
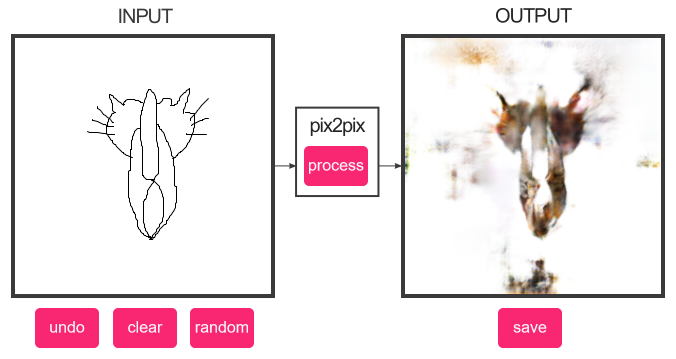
Вы все, наверное, уже видели сверх-реалистичных кошечек, которых можно рисовать вот тут.

Давайте разбираться, что же там внутре.
Disclaimer: пост написан на основе отредактированных логов чата closedcircles.com, отсюда и стиль изложения, и уточняющие вопросы
Все это — реализация пейпера Image-to-Image Translation with Conditional Adversarial Networks из Berkeley AI Research.
Так как это все работает-то?
В пейпере люди решают задачу трансформации картинки в другую так, чтобы человеку не нужно было придумывать loss function.
Одна из главных проблем с нейросетями в генерации картинок — в том, что если использовать как loss просто среднуюю разницу в пикселях, например, L1 или L2 (он же mean squared error), то сеть стремится усреднять все возможные варианты. Если в финальной картинке есть некая неопределенность — например, ребро может быть на разной позиции, или цвет может быть в неком диапазоне, то оптимальный результат с точки зрения L2 loss — что-то среднее между всеми возможными случаями, а не какой-то конкретный из них.
Посему картинки оказываются очень размытыми пятнами.
Для разных отдельных задач люди придумывали другие loss functions, чтобы выразить некую структуру, которая должна быть в результатирующей картинке (для сегментации например Conditional Random Fields пробовали добавлять итд итп), но это все помогает очень инкрементально и очень зависит от задачи.
Ну и вот, следуя новым веяниям, в пейпере в качестве такого дополнительного лосса к L1 втыкают GAN (Generative Adversarial Network). (почитать про GANs можно почитать на Хабре здесь и здесь)
