
Интерфейс
Давайте сначала определим интерфейс данного фильтра. Можно выделить три основные функции:
- Конструктор
- Функция, чтобы добавить элемент к фильтру Блума
- Функция для запроса относится ли элемент частью фильтра Блума
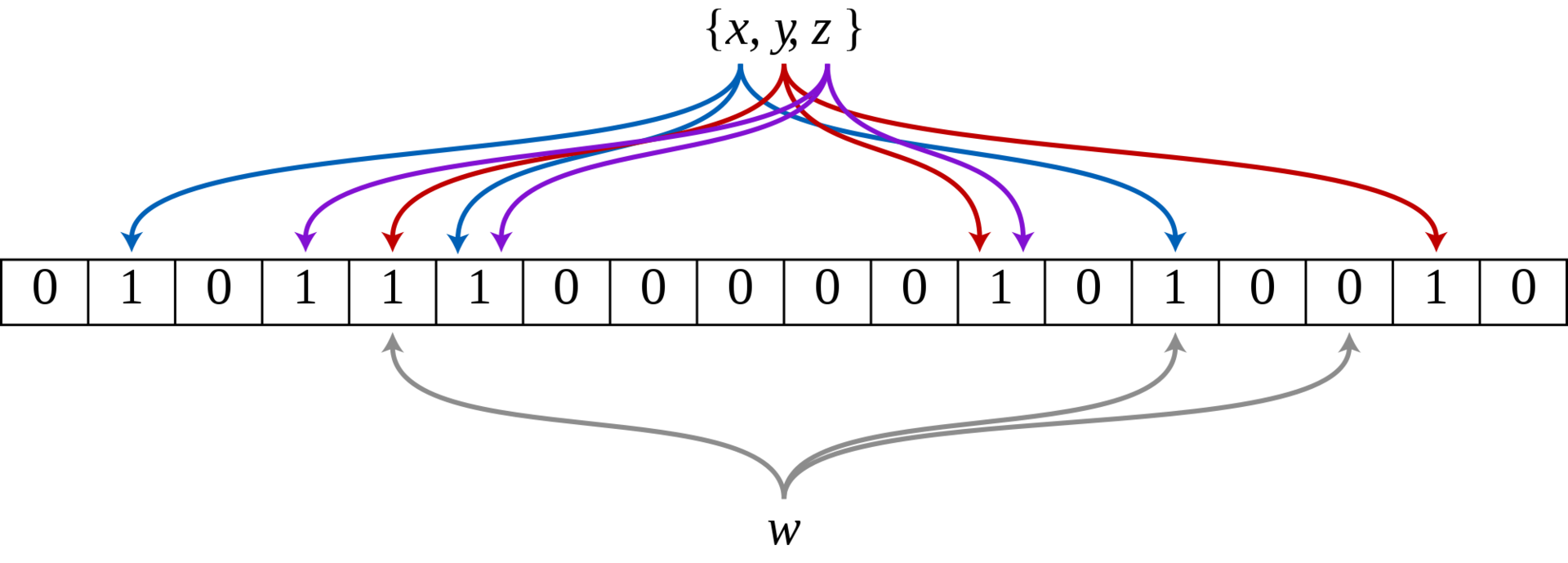
Несколько задействованных переменных, включая небольшое количество векторов, также содержат состояние фильтра.
#include <vector>
struct BloomFilter {
BloomFilter(uint64_t size, uint8_t numHashes);
void add(const uint8_t *data, std::size_t len);
bool possiblyContains(const uint8_t *data, std::size_t len) const;
private:
uint64_t m_size;
uint8_t m_numHashes;
std::vector<bool> m_bits;
};
Стоит отметить, что
std::vector<bool.> является намного более эффективной специализацией std::vector, требует только один бит на элемент (в отличие от одного байта в типичных реализациях). Можно обработать эту структуру по шаблону, как расширение. Вместо жесткого кодирования ключевых типов и хеш-функций, мы можем обработать класс по шаблону с чем-то подобным:
template< class Key, class Hash = std::hash<Key> >
struct BloomFilter {
...
};
Это позволит фильтру Блума быть обобщенным для более сложных типов данных.
Параметры фильтра Блума
Есть два параметра для построения фильтра Блума:
- Размер фильтра в битах
- Число хэш-функций для использования
Мы можем вычислить ложный положительный коэффициент ошибок — n, на основе размера фильтра — m, числа хэш-функций — K и число вложенных элементов -N, с помощью формулы:

