
Сегодня хочу рассказать вам об open source проекте под названием Bagri. Bagri — это распределенная база данных документов (document database), или как сейчас модно говорить NoSQL база данных, написанная на Java и спроектированная с учетом требований, в основном используемых в корпоративном секторе, таких как высокая готовность, отказоустойчивость, масштабируемость и поддержка транзакционности.
Bagri построена поверх продуктов реализующих распределенный кэш, таких как Hazelcast, Coherence, Infinispan и других подобных систем. Именно за счет возможностей распределенного кэша Bagri поддерживает требования корпоративного сектора прямо из коробки. Распределенный кэш используется системой не только как хранилище данных, но и как распределенная система обработки этих данных, что позволяет эффективно и быстро обрабатывать любые большие объемы слабо структурированных данных. Транзакционность в системе решена с помощью алгоритма реализующего multi-version concurrency control
Данные в систему поставляются в виде документов XML или JSON. Есть так же возможность реализовать свое расширение к Bagri и зарегистрировать плагин для работы с новыми форматами документов, а так же с внешними системами хранения документов. Вспомогательный проект bagri-extensions содержит разрабатываемые командой расширения (на данный момент реализован коннектор к MongoDB).
В качестве языка запросов используется XQuery, в дальнейшем планируется так же поддерживать синтаксис SQL, данная задача имеется в Гитхабе проекта.
Bagri не требует предварительных знаний о схеме данных, а формирует словарь данных (уникальных путей в структурах документов) “на лету” во время парсинга входящих документов. Т.о. Bagri полностью schemaless и ему не требуется перестроения таблиц для новых типов документов, т.е. команды create table/add column ему не нужны в принципе.
Для общения между клиентом и сервером Bagri предлагает два API: стандартный XQJ API заявленый в JSR 225 и свой собственный XDM API, предоставляющий дополнительную функциональность, отсутствующую в XQJ. По сути, интерфейсы XQJ являются аналогом функционала, предоставляемого драйвером JDBC при работе с реляционными БД. Вместе с драйвером XQJ с системой поставляется официальный XQJ TCK, который можно запустить и удостовериться что драйвер проходит все тесты XQJ на 100%.
Все документы в Bagri хранятся в схемах, ближайшим аналогом в реляционной базе данных (RDBMS) является database. В настоящее время в качестве распределенного кэша, на котором строится система, используется Hazelcast и под каждую схему выделяется отдельный Hazelcast кластер. Схемы существуют независимо друг от друга, т.е. не происходит “борьбы” за ресурсы между схемами (в Hazelcast каждый кластер настраивается отдельно и имеет свой собственный пул ресурсов).
Мета данные документов (пространства имен, типы документов, уникальные пути) хранятся в соответствующих кэшах и реплицируются между всеми узлами кластера. Т.о. доступ на рабочих узлах к метаданным на чтение осуществляется максимально быстро. Сами данные документов отделены от метаданных и хранятся в распределенных кэшах, при этом данные, относящиеся к одному документу всегда хранятся на одном и том же узле. Есть еще кэши для хранения индексированных значений, для скомпилированных запросов, для журнала транзакций и конечно для результатов выполненных запросов.
Клиент Bagri подключается к серверу с помощью внутренних механизмов клиентского ПО кэша. XQuery запросы на клиенте упаковываются в задания и выполняются на серверных узлах посредством распределенного ExecutorService’а, предоставляемого платформой Hazelcast.
Результаты возвращаются клиенту через выделенный асинхронный канал (очередь Hazelcast)
Вся конфигурация системы хранится в двух файлах: access.xml для настроек ролей и пользователей и config.xml с настройками схем и расширений Bagri. Подробное описание формата этих файлов и всех используемых в них параметров можно прочесть в инструкции по инсталляции и конфигурации системы. Менять настройки схем можно напрямую в файлах, либо через JMX интерфейсы управления схемами развернутых на административном сервере Bagri.
Давайте теперь перейдем от теории к практике и рассмотрим, как мы можем работать с Bagri из нашего Java кода через интерфейсы XQJ.
