
С помощью стандартных элементов тест-плана в Jmeter можно сделать многое, но далеко не всё. Для расширения функциональности и реализации более сложной логики принято использовать BeanShell Sampler — как-то во всём мире так исторически сложилось. И во всём мире от этого периодически страдают, но продолжают есть кактус.
В принципе для достижения наилучших результатов с точки зрения производительности самой нагрузочной станции эффективнее всего будет реализовать свой Java Request или даже написать собственный сэмплер. Но лично мне такое решение не нравится из-за:
Так что я всегда старался избегать такого решения (и пока избежал!). Мне лично нравится, когда код находится в самом тест-плане, причём можно отследить время на выполнение этого кода средствами JMeter. В этом смысле сам подход BeanShell сэмплера весьма удобен, плоха лишь его реализация. Расскажу почему.

Однажды мы разрабатывали высоконагруженный тест-план, использующий вставки кода в BeanShell Sampler. На этапе разработки всё шло прекрасно, но когда мы начали пробные запуски нагрузочных тестов, то столкнулись с очень неприятным поведением. На определённом количестве потоков всё работало нормально. Но при увеличении числа потоков начинался какой-то неадекват. Тест сильно недобирал в целевой интенсивности нагрузки, а отчёты показывали, что время обработки отдельных сэмплеров BeanShell доходило до десятков секунд! Причём, сэмплеров BeanShell было довольно мало – один-два на тред-группу, и не сказать чтобы там происходило что-то сложное. Изучение параметров производительности самой нагрузочной станции не выявило каких-то проблем: загрузка CPU была процентов 20—30, памяти для процесса JMeter было достаточно и сборщик мусора своевременно её очищал. Ясно, что проблема в самом програмном коде JMeter'а или в реализации интерпретатора BeanShell. Игра с галкой Reset bsh.Interpreter ничего не даёт; мало того: в одном месте пишут, что лучше её поставить, чтобы не произошло перерасхода памяти, в другом — что из соображений производительности лучше снять.
Сообщения о подобных проблемах время от времени встречаются на форумах по JMeter и приходят в почтовой рассылке Apache JMeter User. Коллеги также жаловались на поведение некоторых тестов, но склонны были относить проблему к самому инструменту.
В JMeter есть очень похожий сэмплер, который называется JSR223 Sampler. Даже не просто сэмплер, а целое семейство: Sampler, Timer, Pre- и PostProcessor, Assertion, Timer и Listener. Документация по нему начинается с очень ободряющих слов о том, что данный сэмплер позволит добиться значительного улучшения производительности. Но внимательного читателя тут же расстраивает: чтобы добиться этого эффекта следует выбрать скриптовый движок, который поддерживает компиляцию. Тут же, рядом, указано, что движок для Java таковым не является.
Касательно Java я скажу даже больше: она реализуется тем же самым движком, что и BeanShell. В этом легко убедиться, вызвав ошибку в выполняемом коде. В стеке исключений в логе вы увидите, что и там, и там вызывается интерпретатор bsh. Поэтому абсолютно никакой разницы между JSR223/java и BeanShell Sampler не будет. Про остальные движки ничего не сказано, но они также все интерпретируемые. Таким образом в стандартной поставке JMeter нет движков, на которых можно было бы получить профит от компиляции.
Единственным упомянутым в документации компилируемым скриптовым движком является Groovy. Существуют и другие движки, поддерживающие JSR223. Я попробовал Scala, ужаснулся тому, как медленно работает эта связка и оставил эту тему до лучших времён. (Примечание: дело тут, наверное, не в Scala, а в реализации стандарта JSR 223 и в имплементации интерфейса Compilable.)
Чтобы включить поддержку Groovy, нужно скачать с сайта проекта или здесь последнюю версию бинарников. Из архива нам понадобится только один файл: embeddable\groovy-all-{version}.jar. Его нужно распаковать в папку lib Жиметра. После перезапуска программы в списке доступных языков JSR223 появится Groovy:
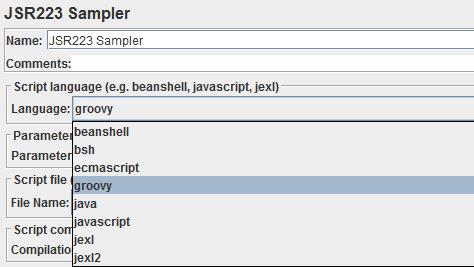
После того, как мы переделали все сэмплеры BeanShell нашего тест-плана на JSR223 + Groovy произошло прямо-таки чудо: всё стало работать как надо (ну или хотя бы как мы запрограммировали), без тормозов, а загрузка CPU стала даже ещё ниже. Время отклика сэмплеров JSR223 стало ниже на порядки и тест вышел на требуемую нагрузку.
