
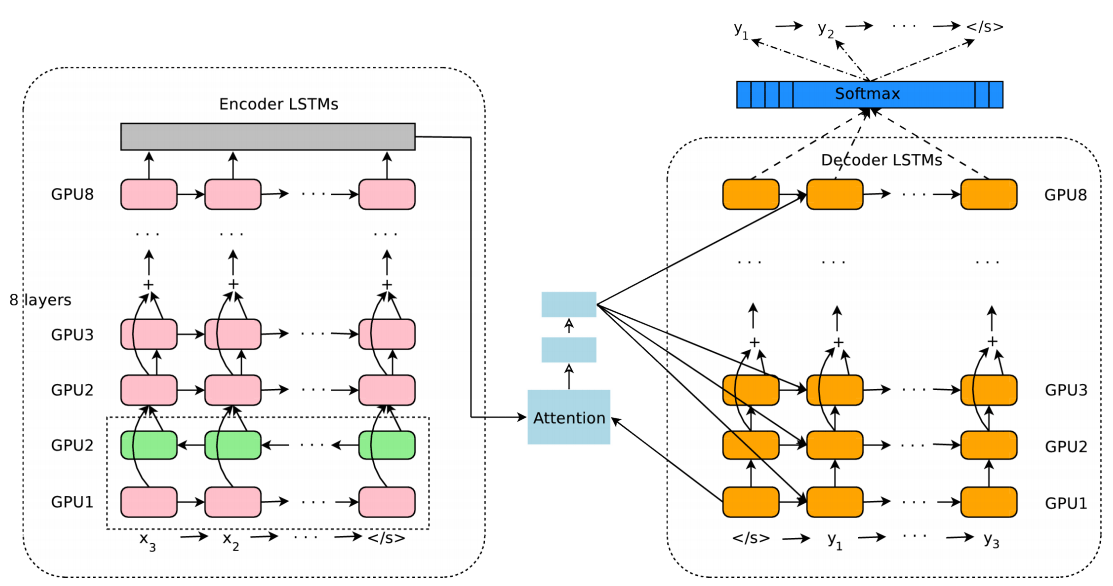
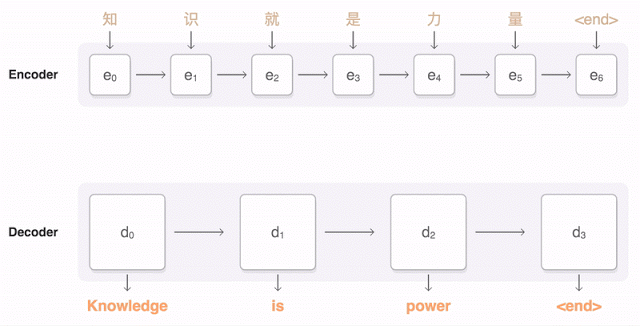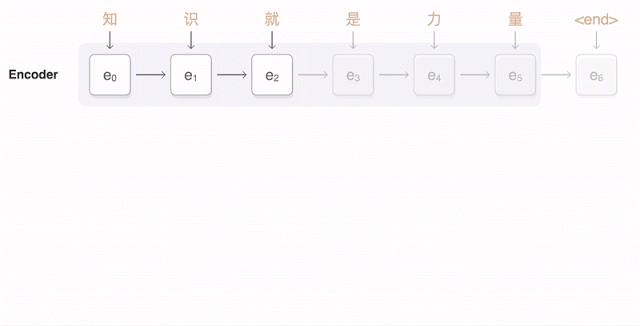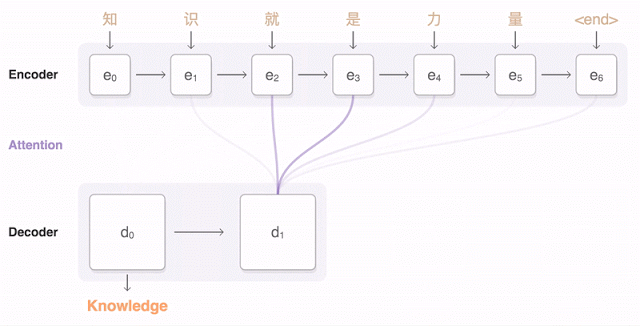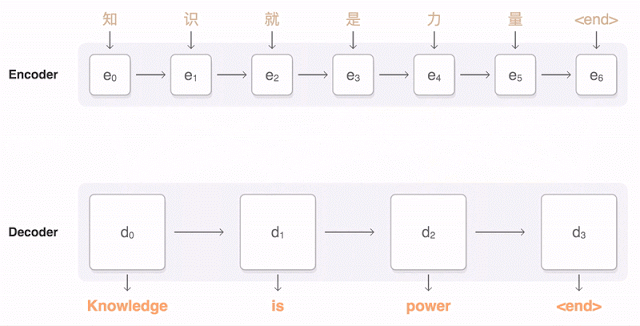
Модель архитектуры GNMT (Google’s Neural Machine Translation). Слева сеть энкодера, справа — декодера, в середине модуль внимания. Нижний слой энкодера двусторонний: розовые модули собирают информацию слева направо, а зелёные — в обратном направлении
Компания Google собирается полностью перевести сервис Google Translate на глубинное обучение. Детальное описание алгоритма нейросети опубликовано на arXiv.org.
