
Впрочем, ругать других всегда легко, а вот сделать что-то работающее бывает не так просто. Мне стало любопытно, можно ли сделать чатбот не ручным заполнением шаблонов ответа, а с помощью обучения нейронной сети на образцах диалогов. Быстрый поиск в Интернете полезной информации не дал, поэтому я решил быстро сделать пару экспериментов и посмотреть что получится.
Обычный чатбот ограничен поверхностными ответами, которые определены заданными шаблонами. Обучаемый чатбот (есть и такие) ищет ответы на похожие вопросы в своей базе диалогов, и иногда даже создавать новые шаблоны. Но все равно «ум» его обычно строго ограничен сверху заданным алгоритмом. А вот бот с нейронной сетью, работающей по принципу вопрос на входе — ответ на выходе — теоретически ничем не ограничен. Есть работы, в которых показано, что нейронные сети могут выучивать правила логического вывода получая на вход предложения на естественном языке, а также отвечать на вопросы касающиеся различных текстов. Но мы не будем пока столь амбициозны в замашках и попробуем просто получить что-то напоминающее ответы типового чатбота.
В качестве исходных данных быстро нашелся только транскрипт диалога на английском языке (состоявший из 3860 реплик). Ну, для опыта сойдет, поскольку с нашим подходом язык принципиальной разницы не имеет. Для начала, чтобы было с чем сравнивать, я наскоро собрал простой чатбот, подбирающий готовые ответы из транскрипта, на основании совпадений слов в фразах собеседника (по косинусу угла между векторами вопроса и ответа, представляющих собой «сумки слов»). Вся программа уместилась строчек на 30:
Вот что получилось:
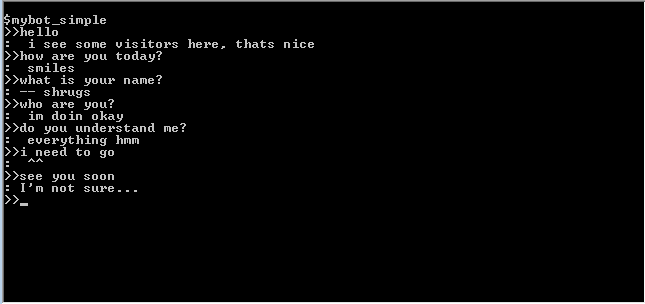
Перевод (примерный) (Ч: — человек, П: — программа):
Ч: привет
П: я вижу посетителей здесь, это хорошо
Ч: Как дела
П: улыбается
Ч: как тебя зовут?
П: пожимает плечами
Ч: Кто ты?
П: у меня все хорошо
Ч: ты понимаешь меня?
П: Абсолютно все, хмм…
Ч: Мне надо идти
П: ^^
Ч: увидимся позже
П: Я не уверена
При поверхностном опросе отвечает довольно неплохо для такой простой программы, не знает правда как ее зовут и кто такая… но тем не менее, определенное ощущение присутствия складывается — хорошая иллюстрация к тому, что мы склонны к чрезмерному одушевлению реально простых алгоритмов (или может быть просто 90% всего общения — поверхностное?).
Обратимся теперь к более сложным алгоритмам. Сразу скажу — сложнее здесь не значит сразу лучше, ибо шаблонные чатботы создаются с целью «обмана» пользователя, и используют разные трюки для создания иллюзии общения, а наша задача обойтись без обмана.
Как сгенерировать текст с помощью нейронной сети? Классический сейчас уже способ для этого — нейронная модель языка (neural language model). Суть заключается в том, что нейронной сети дается задание предсказать следующее слово, исходя из n-предыдущих. Слова на выходе кодируются по принципу один выходной нейрон — одно слово (см рис). Входные слова можно кодировать таким же образом, или использовать распределенное представление слов в векторном пространстве, где близкие по смыслу слова находятся на меньшем расстоянии, чем слова с разным смыслом.