Если возвращаться к тому, с чего мы начинали – различным способам реализации дополнительной программной логики – то решения с Groovy должно хватить на почти все случаи, за исключением разве что тех, где нужно выжимать реально проценты. Скрипты Groovy компилируются в обычный байт-код Java и выполняются в контексте каждого потока так, как будто это родной Java-код (но надо помнить, что компилятор у него свой, и накладные расходы на вызов движка всё же есть). Ребята из Blazemeter проводили сравнение скорости работы различных вариантов реализации и пришли к выводу, что код на Groovy лишь незначительно уступает по скорости коду на чистой Java.
Я также провёл небольшой эксперимент. Я написал небольшой фрагмент, выполняющие некие искусственные вычисления в целочисленной арифметике:
Зависимость от входных данных (Parameters) и запись в лог добавлены на всякий случай, чтобы не дать всяким хитрым компиляторам и интерпретаторам оптимизировать код, исключив его выполнение вообще или закэшировав результат. Причём Parameters также был уникальным. На моём ноутбуке с Core i7 при 100 потоках по 1000 итераций каждый результаты получились такие:
Отрыв Groovy столь значителен, что в это даже с трудом верится, тем не менее, судя по логу, всё отработало корректно.
Большим плюсом Groovy является то, что в 95% случаев произвольный код Java является валидным кодом Groovy. Даже синтаксис BeanShell отстоит дальше от текущего стандарта Java (например, в BeanShell вам приходится извращаться, в случае вызова функций с произвольным числом аргументов). Если вы не заинтересованы в том, чтобы прямо сейчас осваивать все его возможности, то и не надо. С другой стороны, если освоите — наверняка сможете повысить свою эффективность.
Если в BeanShell вы пользовались глобальным пространством имён bsh.shared, то здесь возникает небольшая засада: в Groovy ничего подобного нет. К счастью, эту проблему легко решить своими силами. Для этого пишутся 10 строк кода:
По сути это синглтон, который всегда (каждому потоку) вернёт один и тот же объект. Далее это собирается в jar и кладётся в папку lib Жиметра. Поскольку класс объявлен в глобальном пространстве имён (да, заслуживаю порицания за это), то в коде Groovy, без всяких import можно использовать SharedHashMap, чтобы что-нибудь туда положить:
Когда нужно забрать, то аналогично:
* в Groovy не обязательно объявление типов переменных, а также точки с запятыми.
Предположим, у вас уже есть тест-план в котором уже есть множество сэмплеров BeanShell, и вы нашли эту статью, потому что у вас возникла проблема. Вы хотите переключиться на использование Groovy. Подключение Groovy описано выше и займёт у вас не более пяти минут.
Прежде всего следует создать JSR223 Sampler и перенести в него код из BeanShell. Вы сможете существенно упростить себе жизнь, если сможете унифицировать код и выделить его в отдельный файл, указав его в поле File Name. Тогда вам останется просто вставить сэмплеры JSR223 в нужные места при помощи Copy/Paste. Если нет, копируйте в каждом случае код из BeanShell.
Ключ кэширования
Тут важно отметить, что JMeter будет компилировать код, введённый в самом сэмплере, только если указан ключ компиляции (поле Compilation Cache Key). Это должна быть просто строка, уникальная в пределах тест-плана. Для скриптов, подключаемых через файлы, ключ компиляции вводить не нужно, в качестве него используется полный путь к файлу.
Есть одна тонкость в синтаксисе Groovy. Во-первых там есть два типа строк:
Подробнее см. тут. В строках Groovy есть возможность использовать выражения типа ${expression}, которые автоматически раскрываются внутри строк в значение expression. Это довольно удобный момент, но он удивительным образом совпадает по синтаксису со ссылкой на переменные JMeter. Поэтому если вы пишете в Groovy
и при этом в текущем потоке определена обычная переменная JMeter c именем currId, то её значение будет подставлено непосредственно в скрипт. Кроме того, подставлено один раз, т.к. после этого код будет скомпилирован, а результат закэширован. Поэтому надо следить, чтобы имена переменных, используемые в таких выражениях, не пересекались с переменными JMeter. А если вам действительно нужно передать значение в сэмплер JSR223, то нужно использовать для этого поле Parameters.