По предварительным оценкам Google, нейросеть обеспечивает гораздо лучшее качество перевода, чем обычные статистические методы. Её уже опробовали в сложнейшей языковой паре английский?китайский, и нейросеть сразу на 60% снизила количество ошибок перевода. Результат впечатляет. Другие языковые пары подключат к нейросети в течение ближайших нескольких месяцев.
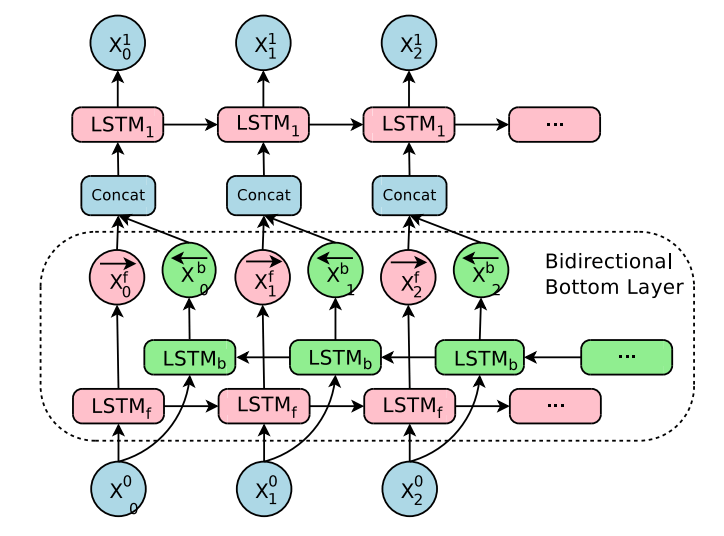
Структура двунаправленных связей в нижнем уровне энкодера
Успех в области машинного перевода — ещё одно достижение ИИ, коих набралось немало в последнее время. Технология обучаемых нейросетей явно находится на подъёме и применяется в разных областях. Особенно явное превосходство над другими компьютерными техниками достигнуто в распознавании изображений и играх. В некоторых из областей нейросети работают даже более эффективно, чем человеческий мозг, например, обыгрывают человека в отдельные настольные игры.
Нейросеть Google для машинного перевода называется Neural Machine Translation System (NMTS). От самого начала и до конца перевод текста теперь полностью выполняет нейросеть. Традиционно ИИ использовался в Google Translate в ограниченном режиме, для некоторых вспомогательных задач. Например, для сравнения текстов, доступных на нескольких языках, вроде официальных документов ООН или Европарламента. В таком режиме сравнивался перевод каждого слова в текстах.
Нейросеть NMTS работает на принципиально новом уровне. Она не только анализирует существующие варианты перевода в процессе обучения, но и выполняет интеллектуальный анализ предложений, разбивая их на «словарные сегменты». В определённой репрезентации внутри сети эти «словарные сегменты» соответствуют смыслам слов.