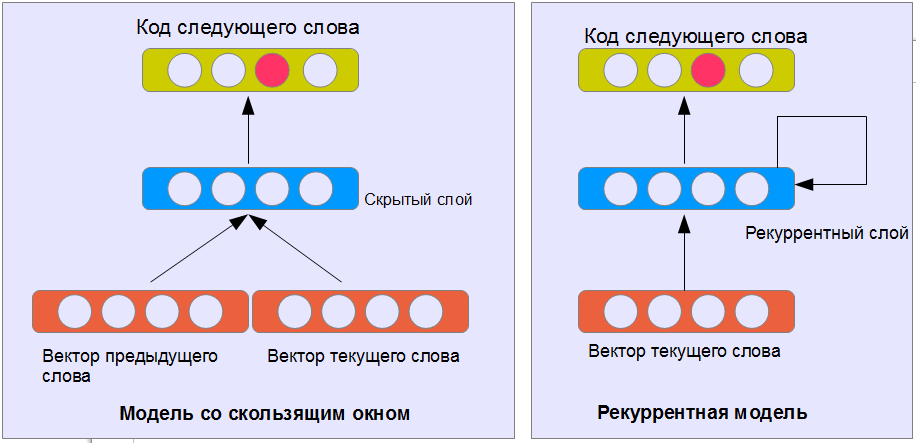
Обученной нейронной сети можно дать начало текста и получить предсказание его окончания (добавляя последнее предсказанное слово в конец и применяя нейронную сеть к новому, удлиненному тексту). Таким образом, можно создать модель ответов. Одна беда — ответы никак не связаны с фразами собеседника.
Очевидное решение проблемы — подать на вход представление предыдущей фразы диалога. Как это сделать? Два из многих возможных способов мы рассмотрели в предыдущей статье про классификацию предложений. Самый простой вариант NBoW – использовать сумму всех векторов слов предыдущей фразы.
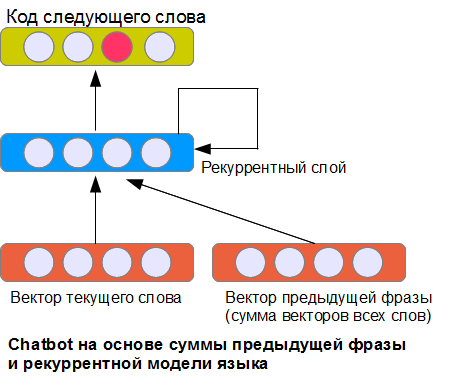
Показанная на картинке архитектура — далеко не единственная из возможных, но, пожалуй, одна из самых простых. Рекуррентный слой получает на вход данные относительно текущего слова, вектор, представляющий предыдущую фразу, а также свои собственные состояния на предыдущем шаге (поэтому он и называется рекуррентный). За счет этого нейронная сеть (теоретически) может помнить информацию о предыдущих словах на неограниченную длину фразы (в противоположность реализации, где учитываются только слова из окна фиксированного размера). На практике, конечно, такой слой представляет определенные трудности в обучении.
После обучения сети получилось следующее:
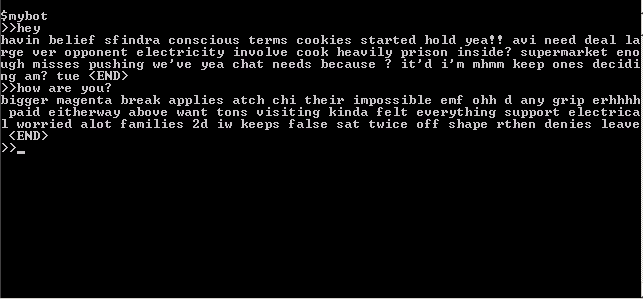
мда… более или менее бессмысленный набор слов. Нет какие-то связи между словами и логика в построении предложений имеется, но общего смысла нет, и связи с вопросами тоже нет никакой (по крайней мере я не вижу). Кроме того, бот чрезмерно болтлив — слова складываются в большие длинные цепочки. Причин этому много — это и маленький (около 15000 слов) объем обучающей выборки, и сложности в тренировке рекуррентной сети, которая реально видит контекст в два-три слова, и поэтому легко теряет нить повествования, и недостаточная выразительность представления предыдущей фразы. Собственно, это и ожидалось, и привел я этот вариант, чтобы показать, что в лоб проблема не решается. Хотя, на самом деле, правильным подбором алгоритма обучения и параметров сети можно добиться более интересных вариантов, но они будут страдать такими проблемами, как многократное повторение фраз, трудности с выбором места окончания предложения, будут копировать длинные фрагменты из исходной обучающей выборки и т. п. Кроме того, такую сеть тяжело анализировать — непонятно, что именно выучено и как работает. Поэтому, не будем тратить время на разбор возможностей этой архитектуры и попробуем более интересный вариант.