При использовании внешнего файла в качестве исходного кода подстановок переменных JMeter не происходит (они происходят только в полях), но использовать Parameters можно.
Если вы не планируете использовать возможности строк Groovy, то желательно использовать строки Java (т.е. в одинарных кавычках). К тому же это будет лучше для производительности, хотя и копейки, конечно.
Поведение сэмплера BeanShell иллюстрирует типичную проблему интерпретатора: низкая скорость работы интерпретируемого кода. Если у вас в BeanShell всего несколько строк, вы, вероятно, не заметите проблем, но точно заметите, если кода много или если там есть циклы. Точно такая же проблема наблюдалась и в интерпретаторе LoadRunner.
Если у вас пока не возникало проблем с запуском теста, использующего BeanShell, то я рекомендовал бы перестраховаться и не создавать их себе в будущем. Вместо этого лучше сразу использовать JSR223 + Groovy, таким образом, уменьшая вероятность появления проблем с производительностью нагрузочных станций.
Важные моменты, которые стоит вынести из статьи.
Как же без него?
В принципе для достижения наилучших результатов с точки зрения производительности самой нагрузочной станции эффективнее всего будет реализовать свой Java Request или даже написать собственный сэмплер. Но лично мне такое решение не нравится из-за:
- больших трудозатрат на разработку решения;
- непрозрачной поддержки решения (код лежит в другом месте, его нужно перекомпилировать при помощи дополнительных действий);
- возможной потери бонусов, которые даёт JMeter (например, если у вас в коде реализован запрос в СУБД, а потом HTTP-запрос, то увидите вы в статистике их в сумме, а не по отдельности).
Так что я всегда старался избегать такого решения (и пока избежал!). Мне лично нравится, когда код находится в самом тест-плане, причём можно отследить время на выполнение этого кода средствами JMeter. В этом смысле сам подход BeanShell сэмплера весьма удобен, плоха лишь его реализация. Расскажу почему.
Чем плох BeanShell Sampler

Однажды мы разрабатывали высоконагруженный тест-план, использующий вставки кода в BeanShell Sampler. На этапе разработки всё шло прекрасно, но когда мы начали пробные запуски нагрузочных тестов, то столкнулись с очень неприятным поведением. На определённом количестве потоков всё работало нормально. Но при увеличении числа потоков начинался какой-то неадекват. Тест сильно недобирал в целевой интенсивности нагрузки, а отчёты показывали, что время обработки отдельных сэмплеров BeanShell доходило до десятков секунд! Причём, сэмплеров BeanShell было довольно мало – один-два на тред-группу, и не сказать чтобы там происходило что-то сложное. Изучение параметров производительности самой нагрузочной станции не выявило каких-то проблем: загрузка CPU была процентов 20—30, памяти для процесса JMeter было достаточно и сборщик мусора своевременно её очищал. Ясно, что проблема в самом програмном коде JMeter'а или в реализации интерпретатора BeanShell. Игра с галкой Reset bsh.Interpreter ничего не даёт; мало того: в одном месте пишут, что лучше её поставить, чтобы не произошло перерасхода памяти, в другом — что из соображений производительности лучше снять.
Сообщения о подобных проблемах время от времени встречаются на форумах по JMeter и приходят в почтовой рассылке Apache JMeter User. Коллеги также жаловались на поведение некоторых тестов, но склонны были относить проблему к самому инструменту.
Что делать
В JMeter есть очень похожий сэмплер, который называется JSR223 Sampler. Даже не просто сэмплер, а целое семейство: Sampler, Timer, Pre- и PostProcessor, Assertion, Timer и Listener. Документация по нему начинается с очень ободряющих слов о том, что данный сэмплер позволит добиться значительного улучшения производительности. Но внимательного читателя тут же расстраивает: чтобы добиться этого эффекта следует выбрать скриптовый движок, который поддерживает компиляцию. Тут же, рядом, указано, что движок для Java таковым не является.
Касательно Java я скажу даже больше: она реализуется тем же самым движком, что и BeanShell. В этом легко убедиться, вызвав ошибку в выполняемом коде. В стеке исключений в логе вы увидите, что и там, и там вызывается интерпретатор bsh. Поэтому абсолютно никакой разницы между JSR223/java и BeanShell Sampler не будет. Про остальные движки ничего не сказано, но они также все интерпретируемые. Таким образом в стандартной поставке JMeter нет движков, на которых можно было бы получить профит от компиляции.
