
Тщательное изучение методологии проведения исследований с помощью магнитно-резонансной томографии делает недействительными результаты целой отрасли науки. В течение нескольких десятилетий нейробиологи и когнитивные психологи использовали для анализа данных фМРТ статистические программы AFNI, SPM и FSL. Как выяснилось, из-за некорректных алгоритмов эти программы могут возвращать до 70% ложноположительных результатов вместо предполагаемых 5%.
Таким образом, примерно 40 000 научных работ, опубликованных в последние десятилетия на основе данных фМРТ, одночасно поставлены под сомнение. Кроме того, новая оценка валидности может оказать сильное влияние на интерпретацию результатов нейровизуализации.
Функциональная магнитно-резонансная томография используется в медицине более 25 лет, и просто удивительно, что до сих пор наиболее часто используемые статистические методы, которые применяются в программном обеспечении МРТ, не были подтверждены на реальных данных, пишут авторы исследования, опубликованного 27 июня 2016 года в журнале Proceedings of the National Academy of Sciences.
Статистические методы — это основа интерпретации результатов фМРТ. Этот метод нейровизуализации позволяет определить активацию определённой области головного мозга во время нормального его функционирования под влиянием различных физических факторов (например, движение тела) и при различных патологических состояниях.
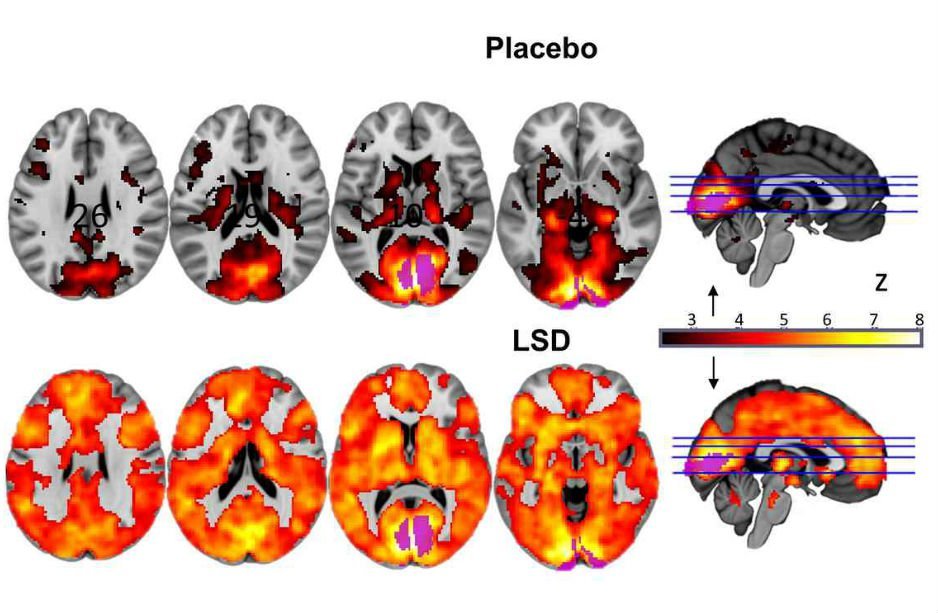
В процессе нейровизуализации по результатам сканирования фМРТ на полученных результатах сканирования с высоким разрешением мозг делится на крошечные участки (воксели). Затем программное обеспечение сканирует воксели и объединяет их в «активные» кластеры, которые соответствуют активации определённой области головного мозга.

Изображение фМРТ с жёлтыми кластерами, в которых «отмечена повышенная активность»
Проблема в том, что данная статистическая процедура выполняется некорректно и, как выяснилось, не соответствует научным требованиям к максимальной погрешности статистических данных. Авторы научной работы пишут: «Наши результаты показывают, что основной причиной некорректной кластеризации являются пространственные функции автокорреляции, которые не соответствуют предполагаемому распределению Гаусса».
Например, баг в программном обеспечении 3dClustSim (часть пакета AFNI) присутствовал 15 лет и был исправлен только в мае 2015 года, во время подготовки данного исследования, говорят авторы научной работы из университета Линчёпинга (Швеция) и Уорикского университета (Великобритания).
