
В школе Skyeng мы редко обучаем английскому с нуля. Обычно к нам приходят люди, уже обладающие каким-то набором знаний, причем этот набор бывает самым разным. Для того, чтобы обучение было полезным, нам нужно как-то определить границу этих знаний. Если в случае грамматики это относительно просто (выясняется на первых занятиях с методистом), то уточнение границ словарного запаса – задача не самая тривиальная. Для ее решения мы разработали и запустили инструмент WordMash.
Упорядочивание слов
Запоминание слов — одна из основных составляющих обучения иностранному языку, на которую тратится бoльшая часть времени и усилий студента. Однако слова любого языка, в том числе английского, не равнозначны: какие-то полезнее, т.к. чаще встречаются (walk vs perambulate); какие-то проще для запоминания (process vs outgrowth), с какими-то ученик постоянно имеет дело по работе или в силу интересов. Для построения максимально эффективной учебной программы (дающей ощутимый результат в кратчайшие сроки) необходимо учитывать эти факторы.
Для эффективного изучения новых слов и поддержания в памяти старых важно уметь определять словарный запас (лексикон) ученика. Традиционный подход заключается в интуитивном определении объема лексикона учителем на основе общения и тестов. Такой подход, однако, полностью опирается на опыт и квалификацию преподавателя и не может быть объективно проконтролирован.
Идеальным методом определения всех известных ученику слов был бы опросник по всему словарю языка с двумя вариантами ответа – «знаю» и «не знаю». Понятно, что реализовать подобный метод практически невозможно: мало кто из учеников готов потратить несколько недель, непрерывно отвечая на вопросы.
Поэтому хорошо зарекомендовал себя способ, основанный на предположении, что из всех слов языка можно составить упорядоченный по сложности список. В его начале идут «простые слова», например те, что выучивают дети в самом начале жизни: «мама», «папа», «хороший», «плохой» и т.д. В конце находятся «сложные» слова — профессиональная лексика, архаизмы, локальные наречия и т.д. В упрощенном случае предполагается, что если человек знает некоторое слово в этом упорядоченном списке, то он знает и все предыдущие слова в этом списке; если же человек не знает некоторое слово, то и последующие слова он тоже не знает. Таким образом, в идеальном случае для оценки словарного запаса человека требуется определить положение границы его знания: номер последнего слова, которое он знает.