Внутри спрингового контекста заявляем бин BagriXQDataSource и настраиваем четыре его основных параметра: адрес удаленного сервера, имя схемы, имя пользователя и пароль.
Получаем XQJ connection:
Затем считываем текстовый файл и на базе него создаем новый документ в Bagri:
Запрос выше вызывает внешнюю функцию store-document определенную в пространстве имен bgdm. Функция принимает на вход 3 параметра: uri, под которым будет сохранен документ, текстовое содержимое документа и необязательный набор опций, определяющий дополнительные параметры работы функции сохранения документа. Запрос валидируется на клиентской стороне и затем отправляется на сервер вместе с параметрами.
На серверной стороне пришедшему документу присваивается уникальный идентификатор. Далее, содержимое документа парсится в соответствии с указанным форматом документа и разбивается на пары путь/значения, при этом все уникальные пути сохраняются в реплицируемом справочнике путей документов. По окончании процедуры парсинга все содержимое документа, разбитое на такие пары, сохраняется в распределённых кэшах системы, а так же кэшируется заголовок документа со служебной информацией. Если в схеме зарегистрированы индексы, все индексируемые значения так же сохраняются в кэше индексов. Подтверждение об успешном сохранении документа передаётся назад на клиентскую сторону.
После того как мы благополучно сохранили наш документ в Bagri, давайте рассмотрим, как мы можем делать запросы к документам, хранящимся в системе.
Получаем подключение XQJ:
Подготавливаем запрос XQuery:
Задаём значение параметра поиска:
Выполняем запрос на сервере:
И просматриваем полученные результаты:
Я думаю будет так же интересно рассказать о том, что же происходит на сервере при выполнении данного кода:
Запрос проходит через XQuery процессор (в настоящее время это Saxon), в котором формируется дерево выполнения запроса (compiled query, XQueryExpression). Затем оно транслируется в набор простых запросов к кэшированным данным по указанным путям:
Эти простые запросы выполняются параллельно на всех узлах распределенного кэша системы. Найденные документы поставляются процессору на последующую обработку. По возможности используются индексы, если запрашиваемые пути были проиндексированы. После окончательной обработки полученных документов процессором результаты передаются клиенту назад через выделенный асинхронный канал.
Bagri предоставляет богатые возможности по расширению поведения системы. Например, можно подключить триггер на любое изменения состояния документа (before/after insert/update/delete) и выполнять в этих точках дополнительную бизнес-логику. Для этого достаточно реализовать интерфейс com.bagri.xdm.cache.api.DocumentTrigger, как показано в одном из примеров, поставляемых с системой (см. samples/bagri-samples-ext):
И затем зарегистрировать триггер в схеме в файле config.xml:
Как показано выше, мы зарегистрировали библиотеку (bagri-samples-ext-1.0.0-EA1.jar), содержащую реализацию триггера. Так же библиотеки могут содержать дополнительные функции, написанные на Java, которые можно вызывать из запросов XQuery, а так же расширения для обработки новых форматов данных или подключения к внешним системам хранения документов.
Bagri может быть развернут следующими способами:
Визуальный административный интерфейс Bagri на данных момент реализован, как плагин для VisualVM и позволяет:
Данный модуль еще находится в стадии активной разработки, функционал плагина постоянно наращивается. В случае обнаружения ошибок, а так же в случае предложений по недостающему функционалу, их всегда можно (и нужно!) занести в issues проекта.
Скриншоты административной консоли — см. ниже
Итак, мы рассмотрели самые базовые возможности распределенной базы данных документов Bagri. Надеемся что вас заинтересовал данный проект и вы попробуете его использовать в своей повседневной работе.
Я же со своей стороны постараюсь в ближайшее время написать для вас еще несколько статей, раскрывающих темы сравнения Bagri с другими похожими продуктами, такими как BaseX, MongoDB, Cassandra и возможности расширения системы путем использования встроенных API (DataFormat API и DataStore API).