Во время проверки результатов работы программ сравнивались данные функциональной магнитно-резонансной томографии в состоянии покоя 499 здоровых пациентов из контрольной группы для получения 3 млн томограмм. Выяснилось, что процент ложноположительных результатов гораздо выше предполагаемых 5% и достигает 70%. Исследователи делают вывод, что параметрические статистические методы, которые используются в популярных программных пакетах SPM, FSL и AFNI, фактически непригодны для кластерного анализа результатов фМРТ, поскольку результаты не соответствуют нормальному распределению.
Вот что бывает, когда исследования проводятся без проверки корректности медицинских инструментов на соответствие научным стандартам статистики.
Авторам научных работ из медицинской области, вероятно, теперь придётся проводить исследования повторно, чтобы повторить полученный результат с помощью надёжного инструментария валидными статистическими методами.
Так что когда встретите очередное исследование с результатами фМРТ, следует с осторожностью принимать эти результаты. На эту тему даже есть комикс XKCD.

Что удивительно, комикс нарисован задолго до изучения статистических методов кластеризации вокселей фМРТ учёными из университета Линчёпинга и Уорикского университета.
Поделиться с друзьями
wtigga
Боюсь, в комиксе говорите не про ювелирные украшения…
SinsI
Там есть дополнительный текст про «неснятый пирсинг», так что скорее всего используется именно основное, а не переносное, значение.
hdfan2
Слишком глубоко копаете. Там именно про драгоценности, т.к. перед прохождением МРТ их нужно снять, и подопытные вместо выполнения нужных задач только и думают об этих драгоценностях. Комикс вообще к статье никак не относится — там подразумевается, что результаты как раз точные, даже слишком уж точные.
atomlib
Также речь может идти про то, что магнитное поле томографа может оторвать пирсинг. То есть может случиться процесс the removal of jewelry.
Welran
По основному тексту активируются центры шума, клаустрофобии и снятия украшений (потому что аппарат МРТ шумит, пациент находится в тесном пространстве и перед МРТ надо снять украшения.). По по комментарию активируются центры воздействия сомнительных исследовательских методологий, беспокойства о не снятом пирсинге и недовольства техниками болтающими о Warped Tour (музыкальный спортивный фестиваль)
Atos
о, спасибо, только после прочтения коммента дошёл смысл комикса )
hdfan2
Если знаете английский, рекомендую сайт explainxkcd.com. Там максимально подробно разобраны все комиксы. Без этого бОльшую часть я бы и сам не понял.
gerahmurov
Я думаю, как раз про украшения. Смысл в том, что перед МРТ надо снять все украшения, аппарат не беззвучен, а внутри мало места и можно испытать клаустрофобию.
Капитан, я всё правильно делаю?
wormball
Когда вам предлагают яичницу, вы тоже думаете, что вас хотят кастрировать?
lamoss
Только когда это происходит во время МРТ
ertaquo
@alexworkv2, RussianDragon, Andrey2008, PavelBelikov, SvyatoslavMC, а что, если проверить код этих трех программ с PSV-Studio? :)
Vjatcheslav3345
Стоит взять на заметку — публичная проверка медпрограмм куда интереснее для множества людей; полезнее и важнее будет, чем даже исследование церновских программ или каких то там игр, браузеров и прочего.
Ryppka
К сожалению, несостоятельность исследования с точки зрения используемых статистических методик, это не только медицинские программы. Это общая проблема сегодняшнего дня, когда наукообразие заменяет здравый смысл и дает укрытие шарлатанам.
В медицине это еще и «адаптация высоконаучного сообщества» к ограничениям, возникшим из-за требований контролируемых испытаний. Результаты должны быть правильными, а тех, кто понимает в статистике проще заставить замолчать: их и так мало кто понимает)
Welran
Так как ошибка заключается в использовании неподходящих статистических методов, то наличие/отсутствие ошибок в коде не имеет значения для данной новости. Так же это опенсорсные программы и их наверняка не раз проверяли на различных анализаторах. Ошибка не в коде, а в самой логике программ.
dmitry_ch
Пациент приходит в клинику, идет по направлению на МРТ, и до исследования начинает проверять код ПО и устанавливать заплаты на него, приговаривая «сам не сделаешь — никто не сделает!» ))
nikitastaf1996
Кстати от медика не так уж далеко до гентушника.Собери все сам, нельзя выключать, низкоуровневый доступ.