Примерный график знания слов упорядоченного списка в идеальном случае. Граница «знания» точно определяет размер лексикона ученика.
Такое идеальное упорядочивание слов, к сожалению, невозможно, поскольку реальный лексикон разных людей отличается (если, конечно, он не нулевой). Изучение слов происходит не последовательно по утвержденному кем-то сверху списку, на него влияет выбранная программа, преподаватель, личные и профессиональные интересы студента. Так, математик и врач знают терминологию своих областей, но не в курсе терминов не из своей области; они по-разному будут воспринимать сложность слов «дифференциал» и «карцинома».
Поэтому имеет смысл говорить об усредненном упорядочивании слов. В этом случае отсутствует понятие четкой границы: ученик может знать слово №1000, не знать слово №1001 и снова знать слово №1002. Для описания реальных ситуаций имеет смысл рассмотреть следующий подход.
Разобьем слова в нашем ранжированном по сложности списке на интервалы (например, по 100 слов) и для каждого интервала определим процент слов из этого интервала, который ученик знает. В результате получится относительно гладкая кривая; если мы знаем номер слова, то с помощью графика мы можем увидеть, с какой вероятностью ученик его знает. Для этой функции можно определить медиану: такой номер слова, что количество неизвестных слов до него равно количеству известных после. Эта медиана и будет играть роль аналога границы и характеризовать численным образом словарный запас ученика.
Выглядит это здорово, если бы не одна проблема: а как, собственно, подготовить сам упорядоченный по сложности список слов?
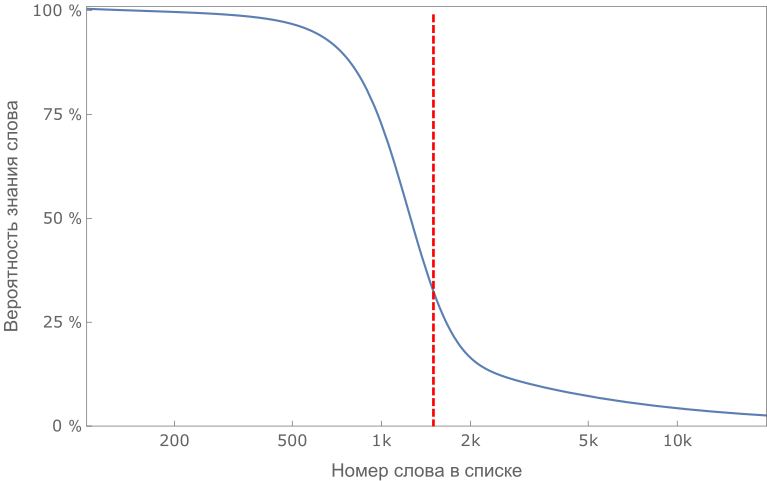
Характерная зависимость вероятности знания слова учеником от номера слова. Красной вертикальной линией показана медиана распределения.
Анализ частотности по Британскому корпусу
Существует теория, согласно которой среднестатистическая сложность слова напрямую зависит от его распространенности (частотности). Действительно, чем чаще нам в процессе обучения будет попадаться слово, тем быстрее мы его выучим. Таким образом, упорядоченный список слов можно построить, проанализировав частотность всех слов в корпусе текстов — специально подобранной и обработанной совокупности разнообразных текстов языка.
Поэтому начали мы с того, что провели частотный анализ Британского Национального Корпуса (British National Corpus). В корпусе представлены письменные тексты (книги, статьи, документы), разговорные (транскрипции бесед, записей, фильмов) и цитаты из докладов, обращений и выступлений. Эти три подкорпуса различаются объемами, однако обладают одинаковой важностью для анализа живого языка, поэтому при подсчете частотности их «вес» в общем результате был уравнен. Далее были рассчитаны частотности и проведена нормализация по подкорпусам (усреднены три результата). Вот выдержка из полученного списка и график зависимости частотности от номера слова:
| Номер слова | Слово | Частотность (на миллиард слов) |
|---|---|---|
| 1 | the | 61 674 367 |
| 2 | be | 35 206 532 |
| 470 | leader | 2 420 806 |
| 5175 | millennium | 11 433 |
| 49818 | negligibly | 67 |
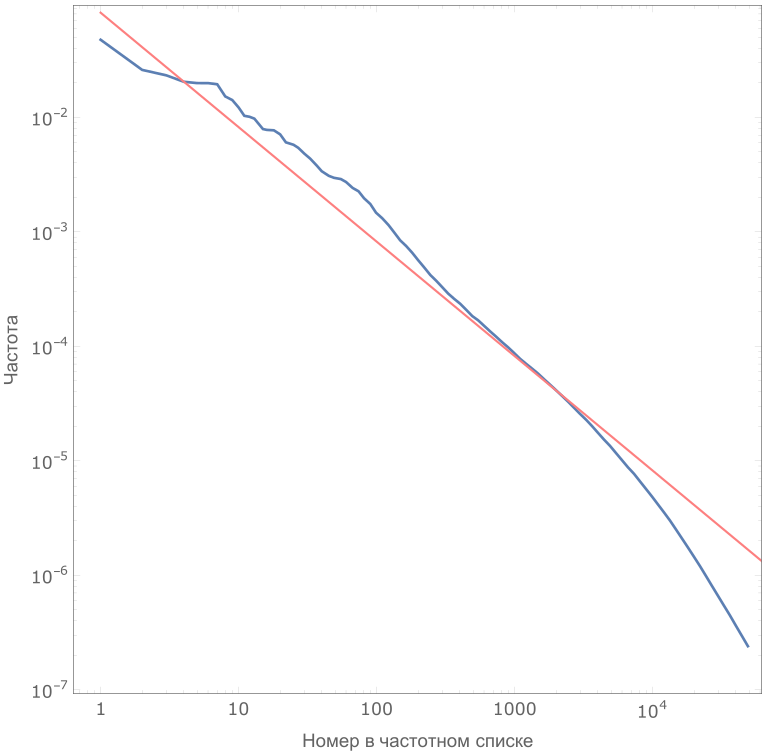
Зависимость частотности слова от его номера в списке. Видно, что начало списка хорошо описывается законом Ципфа (красная прямая).
Субъективность понятия сложности
Утверждение о хорошем соответствии частотности слов в корпусе текстов и относительной упорядоченностью лексикона группы людей справедливо лишь в том случае, если эта группа — активный читатель и производитель этих текстов. Другими словами, британский корпус отражает упорядоченность лексикона прежде всего именно британцев, в меньшей степени других англоговорящих социумов, и в последнюю очередь — русскоязычных учеников, изучающих английский язык.
В качестве важного примера такого несоответствия можно привести слова греческого, латинского или другого происхождения, которые обладают схожей формой в английском и русском языках. Например:
| Английское слово | Русское слово |
|---|---|
| analysis | анализ |
| moment | момент |
| information | информация |
| philosophy | философия |
| bronchitis | бронхит |
| doctor | доктор |
Всего нами были выделено более 5 тысяч подобных слов. Что дает такая схожесть форм в двух языках? Если ученик более-менее способен читать по-английски, ему будет несложно угадать значение слова, хотя он никогда его не учил (если, конечно, это не «ложный друг переводчика» типа magazine).
Следует отметить, что данный эффект положительно влияет на размер пассивного словаря, однако практически никак не связан с активным. С одной стороны, ученик заранее гарантированно не знает, обладает ли слово русского языка похожим переводом в английском, а с другой, зачастую фонетика и орфография существенно отличается. Тем не менее, изучение этих слов не может быть поставлено в один ряд с «родными» для английского языка леммами англосаксонского происхождения, для которых ученику приходится запоминать все лексические единицы (орфографию, фонетику, перевод) без каких-либо подсказок со стороны родного языка.
Даже анализ частотного списка слов носителей английского языка показывает его сильную зависимость от места и времени. Например, сравнение знаменитого Salisbury Word List, показывающего наиболее частотные слова австралийских школьников в 1978-79 годах, и Oxford Wordlist, исследования словарного запаса опять же австралийских школьников, но 30 лет спустя, показывает, что в лексиконе современных детей начали преобладать слова, связанные с консьюмеризмом: bought, new, shop, want и технологиями, тогда как до этого большинство частотных слов были посвящены теме семьи и досуга.
Все это убедило нас в том, что список, отсортированный лишь по частотности, недостаточно хорош для наших целей — обучения английскому языку русскоязычных учеников, — что привело к запуску проекта WordMash.