Bagri, как и любому другому open source проекту, требуются разработчики на Java заинтересованные в данной тематике, так что если вам после прочтения данной статьи станет интересен проект, добро пожаловать на Гитхаб Bagri, там есть много действительно интересных задач.
Bagri построена поверх продуктов реализующих распределенный кэш, таких как Hazelcast, Coherence, Infinispan и других подобных систем. Именно за счет возможностей распределенного кэша Bagri поддерживает требования корпоративного сектора прямо из коробки. Распределенный кэш используется системой не только как хранилище данных, но и как распределенная система обработки этих данных, что позволяет эффективно и быстро обрабатывать любые большие объемы слабо структурированных данных. Транзакционность в системе решена с помощью алгоритма реализующего multi-version concurrency control
Данные в систему поставляются в виде документов XML или JSON. Есть так же возможность реализовать свое расширение к Bagri и зарегистрировать плагин для работы с новыми форматами документов, а так же с внешними системами хранения документов. Вспомогательный проект bagri-extensions содержит разрабатываемые командой расширения (на данный момент реализован коннектор к MongoDB).
В качестве языка запросов используется XQuery, в дальнейшем планируется так же поддерживать синтаксис SQL, данная задача имеется в Гитхабе проекта.
Bagri не требует предварительных знаний о схеме данных, а формирует словарь данных (уникальных путей в структурах документов) “на лету” во время парсинга входящих документов. Т.о. Bagri полностью schemaless и ему не требуется перестроения таблиц для новых типов документов, т.е. команды create table/add column ему не нужны в принципе.
Для общения между клиентом и сервером Bagri предлагает два API: стандартный XQJ API заявленый в JSR 225 и свой собственный XDM API, предоставляющий дополнительную функциональность, отсутствующую в XQJ. По сути, интерфейсы XQJ являются аналогом функционала, предоставляемого драйвером JDBC при работе с реляционными БД. Вместе с драйвером XQJ с системой поставляется официальный XQJ TCK, который можно запустить и удостовериться что драйвер проходит все тесты XQJ на 100%.
Как функционал распределенного кэша используется в Bagri
Все документы в Bagri хранятся в схемах, ближайшим аналогом в реляционной базе данных (RDBMS) является database. В настоящее время в качестве распределенного кэша, на котором строится система, используется Hazelcast и под каждую схему выделяется отдельный Hazelcast кластер. Схемы существуют независимо друг от друга, т.е. не происходит “борьбы” за ресурсы между схемами (в Hazelcast каждый кластер настраивается отдельно и имеет свой собственный пул ресурсов).
Мета данные документов (пространства имен, типы документов, уникальные пути) хранятся в соответствующих кэшах и реплицируются между всеми узлами кластера. Т.о. доступ на рабочих узлах к метаданным на чтение осуществляется максимально быстро. Сами данные документов отделены от метаданных и хранятся в распределенных кэшах, при этом данные, относящиеся к одному документу всегда хранятся на одном и том же узле. Есть еще кэши для хранения индексированных значений, для скомпилированных запросов, для журнала транзакций и конечно для результатов выполненных запросов.
Клиент Bagri подключается к серверу с помощью внутренних механизмов клиентского ПО кэша. XQuery запросы на клиенте упаковываются в задания и выполняются на серверных узлах посредством распределенного ExecutorService’а, предоставляемого платформой Hazelcast.
Результаты возвращаются клиенту через выделенный асинхронный канал (очередь Hazelcast)
Конфигурирование системы
Вся конфигурация системы хранится в двух файлах: access.xml для настроек ролей и пользователей и config.xml с настройками схем и расширений Bagri. Подробное описание формата этих файлов и всех используемых в них параметров можно прочесть в инструкции по инсталляции и конфигурации системы. Менять настройки схем можно напрямую в файлах, либо через JMX интерфейсы управления схемами развернутых на административном сервере Bagri.
Примеры работы с данными
Давайте теперь перейдем от теории к практике и рассмотрим, как мы можем работать с Bagri из нашего Java кода через интерфейсы XQJ.
Внутри спрингового контекста заявляем бин BagriXQDataSource и настраиваем четыре его основных параметра: адрес удаленного сервера, имя схемы, имя пользователя и пароль.
