
Привет, Хабр! Меня зовут Никита Догаев, я Backend Team Lead в команде Контента на портале поставщиков Wildberries. Мы отвечаем за карточки, которые каждый день испытывают на прочность сотни тысяч продавцов из разных стран.
В статье поделюсь своим опытом применения фаззинга для нагрузочных и интеграционных тестирований. Расскажу про генерацию текстов на армянском языке, тестирование SQL-запросов, а также можно ли использовать фаззер и unit-тестирование бок о бок, и какие баги нам удалось найти.

Немного про команду
Команда контента на портале поставщиков отвечает за бережное и ответственное хранение данных о карточках товаров всех продавцов на Wildberries.
Одна из основных задач – разработка и поддержка сервиса API, предназначенного для работы с карточками. Контент карточек – это весь тот текст, который вы видите на странице товара.

Второй немаловажной задачей команды является обработка текстового контента, а именно – валидация и его нормализация. Причём это надо делать быстро, чтобы поставщики долго не ждали, пока обновляются их данные о товаре.
Ну и третья задача – передавать данные о товарах. Так как мы являемся мастер-системой данных и от нас получают информацию о товарах все остальные наши команды, то мы должны их передавать другим нашим сотрудникам, сервисам, потребителям данных.
Почему Fuzzing?
К тестированию кода с помощью fuzzing мы пришли по нескольким причинам.
В наших репозиториях скопилось большое количество методов со сложной логикой.
Множество кейсов в unit-тестах, то есть около 1000 строк кода. Когда у нас возникала ошибка, некоторое количество этих тест-кейсов ломалось. Разработчики тратили много времени на решение этой проблемы, а компания – денег.
В запросе могут приходить непредвиденные данные. Мы обслуживаем поставщиков из разных стран СНГ: это Армения, Казахстан и многие другие. И они могут писать в карточке что угодно. Особенно часто бывает такое, что взяли какой-то PDF-файл или Word, скопировали оттуда данные, кинули, и все символы оттуда перекочевали к нам, из-за чего у нас возникали ошибки.
Проверка внутренних интеграций. Всегда, когда мы нормализируем и валидируем данные о карточках товаров, мы передаем их нашим потребителям (сервисам-потребителям данных), они эти данные получают, обрабатывают и выполняют с ними определённые действия. Бывает такое, что одно из полей у нас становится deprecated (устаревшим). Мы его убираем, отправляем нашим потребителям, и тут, например, команда логистики говорит: «Блин, так у нас же от этого зависела вся логика, мы теперь лежим». Вот поэтому нам надо всё это проверять перед тем, как делать любые изменения в системах.
Но перед тем, как мы перейдем к практическим примерам, начнем с того, с чего мы сами когда-то начали – а именно с теории.
Что такое Fuzzing?

Fuzzing – это техника тестирования программ, которая происходит за счет сгенерированных случайных значений. Данная технология широко распространена и используется для тестирования высоко нагруженных приложений.
Fuzzing лучше использовать при тестировании сложного кода, так как с помощью стандартного unit-тестирования физически очень сложно покрыть все возможные вариации входных данных. Обычно, когда мы создаем unit-тест как разработчик, мы прокидываем несколько тест-кейсов для тех моментов, в которые мы понимаем, где может сплоховать наша программа, но не все. И с помощью fuzzing мы можем полностью покрыть весь наш код тестами.
Fuzzing Go
В данном языке программирования используют coverage-guided fuzzer, который доступен из коробки с версии 1.18. Ранее fuzzing также был доступен в Go, но в виде отдельной библиотеки gofuzz.

Сам fuzz-тест представляет собой функцию, у которой есть приставка fuzz (обязательная) и которая на вход принимает значение testing.F. Оно обладает всеми теми же методами, что и объект testing.T, только у него добавляются две новые функции. Это f.Add и f.Fuzz.

