

Пожалуй, будет достаточно справедливо сказать, что JavaScript — самая важная современная технология в разработке программного обеспечения. Для многих из тех, кто изучал языки программирования, компиляторы и виртуальные машины, всё ещё удивителен тот факт, что при всей своей элегантности с точки зрения структуры языка JavaScript не слишком хорошо оптимизируем с точки зрения компилирования и не может похвастаться замечательной стандартной библиотекой. В зависимости от того, кто ваш собеседник, вы можете неделями перечислять недоработки в JavaScript и всё равно обнаружите какую-то странность, о которой ещё не слышали. Но несмотря на очевидные недостатки, сегодня JavaScript является ключевой технологией в вебе, идет к доминированию в серверной/облачной сфере (благодаря Node.js), а также проникает в интернет вещей.
Возникает вопрос — почему JavaScript так популярен? Боюсь, у меня нет исчерпывающего ответа. Сегодня есть много причин для использования этого языка, важнейшими из которых, вероятно, являются огромная экосистема, выстроенная вокруг JavaScript, и несметное количество ресурсов. Но всё это в известной мере следствия. А почему же изначально язык стал популярен? Вы можете сказать: потому что долгое время он был лингва франка для веба. Но это было очень давно, и разработчики страстно ненавидели JavaScript. Если оглянуться назад, то рост популярности JavaScript начался во второй половине 2000-х. Как раз в те времена движки JavaScript начали гораздо быстрее работать с различными нагрузками, что, вероятно, повлияло на отношение многих к этому языку.
В те годы для измерения скорости применялись так называемые традиционные JavaScript-бенчмарки, начиная с Apple SunSpider, прародителя всех JS-микробенчмарков, затем были Mozilla Kraken и Google V8. Позднее гугловский бенчмарк был вытеснен Octane, а Apple выпустила JetStream. Эти традиционные бенчмарки приложили невероятные усилия для выведения производительности JavaScript на такую высоту, какой в начале века никто не ожидал. Отмечались тысячекратные ускорения, и внезапно использование
<script> перестало быть танцем с дьяволом, а выполнение вычислений на клиентской стороне стало не просто возможным, а даже поощряемым. 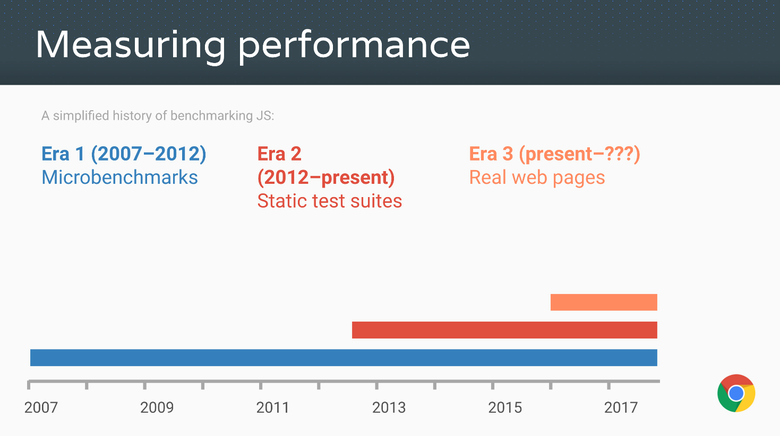
Источник: Advanced JS performance with V8 and Web Assembly, Chrome Developer Summit 2016, @s3ththompson.
В 2016 году все (значимые) JS-движки достигли невероятной производительности, и веб-приложения стали такими же шустрыми, как и нативные (или могут быть такими же шустрыми). Движки поставляются со сложными оптимизированными компиляторами, генерирующими короткие последовательности высокооптимизированного машинного кода. Достигается это за счёт вдумчивого выбора типа/формы (type/shape) для каждой операции (доступ к свойствам, двоичные операции, сравнения, вызовы и так далее) в зависимости от имеющейся статистики по различным типам/формам. Большинство этих оптимизаций диктовались микробенчмарками наподобие SunSpider и Kraken, а также статистическими пакетами вроде Octane и JetStream. Благодаря основанным на JavaScript технологиям вроде asm.js и Emscripten сегодня можно компилировать в JavaScript большие С++-приложения и выполнять их в браузере безо всякого скачивания и установки. Например, вы без труда прямо из коробки поиграете по сети в AngryBots, в то время как раньше для этого требовались специальные плагины вроде Adobe Flash или Chrome PNaCl.
Подавляющее большинство всех этих достижений стало возможным благодаря наличию микробенчмарков и пакетов измерения производительности, а также конкуренции, возникшей между традиционными JS-бенчмарками. Можете что угодно говорить о SunSpider, но очевидно, что без него производительность JavaScript вряд ли была бы такой, как сегодня.
Но довольно восхвалений, пришла пора взглянуть на обратную сторону монеты. Все измерительные тесты — будь то микробенчмарки или большие пакеты — обречены со временем становиться неактуальными! Почему? Потому что бенчмарк может вас чему-то научить только до тех пор, пока вы не начнёте с ним играться. Как только вы превысите (или не превысите) определённый порог, общая применимость оптимизаций, дающих выигрыш для данного бенчмарка, будет экспоненциально уменьшаться.
Например, мы использовали Octane в качестве прокси для измерения производительности реальных веб-приложений. И какое-то время он достаточно хорошо справлялся с этой задачей. Но сегодня распределение времени (distribution of time) в Octane и реальных приложениях сильно различается, поэтому дальнейшая оптимизация Octane вряд ли приведёт к каким-то значимым улучшениям в реальных приложениях (в том числе и для Node.js).

Источник: Real-World JavaScript Performance, конференция BlinkOn 6, @tverwaes.
По мере того как становилось всё более очевидным, что все традиционные бенчмарки для измерения производительности JavaScript, включая самые свежие версии JetStream и Octane, похоже, себя изжили, мы начали искать новые пути измерения реальных приложений, добавив в V8 и Chrome новые перехватчики для профилирования и трассировки. Также мы задействовали средства, позволяющие понять, на что у нас тратится больше времени при просмотре сайтов: на исполнение скрипта, сборку мусора, компилирование и так далее. Результаты исследований оказались очень интересными и неожиданными. Как видно из предыдущей иллюстрации, при запуске Octane более 70 % времени тратится на исполнение JavaScript и сборку мусора, в то время как при просмотре сайтов на JavaScript всегда уходит меньше 30 % времени, а на сборку мусора — не более 5 %. Зато немало времени отнимают парсинг и компилирование, чего не скажешь об Octane. Так что значительные усилия по оптимизации исполнения JavaScript дадут вам хороший прирост попугаев в Octane, но сайты не станут грузиться заметно быстрее. Причём увлечение оптимизацией исполнения JavaScript может даже навредить производительности реальных приложений, потому что на компилирование начнёт уходить больше времени — или вам понадобится отслеживать дополнительные параметры, что удлинит компилирование, IC и Runtime.