Пользовательская страница проекта Wordmash, в котором пользователь из двух слов выбирает более простое на его взгляд.
Умное ранжирование
WordMash — инструмент дополнительной сортировки словаря, основанный на субъективном восприятии сложности отдельных лексических единиц реальными людьми, нашими учениками. Из двух предложенных системой слов пользователь выбирает наиболее, на его взгляд, простое. При этом для упорядочивания списка применяется система рейтингов Эло. Эта система, изначально появившаяся в шахматах, ныне применяется во многих играх и видах спорта — от Го до Magic the Gathering.
Суть ее в том, что величина, на которую изменяются рейтинги игроков после каждой встречи (матча), непостоянна; она зависит от начального рейтинга каждого из соперников (вероятности победы). В случае, если заведомо более сильный игрок (гроссмейстер) обыгрывает заведомо более слабого (новичка), победитель получит, а проигравший потеряет минимальное число очков рейтинга, стремящееся в экстремальных случаях к нулю. Напротив, если в той же ситуации гроссмейстер проиграет, он потеряет заметную часть своего рейтинга. Таким образом, чем выше рейтинг – тем сложнее его поднимать и легче потерять, однако талантливый новичок может добиться адекватной оценки своего мастерства достаточно быстро.
В начале для всех слов был рассчитан начальный рейтинг, как логарифм частотности:
Затем, если было проведено сравнение i-го слова с j-ым, выписывалось количество очков, которое набрало i-ое слово , равное 1 в случае, если i-ое слово оказывалось проще j-го (победа), 0 – если i-ое слово оказывалось сложнее (проигрыш) и 0,5 — если пользователь затруднялся ответить (ничья). Сумма очков сохранялась:
. На основе текущих рейтингов вычислялось матожидание количества набранных очков i-ым словом:
Наконец, вычисляется новый рейтинг слова:
Таким образом, наиболее простые слова поднимаются в рейтинге, а сложные, напротив, опускаются.
Заметим, что подобная методика при некотором размере базы пользователей оказывается устойчива к шуму результатов. Другими словами, рейтинг слов, полученный на основе ответов одного пользователя не может считаться достоверным, однако по мере роста количества участников программы его достоверность постоянно повышается.
Для проверки достоверности метода мы провели эксперимент с шестнадцатью добровольцами с разным уровнем знания языка. Им был предоставлен список из первых 8 тысяч слов изначального частотного списка, в котором они отмечали известные им слова. Для каждого слова был вычислен процент людей, знакомых с ним, и при помощи описанного выше метода интервалов было построено кумулятивное распределение знания слов «усредненным человеком». Это распределение оказалось немонотонным: некоторые слова, находящиеся в списке ниже, оказывались более простыми, чем слова, расположенные в списке выше. После 85 тыс. сравнений эта кривая оказывается немного более гладкой.
Была построена метрика качества сортировки: количество перестановок, которое нужно совершить в списке слов, чтобы кривая стала монотонной (чем меньше перестановок, тем лучше). На графике ниже показано, как зависит эта метрика от количества проведенных сравнений.
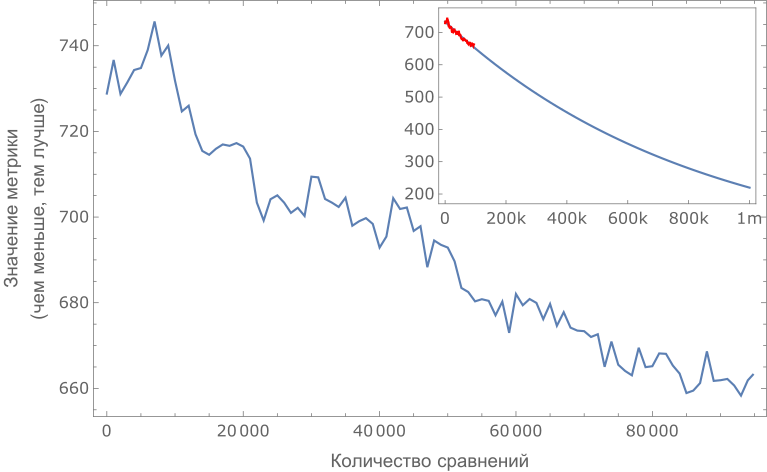
Улучшение сортировки слов (падение метрики) в процессе накопления данных о попарном сравнении слов пользователями. Улучшение сортировки говорит о том, что метод WordMash работает и приводит к желаемому результату.
К сожалению, как и многие другие методы, WordMash наиболее эффективен при начальной сортировке, но для достижения более точных результатов требуется все большее количество сравнений. Оценку требуемого количества сравнений (порядка миллиона) мы получили в результате экстраполяции.