Эта формула не очень полезна в таком виде. Но нам нужно знать насколько большой фильтр должен быть и сколько хеш-функций понадобится, чтобы использовать, учитывая предполагаемое количество элементов набора и коэффициент ошибок. Есть два уравнения, которые мы можем использовать для расчета этих параметров:

Реализация
Вы можете задаться вопросом, как же реализовать kk хеш-функции; двойное хеширование может использоваться, чтобы генерировать kk значения хэш-функции, не влияя на вероятность ложно-положительного результата! Такой результат можно получить используя формулу, где i — ординал, м — размер фильтра Блума и x — значение, которое будет хешировано:

Для начала нужно написать конструктор. Он просто записывает параметры масштабирования и битовый массив.
#include "BloomFilter.h"
#include "MurmurHash3.h"
BloomFilter::BloomFilter(uint64_t size, uint8_t numHashes)
: m_size(size),
m_numHashes(numHashes) {
m_bits.resize(size);
}
Далее давайте напишем функцию для вычисления 128 — битного хэша данного элемента. В данной реализации используется MurmurHash3, 128 бит хэш — функция, которая имеет хорошие компромиссы между производительностью, распределение, потоковым поведением и сопротивлением противоречиям. Поскольку эта функция генерирует 128 бит хэш и нам нужно 2х64 битные хэши, мы можем разделить возвращенный хэш пополам, чтобы получить хэшa(x) хэшb(x).
std::array<uint64_t, 2> hash(const uint8_t *data,
std::size_t len) {
std::array<uint64_t, 2> hashValue;
MurmurHash3_x64_128(data, len, 0, hashValue.data());
return hashValue;
}
Теперь, когда у нас есть хэш-значения, нужно написать функцию, чтобы вернуть выходной сигнал n хэш-функции.
inline uint64_t nthHash(uint8_t n,
uint64_t hashA,
uint64_t hashB,
uint64_t filterSize) {
return (hashA + n * hashB) % filterSize;
}
Все, что осталось сделать — это написать функции для набора контрольных битов для заданных элементов.
void BloomFilter::add(const uint8_t *data, std::size_t len) {
auto hashValues = hash(data, len);
for (int n = 0; n < m_numHashes; n++) {
m_bits[nthHash(n, hashValues[0], hashValues[1], m_size)] = true;
}
}
bool BloomFilter::possiblyContains(const uint8_t *data, std::size_t len) const {
auto hashValues = hash(data, len);
for (int n = 0; n < m_numHashes; n++) {
if (!m_bits[nthHash(n, hashValues[0], hashValues[1], m_size)]) {
return false;
}
}
return true;
}
Результаты
С помощью фильтра Блума 4.3MБ и 13 хэш-функции, вставляя элементы 1.8МБ приняли примерно 189 наносекунд для каждого элемента на средней производительности ноутбуке.
Оригинал данного поста Вы можете найти по ссылке.
Комментарии (30)

bsisoft
13.04.2016 15:38+1Скажите, а Вам приходилось на практике применять фильтр Блума? Если несложно, поясните где и как Вы его использовали?