Есть ещё один пакет бенчмарков, который пытается измерять общую производительность браузера, включая JavaScript и DOM: Speedometer. Он старается подходить к измерению более реалистично, запуская простое приложение TodoMVC, реализованное на разных популярных веб-фреймворках (на сегодняшний день оно немного устарело, но уже делается новая версия). В пакет включены новые тесты (angular, ember, react, vanilla, flight и backbone). На сегодняшний день Speedometer выглядит наиболее предпочтительным вариантом на роль прокси для измерения производительности реальных приложений. Но обратите внимание, что это данные по состоянию на середину 2016 года, и всё уже могло измениться по мере развития применяемых в вебе паттернов (например, мы рефакторим IC-систему для сильного снижения издержек, а также перепроектируем парсер). Хотя выглядит так, будто вышеописанная ситуация имеет отношение только к просмотру сайтов, мы получили очень убедительное доказательство того, что традиционные бенчмарки пиковой производительности не слишком хорошо подходят на роль прокси и в случае с реальными Node.js-приложениями.
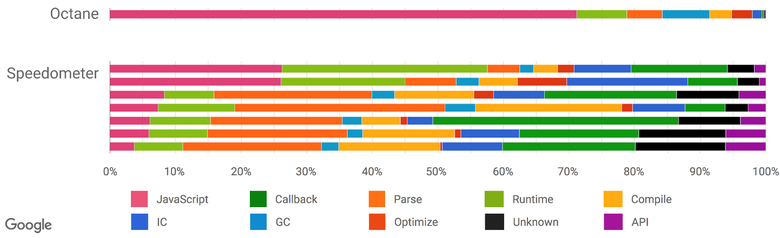
Источник: Real-World JavaScript Performance, конференция BlinkOn 6, @tverwaes.
Возможно, всё это уже известно широкой аудитории, так что дальше я лишь остановлюсь на нескольких конкретных примерах, иллюстрирующих мысль, почему для JS-сообщества не просто полезно, но и критически важно с определённого момента прекратить обращать внимание на статические бенчмарки пиковой производительности. Начну с примеров того, как JS-движки могут проходить бенчмарки и как они это делают на самом деле.
Печально известные примеры с SunSpider
Статья о традиционных JS-бенчмарках была бы неполной без упоминания очевидных проблем SunSpider. Начнём с теста производительности, чья применимость в реальных ситуациях ограничена: bitops-bitwise-and.js.
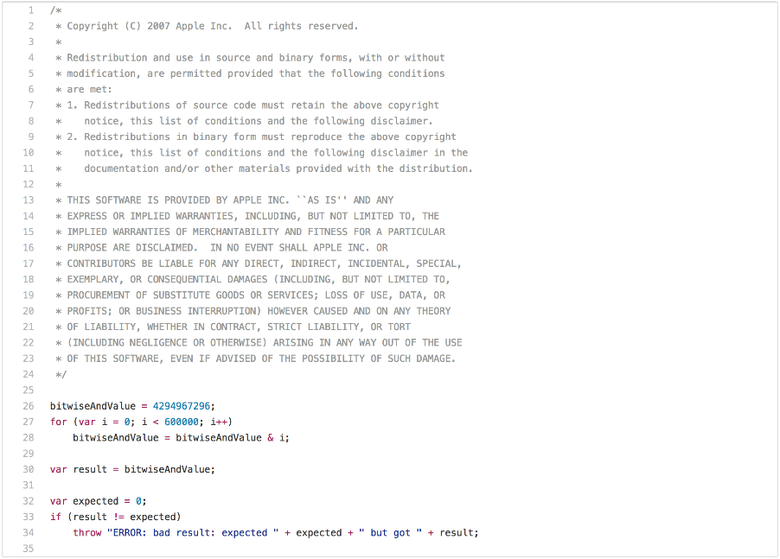
Здесь есть пара алгоритмов, которым требуется быстрая поразрядная операция И (bitwise AND), особенно в коде, транспилированном (transpile) из C/C++ в JavaScript. Однако вряд ли веб-страницам есть дело до того, может ли движок выполнять поразрядную операцию И в цикле вдвое быстрее другого движка. Вероятно, вы заметили, что после первой итерации цикла bitwiseAndValue становится равно 0 и остаётся таковым в течение следующих 599 999 итераций. Так что как только вы прогоните это с хорошей производительностью, то есть быстрее 5 мс на приличном железе, можете начать гонять этот бенчмарк в попытках понять, что нужна только первая итерация этого цикла, а все остальные — просто потеря времени (то есть мёртвый код после расщепления цикла). Для выполнения такого преобразования в JavaScript потребуется проверить:
- является ли
bitwiseAndValueобычным свойством глобального объекта до исполнения скрипта, - чтобы не было перехватчика глобального объекта или его прототипов, и так далее.
Но если вы действительно хотите победить в бенчмарке и ради этого готовы на всё, то можете выполнить тест менее чем за 1 мс. Но применимость оптимизации ограничена лишь этим конкретным случаем, и небольшие изменения теста, вероятно, не приведут к её срабатыванию.
Короче, тест bitops-bitwise-and.js был худшим примером микробенчмарка. Перейдём к более практичному примеру — тесту string-tagcloud.js. По сути, он прогоняет очень раннюю версию полифилла
json.js. Пожалуй, этот тест выглядит куда разумнее предыдущего. Но если внимательнее посмотреть на профиль бенчмарка, то становится очевидно, что он тратит кучу времени на единственное выражение eval (до 20 % общего времени исполнения для парсинга и компилирования и ещё до 10 % для реального исполнения скомпилированного кода):
Посмотрим ещё внимательнее:
eval исполняется лишь один раз и передаётся JSON-строке, содержащей массив из 2501 объекта с полями tag и popularity: ([
{
"tag": "titillation",
"popularity": 4294967296
},
{
"tag": "foamless",
"popularity": 1257718401
},
{
"tag": "snarler",
"popularity": 613166183
},
{
"tag": "multangularness",
"popularity": 368304452
},
{
"tag": "Fesapo unventurous",
"popularity": 248026512
},
{
"tag": "esthesioblast",
"popularity": 179556755
},
{
"tag": "echeneidoid",
"popularity": 136641578
},
{
"tag": "embryoctony",
"popularity": 107852576
},
...