Что это за функции? С помощью функции add мы добавляем значения в первоначальный корпус нашего fuzzer, а с помощью метода fuzz мы инициализируем функцию, в которой fuzzer будет генерировать значение, которое мы хотим, и исполнять наш тест. Те значения, которые генерирует fuzzer, называются fuzzing-аргументами.
Но как же запустить эти тесты? Сначала мы применяем команду go test с флагом -fuzz и названием нашей fuzz-функции. Например, go test -fuzz FuzzTestFuncName.
У команды есть и другие флаги:
-fuzztime – отвечает за количество времени, которое должен проработать fuzzer, или количество итераций;
-fuzzminimizetime — количество времени или количество итераций, которые минимизируются перед тем, как записаться в корпус;
-parallel, который отвечает за то, сколько потоков будет работать наш fuzzer.
Покрытие кода с Fuzzing
Ещё раз отметим, что в Go используется coverage guided fuzzer. Его фишка заключается в том, что при выполнении теста со сгенерированными значениями он определяет, какие участки кода он затронул. Если с новым аргументом была затронута новая ветка кода, то fuzzer запомнит данное значение и поместит в генерированный корпус. Далее он начинает делать мутации над ним, чтобы проверить большую часть кода.

На данном примере мы видим, что изначально вызов функции идёт без seeds, так как мы не добавили в начальный корпус значений. Fuzzer мутирует пустую строку, добавляя туда рандомные значения. Он это делает, пока не доходит до следующего условия. На этом условии у нас уже в корпусе есть значение AAAA, далее идет FAAA, FUAA, FUZA, и доходим до паники с значением FUZZ.
Вообще, fuzzer мог сделать значение FUZZ и какую-то супербольшую строку, в которой были бы ненужные нам символы: точка, слэш и так далее. И тут используется minimize, то есть он убирает все ненужные байты, и мы приходим к оптимальному значению, которое вызывает нашу панику.
Где лежат данные корпуса?

Данные сгенерированного корпуса лежат по пути, который вы видите на скрине. Там файлы, и в них описана версия fuzzer, который запускался, и само значение. Также у нас есть начальный корпус, и для него данные лежат в вашем проекте, где вы запускали fuzz-тест в testdata/fuzz/ + название вашей функции.
Результат fuzz-тестирования

Здесь можно увидеть записи о сборке базового покрытия. Чтобы собрать базовое покрытие, в fuzzing запускают тесты с исходным корпусом и со сгенерированного корпуса для того, чтобы убедиться в отсутствии ошибок и понять покрытие кода на начало теста. Исходный корпус мы сами заполняем с помощью метода add, а сгенерированный корпус заполняется по мере работы fuzzer. Туда идут выводы, которые привели к вызову новой строчки кода.

Тут описано, на скольких потоках fuzzer заработал, это 10 workers.

Тут показано, сколько времени заняла работа с сначала запуска fuzzing, и то, что за это время было запущено около 1 млн 411 тысяч тестов с различными вводными данными, а также сколько seeds было записано по мере работы fuzzing за 3 секунды. То есть в нашем случае это 0, но всего у нас в корпусе лежит уже 8 seed-ов.
Fuzzing и http handler
Перейдём к примерам. Первое, с чего мы в команде начали применять fuzzing – это http handler. Например, возьмём такую задачу. В карточке товара есть поле описания, и в него нельзя добавлять больше трёх Emoji.


Для решения этой задачи мы описали такой хендлер, которым принимаем запрос. В этом запросе есть поле description. Этот description мы отправляем в метод checkEmoji. Метод достает оттуда все Emoji, после чего мы проверяем количество, которое он нашел. Если их больше 3, отдаём ошибку. Если все ок, то отдаем ок.
Для тестирования данного функционала мы можем использовать два типа тестов – нерациональный и рациональный. Давайте посмотрим на них подробнее.
Нерациональный тип

Тут описан fuzz target, в котором мы просим fuzzer сгенерировать нам слайс байт. Его мы валидируем: что это валидный JSON, он unmarshal-ится, и description – не пустая строка. После чего отправляем тестироваться.
В чем же тут проблема? Когда валидируем, мы пропускаем тест-кейсы, а из-за методов valid и unmarshal мы фаззим скорее их, чем тот хендлер, который хотим протестировать на самом деле. То есть все seeds, которые добавляются в сгенерированный корпус, будут сгенерированы для проверки именно методов valid и unmarshal, а не хендлер-функции, из-за чего больше времени будет тратиться на нахождение ошибки.
Рациональный fuzz target

Здесь мы просим fuzzer сделать нам string, мы сразу отправим это в модельку, unmarshal-им, и этот готовый JSON мы отдадим для тестирования нашего хендлера. Тем самым fuzzer будет именно для хендлера, мы быстрее найдем ошибку и радостно пойдем её чинить.
Если сравнить оба варианта, мы увидим, что время работы fuzzing в случае нерационального подхода значительно больше, чем у рационального