Biga
13.04.2016 18:24Могу поделиться своим примером.
Есть сервер сообщений для игры. Обычный pub-sub, то есть клиент коннектится к серверу, подписывается на каналы и ждёт сообщений. Запущено несколько экземпляров сервера для балансировки. Сервера соединяются друг с другом и сообщают, у кого какие подписки, чтобы не бродкастить все сообщения на все сервера. Тут и применяется блум-фильтр: сами идентификаторы подписок не хранятся, есть только несколько бит в блум-фильтре. Используется модификация блум-фильтра — со счётчиком, но работает абсолютно так же.
khim
13.04.2016 18:40+1А кеширование — вы когда-либо использовали? Вот Блум Фильтр — это, грубо говоря, «кеш для кешей»: так как вы храните на один элемент данных только пару-тройку бит, то вы можете точно сказать — стоит вам ходить в кеш или нужно напрямую идти в «медленное» хранилище. Идея кажется дикой — но только до тех пор пока кеш у вас один. Если же кеширующих серверов становится много — вот тогда важно знать какой из них чего знает (и знает ли вообще хоть кто-нибудь хоть чего-нибудь).

begemot_sun
13.04.2016 16:13Добавьте тэг: фильтр Блума. Чтобы было доступно тут:
https://habrahabr.ru/search/?q=%5B%D1%84%D0%B8%D0%BB%D1%8C%D1%82%D1%80%20%D0%B1%D0%BB%D1%83%D0%BC%D0%B0%5D&target_type=posts

Jek_Rock
13.04.2016 16:23+1Вот что Мейерс пишет про std::vector:
«Vector как контейнер STL обладает лишь двумя недостатками. Во-первых, это вообще не контейнер STL. Во-вторых, он не содержит bool.»



ryzhikovas
13.04.2016 16:23«Стоит отметить, что std::vector является намного более эффективной специализацией» — очень спорное утверждение. Требует меньше памяти — да. Но скорость доступа меньше, чем, например, у vector за счет объекта-провайдера, возвращаемого operator[].
khim
13.04.2016 17:00Объект провайдер современные реализации легко выкидывают, это не беда. Беда в том, что на платформе где это важнее всего (почти весь TOP500 — это x86, ведь так?) он не использует операции, которые могли бы его сделать реально быстрым (компилятор про них не знает, а реализацию на asm'е некому сделать).
Кстати неплохая идея для того, кто хочет лучше разобраться с C++: потратить пару вечеров и сделать приличную реализацию vector<bool>… а потом потратить ещё пару месяцев, чтобы убедить разработчиков GCC его включить к себе в библиотеку :-)
Сделать парочку бенчмарков, померить скорость… есть желающие?encyclopedist
15.04.2016 03:33Уже делали.
Вот например статья Ховарда Хиннанта (автора libc++).
Где-то была и оптимизированная реализация, кажется ввиде патча к одной из стандартных библиотек, кажется как раз libc++, но я что-то не могу найти.khim
15.04.2016 12:01Оптимизированную версию делали и не раз. Я сам лично делал и использовал отпимизированную версию в паре своих проктов — это как раз не фокус.
Фокус в том, чтобы сделать оптимизированную версию совместимую с std::vector<bool> и продвинуть её в GCC/Clang (ну или, если вы мазохист, в MSVC).
Дело в том, что в STL — весьма много разновсяких требований, а в x86 (да и в других процессорах) — много разных интересных функций (к примеру тот же find: использовать прямо вот так __builtin_ctz там нельзя, так как результат не определён, но если мы пишем под GCC/Clang, то мы можем вспомнить что у нас есть ассемблер, а в нём — реакция на нуль вполне разумна: BSF/BSR флаг Z выставляют правильно), так что есть где порезвиться и поразвлекаться при создании всего этого (опять-таки при наличии SSE4.2/AVX2 есть PTEST — но для него нужно увеличивать минимальные размеры std::vector<bool>).
В общем с технической точки зрения там ничего страшного и/или сложного нет, а вот если попытаться это продвинуть в стандартную библиотеку… вот это — уже для мазохистов…JIghtuse
15.04.2016 15:01std::vector<bool>ведь упразднять хотят, и вообще он немало проблем родил. Смысл его куда-то продвигать?khim
15.04.2016 15:31У вас с временами что-то не то: не хотят, а хотели. И от этой идеи отказались. И в C++11 и в C++14 он вполне себе есть и никто от него отказываться не собирается. Так может стоит наконец сделать приличную реализацию?
theg4sh
14.04.2016 12:43> Стоит отметить, что std::vector является намного более эффективной специализацией std::vector,…
Не уловил разницы между std::vector и std::vector, видимо упущено что-то типа?