Pilat
Автор одного из планировщика Линукса как раз медик, если не ошибаюсь, хирург.
isden
Con Kolivas — анестезиолог.
Возможно еще кто-то есть, сходу не вспомню.
ertaquo
*PVS-Studio, пардон, опечатался.
Sadler
Интереснее, насколько распределение не соответствует. Если в совокупности там какие-то доли процента, то большая часть исследований окажется корректной, а если десятки процентов, то томографы показывают погоду на Марсе, что вряд ли оставалось бы незамеченным долго.
Welran
Томографы показывают активные участки мозга. Ошибка не в показаниях томографа, а в их интерпретации (некорректном объединении участков в кластера).
Sadler
Welran
Вообще говоря я так понял в статье статистические программы AFNI, SPM и FSL некорректно объявлены программным обеспечением сканера. Вообще они никакого отношения к аппарату МРТ не имеют, а обрабатывают готовые результаты. (Примерно такое же отношение как программа предсказывающая погоду имеет к спутникам наблюдающим Землю).
zenn
Насколько мне позволяет сказать мой опыт статистики — распределение величин может либо соответствовать либо не соответствовать закону распределения (степень «соответствия» редко кого интересует).
Для определения соответствия закону распределения используют «критерии точности», к примеру колмогорова-смирнова или хи-квадрат — оба сводятся к расчету накопительной суммы квадратов (или модулей с сортировкой по возрастанию) отклонений и сравнению этих отклонений с «критическими» значениями из таблицы (если полученное эмпирическое значение > критического значения t05 то делается вывод о том, что выборка не соответствует закону распределения, или для хи-квадрата отвергается нулевая гипотеза об однородности данных).
Sadler
Тем не менее, с практической т.з. порядок найденных отклонений было бы интересно знать.
choupa
Если бы сохранялись «raw» данные, можно было бы провести повторную правильную статистическую обработку сигнала.
Welran
Проблема не в том нельзя провести повторную обработку, её то скорее всего можно сделать в большинстве случаев. Там вроде не какие то сложные утерянные raw данные, а просто картинки мозга с яркими и темными участками по которым уже анализирующие программы ищут статистические корреляции. И они наверняка сохранились. А вот данные уже могут получится совсем другие и результаты 40000 исследований теперь сомнительны. И перепроверить все 40000 это довольно много работы.
kt315
RAW данные предполагают поток данных еще до предоставления их в виде картинок. Имеется в виду, что если есть сырые данные с разнообразных сенсоров и датчиков как они есть, а они полюбому где-то хранятся на какое-то время, то провести иследования заново абсолютно не проблема. Вопрос где и как долго они хранятся, можно ли их сохранить?!
pwrlnd
RAW данные имеют большой объём: на современных аппаратах — гигабайты на обычный скан мозга, который вы делаете, посещая клинику. При исследовании итераций было явно больше, чтобы была возможность посмотреть происходящие процессы в динамике — соответственно объём данных ещё больше. Также стоит учесть, что участников исследования было много, поэтому вполне возможно, что эти данные не сохранились.
Gryphon88
Вообще принято хранить и именно в «равках», также как и журнал исследований. Но некоторые забивают, плюс научные, не клинические, данные трут со временем (там правда может набежать терабайт на исследование) или при увольнении сотрудника, проводившего исследование.
0xd34df00d
Плюс те исследования, что зависят от этих 40 тысяч, и так далее до всего транзитивного замыкания.
dmitry_ch
Вы думаете, оно медикам надо? Они не сами софт писали, так что им (от греха) забыть вопрос и (если обновление будет) следующих уже диагностировать правильнее.
В истории науки таких случаев с неверными методиками проверки было масса, и пациентов кучу прооперировали, и иных даже залечили до смерти — вряд ли кто-то извинился особенно-то: издержки профессии.
tmin10
К сожалению, по умолчанию считается, что весь медицинский софт должен быть идеальным, а на баги в нём мало кто будет думать. Вспоминается печальный случай багов в Therac-25, там как раз тоже уверенность в ПО подвела частично.
