
У меня тут синхронизируется VM надолго, поэтому есть время рассказать про то, что я недавно читал.
Например, про GoogLeNet.
GoogLeNet — это первая инкарнация так называемой Inception architecture, которая референс всем понятно на что:

(кстати, ссылка на него идет первой в списке референсов статьи, чуваки жгут)
Она выиграла ImageNet recognition challenge в 2014-м году с результатом 6.67% top 5 error. Напомню, top 5 error — метрика, в которой алгоритм может выдать 5 вариантов класса картинки и ошибка засчитывается, если среди всех этих вариантов нет правильного. Всего в тестовом датасете 150K картинок и 1000 категорий, то есть задача крайне нетривиальна.
Чтобы понять зачем, как и почему устроен GoogLeNet, как обычно, немного контекста.
Disclaimer: пост написан на основе отредактированных логов чата closedcircles.com, отсюда и стиль изложения, и уточняющие вопросы.
В 2012 году происходит эпохальное событие — ImageNet challenge выигрывает deep convolutional network
Причем не просто выигрывает, а показывает ошибку почти в два раза меньше второго места (15% vs 26% top5 error)
(чтобы показать развитие области, текущий топовый результат — 3%)
Сетка называется AlexNet по имени Alex Krizhevsky, студента Хинтона. В ней всего 8 уровней (5 convolutional и 3 fully-connected), но в целом она толстая и жырная — аж 60M параметров. Eе тренировка не влезает в один GPU с 3GB памяти и Алексу аж приходится придумать трюк как тренировать такое на двух GPU.
И вот люди в Гугле работают над тем, чтобы сделать ее практичнее
Например, чтобы можно было ее использовать на девайсах поменьше и вообще.
GoogLeNet мы любим не столько даже за точность, сколько именно за эффективность в размере модели и необходимом количестве вычислений.
Cобственно пейпер — http://arxiv.org/abs/1409.4842.
Основные идеи у них такие:
- Изначальный AlexNet делал большие свертки, которые требуют много параметров, попробуем делать свертки поменьше с большим количеством лееров.
- А потом будем агрессивно уменьшать количество измерений, чтобы компенсировать более толстые слои. Умно это делать можно с помощью 1x1 convolutions — по сути, линейного фильтра применяющегося по всей картинке, чтобы взять текущее количество измерений, и линейно их смешать в меньшее. Так как он тоже обучается, получается очень эффективно.
- На каждом уровне будем прогонять несколько convolution kernels разного размера, чтобы вытаскивать фичи разного масштаба. Если масштаб слишком большой для текущего уровня, он распознается на следующем.
- Не делаем hidden FC layers вообще, потому что в них очень много параметров. Вместо этого на последнем уровне делаем global average pool и подцепляем его к output layer напрямую.
Вот так выглядит один "inception" module:
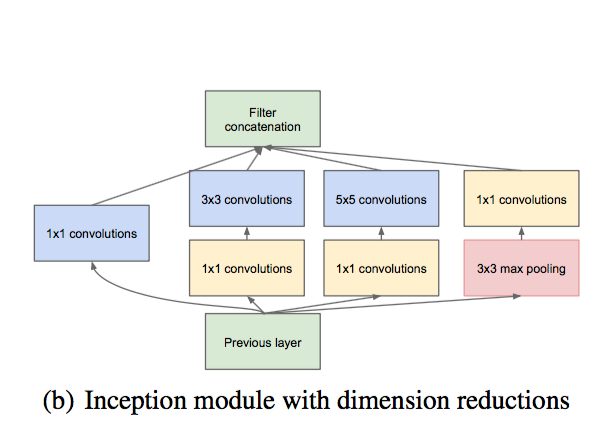
Видны те самые кернелы разного размера, видны 1x1 convolutions для уменьшения размерности.
И вот сеть состоит из 9 таких блоков. В такой конструкции примерно в 10 раз меньше параметров, чем в AlexNet, и вычисляется она тоже быстрее, потому что dimensionality reduction работает хорошо.
А потом оказалось, что она еще и собственно классифицирует картинки лучше — как было написано выше, 6.67% top5 error.
