
Продолжаю рассказывать об интересных докладах на MBC Symposium (MBC, кстати, расшифровывается как Mind Brain Computation).

Surya Ganguli — человек из теоретического neuroscience, то есть, занимается тем, чтобы понять, как работает мозг, на основе измерений импульсов нейронов на различных уровнях.
И вот тут независимо от neuroscience в мире случается deep learning, и у нас получается некую искусственную систему чему-то научить.
В отличие от мозга, в котором у нас ограниченное разрешение, сложность с повторяемостью, итд итп, про deep network-то мы знаем абсолютно все, про все веса, про все состояния. Возникает вопрос — если мы собираемся разобраться, как работает мозг, может попробуем для начала понять как и почему работает вот такая маленькая система?
Без надежд, что мозг работает также, скорее с прицелом разработать какие-то методы, которые могут быть применимы потом.
Disclaimer: пост написан на основе отредактированных логов чата closedcircles.com, отсюда и стиль изложения, и уточняющие вопросы.
Вот ссылка на сам доклад и на собственно опубликованную работу, о которой пойдет речь, но, cерьезно, лучше прочитать пост.
Один из очень старых результатов из нейросетей до того, как они стали называться deep learning — что похоже сеть учится иерархично, сначала более высокоуровневые разделения, потом более детальные.
Что конкретно имеется ввиду
Вот было исследование из старых времен такого рода.

Дадим на вход сети какой-то объект и отношение, а на выходе попросим выучить фичу, типа "canary can move".
Замечу, что в отличие от текущих задач классификации это задача тупо на запоминание информации сетью, нет тестового датасета, есть только тренировочный.
На вход — one-hot encoding объекта и отношения, на выход надо получить вероятность набора фич, у сети всего один hidden layer.
Изучается только как сеть "учит" тренировочный датасет.
И вот оказывается, что сеть сначала учит "высокоуровневые" разделения на животные-растения, а только потом детали про каждый из видов.

Причем собственно классов "животное" и "растение" нигде нет. Есть только конкретные виды животных и растений, про которые изначально сеть ничего не знает.
а как они определили что так получается?
Посмотри на вторую картинку, три графика кластеризации на ней — это на разных стадиях тренировки.
Сначала все случайно и все низенькое. В середине появляется "высокая" главная категория, отделяющая животных от растений, а только потом под ней "вырастают" вторичные.
ок как я понимаю активации в hidden layer — соответствуют каким то свойствам. поэтому объекты с близкими свойствами оказываются ближе друг к другу.
Да. Причем выкоуровневое разделение "животное/растение" учится первым, хотя оно напрямую нигде прописано не было, учится только из данных.
интересно! и это все повторимо естественно, с любыми начальными данными/весами.
Да.
Они пытаются понять, почему так происходит
Для этого они рассматривают еще более простую систему — сеть с одним hidden layer без нелинейности вообще.