Seed-ов в одном из подходов меньше, но они более точны для того, чтобы найти ошибку в вашем коде. Количество запущенных тестов тоже значительно разнится, и в случае использования рационального подхода их меньше, из-за чего при вызове fuzzing такой реализации мы используем меньше компьютерных ресурсов.
Fuzzing и unit-тестирование

Перейдём к следующему кейсу – когда можно использовать fuzzing и unit-тестирование бок о бок. А именно о том, когда с помощью fuzz-аргументов нужно сгенерировать свои рандомные аргументы для тестирования функции. Давайте посмотрим на функцию, которую мы будем тестировать.

Это функция Sum. Она принимает на вход слайс чисел и находит сумму этих значений в слайсе. Тут заведомо сделана ошибка – мы игнорируем значения, которые делятся нацело на 100 000, чтобы мы могли найти какую-то ошибку.

Далее описываем fuzz-тест, в котором изначально в начальный корпус мы добавляем 10, чтобы от него как раз и начинал генерироваться fuzzer. Также мы добавили, чтобы длина слайса, который мы будем генерировать, не была больше 10. Это мы сделали с помощью операции mod. Проходим по циклу от 0 до этого n и генерируем наше значение с помощью rand.Int 63. Далее заполняем наш тестовый слайс, считаем сумму, которая должна получиться и описываем string, в которой мы будем выводить ошибку и какие аргументы привели к этой ошибке.

После чего это всё запускаем, проверяем и получаем ответ, что сумма actual и expected разная. То есть у нас ошибка.

Это можно перенести в unit-тест, чтобы в дальнейшем его запускать. Если на этом этапе мы снова запустим fuzzing, он сгенерирует новые значения, и у нас не повторится ошибка.
В итоге мы получаем следующий алгоритм:
генерируем тестовые данные;
выводим «интересные» значения – те, которые привели к ошибке;
сохраняем «интересные» значения в test cases;
исправляем код;
запускаем unit-тест;
повторяем сначала.
Если ошибок больше нет, опять повторяем сначала, чтобы fuzzer, может быть, еще нашел какую-то ошибку.
Применяем такой подход мы только для маленьких функций. Для больших функций это некорректная проверка, потому что coverage guided не будет работать, и мы не сможем весь код покрыть тестами. То есть тут black box получается, а не grey box.
Генерация контента на иностранном языке
Наши пользователи — сотни тысяч продавцов из разных стран СНГ. И порой у нас появляются карточки, которые заполнены не на латинице или кириллице, а, например, на армянском языке.

Из-за такого текста наш код может выдать ошибку, потому что мы не знали, какие символы могут быть. В базе данных или в коде тоже может произойти какая-то проблема, особенно в плане нормализации строк для нахождения, к примеру, некорректных слов.
Для подобных случаев мы сделали такой вот fuzz-тест, генерирующий текст на иностранном языке:

Если добавится новая страна с новым языком, мы возьмем из unicode нижнюю и верхнюю границы и длину строки.

Далее с помощью mod опишем генерацию длины строки, которая у нас должна быть.