Анимация Google показывает, как китайское предложение разбивается на части, а затем нейросеть подбирает подходящий перевод, учитывая вес каждого фрагмента в оригинальном тексте
В каком-то смысле такой подход напоминает работу нейросетей в машинном зрении. Система обрабатывает изображение попиксельно. Затем уровень обработки постепенно увеличивается, достигая таких сложных черт как границы объектов, геометрические паттерны и т.д. В NMTS та же нейросеть, которая анализирует исходный текст, затем предлагает его перевод.
В данном случае разработчики Google применили существующие разработки в этой области, а также несколько «методологических инноваций», комментируют незавиимые специалисты научную работу, опубликованную на arXiv.org. По их мнению, разработка Google показывает «потрясающий» результат и наглядно демонстрирует, что нейронный перевод с помощью ИИ способен намного превзойти по качеству классические методы машинного перевода. Нейросеть Google явно улучшает качество перевода во многих отношениях.
Для оптимизации NMTS обкатывалась на компьютерном оборудовании, специально разработанном для тестирования нейросети. Именно там обучали в своё время нейросеть AlphaGo, которая после этого победила Ли Седоля, одного из лучших в мире игроков в го.
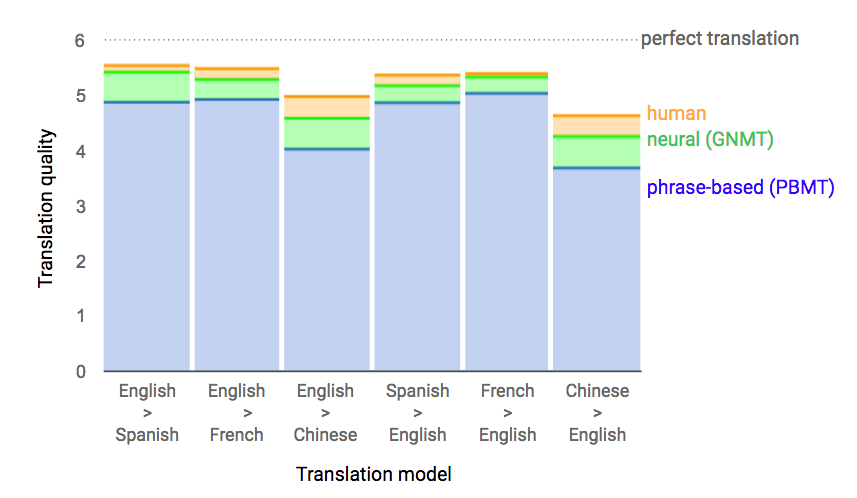
Для оценки эффективности системы исследователи подобрали большой набор предложений из Википедии и новостных статей в интернете. Эти тексты скормили NMTS, в старую систему машинного перевода перевода Google Translate, а также дали людям-переводчикам. В рамках слепого тестирования люди-переводчики оценивали качество перевода каждого фрагмента (в том числе человеческий перевод).
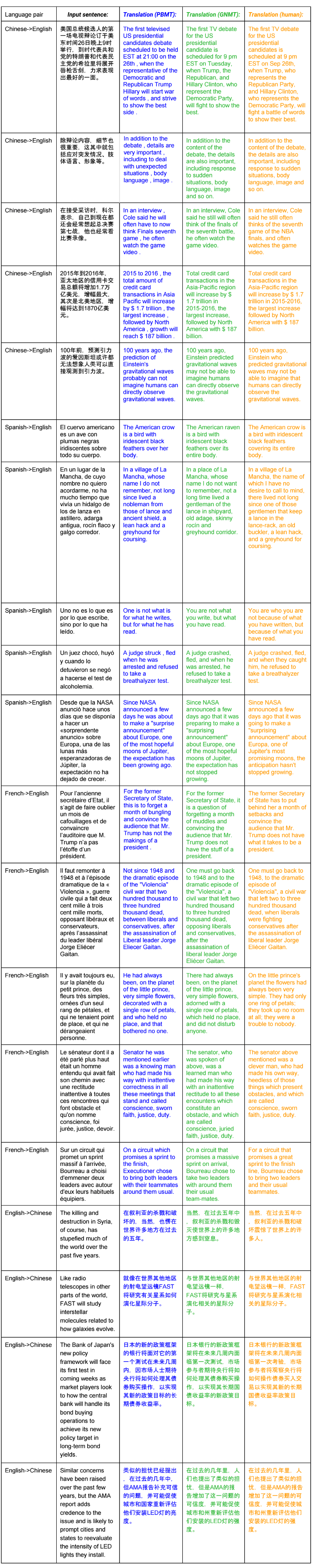
Языковая пара английский?китайский известна своей высокой сложностью. Несмотря на значительное уменьшение количества ошибок, качество перевода в этой языковой паре по-прежнему уступает качеству перевода других индоевропейских языков. В некоторых языковых парах перевод NMTS приближается по качеству к переводу людьми, но авторы научной работы предупреждают, что рано делать далеко идущие выводы, ведь сравнение производилось на ограниченном наборе тщательно отобранных простых предложений.
