

Первая статья посвящается основным элементам Flume, их настройкам и способам запуска Flume. На просторах Хабра уже имеется статья о том, как работать с Flume, поэтому некоторые базовые разделы будут во многом схожи с ней.
В продолжении цикла я постараюсь более подробно осветить каждый из компонентов Flume, рассказать о том, как настроить мониторинг для него, написать свою реализацию одного из элементов и многое другое.
1. Что такое Flume?
Flume представляет собой инструмент, позволяющий управлять потоками данных и, в конечном счете, передавать их на некоторый “пункт назначения” (например, в файловую систему или HDFS).
В целом, организация транспортировки данных посредством Flume напоминает создание эдакого “конвейера” или “водопровода”. Этот “конвейер” состоит из различных участков (узлов), на которых и происходит управление потоком данных (фильтрация, разделение потока и т.п.).
Flume является надежным и удобным инструментом для транспортировки данных. Надежность обеспечивается в первую очередь транзакционностью передачи данных. Т.е. при правильной настройке цепочки узлов Flume не может быть ситуации, при которой данные потеряются или будут переданы не полностью. Удобство же заключается в гибкости конфигурации — большинство задач решаются добавлением в конфигурацию нескольких параметров, а более сложные могут быть решены путем создания собственных элементов Flume.
Для начала обозначим основные термины, а затем мы рассмотрим структуру одиночного узла Flume.
2. Основные термины
- Событие (event) — единица данных с дополнительной мета-информацией. По структуре событие напоминает POST-запрос.
- Заголовки (headers) — мета-информация, набор пар “ключ”-”значение”.
- Содержимое (body) — собственно, данные, ради передачи которых всё затевается. Передается как byte[].
- Клиент (client) — внешний, по отношению к узлу Flume, сервис, поставляющий данные.
- Источник (source) — отвечает за прием данных. При этом Flume предусматривает два типа источников — EventDrivenSource и PollableSource. В первом случае источник сам решает, когда добавлять события в канал (например, HTTPSource добавляет события по мере получения HTTP-запросов). PollableSource в противовес EventDrivenSource является пассивным — Flume просто периодически опрашивает источник на предмет появления новых событий.
- Сток (Sink) — компонент, отвечающий за передачу данных на следующий этап обработки. Это может быть другой узел Flume, файловая система, HDFS и т.п.
- Канал (channel) — компонент, выполняющий роль буфера при транспортировке данных. Канал является пассивным компонентом, он самостоятельно не инициирует никаких действий. Источники добавляют события в канал, в то время как стоки его опустошают.
- Агент (agent) — процесс, в рамках которого функционируют компоненты Flume (источники, каналы, стоки). JVM Instance, в общем. Один узел может содержать несколько агентов.
3. Структура узла Flume
Правильнее было бы назвать этот подраздел “Структура агента Flume”, т.к. узел Flume может состоять из нескольких агентов. Но в рамках данной статьи все примеры будут приводиться как “один узел — один агент”, поэтому я позволю себе вольность и пока не буду разделять эти понятия.
Рассмотрим несколько конфигураций для различных жизненных случаев.
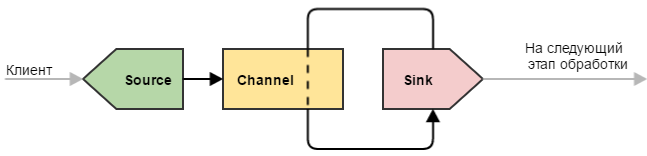
Простой узел
Под простым узлом я подразумеваю самую минималистичную конфигурацию Flume, которая только может быть: источник → канал → сток.
Такую конфигурацию можно использовать для простых целей — например, узел является замыкающим в цепочке узлов нашего «водопровода» и выполняет всего одну роль: принимает данные и записывает их в файл (непосредственно записью занимается сток). Или же узел является промежуточным и просто передает данные дальше (иногда это полезно делать для обеспечения отказоустойчивости — например, развернуть такой узел на машине с Flume-клиентом, чтобы избежать потери данных при проблемах с сетью).
