
Intel SR-IOV
Не совсем технология от Intel, но пощупать удалось только их реализацию. Вкратце, физический адаптер (PF) делится на несколько виртуальных (VF). Трафик внутри одного vlan по умолчанию не выходит за границы PF, и обеспечивает наиболее минимальные задержки по сравнению с виртуальными адаптерами на софтовых бриджах.
С помощью использования Intel FlowDirector в принципе можно изменить поведение и указать правила по которым трафик должен ходить между VF или наружу из PF. Также можно сделать ручное распределение трафика по RX очередям или хардварный дроп трафика сразу при входе на карту. Поддержка конфигурации flow есть в драйверах, но отдельного api конкретно для Flow Director я не нашел. Кто хочет поиграться — можно покопаться в исходниках ethtool, либо использовать Intel DPDK, в нем API реализован, но карта отцепляется от kernel драйвера со всеми вытекающими.
С моей точки зрения, эти технологии в основном для админов, которым просто надо снизить задержки при передаче трафика между виртуальными машинами.
Плюсы: работа как в VMWare, так и KVM. Везде быстрее софтовых бриджей как по задержкам, так и пропусной способности. И CPU не жрет.
Минусы: виртуальный свитч в данном кейсе — нужно превращать в реальный на отдельном железе, куда втыкаются PF от сервера с виртуальными машинами.
И 64 VF на один PF сейчас достаточно мало.
Intel DPDK
Про данный development kit на хабре уже были статьи, поэтому особо распространятся не буду. Но в контесте виртуальных машин, информации довольно мало. Я разберу основные способы использования Intel DPDK в случае если требуется передать трафик между физическим адаптером и виртуальным. Данная технология для нас является основной, так как мы делаем Openflow свитч.
Ну и дальше под виртуальной машиной я подразумеваю KVM c DPDK приложением внутри, так как на гипервизор VMWare особо не поставишь ничего, а внутри виртуальной машины VMWare выбора особо нет, e1000 или vmxnet3. Я советую vmxnet3.
Intel порадовал нас следующими возможностями
Способ 1: Pain
Технически представляет из себя один из двух. Можно подцепить свой виртуальный свитч через TAP, а в качестве виртуального адаптера использовать e1000, и если внутри VM DPDK приложение — цеплятся к нему через igb pmd.
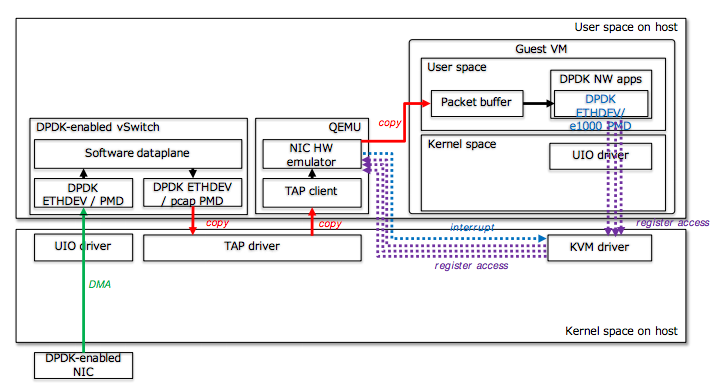
Можно подцепить свой виртуальный свитч через TAP, а в качестве виртуального адаптера использовать virtio-net, и если внутри VM DPDK приложение — цеплятся к нему через virtio pmd.
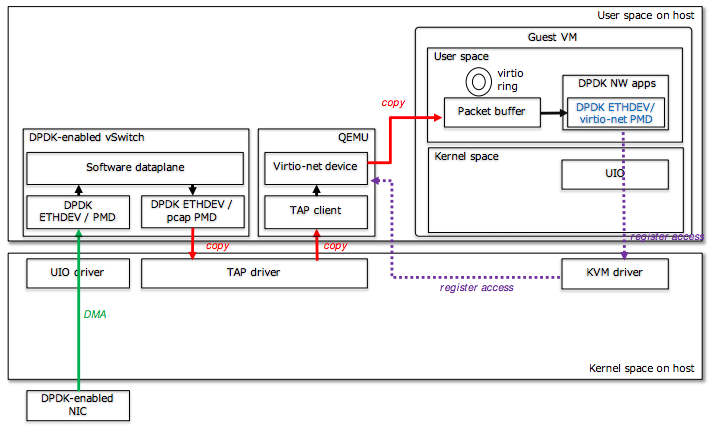
Плюсы этих методов: простота, работает как с DPDK приложениями, так и с обычными.
Минусы: производительность просто боль, много копирований, много переходов внутри виртуальной машины и context switching.
Способ 2: Fast & Furios
Можно подцепить свой виртуальный свитч через IVSHMEM (в Qemu раньше надо было патчить, сейчас вроде влито), а в качестве виртуального адаптера создавать специализированный адаптер DPDK Ring, который является наиболее быстрым IPC механизмом между DPDK приложениями.

Плюсы: лучшая производительность
Минусы: только DPDK приложения
Способ 3: One size fits all
Можно подцепить свой виртуальный свитч через vhost-user API, а в качестве виртуального адаптера использовать virtio-net.

Плюсы: работает как с DPDK приложениями, так и с обычными, производительность хорошая (но хуже способа 2, в случае если внутри VM DPDK приложение)
Минусы: в основном связаны с линк статусами и прочими обвязками, решаемы
Способ 4: Arcane
Intel DPDK также предлагает способ — создание KNI устройства. В двух словах есть отдельный kernel модуль, который организует soft rx/tx очереди, создает виртуальный адаптер с этими очередями и обеспечивает копирование из skb_buf в mbuf и обратно, эмулируя работу сети.
Мы до сих пор его исследуем, пока окончательных результатов нет.
Но уже известны:
Плюсы: можно скомбинировать с DPDK ring, для legacy создавать KNI, для DPDK оставлять ring. Можно создать KNI поверх физической карты.
Минусы: как то не очень едет, CPU жрет тоннами и особых бенефитов не видно.
Но мы работаем над этим.
Will keep you posted.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (9)

Loxmatiymamont
23.11.2016 13:44>>Я советую vmxnet3
К сожалению, под рукой нет конкретных фактов и примеров, но со времён 5.5 вывел для себя золотой алгоритм:
— в машине дурит сеть?
— удали vmxnet, поставь E1000e
— 90% проблема самоустранится
Отсюда вопрос — исходя из чего рекомендация?
drwatson32
23.11.2016 14:46+2Как я написал в начале, я рассматривал с позиции написания DPDK приложения.
Основные бенефиты vmxnet3:
1) multiqueue
2) использование shared memory вместо VMexit-VMentry
Первое за счет RSS может скейлить обработку по ядрам,
второе за счет уменьшения количества VMexit экономит по 600 циклов за выход.
По тестам у vmxnet3 на 97% меньше частота VMexit-VMentry.
С точки зрения традиционных приложений, я за e1000.
navion
23.11.2016 16:00КМК, сами разработчики e1000 толком не тестируют, так как во всех рекомендациях указан vmxnet3. Иначе не объяснить PSOD хоста из-за бага с e1000.

voidnugget
23.11.2016 23:05Слишком мало конкретики — пробуйте профилировать и получать flame graph'ы.
drwatson32
24.11.2016 00:04Я постарался на схемах показать основные потери performance по результатам профилирования. Вам интересно конкретно скриншоты профилировщика?
voidnugget
24.11.2016 01:10Интересуют конкретные цифры.
То что там будет Overhead из-за копирования — и ежу понятно.
Профилятор — профилятору рознь. Надо понимать что есть multisample profiling, есть monitoring gap и прочие нюансы.
Было бы просто замечательно прогнать это всё в афинном окружении (numactl/taskset) на изолированных ядрах, да отрисовать flame graph'ы. Даже банального ptrace хватило бы.
Были бы цифры и графики для каждого из вариантов — было бы понятно конкретно что и сколько времени выполняется.drwatson32
24.11.2016 09:05Ок. Я посмотрю, остались ли у нас репорты, и приложу.
По поводу афинного окружения, тесты выполнялись на хосте, в котором через isolcpu было оставлено только одно ядро ОС, irqbalance выключен, VM и DPDK свитч на разных ядрах, все в рамках одной нумы, память тоже выделялась в рамках одной нумы.
A-Stahl
>траффик
https://ru.wikipedia.org/wiki/%D0%A2%D1%80%D0%B0%D1%84%D0%B8%D0%BA
Я вас поймаю в тёмном корридоре оффисного здания и расстреляю из твоего табельного граммар-шмайссера.
drwatson32
Извините, издержки професcии: https://en.wikipedia.org/wiki/Network_traffic.
Спасибо, поправил.