И после этого будем генерировать строку на том языке, который нам нужен. Мы ходим в unicode, генерируем код символа и всё это вместе контейнируем. После этого подаём на тестируемую функцию.
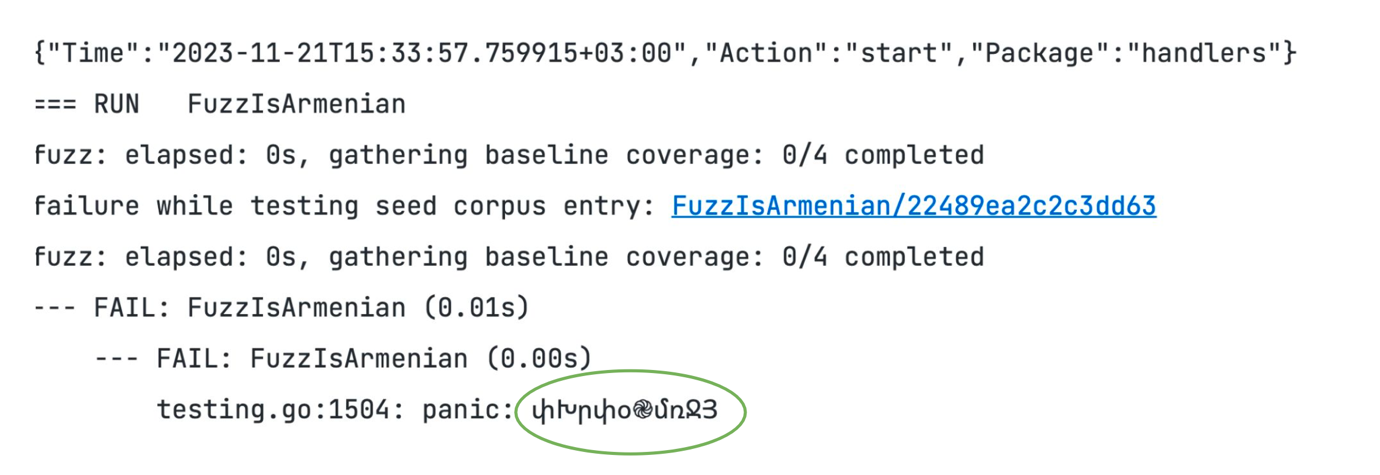
В итоге мы получаем ошибку. В данном примере ошибку вызвал вот такой круглый символ – армянский знак вечности, и мы после теста благополучно это починили.
Fuzzing и SQL
Как же fuzz-ить SQL-запросы? Разберём на нескольких примерах.
Метод записи в таблицу БД

Например, возьмём функцию CreateTestRow. Тут есть запрос SQL, который создает некоторую строку в нашей таблице .foo. Отдаём идентификатор этой строки, которую мы создали. Игнорируем ошибку ErrNoRows, остальные выводим.

Для того, чтобы это проверить, мы написали такой fuzz test, в котором инициализируем тест-контейнер.
Почему берём контейнер? Мы пробовали делать это с виртуалкой, но столкнулись с проблемами. Когда fuzzing прекращает свою работу, сама машина отправляет сигнал kill на процесс fuzzing, и этот kill надо было как-то отследить. У нас это не получилось, из-за чего мы не смогли очищать данные из таблицы. Поэтому мы выбрали решение с тест-контейнерами. Запускаем тест-контейнер, туда отправляем fuzzing-параметры, он создает их, заканчивается fuzz-тест, мы отключаемся от тест-контейнера, всё очищается, и опять заново можем запускать.

После того, как мы сделали инициализацию тест-контейнера и запустили первичные миграции для тестирования нашего метода, мы описываем сам fuzz target и просим сгенерировать нам некоторую строку. Эту строку отправляем на метод создания строки в базе данных и запускаем наш тест.