Делитель
Более сложный пример, который может быть использован для разделения данных. Здесь ситуация немного другая по сравнению с одиночным стоком: наш канал опустошают два стока. Это приводит к тому, что поступающие события делятся между двумя стоками (не дублируются, а именно делятся). Такую конфигурацию можно использовать, чтобы разделить нагрузку между несколькими машинами. При этом, если одна из конечных машин выйдет из строя и привязанный к ней сток не сможет отправлять на нее события, другие стоки продолжат работу в штатном режиме. Естественно, что при этом работающей машине придется отдуваться за двоих.

Примечание: Flume располагает более тонкими инструментами для балансировки нагрузки между стоками, для этого используются Flume Sink Processor’ы. О них речь пойдет в следующих частях цикла.
Дубликатор
Такой узел Flume позволяет отправлять одни и те же события на несколько стоков. Может возникнуть вопрос — а зачем два канала, разве не может канал дублировать события сразу на два стока? Ответ — нет, поскольку не «канал раздает события», а «сток опустошает канал». Даже если бы такой механизм и существовал, то выход из строя одного из стоков привел бы к неработоспособности других (т.к. каналу бы пришлось работать по принципу “либо все смогли, либо никто”). Это объясняется тем, что при сбое на уровне стока отсылаемая пачка событий не исчезает «в никуда», а остается лежать в канале. Ибо транзакция.
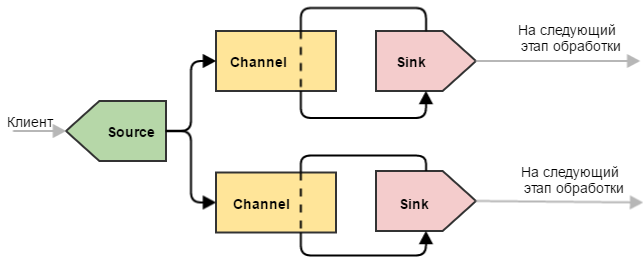
Примечание: в данном примере используется безусловное дублирование — т.е. в оба канала копируется все подряд. Flume позволяет не дублировать, а разделять события по некоторым условиям — для этого используется Flume Channel Selector. О нем речь также пойдет в следующих статьях цикла.
Универсальный приемник
Еще один полезный вариант конфигурации — с несколькими источниками. Крайне полезная конфигурация, когда необходимо “слить воедино” однотипные данные, полученные различными способами.
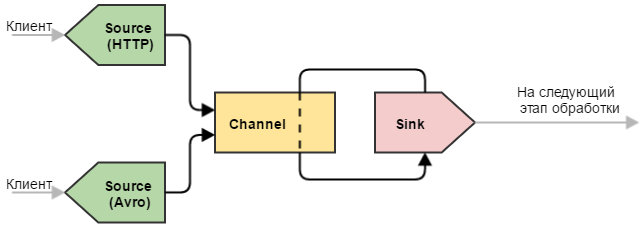
Резюме:
- Узел может иметь в своем составе множество источников, каналов и стоков.
- Один источник может складывать события в несколько каналов (дублировать или распределять по некоторому правилу).
- Несколько источников складывать события в один канал.
- Один сток может работать только с одним каналом.
- Несколько стоков могут забирать события из одного канала (равномерно или по некоторому правилу балансировки).
4. Конфигурация и запуск узла Flume
Думаю, пришло время практических примеров. Стандартный пакет Flume содержит множество реализаций источников/каналов/стоков для разных случаев жизни — описание по их настройке можно найти здесь. В рамках этой статьи я ограничусь самыми простыми реализациями компонентов:
- Memchannel (канал, использующий оперативную память для хранения событий).
- NetCat Source.
- Logger Sink (сток, выводящий события в консоль).
