

Началось всё с того, что я заметил странную особенность CMS Wordpress. Так, при при первом обращении, к моему сайту по адресу www.domain.com/non_existent_file.ext выводился заголовок «404 Not Found», а при повторном «200 OK». На тот момент казалось, что на это могут влиять мои правки в движке и различные прикрученные костыли. Но при диагностике, на этапе отключения плагинов, выяснилось, что причиной такого поведения является плагин «W3 Total Cache». Не разбираясь в деталях, с мыслью «допилят ещё», включил его снова и забыл.
Через пару месяцев решил добавить этот сайт в Я.Вебмастер. Сервис предоставлял несколько способов для подтверждения владения сайтом. На тот момент ими являлись:
— html-файл
— мета-тэг
— txt-файл
— через whois
— через dns
Так как SSH соединение с сервером в то время было открыто, самым простым вариантом показался «txt-файл», который гласил, что для аппрува нужно:
1. Создайте txt-файл с именем yandex_59306eb68da05077.txt с произвольным содержимым (можно пустой)
2. Загрузите его в корневой каталог вашего сайта
3. Убедитесь, что загруженный файл открывается по адресу www.domain.com/yandex_59306eb68da05077.txt.
4. Нажмите на кнопку «Проверить»
Команда touch не заставила себя долго ждать и после нажатия кнопки «Проверить», мой сайт был успешно помещён в раздел «Мои сайты».
Являясь закоренелым любителем почитать логи, во время очередного просмотра, попались строки которые показывали как бот Яндекса проверяет наличие этого файла. Выглядело это следующим образом:
… «GET /yandex_0250d52d00c8a904.txt HTTP/1.1» 404 1362 "-" "… YandexWebmaster/2.0; +http://yandex.com/bots)"
… «GET /yandex_59306eb68da05077.txt HTTP/1.1» 200 0 "-" "… YandexWebmaster/2.0; +http://yandex.com/bots)"
… «GET /yandex_11c01dd326a98199.txt HTTP/1.1» 404 1362 "-" "… YandexWebmaster/2.0; +http://yandex.com/bots)"
Мне стало интересно, а что если отдавать всегда «200 OK». Было принято решение немного «помучить» робота. Так, при возврате сервером кодов отличных от 200 и 404, писалось примерно следущее: «Для заданной страницы (или страницы, полученной после перенаправления) сервер возвращает код статуса http 502 (ожидался код 200).». Если же бот получал 200 постоянно, то так же об этом сообщал и проверка не проходила.
В процессе исследования, случайно, удалось получить подтверждение без наличия файла. Такого я никак не ожидал и стал разбираться с произошедшим.
Последовательность обращений в логе получилась такая:
… «GET /yandex_2dd0e3403151c956.txt HTTP/1.1» 404 1362 "-" "… YandexWebmaster/2.0; +http://yandex.com/bots)"
… «GET /yandex_с220dу5d90c8a331.txt HTTP/1.1» 404 1362 "-" "… YandexWebmaster/2.0; +http://yandex.com/bots)"
… «GET /yandex_d43c048a7be5a791.txt HTTP/1.1» 404 1362 "-" "… YandexWebmaster/2.0; +http://yandex.com/bots)"
… «GET /yandex_d22193589eac5880.txt HTTP/1.1» 404 1362 "-" "… YandexWebmaster/2.0; +http://yandex.com/bots)"
… «GET /yandex_с220dу5d90c8a331.txt HTTP/1.1» 200 0 "-" "… YandexWebmaster/2.0; +http://yandex.com/bots)"
… «GET /yandex_6a5ec74b714c7856.txt HTTP/1.1» 404 1362 "-" "… YandexWebmaster/2.0; +http://yandex.com/bots)"
Провернув трюк ещё раз для наглядности, вспомнил про вышеописанную особенность WordPress. Стало интересно, случается ли такое ещё где-то и как часто.
Был написан простенький чекер на PHP, который слал два запроса с несуществующим именем файла и записывал успешный результат. В качестве списка для тестирования был выбран «Alexa Top 1,000,000».
Не сказать, что результат получился грандиозным, но он был. Вышло около 1500 доменов в различных зонах. При осмотре полученного списка, стало понятным, что плагин «W3 Total Cache» сам по себе ни при чем, так как «проверку» проходили сайты с установленными плагинами QuickCache, MaxCache и другими. Сходство было только одно, большинство из них использовали WordPress. И как выяснилось позже, была ещё одна зависимость, это включенное кеширование в файлы. В W3TC опция называется «Disk (Enhanced)». К сожалению, я не большой любитель копания кода, поэтому причина такого поведения мне не известна.
Так же отмечу, что на некоторых сайтах следов вордпресса обнаружено не было. Возможно он искуссно замаскирован, либо подобный баг возникает ещё где-то.
Далее был отправлен отчёт в «Yandex Bug Bounty». C содержанием:
Здравствуйте.
Метод подтверждения «txt-файл», для некоторых конфигураций сайтов, может позволить подтвердить сайт злоумышленникам.
Cвязано это, как мне кажется, с различными механизмами кеширования.
Так, в реализации кеширующего механизма, для популярной CMS Wordpress в связке с плагинами W3TC, Quick Cache, Max Cache и подобными. Сервер отдаёт заголовок 404 только при первом обращении к недоступному файлу, во второй раз ответ будет 200 ОК. Стоит отметить, что связка WP+кэш-плагины, сама по себе не подвержена, есть ещё некая зависимость, но для её выяснения нужно проводить исследование кода движка.
Вот так выглядит проверка яндекс ботом наличия «txt-файл»-а первый раз:
… «GET /yandex_2dd0e3403151c956.txt HTTP/1.1» 404 136 "-" "… YandexWebmaster/2.0; +http://yandex.com/bots)"
… «GET /yandex_с220dу5d90c8a331.txt HTTP/1.1» 404 136 "-" "… YandexWebmaster/2.0; +http://yandex.com/bots)"
… «GET /yandex_d43c048a7be5a791.txt HTTP/1.1» 404 136 "-" "… YandexWebmaster/2.0; +http://yandex.com/bots)"
А второй будет выглядеть уже так:
… «GET /yandex_d22193589eac5880.txt HTTP/1.1» 404 136 "-" "… YandexWebmaster/2.0; +http://yandex.com/bots)"
… «GET /yandex_с220dу5d90c8a331.txt HTTP/1.1» 200 0 "-" "… YandexWebmaster/2.0; +http://yandex.com/bots)"
… «GET /yandex_6a5ec74b714c7856.txt HTTP/1.1» 404 136 "-" "… YandexWebmaster/2.0; +http://yandex.com/bots)"
Несколько сайтов с подобным поведением и установленной Wordpress:
htmldoc.ru
laminortv.ru
www.comediatv.ru
А в этих случаях:
www.3dnews.ru
rutv.ru
tvkultura.ru
marker.ru
Действует какой-то другой механизм кеширования, но поведение идентично.
Стоит отметить так же этот отчёт: hackerone.com/reports/477. В тот момент, скорее всего, проверка «txt-файл»-а яндекс ботом была бы положительной. Кто знает, сколько ещё сайтов содержат подобный «функционал»?
Это мой первый опыт участия в программе Яндекса и я был приятно удивлён оперативной реакцией сотрудников компании. В этот же день мне ответили и начали разбираться с моим репортом, а на следующий, присудили награду в размере 41337 рублей (примерно $700 в тот момент). Единственное, к чему могу придраться, на мой взгляд цифра 313373 смотрелась бы красивее. Но по большому счёту, это стечение обстоятельств не несло большой выгоды злоумышленникам. Для целевых атак оно не годилось по причине большого количества зависимостей. Извлечение какой либо материальной выгоды из этого, так же сложно представить. Разве что продажа XML лимитов. Поэтому я доволен наградой Яндекса, так как на момент отправки особенного ничего не ожидал.
В качестве морального баунти, через несколько дней после отправленного отчёта, судьба txt-фала была решена (R.I.P.):
...

