и 9) вы научитесь правильно определять пользовательские классы. Вместо применения встроенных классов мы определяем пользовательские классы для более эффективного моделирования данных в проекте. В части 4 (главы 10 и 11) представлены основы использования объектов и управления файлами. Часть 5 (главы 12 и 13) посвящена различным средствам повышения надежности программ, включая ведение журнала, обработку исключений и тестирование. В части 6 (глава 14) все полученные знания синтезируются для построения веб-приложения — проекта, который служит учебной основой для материала всех остальных глав.

Я рекомендую во время работы над книгой сразу воспроизводить все приведенные примеры на компьютере. Это позволит вам быстрее освоить синтаксис Python и основные приемы программирования. Я загрузил весь исходный код на GitHub, и мой общедоступный репозиторий доступен по адресу github.com/ycui1/python_how_to. Однако приводя в книге какой-либо код, я также привожу все необходимые пояснения и результаты, так что ничего страшного, если при чтении книги у вас под рукой не будет компьютера.
Если вы намерены воспроизводить примеры на компьютере, не имеет значения, какая на нем установлена операционная система. Windows, macOS и Linux — подойдет любая, потому что Python является кросс-платформенным языком программирования. Так как в книге я сосредоточусь на важнейших приемах и методах, которые устоялись в последних выпусках Python, не так важно, работаете ли вы на Python 3.8 или более ранней версии. Тем не менее, чтобы извлечь максимум пользы из книги, я рекомендую установить Python версии 3.10 и выше.
Я рекомендую во время работы над книгой сразу воспроизводить все приведенные примеры на компьютере. Это позволит вам быстрее освоить синтаксис Python и основные приемы программирования. Я загрузил весь исходный код на GitHub, и мой общедоступный репозиторий доступен по адресу github.com/ycui1/python_how_to. Однако приводя в книге какой-либо код, я также привожу все необходимые пояснения и результаты, так что ничего страшного, если при чтении книги у вас под рукой не будет компьютера.
Если вы намерены воспроизводить примеры на компьютере, не имеет значения, какая на нем установлена операционная система. Windows, macOS и Linux — подойдет любая, потому что Python является кросс-платформенным языком программирования. Так как в книге я сосредоточусь на важнейших приемах и методах, которые устоялись в последних выпусках Python, не так важно, работаете ли вы на Python 3.8 или более ранней версии. Тем не менее, чтобы извлечь максимум пользы из книги, я рекомендую установить Python версии 3.10 и выше.
Обработка и форматирование строк
В этой главе
- Использование f-строк для интерполяции выражений и применения форматирования
- Преобразование строк в другие типы данных
- Объединение и разбиение строк
- Применение регулярных выражений для расширенной обработки строк
Необходимость правильной обработки и форматирования строк возникает во множестве реальных ситуаций. В этой главе будут рассмотрены некоторые распространенные задачи, встречающиеся при обработке текста.
КАК ИСПОЛЬЗОВАТЬ F-СТРОКИ ДЛЯ ИНТЕРПОЛЯЦИИ И ФОРМАТИРОВАНИЯ
В языке Python предусмотрены разные способы форматирования текстовых строк. Один из популярных способов основан на использовании f-строк, позволяющих встраивать выражения в строковый литерал. Можно использовать и другие методы форматирования, но решения с f-строками лучше читаются, следовательно, f-строки становятся предпочтительным вариантом при подготовке строк для вывода.
ОБРАТИТЕ ВНИМАНИЕ F-строки впервые появились в Python 3.6. Префиксом f-строки может быть как символ f, так и символ F (от слова formatted — отформатированный). Строковый литерал представляет собой последовательность символов, заключенную в одинарные или двойные кавычки.
При использовании строк для вывода часто приходится иметь дело с не-строковыми данными, например целыми числами и числами с плавающей точкой. Допустим, таск-менеджер требует создания строкового вывода с использованием существующих переменных:
# Существующие переменные
name = "Homework"
urgency = 5
# Желательный вывод:
Name: Homework; Urgency Level: 5В этом разделе вы научитесь использовать f-строки для интерполяции не-строковых данных и представления строк в нужном формате. Вы увидите, что при форматировании строк с использованием существующих строк и других разновидностей переменных f-строки являются лучшим решением с точки зрения удобочитаемости.
Форматирование строк до появления f-строк
Класс str работает с текстовыми данными через свои экземпляры, которые мы будем называть строковыми переменными. Помимо строковых переменных, в текстовую информацию также часто включаются такие типы данных, как целые числа и числа с плавающей точкой. Теоретически мы могли бы преобразовать нестроковые данные в строки и соединить их для получения нужного текстового вывода, как показано в листинге 2.1.