Пожалуй так выглядит самая простая конфигурация для узла Flume:
### ==================== Компоненты узла ==================== ###
# Перечисляем все основные компоненты, из которых будет состоять наш узел: источники, каналы и узлы
# <agent>.sources - имена источников, разделенные пробелом (в этом примере один источник: my_source)
my-agent.sources = my-source
# <agent>.channels - аналогично указываем имена каналов
my-agent.channels = my-channel
# <agent>.sinks - для стоков то же самое
my-agent.sinks = my-sink
### ==================== Источник my_source ================== ###
# Тип источника - netcat (источники из стандартной поставки Flume имеют зарезервированные имена-псевдонимы,
# в общем случае здесь можно указать полное имя класса источника, в т.ч., вашего собственного)
my-agent.sources.my-source.type = netcat
# Указываем, куда биндить наш исчтоник
my-agent.sources.my-source.bind = 0.0.0.0
my-agent.sources.my-source.port = 11111
# Указываем источнику канал (или список каналов, через пробел), куда отправлять полученные события
my-agent.sources.my-source.channels = my-channel
### ==================== Канал my_channel ================== ###
# Используем тип канала из пакета Flume - memory (как и с источником, здесь можно казать свой класс), который хранит события в памяти
my-agent.channels.my-channel.type = memory
# Вместимость канала, кол_во событий
my-agent.channels.my-channel.capacity = 10000
# Число событий в одной транзакции (как на добавление, так и на "вытягивание")
my-agent.channels.my-channel.transactionCapacity = 100
### ==================== Сток my_sink ================== ###
# Тип стока - логгер, пишуший события в консоль (и здесь также можно указать свой класс)
my-agent.sinks.my-sink.type = logger
# Из какого канала будем забирать события
my-agent.sinks.my-sink.channel = my-channel
# Настройка исключительно для стока типа logger - сколько первых байт тела события выводить в консоль
my-agent.sinks.my-sink.maxBytesToLog = 256Осталось теперь запустить узел с нашей конфигурацией. Сделать это можно двумя способами:
- На кластере Hadoop, через Cloudera Manager (в этой статье есть подробное описание того, как это сделать).
- Как Java-сервис, используя библиотеки Flume.
Поскольку процесс запуска Flume средствами Cloudera Manager освещен достаточно подробно, рассмотрим второй вариант — с помощью Java.
Прежде всего необходимо добавить зависимости Flume к нашему проекту. Для этого добавим в pom.xml репозиторий Clodera и два артефакта Flume — ng-sdk и ng-node.
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-sdk</artifactId>
<version>1.5.0-cdh5.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-node</artifactId>
<version>1.5.0-cdh5.3.0</version>
</dependency>
</dependencies>После этого создадим класс с точкой входа:
package ru.flume.samples;
import org.apache.flume.node.Application;
public class FlumeLauncher {
public static void main(String[] args) {
// файл с конфигурацией Log4j я позволю себе указать прямо здесь
System.setProperty("log4j.configuration", "file:/flume/config/log4j.properties");
// Запускаем Flume с параметрами:
Application.main(new String[]{
"-f", "/flume/config/sample.conf", // путь до файла с конфигурацией
"-n", "my-agent" // имя агента
});
}
}Читатели, знакомые с Java, заметят, что можно вообще не создавать этот класс, а просто скопировать необходимые зависимости для Flume в отдельную папку и запустить Java с нужными аргументами командной строки. Но это уже дело вкуса — я предпочитаю, чтобы Maven сам подтягивал все необходимые зависимости, в том числе и разработанные нами компоненты Flume, и аккуратно всё это заворачивал в deb-пакет.
Если все пути указаны верно, а конфигурация не содержит ошибок, мы увидим в консоле вот такой лог от Flume.