Во втором варианте я соединил сверточную сеть, описанную в предыдущей статье, с рекуррентной моделью языка:
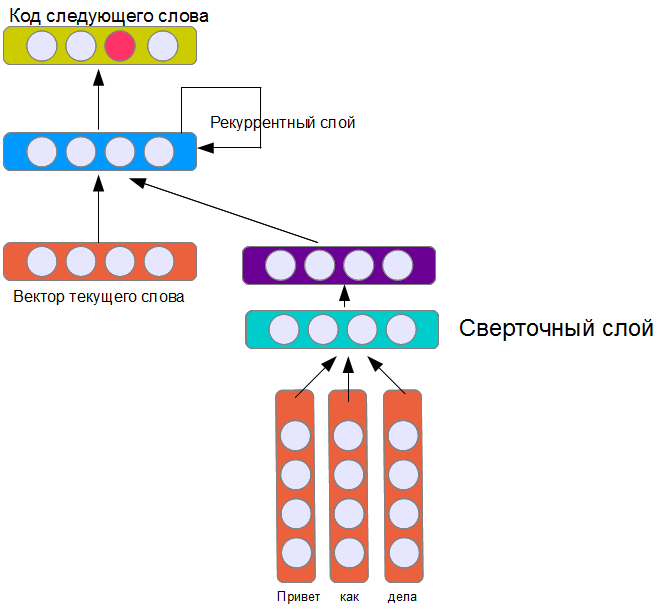
Подобно сети из предыдущей статьи, сверточный слой содержит 16 фильтров. Из общих соображений можно ожидать, что обучатся эта модель из четырех слоев будет труднее и результат будет хуже. Кроме того, 16 фильтров кажется явно недостаточным для создания модели реплики собеседника. Действительно, ее обучение занимает гораздо больше времени, но результат… в общем, судите сами:
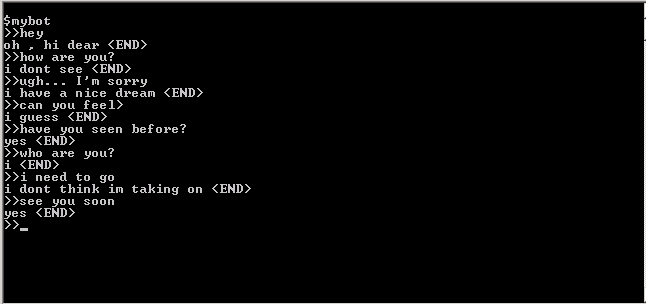
Перевод (примерный) диалога (Ч: — человек, П: — программа)
Ч: привет
П: ох, привет
Ч: как дела?
П: Я не могу видеть
Ч: упс… ну извини
П: похоже мне сниться хороший сон
Ч: ты можешь чувствовать?
П: Я полагаю
Ч: Ты могла видеть раньше?
П: Да
Ч: Кто ты?