В коде создания переменной task скрываются две потенциальные проблемы. Во-первых, он выглядит громоздко и не особенно хорошо читается, так как мы имеем дело с несколькими разными строками, каждая из которых заключена в кавычки. Во-вторых, urgency необходимо преобразовать из int в str, прежде чем значение может быть объединено с другими строками, что дополнительно усложняет операцию конкатенации.
Старые методы форматирования строк
До появления f-строк были доступны два решения. Первое решение записывается в классической форме языка C со знаком %, а во втором используется метод format.
Решение в стиле C использует символ % в строковом литерале для обозначения форматируемой переменной, за которой следует знак % и кортеж соответствующих переменных. Решение с методом format используется примерно так же. Вместо знаков % в литерале в нем применяются фигурные скобки как маркеры строковой интерполяции, а соответствующие переменные перечисляются в методе format.
Следует заметить, что оба способа все еще поддерживаются в Python, но они считаются устаревшими и вам практически не придется пользоваться ими. По этой причине я не стану подробно на них останавливаться. Важно знать, что все, что они позволяют сделать, можно сделать с помощью f-строк — более наглядного механизма строковой интерполяции и форматирования, — как будет показано в разделе 2.1.2.

ОСНОВНЫЕ ПОНЯТИЯ Методами обычно называются функции, определяемые в классах. В данном случае функция format определяется в классе str, поэтому этот метод вызывается для экземпляров str.
Использование f-строк для интерполяции переменных
Форматирование строк часто подразумевает объединение строковых литералов и переменных разных типов (например, целых чисел и строк). При интеграции переменных в f-строку можно интерполировать эти переменные, чтобы они автоматически преобразовывались в строки нужного вида. В этом разделе описаны разные варианты интерполяции распространенных типов данных с использованием f-строк. Для начала рассмотрим, как использовать f-строки при создании вывода, представленного в листинге 2.1.
task_f = f"Name: {name}; Urgency Level: {urgency}"
assert task == task_f == "Name: Homework; Urgency Level: 5"В этом примере переменная task_f создается с применением f-строк. Главное, на что следует обратить внимание, — фигурные скобки, в которые заключаются интерполируемые переменные. Так как f-строки интегрируют механизм строковой интерполяции, они также называются интерполируемыми строковыми литералами.
ОСНОВНЫЕ ПОНЯТИЯ Термин «строковая интерполяция» (string interpolation) не относится к специфике Python, этот механизм присутствует в большинстве основных современных языков (таких, как JavaScript, Swift и C#). В общем случае он предоставляет более компактный и удобочитаемый синтаксис для создания отформатированных строк, чем конкатенация строк и альтернативные способы их форматирования.
Инструкция assert
Ключевое слово Python assert используется для проверок (ассертов), которые вычисляют заданное условие. Если результат равен True, программа продолжает выполняться. Если же результат равен False, выполнение прерывается, а программа выдает ошибку AssertionError.
В этой книге я буду использовать инструкцию assert для демонстрации эквивалентности переменных, задействованных в сравнении. В особом случае, когда проверяемая переменная относится к логическому типу, с технической точки зрения лучше использовать assert true_var и assert not false_var. Но чтобы более наглядно отразить логическое значение переменной, я предпочел использовать assert true_var == True и assert false_var == False.
Вы уже видели, как f-строки интерполируют строки и целочисленные переменные. Как насчет других типов, например, списков list и кортежей tuple?
Эти типы также поддерживаются f-строками, как показывает следующий фрагмент:

ЗАБЕГАЯ ВПЕРЕД F-строки также поддерживают экземпляры пользовательских классов. Когда в главе 8 мы займемся созданием пользовательских классов, мы еще вернемся к тому, как строковая интерполяция работает с пользовательскими экземплярами (раздел 8.4).
Использование f-строк для интерполяции выражений
Мы рассмотрели, как в f-строках интерполируются переменные. На более общем уровне f-строки также могут интерполировать выражения, что избавляет вас от необходимости создания промежуточных переменных. Например, при создании строкового вывода можно обратиться к элементу объекта dict или использовать результат вызова функции. В таких распространенных ситуациях можно включить эти выражения в f-строки, как показывает следующий фрагмент кода:

Эти выражения заключаются в фигурные скобки, чтобы f-строки напрямую вычислили их для получения нужного строкового вывода:
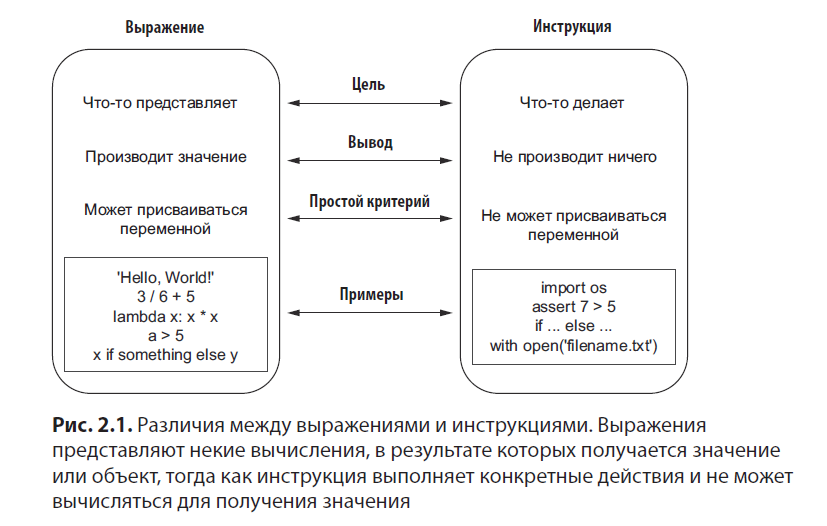
{tasks[0]} -> "homework"; {task_name.title()} -> "Grocery Shopping"; {number*number} -> 25.В тексте часто встречается термин «выражение» (expression), относящийся к числу ключевых понятий программирования. Начинающие программисты могут путать его со связанным понятием — инструкцией (statement). Выражение обычно представляет собой одну строку кода (хотя может занимать несколько строк при заключении в тройные кавычки), результатом вычисления которой является значение объекта, например строки или экземпляра нестандартного класса. Из этого определения легко выводится, что переменные являются разновидностями выражений.
С другой стороны, инструкции не создают никакого значения или объекта. Цель инструкции заключается в выполнении некоторого действия. Например, ключевое слово assert создает проверочную инструкцию (или команду), которая проверяет выполнение некоторого условия, прежде чем процесс продолжится. Мы не пытаемся получить логическое значение True или False, а проверяем условие. Рисунок 2.1 показывает, чем выражения отличаются от инструкций.
Хотя f-строки поддерживают интерполяцию выражений, эту возможность следует использовать с осторожностью, потому что любые сложные выражения в f-строках ухудшают читаемость вашего кода. Следующий пример демонстрирует злоупотребление f-строками, использующими сложные выражения:

Существует хороший практический критерий оценки удобочитаемости вашего кода — определите, сколько времени потребуется читателю, чтобы разобраться в нем. Чтобы понять, что происходит в приведенном выше фрагменте, читателю понадобятся десятки секунд. Сравните со следующей переработанной версией:
scores = [95, 98, 97, 96, 97, 93]
total_score = sum(scores)
subject_count = len(scores)
average_score = total_score / subject_count
summary_text = f"Your Average Score: {average_score}."В этой версии заслуживает внимания ряд обстоятельств. Во-первых, оценки сохраняются в объекте list, что позволяет избавиться от дублирования данных. Во-вторых, вычисления разбиты на несколько шагов, при этом каждый шаг представляет собой более простое вычисление. В-третьих, ключевым фактором для улучшения удобочитаемости становится использование на каждом шаге содержательного имени, обозначающего результат вычислений. Такой код хорошо читается без единого комментария, все понятно само по себе.
УДОБОЧИТАЕМОСТЬ Создайте необходимые промежуточные переменные с содержательными именами, чтобы наглядно обозначить каждый шаг ваших операций. Для простых операций вам даже не придется писать комментарии, потому что содержательные имена описывают смысл каждой операции.
Применение спецификаторов для форматирования f-строк
Правильное форматирование текстовых данных (например, выравнивание) играет ключевую роль в передаче информации. Так как f-строки проектировались для форматирования строк, они предоставляют возможность задать спецификатор формата (начинающийся с двоеточия) для применения дополнительных правил форматирования к выражению в фигурных скобках (рис. 2.2). В этом разделе вы узнаете, как применять спецификаторы для форматирования f-строк.
При интерполяции можно воспользоваться спецификатором формата — необязательным компонентом, который определяет, как должна форматироваться интерполированная строка выражения. F-строка может получать разные виды спецификаторов формата. Рассмотрим самые полезные их разновидности, начиная с выравнивания текста.

