

File Channel
В прошлой статье мы рассмотрели Memory Channel. Очевидно, что канал, использующий для хранения данных память, не является надежным. Перезапуск узла приведет к тому, что все данные, хранящиеся в канале, будут потеряны. Это не делает Memory Channel бесполезным, есть некоторые случаи, когда его использование очень даже оправдано в силу быстродействия. Однако для действительно надежной транспортной системы необходимо более устойчивое к неполадкам решение.
Таким решением является файловый канал — File Channel. Несложно догадаться, что этот канал хранит данные в файлах. При этом канал использует Random Access для работы с файлом, позволяя таким образом и добавлять и забирать события, сохраняя их последовательность. Для быстрой навигации канал использует систему меток (checkpoints), с помощью которых реализуется механизм WAL. Всё это, в общем-то, спрятано «под капотом» канала, а для его настройки используются следующие параметры (жирным шрифтом — обязательные параметры).
| Параметр | Описание | По умолчанию |
|---|---|---|
type |
Реализация канала, должно быть указано file | - |
checkpointDir |
Папка для хранения файлов с метками. Если не указана, канал будет использовать домашнюю папку Flume. | $HOME/... |
useDualCheckpoints |
Делать ли бекап папки с метками. | false |
backupCheckpointDir |
Папка для бекапов файлов с метками, нужно обязательно указывать, если useDualCheckpoints=true (разумеется, этот бекап лучше держать подальше от оригинала — например, на другом диске). | - |
dataDirs |
Список папок через запятую, в которых будут размещаться файлы с данными. Лучше указывать несколько папок на различных дисках для повышения производительности. Если папки не указаны, канал также будет использовать домашнюю папку Flume. | $HOME/... |
capacity |
Вместимость канала, указывается число событий. | 1000000 |
transactionCapacity |
Максимальное число событий в одной транзакции. Очень важный параметр, от которого может зависеть работоспособность всей транспортной системы. Подробнее об этом будет написано ниже. | 10000 |
checkpointInterval |
Интервал между созданием новых меток, в миллисекуднах. Метки играют важную роль при перезапуске, позволяя «перепрыгивать» участки файлов с данными при восстановлении состояния канала. В итоге канал не перечитывает файлы с данными целиком, что существенно ускоряет запуск при «забитом» канале. | 30000 |
checkpointOnClose |
Записывать ли метку при закрытии канала. Замыкающая метка позволит каналу восстановиться при перезапуске максимально быстро — но её создание займет некоторое время при закрытии канала (на самом деле, очень незначительное). | true |
keep-alive |
Таймаут (в секундах) для операции добавления в канал. Т.е., если канал забит, транзакция «даст ему шанс», выждав некоторое время. И если свободного места в канале так и не появилось, то транзакция откатится. | 3 |
maxFileSize |
Максимальный размер файла канала, в байтах. Значение этого параметра не определяет, сколько места может «откусить» ваш канал — оно задает размер одного файла с данными, а этих файлов канал может создать несколько. | 2146435071 (2ГБ) |
minimumRequiredSpace |
Если на вашем диске меньше свободного места, чем указано в этом параметре, то канал не будет принимать новые события. В случае, если папки с данными расположены на нескольких дисках, Flume будет использовать | 524288000 (500МБ) |
- Убедитесь, что Flume имеет право записывать данные в папки.
Или, если быть точнее, пользователь, от чьего имени запущен Flume, имеет права записи в папках для checkpoints и data.
- SSD значительно ускоряет работу канала.
На графике ниже показано время отправки пачки из 500 событий на узлы Flume, использующие файловые каналы. Один из узлов использует SSD для хранения данных канала, другой — SATA. Разница существенная.
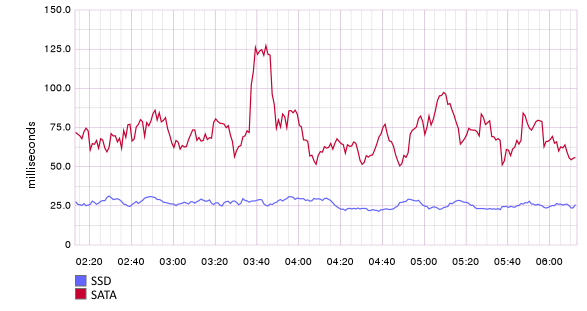
Если выполнить нехитрое деление, то получим, что узел Flume с файловым каналом на SSD может переваривать до 500/0.025 = 20000 событий в секунду (для справки — размер сообщений в данном примере около 1КБ, а канал использует для хранения только один диск).
- Capacity канала очень чувствительна к изменениям.
Если вы вдруг решили поменять вместимость вашего канала, то вас может ждать неприятный сюрприз — канал запустит replay для восстановления данных. Это значит, что вместо использования файлов checkpoints для дальнейшей навигации/работы с данными канал полностью пробежит по всем файлам с данными. Если в данных в канале много, процесс может занять приличное время.
- Нештатная остановка канала может привести к потере данных.
Это может произойти, если вы убили процесс Flume (или hard reset). А может и не произойти. На моей памяти у нас такое случалось всего один раз — файл с данными был «испорчен» и пришлось вручную удалить все файлы с данными канала (благо, каналы у нас не забивались и потерь удалось избежать). Таким образом, 100% надежности канал всё-таки не дает — всегда есть вероятность, что кто-то «дёрнет рубильник» и произойдет непоправимое. Что ж, если такое произошло и канал отказывается запускаться, ваши действия могут быть такими:
- Попробуйте удалить файлы меток (checkpoints) — в этом случае канал попытается восстановиться только по файлам с данными.
- Если предыдущий пункт не помог и канал пишет что-то в стиле «Unable to read data from channel, channel will be closed», значит файл с данными испорчен. Тут поможет только полная чистка всех папок с данными. Увы.
- Попробуйте удалить файлы меток (checkpoints) — в этом случае канал попытается восстановиться только по файлам с данными.
В качестве альтернативы File-Channel Flume предлагает еще несколько каналов — в частности, JDBC-channel, использующий в качестве буфера базу данных, и Kafka-channel. Разумеется, что для использования таких каналов нужно отдельно разворачивать базу данных и Kafka.
