
В OpenCorpora мы создаём открытые данные для обучения и тестирования математических моделей анализа текста на русском языке. Таким образом, мы помогаем российской компьютерной лингвистике догнать западную. Потом будем помогать обгонять ;)
Сегодня мы расскажем о разметке именованных сущностей. Это ещё один слой разметки текстов в Открытом корпусе. Мы будем выделять в тексте имена людей, названия компаний и географических объектов.

Зачем мы это делаем?
Морфологическую разметку мы начали и продолжаем по собственной инициативе. Работу над разметкой сущностей мы ведём совместно с оргкомитетом соревнования factRuEval-2016, которое пройдёт в рамках конференции по компьютерной лингвистике Диалог-21. На данном этапе сущности размечаются не во всём корпусе, а только в небольшом его подмножестве, которое станет обучающей и тестовой коллекциями для участников соревнования. В сумме это около 1000 новостных текстов объёмом по 3-4 абзаца. Как обычно, результат разметки будет опубликован на условиях лицензии Creative Commons. Обучающая часть коллекции будет публиковаться по мере её модерации, а разметка тестовой части — не ранее завершения соревнования и подведения его итогов.
Что такое разметка именованных сущностей?
Извлечение именованных сущностей из текста — одна из востребованных функций текстовой аналитики (см. об этом подробно, например, в блоге компании Textocat).
Было бы классно, если бы существовало несколько десятков конкурирующих между собой решений, позволяющих перечислить все упомянутые в тексте объекты, дать их нормализованные названия и соответствующие им идентификаторы объектов. И всё это для русского языка и с открытым исходным кодом. Принимая участие в организации соревнования factRuEval и в подготовке данных для него, мы делаем шаг в эту сторону и приглашаем вас присоединиться.
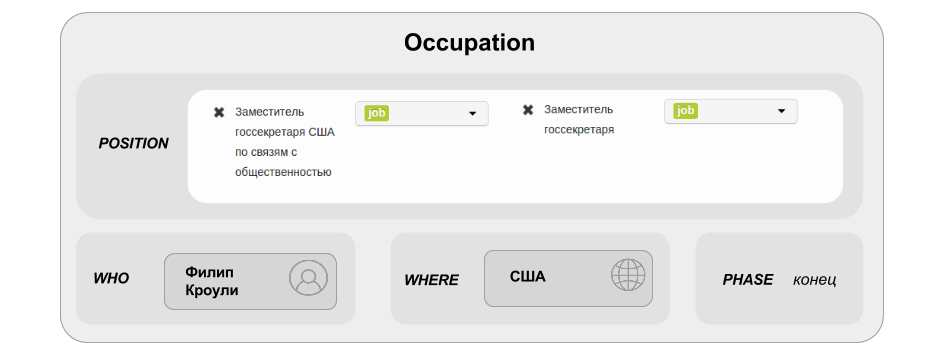
Если коротко, то выделение именованных сущностей состоит в том, чтобы найти в текстах имена собственные (ФИО персон, названия организаций и географических объектов), выделить их и пометить соответствующим тегом. Например, для персон нужно отдельно отметить фамилию, имя и отчество, после чего объединить выделенные отрезки в одно упоминание объекта с типом Person. Об этом мы написали подробную инструкцию и записали маленькое видео.