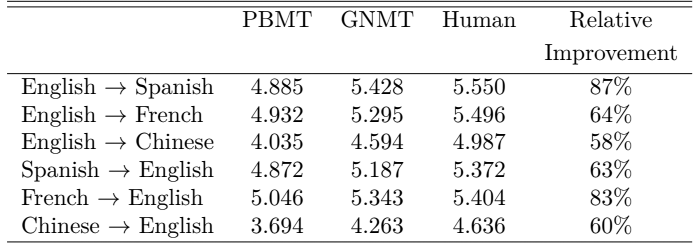
Те же результаты в более наглядном виде.
По мнению специалистов, компьютер сможет приблизиться или обойти человека по качеству перевода только в том случае, если к системе машинного перевода подключат дополнительные каналы входящей информации. Не только текст, но и видео, и звук. «В будущем роботы смогут двигаться, манипулировать объектами, чувствовать боль через сенсоры боли — и выражать свои чувства в тексте», — говорит Юрген Шмидхубер (Jurgen Schmidhuber) из Университета Лугано (Швейцария).
Система Google Translate в настоящее время обрабатывает около 10 000 языковых пар для машинного перевода.
Комментарии (56)

NeoCode
28.09.2016 15:46А зачем ограничиваться официальными документами ООН и Европарламета, если есть огромная библиотека Google books, в которой наверняка есть немало книг переведенных профессиональными переводчиками на разные языки?

TrurlMcByte
28.09.2016 16:17+5Художественный перевод иногда слишком художественный. В отличии от официального.
NeoCode
28.09.2016 22:46Ну так нейросеть же, вот пускай и учится переводить художественно. А официальные документы написаны бюрократическим языком (причем чем круче лавочка тем заковыристее бюрократический язык), поэтому в повседневном переводе малополезны.
TrurlMcByte
29.09.2016 03:59+3Ты себе явно не представляешь степень художественности при самых обычных литературных переводах. Зачастую получается совсем новое произведение, с отдалённо похожим на оригинал сюжетом. А иногда и вообще не похожим.

eugenius_nsk
03.10.2016 12:47+1Классика:
«И Боромир, превозмогая смерть, улыбнулся.» — Перевод В. Муравьева, А. Кистяковского.
«Тень улыбки промелькнула на бледном, без кровинки, лице Боромира.» — Перевод Н. Григорьевой, В. Грушецкого.
«Уста Боромира тронула слабая улыбка.» — Перевод М. Каменкович, В. Каррика.
«Boromir smiled.» — Оригинал.

Efethu
28.09.2016 16:26Я так понимаю, это все еще эксперименты и на translate.google.com ничего еще недоступно.
Пример с Го хороший, но нельзя забывать, что там против Ли Седоля трудился целый небольшой датацентр — 1900 CPU и 280 GPU.
Вполне возможно, что переводы с участием нейросети потребуют такого количества ресурсов, что гугл не сможет их предоставить в качестве бесплатного онлайн сервиса в ближайшем будущем.
Впрочем, я бы все равно не рекомендовал новому поколению при поступлении в вуз выбирать профессию переводчика.
Sadler
28.09.2016 16:36+1Затратно по ресурсам в основном обучение (не берём случай с посэмпловым восстановлением звука из недавней статьи) и переборные этапы алгоритма (в том же AlphaGo был перебор дерева решений). В этой работе я не вижу ничего подобного, лишь две LSTM, так что оно максимум может быть затратно в плане RAM, но едва ли сильно медленно.

