
Взрывной рост частного и корпоративного контента признан одной из самых значимых характеристик десятилетия. Согласно данным журнала «Экономист», в начале 2000-х было создано всего 150 экзабайт (миллиардов гигабайт) контента, а уже через 10 лет этот показатель возрос до 1200 экзабайт. Согласно прогнозам, эта цифра возрастет в тысячи раз к 2020 году.
Мы в Cloud4Y считаем, что единственный возможный прогноз относительно требований к будущим хранилищам данных — их полная непрогнозируемость, а также тот факт, что их объем будет значительно больше того, который только можно представить. Вместо того, чтобы пытаться управлять этим ростом, следует сместить фокус на управление «Большим Контентом».
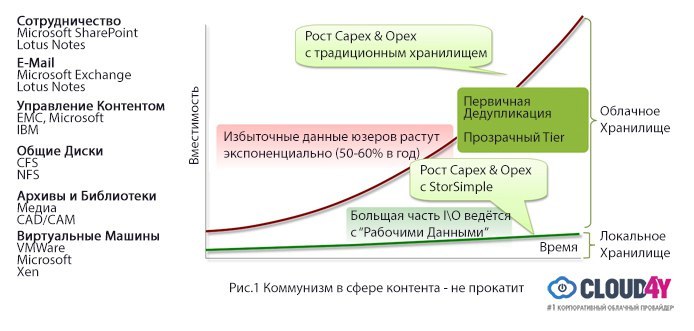
Общий объем контента неуклонно растет. Однако большинство людей заботится только о неком «рабочем наборе» контента. Например, в SharePoint люди чаще переживают о последних добавленных данных, а если речь идет об электронной почте, то нас скорее заботят сегодняшние письма, а не полученные год назад.
Традиционной проблемой «Большого Контента» считается скромный общий диск, где хранится общий контент. Например, здесь может храниться корпоративная презентация, и типичный индивид просто берет ее, делает «копипаст», добавляет пару слайдов от себя и сохраняет новую копию. Одни и те же слайды пересохраняются снова и снова, при этом старые презентации никуда не деваются. Знакомо, не так ли?
Новой большой проблемой «Большого Контента» считаются огромный объемы видео и другихмедиа-средств . При всем этом мы не можем грести весь контент под одну гребенку; при работе с ним следует думать как Google, иначе капитальные и операционные расходы будут расти пропорционально объемам информации.
Если бы поисковики считали все данные одинаковыми, искомая информация могла бы найтись как на первой, так и на двадцатой странице. Поисковые сервисы научились ранжировать информацию, и этот же подход должен применяться к сохраняемым нами ежедневно данным — причем автоматически, без участия человека. Контент первостепенной необходимости должен располагаться на доступных локальных дисках, а второстепенные данные — автоматически ранжировано складироваться в облаке.
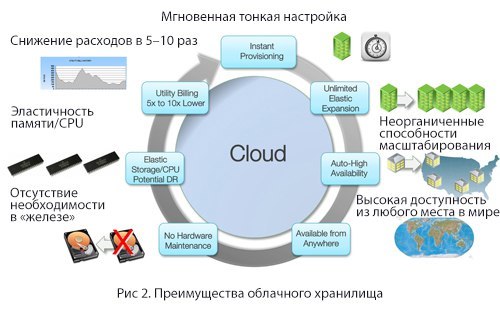
Когда дело касается хранения, облако имеет некоторые неоспоримые преимущества:
Приведем некоторые мифы об облачных хранилищах:
Архитектура Cloud-
Чтобы использовать преимущества, присущие облаку, нужно иметь архитектуру, предназначенную для него. В данной статье будут рассмотрены модели использования архитектуры «Cloud-as-a-Tier » и представлены идеи о том, как она может быть использована для организации безопасных многоуровневых корпоративных облачных систем хранения данных. Мы рассмотрим это в контексте динамического жизненного цикла контента в облаке в сравнении с традиционными способами хранения, архивации и защиты данных, а также аварийного восстановления.