Единственным упомянутым в документации компилируемым скриптовым движком является Groovy. Существуют и другие движки, поддерживающие JSR223. Я попробовал Scala, ужаснулся тому, как медленно работает эта связка и оставил эту тему до лучших времён. (Примечание: дело тут, наверное, не в Scala, а в реализации стандарта JSR 223 и в имплементации интерфейса Compilable.)
Чтобы включить поддержку Groovy, нужно скачать с сайта проекта или здесь последнюю версию бинарников. Из архива нам понадобится только один файл: embeddable\groovy-all-{version}.jar. Его нужно распаковать в папку lib Жиметра. После перезапуска программы в списке доступных языков JSR223 появится Groovy:

После того, как мы переделали все сэмплеры BeanShell нашего тест-плана на JSR223 + Groovy произошло прямо-таки чудо: всё стало работать как надо (ну или хотя бы как мы запрограммировали), без тормозов, а загрузка CPU стала даже ещё ниже. Время отклика сэмплеров JSR223 стало ниже на порядки и тест вышел на требуемую нагрузку.
Производительность Groovy
Если возвращаться к тому, с чего мы начинали – различным способам реализации дополнительной программной логики – то решения с Groovy должно хватить на почти все случаи, за исключением разве что тех, где нужно выжимать реально проценты. Скрипты Groovy компилируются в обычный байт-код Java и выполняются в контексте каждого потока так, как будто это родной Java-код (но надо помнить, что компилятор у него свой, и накладные расходы на вызов движка всё же есть). Ребята из Blazemeter проводили сравнение скорости работы различных вариантов реализации и пришли к выводу, что код на Groovy лишь незначительно уступает по скорости коду на чистой Java.
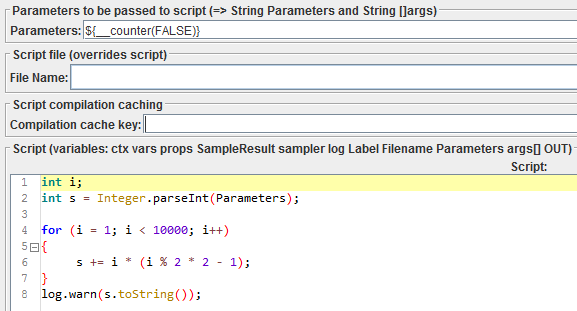
Я также провёл небольшой эксперимент. Я написал небольшой фрагмент, выполняющие некие искусственные вычисления в целочисленной арифметике:
int i;
int s = Integer.parseInt(Parameters);
for (i = 1; i < 10000; i++)
{
s += i * (i % 2 * 2 - 1);
}
log.warn(s.toString());
Зависимость от входных данных (Parameters) и запись в лог добавлены на всякий случай, чтобы не дать всяким хитрым компиляторам и интерпретаторам оптимизировать код, исключив его выполнение вообще или закэшировав результат. Причём Parameters также был уникальным. На моём ноутбуке с Core i7 при 100 потоках по 1000 итераций каждый результаты получились такие:
| Имплементация | Throughput |
|---|---|
| BeanShell Sampler | ~20 / sec |
| JSR223 + (java | beanshell | bsh) | ~20 / sec |
| JSR223 + Groovy | ~13800 / sec |
Отрыв Groovy столь значителен, что в это даже с трудом верится, тем не менее, судя по логу, всё отработало корректно.
Java как подмножество Groovy
Большим плюсом Groovy является то, что в 95% случаев произвольный код Java является валидным кодом Groovy. Даже синтаксис BeanShell отстоит дальше от текущего стандарта Java (например, в BeanShell вам приходится извращаться, в случае вызова функций с произвольным числом аргументов). Если вы не заинтересованы в том, чтобы прямо сейчас осваивать все его возможности, то и не надо. С другой стороны, если освоите — наверняка сможете повысить свою эффективность.
bsh.shared
Если в BeanShell вы пользовались глобальным пространством имён bsh.shared, то здесь возникает небольшая засада: в Groovy ничего подобного нет. К счастью, эту проблему легко решить своими силами. Для этого пишутся 10 строк кода:
import java.util.concurrent.ConcurrentHashMap;
public class SharedHashMap
{
private static final ConcurrentHashMap instance = new ConcurrentHashMap();
public static ConcurrentHashMap GetInstance()
{
return instance;
}
}
По сути это синглтон, который всегда (каждому потоку) вернёт один и тот же объект. Далее это собирается в jar и кладётся в папку lib Жиметра. Поскольку класс объявлен в глобальном пространстве имён (да, заслуживаю порицания за это), то в коде Groovy, без всяких import можно использовать SharedHashMap, чтобы что-нибудь туда положить:
// Получаем ссылку на глобальный hash map.