П: Я
Ч: Мне пора идти
П: Я не уверена, что могу принять это
Ч: увидимся позже
П: Да
На мой взгляд достаточно эффектно. Напоминает фрагменты из фантастических романов, где искусственный интеллект оживает в компьютере, особенно утверждения программы, что она не может видеть, но могла видеть раньше. Впору заявлять о создании ИИ и великом достижении…
На самом деле, конечно, никаким разумом эта нейронная сеть не обладает, что не делает ее, правда менее интересной. Дело в том, что мы может проанализировать, что на самом деле было выучено, проследив зависимость активации нейронов сверточного слоя от входных фраз. Путем такого анализа, удалось обнаружить нейрон, реагирующий на слова приветствия («hello», «hi», «he»y и т. п.), а также нейрон, распознающий вопросительные фразы типа «have you … ?» — при этом знак вопроса не обязателен (на них нейронная сеть выучилась отвечать обычно «yes”), кроме того, если в вопросе фигурирует слово „you” (“ты»), повышается вероятность того, что ответ будет начинаться со слова «I” (“я»).
Таким образом, нейронная сеть выучила некоторые типичные шаблоны разговора и языковые трюки, которые часто используются при программировании чатботов «вручную», хорошо распорядившись имеющимися в наличии 16-ю фильтрами. Не исключено, что заменив простую сверточную сеть на многослойную, добавив фильтров и увеличив объем обучающей выборки, можно получить чатботы, которые будут казаться более «умными» нежели их аналоги, основанные на ручном подборе шаблонов. Но этот вопрос уже за пределами нашей статьи.
Комментарии (9)


0x0FFF
30.04.2015 10:09+3Было бы интересно взглянуть на ваш код

darkrain
30.04.2015 10:20Да, было бы круто это видеть на гитхабе, я бы с удовольствием поучавствовал в разработке, как раз бьюсь над этим в последнее время и вот неделю назад у меня такая же появилась идея соединить сверточную сеть с рекурентной моделью языка.
Я думаю многие бы поучавствовали)
Durham Автор
30.04.2015 13:47+2Не ожидал, что будет интерес. Прямо сейчас код не годится для выкладывания, но раз есть потребность, попробуем привести в порядок, и сделать доступным для использования.
darkrain
01.05.2015 08:26Да, только не уходите в перфекционизм) в общем держите нас в курсе) подписался на вашу компанию, все посты очень годные.

Tiendil
30.04.2015 11:08Но все равно «ум» его обычно строго ограничен сверху заданным алгоритмом. А вот бот с нейронной сетью, работающей по принципу вопрос на входе — ответ на выходе — теоретически ничем не ограничен
Крайне странное утверждение. Нейронная сеть — тоже алгоритм, так что либо оба варианта ограничены либо оба не ограничены.Durham Автор
30.04.2015 13:05Без контекста утверждение действительно звучит странно. Но имелось в виду вот что: типичный алгоритм обучения чат-бота не отличается особыми возможностями. Достаточно продвинутые варианты могут, например, из фразы «ты смотрел фильм „Матрица“?» запомнить, что «Матрица» — это фильм, используя скажем шаблон «ты смотрел… фильм yyy». В результате чатбот будет обучатся, но только тому, что предусмотрено заранее, т.е. он не выучит никогда арифметику, логику, и даже не сможет обобщить названия фильмов, на названия, скажем, цветов, если это не предусмотрено разработчиком. Поэтому, в случае чатбота, как правило, если функция обучения чему-то не явно предусмотрена и тщательно не продумана, то такое обучение останется для него невозможным. То есть, здесь имеется в виду, не любой алгоритм обучения вообще, а набор средств, который обычно используется для создания чатботов.
Нейронные сети, теоретически, могут реализовывать любую вычислимую функцию, а следовательно, в принципе, их можно обучить тому, чему бот, скажем на AIML никогда не сможет. В этом смысле идея привлекательна — мы загрузим много много примеров диалогов, и получим думающий компьютер на выходе. На практике, конечно, такое пока не получается из-за ряда ограничений.

Equin0x
02.05.2015 19:27Сотовые провайдеры с их логами SMS переписок дадут всем фору в имитации общения на любую тему )
alterpub
Достал дробовик и пристрелил.