В качестве заключения мы представим вам модель новой, более простой корпоративной облачной архитектуры хранения, которая станет альтернативой для покупки «железа» и ПО с целью создания:
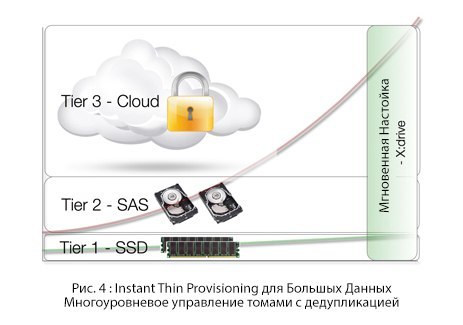
Когда вы планируете развертывание приложений для «Большого Контента», основной вопрос — сколько памяти для него необходимо.
Если ваши планы уходят далеко вперед и рассчитываете объемы хранилища не по годам, а по терабайтам (то есть, хотите платить только за использованное пространство), то вы существенно экономите. С другой стороны, если вы занимаетесь только краткосрочным планированием, и у вас внезапно заканчивается дисковое пространство, вы теряете время и вынуждены заниматься перепланированием и реорганизацией.
Ведь, как мы уже сказали во введении, «единственный возможный прогноз относительно требований к будущим хранилищам данных — их полная непрогнозируемость».
Традиционный подход, впервые испытанный компанией HP с их 3PAR, подразумевает «Тонкое выделение ресурсов», снимающее необходимость в авансовом выделении мощностей. Гибридное облако выводит этот принцип на новый уровень, позволяя компаниям мгновенно обеспечивать себя необходимыми объемами для хранения, оплачивая только использованные.
Самый простой пример, позволяющий проиллюстрировать все это — SharePoint. Как мы уже говорили, для пользователя свойственно менять, например, в презентации размером в 5 Мб только имя автора и титульный лист, сохраняя обе версии. Традиционно обе версии весят 5 Мб; дедупликация меняет этот подход, представляя весь информационный мир как набор информационных блоков. Один и тот же блок никогда не сохраняется дважды; в нашем примере будут сохранены только измененные блоки, позволяя второй версии презентации занимать десятки килобайт вместо 5 Мб.
Взгляд на информационный мир как на набор блоков имеет и другие преимущества. Например, контент, который необходим постоянно, выводится на передний уровень, а тот, который не используется годами, просто хранитсягде-то на заднем плане — все это аналогично ранжированию сайтов в поисковике.
Безопасность в Cloud-
Нарушения безопасности обычно подразумевают доступ человека к незашифрованным данным. Последние примеры таков: правительство Великобритании сохранило данные о страховании каждого гражданина вместе с его банковскими реквизитами и отправило их в Лондон. Впоследствии все эти данные были проданы в Интернете. Сегодня сложное шифрование данных сделало бы эти нарушения безопасности невозможными. Безопасности в облаке — это просто вопрос воспитания.
Есть несколько ключевых архитектурных вопросов, которые важны для реализации защищенного облака. Все блоки, которые перемещаются от локального хранилища к облаку хранения должны быть зашифрованы как в состоянии покоя, так и в движении. Второй важный компонент — это управление ключами: они должны храниться у заказчика, а не в облаке. Иначе мы снова полагаемся на человека, позволяя ему осуществлять доступ к незашифрованному контенту.
Существует дополнительный способ: агрегированный доступ к хранилищу, когда каждый клиент имеет свой собственный ключ. Однако продавец — агрегатор, также имеет доступ к этим ключам — и снова это угроза безопасности.
Как мы уже говорили, «Коммунизм Контента» неприменим к облаку: вы же не хотели бы, что весь ваш контент перенесся в облако — вам нужно чтобы исчезла из зоны видимости неиспользуемая его часть. Все, что нужно для архитектуры «Сloud-as-a-tier » — это способность понять поведение пользователя и адаптировать к нему особенности хранения.
С ростом объемов сохраняемой информации у администраторов возникает потребность архивировать ее часть и изымать из живого доступа. Обычно это делается из соображений экономии. При этом возможны проблемы по мере необходимости в данных: что, например, если данные, заархивированные после шестимесячного простоя, срочно необходимы к ежегодному отчету?