sharedHashMap = SharedHashMap.GetInstance()
// Кладём туда что-нибудь.
sharedHashMap.put('Counter', new java.util.concurrent.atomic.AtomicInteger())
Когда нужно забрать, то аналогично:
sharedHashMap = SharedHashMap.GetInstance() // *
counter = sharedHashMap.get('Counter')
counter.incrementAndGet()
//..
* в Groovy не обязательно объявление типов переменных, а также точки с запятыми.
Миграция с BeanShell Sampler
Предположим, у вас уже есть тест-план в котором уже есть множество сэмплеров BeanShell, и вы нашли эту статью, потому что у вас возникла проблема. Вы хотите переключиться на использование Groovy. Подключение Groovy описано выше и займёт у вас не более пяти минут.
Прежде всего следует создать JSR223 Sampler и перенести в него код из BeanShell. Вы сможете существенно упростить себе жизнь, если сможете унифицировать код и выделить его в отдельный файл, указав его в поле File Name. Тогда вам останется просто вставить сэмплеры JSR223 в нужные места при помощи Copy/Paste. Если нет, копируйте в каждом случае код из BeanShell.
Ключ кэширования
Тут важно отметить, что JMeter будет компилировать код, введённый в самом сэмплере, только если указан ключ компиляции (поле Compilation Cache Key). Это должна быть просто строка, уникальная в пределах тест-плана. Для скриптов, подключаемых через файлы, ключ компиляции вводить не нужно, в качестве него используется полный путь к файлу.
Строки Java и Groovy
Есть одна тонкость в синтаксисе Groovy. Во-первых там есть два типа строк:
- в двойных кавычках — строки Groovy
- в одинарных кавычках — строки Java
Подробнее см. тут. В строках Groovy есть возможность использовать выражения типа ${expression}, которые автоматически раскрываются внутри строк в значение expression. Это довольно удобный момент, но он удивительным образом совпадает по синтаксису со ссылкой на переменные JMeter. Поэтому если вы пишете в Groovy
currId = 123
log.info("Current ID: ${currId}")
и при этом в текущем потоке определена обычная переменная JMeter c именем currId, то её значение будет подставлено непосредственно в скрипт. Кроме того, подставлено один раз, т.к. после этого код будет скомпилирован, а результат закэширован. Поэтому надо следить, чтобы имена переменных, используемые в таких выражениях, не пересекались с переменными JMeter. А если вам действительно нужно передать значение в сэмплер JSR223, то нужно использовать для этого поле Parameters.

При использовании внешнего файла в качестве исходного кода подстановок переменных JMeter не происходит (они происходят только в полях), но использовать Parameters можно.
Если вы не планируете использовать возможности строк Groovy, то желательно использовать строки Java (т.е. в одинарных кавычках). К тому же это будет лучше для производительности, хотя и копейки, конечно.
Заключение
Поведение сэмплера BeanShell иллюстрирует типичную проблему интерпретатора: низкая скорость работы интерпретируемого кода. Если у вас в BeanShell всего несколько строк, вы, вероятно, не заметите проблем, но точно заметите, если кода много или если там есть циклы. Точно такая же проблема наблюдалась и в интерпретаторе LoadRunner.
Если у вас пока не возникало проблем с запуском теста, использующего BeanShell, то я рекомендовал бы перестраховаться и не создавать их себе в будущем. Вместо этого лучше сразу использовать JSR223 + Groovy, таким образом, уменьшая вероятность появления проблем с производительностью нагрузочных станций.
Важные моменты, которые стоит вынести из статьи.
- Не следует использовать BeanShell Sampler, вместо него пользуемся JSR223 + Groovy.
- JSR223 + java = тот же BeanShell, поэтому см. п. 1.
- Если есть возможность унифицировать код нескольких JSR223, то используем внешний файл. Помимо того, что устранение дублирования кода само по себе есть хороший стиль программирования, при этом не нужно заботиться о Compilation Cache Key.
- Если пользуемся встроенным в сэмплер скриптом, не забываем про Compilation Cache Key.
- Если нужен аналог bsh.shared, используем приведённое выше решение.