Выравнивание строк для формирования визуальной структуры
Одним из способов повышения эффективности передачи информации является ее структурированная организация; это в полной мере относится к представлению текстовых данных. Как показано на рис. 2.3, сценарий B благодаря применению более организованной структуры с выравниванием столбцов предоставляет информацию нагляднее, чем сценарий А.

Для выравнивания текста в f-строках используются три символа: <, > и ^, включающие выравнивание текста по левому краю, по правому краю и по центру соответственно. Если вы начнете путаться в том, какой символ что делает, посмотрите, в каком направлении указывает стрелка: например, если она направлена влево, то текст выравнивается по левому краю.
Для определения режима выравнивания текста в спецификаторе формата используется синтаксис
f"{expr:x<n}", где expr — интерполированное выражение, x — символ-заполнитель для выравнивания (если не указан, по умолчанию используется пробел), < — признак выравнивания по левому краю и n — целочисленный интервал, до которого расширяется вывод. Следующий листинг показывает, как создать две записи с выровненными полями для получения более наглядного вывода.
В этом листинге стоит обратить внимание на то, что применение одного спецификатора формата ко всем выражениям приводит к повторению. Если в вашем коде встречаются повторения, скорее всего, вы нарушаете принцип DRY (Don’t Repeat Yourself, то есть «не повторяйтесь»), а это указывает на необходимость рефакторинга.
Принцип DRY и рефакторинг
В программировании разработчики руководствуются рядом принципов. К их числу относится знаменитый принцип DRY. Если в вашей программе встречается повторяющийся код, скорее всего, следует провести рефакторинг для устранения таких повторений. Некоторые IDE, в частности PyCharm, включают средства автоматического выявления повторений. Пользуйтесь ими для улучшения своих программ.
Говоря о рефакторинге, я имею в виду меры по обновлению существующего кода для улучшения его структуры и, как следствие, повышения удобства сопровождения. Рефакторинг не добавляет новые возможности в вашу программу; вместо этого он изменяет структуру существующего кода без добавления каких-либо изменений в его поведение. Примеры рефакторинга будут приводиться в книге там, где его применение уместно.
Если появятся новые требования к выравниванию текста, в листинге 2.2 код придется обновлять в трех местах; это неудобно и повышает риск ошибок. В результате рефакторинга мы хотим получить механизм использования переменной в качестве спецификатора формата. В листинге 2.3 приведено возможное решение, в котором выделяется повторяющаяся часть — спецификатор формата. Если же пойти немного дальше по пути рефакторинга, можно определить функцию, которая будет получать спецификатор формата в параметре; это позволит экспериментировать с разными спецификаторами формата. Чтобы улучшить удобочитаемость кода, мы создадим отдельные переменные для данных задачи.

В листинге 2.3 стоит обратить внимание на то, что спецификатор формата fmt заключен в фигурные скобки внутри внешних фигурных скобок. Python знает, как заменить {fmt} правильным спецификатором формата. Опробуем эту функцию с разными спецификаторами формата:

Как видите, полученный в результате рефакторинга код позволяет назначить произвольный спецификатор формата, и эта гибкость подчеркивает преимущества рефакторинга. Когда спецификаторы формата используются для выравнивания, текст образует четко различимые столбцы. Тем самым создаются визуальные границы для разделения разных информационных полей.
СОПРОВОЖДАЕМОСТЬ Мы постоянно ищем возможности для рефакторинга своего кода, обычно на «локальном» уровне. Локальная оптимизация может показаться чем-то незначительным, но эти мелкие усовершенствования накапливаются и определяют общее удобство сопровождения проекта.
Для заполнения в приведенном примере используются пробелы, но можно использовать и другие символы. Выбор символов зависит от того, способствуют ли они наглядному выделению информации. В табл. 2.1 приведены примеры использования разных заполнителей и режимов выравнивания.