Общая схема у них такая:
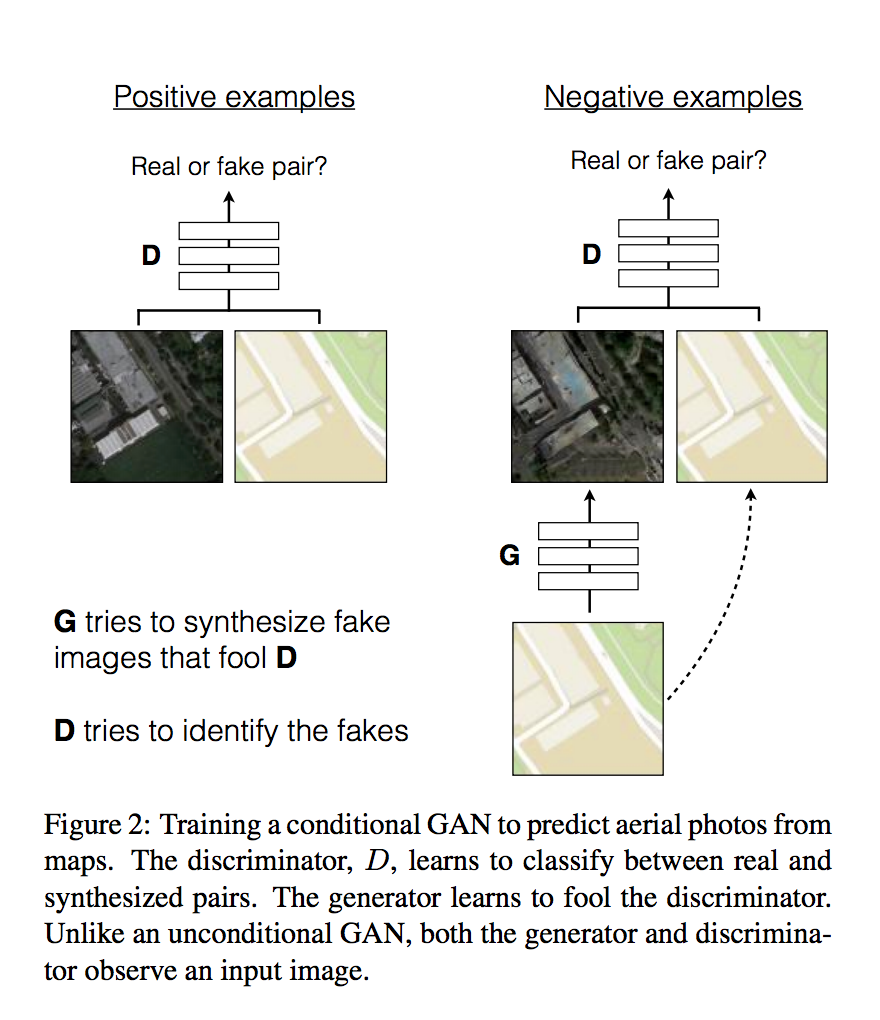
Генератору на вход дается input image — она является дополнительным условием на то, что нужно сгенерировать. На ее основе генератор должен сгенерировать картинку на выход.
Дискриминатору — дается и input image, и то, что сгенерировал генератор (или, для positive examples — настоящая пара из тренировочного датасета), и он должен выдать является ли сгенерированная картинка настоящей или сгенерированной. Таким образом, если генератор будет генерировать картинку, не относящуюся к входной — дискриминатор должен это определить и отбросить.
Генератор является результатом итеративной тренировки этой пары сетей.
В целом, это стандартный подход Сonditional GANs — варианта GAN, где модель должна генерировать картинки соответствующие дополнительному входному вектору класса.
Только здесь входной вектор класса — картинка, и общий loss — это GAN loss + L1.
В смысле "втыкают GAN" в контексте обсуждения loss'ов? Типа добавляют генератор и решают задачу на нахождение минимакса?
Ну да.
На высоком уровне все!
Какие у них интересные детали
В отличие от классического подхода к GANs, генератору вообще не передается никакого шумового вектора.
Все разнообразие только от того, что в сети есть dropout, и они его не выключают после тренировки.
- Архитектура сети — U-Net, достаточно новая архитектура для сегментации, у которой есть много skip connections от энкодера до декодера (вот короткое описание)
Вот картинка, которая показывает, что и GAN loss, и U-net помогают.