INFO main conf.FlumeConfiguration - Processing:my-sink
INFO main conf.FlumeConfiguration - Added sinks: my-sink Agent: my-agent
INFO main conf.FlumeConfiguration - Processing:my-sink
INFO main conf.FlumeConfiguration - Processing:my-sink
INFO main conf.FlumeConfiguration - Post-validation flume configuration contains configuration for agents: [my-agent]
INFO main node.AbstractConfigurationProvider - Creating channels
INFO main channel.DefaultChannelFactory - Creating instance of channel my-channel type memory
INFO main node.AbstractConfigurationProvider - Created channel my-channel
INFO main source.DefaultSourceFactory - Creating instance of source my-source, type netcat
INFO main sink.DefaultSinkFactory - Creating instance of sink: my-sink, type: logger
INFO main node.AbstractConfigurationProvider - Channel my-channel connected to [my-source, my-sink]
INFO main node.Application - Starting new configuration:
{
sourceRunners:{
my-source=EventDrivenSourceRunner: {
source:org.apache.flume.source.NetcatSource{
name:my-source,
state:IDLE
}
}
}
sinkRunners:{
my-sink=SinkRunner: {
policy:org.apache.flume.sink.DefaultSinkProcessor@77f03bb1 counterGroup:{ name:null counters:{} }
}
}
channels:{
my-channel=org.apache.flume.channel.MemoryChannel{
name: my-channel
}
}
}
INFO main node.Application - Starting Channel my-channel
INFO main node.Application - Waiting for channel: my-channel to start. Sleeping for 500 ms
INFO lifecycleSupervisor-1-0 instrumentation.MonitoredCounterGroup - Monitored counter group for type: CHANNEL, name: my-channel: Successfully registered new MBean.
INFO lifecycleSupervisor-1-0 instrumentation.MonitoredCounterGroup - Component type: CHANNEL, name: my-channel started
INFO main node.Application - Starting Sink my-sink
INFO main node.Application - Starting Source my-source
INFO lifecycleSupervisor-1-1 source.NetcatSource - Source starting
INFO lifecycleSupervisor-1-1 source.NetcatSource - Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/0:0:0:0:0:0:0:0:11111]Чтобы убедиться, что всё работает корректно, отправим нашему NetCat-источнику небольшой тестовый файл test.txt, в котором содержится 4 строки:
Message 1
Message 2
Message 3Важно, чтобы файл оканчивался переносом строки. Для NetCat-источника он является разделителем событий. Если мы не добавим в конец файла этот перенос строки, то источник будет считать, что последнее событие пришло не полностью. В результате этого он будет упорно ждать разделителя, который, естественно, никогда не придет. Итак, выполняем команду:
nc 127.0.0.1 11111 < test.txtВ результате этого NetCat должен вывести на экран три сообщения «ОК», как подтверждение того, что все строки файла благополучно отправлены и получены источником Flume. В это же время, сток должен вывести в консоль вот такие сообщения:
sink.LoggerSink - Event: { headers:{} body: 4D 65 73 73 61 67 65 20 31 0D Message 1. }
sink.LoggerSink - Event: { headers:{} body: 4D 65 73 73 61 67 65 20 32 0D Message 2. }
sink.LoggerSink - Event: { headers:{} body: 4D 65 73 73 61 67 65 20 33 0D Message 3. }Примечание: Flume при запуске регистрирует свой shutdownHook, поэтому нет необходимости вручную высвобождать какие-либо ресурсы (соединения, открытые файлы и т.п.) — все компоненты узла самостоятельно завершат работу вместе с JVM.
5. Цепочка узлов Flume
Итак, мы разобрались, как настроить и запустить одиночный узел Flume. Однако для управления потоками данных одного узла явно маловато. Попробуем построить небольшую цепочку из трех узлов, выполняющих задачу деления (по сути — балансировка): первый узел Flume принимает информацию от клиента и отправляет события на два других узла. При этом события не дублируются на втором и третьем узлах, а равномерно распределяются между ними.
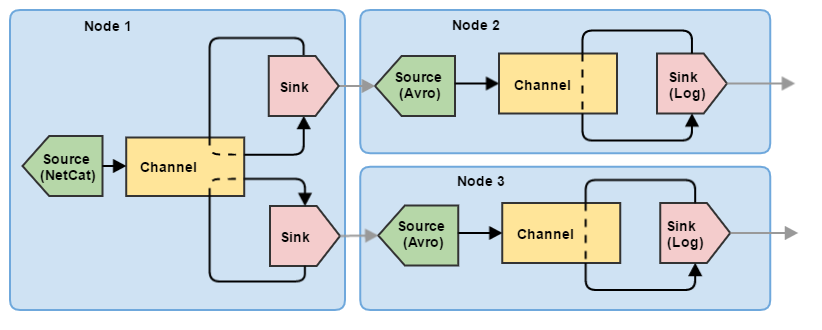
Соответственно, для такой схемы необходимо несколько конфигураций (для каждого узла — своя).