Fagot63
28.09.2016 23:35Пусть даже платно. Если качество перевода будет на уровне, я лично готов платить.
mypallmall
28.09.2016 17:25In addition to releasing this research paper today, we are announcing the launch of GNMT in production on a notoriously difficult language pair: Chinese to English. The Google Translate mobile and web apps are now using GNMT for 100% of machine translations from Chinese to English—about 18 million translations per day. The production deployment of GNMT was made possible by use of our publicly available machine learning toolkit TensorFlow and our Tensor Processing Units (TPUs), which provide sufficient computational power to deploy these powerful GNMT models while meeting the stringent latency requirements of the Google Translate product. Translating from Chinese to English is one of the more than 10,000 language pairs supported by Google Translate, and we will be working to roll out GNMT to many more of these over the coming months.
https://research.googleblog.com/2016/09/a-neural-network-for-machine.htmlEfethu
28.09.2016 18:04Возможно, он и включен, но стандартная проверка двойным переводом, к сожалению, как обычно, меняет смысл чуть ли не на противоположный.
«Police shot a man they said was acting erratically in a San Diego suburb Tuesday, drawing an angry cluster of protesters who believed it was another instance of law enforcement shooting an unarmed black man»
«Police officers who shot, they said, were destabilizing in the suburbs of San Diego on Tuesday, drawing an angry cluster of protesters who believe this is another example of shooting unarmed black law enforcement.»
Подождем пары русский<->английский, там качество будет более наглядным.daiver19
28.09.2016 18:50+2Так вроде английский-китайский еще на старом движке (судя по формулировке, по крайней мере). Данный алгоритм в теории должен давать идентичные переводы после прогона туда-сюда.
kazaff
28.09.2016 16:27Нейросети сейчас больше дань моде, чем необходимость. Не так давно Серебряной Пулей в ИТ считали big data и использовали этот метод к месту и не к месту.

SAN4EZ7714
28.09.2016 16:41+1Не совсем. Нейросети сейчас показывают объективно лучший результат во многих задачах. И как следствие все больше используется в коммерции. (к примеру беспилотные авто)
А big data уже давно неотделима от крупного бизнеса. (к примеру в банках)
mypallmall
28.09.2016 17:37+1Вы считаете Тесла, забавы ради так упорно автопилот обновляет?
И еще, возможно ли то, что показано в ролике без нейросетей? А, именно, очень такой не слабый прогресс, который уже влияет на рынок страхования в США. Вы только представьте, какая это часть американской экономики и мировой экономики. Я про страхование.
xtala
28.09.2016 18:05-1А руль с правой стороны почему?
Efethu
28.09.2016 18:31+1Потому что автопилот еще недостаточно совершенен, чтобы убрать руль совсем.
А так вообще треть населения земного шара ездит по дорогам с левосторонним движением.
Sly_tom_cat
29.09.2016 00:08Островитяне — странные немного они… но у этого хоть язык понятный. Для этого отдельно взятого острова — это редкость…
UK детектится по беглому взгляду на дорожную карту — наверно ни в одной другой стране не делают столько много круговых развязок как в Англии.
Efethu
28.09.2016 18:25Мы не видели код автопилота теслы и не знаем, что они там обновляют.
Но подозреваю, что количество костылей и подпорок, которые у них в коде таково, что можно будет выключить нейросеть и машина все равно будет держать полосу и тормозить.
Другим круиз контролям это как-то удается.
Использование нейросетей в страховании вещь очень спорная. Нейросеть может поставить вас в «группу риска» абсолютно по любому поводу. «Слабая активность на фейсбуке», «Мало путешествует», «Работает в такси»(но айтишником).
В среднем это компании, конечно, принесет прирост прибыли, а вот вы, если выделяетесь чем-то из серой массы, можете быть вынуждены платить за страховку вдвое больше остальных, а кредит вообще не получить.mypallmall
28.09.2016 20:12Я про применение ИИ, нейронных сетей в машинах, автомобилях, «тачках».
Тесла своим автопилотом поразила финансовые дома, которые занимаются всеми видами страховок тем или иным образом связанные с автомобилями.
И их мало интересует, костыли это или ходули.