Avro Source и Avro Sink
Avro — это один из инструментов сериализации данных, благодаря которому источник и сток получили свои названия. Сетевое взаимодействие этих компонентов реализовано с помощью Netty. В сравнении с Netcat Source, рассмотренным в предыдущей статье, Avro Source обладает следующими преимуществами:
- Может использовать заголовки в событиях (т.е. передавать вместе с данными вспомогательную информацию).
- Может принимать информацию от нескольких клиентов одновременно. Netcat работает на обычном сокете и принимает входящие соединения последовательно, а значит, может обслуживать только одного клиента в момент времени.
Итак, рассмотрим настройки, которые нам предлагает Avro Source.
| Параметр | Описание | По умолчанию |
type |
Реализация источника, должно быть указано avro. | - |
channels |
Каналы, в которые источник будет отправлять события (через пробел). | - |
bind |
Хост/IP, за которым закрепляем источник. | - |
port |
Порт, на котором источник будет принимать подключения от клиентов. | - |
threads |
Число потоков, обрабатывающих входящие события (I/O workers). При выборе значения следует ориентироваться на число потенциальных клиентов, которые будут слать события этому источнику. Необходимо выставлять как минимум 2 потока, иначе ваш источник может попросту «зависнуть», даже если клиент у него всего один. Если не уверены, сколько потоков необходимо — не указывайте этот параметр в конфигурации. | не ограничено |
compression-type |
Сжатие данных, здесь вариантов немного — либо none, либо deflate. Указывать необходимо только в том случае, если клиент передает данные в сжатом виде. Сжатие поможет вам существенно сэкономить трафик, и чем больше событий за раз вы передаете — тем существеннее будет эта экономия. | none |
- selector.type — селектор каналов, о них я упоминал в предыдущей статье. Позволяют делить или дублировать события в несколько каналов по некоторым правилам. Детальнее селекторы будут рассмотрены ниже.
- interceptors — список перехватчиков, через пробел. Перехватчики срабатывают ДО того, как события попадут в канал. Их используют, чтобы каким-то образом модифицировать события (например, добавить заголовки или изменить содержимое события). О них также речь пойдет ниже.
Также для этого источника предусмотрена настройка фильтров Netty и параметры шифрования данных. Для отправки событий этому источнику можно использовать вот такой код.
import java.util.HashMap;
import java.util.Map;
import org.apache.flume.Event;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.api.RpcClient;
import org.apache.flume.api.RpcClientFactory;
import org.apache.flume.event.EventBuilder;
import org.apache.flume.event.SimpleEvent;
public class FlumeSender {
public static void main(String[] args) throws EventDeliveryException {
RpcClient avroClient = RpcClientFactory.getDefaultInstance("127.0.0.1", 50001);
Map<String, String> headers = new HashMap<>();
headers.put("type", "common");
Event event = EventBuilder.withBody("Тело события".getBytes(), headers);
avroClient.append(event);
avroClient.close();
}
}Теперь рассмотрим конфигурацию Avro-стока.
| Параметр | Описание | По умолчанию |
|---|---|---|
type |
Реализация стока, должно быть указано avro. | - |
channel |
Канал, из которого сток будет вытягивать события. | - |
hostname |
Хост/IP, на который сток будет отправлять события. | - |
port |
Порт, на котором указанная машина (hostname) ожидает подключения клиентов. | - |
batch-size |
очень важный параметр: размер «пачки» событий, отправляемых клиенту за один запрос. В то же время, это же значение используется при опустошении канала. Т.е., это еще и число событий, считываемых из канала за одну транзакцию. | 100 |
connect-timeout |
Таймаут соединения (handshake), в миллисекундах. | 20000 |
request-timeout |
Таймаут запроса (отправки пачки событий), в миллисекундах. | 20000 |
reset-connection-interval |
Интервал «смены хоста». Подразумевается, что за указанным hostname может скрываться несколько машин, обслуживаемых балансером. Этот параметр принудительно заставляет сток переключаться между машинами через указанный интервал времени. Удобство, по замыслу создателей стока, заключается в том, что если в зону ответственности балансера добавляется новая машина, отсутствует необходимость перезапускать узел Flume — сток сам сообразит, что появился еще один «пункт назначения». По умолчанию сток не осуществляет смены хостов. | -1 |
maxIoWorkers |
Аналог threads для Avro Source. | 2 * PROC_CORES |
compression-type |
То же самое, что и для Avro Source. Разница в том, что сток сжимает данные, а источник, напротив, распаковывает. Соответственно, если Avro Sink шлет события на Avro Source, тип сжатия на обоих должен быть одинаковый. | none |
compression-level |
Уровень сжатия, только если compression-type=deflate (0 — не сжимать, 9 — максимальное сжатие). | 6 |
- Аккуратно выбирайте Batch Size.
Как я уже говорил, это очень важный параметр, непродуманный выбор которого может значительно подпортить вам жизнь. Прежде всего, batch-size обязательно должен быть меньше или равен вместимости транзакции канала (transactionCapacity). Это явно касается Avro Sink и неявно — Avro Source. Рассмотрим на примере:
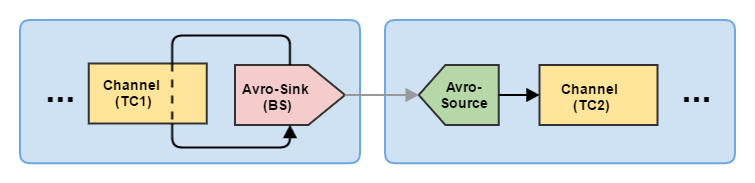
Здесь TC — это transactionCapacity, а BS — batch-size. Условие нормальной работы заключается в том, что: BS <= TC1 и BS <= TC2. То есть, необходимо учитывать не только вместимость транзакции канала, с которым работает сток, но вместимость транзакции канала (-ов), с которым работает принимающий Avro Source. В противном случае сток не сможет опустошать свой канал, а источник — добавлять события в свой. В таких случаях Flume начинает интенсивно лить в лог сообщения об ошибках.