В системах типа Content Management Systems или SharePoint архивирование происходит еще более сложно, ведь необходимо архивировать не только контент, но также связанные с ним политики безопасности и многое другое. Многочисленные блоки, связанные между собой, должны быть заархивированы таким образом, чтобы при необходимости доступ осуществлялся ко всей информации в комплексе.
Облако с его эластичностью предлагает огромные объемы, свободные для размещения данных, и имеет потенциал для того, чтобы стать решением вопроса. Экономика хранения становится оптимальной, когда объединяются возможности дедупликации, сжатия и шифрования и облако используется для основного и резервного хранения.
Облако не стоит рассматривать как просто диск в глобальной сети; поступая так, вы можете получить печальный опыт, особенно, если вы не знаете о резервном копировании.
Люди в шутку говорят: «Какой самый быстрый способ резервного копирования в облако? Ответ — просто ничего не делать». Если вы храните данные в облаке, то это и есть резервное копирование. Копироваться для создания резервной версии должен только тот контент, который хранится в данный момент на устройстве — естественно, после дедупликации, сжатия и шифрования. Точнее, только уникальные блоки информации такого контента — достаточно скромный объем.
Быстрое восстановление «Большого Контента» из облака
Известно, что люди неочень-то задумываются о создании резервных копий — до того момента, как эти копии могут понадобиться.
Облачная архитектура имеет большое влияние на возможности восстановления данных в первичном или вторичном ЦОД. Если ваша резервная версия — это одна большая информационная «глыба» весом в несколько терабайт, то восстановление может быть медленным и болезненным процессом. Для быстрого восстановления необходимо использовать возможности «cloud-as-a-tier ».
Такой подход позволяет складировать информацию в многоуровневые структуры для хранения рабочего набора на быстрых SSD и локальных дисках. Архитектура позволяет рационально восстанавливать мультитерабайтные объемы — без вытягивания всего информационного объема. Извлекается только небольшое количество данных — «рабочий набор», а остальные блоки остаются в облаке и выдаются по мере необходимости. «Рабочий набор» создается заново буквально на лету, а в это время полный объем данных уже снова на своем месте.
Аварийное восстановление в Cloud-
Если спросить пользователей, как часто они проверяют свои процедуры аварийного восстановления, они начинают говорить очень тихо или краснеть. Аварии по своей натуре непредсказуемы. До 11 сентября процедура переноса записанных сохраненных данных происходила с помощью самолетов, а когда случился ураган Катрина, все данные остались в затопленных шахтах.
С появлением облака возникла возможность регулярно проверять политики аварийного восстановления, ведь облако доступно отовсюду и в любой момент.
Все, что необходимо — это иметь под рукой доступный девайс, на который можно установить всю конфигурацию. Затем облачные объемы могут снова перенестись для хранения в удаленное место, а контент снова становится доступен.
«Большой Контент» и виртуальная машина имеют одно общее свойство — они достаточно объемные. Обширные библиотеки виртуальных машин также могут храниться с использованием архитектуры «cloud-as-a-tier ». Архитектура может применяться как ко всей виртуальной машине, так и просто к хранилищу данных.
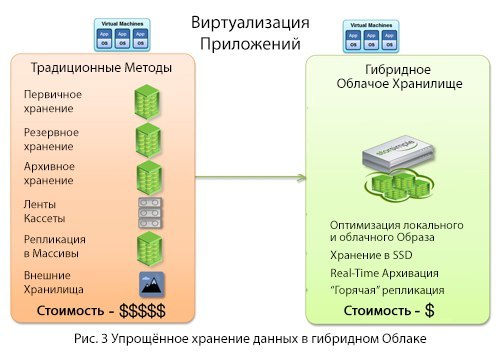
Традиционный подход к корпоративному хранению достаточно сложениз-за особенностей программного или аппаратного обеспечения. Для традиционного подхода необходимо слишком много факторов.
Гибридное облако с архитектурой «cloud-as-a-tier » разработано для использования преимуществ, присущих облаку, и упрощения хранения. Гибридному облаку необходимы всего две составляющих:
Проще говоря, облако позволяет ранжировать информацию и хранить в локальном доступе только то, что необходимо на ежедневной основе. Ваши локальные приложения остаются на месте — облако просто интегрируется в существующую сеть. Ничто не гарантирует такой простоты хранения «Большого Контента», как виртуальная машина. Как небольшие планеты вращаются вокруг огромных, так и «Большой Контент» привлечет шустрые виртуальные машины, а потом заставит их двигаться в сторону контента и облачного провайдера, который управляет контентом.