<bean id="xqDataSource" class="com.bagri.xqj.BagriXQDataSource">
<property name="properties">
<props>
<prop key="address">${schema.address}</prop>
<prop key="schema">${schema.name}</prop>
<prop key="user">${schema.user}</prop>
<prop key="password">${schema.password}</prop>
</props>
</property>
</bean>
<bean id="xqConnection" factory-bean="xqDataSource" factory-method="getConnection“/>
Получаем XQJ connection:
context = new ClassPathXmlApplicationContext("spring/xqj-client-context.xml");
XQConnection xqc = context.getBean(XQConnection.class);Затем считываем текстовый файл и на базе него создаем новый документ в Bagri:
String content = readTextFile(fileName);
String query = "declare namespace bgdm=\"http://bagridb.com/bagri-xdm\";\n" +
"declare variable $uri external;\n" +
"declare variable $content external;\n" +
"declare variable $props external;\n" +
"let $id := bgdm:store-document($uri, $content, $props)\n" +
"return $id\n";
XQPreparedExpression xqpe = xqc.prepareExpression(query);
xqpe.bindString(new QName("uri"), fileName, xqc.createAtomicType(XQBASETYPE_ANYURI));
xqpe.bindString(new QName("content"), content, xqc.createAtomicType(XQBASETYPE_STRING));
List<String> props = new ArrayList<>(2);
props.add(“xdm.document.data.format=xml"); //can be “json” or something else..
xqpe.bindSequence(new QName("props"), xqConn.createSequence(props.iterator()));
XQSequence xqs = xqpe.executeQuery();
xqs.next();
long id = xqs.getLong();Запрос выше вызывает внешнюю функцию store-document определенную в пространстве имен bgdm. Функция принимает на вход 3 параметра: uri, под которым будет сохранен документ, текстовое содержимое документа и необязательный набор опций, определяющий дополнительные параметры работы функции сохранения документа. Запрос валидируется на клиентской стороне и затем отправляется на сервер вместе с параметрами.
На серверной стороне пришедшему документу присваивается уникальный идентификатор. Далее, содержимое документа парсится в соответствии с указанным форматом документа и разбивается на пары путь/значения, при этом все уникальные пути сохраняются в реплицируемом справочнике путей документов. По окончании процедуры парсинга все содержимое документа, разбитое на такие пары, сохраняется в распределённых кэшах системы, а так же кэшируется заголовок документа со служебной информацией. Если в схеме зарегистрированы индексы, все индексируемые значения так же сохраняются в кэше индексов. Подтверждение об успешном сохранении документа передаётся назад на клиентскую сторону.
После того как мы благополучно сохранили наш документ в Bagri, давайте рассмотрим, как мы можем делать запросы к документам, хранящимся в системе.
Получаем подключение XQJ:
XQConnection xqc = context.getBean(XQConnection.class);Подготавливаем запрос XQuery:
String query = "declare namespace s=\"http://tpox-benchmark.com/security\";\n" +
"declare variable $sym external;\n" +
"for $sec in fn:collection(\“securities\")/s:Security\n" +
"where $sec/s:Symbol=$sym\n" +
"return $sec\n";
XQPreparedExpression xqpe = xqc.prepareExpression(query);Задаём значение параметра поиска:
xqpe.bindString(new QName("sym"), “IBM”, null);Выполняем запрос на сервере:
XQResultSequence xqs = xqpe.executeQuery();И просматриваем полученные результаты:
while (xqs.next()) {
System.out.println(xqs.getItemAsString(null));
}Я думаю будет так же интересно рассказать о том, что же происходит на сервере при выполнении данного кода:
Запрос проходит через XQuery процессор (в настоящее время это Saxon), в котором формируется дерево выполнения запроса (compiled query, XQueryExpression). Затем оно транслируется в набор простых запросов к кэшированным данным по указанным путям:
[PathExpression [path=/ns2:Security/ns2:Symbol/text(), param=var0, docType=2, compType=EQ]], params={var0=IBM}Эти простые запросы выполняются параллельно на всех узлах распределенного кэша системы. Найденные документы поставляются процессору на последующую обработку. По возможности используются индексы, если запрашиваемые пути были проиндексированы. После окончательной обработки полученных документов процессором результаты передаются клиенту назад через выделенный асинхронный канал.