Случай из практики. В одном из стоков мы как-то поставили batch-size = 10000, в то время как на принимающем узле для канала была выставлена TC = 5000. И всё работало замечательно. Пока объём данных был небольшим, сток попросту не вытягивал из канала позволенные 10000 событий за раз — в канале не успевало накопиться столько событий. Но спустя некоторое время объем данных увеличился и у нас начались проблемы. Принимающий узел начал отклонять большие пачки данных. Ошибку вовремя заметили, изменили параметры и скопившиеся в канале данные озорным ручейком дотекли до места назначения.
- Отправляйте события крупными пачками.
Транзакция — операция довольно дорогостоящая по ресурсам. Меньше транзакций — больше производительность. Опять же, сжатие при передаче большого числа событий работает гораздо эффективнее. Соответственно, помимо batch-size придётся увеличить и transactionCapacity ваших каналов.
- Переопределите зависимость netty для ваших узлов.
Мы используем версию netty 3.10.5 Final, в то время как Flume подтягивает более старую netty 3.6.2 Final. Проблема старой версии заключается в небольшом баге, из-за которого Avro Sink / Avro Source не могут периодически подключиться друг к другу. Это приводит к тому, что в передаче данных периодически возникают простои на несколько минут (потом все приходит в норму). В случае, если данные должны поступать максимально быстро, такие «пробки» могут стать проблемой.

В случае, если вы запускаете Flume средствами Java, переопределить зависимость можно средствами Maven. Если же вы настраиваете Flume средствами Cloudera или в виде сервиса, то зависимость Netty придётся менять вручную. Найти их можно в следующих папках:
- Cloudera — /opt/cloudera/parcels/CDH-${VERSION}/lib/flume-ng/lib;
- Service (stand-aloone) — $FLUME_HOME/lib.
File-Roll Sink
Итак, мы разобрались, как настроить транспортные узлы на основе Avro Source/Sink и файлового канала. Осталось теперь разобраться с компонентами, которые замыкают (т.е. выводят данные из зоны ответственности Flume) нашу транспортную сеть.

Первый замыкающий сток, который стоит рассмотреть, это File-Roll Sink. Я бы сказал, что это сток для ленивых. Он поддерживает минимум настроек и может делать только одну вещь — записывать события в файлы.
| Параметр | Описание | По умолчанию |
|---|---|---|
type |
Реализация стока, должно быть указано file_roll. | - |
channel |
Канал, из которого сток будет вытягивать события. | - |
directory |
Папка, в которой будут храниться файлы. | - |
rollInterval |
Интервал между созданием новых файлов (0 — писать всё в один файл), в секундах. | 30 |
serializer |
Сериализация событий. Можно указать: TEXT, HEADER_AND_TEXT, AVRO_EVENT или свой класс, реализующий интерфейс EventSerializer.Builder. | TEXT |
batch-size |
Аналогично Avro Sink, размер пачки событий, забираемых за транзакцию с канала. | 100 |
Почему я считаю его стоком для ленивых? Потому что в нем абсолютно ничего нельзя настроить. Ни сжатия, ни наименоваия файлов (в качестве имени будет использован timestamp создания), ни группировки по подпапкам — ничего. Даже размер файла ограничить нельзя. Этот сток подходит, пожалуй, только для случаев, когда «нет времени объяснять — нам нужно срочно начать принимать данные!».
Примечание. Поскольку необходимость записывать данные в файлы всё-таки имеется, мы пришли к выводу, что целесообразнее реализовать свой файловый сток, чем использовать этот. Учитывая, что все исходники Flume открыты, сделать его оказалось несложно, мы уложились за день. На второй день поправили мелкие баги — и сток уже больше года исправно работает, раскладывая данные по папкам в аккуратные архивы. Этот сток я выложу на GitHub после третьей части цикла.
HDFS Sink
Этот сток уже посерьезней — он поддерживает уйму настроек. Немного удивительно, что File-Roll Sink не сделан аналогичным образом.
| Параметр | Описание | По умолчанию |
|---|---|---|
type |
Реализация стока, должно быть указано hdfs. | - |
channel |
Канал, из которого сток будет вытягивать события. | - |
hdfs.path |
Папка, в которую будут записываться файлы. Убедитесь, что для этой папки выставлены нужные права доступа. Если вы настраиваете сток средствами Cloudera, то данные будут писаться от имени пользователя flume. | - |
hdfs.filePrefix |
Префикс имени файла. Базовое имя файла, как и для File-Roll — timestamp его создания. Соответстенно, если вы укажете my-data, итоговое имя файла будет my-data1476318264182. | FlumeData |
hdfs.fileSuffix |
Постфикс имени файла. Добавляется в конец имени файла. Можно использовать, чтобы указать расширение, например, .gz. | - |
hdfs.inUsePrefix |
Аналогично filePrefix, но для временного файла, в который еще ведется запись данных. | - |
hdfs.inUseSuffix |
Аналогично fileSuffix, но для временного файла. По сути, временное расширение. | .tmp |
hdfs.rollInterval |
Период создания новых файлов, в секундах. Если файлы не нужно закрывать по такому критерию, ставим 0. | 30 |
hdfs.rollSize |
Триггер для закрытия файлов по объему, указывается в байтах. Также ставим 0, если этот критерий нам не подходит. | 1024 |
hdfs.rollCount |
Триггер для закрытия файлов по числу событий. Также можно поставить 0. | 10 |
hdfs.idleTimeout |
Триггер для закрытия файлов из-за неактивности, в секундах. То есть, если в файл некоторое время ничего не записывается — он закрывается. Этот триггер по умолчанию отключен. | 0 |
hdfs.batchSize |
То же самое, что и для других стоков. Хотя в документации к стоку написано, что это число событий, записываемых в файл, прежде чем они будут сброшены в HDFS. При выборе также ориентируемся на объем транзакции канала. | 100 |
hdfs.fileType |