...

P.S.

Надеюсь, что у него всё получилось :)
Комментарии (31)

zapimir
07.02.2016 18:16+29через несколько дней после отправленного отчёта, судьба txt-фала была решена (R.I.P.):
И что во всем яндексе не нашлось человека который предложил бы создавать txt-файл с каким либо содержимым, каким-нибудь хэшем, как это делают все остальные, а не надеяться на код ответа сервера.
fr33z3
07.02.2016 19:05+1Я думаю, вскоре появится. Странно конечно, что с самого начала это не сделали, но сейчас им нужно все согласовать, прописать стандарты и так далее. В таких компаниях, как яндекс дажи такие незначительные изменения так быстро не делаются.

m_z
07.02.2016 19:58+1Т.е. чтобы выпилить фичу никаких согласований не требуется, а внести простое исправление нужно месяцы? Да и в тексте указано «решение отказаться».

mannaro
07.02.2016 20:29+2Выпилить фичу — это просто решение менеджера. А вот ввести новую фичу — решение команды. Поэтому первое и быстрее, чем второе. Но так, да. Неправильно это.

el777
07.02.2016 23:24+8Выпилить фичу — это закрыть известный баг. При наличии альтернатив — это, конечно, не очень удобно, но не фатально.
Добавить фичу, не согласовав с остальными отделами/проектами/и т.д. — это добавить 10 неизвестных багов. Может отвалиться что угодно — например, подтверждение для Директа или еще чего. В итоге заранее неопределенный круг пользователей может оказаться под угрозой.
Думаю именно так и появилось подтверждение через текстовый файл. Есть полная процедура — через html-файл с проверкой содержимого. Решение ввести упрощенную схему выглядит совершенно логично — веб-мастер контролирует содержимое своего сайта, он может создать файл с особым именем и записать туда что-то. Начинаем оптимизировать. Если вебмастер уже создал файл, то зачем проверять содержимое? Логично? Весьма. Внутри системы изъяна нет. Проблема начинается при «интеграционном тестировании» с интернетом. Практически все распространенные системы ведут себя как положено. Но есть особый баг в ряде CMS, где наличие файла можно сымитировать.