Возможности расширения системы
Bagri предоставляет богатые возможности по расширению поведения системы. Например, можно подключить триггер на любое изменения состояния документа (before/after insert/update/delete) и выполнять в этих точках дополнительную бизнес-логику. Для этого достаточно реализовать интерфейс com.bagri.xdm.cache.api.DocumentTrigger, как показано в одном из примеров, поставляемых с системой (см. samples/bagri-samples-ext):
public class SampleTrigger implements DocumentTrigger {
private static final transient Logger logger = LoggerFactory.getLogger(SampleTrigger.class);
public void beforeInsert(Document doc, SchemaRepository repo) {
logger.trace("beforeInsert; doc: {}; repo: {}", doc, repo);
}
public void afterInsert(Document doc, SchemaRepository repo) {
logger.trace("afterInsert; doc: {}; repo: {}", doc, repo);
}
public void beforeUpdate(Document doc, SchemaRepository repo) {
logger.trace("beforeUpdate; doc: {}; repo: {}", doc, repo);
}
public void afterUpdate(Document doc, SchemaRepository repo) {
logger.trace("afterUpdate; doc: {}; repo: {}", doc, repo);
}
public void beforeDelete(Document doc, SchemaRepository repo) {
logger.trace("beforeDelete; doc: {}; repo: {}", doc, repo);
}
public void afterDelete(Document doc, SchemaRepository repo) {
logger.trace("afterDelete; doc: {}; repo: {}", doc, repo);
}
}И затем зарегистрировать триггер в схеме в файле config.xml:
<schema name="sample" active="true">
<version>1</version>
<createdAt>2016-09-01T15:00:58.096+04:00</createdAt>
<createdBy>admin</createdBy>
<description>sample schema</description>
<properties>
………
</properties>
<collections/>
<fragments/>
<indexes/>
<triggers>
<trigger xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="ns2:javatrigger">
<version>1</version>
<createdAt>2016-09-01T15:00:58.096+04:00</createdAt>
<createdBy>admin</createdBy>
<docType>/{http://tpox-benchmark.com/security}Security</docType>
<synchronous>false</synchronous>
<enabled>true</enabled>
<index>1</index>
<actions>
<action order="after" scope="delete"/>
<action order="before" scope="insert"/>
</actions>
<library>trigger_library</library>
<className>com.bagri.samples.ext.SampleTrigger</className>
</trigger>
</triggers>
</schema>
</schemas>
<libraries>
<library name="trigger_library">
<version>1</version>
<createdAt>2016-09-01T15:00:58.096+04:00</createdAt>
<createdBy>admin</createdBy>
<fileName>bagri-samples-ext-1.0.0-EA1.jar</fileName>
<description>Sample extension trigger Library</description>
<enabled>true</enabled>
<functions/>
</library>
</libraries>
Как показано выше, мы зарегистрировали библиотеку (bagri-samples-ext-1.0.0-EA1.jar), содержащую реализацию триггера. Так же библиотеки могут содержать дополнительные функции, написанные на Java, которые можно вызывать из запросов XQuery, а так же расширения для обработки новых форматов данных или подключения к внешним системам хранения документов.
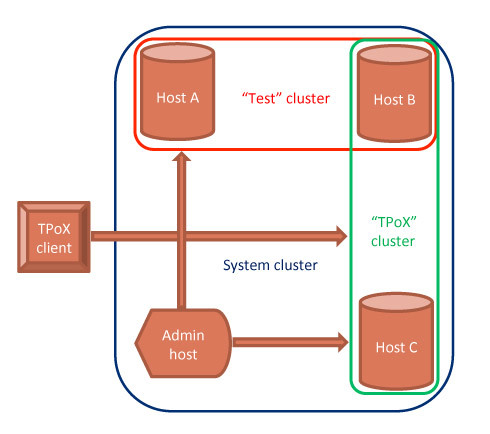
Варианты развертывания системы
Bagri может быть развернут следующими способами:
- Standalone Java app — подходит для небольших приложений, которым нужно обрабатывать ограниченный набор данных. Все работает в рамках одной JVM с одной схемой, предоставляя максимальную производительность на ограниченных (памятью одной JVM) объемах данных.