Тип файла — SequenceFile (Hadoop-файл с парами ключ-значение, как правило, в качестве ключа используется timestamp из хидера «timestamp» или текущее время), DataStream (текстовые данные, по сути, построчная запись с указанной сериализацией, как в File-Roll Sink) или CompressedStream (аналог DataStream, но с сжатием). | SequenceFile |
hdfs.writeFormat |
Формат записи — Text или Writable. Только для SequenceFile. Отличие — в качестве значения будет писаться либо текст (TextWritable) или байты (BytesWritable). | 5000 |
serializer |
Настраивается для DataStream и CompressedStream, по аналогии с File-Roll Sink. | TEXT |
hdfs.codeC |
Этот параметр необходимо указывать, если вы используете тип файла CompressedStream. Предлагаются такие варианты сжатия: gzip, bzip2, lzo, lzop, snappy. | - |
hdfs.maxOpenFiles |
Максимально допустимое число одновременно открытых файлов. Если этот порог будет превышен, то наиболее старый файл будет закрыт. | 5000 |
hdfs.minBlockReplicas |
Важный параметр. Минимальное число реплик на блок HDFS. Если не указан, берется из конфигурации Hadoop, указанной в classpath при запуске (т.е. настроек вашего кластера). Честно говоря, я не могу объяснить причину поведения Flume, связанного с этим параметром. Суть в том, что если значение этого параметра отличается от 1, то сток начнет закрывать файлы без оглядки на другие триггеры и в рекордные сроки наплодит уйму мелких файлов. | - |
hdfs.maxOpenFiles |
Максимально допустимое число одновременно открытых файлов. Если этот порог будет превышен, то наиболее старый файл будет закрыт. | 5000 |
hdfs.callTimeout |
Таймаут обращения к HDFS (открыть/закрыть файл, сбросить данные), в миллисекундах. | 10000 |
hdfs.closeTries |
Число попыток закрыть файл (если с первого раза не получилось). 0 — пытаться до победного конца. | 0 |
hdfs.retryInterval |
Как часто пытаться закрыть файл в случае неудачи, в секундах. | 180 |
hdfs.threadsPoolSize |
Число потоков, осуществляющих IO операции с HDFS. Если у вас «солянка» из событий, которые расфасовываются по многим файлам, то лучше поставить это число побольше. | 10 |
hdfs.rollTimerPoolSize |
В отличии от предыдущего пула, этот пул потоков выполняет задачи по расписнию (закрывает файлы). Причем, он работает на основе двух параметров — rollInterval и retryInterval. Т.е. этот пул выполняет как плановое закрытие по триггеру, так и периодические повторные попытки закрыть файл. Одного потока должно быть достаточно. | 1 |
hdfs.useLocalTimeStamp |
HDFS сток предполагает использование элементов даты в назании формируемых файлов (например, hdfs.path = /logs/%Y-%m-%d позволит вам группировать файлы по дням). Использование даты предполагает, что она откуда-то должна быть получена. Этот параметр предлагает два варианта: использовать время на момент обработки события (true) или использовать время, указанное в событии — а именно, в заголовке «timestamp» (false). Если вы используете timestamp события, то убедитесь, что ваши собтия имеют этот заголовок. Иначе не будут записаны в HDFS. | false |
hdfs.round |
Округлять timestamp до некоторого значения. | false |
hdfs.roundValue |
Насколько округлять timestamp. | 1 |
hdfs.roundUnit |
В каких единицах округлять (second,minute или hour). | second |
Возможно вы заметили интересную особенность конфигурации HDFS-стока — здесь нет параметра, указывающего адрес HDFS. Создатели стока предполагают, что данный сток должен быть использован на тех же машинах, что и HDFS.
Итак, что же необходимо учитывать при настройке этого стока.
- Используйте крупные batch-size и transactionCapacity.
В общем-то, здесь все аналогично с другими стоками — транзакция достаточно дорогая в плане ресурсов, поэтому лучше лить крупными порциями.
- Не злоупотребляйте макросами в именовании файлов.
Использование элементов даты в именах файлов/папок или плейсхолдеров для заголовков — это, безусловно, удобный инструмент. Но не очень быстрый. Мне кажется, подстановку даты создатели могли сделать оптимальнее — если вы заглянете в исходники, то удивитесь числу выполняемых операций для форматирования этих строк. Предположим, мы решили задать вот такую структуру папок:
Здесь dir и src — значения заголовков событий с соотв. ключами. Результирующий файл будет иметь вид /logs/web/my-source/2016-04-15/2016-04-15-12-00-00.my-host.my-source.gz. На моем компьютере генерация этого имени для 1 млн. событий занимает почти 20 секунд! Т.е. для 10000 событий это займет примерно 200мс. Делаем вывод: если вы претендуете на скорость записи 10000 событий в секунду, будьте готовы отдать 20% времени на генерацию имени файла. Это ужасно. Вылечить это можно, взяв на себя ответственность за генерацию имени файла на стороне клиента. Да, для этого придется написать немного кода, но зато можно будет изменить настройки стока на вот такие:hdfs.path = /logs/%{dir} hdfs.filePrefix = %{src}/%Y-%m-%d/%Y-%m-%d-%H-%M-%S.%{host}.%{src}
Передавая сформированное имя файла в заголовке file-name вы сэкономите ресурсы и время. Формирование пути файла по таким заголовком занимает уже не 20 секунд, а 500-600 миллисекунд для 1 млн. событий. Т.е., почти в 40 раз быстрее.hdfs.path = /logs hdfs.filePrefix = %{file-name}
- Объединяйте события.
Еще один маленький хак, позволяющий существенно повысить производительность стока. Если вы пишете события в файл построчно, то можно объединять их на стороне клиента. Например, ваш сервис генерирует логи, которые должны идти в один и тот же файл. Так почему бы не объединить несколько строк в одну, использовав в качестве разделителя \n? Сама по себе запись данных в HDFS или файловую систему занимает куда меньше времени, чем вся эта «цифровая бюрократия» вокруг данных.