Своими силами мы не сможем провести такое количество сравнений, поэтому мы открыли инструмент для добровольцев по адресу http://tools.skyeng.ru/wordmash. Для этого пришлось продумать дополнительные алгоритмы отсеивания случайных результатов, которые могут возникать как в результате баловства, так и «эффекта любимой кнопки» или просто утомленности пользователя. Какое-то количество таких случайных результатов все-таки просочится в базу, но при том масштабе исследования, который мы задумали, они будут находится в пределах статистической погрешности.
Определение словарного запаса ученика
Имея в руках результаты работы инструмента WordMash, мы сможем достаточно точно определять объем лексикона ученика, что позволит точнее подбирать для него учебные материалы. График роста этого объема, в свою очередь, служит хорошим мотивирующим фактором и показателем эффективности обучения. Для определения словарного запаса мы используем инструмент, аналогичный Test Your Vocabulary, но с модифицированной WordMash базой сложности слов.
На первой итерации, спрашивая несколько слов, логарифмически равномерно покрывающих весь диапазон ранжированного списка, мы находим приблизительную границу медианным методом. На второй итерации мы уточняем эту границу, спрашивая слова в окрестности приблизительной границы.
Следует отметить, что в случае логарифмически распределенных величин медианный метод определения границы следует слегка видоизменить (скорректировать на плотность слов). Если номера слов распределены логарифмически равномерно:
, где k = 1, 2, 3 и т.д. а
— константа, и мы получили ответы ученика
, которые равны 1, если он знает слово и 0, если не знает, то оценка границы составит:
Благодаря инструментам ранжирования слов и определения словарного запаса ученика, мы сможем повысить эффективность обучения, создавая сервисы, хорошо дополняющие нашу экосистему — например, «Тепловую карту текста» (обозначение вероятности знания учеником слова цветом) или WordSet Generator (инструмент создания списков слов для изучения на основе конкретных текстов и уровня ученика). Обладая достаточно правдивым упорядоченным по сложности списком слов, мы сможем тонко подстраивать уроки под потребности конкретного ученика – так, чтобы они были интересными (содержали новую полезную информацию) и не чрезмерно сложными (когда незнакомых слов в тексте больше двадцати).
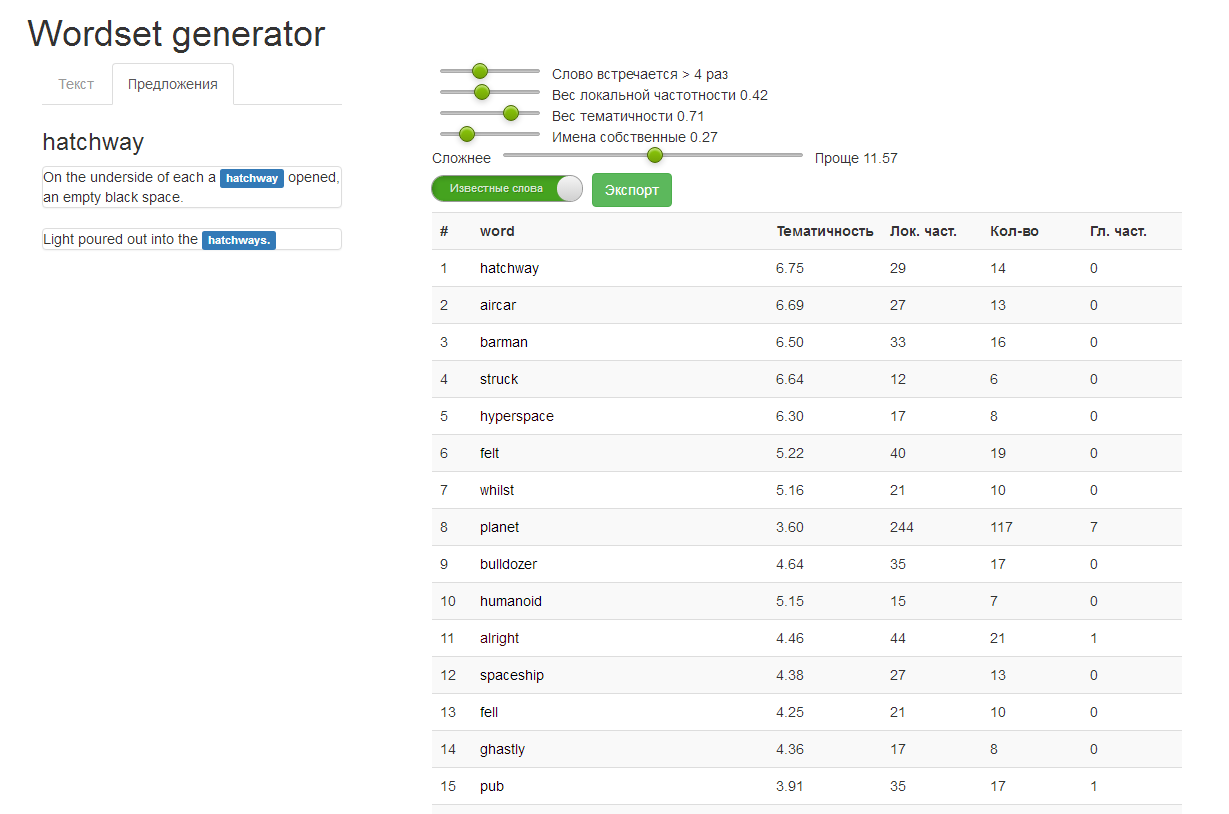
Прототип инструмента Wordset Generator с результатом обработки «Автостопом по Галактике» Дугласа Адамса
Сейчас инструмент WordMash запущен, мы набираем необходимую базу в миллион сравнений и просим читателей принять участие в эксперименте. Если есть свободная минутка — зайдите, пожалуйста, на сайт и оцените несколько пар слов с помощью клавиш курсора. Всего вам будет предложено десять тысяч пар, но все их проходить необязательно — мы сохраняем данные после каждого сравнения.
Прислушавшись к комментаторам здесь на «Хабре», мы сделали WordMash открытым: чтобы сравнивать слова, регистрироваться не обязательно, прогресс будет сохраняться с помощью куки. Тем не менее, если вы готовы потратить на сравнения заметное время, мы рекомендуем зарегистрироваться, чтобы, во-первых, сохранять индивидуальную статистику, а во-вторых, знать, кому выдать бесплатный урок в качестве благодарности. Кроме того, с регистрацией мы сможем гарантировать, что история ваших сравнений никуда не пропадет. Результаты мы храним для будущих анализов, выявления закономерностей и еще более тонкой подстройки индивидуальных программ обучения.
Комментарии (34)