Они понимают, что в течении 3-5-7-10 лет рынок автомобильного страхования может в корне измениться или исчезнуть вовсе. Поэтому не в шутку и всерьез ищут новые ниши для своих капиталов.
На данный момент все мало мальски значимые автопроизводители очень активно занимаются разработкой своего автопилота. Несмотря на то, что громкие заголовки делают далеко не все компании.
Это кстати одна из версий, почему Крис Урмсон, главный технический директор проекта беспилотных автомобилей Google, покинул проект в этом августе.
Рынок «на пути к автопилоту» сейчас переживает очень сильное развитие, которое не сильно заметно людям во в него не вовлеченным.
Более подробно тут: https://www.quora.com/Why-are-so-many-people-leaving-Googles-self-driving-car-unit
Shurik_13
28.09.2016 16:27<...> учитывая вес каждого фрагмента в оригинальном тексте
Ну и как же компьютер способен «взвесить» этот самый фрагмент? Откуда машина берет семантическую составляющую?
Еще ладно книги и документы, но если мы говорим о переводе разговорной речи (особенно устной), о какой точности может идти речь, если абсолютно большая часть информации — это невербальные признаки (интонация, жесты, мимика, поза, расстояние, громкость). Разумеется нужны дополнительные «каналы входящей информации», но нужны алгоритмы намного более сложные чем те, которые отличают кошек от хлеба на картинках.
Пойду дальше распечатывать письма от моих друзей, а Google Translate пускай пока решит — ножом или на принтере.Sadler
28.09.2016 16:42Я вот тоже не могу уловить Ваши мимику, жесты, позу, расстояние и громкость через интернет, однако мне это не мешает использовать разговорный стиль в общении.
Почитайте о word2vec, как-то так и определяет. Если кратко, определяет по месторасположению в предложении: с какими словами рядом может/не может располагаться, вместо каких слов в предложении может употребляться и т.п. На больших масштабах эта штука начинает работать весьма точно.Shurik_13
28.09.2016 16:51Но вы прекрасно можете воспринять и учесть оттенок и оценку, которую я вкладываю в свой комментарий. Вы прекрасно понимаете, что я негодую и отрицаю успех сабжа, хотя мой комментарий начинается с двух простых и не самых эмоциональных, но риторических вопросов.
Word2vec — правильное направление развития. В лингвистике это называется корпусом языка и позволяет всего лишь фиксировать состояние языка, но никак не способствует развитию каких-либо технологий напрямую. Другими словами, можно сколь угодно долго собирать корпус и выявлять частотность, но это никогда не позволит машине понять, где и почему она ошиблась.
daiver19
28.09.2016 18:54+1Ваше предложение не может 100-процентно трактовать ни один интеллект, кроме вашего собственного. Вы вот еще слово «коса» на английский предложите перевести без контекста.
Shurik_13
28.09.2016 22:22Вопрос не в текстовом контексте, а в семантическом. Мой собеседник почти наверняка будет знать, вернулся ли я только что с почты или закончил устанавливать драйверы. Машине же придется откуда-то брать и обрабатывать колоссальное количество информации, включая персональные данные и полный контекст ситуации.
daiver19
28.09.2016 23:27+2Вы просто хотите от машины решения задачи, которую ей не ставили. Задача на данный момент — перевод текста. Т.е. и машина, и человек для её решения получат одинаковый вход. Вот когда будет задача «общайся с человеком», тогда это будет справедливым аргументом.
Delics
28.09.2016 21:22«Вес слова» — количество слов в большой выборке, деленное на частоту упоминания данного слова в этой выборке.
Также можно составить и «веса фрагментов».Shurik_13
28.09.2016 22:18Но как вес позволит машине определить, что наиболее тяжелое значение — верное? Корпус языка всего лишь позволяет узнать вероятность, с которой определенные слова встречаются в одном предложении. Разговорная речь полна сарказма, иронии, оксюморонов и прочих стилистических особенностей, в которых может встречаться огромное количество уникальных комбинаций слов. Это уже не говоря о референсах и цитатах, за которыми стоит гигантский культорологический контекст. Дав машине прочитать словарь вы не научите ее культуре, которую представляет язык.
Delics
28.09.2016 23:12Всё же в большинстве случаев, «тяжелые» слова появляются во фразах не случайно. И на них ИИ обязательно надо обратить внимание.