Вот такая система — на вход дается one-hot id объекта, на выходе нужно выдать его свойства.
Опять же, проверяем только как оно учится, нет никакого тестового датасета.
Хотя такая сеть без нелинейности не имеет никакой representational power по сравнению с тупо линейной матрицей, наличие двух уровней делают обучение нелинейным, потому что оптимизируется уже квадратичное отклонение.
Оказывается, уравнения динамики обучения такой системы уже можно решить аналитически.
В целом, то что такая система "выучивает" в итоге, было известно давно — она стремится к singular value decomposition матрицы фичи-объекты.
(мне сложно описать, что такое SVD в двух словах, но можно себе представлять, что это некое линейное разложение, где для каждого объекта вводится вектор "внутреннего представления", из которого линейным преобразованием получаются итоговые фичи. Хороший туториал, например, здесь)
матрица N-мерная по количеству фич?.
NxM, где N — количество фич, а M — объектов.
То есть, получающийся embedding — это как раз внутренний вектор SVD.
Более интересно то, каким образом система "стремится" к этому разложению.
Оказывается, что сначала система "выучивает" разделение, соотвествующее самому большому singular value, потом учит следующее, и потом более маленькое.
Объясняется такое поведение наличием седловых точек.
Седловые точки — это точки, где градиент 0, но они не являются ни локальными минимумами, ни локальными максимумами, и градиентный спуск любит в них скатываться и из них сложно выбраться:
Вот на картинке ниже красная точка — это та самая седловая точка:
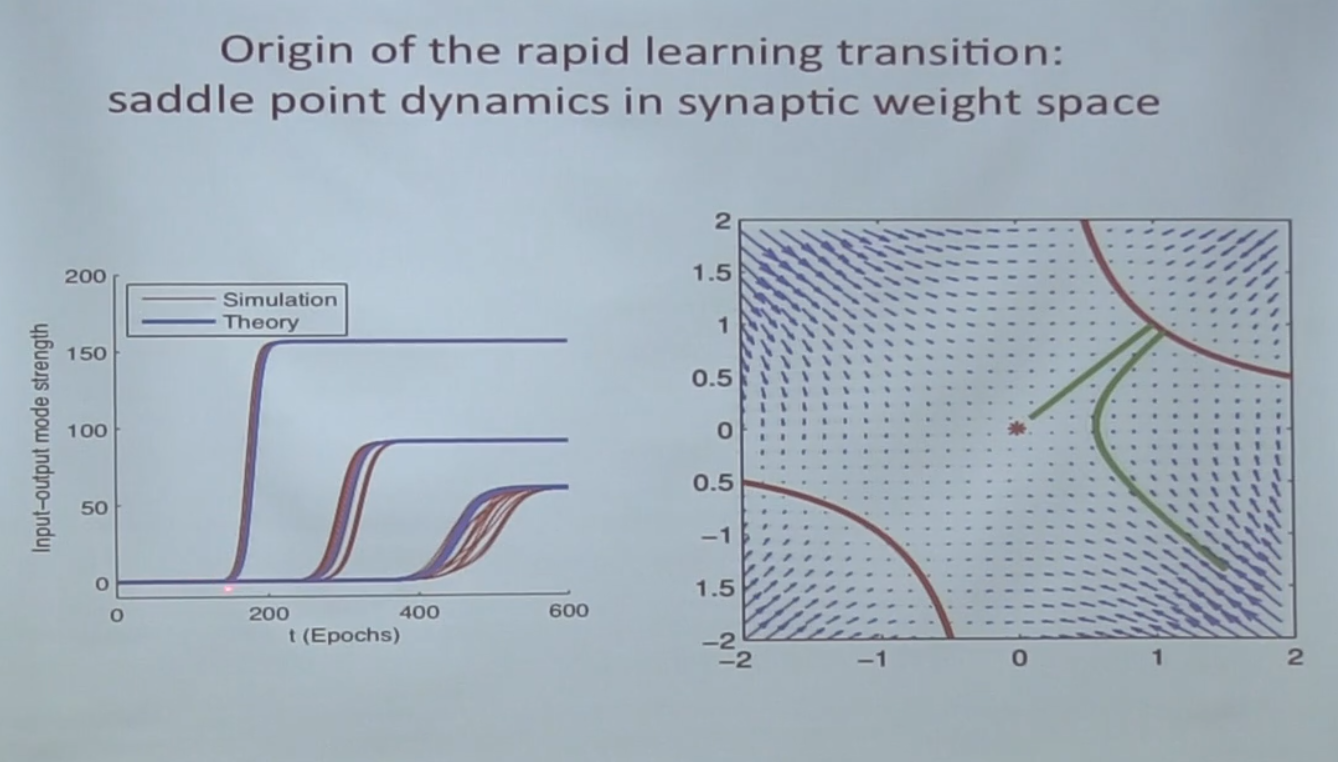
Сначала система в нее скатывается и долго там плутает, и в конце концов выходит из нее по зеленой линии.
что это на графике слева — input/output mode strength?
Это собственно значение singular value для каждой моды.
И про SVD мы хорошо знаем, что определяет параметры системы — их определяет матрица корреляций между объектами, то есть, SVD находит наиболее скореллированное направление среди данных объектов.
И чем больше "выровнены" объекты по некому направлению, тем singular value этого направления больше.
а объясни еще раз про седловые точки и градиентный спуск — и связь с singular value.
Оказывается, что в пространстве оптимизации линейной сети каждой singular value соответствует седловая точка, и "обучению" соотвествующей singular value соотвествует "выход" из этой седловой точки.
чтоб выучить все фичи нужно попасть во все седловые точки?
Да. Понятно, здесь имеются ввиду фичи "эмбеддинга", а не финальные.
Причем не только попасть, а выйти из них, т.е. например растения и животные разделяет седловая точка.
фичи эмбеддинга — это активации нейронов скрытого слоя?
Да. Пока ты в ней копошишься — ты не можешь понять, что есть что, а вот если свалился в одну сторону — опа, там все деревья!
ага понятно, а как получается что сначала сваливается в точку самого большого сингулярного числа?
Потому что у нее самая большая яма и скатываешься прежде всего в нее.
и случайно забрести куда то не туда не получится? в какой то другой локальный минимум
В линейной системе нет локальных минимумов.
В общем, нет, не получится статистически, потому что основное направление из датасета перевешивает.
и тут глупый вопрос — у gradient descent разве не цель свалиться в яму?
Ну да. Но седловые точки его притягивают, хотя минимумом не являются. Из них сложно вылезти, но когда вылез — градиентный спуск вывезет дальше вниз, вдаль от седловой точки.
а от датасета это зависит? если например больше данных для рыба/птица скажем, чем между животное/растение
Да, зависит. Singular values — это свойство всего датасета, глобальное, не локальное.
А что все это говорит нам применительно к изначальной задаче?.
Мы разобрались, что в её несколько упрощённой формулировке (но которая сохраняет описанное свойство), обучение происходит согласно SVD разложению начиная с самого большого singular value.
Главная движущая сила — это наиболее сильные корреляции между объектами.
Это пока не полностью объясняет ситуацию, но важный промежуточный результат.
А теперь следующий момент, как выйти на иерархическое представление.
Мысль такая: если картина мира иерархична (т.е. сначала определяется некая высокоуровневая фича, а потом уже в зависимости от нее детали), то чем фича выше по иерархии, тем на большее количество объектов она влияет и тем больше корреляций объясняет.
Они демонстируют это вот такой простой моделью.
Сгененируем объекты следующим простым образом — сначала сгенерируем одну фичу случайно, потом для объектов где получился 0 сгенерируем случайно другую фичу, а у тех что 1 — третью, и так по иерархии.
На следующей картинке это показано деревом сверху справа:

Оказывается, что если так нагенерить объектов, самое сильное singular value соотвествует как раз первой ноде (что в целом достаточно очевидно, это как раз направление, по которому можно разделить большинство объектов)
И это наконец дает нам объяснение изначального феномена.
Упрощенная сеть естественным образом последовательно выучивает направления самых сильных корреляций объектов, а так как объекты в реальных данных обладают иерархическими свойствами, свойства выше в иерархии генерируют наиболее сильные корреляции.
Посему сеть учит их первыми, а более детальные (влияющиее на меньшее количество объектов) — вторыми.
Эту идею можно развивать в разные стороны
Например, в психологии есть такой мистический момент — формирование категорий.
Вот есть в мире объекты, у них есть фичи. Каким образом мозг выделяет категорию, например "животные"?

Если об этом думать последовательно, возникает chicken and egg problem:
- Мы могли бы сгруппировать объекты в категорию, но надо понять на основе каких фич.
- Мы могли бы придумать категорию на основе набора фич, но тогда нужно понять, какие объекты туда включить, чтобы взять фичи!
И вот известно, что то, насколько категория "coherent" — важно.
Классический пример, что для категории "собаки" у нас есть слово "собака", а для категории "вещи синего цвета" — нет. Именно потому что вещи синего цвета друг на друга не похожи.
Чтобы попробовать продемонстрировать этот эффект в обучении, давайте сгенерируем случайных данных:

Вот мы сгенерировали случайные объекты со случайными фичами, справа — визуализация матрицы. Кормим эти объекты на вход уже полюбившейся нам линейной сети, чтобы она выучила соотвествие фич объектам.
Это считай такая же ситуация, что и обсуждалась раньше — вот суп объектов и фичей, есть ли тут категории?
Категории на самом деле в данных есть — мы генерировали данные не случайно, а кидая монетку приналдлежит ли объект некой категории. Если столбцы-строки переставить, то выглядит это так:
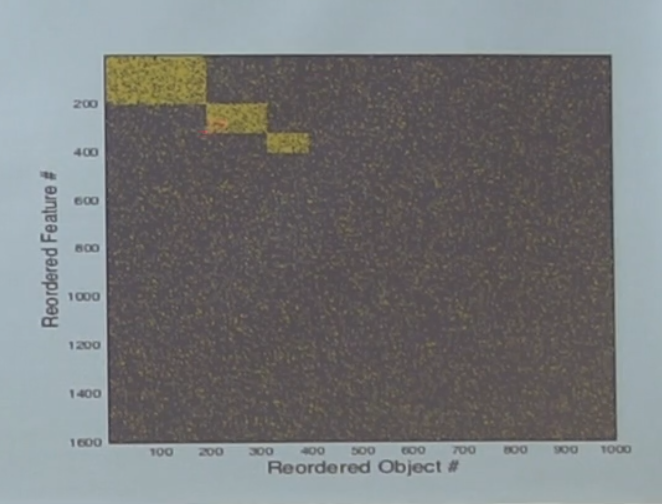
То есть, в этом шуме есть на самом деле три категории. Спрашивается, выучит ли их наша сеть?
Оказывается, можно аналитически показать, что это зависит от размера вот этого прямоугольника по отношению ко всему датасету. Eсли категория достаточно большая — выучится, а если нет — потонет в шуме. Кроме того, факт возможности идентификации категории зависит не только от количества объектов в ней, а именно от соотношения размера ко всему датасету.
Критическое значение размера категории — пропорционально sqrt(N*M).
Кстати, а мне пока не очень понятно, почему мы тогда не имеем слова для "Все синие вещи". Как раз соотношение ко всем данных весьма приличное.
Нет! У синих объектов слишком мало совпадающих фич.
Квадрат большой, но очень разреженный. Для появления категории есть ограничения и по размеру области, и по ее "плотности".
Ну так вот, последний пойнт.
То, что понятие "категории" зависит от всего датасета поясняет, почему так сложно об этом говорить в традиционной психологии.
Выделение объектов в категорию зависит от всего опыта человечества, и подступиться к нему "локально" очень сложно.
Но даже такая простая модель демонстрирует, как обучение решает эту chicken and egg problem, находя в шуме структуру.
Подытожу
С одной стороны, эта работа намекает, за счет чего так эффективно обучаются сети — потому что данные в реальном мире имеют определенную структуру, и это выражается в ландшафте оптимизации, по которому "скатывается" обучение градиентным спуском.
С другой, она опять же хорошо показывает, насколько теория пока далека от практики — обсуждаемая модель крайне примитивна даже по меркам нейросетей прошлого, не говоря уж о современных очень глубоких архитектурах.
Выводы, впрочем, можно экстраполировать.
Комментарии (6)

las68
02.05.2016 12:00Интересно, а этот алгоритм сумеет понять, есть ли у нас множественные локальные плато, т.е. на самом деле внутри групп есть подгруппы?

realbtr
02.05.2016 18:26Понять — это про человека :)
Архитектура сети, распознающей группы для подрупп будет более-менее унифицированной в случае deep learning.
Алгоритм мог бы понять, если бы на вход одной сети подавать архитектуры других сетей и результаты обучения, и тогда он бы классифицировал (т.е. понимал), какие архитектуры обеспечивают классификацию на группы и подгруппы, а какие нет.
Но вот множественные плато — это действительно «т.е. на самом деле внутри групп есть подруппы»?

sim0nsays
02.05.2016 19:52+1Это и есть иерархическое обучение разделениям фич. Они пробовали выделять и иерархические категории тоже, со сходным результатом
realbtr
Вообще, процесс можно представить как выращивание гетерархии. Вниз растут корни фич с высоким разрешением, вверх растут ветви обобщений, и каждая новая точка становится седловой. Рост фич и обобщений происходит связно — чем больше фич активировано по уже известным деталям, тем выше ветви и глубже корни. Сеть это техническое решение, семантика же имеет вид постоянно растущей гетерархии. Чтобы появился новый шаг в глубину, необходимо, чтобы образовался новый шаг в высоту. Глубина — повышает разрешение восприятия. Высота связана с этим разрешением. Каждый новый бит различает какие-либо категории, а не является сам-по-себе. Если принять, что глубина разрешения растет точно в соответствии с числом различаемых категорий и их ветвистостью, то структура семантической сети становится понятна в развитии, от шага к шагу.
sim0nsays
Я прочитал определение гетерархии в википедии и оно ничем мне не помогло понять ваш комментарий :)
realbtr
Да уж, рисовать надо. Не доходят руки статью закончить, но — обязательно.
Если грубо — из каждой точки растут два дерева. Вверх — ветви обобщений, вниз — корни фич. Вниз — увеличивается разрешение, вверх — увеличивается абстракция. И точное соответствие — каждый новый бит различает новый путь в группах абстракций.
В результате каждый узел объединяет некоторые фичи в некоторое совместное обобщение. Получается семантическая сеть. Любые несколько точек семантической сети если распознаются совместно, в рамках одного контекста — соединяются в обобщение. А если уже соединены — увеличивается разрешающая способность в глубину на 1 бит (т.е. возникает новая фича или увеличивается разрешение уже имеющейся фичи) и получается одновременная операция «обобщение+различение».
Но мой метод не связан с нейронными сетями, алгоритм работы с семантической сетью последовательный (идея управления движением точки фокуса внимания).
Поэтому может быть не очень понятно в таком сжатом виде.