])Очевидно, что будет дорого парсить эти объектные литералы, генерировать нативный код и затем его исполнять. Гораздо дешевле просто парсить входную строку в виде JSON и генерировать соответствующий объектный граф. Чтобы улучшить результаты в бенчмарке, можно попробовать всегда изначально интерпретировать
eval как JSON и реально выполнять парсинг, компилирование и исполнение только в том случае, если не получится прочитать в виде JSON (правда, для пропуска скобок потребуется дополнительная магия). В 2007 году такое не сошло бы даже за плохой хак, ведь ещё не существовало JSON.parse. А к 2017-му это превратилось просто в технический долг в JavaScript-движке, да ещё и потенциально может замедлить использование eval. По сути, обновление бенчмарка до современного JavaScript--- string-tagcloud.js.ORIG 2016-12-14 09:00:52.869887104 +0100
+++ string-tagcloud.js 2016-12-14 09:01:01.033944051 +0100
@@ -198,7 +198,7 @@
replace(/"[^"\\\n\r]*"|true|false|null|-?\d+(?:\.\d*)?(:?[eE][+\-]?\d+)?/g, ']').
replace(/(?:^|:|,)(?:\s*\[)+/g, ''))) {
- j = eval('(' + this + ')');
+ j = JSON.parse(this);
return typeof filter === 'function' ? walk('', j) : j;
}приводит к немедленному повышению производительности: на сегодняшний день runtime для V8 LKGR снижается с 36 до 26 мс, 30-процентное улучшение!
$ node string-tagcloud.js.ORIG
Time (string-tagcloud): 36 ms.
$ node string-tagcloud.js
Time (string-tagcloud): 26 ms.
$ node -v
v8.0.0-pre
$ Это обычная проблема статичных бенчмарков и пакетов тестирования производительности. Сегодня никто не будет всерьёз использовать
eval для парсинга JSON-данных (по причине безопасности, а не только производительности). Вместо этого во всём коде, написанном за последние пять лет, используется JSON.parse. Более того, применение eval для парсинга JSON в production может быть расценено как баг! Так что в этом древнем бенчмарке не учитываются усилия авторов движков по увеличению производительности относительно недавно написанного кода. Вместо этого было бы полезно сделать eval излишне сложным, чтобы получить хороший результат в string-tagcloud.js.Перейдём к другому примеру — 3d-cube.js. Этот бенчмарк выполняет много матричных операций, с которыми даже самые умные компиляторы не могут ничего поделать, кроме как просто исполнить. Бенчмарк тратит много времени на выполнение функции Loop и вызываемых ею функций.

Интересное наблюдение: функции
RotateX, RotateY и RotateZ всегда вызываются с параметром-константой Phi.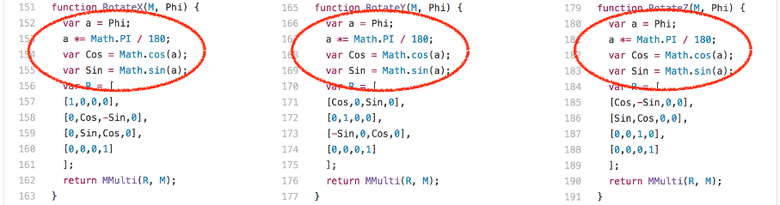
Это означает, что мы всегда вычисляем они и те же значения для Math.sin и Math.cos, каждое по 204 раза. Есть только три разных входных значения:
- 0,017453292519943295
- 0,05235987755982989
- 0,08726646259971647
Чтобы избежать лишних вычислений одних и тех же значений синуса и косинуса, можно кешировать ранее вычисленные значения. Раньше V8 именно это и делал, а все остальные движки делают так до сих пор. Мы убрали из V8 так называемый трансцендентальный кеш, поскольку его избыточность была заметна при реальных нагрузках, когда ты не вычисляешь всегда одни и те же значения в строке. Мы сильно провалились в результатах бенчмарка SunSpider, убрав эту специфическую оптимизацию, но полностью уверены, что не имеет смысла оптимизировать под бенчмарк и в то же время ухудшать результаты на реальных проектах.
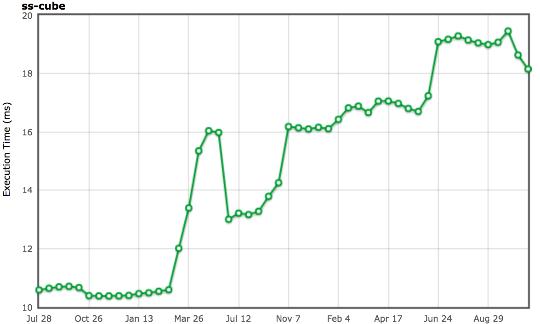
Источник: arewefastyet.com.
Очевидно, что лучший способ работы с такими константами — входными синусом/косинусом — нормальная эвристика замещения вызова (inlining heuristic), которая попытается сбалансировать замещение и учесть разные факторы вроде предпочтения замещения в точках вызова, когда может быть полезна свёртка констант (constant folding) (как в случае с
RotateX, RotateY и RotateZ). Но по ряду причин такое не подходило для компилятора Crankshaft. Зато это разумный вариант в случае с Ignition и TurboFan, и мы уже работаем над улучшением эвристики замещения.Сборка мусора считается вредной
Помимо специфических случаев, у SunSpider есть и другая фундаментальная проблема: общее время исполнения. Сейчас на приличном железе Intel движок V8 прогоняет весь бенчмарк примерно за 200 мс (в зависимости от живых объектов в новом пространстве и фрагментации старого пространства), в то время как основная пауза на сборку мусора легко может достигать 30 мс. И мы ещё не учитываем расходы на инкрементальную маркировку (incremental marking), а это более 10 % общего времени исполнения пакета SunSpider! Так что если движок не хочет замедлиться на 10—20 % из-за сборки мусора, то ему нужно как-то удостовериться, что она не будет инициирована во время выполнения SunSpider.