Так что разбивка на группы по весу вполне логична.

red75prim
29.09.2016 10:32LSTM-сети хороши тем, что они учатся создавать и использовать контекст для определения вероятности варианта перевода. Сеть сворачивает культурные особенности текста в вектор контекста. Возможно в этом векторе есть и детектор иронии. Если это не понимание, то я даже и не знаю, что можно назвать пониманием.
Конечно, современные сети не идеальны. У них нет мета-уровня. Они не умеют учиться учится, т.е. не умеют кодифицировать найденные закономерности для использования в похожих ситуациях и т.п. Но, учитывая результаты их работы, называть их тупыми числодробилками, как, например, делает некий известный лингвист, в своё время сильно помешавший развитию статистических подходов в лигвистике, становится всё тяжелее.
Shurik_13
29.09.2016 10:41Именно! Разумеется, мета-уровень и отличает машину от живого переводчика. И хотя статься содержит впечатляющие графики, на которых машина почти догнала человека, между ними все равно огромная пропасть.
Как лингвист я не верю в успех машинного перевода на текущем этапе развития, но не буду скрывать своего восхищения самой идеей обработки целых культур в виде векторов контекста.

0xd34df00d
29.09.2016 19:04Я сначала распарсил ваше предложение в смысле принтера, например, и только вторая часть помогла мне вспомнить, что у слова «распечатывать» есть и другой смысл. Априорная вероятность околопринтерного у меня высоковата.
Я не Google Translate, честно-честно!
mickey99
30.09.2016 16:36У Google Translate уже есть «Варианты перевода» на уровне слова/словосочетания. Будет на уровне предложения, потом на уровне абзаца, и т.д.

potan
28.09.2016 18:27А в чем особая сложность пары английский-китайский? Я думаю пара венгерский-вьетнамский будет заметно сложнее.

tUUtiKKi13
28.09.2016 19:39Пары венгерский-вьетнамский может и не быть. В таких случаях используют буфферный язык.
То есть, например, венгерский — английский, английский — китайский.
Randl
28.09.2016 20:04Пара венгерский-вьетнамский сложна с точки зрения количества материала для обучения. Поэтому скорее всего перевод идет через английский.
Пара английский-китайский сложна именно с точки зрения разницы между языками, а материалов как раз достаточно.potan
28.09.2016 20:26Английский и китайский оба аналитические языки, где словоформы мало употребляются. Кроме того очень много китайцев владеют английским, что может порадить достаточно большое количество легко переводимых конструкций в существующих текстах.
Угро-финские языки отличаются от китайского или вьетнамского значительно сильнее.
Я думаю, что при выборе пары все-таки руководтвовались не столько сложностью, сколько доступностью обучающей выборки.
Crr
29.09.2016 11:56Надеюсь, это научит Google Translate переводить следующую фразу на английский: «Я, конечно, могу писать по-английски».



xtala
Мужайтесь. Мы больше не увидим перлы от китайских товарищей в стиле: «Кастрюлька утюга варит рыб».
Ra-Jah
Все хуже, очевидные предложения не мог перевести.
https://hsto.org/files/850/ed8/f35/850ed8f35c0046b5be2c741d831c4a73.png
Его даже как словарь опасно использовать, не говоря о семантике. Схема работы ничего не прояснила, но очень любопытно увидеть результат.
EndUser
Русский же не подключали ещё.
AndSoft
вышеупомянутые примеры тоже пока переводятся «по-старому»
Ra-Jah
Признаться честно, я считал, что переводчик гугла изначально был подключен к нейросетям. :(
nikitastaf1996
Как я понял они еще это не ввели для пары английский-русский.Для пары китайский-английский.Так тяжело найти норм статью на китайском.
http://tech.qq.com/a/20160928/038373.htm
Ну вроде бы неплохо.Построение слегка неверное но это прекрасный результат.
lonelymyp
Это ещё достаточно безобидный вариант.
Вот такой вариант может создать определённые сложности:
https://goo.gl/1e8p9F
mik63
А «Символ власти»? ))) это про пульт ДУ.
xtala
А это наверное М.Веллер переводил.
betrachtung
bondbig