Здесь, кстати, хорошо видна изначальная проблема с использованием только L1 loss — даже мощная модель генерирует размытые пятна, чтобы минимизировать среднее отклонение.
- Они тренируют модель на патчах 70x70, а потом применяют на больших картинках через full convolution. Забавно, что 70x70 дает в среднем результаты лучше, чем делать сразу на всей картинке 256x256 целиком.
А где же кошечки!!!
После этого есть система, которую можно научить на произвольных входах и выходах, даже если они из совсем разных задач.
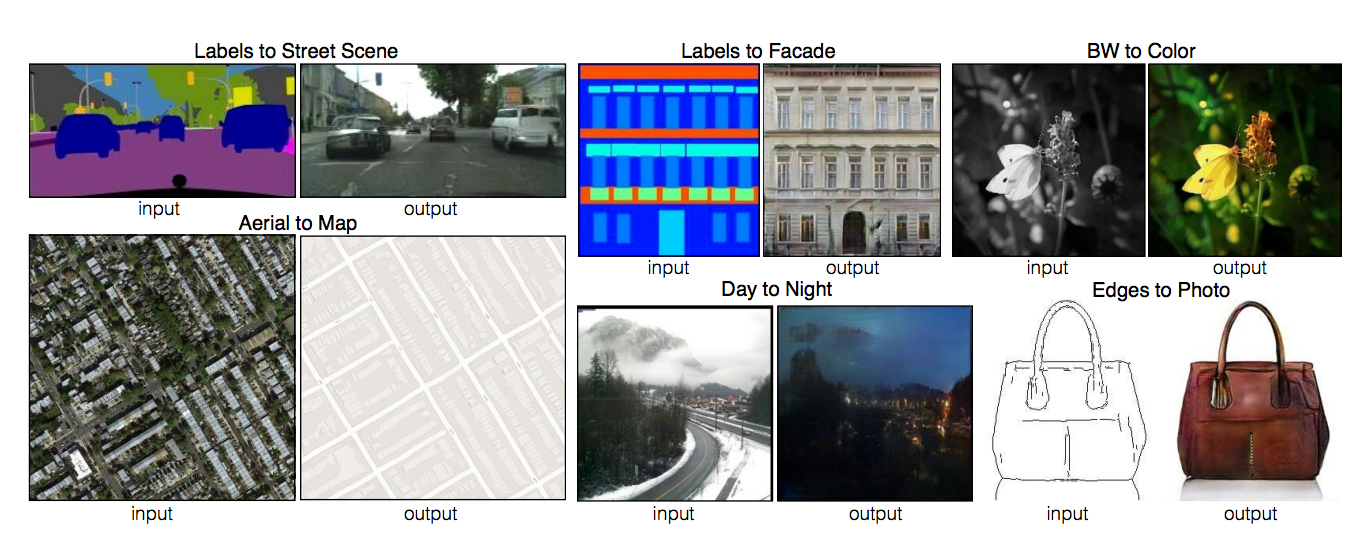
Из сегментации в фотографию, из дневной фотки в ночную, из черно-белой в цветную итд.
И вот последний пример — это из ребер в картинку. Ребра по картинке генерируются стандартным алгоритмом из computer vision.
Это означает, что можно просто взять набор картинок, прогнать edge detection, и вот на этих парах
натренировать. Можно и на кошечках:
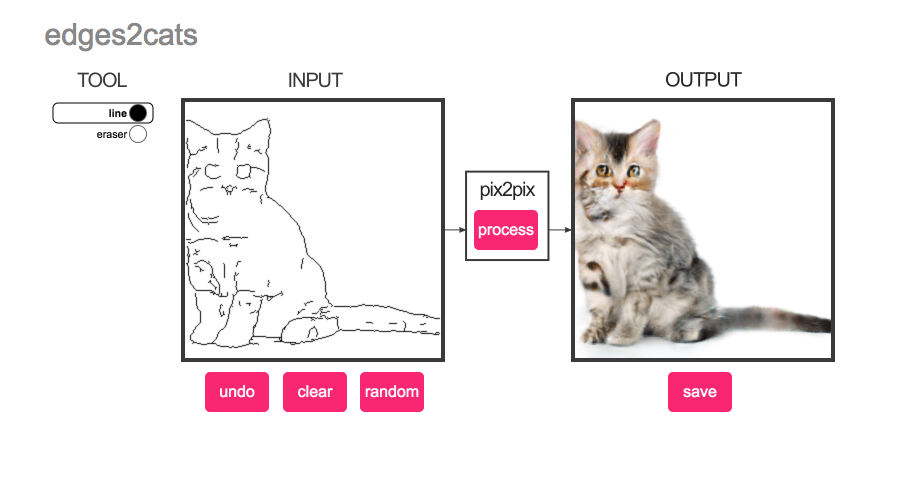
И после этого модель может что-то сгенерировать для любых скетчей, которые рисуют люди.
(присылайте, кстати, что вам запомнилось)
Так был ликвидирован недостаток хлебообразных кошек у человечества!
В целом, эта работа — еще один пример того, как взлетают GANs начиная с прошлого года. Оказывается, что это очень мощный и гибкий инструмент, который выражает "хочу чтобы было неотличимо от настоящего, хоть и не знаю, что это конкретно значит" как цель оптимизации.
Надеюсь, кто-то напишет полный обзор остального, происходящего в области! Там все очень круто.
Спасибо за внимание.
Комментарии (24)

mountain_mike
07.03.2017 11:17+7котодемон




Writerim
07.03.2017 11:52+1Качество картинок напрямую зависит от того какой по размеру объект. Чем меньше, тем больше алгоритм старается рисовать за его пределами.
Пример




sim0nsays
07.03.2017 12:07+1Ага, у модели мощный prior на то, какого размера могут быть объекты, потому что она поди видела только определенного размера объекты во время тренировки. Если такое очень важно — можно такие примеры специально в training set подмешивать.
Writerim
07.03.2017 13:05+1
sim0nsays
07.03.2017 13:08Надо ребра передавать, мне кажется. Прогони через какой-нибудь Canny edge detector?
RomanArzumanyan
07.03.2017 16:06+1Как вы вставили картинку в поле для рисования?
oPOCCOMAXAo
07.03.2017 17:43так это же не поле для рисования, а канвас. у него есть метод для вставки картинки









BasmanovDaniil
Что такое пейпер?
sim0nsays
Статья, от английского paper. Полураспад мозга :(
Dark_Daiver
Paper — статья, конкретно в этом случае — научная публикация
KotV4