«Большой Контент» станет новым центром притяжения, и приложения последуют за ним в облако.
Мы в Cloud4Y считаем, что единственный возможный прогноз относительно требований к будущим хранилищам данных — их полная непрогнозируемость, а также тот факт, что их объем будет значительно больше того, который только можно представить. Вместо того, чтобы пытаться управлять этим ростом, следует сместить фокус на управление «Большим Контентом».
Коммунизм в сфере контента не работает, или думай как Google
Общий объем контента неуклонно растет. Однако большинство людей заботится только о неком «рабочем наборе» контента. Например, в SharePoint люди чаще переживают о последних добавленных данных, а если речь идет об электронной почте, то нас скорее заботят сегодняшние письма, а не полученные год назад.
Традиционной проблемой «Большого Контента» считается скромный общий диск, где хранится общий контент. Например, здесь может храниться корпоративная презентация, и типичный индивид просто берет ее, делает «копипаст», добавляет пару слайдов от себя и сохраняет новую копию. Одни и те же слайды пересохраняются снова и снова, при этом старые презентации никуда не деваются. Знакомо, не так ли?
Новой большой проблемой «Большого Контента» считаются огромный объемы видео и других
Если бы поисковики считали все данные одинаковыми, искомая информация могла бы найтись как на первой, так и на двадцатой странице. Поисковые сервисы научились ранжировать информацию, и этот же подход должен применяться к сохраняемым нами ежедневно данным — причем автоматически, без участия человека. Контент первостепенной необходимости должен располагаться на доступных локальных дисках, а второстепенные данные — автоматически ранжировано складироваться в облаке.
Потенциал облака и эластичного облачного хранилища
Когда дело касается хранения, облако имеет некоторые неоспоримые преимущества:
- Мгновенная тонкая настройка
- Неорганиченные способности масштабирования
- Высокая доступность из любого места в мире
- Отсутствие необходимости в «железе»
- Эластичность памяти/CPU
- Снижение расходов в 5–10 раз
Приведем некоторые мифы об облачных хранилищах:
- Вам придется переписать пользовательские приложения и реорганизовать резервное копирование, поскольку облако использует HTTP/REST API.
- Вам придется столкнуться с вопросами производительности
из-за задержек и затрат на полосы пропускания WAN. - Оптимизация WAN не работает с публичными облаками
- Облако небезопасно
Архитектура Cloud-as-a-Tier : стратегия корпоративного облачного хранения
Чтобы использовать преимущества, присущие облаку, нужно иметь архитектуру, предназначенную для него. В данной статье будут рассмотрены модели использования архитектуры «Cloud-
В качестве заключения мы представим вам модель новой, более простой корпоративной облачной архитектуры хранения, которая станет альтернативой для покупки «железа» и ПО с целью создания:
- Основного хранилища
- Хранилища резервных копий
- Архивного хранения
- Инфраструктуры и управления лентой данных
- Реплик данных для аварийного восстановления
- Удаленных площадок для
гео-устойчивости
Тонкое выделение ресурсов для «Большого Контента»
Когда вы планируете развертывание приложений для «Большого Контента», основной вопрос — сколько памяти для него необходимо.
Если ваши планы уходят далеко вперед и рассчитываете объемы хранилища не по годам, а по терабайтам (то есть, хотите платить только за использованное пространство), то вы существенно экономите. С другой стороны, если вы занимаетесь только краткосрочным планированием, и у вас внезапно заканчивается дисковое пространство, вы теряете время и вынуждены заниматься перепланированием и реорганизацией.
Ведь, как мы уже сказали во введении, «единственный возможный прогноз относительно требований к будущим хранилищам данных — их полная непрогнозируемость».
Традиционный подход, впервые испытанный компанией HP с их 3PAR, подразумевает «Тонкое выделение ресурсов», снимающее необходимость в авансовом выделении мощностей. Гибридное облако выводит этот принцип на новый уровень, позволяя компаниям мгновенно обеспечивать себя необходимыми объемами для хранения, оплачивая только использованные.