- Client-server, distributed database — клиенты общаются с распределенной системой хранения данных посредством XDM/XQJ-драйвера. Распределенная обработка запросов в памяти, возможность on-line обработки неограниченного количества данных
- Administration server — предоставляет дополнительный функционал по сбору статистик и мониторингу состояния рабочих узлов системы. Обычно развертывается как отдельный узел, но это не обязательный компонент, система может работать и без него.
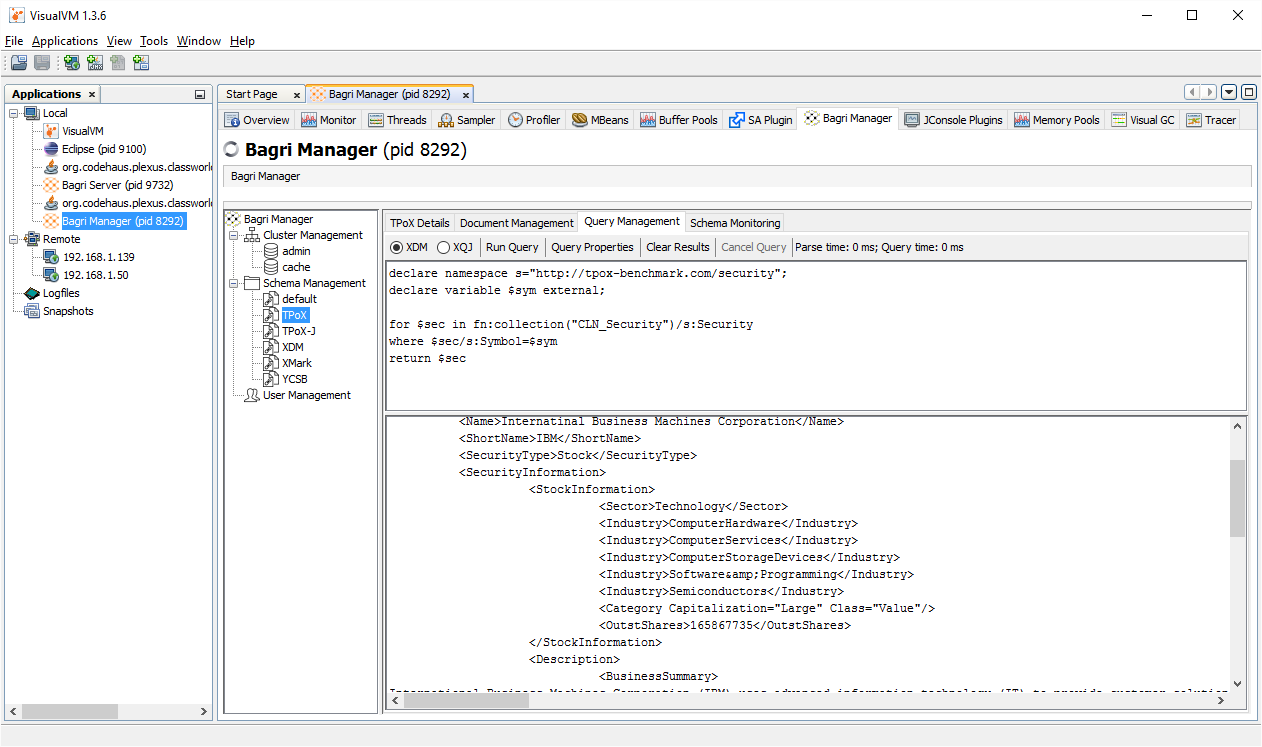
Визуальный административный интерфейс
Визуальный административный интерфейс Bagri на данных момент реализован, как плагин для VisualVM и позволяет:
- конфигурировать пользователей и роли
- подключать внешние библиотеки функций Java и дополнительные модули XQuery для использования их в запросах
- конфигурировать схемы и их составляющие: коллекции, словари мета-данных, индексы и триггера, доступ пользователей и ролей к схемам
- визуально просматривать документы и коллекции
- выполнять XQuery запросы и получать результаты через встроенную консоль
Данный модуль еще находится в стадии активной разработки, функционал плагина постоянно наращивается. В случае обнаружения ошибок, а так же в случае предложений по недостающему функционалу, их всегда можно (и нужно!) занести в issues проекта.