slavaZim
19.05.2016 21:41+4Вы бы лучше при клике на само слово вместо выбора его перевод показывали. А это оказалось замена стрелочке с клавиатуры. Если бы можно было сразу перевод посмотреть, я бы позалипал, а так просто в свое время вам калибровать рейтинги неохота

Wadik
20.05.2016 08:04Аналогично. Прошел один столбик, дальше просто стало жалко время. Был бы перевод слов, я бы посидел дольше.
Ontaelio
19.05.2016 21:42Задача этого инструмента — определить сложность английских слов для русскоговорящих учеников. Если показывать переводы, решить эту задачу не получится.
Rikkitik
21.05.2016 18:13Перевод «более сложного слова» после клика был бы символической наградой добровольцу. В конце концов, люди, добровольно участвующие в образовательных проектах, обычно любознательны и не склонны к простому механическому «закликиванию». Да и велик шанс отвлечься на поиск перевода заинтересовавшего слова и больше не вернуться на страницу.
Моего интереса хватило чуть больше, чем на один столбик, ощущение неудовлетворённости от «пролетающих мимо» интересных слов быстро перевесило удовлетворение от общественной полезности занятия.

deniskreshikhin
19.05.2016 22:04+3Странная идея, в английском языке самые простые слова они же и самые сложные.
Например to go кроме базового значения имеет еще около 39 значений и образует кучу нетривиальных вариантов использования. А слово honorificabilitudinitas имеет одно конкретное значение и довольно простое.Ontaelio
20.05.2016 12:49Это уже совсем другая история. Вордмеш решает свою, довольно узкую задачу, он не пытается сделать сразу и все.

hmpd
19.05.2016 22:04Спасибо за подробное описание механизма работы.
Приятно видеть свежие подходы в обучении иностранным языкам.

grossws
20.05.2016 02:00А где-то можно посмотреть на оценку своего словарного запаса на основе этой тренируемой модели?

Pauelt
20.05.2016 13:56+1Для определения словарного запаса в Skyeng есть другой инструмент — level.skyeng.ru

findoff
20.05.2016 15:33+1Если включено расширение вроде uMatrix для хрома, то очень обламывает когда ты уже прошел, и нет результатов.
Т. е. я понимаю что ССЗБ, но странно что отвал только на 3-м этапе.
У пары человек в последнем хроме на Win7 не отображаются варианты(Шрифт не подгружается).ZyXI
20.05.2016 15:42У меня в qupzilla никаких расширений нет (я его и не использую почти), результат также отсутствует: после прохождения второго этапа показывает первый.
ZyXI
20.05.2016 15:35+1Что?то он ни в firefox, ни в vivaldi, ни в yandex браузере не хочет показывать слова:

, хотя они там явно есть. Просто chromium, qupzilla, а также [e]links, lynx и w3m их?таки отображают.