Дедупликация, ранжирование данных и автоматическое распределение по уровням
Самый простой пример, позволяющий проиллюстрировать все это — SharePoint. Как мы уже говорили, для пользователя свойственно менять, например, в презентации размером в 5 Мб только имя автора и титульный лист, сохраняя обе версии. Традиционно обе версии весят 5 Мб; дедупликация меняет этот подход, представляя весь информационный мир как набор информационных блоков. Один и тот же блок никогда не сохраняется дважды; в нашем примере будут сохранены только измененные блоки, позволяя второй версии презентации занимать десятки килобайт вместо 5 Мб.
Взгляд на информационный мир как на набор блоков имеет и другие преимущества. Например, контент, который необходим постоянно, выводится на передний уровень, а тот, который не используется годами, просто хранится
Безопасность в Cloud-as-a-Tier
Нарушения безопасности обычно подразумевают доступ человека к незашифрованным данным. Последние примеры таков: правительство Великобритании сохранило данные о страховании каждого гражданина вместе с его банковскими реквизитами и отправило их в Лондон. Впоследствии все эти данные были проданы в Интернете. Сегодня сложное шифрование данных сделало бы эти нарушения безопасности невозможными. Безопасности в облаке — это просто вопрос воспитания.
Есть несколько ключевых архитектурных вопросов, которые важны для реализации защищенного облака. Все блоки, которые перемещаются от локального хранилища к облаку хранения должны быть зашифрованы как в состоянии покоя, так и в движении. Второй важный компонент — это управление ключами: они должны храниться у заказчика, а не в облаке. Иначе мы снова полагаемся на человека, позволяя ему осуществлять доступ к незашифрованному контенту.
Существует дополнительный способ: агрегированный доступ к хранилищу, когда каждый клиент имеет свой собственный ключ. Однако продавец — агрегатор, также имеет доступ к этим ключам — и снова это угроза безопасности.
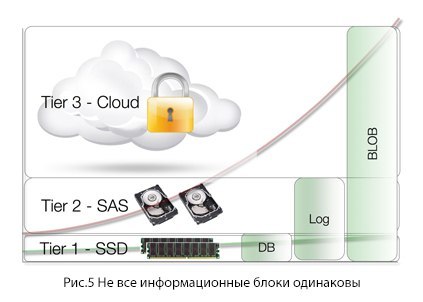
Не все информационные блоки одинаковы
Как мы уже говорили, «Коммунизм Контента» неприменим к облаку: вы же не хотели бы, что весь ваш контент перенесся в облако — вам нужно чтобы исчезла из зоны видимости неиспользуемая его часть. Все, что нужно для архитектуры «Сloud-
«Живое» архивирование, или «No more Tears with Tiers»
С ростом объемов сохраняемой информации у администраторов возникает потребность архивировать ее часть и изымать из живого доступа. Обычно это делается из соображений экономии. При этом возможны проблемы по мере необходимости в данных: что, например, если данные, заархивированные после шестимесячного простоя, срочно необходимы к ежегодному отчету?
В системах типа Content Management Systems или SharePoint архивирование происходит еще более сложно, ведь необходимо архивировать не только контент, но также связанные с ним политики безопасности и многое другое. Многочисленные блоки, связанные между собой, должны быть заархивированы таким образом, чтобы при необходимости доступ осуществлялся ко всей информации в комплексе.
Облако с его эластичностью предлагает огромные объемы, свободные для размещения данных, и имеет потенциал для того, чтобы стать решением вопроса. Экономика хранения становится оптимальной, когда объединяются возможности дедупликации, сжатия и шифрования и облако используется для основного и резервного хранения.
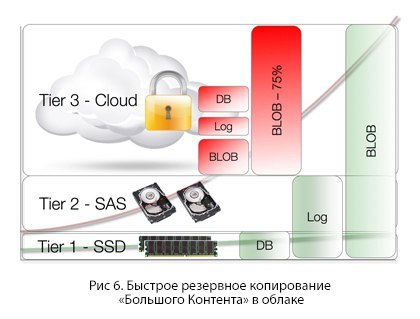
Быстрое резервное копирование «Большого Контента» в облаке
Облако не стоит рассматривать как просто диск в глобальной сети; поступая так, вы можете получить печальный опыт, особенно, если вы не знаете о резервном копировании.