Что будет дальше?
Разметка сущностей уже идёт. Следующими этапами разметки коллекции текстов для factRuEval будет идентификация упоминаний объектов между собой, связывание их с WikiData и разметка фактов. Первые два пункта подразумевают, что несколько отдельных упоминаний в тексте одного и того же объекта реального мира (например, Иванов Иван, Иванов и Иванов И.И.) будут объединены друг с другом в одну сущность. Для этой сущности будет указываться идентификатор из WikiData.
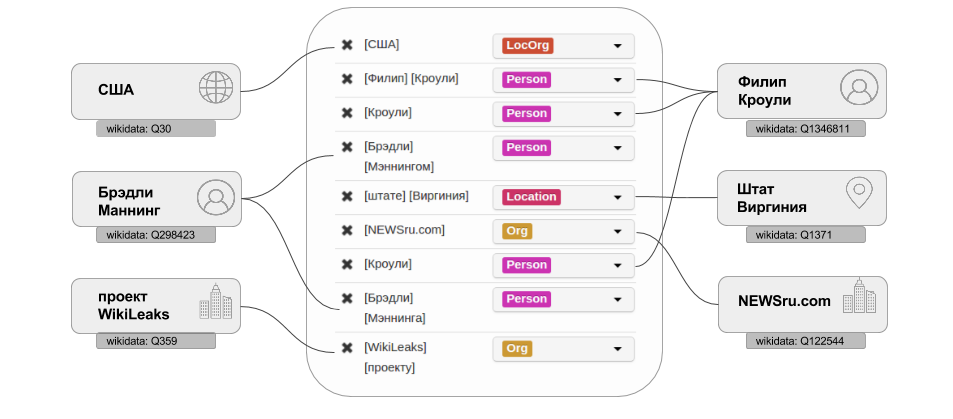
Под фактами имеются в виду описанные в тексте отношения между уже выделенными на предыдущих этапах объектами: отношение Occupation (работать в компании) между персоной и организацией, отношение Ownership (владеть) между персоной и организацией и другие подобные отношения.
Как нам помочь?
1. примите участие в разметке.
Теперь у нас есть два направления работы: именованные сущности и морфология. Для выполнения заданий в обоих направлениях достаточно прочитать инструкции.
2. напишите об этой работе в социальных сетях и попросите ваших друзей помочь нам.
Не все читают GeekTimes, но очень многие готовы помогать по чуть-чуть.
Update: Прямая ссылка на разметку сущностей: http://opencorpora.org/ner.php (она есть в инструкции, пусть будет и тут тоже).
Комментарии (10)

Sadler
17.12.2015 07:57+2Удачи вам. Я некоторое время пытался привести викисловарь к состоянию такой универсальной лингвистической БД, да одного человека здесь явно мало.

bocharov
17.12.2015 10:42+1Спасибо!
Чем-то похожим, на то, о чём вы пишите, занимается (или занимался) vk.com/componavt. Возможно, что вы сможете объединить усилия.

dema
17.12.2015 09:46+21. Не даёт удалить span даже если нет упоминаний.
2. Не даёт проставить тип Location/Person. Написано, что надо кликнуть на спане, не работает.
В консоли выдаёт ошибку:
POST opencorpora.org/ajax/ner.php 500 (Internal Server Error)
formData=act=newEntity&tokens%5B%5D=112615&types%5B%5D=15¶graph=Array
возвращает "{«error»:1,«error_message»:""}"bocharov
17.12.2015 10:38Спасибо. Разбираемся.
Скажите, пожалуйста, идентификатор текста (он в урле).

Nashev
17.12.2015 21:03+1А Компрено не поможет? Или это наоборот, чтобы его сравнить с чисто человеческой разметкой, и затем доучивать?
bocharov
17.12.2015 21:09+1Это как раз для того, чтобы разную автоматику сравнить с условным идеалом, оценить и осознать перспективы.
Компрено поможет, но сделает результаты оценки слегка перекошенными в сторону тех примеров, которые Компрено понимает хорошо. Оценить само Компрено при этом будет проблематично, а хочется. Поэтому делаем всё чисто, т.е. вручную.
MichaelBorisov
Попытался зарегистрироваться, выдает «DB Error». Хабраэффект?
bocharov
Спасибо.
Нет, не он. Скорее всего вы делали это через Facebook или другую соцсеть. Мы давно используем Loginza для интеграции с ними. Последнее время Loginza глючит.
Попробуйте следующее:
1. повторить попытку входа тем же способом (иногда это помогает)
Если первое не поможет:
2. сделать другой логин прямо на OpenCorpora. Если вы раньше уже заходили через соцсеть, пришлите, пожалуйста, ссылку на профиль, через который заходили. Мы свяжем два профиля у себя в один.
Прошу прощения за неудобство.