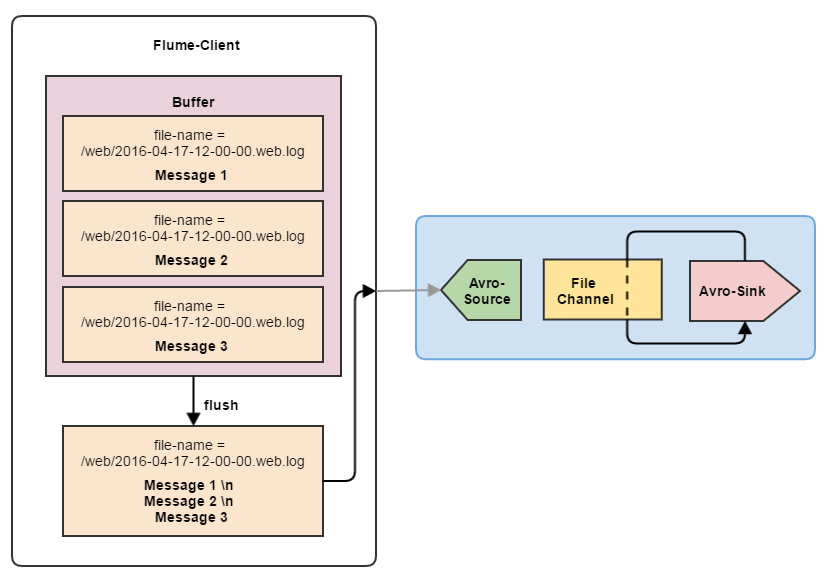
Объединяя события в соотношении хотя бы 5 к 1 вы уже получите существенный прирост производительности. Естественно, здесь нужно быть осторожным — если события на клиенте генерируются по одному, то наполнение буфера для объединения событий может занять некоторое время. Всё это время события будут храниться в памяти, ожидая формирования группы для объединения. А значит повышаются шансы потерять данные. Резюме:
- Для небольших объемов данных клиенту лучше отправлять события во Flume по одному — меньше шансов их потерять.
- Для больших объемов данных предпочтительно использовать объединение событий. Если события генерируются интенсивно, буфер для 5-10 событий будет набираться достаточно быстро. При этом вы существенно повысите производительность стоков.
- Для небольших объемов данных клиенту лучше отправлять события во Flume по одному — меньше шансов их потерять.
- Разверните стоки на нескольких машинах HDFS-кластера.
При настройке Flume через Cloudera имеется возможность запустить на каждой ноде кластера отдельный узел Flume. И этой возможностью лучше воспользоваться — поскольку таким образом нагрузка распределяется между всеми машинами кластера. При этом, если вы используете общую конфигурацию (т.е. один и тот же файл конфигурации на всех машинах), убедитесь, что у вас не возникнет конфликтов имен файлов. Сделать это можно, задействовав перехватчик событий, добавляющий в заголовки название хоста. Соответвенно, вам останется только указать в шаблоне имени файла этот заголовок (см. ниже).
Примечание. На самом деле при принятии такого решения стоит задуматься — ведь каждый сток будет писать однородные данные в свой файл. В результате вы можете получить кучу мелких файлов на HDFS. Решение должно быть взвешенным — если объем данных невелик, то можно ограничиться одним узлом Flume для записи в HDFS. Это так называемая консолидация данных — когда данные из множества источников в итоге попадают на один сток. Однако если данные «текут рекой», то одного узла может быть недостаточно. Подробнее о проектировании всей транспортной сети мы поговорим в следующей статье этого цикла.
Перехватчики событий (Flume Interceptors)
Я много раз упоминал эти таинственные перехватчики, пожалуй теперь самое время рассказать о том, что это такое. Перехватчики — это обработчики событий, которые работают на этапе между получением событий на источнике и отправкой их в канал. Перехватчики могут преобразовывать события, изменять их или фильтровать.
Flume предоставляет по умолчанию множество перехватчиков, позволяющих:
- Добавлять статичные заголовки (константы, timestamp, hostname).
- Генерировать случайный UUID в заголовках.
- Извлекать значения из тела события (регулярными выражениями) и использовать их как заголовки.
- Изменять содержимое событий (опять регулярными выражениями).
- Фильтровать события на основе содержимого.
# ============================ Avro-источник с перехватчиками ============================ #
# Обязательные параметры для Vvro-источника
my-agent.sources.avro-source.type = avro
my-agent.sources.avro-source.bind = 0.0.0.0
my-agent.sources.avro-source.port = 50001
my-agent.sources.avro-source.channels = my-agent-channel
# Добавляем к источнику перехватчики, указываем их названия (названия значения не имеют)
my-agent.sources.avro-source.interceptors = ts directory host replace group-replace filter extractor