Форматирование чисел
Числа — неотъемлемые источники информации, которые часто включаются в текстовый материал. Существуют различные формы числовых значений: большие целые числа, числа с плавающей точкой, проценты и т. д. В этом разделе вы узнаете, как f-строки представляют числовые значения со спецификаторами формата, упрощающими восприятие информации.
Множество простых чисел бесконечно. Обычный поиск в Google показывает, что наименьшее простое число, превышающее 1 миллиард, равно 1 000 000 007. При выводе такого большого числа желательно разделять группы цифр, и чаще всего после каждых трех цифр вставляется запятая. Для назначения разделителей групп разрядов в целых числах в f-строке используется спецификатор формата xd, где x — разделитель, а d — спецификатор формата для целых чисел:
large_prime_number = 1000000007
print(f"Use commas: {large_prime_number:,d}")
# Вывод: Use commas: 1,000,000,007Числа с плавающей точкой, как и дробные числа вообще, встречаются почти в каждом научном или инженерном отчете. Как и следовало ожидать, у f-строк существуют спецификаторы формата, которые позволяют форматировать дробные числа в удобочитаемом виде. Рассмотрим следующие примеры:
decimal_number = 1.23456
print(f"Two digits: {decimal_number:.2f}")
# Вывод: Two digits: 1.23
print(f"Four digits: {decimal_number:.4f}")
# Вывод: Four digits: 1.2346Если для целых чисел использовался спецификатор формата d, то для дробных значений используется спецификатор f. Хотя спецификатор f может использоваться автономно, чаще указывается, сколько цифр должно выводиться в дробной части: .2 для вывода двух цифр, .4 — для четырех цифр, и т. д.
По аналогии с использованием f для дробных чисел, можно воспользоваться спецификатором формата e для экспоненциальной (научной) записи. Пример использования этой возможности:
sci_number = 0.00000000412733
print(f"Sci notation: {sci_number:e}")
# Вывод: Sci notation: 4.1227330e-09
print(f"Sci notation: {sci_number:.2e}")
# Вывод: Sci notation: 4.13e-09Другая распространенная форма числовых значений — проценты. При выводе процентов используется спецификатор формата %. Как и в случае со спецификаторами e и f, мы можем использовать спецификатор % сам по себе или с указанием точности (например, .2 для вывода двух знаков в дробной части):
pct_number = 0.179323
print(f"Percentage: {pct_number:%}")
# Вывод: Percentage: 17.932300%
print(f"Percentage two digits: {pct_number:.2%}")
# Вывод: Percentage two digits: 17.93%Помимо этих спецификаторов, f-строки поддерживают и другие. В табл. 2.2 приведены популярные спецификаторы, применяемые к f-строкам при работе с числами.

Обсуждение
Хотя с прямой интерполяцией выражений f-строками код становится более чистым, избегайте использования сложных выражений в f-строках — они могут запутать читателей вашего кода. Если выражения слишком сложные, создайте промежуточные переменные с содержательными именами.
В Python все еще поддерживаются традиционные способы в стиле C и с использованием format, но реальной необходимости в их изучении нет (впрочем, они могут встретиться вам в старом коде). Каждый раз, когда вам потребуется создать строковый вывод, используйте f-строки. И не забывайте о выравнивании текста и форматировании числовых значений — это сделает текстовый вывод более понятным.
Задача
Джеймс работает в IT-отделе компании оптовой торговли и готовит шаблон для ценников. Допустим, данные товара сохраняются в объекте
dict: {"name": "Vacuum", "price": 130.675}. Как Джеймсу записать f-строку, если нужно, чтобы в ценнике выводилась строка Vacuum: {130.68}? Обратите внимание: цена должна выводиться с точностью до двух знаков, а вывод включает фигурные скобки — символы, используемые для строковой интерполяции в f-строках.ПОДСКАЗКА Фигурные скобки являются специальными символами в f-строках. Если строковый литерал включает специальные символы, необходимо экранировать их, чтобы они не рассматривались как специальные символы. Для экранирования фигурных скобок включите дополнительную фигурную скобку: {{ означает {, а }} означает }.
Об авторе
Доктор Юн Цуй — ученый, проработавший в области биомедицины более пятнадцати лет. Его исследовательская работа была посвящена разработке мобильных приложений медицинского назначения для поведенческой психотерапии на языках Swift и Kotlin. Его любимый язык Python стал основным средством для анализа данных, машинного обучения и разработки исследовательского инструментария. В свободное время он публикует в блогах посты по различным техническим темам, включая мобильную разработку, программирование на языке Python и искусственный интеллект.
Более подробно с книгой можно ознакомиться на сайте издательства:
» Оглавление
» Отрывок
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 25% по купону — Python



khromova1
Вау, очень классная книга на самом деле.