Люди в шутку говорят: «Какой самый быстрый способ резервного копирования в облако? Ответ — просто ничего не делать». Если вы храните данные в облаке, то это и есть резервное копирование. Копироваться для создания резервной версии должен только тот контент, который хранится в данный момент на устройстве — естественно, после дедупликации, сжатия и шифрования. Точнее, только уникальные блоки информации такого контента — достаточно скромный объем.
Быстрое восстановление «Большого Контента» из облака
Известно, что люди не
Облачная архитектура имеет большое влияние на возможности восстановления данных в первичном или вторичном ЦОД. Если ваша резервная версия — это одна большая информационная «глыба» весом в несколько терабайт, то восстановление может быть медленным и болезненным процессом. Для быстрого восстановления необходимо использовать возможности «cloud-
Такой подход позволяет складировать информацию в многоуровневые структуры для хранения рабочего набора на быстрых SSD и локальных дисках. Архитектура позволяет рационально восстанавливать мультитерабайтные объемы — без вытягивания всего информационного объема. Извлекается только небольшое количество данных — «рабочий набор», а остальные блоки остаются в облаке и выдаются по мере необходимости. «Рабочий набор» создается заново буквально на лету, а в это время полный объем данных уже снова на своем месте.
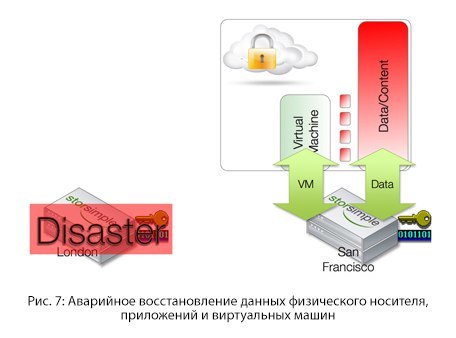
Аварийное восстановление в Cloud-as-a-Tier
Если спросить пользователей, как часто они проверяют свои процедуры аварийного восстановления, они начинают говорить очень тихо или краснеть. Аварии по своей натуре непредсказуемы. До 11 сентября процедура переноса записанных сохраненных данных происходила с помощью самолетов, а когда случился ураган Катрина, все данные остались в затопленных шахтах.
С появлением облака возникла возможность регулярно проверять политики аварийного восстановления, ведь облако доступно отовсюду и в любой момент.
Все, что необходимо — это иметь под рукой доступный девайс, на который можно установить всю конфигурацию. Затем облачные объемы могут снова перенестись для хранения в удаленное место, а контент снова становится доступен.
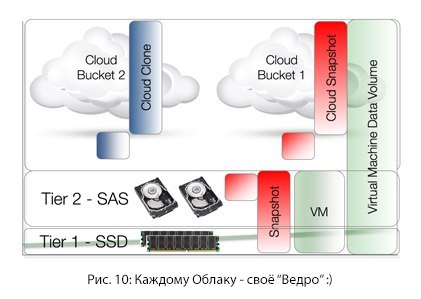
«Большой Контент» и виртуальная машина имеют одно общее свойство — они достаточно объемные. Обширные библиотеки виртуальных машин также могут храниться с использованием архитектуры «cloud-
Вместо заключения
Традиционный подход к корпоративному хранению достаточно сложен
Гибридное облако с архитектурой «cloud-
- Устройство для передачи информации в облако
- Облачный провайдер
Проще говоря, облако позволяет ранжировать информацию и хранить в локальном доступе только то, что необходимо на ежедневной основе. Ваши локальные приложения остаются на месте — облако просто интегрируется в существующую сеть. Ничто не гарантирует такой простоты хранения «Большого Контента», как виртуальная машина. Как небольшие планеты вращаются вокруг огромных, так и «Большой Контент» привлечет шустрые виртуальные машины, а потом заставит их двигаться в сторону контента и облачного провайдера, который управляет контентом.
«Большой Контент» станет новым центром притяжения, и приложения последуют за ним в облако.