Greendq
21.05.2016 19:27У вас там время жизни сессии слишком маленькое — стоило отвлечься на несколько минут на звонок — и опять по кругу :)

Pugnator
20.05.2016 02:41+1Как быть с ситуацией, когда видя слово, человек помнит его перевод, просто зрительно, а вот обратно через 5 секунд не вспомнит. Сужу по себе. Сейчас изучаю новый для себя язык и пытаюсь сделать себе удобный инструмент под себя именно для тренировки словарного запаса.
Читать книги это всё здорово. Но.
По той же причине системы типа anki далеко не всегда удачны. ИМХО.XAHOK
20.05.2016 05:15У меня была та же самая проблема: читаю всего раза в 2 медленнее, чем на русском, но большую часть слов схватывал с написания, а в обратную сторону кроме нескольких десятков слов выдать не мог.
Идеальный вариант просто общаться, хотя бы письменно, на выбранном вами языке и использовать изучаемые слова и фразу. Если нет возможности общаться, то попробуйте просто думать на этом языке, только без костылей в виде перевода с родного на изучаемый (ооо, как же оно выносит мозг. Прямо как проблема белой обезьянки). Да и вообще этим костылем лучше не пользоваться. Мне этот способ хорошо помогает запоминать как отдельные слова, так и целые выражения. Правда не особо быстро, но забыть слова уже очень тяжело будет, да и практикуете не слова по отдельности, а случайными группами, включая повторы ранее выученных слов. В этом случае карточки служат в качестве напоминания, чего учить сегодня. Да и помимо словарного запаса получается хороша практика грамматики языка. Особенно оно мне помогло перестать разбирать по кускам с детальным анализом «извращения» (естественно, только по сравнению с русским языком) в стиле future perfect + passive voice в английском, а воспринимать его как есть, со всей смысловой нагрузкой.Ontaelio
20.05.2016 10:57Безусловно, этот способ идеален, если стоит задача овладеть языком. Но он очень долгий (если нет возможности смотаться на полгода в Англию), и требует приверженности. Многим нашим ученикам этого не нужно. Они хотят читать свежие статьи в своей профессиональной области, понимать докладчиков на конференциях, ну или смотреть «Звездные войны» в оригинале, причем хотят они этого здесь и сейчас. Мы не можем предложить им сперва изучить грамматику, поговорить о погоде и питомцах, Лондон из зе кепитал, вот это все, а потом, года через два, дойти до специальной лексики. Нам надо оценить их текущий уровень и подготовить минимальный набор необходимых слов — собственно, для этой задачи и создается связка WordMash — Wordset Generator.
XAHOK
20.05.2016 13:54Но он очень долгий (если нет возможности смотаться на полгода в Англию), и требует приверженности.
Честно говоря был очень удивлен, что вы его приняли за основной способ изучения языка. Он является не более, чем дополнением к любым другим и служит не более чем для забивания слов и фраз на уровень подсознательного восприятия. Как основное способ изучения языка он точно не годится.
А про приверженность вы угадали. Что бы заставить себя думать исключительно на английском, без русского, порой приходилось чуть ли не головой об стену биться. За то первое же столкновение с англоязычным докладчиком-итальянцем показало, что мозг успевает воспринимать его, не смотря на очень быстрое произношение.
Что касается сроков, то тут все на самом деле чуть быстрее. Уровня свободной переписки со словарем можно достичь за пол года и без особых проблем. Конечно, если не считать, что я придумал панацею. Через год можно достаточно свободно общаться в пределах своего словарного запаса. Но все равно оно останется именно полигоном для обкатки новых слов и знаний, которые нужно откуда-то получать.
Они хотят читать свежие статьи в своей профессиональной области, понимать докладчиков на конференциях, ну или смотреть «Звездные войны» в оригинале, причем хотят они этого здесь и сейчас.
Так я и не спорю, что обучение это комплексный подход, особенно методами с быстрой отдачей.
Мы не можем предложить им сперва изучить грамматику, поговорить о погоде и питомцах, Лондон из зе кепитал, вот это все, а потом, года через два, дойти до специальной лексики.
Ооо, вот этот метод реально очень долгий. На мне оно с работает сейчас, когда есть наработанная база и необходима шлифовка языка. А раньше он вызывал скорее отторжение, чем давал реальную пользу. Наверно потому, что практическую отдачу от него ты получаешь не сразу, а только после накопления критической массы знаний, что очень сильно демотивирует.Ontaelio
20.05.2016 16:51Честно говоря был очень удивлен, что вы его приняли за основной способ изучения языка.
Я не очень ясно выразился — разумеется, речь идет именно о лексическом запасе.XAHOK
20.05.2016 16:55Наверно я тоже не удачно выразился. Зацикливаться на одной методике и считать ее самой лучшей — это, наверно, самая большая ошибка, которую можно совершить.
Ontaelio
20.05.2016 10:36Мы сейчас как раз решаем эту задачу с мобильным приложением (напишем подробно позже). Описанная ситуация — это базовый пассивный навык знания слов. Умение вспомнить английское слово — это уже активный навык. Умение его правильно написать — еще один. Еще два навыка — понимание на слух и произношение. Анки умеет тренировать базовый пассивный навык. Наше мобильное приложение позволит тренировать и все остальные (на выбор ученика).
От себя добавлю, что умение читать и понимать книги — это уже очень хорошо. Дальше осталось прочитать пару сотен, и с лексиконом все будет в порядке. Причем английские слова привяжутся не к русским переводам, а к самим понятиям.