Для этого используются разные трюки, но все они, насколько мне известно, не оказывают положительного влияния на реальные задачи. V8 поступает просто: поскольку каждый тест SunSpider выполняется в новом
<iframe>, соответствующем новому нативному контексту, то мы просто регистрируем создание и размещение <iframe> (на каждый из тестов SunSpider тратится меньше 50 мс). И тогда сборка мусора выполняется между процедурами размещения и создания, а не во время теста. Эта уловка работает хорошо и в 99,99 % случаев не влияет на реальные проекты. Но если V8 решит, что ваше приложение выглядит как тест SunSpider, то принудительно запустит сборщик мусора, и это негативно отразится на скорости работы. Так что не позволяйте приложению выглядеть как SunSpider!Я мог бы привести и другие примеры, связанные с SunSpider, но не думаю, что это будет полезно. Надеюсь, вам уже ясно, что оптимизировать под SunSpider ради того, чтобы превзойти результаты хорошей производительности, не имеет смысла для реальных приложений. Думаю, мир выиграл бы от того, если бы SunSpider больше вообще не было, потому что движки могут применять странные хаки, полезные только для этого пакета и способные навредить в реальных ситуациях.
К сожалению, SunSpider всё ещё очень активно используется в прессе при сравнении того, что журналисты считают производительностью браузеров. Или, что ещё хуже, для сравнения смартфонов! Конечно, тут проявляется и интерес производителей. Лагерю Android важно, чтобы Chrome показывал хорошие результаты на SunSpider (и прочих ныне бессмысленных бенчмарках). Производителям смартфонов нужно зарабатывать, продавая свою продукцию, а для этого требуются хорошие обзоры. Некоторые компании даже поставляют в смартфонах старые версии V8, показывающие более высокие результаты в SunSpider. А в результате пользователи получают незакрытые дыры в безопасности, которые уже давно были пофиксены в более поздних версиях. Причём старые версии V8 по факту работают медленнее!
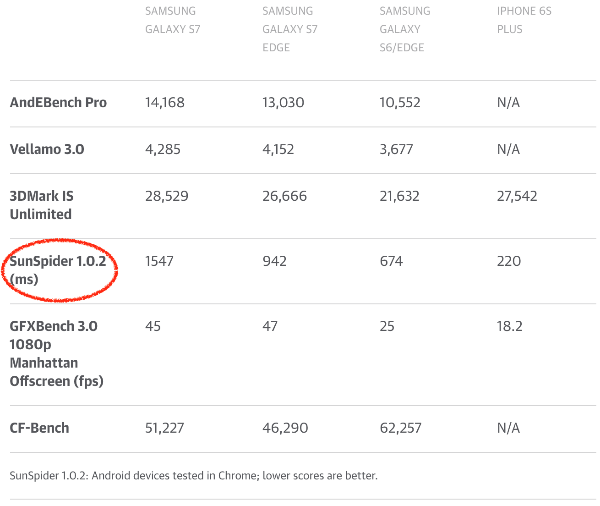
Источник: Galaxy S7 and S7 Edge review: Samsung’s finest get more polished, www.engadget.com.
Если JavaScript-сообщество действительно заинтересовано в получении объективных данных о производительности, то нам нужно заставить журналистов перестать использовать традиционные бенчмарки при сравнении браузеров и смартфонов. Я понимаю, что проще запустить бенчмарк в каждом браузере и сравнить полученные числа, но в таком случае — пожалуйста-пожалуйста! — обратите внимание на бенчмарки, которые хоть как-то соответствуют современному положению дел. То есть реальным веб-страницам. Если вам нужно сравнить два смартфона через браузерный бенчмарк, возьмите хотя бы Speedometer.
Менее очевидная ситуация с Kraken
Бенчмарк Kraken был выпущен Mozilla в сентябре 2010-го. Заявлялось, что он содержит фрагменты кода и ядра реальных приложений. Я не стану уделять Kraken слишком много времени, потому что он не оказал такого влияния на производительность JavaScript, как SunSpider и Octane. Опишу лишь пример с тестом audio-oscillator.js.

Тест 500 раз вызывает функцию
calcOsc. Она сначала вызывает generate применительно к глобалу sine Oscillator, затем создаёт новый Oscillator, вызывает применительно к нему generate и добавляет к sine Oscillator. Не углубляясь в детали, почему здесь так делается, давайте рассмотрим метод generate в прототипе Oscillator.
Глядя на код, можно предположить, что основную часть времени занимают доступы к массивам, или умножения, или циклические вызовы Math.round. Но на самом деле в runtime
Oscillator.prototype.generate доминирует выражение offset % this.waveTableLength. Если запустить бенчмарк в профайлере на любой Intel-машине, то окажется, что более 20 % процессорных циклов тратятся на инструкцию idiv, которая генерируется для модуля (modulus). Интересное наблюдение: поле waveTableLength экземпляра Oscillator всегда содержит значение 2048, единожды присвоенное в конструкторе Oscillator.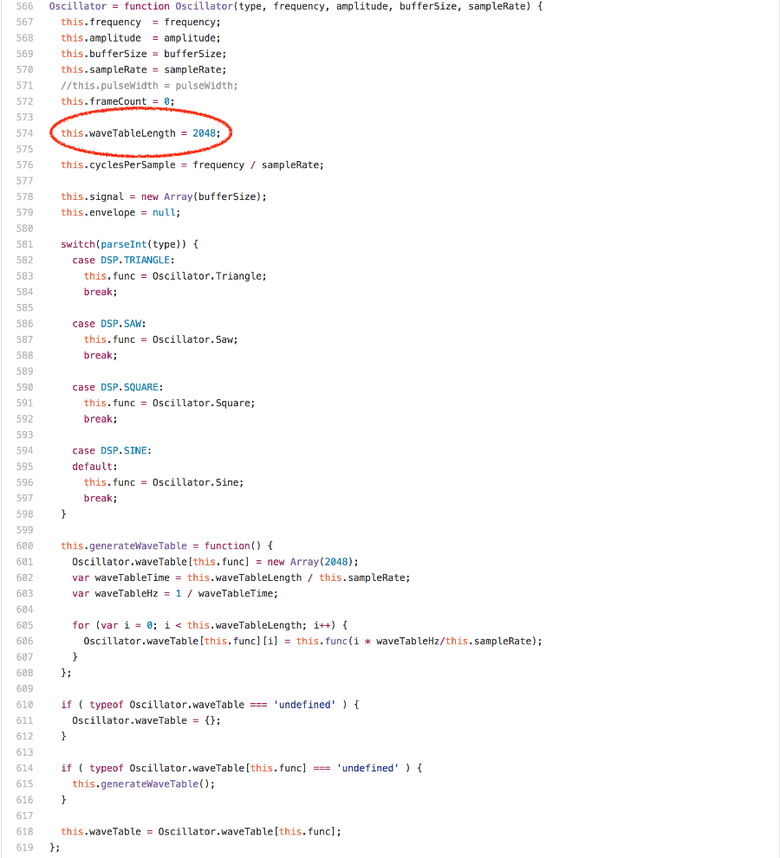
Если мы знаем, что правая часть операции целочисленного модуля — это степень двойки, то мы можем сгенерировать куда лучший код и полностью избежать на Intel инструкции
idiv. Можно попробовать положиться на замещение вызова всего в функции calcOsc и позволить подстановке констант исключить загрузку/хранение. Но это сработает для sine Oscillator, помещённой вне функции calcOsc.Итак, мы добавили поддержку отслеживания значений определённых констант в качестве ответной реакции правой части оператора модуля. В V8 это имеет какой-то смысл, поскольку мы изучаем тип обратной связи для двоичных операций вроде
+, * и %, то есть оператор отслеживает типы входных данных, которые он видит, и типы полученных выходных данных (см. слайды с круглого стола Fast arithmetic for dynamic languages). Было достаточно легко внедрить этот механизм в fullcodegen и Crankshaft, а
BinaryOpIC для MOD также может проверять известную степень двойки для правой части. Запуск дефолтной конфигурации V8 (c Crankshaft и fullcodegen)$ ~/Projects/v8/out/Release/d8 --trace-ic audio-oscillator.js
[...SNIP...]
[BinaryOpIC(MOD:None*None->None) => (MOD:Smi*2048->Smi) @ ~Oscillator.generate+598 at audio-oscillator.js:697]
[...SNIP...]
$ демонстрирует, что
BinaryOpIC выбирает нужную обратную связь по константе (constant feedback) для правой части модуля, а также корректно отслеживает, чтобы левая часть всегда представляла собой маленькое целое число (Smi в V8), и чтобы мы всегда получали маленький целочисленный результат. Если посмотреть на сгенерированный с помощью --print-opt-code --code-comments код, то становится понятно, что Crankshaft использует обратную связь для создания эффективной кодовой последовательности для целочисленного модуля в Oscillator.prototype.generate: [...SNIP...]
;;; <@80,#84> load-named-field
0x133a0bdacc4a 330 8b4343 movl rax,[rbx+0x43]
;;; <@83,#86> compare-numeric-and-branch
0x133a0bdacc4d 333 3d00080000 cmp rax,0x800
0x133a0bdacc52 338 0f85ff000000 jnz 599 (0x133a0bdacd57)
[...SNIP...]
;;; <@90,#94> mod-by-power-of-2-i
0x133a0bdacc5b 347 4585db testl r11,r11
0x133a0bdacc5e 350 790f jns 367 (0x133a0bdacc6f)
0x133a0bdacc60 352 41f7db negl r11
0x133a0bdacc63 355 4181e3ff070000 andl r11,0x7ff
0x133a0bdacc6a 362 41f7db negl r11
0x133a0bdacc6d 365 eb07 jmp 374 (0x133a0bdacc76)
0x133a0bdacc6f 367 4181e3ff070000 andl r11,0x7ff
[...SNIP...]
;;; <@127,#88> deoptimize
0x133a0bdacd57 599 e81273cdff call 0x133a0ba8406e
[...SNIP...]Итак, мы загружаем значение
this.waveTableLength (rbx содержит ссылку this), проверяем, чтобы оно было равно 2048 (десятичное 0x800). Если равно, то вместо использования функции idiv мы просто выполняем поразрядную операцию И с соответствующей битовой маской (r11 содержит значение начинающей цикл переменной i), уделяя внимание сохранению знака левой части. Проблема избыточной специализации
Это классная уловка, но, как и в случае со многими уловками, предназначенными для получения хороших результатов в бенчмарках, тут есть одна главная проблема: избыточная специализация! Как только правая часть изменится, весь оптимизированный код должен быть деоптимизирован (больше неверно предположение, что правая сторона всегда представляет собой определённую степень двойки). Никакие последующие оптимизации не должны снова использовать
idiv, поскольку в этом случае BinaryOpIC наверняка зарепортит фидбек в форму Smi*Smi->Smi. Предположим, что мы создали ещё один экземпляр Oscillator, настроили на него другой waveTableLength и применили generate. Тогда будет потеряно 20 % производительности, хотя мы не влияли на действительно интересные Oscillator‘ы; то есть движок здесь налагает нелокальный штраф (non-local penalization). --- audio-oscillator.js.ORIG 2016-12-15 22:01:43.897033156 +0100
+++ audio-oscillator.js 2016-12-15 22:02:26.397326067 +0100
@@ -1931,6 +1931,10 @@
var frequency = 344.53;
var sine = new Oscillator(Oscillator.Sine, frequency, 1, bufferSize, sampleRate);
+var unused = new Oscillator(Oscillator.Sine, frequency, 1, bufferSize, sampleRate);
+unused.waveTableLength = 1024;
+unused.generate();
+
var calcOsc = function() {
sine.generate();Если сравнить время исполнения оригинального
audio-oscillator.js и версии, содержащей дополнительный неиспользуемый экземпляр Oscillator с модифицированным waveTableLength, получим ожидаемые результаты:$ ~/Projects/v8/out/Release/d8 audio-oscillator.js.ORIG
Time (audio-oscillator-once): 64 ms.
$ ~/Projects/v8/out/Release/d8 audio-oscillator.js
Time (audio-oscillator-once): 81 ms.