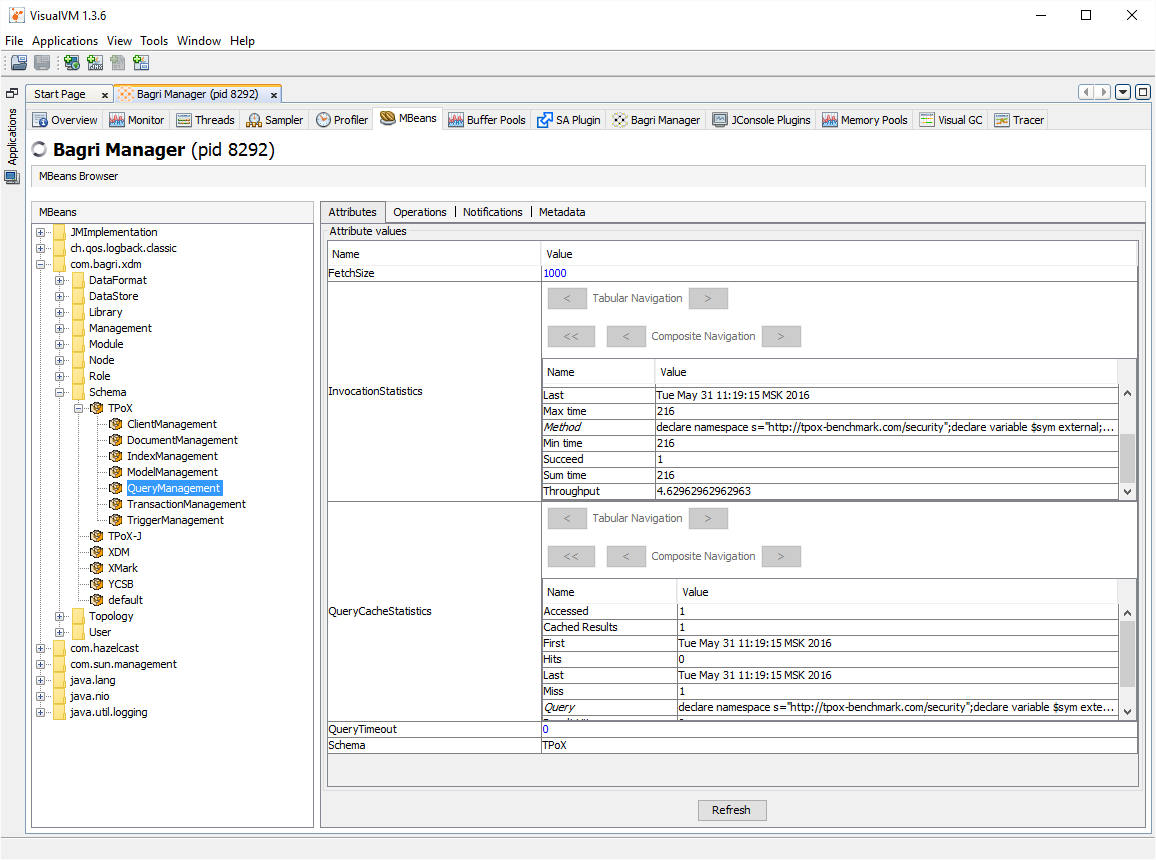
Скриншоты административной консоли — см. ниже
Итак, мы рассмотрели самые базовые возможности распределенной базы данных документов Bagri. Надеемся что вас заинтересовал данный проект и вы попробуете его использовать в своей повседневной работе.