В итоге мы обнаруживаем такую ошибку: определённый символ не может записаться в базу данных, из-за чего нам надо его починить.
Чтение с базы данных
Перейдём к следующему примеру – это чтение с базы данных.
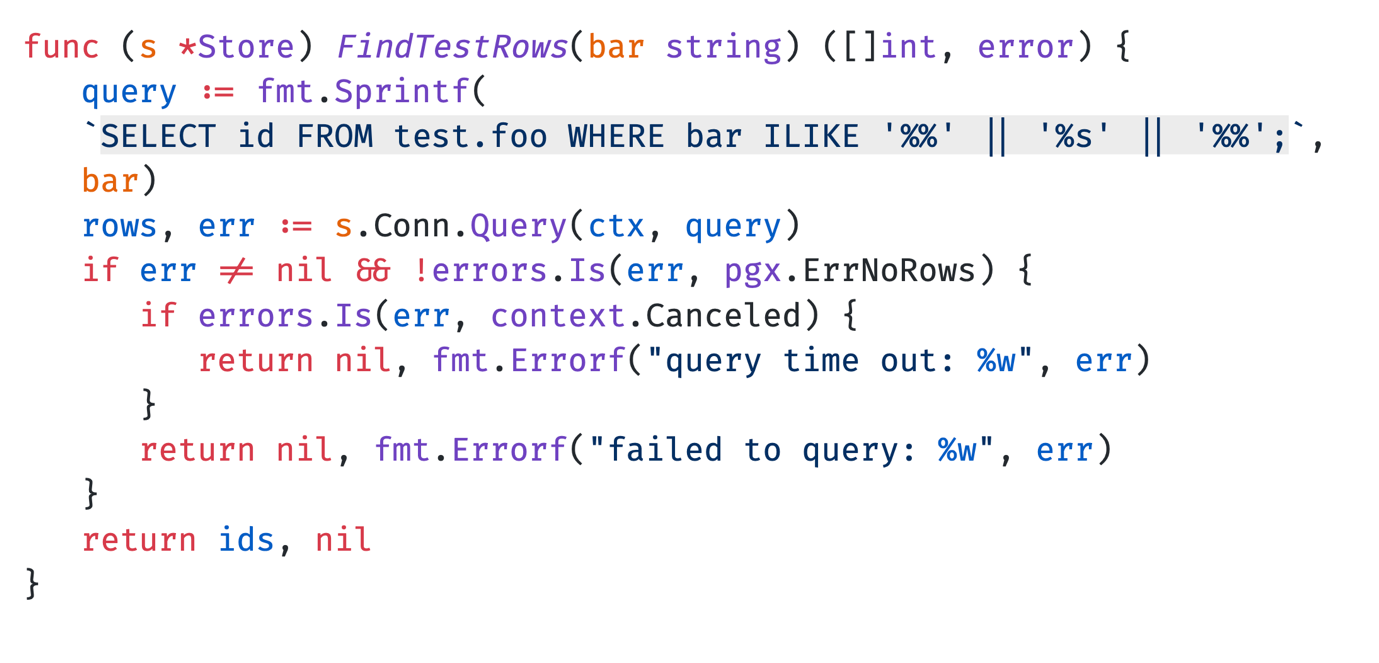
У нас есть такой запрос, где мы получаем идентификатор с таблицы .foo по значению bar с помощью операции ILIKE. Опять же, игнорируем ErrNoRows, добавляем обработку ошибки, если у нас time. out, и выводим ошибку и идентификаторы.

Описываем инициализацию тест-контейнера, запускаем наши миграции, описываем fuzz target и переводим туда наш метод FindTestRows.
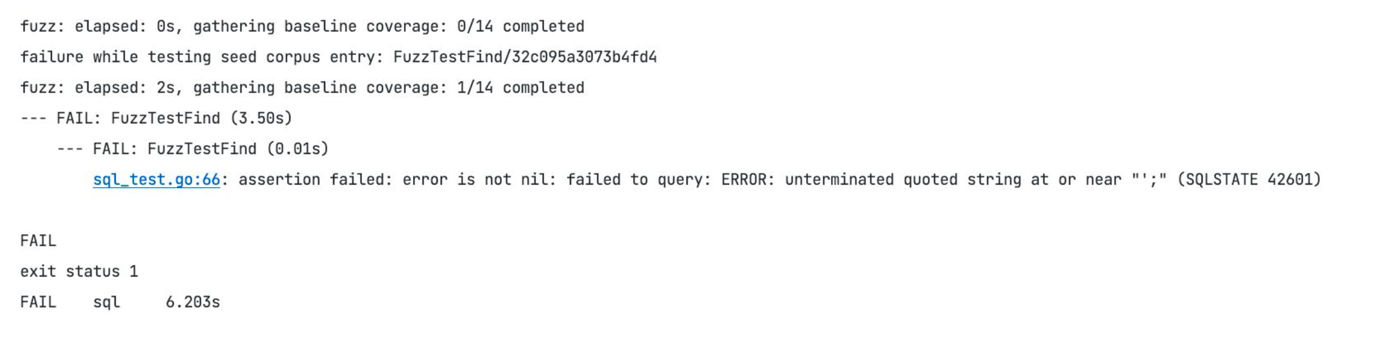
После чего мы находим ошибку, а именно SQL-инъекцию, которую нам надо починить, то есть использовать, к примеру, placeholders в нашем запросе.
Какие баги мы смогли найти с помощью fuzzing?
Panic при работе с индексами
Это касается методов, в которых мы работаем со слайсами, go-каналами, указателями или рефлексией. Ещё можно отловить ошибку деления на ноль, к примеру.
Ошибки при вызове неправильного status code при работе хендлера
К примеру, у нас ошибка авторизации, а мы отдаем ошибку 500, хотя должны 403. Fuzzing помог обнаружить эти проблемы.
Неприятный баг, связанный с символами й и ё
В методе валидации текста, а именно в функции поиска запрещённых слов, нам нужно отловить запрещённые слова или словосочетания из текстового контента карточки товара и вывести их продавцу. Чтобы он понимал, из-за чего его данные не сохраняются в нашу таблицу.
При поиске строки мы делаем ее нормализацию для дальнейшего поиска, и в результате получаем найденное запрещённое слово в ненормализированном виде. Для вывода запрещенного слова клиенту нам надо денормализировать строку к её исходному виду. Именно тут и был баг.