knagaev
15.04.2016 12:34+2Товарищи… ну нельзя же так переводить…
У вас
«С помощью фильтра Блума 4.3MБ и 13 хэш-функции, вставляя элементы 1.8МБ приняли примерно 189 наносекунд для каждого элемента на средней производительности ноутбуке.»
Должно быть
«C 4.3-Мбайтным фильтром Блума и 13 хэш-функциями при добавлении 1.8 миллионов элементов среднее время вставки одного элемента составило приблизительно 189 наносекунд на моем ноутбуке.»
(Оригинал — With a 4.3MB Bloom filter and 13 hash functions, inserting 1.8M items took roughly 189 nanoseconds per element on my laptop.)
P.S. И всё равно за статью большое спасибо :)
lockywolf
20.04.2016 15:11Как-то не очень круто иметь фильтр в три раза больше самого набора данных.
knagaev
20.04.2016 15:15+2Тут в том-то и дело, что в оригинальной статье фильтр мерился в мегабайтах, а набор данных в элементах.
Если элементы размером не меньше трёх битов, то набор всё-таки будет больше фильтра :)
RomanArzumanyan
Можно кратное введение для тех, кто не в теме: где применяется данный фильтр, и почему его стоит писать на С++?
IvaYan
Фильтр Блума позволяет очень эффективно определить, «видел» ли фильтр некие данные. Фильтр может давать ложноположительные срабатывания (не видел, но говорит, что видел), но никогда на дает ложноотрицательных (если фильтр говорит, что не видел, значит 100% не видел).
Используется, например, в базах данных при поиске страниц. Через фильтр прогоняется какой-нибудь идентификатор страницы, и если фильтр говорит, что «видел» его, то страница в памяти, иначе — на диске. Фильтр он в том смысле, что «фильтрует» запросы к диску.
Komei
Меня мучает такой вопрос, а чем он эффективнее простого битового массива + установка бита по одной хеш-функции?
khim
Меньше ложноположительных срабатываний.
Грубо: пусть у вас массив, скажем, на 20'000 битов. Если он «увидит» 1000 элементов с одной хорошей хеш-функцией, то он пропустит новый элемент с вероятностью 1/20.
Если же вы построили блум-фильтр на 10 функций, то даже если в этом массиве будет установлена половина битов (а больше ну никак не выйдет), то каждая функция будет давать ложноположительное срабатывание с вероятностью 1/2 — но зато все вместе они датут отсеивание с 99.9% вероятностью! А 1/1000 — это гораздо лучше, чем 1/20, согласитесь.
Чем больше у вас функций — тем больше выигрыш, но и тем больше памяти нужно для эффективной работы и тем медленнее работает фильтр.
Komei
Большое спасибо. Теперь ясно.
afend69
Очень просто. У Вас есть миллиард объектов. Вам нужно найти объект, удовлетворяющий заданным условиям (состоянию). Прежде чем начать поиск, при помощи фильтра Блума Вы можете определить (с определенной вероятностью), что этот объект есть в этом наборе. Или его там нет. Читал, что фильтр Блума использует Google.
RPG18
В частности в LevelDB
Whiteha
Фильтр Блума компактно хранит множество элементов и позволяет проверять принадлежность заданного элемента к множеству, с фолспозитивами, но без фолснегативов. C++ потому что это структура данных предназначена для чего-то высокопроизводительного, относительно больших объемов данных, а обычно такие вещи требуют плюсов.
Примеры из вики:
Прокси-сервер Squid использует фильтры Блума для опции cache digests.
Google BigTable использует фильтры Блума для уменьшения числа обращений к жесткому диску при проверке на существование заданной строки или столбца в таблице базы данных.
Компьютерные программы для проверки орфографии.
Биоинформатика.
JIghtuse
В оригинальной статье есть краткая справка и пара ссылок на подробности. Непонятно, зачем при переводе убрали.