# ------------------------------------------------------------------------------ #
# Первый перехватчик добавляет статичный заголовок ко всем событиям.
# Наименование заголовка будет "dir", а значение — "test-folder".
my-agent.sources.avro-source.interceptors.directory.type = static
my-agent.sources.avro-source.interceptors.directory.key = dir
my-agent.sources.avro-source.interceptors.directory.value = test-folder
# Если такой заголовок уже есть — сохранить имеющийся (по умолчанию — false)
my-agent.sources.avro-source.interceptors.directory.preserveExisting = true
# ------------------------------------------------------------------------------ #
# Второй перехватчик добавляет заголовок "timestamp" ко всем событиям с текущим значением времени, в миллисекундах
my-agent.sources.avro-source.interceptors.ts.type = timestamp
my-agent.sources.avro-source.interceptors.ts.preserveExisting = true
# ------------------------------------------------------------------------------ #
# Третий перехватчик добавляет заголовок с хостом/IP текущей машины
my-agent.sources.avro-source.interceptors.host.type = host
my-agent.sources.avro-source.interceptors.host.useIP = true
# Наименование заголовка (аналог directory.key)
my-agent.sources.avro-source.interceptors.host.hostHeader = host
my-agent.sources.avro-source.interceptors.host.preserveExisting = true
# ------------------------------------------------------------------------------ #
# Этот перехватчик заменяет все символы табуляции на ; в теле события
my-agent.sources.avro-source.interceptors.replace.type = search_replace
my-agent.sources.avro-source.interceptors.replace.searchPattern = \t
my-agent.sources.avro-source.interceptors.replace.replaceString = ;
# Тело передается как byte[], поэтому необходимо указать кодировку (по умолчанию — UTF-8)
my-agent.sources.avro-source.interceptors.replace.charset = UTF-8
# ------------------------------------------------------------------------------ #
# Более "умный" вариант замены
my-agent.sources.avro-source.interceptors.group-replace.type = search_replace
# Предположим, наша строка начинается с даты 2014-01-20 и нам нужно поменять ее формат на 20/01/2014
# при этом сохранив всё остальное. Мы "разбиваем" строку на 4 блока () и затем выполняем подстановку,
# используя индексы этих блоков в результирующей строке
my-agent.sources.avro-source.interceptors.group-replace.searchPattern = (\\d{4})-(\\d{2})-(\\d{2})(.*)
my-agent.sources.avro-source.interceptors.group-replace.replaceString = $3/$2/$1$4
# ------------------------------------------------------------------------------ #
# Перехватчик-фильтр, исключает события по регулярному выражению
my-agent.sources.avro-source.interceptors.filter.type = regex_filter
my-agent.sources.avro-source.interceptors.filter.regex = error$
# Если true — то фильтровать события, тело которых подходит под регулярное выражение,
# в противном случае — фильтровать то, что не подходит под регулярку
my-agent.sources.avro-source.interceptors.filter.excludeEvents = true
# ------------------------------------------------------------------------------ #
# Перехватчик, извлекающий данные из события и добавляющий их в заголовки
my-agent.sources.avro-source.interceptors.extractor.type = regex_extractor
# Например, мы передаем события вида: "2016-04-15;WARINING;КАКАЯ-ТО ИНФОРМАЦИЯ"
my-agent.sources.avro-source.interceptors.extractor.regex = (\\d{4}-\\d{2}-\\d{2});(.*);
# здесь важно — сериализаторы должны быть перечислены в том же порядке,
# что и соотв. группы в регулярном выражении
# (\\d{4}-\\d{2}-\\d{2}) -> $1 -> ts
# (.*) -> $2 -> loglevel
my-agent.sources.avro-source.interceptors.extractor.serializers = ts loglevel
# Первую группу будем сериализовать специальным классом, который извлекая из даты TS
my-agent.sources.avro-source.interceptors.extractor.serializers.ts.type = org.apache.flume.interceptor.RegexExtractorInterceptorMillisSerializer
my-agent.sources.avro-source.interceptors.extractor.serializers.ts.name = timestamp
my-agent.sources.avro-source.interceptors.extractor.serializers.ts.pattern = yyyy-MM-dd
# Вторую группу будем сериализовать as is
my-agent.sources.avro-source.interceptors.extractor.serializers.loglevel.name = levelСреди стандартных перехватчиков, к несчастью, не обнаружилось фильтра по заголовкам. Впрочем, при желании такой перехватчик можно написать самому. Теперь, чтобы полноценно сконфигурировать транспорт Flume, нам необходимо рассмотреть еще один тип компонентов Flume — селекторы.
Канальные селекторы (Flume Channel Selectors)
Селектор необходим каналу для того, чтобы понимать, в какой канал какие события отправлять. Всего существует 2 типа селекторов:
- replicating — селектор, благодаря которому источник дублирует события во все связанные каналы. Именно он используется Flume по умолчанию. При этом, этот селектор позволяет выделить «опциональные» каналы. В отличии от основных, источник будет игнорировать неудачные добавления событий в такие каналы.
- multiplexing — селектор, распределяющий события между каналами по некоторым правилам. Реализация стандартного multiplexing-селектора позволяет распределять события между каналами на основе значений заголовков.
# ============================ Avro-источник с селектором ============================ #
my-source.sources.avro-source.type = avro
my-source.sources.avro-source.port = 50002
my-source.sources.avro-source.bind = 127.0.0.1
my-source.sources.avro-source.channels = hdfs-channel file-roll-channel null-channel
# Объявляем селектор — multiplexing, будем сортировать события
# Предположим, что мы ранее помечали события как "важные" и "обычные" и хотим,
# чтобы важные события записывались в файловую систему и HDFS, а обычные — только в файлы
my-source.sources.avro-source.selector.type = multiplexing
# указываем название заголовка, по которому будем делить события
my-source.sources.avro-source.selector.header = type
# если type = important, то отправляем события и в HDFS, и в файловый сток
my-source.sources.avro-source.selector.mapping.important = hdfs-channel file-roll-channel
# если type = common, то только в файловый сток
my-source.sources.avro-source.selector.mapping.common = file-roll-channel
# если заголовок type не найден или значение какое-то другое, отправляем событие на фильтрацию
# (как правило, для фильтрации используем небольшой memchannel и null-sink)
my-source.sources.avro-source.selector.mapping.default = hdfs-null-channelСелекторы обрабатывают события после перехватчиков. Это значит, что вы можете выполнить над событиями некоторые манипуляции перехватчиками (например, понаизвлекать различные заголовки) и использовать результаты этих манипуляций уже в селекторе.
Заключение
Статья неожиданно получилась большой, поэтому обещанный мониторинг узла я решил рассмотреть в следующей части этого цикла статей. В заключение хочу продемонстрировать одну из рабочих конфигураций Flume для HDFS. Она неплохо подходит для доставки и организации небольших объемов данных — примерно до 2000 событий в секунду на одну ноду. Этот узел требует наличия в событиях заголовков roll («15m» или «60m»), dir и srс — с помощью них получается двухуровневая иерархия папок.