Я же со своей стороны постараюсь в ближайшее время написать для вас еще несколько статей, раскрывающих темы сравнения Bagri с другими похожими продуктами, такими как BaseX, MongoDB, Cassandra и возможности расширения системы путем использования встроенных API (DataFormat API и DataStore API).
Bagri, как и любому другому open source проекту, требуются разработчики на Java заинтересованные в данной тематике, так что если вам после прочтения данной статьи станет интересен проект, добро пожаловать на Гитхаб Bagri, там есть много действительно интересных задач.
Поделиться с друзьями
Комментарии (6)

AlexPu
16.09.2016 11:07Мне очень понравилось — в ближайшее время попробую и… буду тметь в виду на будущее… как там насчет корпоративного сектора не знаю, но вот в тех областях, где я работаю очень даже применимо и выглядит довольно привлекательно…
Но это предварительно конечно — надо попробовать…dsukhoroslov
16.09.2016 14:44Если что — обращайтесь, буду рад помочь с прототипом…
AlexPu
16.09.2016 15:49Спасибо
я-б с удовольствием — я давно дивился отчего это Hazelcast никто толком не использует для распределенного хранения данных — допустить мысль, что я один такой умный я не мог, поэтому подозревал, что я чего-то не знаю (и за не имением времени узнать не могу — просто потому, что не горит)… Вот теперь посмотрим что это за зверь…
Но до прототипа правда пока далеко :)
fediq
Из статьи непонятно самое главное — на какую нишу нацелена Bagri? Под какие задачи подходит лучше всего? Как выглядит в сравнении с другими решениями — базами данных, кешами, execution-фреймворками? Чем она удобнее, быстрее, надёжнее?
Короче, почему я буду использовать молодую зелёную базёнку вместо зрелых, проверенных продакшеном решений?
mhalifax
Добрый вечер, спасибо за ваш комментарий, попробую ответить по пунктам:
Систему хорошо использовать в первую очередь в тех случаях, когда документооборот основан на XML. Это финансы, логистика, страхование, медицина, и другие индустрии где формат документов, которыми обмениваются участники, строго определён корпоративными схемами XSD. Система позволяет не парсить каждый входящий документ, а класть его в базу как есть, а потом эффективно выполнять любые запросы над хранимыми документами используя мощный инструментарий XQuery 3.1.
На самое деле, мне кажется данный вопрос достоин отдельной статьи, насколько мне известно у автора Багри есть подробные сравнения с конкурирующими продуктами в первую очередь это Marklogic, BaseX,MongoDB, я думаю в скором времени я получу эти данные и смогу написать развернутую статью, если вкратце, существующие системы: либо принципиально одно-нодные, плохо или вообще не масштабируются, но хорошо работают с XML, либо распределенные, масштабируются хорошо, но с XML не работают и, как правило, в них не поддерживаются транзакции, также Багри реализует стандартный XQJ драйвер, а не проприетарный API, системой поддерживаются уникальные индексы (unique indices), которые хорошо работают в транзакциях. Так же процессинговую логику на стороне сервера можно расширять с помощью триггеров написанных на Java или Xquery. Как уже было сказано выше наиболее близким к Багри коммерческим продуктом на рынке на данный момент является Marklogic, в нем практически есть все, что есть в Багри, но он безумно дорог и по словам автора Marklogic медленнее Багри.
dsukhoroslov
Максим, спасибо за статью. Про индексы немного поясню: да, поддерживаются уникальные индексы, а в MarkLogic они как раз отсутствуют. По причине использования MVCC, скорее всего. В других системах типа Mongo есть уникальные индексы, но нет транзакционности на много-документных операциях.
Еще в плюсы системе поставил бы исключительно простую масштабируемость, отказоустойчивость (не нужно отдельно конфигурировать бэкап-сервера, указывать кто чьей репликой яввляется и т.п.)…