valera5505
07.02.2016 23:22+8HTML-файл делает по сути то же самое
СкриншотDmitriyPopov
08.02.2016 11:53как это делают все остальные
А кого Вы имеете ввиду, когда пишете «все остальные»?
Не могли бы вы рассказать — у каких других вебмастерских сервисов есть «подтверждение через текстовые файлы»? Я может быть плохо искал?zapimir
08.02.2016 12:03Не обязательно вебмастерские, любые другие сервисы которые требуют подтверждение владением сайта. А это различные конторы выдающие SSL-сертификаты, рекламные сети, платежные системы и т.п. Да у самого Яндекса есть проверка по html, или чтобы найти на сайте нужный хэш его обязательно нужно в html заворачивать?

booomerang
08.02.2016 01:06-19Являясь закоренелым любителем почитать логи...
К сожалению, я не большой любитель копания кода...
Почему я замечаю, такие ненужные факты об авторе?!

ONEGiN
08.02.2016 02:29+5В чем магия чисел 41337 313373?

Psychosynthesis
08.02.2016 13:48+3Это были времена, когда в половине программ русский шрифт не поддерживался и «cool-][ацкеры» изгалялись с написанием собственных ников любыми способами. Хотя память мне подсказывает, что 31337 началось гораздо раньше и появилось ещё во времена Митника за Океаном. В общем, было дело, 31337 читали как eleet, аля «элитный» (хотя элита и пишется через i). А автор, видимо, с последней тройкой просто ошибся.

Untosh
09.02.2016 11:28+2Вряд ли автор ошибся. Ведь в слове elite на конце есть буква e. Так почему бы дополнительно троечку не добавить? Сумма-то гораздо внушительнее получилась бы без потери смысла. :)
fso
08.02.2016 02:39+1Не покидает мысль, что в таком случае содержимое txt (и html) файла, которое однозначно определяется именем, не имеет особого значения.
Труда не составит и сформировать корректное «содержимое» файла с именем yandex_0123456ABCDEF.html в виде
<html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> </head> <body>Verification: 0123456ABCDEF<</body> </html>
Тоесть на запрос бота яндекса, легко отдается «корректный» проверочный файл. Хорошая идея для плагина вордпресса — «автоподтвержение в яндексе».
mapron
08.02.2016 03:17+1А как сайт узнает, на какой из 20 запросов бота яндекса, нужно ответить верным кодом? фишка подтверждения, что их этих запросов какой-то случайный есть с реальным кодом, остальные — нет.
fso
08.02.2016 03:37+1Либо последовательность 404-200-404, либо случайно. Возможно, для html-файла бот делает один или несколько предсказуемых запросов, не смотрел.

TheMengzor
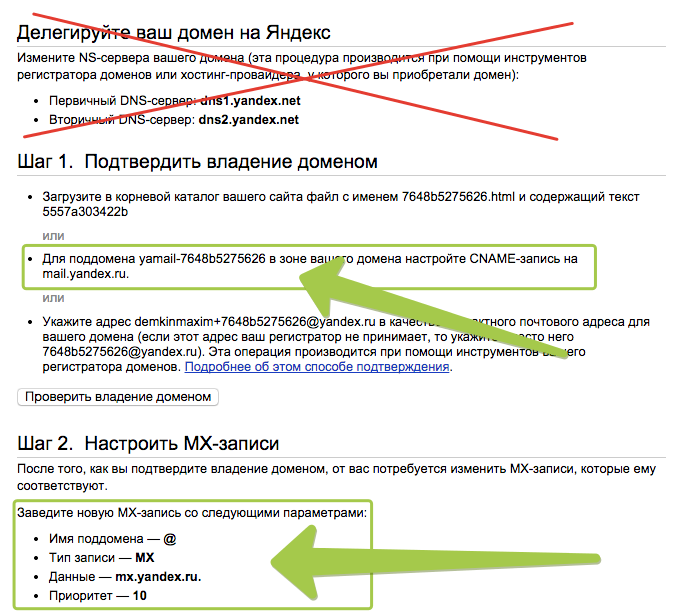
09.02.2016 13:05Удивительно, что у Яндекс Почты для Доменов верификация идет по имени файла и его контенту.
Нашел вот чужой скриншот в интернетах.




EnterSandman
Достаточно было бы проверять не только наличие файла, но и его содержимое
Delphinum
На деле это решение все равно потребовало бы от вебмастеров переподтверждения. Потому поддерживаю Яндекс, смысла в этом способе нет, если подтверждение через HTML по сути то же самое.
Borz
чем отличается от проверки HTML файла? и как это поможет человеку с тысячей сайтов, если раньше достаточно было пустого файла?
grishkaa
В HTML файл надо положить определённую строку, которую тоже даёт яндекс (и которую он тоже проверяет).
Borz
вот и я про то — чем отличается требование «положить определённую строку в HTML файл» от «положить определённую строку в TXT файл»? Не предлагаете же в TXT проверять просто сам факт наличия содержимого в TXT файле