flume-hdfs.sources = hdfs-source
flume-hdfs.channels = hdfs-15m-channel hdfs-60m-channel hdfs-null-channel
flume-hdfs.sinks = hdfs-15m-sink hdfs-60m-sink
# =========== Avro-источник, с селектором и добавлением заголовка host ============ #
flume-hdfs.sources.hdfs-source.type = avro
flume-hdfs.sources.hdfs-source.port = 50002
flume-hdfs.sources.hdfs-source.bind = 0.0.0.0
flume-hdfs.sources.hdfs-source.interceptors = hostname
flume-hdfs.sources.hdfs-source.interceptors.hostname.type = host
flume-hdfs.sources.hdfs-source.interceptors.hostname.hostHeader = host
flume-hdfs.sources.hdfs-source.channels = hdfs-null-channel hdfs-15m-channel
flume-hdfs.sources.hdfs-source.selector.type = multiplexing
flume-hdfs.sources.hdfs-source.selector.header = roll
flume-hdfs.sources.hdfs-source.selector.mapping.15m = hdfs-15m-channel
flume-hdfs.sources.hdfs-source.selector.mapping.60m = hdfs-60m-channel
flume-hdfs.sources.hdfs-source.selector.mapping.default = hdfs-null-channel
# ============================ Файловый канал, 15 минут ============================ #
flume-hdfs.channels.hdfs-15m-channel.type = file
flume-hdfs.channels.hdfs-15m-channel.maxFileSize = 1073741824
flume-hdfs.channels.hdfs-15m-channel.capacity = 10000000
flume-hdfs.channels.hdfs-15m-channel.transactionCapacity = 10000
flume-hdfs.channels.hdfs-15m-channel.dataDirs = /flume/flume-hdfs/hdfs-60m-channel/data1,/flume/flume-hdfs/hdfs-60m-channel/data2
flume-hdfs.channels.hdfs-15m-channel.checkpointDir = /flume/flume-hdfs/hdfs-15m-channel/checkpoint
# ============================ Файловый канал, 60 минут ============================ #
flume-hdfs.channels.hdfs-60m-channel.type = file
flume-hdfs.channels.hdfs-60m-channel.maxFileSize = 1073741824
flume-hdfs.channels.hdfs-60m-channel.capacity = 10000000
flume-hdfs.channels.hdfs-60m-channel.transactionCapacity = 10000
flume-hdfs.channels.hdfs-60m-channel.dataDirs =/flume/flume-hdfs/hdfs-60m-channel/data1,/flume/flume-hdfs/hdfs-60m-channel/data2
flume-hdfs.channels.hdfs-60m-channel.checkpointDir = /flume/flume-hdfs/hdfs-60m-channel/checkpoint
# =========== Сток для файлов, заворачиваемых каждые 15 минут (5 мин. неактивности) =========== #
flume-hdfs.sinks.hdfs-15m-sink.type = hdfs
flume-hdfs.sinks.hdfs-15m-sink.channel = hdfs-15m-channel
flume-hdfs.sinks.hdfs-15m-sink.hdfs.filePrefix = %{src}/%Y-%m-%d/%Y-%m-%d-%H-%M-%S.%{src}.%{host}.log
flume-hdfs.sinks.hdfs-15m-sink.hdfs.path = /logs/%{dir}
flume-hdfs.sinks.hdfs-15m-sink.hdfs.fileSuffix = .gz
flume-hdfs.sinks.hdfs-15m-sink.hdfs.writeFormat = Text
flume-hdfs.sinks.hdfs-15m-sink.hdfs.codeC = gzip
flume-hdfs.sinks.hdfs-15m-sink.hdfs.fileType = CompressedStream
flume-hdfs.sinks.hdfs-15m-sink.hdfs.minBlockReplicas = 1
flume-hdfs.sinks.hdfs-15m-sink.hdfs.rollInterval = 0
flume-hdfs.sinks.hdfs-15m-sink.hdfs.rollSize = 0
flume-hdfs.sinks.hdfs-15m-sink.hdfs.rollCount = 0
flume-hdfs.sinks.hdfs-15m-sink.hdfs.idleTimeout = 300
flume-hdfs.sinks.hdfs-15m-sink.hdfs.round = true
flume-hdfs.sinks.hdfs-15m-sink.hdfs.roundValue = 15
flume-hdfs.sinks.hdfs-15m-sink.hdfs.roundUnit = minute
flume-hdfs.sinks.hdfs-15m-sink.hdfs.threadsPoolSize = 8
flume-hdfs.sinks.hdfs-15m-sink.hdfs.batchSize = 10000
# =========== Сток для файлов, заворачиваемых каждые 60 минут (20 мин. неактивности) =========== #
flume-hdfs.sinks.hdfs-60m-sink.type = hdfs
flume-hdfs.sinks.hdfs-60m-sink.channel = hdfs-60m-channel
flume-hdfs.sinks.hdfs-60m-sink.hdfs.filePrefix = %{src}/%Y-%m-%d/%Y-%m-%d-%H-%M-%S.%{src}.%{host}.log
flume-hdfs.sinks.hdfs-60m-sink.hdfs.path = /logs/%{dir}
flume-hdfs.sinks.hdfs-60m-sink.hdfs.fileSuffix = .gz
flume-hdfs.sinks.hdfs-60m-sink.hdfs.writeFormat = Text
flume-hdfs.sinks.hdfs-60m-sink.hdfs.codeC = gzip
flume-hdfs.sinks.hdfs-60m-sink.hdfs.fileType = CompressedStream
flume-hdfs.sinks.hdfs-60m-sink.hdfs.minBlockReplicas = 1
flume-hdfs.sinks.hdfs-60m-sink.hdfs.rollInterval = 0
flume-hdfs.sinks.hdfs-60m-sink.hdfs.rollSize = 0
flume-hdfs.sinks.hdfs-60m-sink.hdfs.rollCount = 0
flume-hdfs.sinks.hdfs-60m-sink.hdfs.idleTimeout = 1200
flume-hdfs.sinks.hdfs-60m-sink.hdfs.round = true
flume-hdfs.sinks.hdfs-60m-sink.hdfs.roundValue = 60
flume-hdfs.sinks.hdfs-60m-sink.hdfs.roundUnit = minute
flume-hdfs.sinks.hdfs-60m-sink.hdfs.threadsPoolSize = 8
flume-hdfs.sinks.hdfs-60m-sink.hdfs.batchSize = 10000
# ================ NULL-сток + небольшой канал для него =============== #
flume-hdfs.channels.hdfs-null-channel.type = memory
flume-hdfs.channels.hdfs-null-channel.capacity = 30000
flume-hdfs.channels.hdfs-null-channel.transactionCapacity = 10000
flume-hdfs.channels.hdfs-null-channel.byteCapacityBufferPercentage = 20
flume-hdfs.sinks.hdfs-null-sink.channel = hdfs-null-channel
flume-hdfs.sinks.hdfs-null-sink.type = null
В следующей, заключительной статье цикла, мы рассмотрим:
- Процесс построения полноценного транспорта данных на основе Flume.