$ Это пример ужасного падения производительности. Допустим, разработчик пишет код для библиотеки, осторожно настраивает и оптимизирует использование определённых входных значений, в результате получая приличную производительность. Потребитель обращается к библиотеке, но производительность оказывается гораздо ниже, потому что использует он её чуть иначе. Например, каким-то образом испортив обратную связь о типе для какого-то
BinaryOpIC, он получил 20-процентное замедление работы (по сравнению с результатами, полученными автором библиотеки). И причину замедления не могут объяснить ни автор, ни пользователь, это выглядит непонятной случайностью.Сегодня такое не редкость в мире JavaScript. Пары подобных снижений производительности просто нельзя избежать, поскольку их причина в том, что производительность JavaScript основана на оптимистичных предположениях и спекуляциях. Мы потратили кучу времени и сил, пытаясь придумать способы избежать подобных падений, и до сих пор имеем (почти) такую же производительность. Похоже, стоит при любой возможности избегать
idiv, даже если вы не знаете, что правая часть всегда равна степени двойки (посредством динамической обратной связи). TurboFan, в отличие от Crankshaft, во время runtime всегда проверяет, равен ли входной параметр степени двойки, поэтому в общем случае код для целочисленного модуля со знаком и с оптимизацией правой части в виде (неизвестной) степени двойки выглядит так (псевдокод):if 0 < rhs then
msk = rhs - 1
if rhs & msk != 0 then
lhs % rhs
else
if lhs < 0 then
-(-lhs & msk)
else
lhs & msk
else
if rhs < -1 then
lhs % rhs
else
zeroЭто даёт нам гораздо более устойчивую и предсказуемую производительность (с TurboFan):
$ ~/Projects/v8/out/Release/d8 --turbo audio-oscillator.js.ORIG
Time (audio-oscillator-once): 69 ms.
$ ~/Projects/v8/out/Release/d8 --turbo audio-oscillator.js
Time (audio-oscillator-once): 69 ms.
$ Проблема с бенчмарками и избыточной специализацией заключается в том, что бенчмарк может подсказывать вам, куда смотреть и что делать, но не ответит, как далеко нужно зайти, и не защитит вашу оптимизацию. Например, все JS-движки используют бенчмарки для защиты от снижения производительности, но запуск Kraken не позволит нам защититься при общем подходе, используемом в TurboFan. То есть мы можем деградировать оптимизацию модуля в TurboFan до сверхспециализированной версии Crankshaft, и бенчмарк не сообщит нам о регрессе, потому что, с его точки зрения, всё прекрасно! Теперь вы можете расширить бенчмарк, предположим, в том же ключе, в каком я сделал выше, и попытаться всё покрыть бенчмарками. Именно это в определённой степени делают и разработчики движков. Но такой подход нельзя произвольно масштабировать. Даже если бенчмарки удобны и просты в использовании, нельзя забывать и о здравом смысле, иначе всё поглотит избыточная специализация, и от падения производительности вас будет отделять очень тонкая граница.
С тестами Kraken есть ряд других проблем, но давайте перейдём к наиболее влиятельному JS-бенчмарку за последние пять лет — Octane.
Взглянем на Octane повнимательнее
Бенчмарк Octane — это наследник бенчмарка V8. Он был анонсирован Google в середине 2012 года, а текущая версия Octane 2.0 — в конце 2013-го. В этой версии содержится 15 отдельных тестов, для двух из которых — Splay и Mandreel — мы измерили пропускную способность (throughput) и задержку. Для этого мы прогнали ряд задач, включая компилирование самого себя компилятором Microsofts TypeScript, чистое измерение производительности asm.js с помощью теста zlib, лучевую трассировку (ray tracer), двумерный физический движок и так далее. Подробности по каждому бенчмарку можете узнать из описания. Все эти задачи обдуманно выбрали для демонстрации определённых аспектов производительности JavaScript, которые считались важными в 2012 году или должны были обрести значение в ближайшем будущем.
По большому счёту, Octane прекрасно справился со своими целями и вывел производительность JavaScript на новый уровень в 2012—2013-м. Но за прошедшие годы мир очень изменился. Особенно сильно на полезность Octane влияет устарелость большинства тестов в пакете (например, древние версии TypeScript и zlib скомпилированы с помощью древней версии Emscripten, а Mandreel теперь и вовсе недоступен).
Мы наблюдали большое соперничество между фреймворками в вебе, особенно между Ember и AngularJS, использующими шаблоны исполнения JavaScript, которые вообще не отражены в Octane и зачастую страдают от (наших) специфических оптимизаций. Также мы наблюдали победу JavaScript на серверном и инструментальном фронтах, в результате которой масштабные JS-приложения зачастую работают в течение многих недель, если не лет, и это тоже никак не отражено в Octane. Как говорилось в начале, у нас есть серьёзные свидетельства того, что исполнение и профилирование памяти в Octane полностью отличается от текущего состояния дел в вебе.
Давайте посмотрим на конкретные примеры работы с Octane, чьи оптимизации больше не соответствуют современным задачам. Звучит несколько негативно, но на самом деле это не так! Как я уже упоминал пару раз, Octane — важная глава в истории производительности JavaScript, он сыграл очень заметную роль. Все оптимизации, внедрённые в JS-движки благодаря этому пакету бенчмарков, внедрялись с хорошей уверенностью в том, что Octane — хороший прокси для измерения производительности реальных приложений! У каждого времени свой бенчмарк, и для любого бенчмарка наступает момент, когда его нужно отпустить!
Рассмотрим тест Box2D, основанный на Box2DWeb, популярном двумерном физическом движке, портированном на JavaScript. Здесь выполняется большое количество вычислений с плавающей запятой, под которые в JS-движках внедрено много хороших оптимизаций. Но этот тест, судя по всему, содержит баг, и он может использоваться для некоторой манипуляции (я вставил в свой пример соответствующий эксплойт). В бенчмарке есть функция
D.prototype.UpdatePairs (деминифицировано):D.prototype.UpdatePairs = function(b) {
var e = this;
var f = e.m_pairCount = 0,
m;
for (f = 0; f < e.m_moveBuffer.length; ++f) {
m = e.m_moveBuffer[f];
var r = e.m_tree.GetFatAABB(m);
e.m_tree.Query(function(t) {
if (t == m) return true;
if (e.m_pairCount == e.m_pairBuffer.length) e.m_pairBuffer[e.m_pairCount] = new O;
var x = e.m_pairBuffer[e.m_pairCount];
x.proxyA = t < m ? t : m;
x.proxyB = t >= m ? t : m;
++e.m_pairCount;
return true
},
r)
}
for (f = e.m_moveBuffer.length = 0; f < e.m_pairCount;) {
r = e.m_pairBuffer[f];
var s = e.m_tree.GetUserData(r.proxyA),
v = e.m_tree.GetUserData(r.proxyB);
b(s, v);
for (++f; f < e.m_pairCount;) {
s = e.m_pairBuffer[f];
if (s.proxyA != r.proxyA || s.proxyB != r.proxyB) break;
++f
}
}
};Профилирование показывает, что много времени тратится на выполнение невинно выглядящей внутренней функции, передаваемой в первом цикле
e.m_tree.Query:function(t) {
if (t == m) return true;
if (e.m_pairCount == e.m_pairBuffer.length) e.m_pairBuffer[e.m_pairCount] = new O;
var x = e.m_pairBuffer[e.m_pairCount];
x.proxyA = t < m ? t : m;
x.proxyB = t >= m ? t : m;
++e.m_pairCount;
return true
}Точнее, время тратится не на саму функцию, а на запускаемые ею операции и функции встроенной библиотеки. 4—7 % общего времени исполнения уходит на вызов бенчмарка в runtime-функции Compare, который реализует общий случай абстрактного относительного сравнения (abstract relational comparison).