node1.sources = my-source
node1.channels = my-channel
# Теперь здесь 2 стока:
node1.sinks = my-sink1 my-sink2
node1.sources.my-source.type = netcat
node1.sources.my-source.bind = 0.0.0.0
node1.sources.my-source.port = 11111
node1.sources.my-source.channels = my-channel
node1.channels.my-channel.type = memory
node1.channels.my-channel.capacity = 10000
node1.channels.my-channel.transactionCapacity = 100
# Оба стока делаем с типом avro, они будут опустошать наш единственный канал вдвоем
# Хосты принимающих узлов я оставлю локальными, чтобы всю эту цепочку можно было
# попробовать запустить на одной машине
node1.sinks.my-sink1.type = avro
node1.sinks.my-sink1.channel = my-channel
node1.sinks.my-sink1.hostname = 127.0.0.1
node1.sinks.my-sink1.port = 11112
node1.sinks.my-sink1.batch-size = 100
node1.sinks.my-sink2.type = avro
node1.sinks.my-sink2.channel = my-channel
node1.sinks.my-sink2.hostname = 127.0.0.1
node1.sinks.my-sink2.port = 11113
node1.sinks.my-sink2.batch-size = 100node2.sources = my-source
node2.channels = my-channel
node2.sinks = my-sink
# Поскольку на узле 1 сток имеет тип avro, здесь мы указываем источник типа avro
node2.sources.my-source.type = avro
node2.sources.my-source.bind = 0.0.0.0
node2.sources.my-source.port = 11112
node2.sources.my-source.channels = my-channel
node2.channels.my-channel.type = memory
node2.channels.my-channel.capacity = 10000
node2.channels.my-channel.transactionCapacity = 100
node2.sinks.my-sink.type = logger
node2.sinks.my-sink.channel = my-channel
node2.sinks.my-sink.maxBytesToLog = 256
node3.sources = my-source
node3.channels = my-channel
node3.sinks = my-sink
# Поскольку на узле 1 сток имеет тип avro, здесь мы указываем источник типа avro
node3.sources.my-source.type = avro
node3.sources.my-source.bind = 0.0.0.0
node3.sources.my-source.port = 11113
node3.sources.my-source.channels = my-channel
node3.channels.my-channel.type = memory
node3.channels.my-channel.capacity = 10000
node3.channels.my-channel.transactionCapacity = 100
node3.sinks.my-sink.type = logger
node3.sinks.my-sink.channel = my-channel
node3.sinks.my-sink.maxBytesToLog = 256Конфигурации для узлов 2 и 3 в данном примере идентичны, отличаются только номерами портов. Также для связи между узлами здесь используются стандартные компоненты Flume: Avro источник и Avro сток. Подробнее они будут описаны в следующих статьях, пока же нам достаточно того, что Avro Sink может отправлять по сети события, а Avro Source может их принимать.
Соответственно, запускаться каждый из узлов должен в отдельном процессе, а параметры запуска будут выглядеть следующим образом:
Application.main(new String[]{"-f", "/flume/config/node1.conf", "-n", "node1"});
// для других узлов по аналогии:
//Application.main(new String[]{"-f", "/flume/config/node2.conf", "-n", "node2"});
//Application.main(new String[]{"-f", "/flume/config/node3.conf", "-n", "node3"});Можно убедиться в работоспособности этой конфигурации, скормив первому узлу текстовый файл с сотней строк (маленькие порции данных могут пачкой отправиться на один из узлов и желаемого эффекта разделения данных мы не увидим).
Заключение
Эта статья является ознакомительной, приведенные здесь примеры конфигурации узлов Flume могут пригодиться лишь для отладки или знакомства с этим инструментом. В реальных проектах топология Flume выходит далеко за рамки одного-двух узлов, а конфигурации компонентов являются куда более сложными.