- Примеры разработки собственных компонентов.
- Обещанный мониторинг узлов, который не вошел в эту статью.
Комментарии (12)

voidnugget
22.04.2016 14:54Было бы неплохо объяснить что:
- Flume является средством потоковой обработки логов, т.е. вместо низких задержек у него в приоритете высокая пропускная способность и возможность простого партицирования (consistency + partition tolerance + weak availability)
- У Storm с точностью до наоборот — быстро обработали и отдали, в очередь больше положенного не кладём (availability + consistency + weak partitionioning)
- У Kafka задача — обеспечить высокую доступность с возможностью партицирования, но со слабой консистентностью (availability + partition tolerance + weak consistency)
- Сamel вообще не заморачивается с производительностью и доступностью — ему главное один интерфейс преобразовать в другой (consistency + whatever)
Грубо говоря, хаброобыватели из-за недопонимания специфических архитектурных решений высокодоступных или высокопроизводительных проектов сравнивают разные виды кошачих: тигра, гепарда, и льва; спрашивают: кто из них лучше добычу ловит? Вот надо сравнивать по обстоятельствам и ареалу обитания.

zyrik
22.04.2016 21:05А Вы не могли бы пояснить на пальцах, что все эти термины значат и где следуюет применять какое решение? Вот у меня пока совсем нету ещё представления, где лучше использовать Kafka, а где Flume. Возьмем пример, логи с помощью syslog-ng можно слать как в Flume, так и в Kafka. В каком случае какое решение надо выбирать?
voidnugget
22.04.2016 22:08
Что где использовать — зависит от объёма и скорости прироста логов, количества машин.
kafka спроектирована таким образом что бы работать в кластере, но вы не сможете получать наиболее актуальные данные в текущий момент времени. kafka это просто очередь событий/сообщений, никаких преобразований внутри не происходит. С flume ситуация совсем другая: он обрабатывает и преобразовывает логи в удобоваримый вид для последующей записи в БД hdfs / hbase / scylladb etc. flume может быть как потребителем (sink) данных с kafka, и преобразовывать логи, которые хранятся в очередях, так и поставщиком данных (source) для kafka.
По этому, это проекты с совершенно различными задачами.
Если вам не хватает пропускной способности flume — вы перед ним ставите kafka в качестве буфера.
Также очереди на kafka довольно просто реплицировать для обеспечения отказоустойчивости.
Deneb
22.04.2016 22:15Если вам не хватает пропускной способности flume — вы перед ним ставите kafka в качестве буфера.
Не могли бы вы пояснить, каким образом использование Kafka между клиентом и Flume поможет решить проблему с пропускной способностью?voidnugget
22.04.2016 22:33Если объяснять на пальцах правой ноги, то:
Вот у вас есть винт с пропускной способностью в 3Гбит'a и большими задержками? и есть оперативка с пропускной способностью в 12Гбит и низкими задержками?, вот вы ж в оперативку пишите избыток того что пишется на винт, и потребление памяти будет расти в логарифмической прогрессии, в идеальных условиях.
Вот те же яйца и с kafka и flume: у вас есть flume со средней пропускной способностью и большими задержками?, и есть kafka, с высокой пропускной способностью и низкими задержками?, почти как запись в /dev/null.
kafka по своей природе любит кушать гигабайты и десятки гигабайт оператвы и слаживать всё в чистом виде на винт, прямо как на грампластинку. Потом это всё можно обработать 4-8 flume'ами, положить в другую kafk'у или сразу записать в БД.
? — под задержкой нужно понимать готовность устройства к обработке следующего запроса.
Deneb
22.04.2016 22:39Что мешает сразу раскидывать всё это добро по 4-8 узлам Flume? Мы же рассматриваем потоковую обработку данных, у нас нет никакого «потом». Если в цепочке хотя бы 1 звено не успевает, то в итоге «забиваются» все звенья перед ним — это вопрос времени. Другое дело, если вы рассматриваете пиковые нагрузки (т.е. Flume не справляется эпизодически) — но что тогда мешает просто сделать каналы потолще?
voidnugget
22.04.2016 22:46Под пропускной способностью имеется ввиду не пропускная способность сетевого интерфейса, а то сколько запросов Flume может обработать в секунду. Тут пишется о сценарии ~300-500Гб логов в час, с которого потом выжимается 120-250Гб.
voidnugget
22.04.2016 22:53Недавно вышла хорошая книжка по похожей теме
Site Reliability Engineering
Edited by Betsy Beyer, Chris Jones, Jennifer Petoff and Niall Richard Murphy
Deneb
22.04.2016 21:16Я думаю, чтобы определиться с решением, нужно сначала понять — а что дальше планируется делать с логами? Ведь отправить их в Flume/Kafka — это не конечная цель.
voidnugget
22.04.2016 22:39Обычно потом пишут в БД и отрисовуют всякими graylog'aми и kibana. После устаревания утрамбовывают этот компост в "холодное" хранилище на магнитных лентах "аля бобинах", в сервисах типа Amazon Glacier, и подёргивают 6-7 раз в год.
В чистом виде логи писать в БД получается очень расточительно — БД растут как на дрожжах, да и не каждый может позволить себе завести кластер elasticsearch'ей для kibana. Ну, чуваков c elastic.co тоже можно понять, они то разрабатывали всё это не для того что бы в больших масштабах с пол-пинка заводилось — нужно ещё кучу граблей и костылей, а им с того копеечка за поддержку и наставление падаванов.
facha
Большое спасибо за статью. Есть несколько не связанных между собой вопросов. Если можете, ответьте пожалуйста.
— Когда мы выбираем Avro Source и Avro Sink, Аvro используется только для передачи? Или данные сохраняются в Avro?
— Насколько flume конкурент новомодной kafka?
— Interseptors можно писать только на java?
Deneb
По вопросам: