

Хорошая новость в том, что интересные задачи окружают нас повсюду. Сильное желание и смелость творят чудеса на пути к цели — задача любого масштаба станет вам под силу, стоит просто начать её делать.
Недавно мы написали синтаксический анализатор языка запросов 1С и его транслятор в обычный SQL. Это позволило нам выполнять запросы к 1С без участия 1С :) Минимальная рабочая версия на regexp-ах получилась недели за две. Ещё месяц ушёл на полноценный парсер через грамматики, разгребание нюансов структуры БД разных 1С-объектов и реализацию специфических операторов и функций. В результате решение поддерживает практически все конструкции языка, исходный код выложен на GitHub.
Под катом мы расскажем, зачем нам это понадобилось, как удалось, а так же затронем несколько интересных технических подробностей.
С чего всё началось?
Мы работаем в крупной бухгалтерской компании Кнопка. У нас обслуживается 1005 клиентов, работают 75 бухгалтеров и 11 разработчиков. Наши бухгалтеры ведут учёт тысячи клиентских баз в системе
 Самый сложный этап в работе бухгалтера — это отчётность. Казалось бы, 1С умеет готовить любую отчётность, но для этого ей необходимо актуальное состояние базы. Кто-то должен завести в систему все первичные документы, импортировать банковскую выписку, создать и провести необходимые учётные документы. При этом сроки сдачи отчётности в нашем любимом государстве строго ограничены, поэтому бухгалтеры обычно живут от одного бессонного цейтнота до другого.
Самый сложный этап в работе бухгалтера — это отчётность. Казалось бы, 1С умеет готовить любую отчётность, но для этого ей необходимо актуальное состояние базы. Кто-то должен завести в систему все первичные документы, импортировать банковскую выписку, создать и провести необходимые учётные документы. При этом сроки сдачи отчётности в нашем любимом государстве строго ограничены, поэтому бухгалтеры обычно живут от одного бессонного цейтнота до другого.Мы задумались: как можно облегчить бухгалтерам жизнь?
Оказалось, что много проблем с отчётностью возникает из-за мелких ошибок в бухгалтерской базе:
- дубликаты контрагента или договора;
- дубликаты первичных документов;
- контрагент без ИНН;
- документ с датой из далёкого прошлого или будущего.
 Перечисленные проблемы легко найти с помощью языка запросов 1С, поэтому появилась идея сделать автоматизированный аудит клиентских баз. Мы написали несколько запросов и стали выполнять их каждую ночь на всех базах 1С. Найденные проблемы мы показывали бухгалтерам в удобной гугло-табличке, и всячески призывали к тому, чтобы табличка оставалась пустой.
Перечисленные проблемы легко найти с помощью языка запросов 1С, поэтому появилась идея сделать автоматизированный аудит клиентских баз. Мы написали несколько запросов и стали выполнять их каждую ночь на всех базах 1С. Найденные проблемы мы показывали бухгалтерам в удобной гугло-табличке, и всячески призывали к тому, чтобы табличка оставалась пустой.Выполнять эти запросы через стандартное COM апи 1С — не лучшая идея. Во-первых, это долго — обойти тысячу баз и запустить на каждой из них все запросы занимает 10 часов. Во-вторых, это существенно нагружает сервер 1С, которому обычно и так несладко живётся. Неприятно ради аудита замедлять текущую ежедневную работу людей.
Между тем, типичный запрос 1С выглядит так:
select
doc.Дата as Date,
doc.Номер as Number,
doc.Организация.ИНН as Inn,
doc.Контрагент.ИНН as CounterpartyInn,
Представление(doc.Контрагент.ЮридическоеФизическоеЛицо) as CounterpartyType,
doc.НазначениеПлатежа as Description,
doc.СуммаДокумента as Sum
from Документ.ПоступлениеНаРасчетныйСчет doc
where
not doc.ДоговорКонтрагента.ПометкаУдаления
and doc.Проведен
and doc.видоперации = Значение(Перечисление.ВидыОперацийПоступлениеДенежныхСредств.ОплатаПокупателя)
and ГОД(doc.Дата) = ГОД(&Now)
Несмотря на то, что это очень похоже на SQL, такую штуку не получится просто так взять и запустить напрямую через БД.
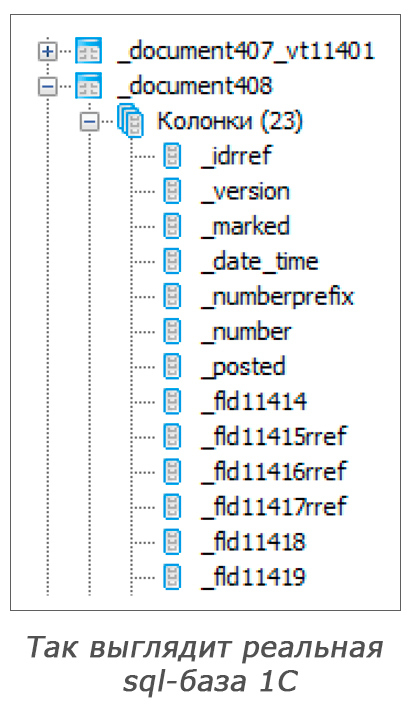 Реальных причин тому три:
Реальных причин тому три:- Магические имена таблиц и колонок в базе. Это легко решается, так как 1С документирует их соответствие именам из запроса.
- Вложенные свойства. Например,
doc.Организация.ИННв SQL соответствуетleft joinдвух табличекДокумент.ПоступлениеНаРасчетныйСчетиСправочник.Организации. - Специфические для 1С операторы и функции, такие как
Значение, Представление и Год. Их тоже нужно дополнительно транслировать в соответствующие конструкции СУБД.
Осознав всё это, мы написали утилиту, которая преобразовывает запрос с диалекта 1С в обычный SQL, запускает его параллельно на всех физических серверах PostgreSQL, результат объединяет и складывает в отдельную таблицу в MS SQL. В результате время сбора данных сократилось с 10 часов до 3 минут.
Регулярные выражения
В первой версии логику преобразования запроса мы реализовали целиком через regexp-ы. В COM апи 1С есть функция ПолучитьСтруктуруХраненияБазыДанных. Она возвращает информацию о том, каким таблицам и полям соответствуют объекты и свойства в 1С запросе. Используя несколько regexp-шаблонов, мы просто заменяли одни имена на другие. Этого удалось довольно легко достичь при условии, что все обращения к объектам и свойствам имели псевдонимы.
Больше всего хлопот доставили вложенные свойства. 1С хранит их в связанных таблицах, поэтому приходилось исходное имя объекта в конструкции
from заменять на подзапрос, в котором были все нужные left join-ы.select
doc.Контрагент.ИНН
from Документ.ПоступлениеТоваровУслуг doc
-- конвертировалось в
select
doc.gen0
from (select
tContractor.inn gen0
from tDoc
left join tContractor on tDoc.contractorId = tContractor.id) doc
Кроме переименования свойств и генерации left
join-ов, транслятор применял ещё ряд преобразований. Так, например, все join-ы в исходном запросе приходилось снабжать дополнительным условием на равенство поля Область (area). Дело в том, что в одной базе данных PostgreSQL у нас живут несколько клиентских баз 1C, и данные одного клиента от данных другого отличаются специальным идентификатором, который 1С называет областью. В базе 1С создает ряд индексов по умолчанию. Все они первым компонентом ключа имеют область, так как все запросы выполняются в рамках одного клиента. Чтобы наши запросы использовали стандартные индексы, и чтобы не думать об этом при их написании, мы стали добавлять это условие автоматически при трансляции запроса.Использование regexp-ов оказалось верным решением, так как позволило быстро получить конечный результат и понять, что из всей этой затеи получается что-то полезное. Всем советуем proof of concept-ы и эксперименты делать именно так — максимально простыми подручными средствами. А что может быть проще и эффективнее при работе с текстами, чем regexp-ы?
Конечно, есть и недостатки. Первый и очевидный — это срезанные углы и ограничения синтаксиса. Regexp-ы для свойств и таблиц требовали расстановки псевдонимов в запросе и, вообще, могли случайно заматчиться с какой-нибудь другой конструкцией, например, константной строкой.
Другая проблема — смешение логики синтаксического анализа текста и его преобразование по нужным правилам. Каждый раз, реализуя новую фичу, нужно было изобретать и новую адскую смесь regexp-ов с вызовами
IndexOf на строках, которая вычленит соответствующие элементы в исходном запросе.Так, например, выглядел код, который добавлял условие на равенство областей ко всем join-ам:
private string PatchJoin(string joinText, int joinPosition, string alias)
{
var fromPosition = queryText.LastIndexOf("from", joinPosition, StringComparison.OrdinalIgnoreCase);
if (fromPosition < 0)
throw new InvalidOperationException("assertion failure");
var tableMatch = tableNameRegex.Match(queryText, fromPosition);
if (!tableMatch.Success)
throw new InvalidOperationException("assertion failure");
var mainTableAlias = tableMatch.Groups[3].Value;
var mainTableEntity = GetQueryEntity(mainTableAlias);
var joinTableEntity = GetQueryEntity(alias);
var condition = string.Format("{0}.{1} = {2}.{3} and ", mainTableAlias,
mainTableEntity.GetAreaColumnName(), alias, joinTableEntity.GetAreaColumnName());
return joinText + condition;
}
В коде хотелось иметь дело с объектной моделью исходного запроса, с
ColumnReference и JoinClause, а вместо этого были только найденные regexp-ами подстроки и смещения в тексте запроса.Согласитесь, что такой вариант выглядит гораздо проще и понятнее предыдущего:
private void PatchJoin(SelectClause selectClause, JoinClause joinClause)
{
joinClause.Condition = new AndExpression
{
Left = new EqualityExpression
{
Left = new ColumnReferenceExpression
{
Name = PropertyNames.area,
Table = selectClause.Source
},
Right = new ColumnReferenceExpression
{
Name = PropertyNames.area,
Table = joinClause.Source
}
},
Right = joinClause.Condition
};
}
Такая объектная модель называется Abstract syntax tree (AST).
AST
Интересно, что впервые AST у нас появилось не при парсинге исходного запроса, а наоборот, при форматировании результата в SQL. Дело в том, что логика конструирования подзапроса для вложенных свойств становилась довольно витиеватой, и для её упрощения (и в соответствии с SRP) мы разбили весь процесс на два этапа: вначале создаем дерево объектов, описывающих подзапрос, затем отдельно сериализуем его в SQL. В какой-то момент мы осознали, что это и есть AST, и для решения проблем с regexp-ами нужно просто научиться создавать его для исходного запроса.
Термин AST широко используется при обсуждении нюансов синтаксического анализа. Деревом оно называется потому что этой структурой данных хорошо описываются типичные для языков программирования конструкции, обычно обладающие свойством рекурсивности и отсутствия циклов (хотя это и не всегда справедливо).
Для примера рассмотрим такой запрос:
select p.surname as 'person surname'
from persons p
where p.name = 'иван'
В виде AST он выглядит так:

На рисунке узлы — экземпляры классов, стрелочки и подписи — свойства этих классов.
Такую объектную модель можно собрать через код следующим образом:
var table = new TableDeclarationClause
{
Name = "PersonsTable",
Alias = "t"
};
var selectClause = new SelectClause
{
FromExpression = table,
WhereExpression = new EqualityExpression
{
Left = new ColumnReferenceExpression
{
Table = table,
Name = "name"
},
Right = new LiteralExpression
{
Value = "иван"
}
}
};
selectClause.Fields.Add(new SelectFieldExpression
{
Expression = new ColumnReferenceExpression
{
Table = table,
Name = "surname"
}
});
Стоит отметить, что приведённый пример AST не является единственно правильным. Конкретная структура классов и связей между ними определяется спецификой задачи. Основная цель любого AST — облегчить решение задачи, сделать выполнение типичных операций максимально удобным. Поэтому чем оно будет проще и естественнее описывать конструкции искомого языка, тем лучше.
Переход от regexp-ов к AST позволил избавиться от многих хаков, сделать код чище и понятнее. Вместе с тем, теперь наша утилита должна была знать обо всех конструкциях исходного языка, чтобы создать для них соответствующий узел в дереве. Для этого пришлось написать грамматику языка запросов 1С и парсер для неё.
Грамматики
Итак, в какой-то момент стало понятно, что нам нужно AST исходного запроса. В интернете есть много библиотек, которые умеют парсить SQL и создавать AST для него, но при более пристальном взгляде они оказываются либо платными, либо поддерживают лишь подмножество SQL. К тому же не понятно, как их приспособить для распознавания 1С-диалекта SQL, ведь он содержит ряд специфических расширений.
Поэтому мы решили написать свой парсер. Синтаксические анализаторы обычно начинают делать с описания грамматики того языка, который требуется распознать. Формальная грамматика — классический инструмент описания структуры языков программирования. Её основу составляют правила вывода, то есть рекурсивные определения каждой языковой конструкции.
Например, такими правилами можно описать язык арифметических выражений:
E > number | (E) | E + E | E - E | E * E | E / EТакую запись можно читать следующим образом:
- любое число
(number)— это выражение(E); - если выражение заключено в скобки, то всё это, вместе со скобками — тоже выражение;
- два выражения, соединенные арифметической операцией, так же составляют выражение.
Символы, для которых определены правила вывода, называют нетерминалами. Символы, для которых не определены правила, и которые являются элементами языка — терминалами. Применяя правила, из нетерминалов можно получать строки, состоящие из других нетерминалов и терминалов, пока не останутся только терминалы. В примере выше
E — это нетерминал, а символы +, -, *, / и number — терминалы, образующие язык арифметических выражений.Существуют специальные инструменты — генераторы синтаксических анализаторов, которые по описанию языка, заданному в виде грамматики, умеют генерировать распознающий этот язык код. Самые известные из них — это yacc, bison и antlr. Для C# есть менее распространённая библиотека Irony. Про неё уже была небольшая статья на Хабре, а вот пост Скотта Хансельмана про неё.
Основная фишка библиотечки Irony в том, что правила грамматики можно описывать прямо на
C#, используя перегрузку операторов. В итоге получается вполне симпатичный DSL, по форме очень похожий на классическую форму записи правил:var e = new NonTerminal("expression");
var number = new NumberLiteral("number");
e.Rule = e + "+" + e | e + "-" + e | e + "*" + e | e + "/" + e | "(" + e + ")" | number;
Символ | означает, что может применяться любой из вариантов правила (логический or).Символ + — конкатенация, символы должны следовать друг за другом.
Irony разделяет понятия Parse Tree и Abstract Syntax Tree.Parse Tree — это артефакт процесса распознания текста, результат последовательного применения правил грамматики. В его внутренних узлах стоят нетерминалы, а в потомки попадают символы из правых частей соответствующих правил.
Например, выражению
1+(2+3) при применении правил:e1: E > E + E
e2: E > (E)
e3: E > number
соответствует такое Parse Tree:

Parse Tree не зависят от конкретного языка и в Irony описываются одним классом
ParseTreeNode.Abstract Syntax Tree наоборот, целиком определяется конкретной задачей, и состоит из специфичных для этой задачи классов и связей между ними.
Например, AST для грамматики выше может состоять всего из одного класса
BinaryOperator:public enum OperatorType
{
Plus,
Minus,
Mul,
Div
}
public class BinaryOperator
{
public object Left { get; set; }
public object Right { get; set; }
public OperatorType Type { get; set; }
}
Свойства
Left и Right имеют тип object, т.к. они могут ссылаться либо на число, либо на другой BinaryOperator:
Irony позволяет создать AST последовательно, поднимаясь от листьев к корню, одновременно с применением правил грамматики. Для этого на каждый нетерминал можно навесить делегат
AstNodeCreator, который Irony вызовет в момент применения любого из сопоставленных этому нетерминалу правил. Этот делегат должен на основе переданного ParseTreeNode создать соответствующий ему узел AST и положить ссылку на него обратно в ParseTreeNode. К моменту вызова делегата все дочерние узлы Parse Tree уже обработаны и AstNodeCreator для них уже был вызван, поэтому в теле делегата мы можем пользоваться уже заполненным свойством AstNode дочерних узлов.Когда мы таким образом доходим до корневого нетерминала, в его
AstNode образуется корневой узел AST, в нашем случае — SqlQuery. Для грамматики арифметических выражений выше AstNodeCreator может выглядеть так:
var e = new NonTerminal("expression",
delegate(AstContext context, ParseTreeNode node)
{
//соответствует правилу E > number,
if (node.ChildNodes.Count == 1)
{
node.AstNode = node.ChildNodes[0].Token.Value;
return;
}
//правила вида E > E op E
if (node.ChildNodes[0].AstNode != null && node.ChildNodes[2].AstNode != null)
{
node.AstNode = new BinaryOperator
{
Left = node.ChildNodes[0].AstNode,
Operator = node.ChildNodes[1].FindTokenAndGetText(),
Right = node.ChildNodes[2].AstNode
};
return;
}
//правило со скобками
node.AstNode = node.ChildNodes[1].AstNode;
});
Итак, с помощью Irony мы научились конструировать AST по исходному запросу. Остался лишь один большой вопрос — как эффективно структурировать код для преобразования AST, ведь в конечном счете из исходного AST нам нужно получить AST результирующего SQL запроса. В этом нам поможет паттерн Visitor.
Visitor
Паттерн Visitor (или double dispatch) — один из самых сложных в GoF и, возможно поэтому, один из самых редко используемых. За свой опыт мы видели только одно активное его применение — для преобразования различных AST. Конкретный пример — это класс ExpressionVisitor в .NET, который неизбежно возникает, когда делаешь linq provider или просто хочешь немного подправить генерируемые компилятором expression tree.
Какую проблему решают visitor-ы?
Самая естественная и необходимая вещь, которую часто приходится делать при работе с AST — это превращать его в строку. Возьмем к примеру наш AST: после замены русских имён таблиц на английские, генерации
left join-ов и преобразования 1С-операторов в операторы БД, на выходе нам нужно получить строку, которую мы сможем отдать на выполнение в PostgreSQL.Возможный вариант решения этой задачи таков:
internal class SelectClause : ISqlElement
{
//...
public void BuildSql(StringBuilder target)
{
target.Append("select ");
for (var i = 0; i < Fields.Count; i++)
{
if (i != 0)
target.Append(",");
Fields[i].BuildSql(target);
}
target.Append("\r\nfrom ");
From.BuildSql(target);
foreach (var c in JoinClauses)
{
target.Append("\r\n");
c.BuildSql(target);
}
}
}
Про этот код можно сделать два важных наблюдения:
- все узлы дерева должны иметь метод
BuildSql, чтобы рекурсия работала; - метод
BuildSqlнаSelectClauseперевызываетBuildSqlна всех дочерних узлах.
Теперь рассмотрим другую задачу. Допустим нам нужно добавить условие на равенство поля
area между основной таблицей и всеми приджойненными, чтобы попадать в индексы PostgreSQL. Для этого нам нужно пробежаться по всем JoinClause в запросе, но, учитывая возможные подзапросы, нам нужно не забыть заглянуть и во все остальные узлы.Это означает, что если следовать той же структуре кода, что и выше, то мы должны будем:
- добавить метод
AddAreaToJoinClauseво все узлы дерева; - его реализации на всех узлах, кроме
JoinClause, должны будут пробросить вызов своим потомкам.
Проблема с этим подходом ясна — чем больше у нас будет различных логических операций над деревом, тем больше будет методов в узлах, и тем больше копипаста между этими методами.
Visitor-ы решают эту проблему за счёт следующего:
- Логические операции перестают быть методами на узлах, а становятся отдельными объектами — наследниками абстрактного класса
SqlVisitor(см. рисунок ниже). - Каждому типу узла соответствует отдельный метод
Visitв базовомSqlVisitor-е, например,VisitSelectClause(SelectClause clause)илиVisitJoinClause(JoinClause clause). - Методы
BuildSqlиAddAreaToJoinClauseзаменяются на один общий методAccept. - Каждый узел реализует его путем проброса на соответствующий метод на
SqlVisitor-е, который приходит параметром. - Конкретные операции наследуются от
SqlVisitorи переопределяют только те методы, которые им интересны. - Реализации методов
Visitв базовомSqlVisitor-епросто перевызываютVisitдля всех дочерних узлов, за счёт этого устраняется дублирование кода.
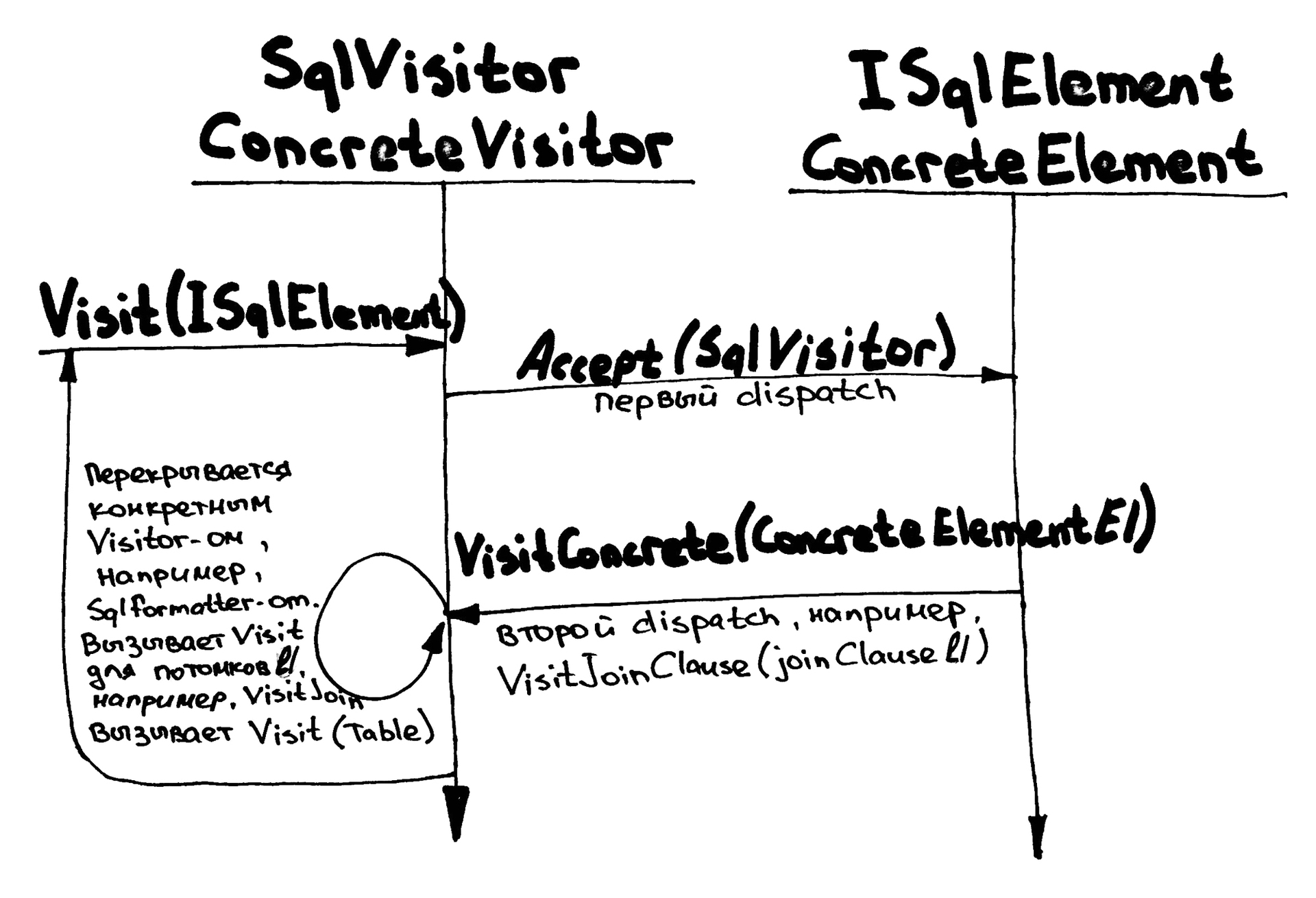
Пример с сериализацией в SQL адаптируется следующим образом:
internal interface ISqlElement
{
void Accept(SqlVisitor visitor);
}
internal class SqlVisitor
{
public virtual void Visit(ISqlElement sqlElement)
{
sqlElement.Accept(this);
}
public virtual void VisitSelectClause(SelectClause selectClause)
{
}
//...
}
internal class SqlFormatter : SqlVisitor
{
private readonly StringBuilder target = new StringBuilder();
public override void VisitSelectClause(SelectClause selectClause)
{
target.Append("select ");
for (var i = 0; i < selectClause.Fields.Count; i++)
{
if (i != 0)
target.Append(",");
Visit(selectClause.Fields[i]);
}
target.Append("\r\nfrom ");
Visit(selectClause.Source);
foreach (var c in selectClause.JoinClauses)
{
target.Append("\r\n");
Visit(c);
}
}
}
internal class SelectClause : ISqlElement
{
//...
public void Accept(SqlVisitor visitor)
{
visitor.VisitSelectClause(this);
}
}
Название double dispatch вполне точно описывает эту схему:
- Первый dispatch происходит в классе
SqlVisitorпри переходе отVisitкAcceptна конкретном узле, в этот момент становится известен тип узла. - Второй dispatch следует за первым при переходе от
Acceptна узле к конкретному методу наSqlVisitor, здесь становится известна операция, которую нужно применить к выбранному узлу.
Итого
В статье подробно описан рецепт приготовления транслятора языка запросов 1С в запросы SQL. Мы прошли через эксперименты с регулярными выражениями, получив работающий прототип и подтверждение того, что штука полезная и стоит двигаться дальше. И когда на код стало невозможно смотреть без стыда и боли, а жонглирование с regexp-ами не приводило к нужному результату, мы сделали серьёзный шаг — перешли к AST и грамматикам. Далее с помощью visitor-ов мы научились преобразовывать AST, реализуя тем самым логику перевода с одного языка на другой.
Стоит отметить, что этот путь мы не проходили в одиночку, и даже не пришлось открывать Dragon Book. Для синтаксического анализа и построения AST мы использовали готовую библиотеку Irony, которая позволила не изобретать велосипед, а сразу перейти к решению прикладной задачи.
Практический результат для компании заключается в сокращении скорости получения данных с 10 часов до 3 минут. Это позволило нашим аналитикам быстро ставить эксперименты и проверять гипотезы о бизнесе клиентов и работе бухгалтеров. Это особенно удобно, так как клиентов у нас много, а их базы распределены между пятью физическими серверами PostgreSQL.
Резюмируя всё вышесказанное:
- Ставьте эксперименты и получайте proof of concept максимально быстро и дешево.
- Ставьте амбициозные цели, и двигайтесь к ним маленькими шагами, постепенно дотачивая инструмент до нужного состояния.
- Для большинства задач уже есть готовое решение, или хотя бы фундамент.
- Синтаксический анализ и грамматики применимы в обычных бизнес-приложениях.
- Решайте конкретную задачу, а общее решение придёт само.
Код бибилиотеки и примеры использования ждут вас на GitHub.
На досуге советуем почитать:
Комментарии (29)

vpozdnyakov
01.11.2016 11:21спасибо большое за статью, хотелось бы уточнить
специальным идентификатором, который 1С называет областью
вы имеете в виду «разделители»?gusev_p
01.11.2016 11:30Да, в конфигурации «1С: Бухгалтерия» есть специальный общий реквизит «ОбластьДанныхОсновныеДанные», который выступает таким универсальным разделителем. Это просто целочисленный идентификатор, 1С автоматически подставляет его для всех использующих объектов.

fishca
01.11.2016 15:15Разделитель

gusev_p
01.11.2016 15:24Да, вы правы, мы сейчас это не учитываем. Мы даже не учитываем, используется ли «ОбластьДанныхОсновныеДанные» конкретным объектом, и добавляем условие на равенство областей вообще ко всем джойнам в исходном запросе. Учитывать это не сложно, просто потребность не возникала.
fishca
01.11.2016 15:37-1Еще, может конечно не по теме, но все таки спрошу, как обстоят дела с соблюдением
Лицензии ?

movemind
01.11.2016 15:49Мы ничего не делаем, что перечислено в п. 65 и не строим решение на платформе 1С: Предприятие. Мы просто читаем данные из базы PostgreSQL, восстановленной из бэкапа, находящейся вне платформы 1С.
fishca
01.11.2016 16:40Т.е. у вас схема работы:
1. Рабочая база отдельно, в ней работают пользователи в 1С Предприятии в «обычном интерфейсе» через клиента 1С
2. Создаете копию рабочей базы средствами SQL и к ней формируете прямые запросы.
В компанию 1С обращались с вопросом правомерности использования такого варианта работы?fishca
01.11.2016 16:48-11С не приветствует сторонний доступ к своим данным

evgeny_kobzev
02.11.2016 09:52Да, мы не хотим вмешиваться в работу 1С и её дестабилизировать, это совершенно не в наших интересах.
В компанию 1С не обращались, потому что нам не кажется, что мы что-то нарушаем, зачем уточнять то, в чем ты уверен :slightly_smiling_face:fishca
02.11.2016 14:58В компанию 1С не обращались, потому что нам не кажется, что мы что-то нарушаем, зачем уточнять то, в чем ты уверен
Я бы не был так уверен.
1. Вы обращаетесь к базе 1С через СОМ-коннектор — это правомерное использование, которое должно быть обеспечено лицензией — к этому вопросов вообще нет.
2. А вот после того как вы сходили в базу 1С, у вас наступает как бы «амнезия», и вы начинаете говорить что вы идете с помощью запросов не в базу 1С, а в какаю-то другую.
Либо я тогда не понял вашу схему работы, либо есть какое-то лукавство.evgeny_kobzev
02.11.2016 20:06Процитирую статью комментарии к который мы с вами пишем: «Выполнять эти запросы через стандартное COM апи 1С — не лучшая идея. Во-первых, это долго — обойти тысячу баз и запустить на каждой из них все запросы занимает 10 часов. Во-вторых, это существенно нагружает сервер 1С, которому обычно и так несладко живётся. Неприятно ради аудита замедлять текущую ежедневную работу людей.» Мы не используем com коннекторы, хотя пользуемся ими для других задач.
И следующая цитата:
«Осознав всё это, мы написали утилиту, которая преобразовывает запрос с диалекта 1С в обычный SQL, запускает его параллельно на всех физических серверах PostgreSQL, результат объединяет и складывает в отдельную таблицу в MS SQL. В результате время сбора данных сократилось с 10 часов до 3 минут.»
Вот эту вторую штуку мы делаем на базе, к которой 1с вообще не ходит, восстановленной из бэкапа и развёрнутой сбоку. В чем лукавство и амнезия?fishca
02.11.2016 23:02преобразовывает запрос с диалекта 1С в обычный SQL, запускает его параллельно на всех физических серверах PostgreSQL
1. Получается Вы обращаетесь к данным базы 1С
результат объединяет и складывает в отдельную таблицу в MS SQL
2. Т.е. вы данные периодически в этой отдельной базе обновляете читая опять же данные базы 1С.
Пока у меня складывается ощущение что этим действиями нарушается п. 65, а именно:
"Это ограничение распространяется на любые действия с данными, в том числе на изменение их структуры, а так же на чтение или изменение самих данных информационной базы или служебных данных «1С: Предприятия»."
Darth_Malok
01.11.2016 15:26Хм… а не проще ли выполнить запрос на языке 1с в консоли запросов и посмотреть через sql profiler что передаёт сервер-1с sql-серверу? Можно даже автоматизировать это всё, наверное.
Имхо, это намного проще, чем учитывать все нюансы работы регистров, общих реквизитов и т.д.fishca
01.11.2016 15:31Предлагаете написать запускатор запросов всех комбинаций и вылавливатель их в профайлере?
gusev_p
01.11.2016 15:37Не знаю, может и проще. Все равно пришлось бы патчить запрос, хотя бы чтобы он по нужным нам областям работал, а не только по одной. Ну и от 1С зависимость: запрос меняется — нужно 1С дергать, а подключение к нему через COM — процесс очень не быстрый.
movemind
01.11.2016 15:39В этом случае придётся запрофилировать запрос для каждой области данных, то есть 1000 профилирований сделать для каждого запроса, это кажется утомительным.

alexey-lustin
02.11.2016 01:25+3Вначале призову EvilBeaver — самый сок в статье это AST запросов. Нужно посмотреть можно ли учитывая MIT лицензию портировать AST в oscript.io
Теперь что касается архитектурного решение — коллеги из Кнопки. Очень опасное решение — в том числе из-за непрозрачности лицензионной чистоты.
Но тут даже не это — доступ через COM.v83, сразу ограничивает нас:
- Windows окружением — для вызывающего контекст запроса
- Зависимостью от comctrl.dll — который возможен только одной версии на хосте вызывающем подобный запрос.
Но это еще полбеды — дело в том что LinqFor1C в 1С мире является вотчиной Elisy https://habrahabr.ru/post/210654/, можно было и не писать свой.
Но и это еще не все.
Смотрите какая интересная составляющая:
вы указываете что у вас множество клиентских баз — а это не совсем так в реальности: это одна СУБД, только с "computed by" полем. Как раз тот самый разделитель данных который так любят во Fresh
второе — вы говорите что у вас были проблемы с незаполненными реквизитами и качеством первичных данных, но текущий патерн реализации следующий
использовать расширение конфигурации — можно посмотреть как это сделано у Евгении Карук http://infostart.ru/public/426393/
- ИНН и дубликаты контрагентов — также уже принято использовать 1С: Контрагент для актуальности данных https://portal.1c.ru/applications/3
и все это делать не в режиме патерна внешней проверки "раз в месяц", а в условном онлайне, то есть "по событию", кстати учитывая что вроде как у вас БП 3.0 — то можно использовать создание "задач", для бухгалтера — что является штатным механизмом "Проверь дубли", "Исправь дубли" и т.д.
Ну в окончании — если все таки нужно было сделать именно внешним сервисом: то лучше смотреть в сторону Metadata.js — https://github.com/oknosoft/metadata.js
Что касается вообще подобных архитектурных решений: зачем понадобилось именно делать предрасчетную реплику в MSSQL если используется PostgreSQL? Почему тогда хотя бы не остаться в том же стэке СУБД ?
И последнее — вот эти пресловутые 10 часов в исходной задаче? А что это за запрос был такой который делал аудит 10 часов ?
Ну и совсем последнее — так уж получилось, что есть еще одно интересное решение http://www.vanessa-sharp.ru/index.html — мы на него наткнулись когда случайно вдруг выяснилось что у нас 1С ассоциируется с бабочками семейства Vanessa, а у некоторых с скрипачками
Магические имена таблиц и колонок в базе.
Этот волшебный метод — согласно рекомендациям 1С, необходимо использовать для написания алгоритмов 1С в части средств мониторинга и просмотра, а не для создания инструментов прямого доступа к данным.
Я все это написал к тому — что у меня такое впечатление, что решение принималось, без учета текущих реалий в мире 1С. Может стоило в начале обсудить? Хотя бы в Gitter'е oscript https://gitter.im/EvilBeaver/OneScript
gusev_p
02.11.2016 09:56+1Спасибо за комментарий! По пунктам:
COM.v83 и windows-окружение. Для нас это не проблема, т.к. основное приложение у нас на .net и все равно нужны виндовые машины. Про comctrl.dll честно говоря не понял проблему, если речь про то, что на одной машине через него можно ходить только в одну версию платформы, то это как раз то, что нам нужно. Уточню, все эти нюансы относятся только к процедуре выкачивания метаданных из 1С, для выпонения запросов 1С не нужен.
Про другие Linq-провайдеры. Я смотрел на те из них, на которые есть ссылки со странички на github-е. Мне хотелось легкий и невербозный дизайн, бесплатность и open source. В них я этого не нашел. Возможно я пропустил какие-то другие решения.
У нас 5 физических баз PostgreSQL, на каждой из которых крутится около двухсот баз 1С, данные разводятся действительно стандартным разделителем «ОбластьДанныхОсновныеДанные». Не очень понял, какой от сюда вывод, Fresh умеет запускать запросы на всех клиентских базах?
Про задачи для бухгалтера — интересно, но нам в первую очередь нужно средство мониторинга, чтобы каждый день на скраме видеть, у каких бухгалтеров где проблемы. С задачами нам пришлось бы незакрытые задачи импортировать из каждой 1С-ной базы в нашу общую базу. Кроме того, если появляется новый вид проверки нам нужно будет как-то быстро добавить его во все наши тысячу баз. Это возможно сделать эффективно?
Metadata.js — смотрели, но у нас есть отдельное приложение на .net, которое помимо интеграции с 1С еще много полезной бизнес-логики крутит, так что в 1С ходить удобнее прямо из него.
MSSQL — там у нас лежит разная статистика из всевозможных источников, не только 1С, просто исторически так сложилось.
Про 10 часов в исходной задаче. Это суммарное время прогона всех запросов, реализующих наши проверки, на каждой из тысячи баз. По большей части там всевозможные хитрые проверки на дубликаты разных сущностей — контрагентов, договоров, документов.
Рекомендации 1С это одно, а реальная жизнь — немного другое. Вполне допускаю, что мы не знали про какие-то уже готовые решения, когда начинали делать эту штуку. Я вот, например, вообще c 1С первый раз связался пол года назад :) Поэтому спасибо вам за полезные ссылки и наводки. Тем не менее, проблемы нужно как-то решать, и у нашего подхода есть свои плюсы. Мы можем, например, очень быстро проверять гипотезы о бизнесе клиента, находить паттерны в данных и как-то реагировать на них.
evgeny_kobzev
02.11.2016 10:00Vanessa вообще классная, особенно раздел http://www.vanessa-sharp.ru/reference-linq.html

EvilBeaver
02.11.2016 14:54alexey-lustin, AST запросов обнаружил, спасибо. MIT, насколько я знаю, позволяет утаскивать к себе, но надо будет еще подробнее поглядеть.
fishca
02.11.2016 15:01использовать расширение конфигурации — можно посмотреть как это сделано у Евгении Карук http://infostart.ru/public/426393/
Не нашел в профиле ни одной публикации связанной с расширением, может речь идет про доклад на infostart event?
Bonart
Sprache для прототипов использовать не пробовали?
Выигрывает у регулярок во всем кроме скорости парсинга. И тяжелый парсер потом не факт, что вообще понадобится.
gusev_p
Не знал про эту библиотеку. Посмотрел бегло, судя по примерам, вроде это какая-то надстройка над regexp-ами? Там можно для не регулярных языков обычные грамматики писать?
gusev_p
все, разобрался с parser combinator-ами, выглядит клево, да
Bonart
Я использовал Sprache для реализации статического анализа формул. Получилось шикарно, новый функционал добавлялся без изменения кода и поведения для старого.
С регулярками очень быстро получалась write-only каша без малейших признаков композабельности.