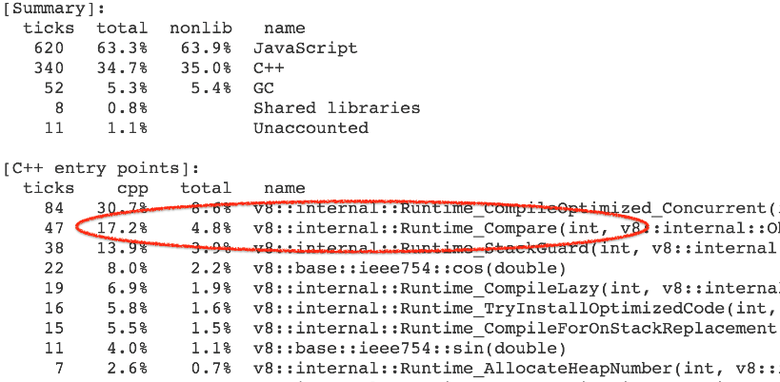
Почти все вызовы runtime-функции идут из CompareICStub, используемого для двух относительных сравнений во внутренней функции:
x.proxyA = t < m ? t : m;
x.proxyB = t >= m ? t : m;То есть на эти две безобидные строки приходится 99 % времени выполнения функции! Как так? Ну, как и многие другие вещи в JavaScript, абстрактное относительное сравнение не всегда используется интуитивно правильно. В нашей функции
t и m — всегда экземпляры L, центрального класса приложения. Но при этом не переопределяются свойства Symbol.toPrimitive, "toString", "valueOf" и Symbol.toStringTag, относящиеся к абстрактному относительному сравнению. Если написать t < m, то:- Вызывается ToPrimitive(
t,hint Number). - Запускается OrdinaryToPrimitive(
t,"number"), потому что нетSymbol.toPrimitive. - Исполняется
t.valueOf(), в результате получим самоt, поскольку вызывается дефолтная Object.prototype.valueOf. - Затем идёт
t.toString(), в результате получим"[object Object]", потому что используется дефолтная Object.prototype.toString, а Symbol.toStringTag дляLне обнаружена. - Вызывается ToPrimitive(
m,hint Number). - Запускается OrdinaryToPrimitive(
m,"number"), потому что нет Symbol.toPrimitive. - Исполняется
m.valueOf(), в результате получим само m, поскольку вызывается дефолтная Object.prototype.valueOf. - Затем идёт
m.toString(), в результате получим"[object Object]", потому что используется дефолтная Object.prototype.toString, а Symbol.toStringTag дляLне обнаружена. - Выполняется сравнение
"[object Object]" < "[object Object]", в результате получим
То же самое и при
t >= m, только в конце всегда будем получать true. Баг в том, что нет смысла делать абстрактное относительное сравнение таким образом. Суть эксплойта: можно заставить компилятор выполнить свёртку констант, то есть применить к бенчмарку подобный патч:--- octane-box2d.js.ORIG 2016-12-16 07:28:58.442977631 +0100
+++ octane-box2d.js 2016-12-16 07:29:05.615028272 +0100
@@ -2021,8 +2021,8 @@
if (t == m) return true;
if (e.m_pairCount == e.m_pairBuffer.length) e.m_pairBuffer[e.m_pairCount] = new O;
var x = e.m_pairBuffer[e.m_pairCount];
- x.proxyA = t < m ? t : m;
- x.proxyB = t >= m ? t : m;
+ x.proxyA = m;
+ x.proxyB = t;
++e.m_pairCount;
return true
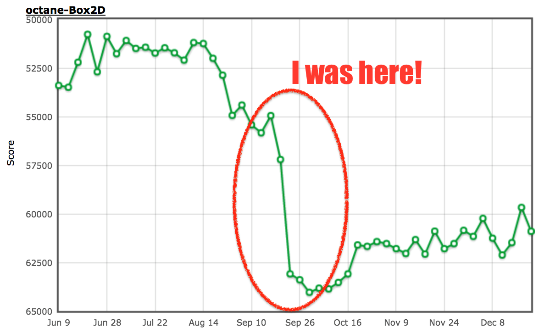
},Это позволит увеличить результат на 13 %, отказавшись от сравнения всех запускаемых им поисков и вызовов встроенной функции:
$ ~/Projects/v8/out/Release/d8 octane-box2d.js.ORIG
Score (Box2D): 48063
$ ~/Projects/v8/out/Release/d8 octane-box2d.js
Score (Box2D): 55359
$Как мы это сделали? Похоже, у нас уже был механизм отслеживания формы объектов, которые сравниваются в
CompareIC: так называемое отслеживание отображения (map) известного получателя (known receiver map tracking) (в терминологии V8 map — это форма + прототип объекта). Но этот механизм применялся только в абстрактных сравнениях и сравнениях на строгое равенство. Однако я легко могу использовать отслеживание и для получения обратной связи для абстрактного относительного сравнения:$ ~/Projects/v8/out/Release/d8 --trace-ic octane-box2d.js
[...SNIP...]
[CompareIC in ~+557 at octane-box2d.js:2024 ((UNINITIALIZED+UNINITIALIZED=UNINITIALIZED)->(RECEIVER+RECEIVER=KNOWN_RECEIVER))#LT @ 0x1d5a860493a1]
[CompareIC in ~+649 at octane-box2d.js:2025 ((UNINITIALIZED+UNINITIALIZED=UNINITIALIZED)->(RECEIVER+RECEIVER=KNOWN_RECEIVER))#GTE @ 0x1d5a860496e1]
[...SNIP...]