В следующей статье:
- Использование заголовков и канальных селекторов (Channel Selector).
- «Боевые» компоненты Flume:
- Avro Source;
- File Channel;
- Avro Sink;
- HDFS Sink;
- File Roll Sink.
- Мониторинг состояния узла Flume.
Использованные источники и полезные ссылки
- Официальная страница Apache Flume
- Официальный гайд по настройке компонентов Flume
- Hadoop, часть 2: сбор данных через Flume | Блог компании Селектел — статья о настройке Flume средствами Cloudera.
- Hari Shreedharan: Using Flume — неплохая книга, описывающая возможности Flume.
Комментарии (11)

dgr
29.03.2016 21:28+1Я бы еще добавил, что Flume очень легко расширяется, написать собственный source, channel или sink просто.

Deneb
29.03.2016 21:33+1Да, вы совершенно правы, разработка самописных компонентов для Flume не требует значительных усилий. Правда, мы разрабатывали только source/sink реализации — channel'ы как-то не было необходимости) Во второй части цикла приведу примеры нестандартных компонентов.

f1sherox
31.03.2016 12:26Отличная статья, спасибо. Жду продолжения.
Есть ли опыт работы с Apache Storm? Интересно узнать мнение о работе этого инструмента в сравнении с Flume.Deneb
31.03.2016 12:47Здесь ситуация такая же как с Apache Camel — опыта работы с Apache Storm у меня нет =) Судя по описаниям и примерам, Storm является "вычислительным инструментом без хранения данных", Flume же — просто транспорт. Да, он позволяет выполнять различные манипуляции над данными, но задачи типа MapReduce, конечно, решать не умеет. Я думаю, что Storm ближе к категории инструментов типа Akka.
LeshiyUrban
Спасибо за информацию. А это с Apache Camel слегка не конкурирует?
Deneb
К несчастью, я не имею практического опыта работы с Apache Camel. После беглого прочтения User Guide/Manual для Camel могу сказать, что здесь вряд ли может быть конкуренция:
Я думаю, Camel логичнее использовать для задач, где решающую роль играет содержимое сообщений/событий, а Flume — где нужно "разложить данные по полочкам". Было бы интересно услышать ваше мнение)
LeshiyUrban
Мое мнение зиждется на беглом прочтении документации о Apache Flume и нескольких лет разработки на Apache Camel)
Camel довольно таки универсальный инструмент для передачи, преобразования и маршрутизации сообщений откуда угодно, куда угодно и как угодно. С огромным набором готовых входов (Source в терминологии Flume), выходов (Sink в т. Flume) и преобразований. Важное отличие: надо кодировать (xml, DSL, java, scala, groovy) и одним конфигом как в Flume не обойтись.
У меня создалось впечатление, что Flume это Camel, из которого выкинули все по-максимуму и дописали пару функций)) Но это чисто ИМХО.
Deneb
А есть в Camel какой-то аналог каналов Flume? Я видел, что Camel поддерживает транзакционность, но что будет, если один из endpoint's окажется в нерабочем состоянии? Где будет копиться очередь не доставленных сообщений и дойдут ли они в итоге, когда машина вернется в строй?
LeshiyUrban
Очередь сообщений будет копится в зависимости от типа источника. Например: для БД, транзакция означает откат и в БД, seda — аналог BlockingQueue с заданием лимитов. В каждом случае по своему.
Если упрощено, то да, в большинстве случаев сообщение будет передано, когда абонент вернется в строй
Deneb
Если речь идет о БД, то тогда наверное имеет смысл сравнивать производительность. В Flume каналы реализованы для быстрой передачи довольно больших объемов данных. Сейчас я не готов предоставить характеристики "в попугаях", пожалуй затрону эту тему в следующих частях. Спасибо за ответ!
voidnugget
Некорректно сравнивать Camel с Flume так как задачи совсем различные: Flume разрабатывался для потоковой обработки логов в конвейерах, а Camel для преобразования разнородных интерфейсов.