

Skyeng делится с Хабром ссылкой на внутреннее приложение, которым пользуются наши методисты.
Мы в школе Skyeng убеждены, что чем быстрее ученик получает ощутимый эффект от занятия или тренировки, тем выше его мотивация и эффективнее само обучение. Традиционная методика изучения языков обещает конкретный результат лишь через длительное время — год, два, т.е. требует вложения значительных сил, времени и средств без немедленного эффекта. Мы считаем, что вполне реально получить “возврат инвестиций” быстро, если ставить перед собой небольшие конкретные задачи и решать их. Сегодня мы расскажем про один из наших служебных инструментов, предназначенный как раз для этого, и дадим читателям возможность попробовать его в деле, составить собственные списки слов, самые интересные из которых будут предложены всем пользователями Aword!
Если вам надо приготовить ирландское рагу по оригинальному рецепту на английском, традиционная школа предложит выучить 200 наименований кухонной утвари и 300 наименований различных продуктов. Мы предлагаем сразу учить слова, имеющие непосредственное отношение к задаче — т.е. встречающиеся в рецептах именно ирландского рагу. Инженеру-конструктору для чтения профессиональной литературы необязательно проходить уроки про “Лондон из зе капитэл” и экологию: ему достаточно знания базовой и узкоспециальной лексики.
Для решения таких конкретных задач мы готовим тематические наборы слов, которые могут заучивать пользователи нашего мобильного приложения Aword. А для подготовки этих сетов мы используем инструмент Wordset Generator, создающий упорядоченный список слов для запоминания из текста или набора текстов, которые хочет прочитать ученик.

Результат обработки книги Дугласа Адамса “Автостопом по Галактике”

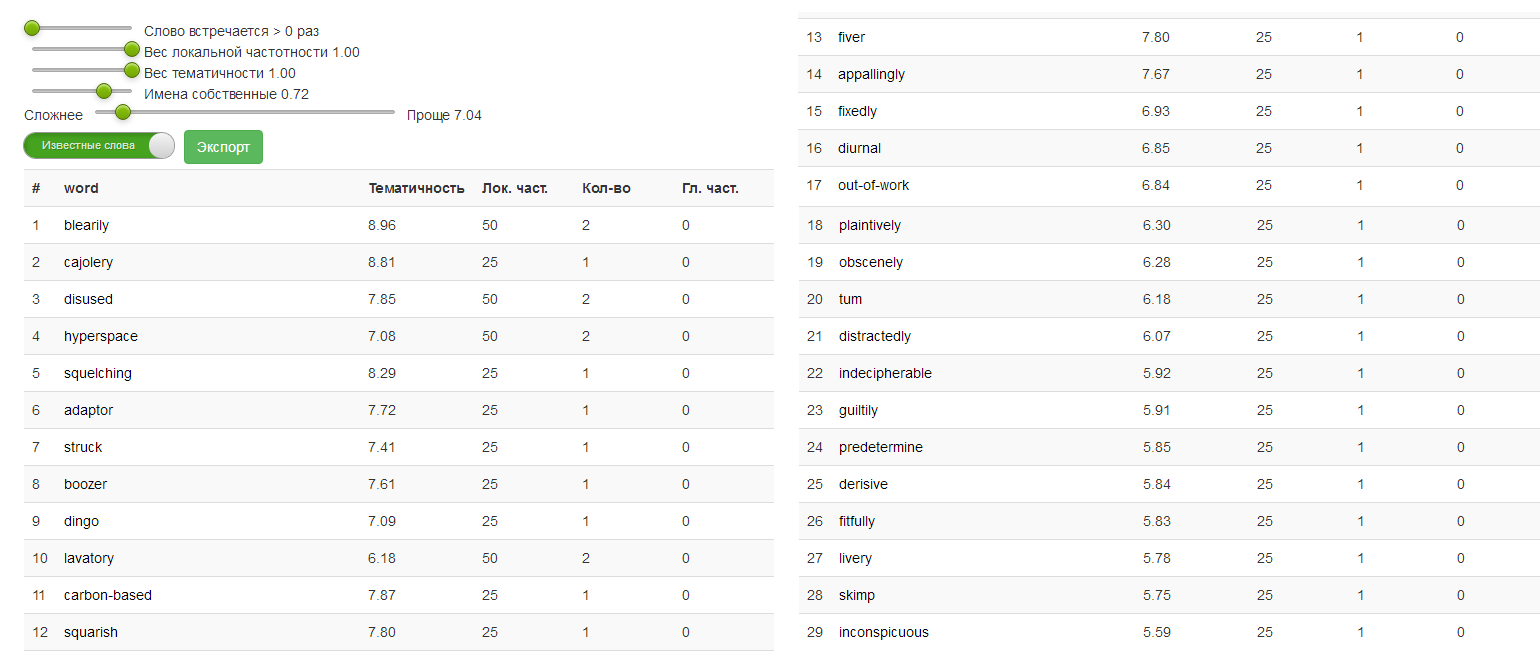
Слова, встречающиеся в 5 сезонах игры престолов, наложенные на модельную кривую знания ученика. Координаты каждой точки (слова) — полезность от номера слова. Справа показаны наиболее полезные для такого ученика 25 слов из сериала.
Создание Wordset Generator стало возможно благодаря наличию у нас инструментов ранжирования слов и определения словарного запаса конкретного ученика (в одной из предыдущих статей мы рассказывали, зачем мы сделали эти инструменты, а не воспользовались готовыми корпусами). Для каждого слова может быть вычислена эффективная полезность: насколько изучение этого слова увеличит коэффициент понимания текста. С помощью Wordset Generator мы можем порекомендовать ученику изучать в первую очередь самые распространенные неизвестные ему слова или же, напротив, наиболее важные в его профессиональной деятельности.
Алгоритм
— Составляется список всех использованных в тексте слов, с указанием количества вхождений.
— Отсекаются (отправляются в отдельный список) все слова, отсутствующие в нашем словаре. Как правило, это выдуманные автором слова, имена, названия.
— Определяется «тематичность» каждого слова в списке, для чего сравнивается частота вхождения слова в анализируемом тексте с частотой вхождения этого слова в корпусе текстов английского языка (его распространенности). Число означает, во сколько раз чаще слово присутствует в анализируемом тексте.
Дальше проводится полуавтоматическая подстройка списка под конкретные нужды (с помощью заданных параметров или перемещения ползунков).
— Задается уровень знания ученика («сложность»). При этом отсекаются слова, с которыми ученик, скорее всего, уже знаком.
— Выбираются веса тематичности и локальной частотности. Тематичность важна в том случае, если мы готовим список профессиональных терминов для использования по работе. В случае анализа художественной литературы важнее частотность.
— Наконец, алгоритм умеет вычислять вероятность того, что конкретное слово в данном тексте является именем собственным (в веб-версии такие слова подсвечиваются разной интенсивности красным цветом). Ползунок «Имена собственные» позволяет удалять такие слова в соответствии с заданной вероятностью; в большинстве случаев здесь требуется ручное вмешательство, особенно если речь идет о художественной литературе.
Не только машина
Инструмент Wordset Generator значительно облегчил работу нашего контент-отдела, но, конечно, не взял ее на себя. Методисты по-прежнему играют важную роль в составлении тематических наборов слов для заучивания.
Во-первых, им необходимо подготовить корпус текстов, из которых будут извлекаться слова. Если с конкретной книгой или фильмом эта задача более-менее проста, то в случае тематических наборов типа “В аэропорту” нужно перелопатить довольно значительный объем информации, чтобы набрать хорошую репрезентативную выборку: классические тексты из учебников, статьи из путеводителей, правила авиакомпаний, отзывы в блогах (как правило, жалобы) и т.д. Важно, чтобы эти тексты были современные и живые, поскольку мы хотим учить студентов языку, на котором сегодня говорят и пишут американцы и британцы.
Во-вторых, необходимо настроить правильные параметры сложности, тематичности и прочие. Все это делается только ручным перетаскиванием ползунков, поскольку сильно зависит от цели набора, уровня подготовки ученика, специфики темы и т.д.
В-третьих, требуется серьезная работа с полученным набором слов. Необходимо выяснить точное значение слова в данном контексте. Кроме того, зачастую необходимый термин состоит не из одного слова, а из нескольких, их тоже надо найти и привести список в порядок. Так, в случае аэропортовой лексики мы обнаружили среди часто встречающихся слово metal: на самом деле речь шла о metal detector. Подобные словосочетания часто состоят из простых слов, которые инструмент отбрасывает – их надо найти и вернуть на место.
Наконец, надо еще подобрать ко всем словам картинки – так, чтобы они соответствовали нужному смыслу. Этим тоже занимается специальный человек.
Применение
Наиболее очевидное применение инструмента Wordset Generator для наших студентов – создание списков слов для заучивания под конкретные книги или фильмы. Если проанализировать текст книги, составить список из сотни слов и поучить его в мобильном приложении – читать будет значительно проще, не придется каждые пять минут лазить в словарь.
Благодаря инструменту мы можем быстро готовить наборы слов под конкретное событие: презентацию очередного Айфона, чемпионат по футболу, громкую премьеру или какой-нибудь медийный скандал. С такой просьбой к нам могут обращаться наши ученики, и мы сами стараемся отслеживать потенциально востребованные “скоропортящиеся” темы, чтобы своевременно предложить пользователям мобильного приложения набор слов под них.

Анализ художественной литературы помогает методистам готовить рекомендационные списки для каждого уровня учеников. Чем меньше «сложных» слов выдает программа – тем доступнее текст для студентов, находящихся в середине пути изучения языка. Для высоких же уровней такие тексты не представляют трудности и не несут образовательной пользы – им надо подыскивать более богатые лексически произведения. Например, в произвольно выбранном детективе Агаты Кристи (After the Funeral) «сложных» слов насчитывается менее 300; в «Улиссе» Джеймса Джойса список заходит за 2000.
Очень полезен инструмент Wordset Generator в нашей работе с корпоративными клиентами, которым зачастую требуется изучение и заучивание специальной профессиональной лексики. Так, для одного из корпоративных клиентов, работающего в аэрокосмической отрасли, мы подготовили списки слов на основе анализа десятков статей в профессиональных журналах. Важно, что в высокотехнологичных областях лексика постоянно обновляется; использование нашего инструмента и подборки максимально свежих материалов позволяет создавать списки, содержащие наиболее актуальные термины.
К делу!
Мы решили дать читателям Хабра возможность самостоятельно поиграться с Wordset Generator – вот он: http://tools.skyeng.ru/sandbox/wordset-generator/
Он более-менее интуитивный, хотя стоит учитывать, что это наш внутренний инструмент, не предназначенный для широкой публики, а потому интерфейс его весьма аскетичен и непричесан.
В открытой версии есть ограничение на размер текста — не больше 80 тысяч знаков, включая пробелы и переносы строк. Практика показывает, что это оптимальное значение для полезного применения инструмента «в быту». Берите то, что собираетесь прочитать в ближайшее время: пару глав, десять страниц или несколько статей. Вы получите компактный набор, который можно тренировать в мобильном приложении в течение дня, а вечером закрепить выученное в контексте (попутно насладившись книгой). Например:
перед вами – результат парсинга первой главы “Автостопом по Галактике” Адамса. Сравните со скриншотом в начале статьи, где показан результат анализа всей книги с теми же параметрами. Эти слова там тоже есть, но где-то в третьей-четвертой сотне, а здесь они представлены, как на блюдечке.
Полученные слова можно добавить в приложение вручную с помощью встроенного словаря. А читатели Хабра могут создать собственный список слов, экспортировать его в CSV и поделиться ссылкой на полученный файл в комментариях к этому посту. Через неделю мы выберем самые интересные сеты, предложенные Хабром, и включим их в наше приложение в специальной категории “Сеты от хабровчан”.
Само приложение Aword можно взять в App Store. Уже скоро оно будет доступно в Google Play, а в ноябре — в Web-версии!
Удачного изучения слов!
И традиционно напоминаем, что мы будем рады видеть в нашей команде ценных специалистов!
Комментарии (28)

Ontaelio
24.10.2016 13:26«Вес локальной частотности» — наверху слова, чаще всего встречающиеся в тексте.
«Тематичность» — наверху наиболее «тематические» слова, т.е. те, которые в этом тексте встречаются чаще, чем в усредненном корпусе английских текстов.
«Имена собственные» — можно убирать слова, которые инструмент считает именами.
«Сложнее — проще — ползунок для выбора уровня знания лексики, отсекает простые слова.
Универсального рецепта настройки ползунков нет, нужный список достигается экспериментами (набор перестраивается на лету).
pkivalin
24.10.2016 17:49Сервис лежит? Не реагирует на кнопку «проанализировать текст».
Ну и пока сам не могу проверить, вопрос — умеет убирать лишний мусор из файлов субтитров (.srt)? Таймштампы, цвет и прочую метаинформацию?EvgeniyKuvshinov
24.10.2016 18:39У меня тоже не работает сервис. А почистить субтитры можно через текстовый редактор, например sublime, используя замену по вот такой регулярке:
(^[0-9,:\->\s]*\n|<.+?>)
на пустую строку. Может быть не совсем точно, но почти везде сработает.
Ontaelio
24.10.2016 18:44Да, к сожалению, сервер прилег. Сейчас чиним. Приносим извинения за временные неудобства.
(и просим отнестись с пониманием — все-таки это внутренний инструмент, изначально предназначенный для одного-двух пользователей. Неделю его готовили к открытию для Хабра, но где-то что-то недотестили)
Что касается вопроса — то в рабочем состоянии он лишние символы пропускает, титры должны проходить.
Temurson
24.10.2016 21:59Просто отличный инструмент! Обязательно буду пользоваться, большое вам спасибо. Простите за оффтоп, но не знает ли кто-нибудь что-то подобное для немецкого языка? С английским у меня уже и так все в порядке, учу немецкий, но ужасно надоедает искать незнакомые слова в фильмах и книгах и выписывать их. Заранее спасибо.