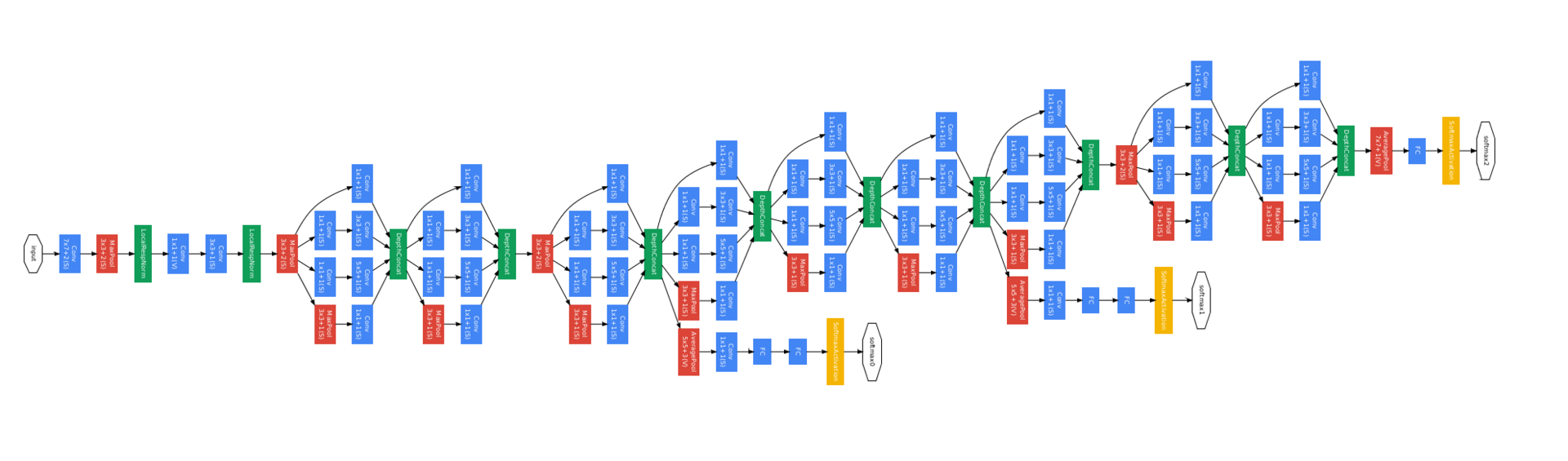
Вот картинка полной сети. Она выглядит страшно, но когда понимаешь, что это повторяющиеся блоки, попроще.
Какие еще подробности рассказать...
У нее три training head (желтые квардратики) — это было сделано для того, чтобы проще было тренировать такую глубокую сеть. В каждом дополнительном training head есть немного FC layers, которые предсказывают тот же класс на основе низких уровней, чтобы до нижних уровней сигнал доходил побыстрее (правда, в следующих работах оказалось, что они помогают скорее потому что являются дополнительной регуляризацией).
В релизе все ведущее ко вспомогательным training heads выкидывается. Такая техника используется в других местах в литературе, но с тех пор мы научились лучше deepnets тренировать, поэтому часто уже нужно.
Такая архитектура, кроме собственно GoogLeNet, называется Inception-v1.
Inception-BN — это та же сетка, только натренированная с использованием Batch Normalization (вот здесь хорошее объяснение на пальцах).
А Inception-v2 и далее — уже более сложные архитектуры, про которые я расскажу в следующий раз, а то тут могут начать кормить скоро.
"Le" в GoogLeNet — референс на LeNet 5, первую сетку, опубликованную ЛеКуном before deep learning was a thing.
Про сжатие сетей я тоже недавно кое-что читал. Там берут сеть, обрезают из нее лишние веса, сеть уменьшается раз в сто, точность почти не страдает. То есть, вроде как, прямо с гигабайт до мегабайт, можно пихать в память мобильника. Чувствую, еще лет десять и каждая камера начнет видеть по-настоящему.
Про сжатие пейпер, кстати, если интересно — http://arxiv.org/abs/1510.00149.
Ага. Это игры немного разного уровня.