haldagan
20.05.2016 10:58+2Немного поучаствовал, да бросил — в ~90% случаев приходится жать вниз, т.к. сложность сравнить почти невозможно. Довольно часто — оба слова с субъективно одинаковой сложностью, сильно реже — 2 слова, определений которых я не знаю. Складывается такое ощущение, что они уже прилично упорядочены.
Как у вас считается рейтинг доверия? После выбора bogy > just, рейтинг упал с 96 до 84.
Единственное мое предположение — большинство читает bogy как «body» и дает ему «легкий» рейтинг по сравнению со всеми остальными.Ontaelio
20.05.2016 12:46Видимая цифра рейтинга обновляется с задержкой, по ней нельзя отследить конкретную ошибку.
romaf
20.05.2016 10:58На мой взгляд у вас очень сильно нехватает какой-то геймификации в этом сервисе.
Я зашел, ответил где-то на 20 слов, увидел, что мне отвечать можно еще очень очень долго и мотивация сразу пропала.
Вам стоило либо показывать перевод, тогда я мог бы поотвечать подольше, с целью изучить новые слова.
Либо сделать что-то вроде: «Вы набрали 73 попугая, расскажите друзьям, узнайте, смогут ли они побить ваш рекорд.»
Еще совсем непонятно что делать, если оба слова простые и известные, например, sex vs girl.haldagan
20.05.2016 11:08>если оба слова простые и известные
ИМХО: в этом случае «победить» должно «girl», т.к. оно, насколько мне известно, имеет только одно значение — молодая особа женского пола (девочка/девушка), а у «sex» — по крайней мере два общеупотребительных значения в зависимости от контекста — «пол» и «коитус».
naneri
20.05.2016 11:30А у этих ребят не пробовали их базу попросить? — testyourvocab.com

p53
20.05.2016 13:22Как раз идея в том, что их список — лишь начальное приближение. Поскольку он собирался на корпусах нэтивов, он не лучшим образом отражает то, как видят английский язык русскоговорящие люди.
GeorgeIV
20.05.2016 11:39+1Не совсем понятно с регистрацией. Зарегился, чтобы более полноценно поучаствовать в этом полезном процессе, а мне сразу же начали предлагать курсы, выяснять, когда со мной лучше связаться и т.п. Это как-то напрягает.
Сам процесс долгий, но хочется пройти его до конца и увидеть СВОЙ результат. Смогу ли я продолжить с другого компа после авторизации на нем или все сначала?

marenkov
20.05.2016 12:38Нужна мотивация. В текущем варианте дальше нескольких десятков слов никто не пойдет. А зачем? Обычно в подобных случаях есть выбор: заплатить vs выполнить работу, и получить что-то полезное. В вашем случае либо должно быть обещание, что тест будет бесплатным и общедоступным (выполняем полезную работу для всеобщего блага), либо начислять балы, которые можно будет использовать вместо оплаты.
Avitale
20.05.2016 13:47Хотелось бы все-таки оформления в игровой форме — лично я усердно добивала до 100 уровня доверия, потом забила. Если бы можно было сохранять результаты и продолжать работу позже или на другом компьютере — было бы здорово.
Barafu
Серьёзно задумался, когда сайт предложил мне выбрать между словами «sex» и «fuck». Ну вот прям не знаю.
Ontaelio
Если ответ не так очевиден, надо жать кнопку «вниз»!