Проиллюстрируем ошибку. Есть слово «вейп» в определённой категории, к примеру, электроника, и оно считается запрещённым. Мы находим и выводим уже не «вейп», а какой-то «вейn», где n – вообще латинская буква. Всё это отловили и починили. Спасибо fuzzing, что помогает находить такие баги.
Как применить fuzzing для нагрузочного тестирования
Что мы хотим получить?
Ничего не испортить при новом релизе
Когда мы вносим правки, добавляем новые поля, убираем старые поля или изменяем логику формирования нынешних полей, мы не должны ничего испортить ни у наших интеграторов, ни у нас самих.
Нагрузочный тест нас и наших потребителей
Во-первых, мы должны провести нагрузочный тест при новой логике нашего writer в брокер, а во-вторых, понять, справляются ли наши потребители (особенно новые) с тем количеством информации, которую мы передаем брокеру или нет.
Какое решение мы сделали?
Изначально написали fuzz-тест.
Далее для него описали методы формирования событий карточек товаров с помощью, например, byte shuffle. И сделали формирование событий категории, карточки товара, размеров и характеристик.
Далее отправили эти события в брокер сообщений, к примеру, на Kafka.
Передали данные для подключения к брокеру нашим потребителям для того, чтобы они смогли протестировать свои интеграции с нами.
Реализовали бота, который собирал события с Grafana. Если кого-то произошла ошибка, сразу выписывал это в алертинг. Они следили за ботом, тегали, кто ответственный за этот сервис и шли чинить.
Настроили мониторинг данных этих алертов при запуске фаст-тестов на stage окружении, и теперь оповещаем наших потребителей о том, что запускаем интеграционные тесты. Ждем около часа после запуска. Если алертов нет, то все ок, и мы можем двигаться в прод.
Настроили мониторинг ресурсов. Если какой-то из сервисов у нас или у наших потребителей начинает троттлить или перезапускаться из-за переполнения памяти, мы также получаем уведомления. Тем самым новые сервисы потребителей данных могут протестировать нагрузку при интеграции с нами перед выходом в продакшен.
В результате мы получили меньше багов в продакшене, больше сохранённых нервных клеток при релизе и больше уверенности у новых потребителей при выходе в продакшен.
Выводы
Fuzzing в Go – это круто. Его можно использовать почти везде, но не везде.
Не стоит пропускать fuzz-тесты из-за сгенерированных аргументов. Потому что тем самым будете fuzz-ить именно эти методы, а не те, что надо.
Если пришлось генерировать данные из fuzz-данных, то при ошибке выводите их в результат. Чтобы на основе сгенерированных значений описать тест-кейс в unit-тест для дальнейшей проверки вашего кода. Это подойдёт для маленьких функций, где вы не хотите описывать тест-кейсы сами, а доверяетесь fuzzer.
Для fuzzing SQL нужно использовать тест-контейнер, чтобы не хранить fuzz-значения в таблицах. Также с помощью fuzzing в Go можно тестировать методы, которые вызывают SQL-запросы, например, SQL-инъекции.
Fuzzing можно применить для нагрузочного тестирования – именно так мы сделали в нашей команде.
Fuzzing прост в применении, но при этом помогает отловить сложновоспроизводимые и весьма неприятные баги. В комментариях можно поделиться своими кейсами применения фаззинга)
Материал подготовлен по мотивам моего доклада на Golang Conf.
marxxt
Спасибо за статью! Вы делаете фаззеры для каждого sql-запроса? или выбираете как-то или составляете его чисто под фаззер?
dogaevnikita Автор
Обычно мы фаззим только определенные запросы, в частности те, где не тривиальная логика сборки финального запроса, со множеством фильтров.