molec
25.10.2016 06:44Вы же понимаете, с немецким просто не будет. Учитывая «крокодилов» — длинные составные слова, сервис под него будет сделать непросто. Регулярная ситуация для немецкого — два корня в слове знаешь, а третий нет.Вероятность того, что это же составное слово встретится еще раз — минимальна. Зато узнать этот злосчастный корешок было бы интересно.
xwild
25.10.2016 05:17Давно ждал когда кто-нибудь сделает нормальный сервис для этого. Сам составлял колоды anki для слов которые надоедало смотреть в словаре, как будет приложение на android обязательно попробую. Кстати, почему до сих пор первым делают приложение для ios? Вроде android это 80% рынка уже.
protasov_a
25.10.2016 06:42Android опережает iOS по загрузкам в два раза, а iOS почти настолько же обгоняет Android по доходам. (с) По этой причине приложение на iOS зачастую делать просто выгоднее.
iridiumhawk
25.10.2016 06:43С точки зрения анализа, инструмент интересный. Но с практической позиции, когда нужен результат, то есть общение на английском, то никакие словари не приблизят вас к этому. На себе проверено, выучивание отдельных слов, без контекста их использования, бесполезно, а иногда и вредно. Много глагольных конструкций, и очень много многозначных слов. Кучу разных словарей использовал, и оффлайн и онлайн. Только чуть. Самый лучший результат дает слушание английской речи, например подкастов, или просмотр фильмов/сериалов, с последующим изучением слов, которые были не понятны. Тогда они привязываются к контексту употребления и закрепляются хорошо.
Ontaelio
25.10.2016 09:11Для последующего изучения слов надо обладать крепкой волей (фильм-то уже отсмотрен, а книга — прочитана). В нашем случае речь идет о предварительном изучении слов, которые во время просмотра кино/чтения книги надо будет вспомнить в контексте. Это хорошая тренировка, к тому же приятная.
iridiumhawk
25.10.2016 10:49Ну вы согласны, что есть многозначные слова? Есть фразовые глаголы. Вот мы имеем список слов, которые нужно предварительно выучить. Какое значение слова учить?
На практике я использовал Lingualeo.ru, мне очень не понравилось, там в процессе изучения слова используется одно значение, без контекста, ты что-то запоминаешь, а потом когда это слово встречается в английском тексте, ты не можешь понять смысла, потому-что используется другое значение, которое ты не запоминал. И значит время потраченное на запоминание этого слова было потрачено впустую.
Обязательно нужно учить сразу все значения слова, а для этого необходимо при запоминании использовать контекст (примеры), в которых значения слова различны.

Destiner
25.10.2016 06:43Добрый день. Я недавно делал похожий инструмент для исследования того, насколько изучение таких слов помогает понять текст. И результаты меня не обрадовали: даже 50-100 слов (включая имена собственные, что вообще неправильно, а без них получилось бы ещё меньше) дали в моём локальном корпусе всего лишь 3-5% понимания. Для корпуса брал один сезон сериала.
В связи с этим вопрос: рассчитывали ли вы, сколько примерно процентов понимания текста даёт заучивание слов из генерируемого списка? И ещё, учитывали ли вы различные формы одного и того же слова (например, fight и fought, potato и potatoes)?Ontaelio
25.10.2016 09:02Формы — да, разумеется.
Процент понимания — сильно зависит от сферы применения инструмента. Если это профессиональные тексты, где очень высока тематичность слов, то результат отличный. В случае художественной литературы — зависит от уровня ученика, здесь нет универсальной формулы. В любом случае, ясно, что это инструмент для расширения словарного запаса, а не создания его с нуля, т.е. базовая лексика учится не здесь. Если брать не всю книгу, а отдельные главы, то выдача получается довольно полезная.
dnovik01
25.10.2016 08:26Хороший инструмент! Думаю, что он будет наиболее полезен для людей уже знающих язык, приницип построения предложений и желающих пополнить словарный запас.

SoraMusoka
26.10.2016 13:56Ontaelio
Отличный инструмент! Можете открыть свой API, для не коммерческих целей? В частности хотелось бы изменить дизайн инструмента и добавить улучшения, такие как:
— интеграция с личным словарем (Google/Abby/etc)
— возможность исключить/скрыть слова, из личного словаря
— сортировку по колонкам таблицы
— загрузку файлов (например субтитров)
и др
mngr
Не могли бы вы более подробно описать настройки генератора и на что они влияют?