Vjatcheslav3345
Кстати, а есть в мире организации, которые занимаются проверкой не программных багов (как в случае с PVS-Studio), а ошибок в алгоритмах — например, фирмы или сообщества, основанные профессиональными математиками и предлагающие проверку на ошибки в алгоритмах?
taujavarob
Vjatcheslav3345 >Кстати, а есть в мире организации, которые занимаются проверкой не программных багов (как в случае с PVS-Studio), а ошибок в алгоритмах — например, фирмы или сообщества, основанные профессиональными математиками и предлагающие проверку на ошибки в алгоритмах?
Есть — например софт для управления поездами метро во Франции (без машиниста) не содержит программных ошибок.
Для этого применяется специальная методика разработки — выдвижения гипотез и проведение доказательств.
potan
Пора уже задуматься над системой в стиле реактивного программирования, которая при нахождения ошибки в использованной программе, изобретения новых статметодов, появления уточненных данных и тп, пересчитывала все в зависимых статьях и перепроверяла их выводы.
По моему, достойная задача.
chersanya
Этому мешает примерно то же, что мешает сделать автоматическую проверку всех математических статей на правильность доказательств теорем с помощью соответствующего софта: для этого требуется всё писать в некоем машиночитаемом формате, намного более громоздком, чем обычный текст. Поэтому и делать так особо никото не будет.
Gryphon88
сырые данные к статьям не прикладывают
potan
Обычно из приводят в Supplementary information. Правда, редко когда в структурированном виде.
Gryphon88
Для биомедицинских статей видел считанные разы, к сожалению. Исходные картинки (полный сырой набор) не видел вообще ни разу. Бывает, видишь таблицу, а там стандартное отклонение подозрительно маленькое, как будто это на самом деле ошибка среднего, хочешь данные пересчитать из сорца или полу-сорца, типа экселевского листа с результатами измерений, но до стат.обработкии — а нету.
alexhott
Статья целенаправленно написана некорректно чтобы спутать обычного читаеля?
Или это такой маркетинговый ход чей-то?
Речь идет про визуализацию активности мозга с помощью томографии — а это далеко не целая отрасль науки, а довольно узкая специализация.
И если учесть, что МРТ в гораздо большей мере используется для целей визуализации состояния тканей, то процент ошибочных исследований примерно 0,0001%.
Статья должна иметь заголовок что-то типа: Проблема исследования активности мозга с помощью МРТ и начинаться с того, что человек пока понятия не имеет как работает мозг, а только начинает делать догадки. И пытаться с помощью МРТ оценить функциональное состояние. — а далее по тексту.
6ft
Почти никогда не комментирую ничего в интернете, но здесь не мог пройти мимо по профессиональным причинам (я занимаюсь исследованиями с использованием фМРТ).
В статье целая куча неточностей, и вот самые главные: SPM, FSL и AFNI — это не «программное обеспечение сканеров». Это отдельные статистические пакеты, обычно опен-сорсные, написанные людьми, которые занимаются анализом фМРТ-данных. Эти люди — не «медики», как написано в статье. Медики вообще очень редко занимаются анализом именно функционального МРТ, их больше интересуют структурные снимки. Это ученые — в основном когнитивные психологии и нейробиологи, и для анализа фМРТ данных не нужно иметь медицинскую степень — вообще. Как работает реально ПО самих сканеров, я (и большинство людей которые работают в этой области) имею весьма отдаленно представление.
Дальше. Основная идея статьи в ПНАС в том, что базовые методы анализа кластеров, которые большинство людей используют в этих пакетах, дают много ложно-позитивных результатов. Это на самом деле не новость, и это известно довольно большому кругу ученых, которые этим серьезно занимаются. В основном это связано с гетерогенной структурой мозга и локальными корреляциями между соседними вокселями, которые эти методы (составляющие только часть пакетов!) не принимают во внимание. То есть вся суть в том, что нужно использовать адекватные методы, а не в том, что там есть какие-то баги. Баг там был только один и только в одном пакете (AFNI). Все остальные пакеты — опенсорс и над ними одновременно работает много людей, так что большинство багов выявляются довольно быстро.