Можно оптимизировать на уровне архитектуры и обучения, а можно на низком уровне — работая уже с выученными весами.
Скорее всего, на практике нужно и то, и другое.
Кстати, вопрос в космос.
А можно из этого всего сделать какой-то глобальный вывод?
Почему это все работает? Или хотя бы — как лучше дизайнить сети с учетом этого опыта?
Отличные вопросы, про это будет много мяса в следующей части рассказа. Stay tuned!
Комментарии (15)

BelBES
25.05.2016 10:23А можно пару вопросов?
- Откуда вообще была придумана архитектура ineption'а? Из статей о GoogLeNet этот момент не совсем понятен… есть какое-то обоснование того, что вот таки блоки работают лучше, чем сети с последовательными слоями? Или там просто брутфорсом получили такой блок и дальше использовали как есть?
- Почему замена MLP на GAP на выходе сетки считается практически равнозначной, параметров у модели ведь значительно меньше становится?

supersonic_snail
25.05.2016 11:101 — Мотивация и правда на особо описана. Как мне кажется, Inception блок извлекает features на разных масштабах — там параллельно 1х1, 3х3, 5х5 convolutions + max pooling. Возможно в этом и была идея. К слову, мотивацию в статьях вообще крайне редко пишут — она скорее мешает пройти ревью на конференцию.
2 — Сеть с много параметров не обязательно будет иметь хорошие результаты. Если взять обычную fc-сеть с 1 скрытым слоем на 1кк нейронов, то будет куча параметров, но работать она будет так себе, если вообще будет. Как вариант объяснения — receptive field каждого пиксела в самом последнем слое уже почти занимает всю картинку. Точного размера не скажу, надо считать. Особой необходимости пропускать это через fc слои нет. Как бонус — значительное уменьшение модели, чего они и добивались.

sim0nsays
25.05.2016 19:24Я вроде описываю мотивацию — хотелось архитектуру компактнее, мужики исследовали разные идеи как это сделать — делать convolutions меньше, уменьшать размерность, придумать что-то вместо FC layers. А оказалось, оно очень неплохо работает! Я думаю, такой блок получили большим количеством последовательных экспериментов.
Про второе — видимо, потому что большое количество параметров в FC layers избыточны (как показывает работа по Deep Compression, например). Последние inception blocks уже очень толстые и про свертки в них можно думать как применяющиеся ко всей картинке FC layers, только в окрестности каждого пикселя. И вот идея в том, чтобы усреднить такой вход в гриде 7x7 и сказать, что это финальные фичи. Опять же, почему конкретно это работает это нынче сложный в deep learning вопрос. Пока получается только эмпирически
grossws
Не очень понятно как convolution 1x1 уменьшает размерность. Можете пояснить, что понимается по conv 1x1 в этом случае?
sim0nsays
Например, некий layer выдает матрицу активаций 14x14x152 и она дается на вход 1x1 convolution. На выходе может быть, например, 14x14x64 — то есть, те же размеры по вертикали и горизонтали, но меньшая глубина. У такого 1x1 conv будем 152*64 параметра, и он просто сделает линейное преобразование для каждого многомерного "пикселя", коих 14x14.
grossws
Чем оно тогда отличается от FC слоя
14x14x152 -> 14x14x64? Функцией активации?supersonic_snail
FC слой будет не 14х14х152->14x14x64, а 14x14x152->512. 1х1 conv слой явно сохраняет x и y измерения, FC нет. Собственно в этом и принципиальное отличие.
grossws
Т. е. чисто терминологическое отличие, спасибо.
sim0nsays
Нет, не только. Количество параметров и то, как происходят вычисления, разные. Отличие то же, что и у convolutional vs fully connected layers в принципе
sim0nsays
Предыдущий комментарий по делу. Я дополню тем, каждый нейрон FC layer получает на вход все 14x14x152, а conv 1x1 — только 152, но прогоняется для каждого "пикселя" 14x14 независимо
grossws
Тоже верно, туплю.
mrgloom
Тут есть неплохое описание CONV слоя и 1X1 CONV слоя в частности.
http://cs231n.github.io/convolutional-networks/