$ Используемое в базовом коде
CompareIC говорит нам, что для выполняемых в нашей функции сравнений «менее чем» и «больше либо равно» видит только RECEIVER’ы (JavaScript-объекты в терминологии V8). И все эти получатели имеют одно и то же отображение (map) 0x1d5a860493a1, соответствующее отображению экземпляров L. В оптимизированном коде для этих операций мы можем выполнить свёртку констант до false и true соответственно, потому что мы знаем: обе части сравнения — экземпляры с отображением 0x1d5a860493a1. Никто не вмешается в цепочку прототипов L, то есть по умолчанию используются методы the Symbol.toPrimitive, "valueOf" и "toString". Также никто не задаст свойство аксессора Symbol.toStringTag. Дальше в Crankshaft творится чёрная магия с большим количеством проклятий и изначально непроверенным Symbol.toStringTag:
В конце получаем огромный прирост в производительности для конкретного бенчмарка:
В свою защиту хочу сказать: я не был уверен в том, что такое поведение всегда говорит о баге в исходном коде. Я даже предполагал, что в реальных условиях такое может происходить довольно часто, к тому же мне казалось, что JS-разработчики не всегда обращают внимание на подобные потенциальные баги. Но я ошибался, и признаю свою ошибку! Должен признать, что данная оптимизация относится исключительно к бенчмарку и никак не поможет в реальном коде (если только он не создан с учётом этой оптимизации, но тогда можно прямо написать
true или false, а не использовать относительное сравнение констант). Вероятно, вам интересно, почему вскоре после моего патча была отмечена небольшая регрессия. Как раз тогда мы бросили всю команду на внедрение ES2015, и пришлось немало попотеть, чтобы сделать это без серьёзных провалов в традиционных бенчмарках (ES2015 — настоящий монстр!).Перейдём к бенчмарку Mandreel. Это был компилятор для преобразования кода C/C++ в JavaScript. Он не использовал подмножество asm.js, в отличие от более раннего компилятора Emscripten, и примерно три года назад был объявлен устаревшим (примерно с тех пор вообще исчез из интернета). Однако Octane ещё содержит версию физического движка Bullet, скомпилированного с помощью Mandreel. Нас заинтересовал тест MandreelLatency, благодаря которому бенчмарк может выполнять частые измерения времени. Идея в том, что Mandreel воздействует на компилятор виртуальной машины, а тест показывает получившуюся задержку. Чем длиннее паузы между измерениями, тем ниже балл. В теории всё звучит неплохо, и так оно и есть на самом деле. Но вендоры придумали, как обмануть бенчмарк.
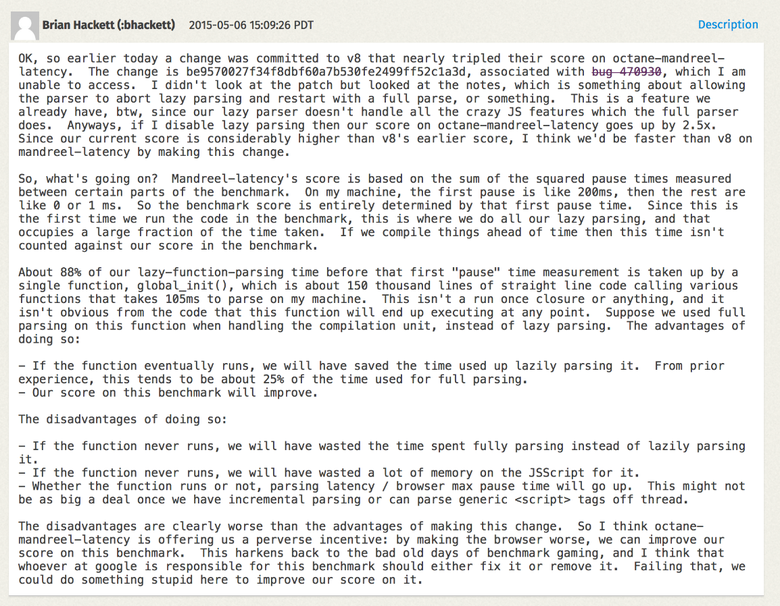
Mandreel содержит огромную инициализирующую функцию
global_init, и на её парсинг и генерирование основного кода уходит огромное количество времени. Поскольку движки обычно по многу раз парсят в скриптах разные функции, то сначала в скрипте находят все функции (стадия препарсинга), а затем, когда функция вызывается впервые, она полностью парсится и для неё генерируется основной код (или байткод). В V8 это называется ленивым парсингом. Для поиска функций, которые можно вызвать немедленно, если препарсинг будет лишь потерей времени, в движке применяется эвристика. Но для функции global_init из Mandreel это не очевидно, поэтому на препарсинг + парсинг + компилирование большой функции уходит масса времени. Чтобы избежать препарсинга и для функции global_init, мы добавили дополнительную эвристику.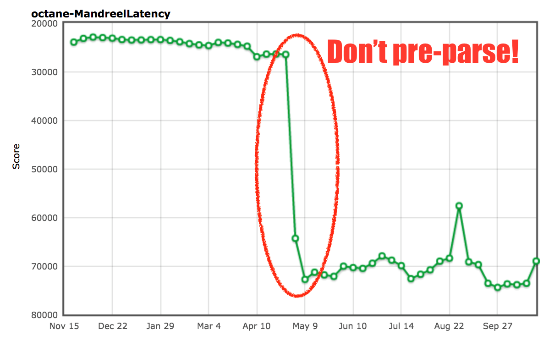
Источник: arewefastyet.com.
Внедрив определение
global_init и избежав дорогого препарсинга, мы получили почти 200-процентное улучшение. Мы считаем, что это не должно негативно сказаться на реальных проектах, но не можем гарантировать, что не возникнет осложнения с большими функциями в тех случаях, когда препарсинг был бы полезен (потому что они не исполняются немедленно).Рассмотрим другой, несколько противоречивый бенчмарк — splay.js. Этот тест предназначен для манипулирования данными, для работы с косыми деревьями (splay trees) и тренировки подсистемы автоматического управления памятью (сборщика мусора). В нём есть инструментарий для выполнения частых измерений времени: длинные паузы между ними говорят о высоком уровне задержки при работе сборщика мусора. Тест классифицирует паузы по вёдрам (buckets) и штрафует за длинные паузы, снижая общий балл. Звучит прекрасно! В теории. Давайте посмотрим на код, лежащий в основе механизма работы с косыми деревьями:

Это ключевая конструкция, и, что бы вы ни думали, глядя на весь бенчмарк, именно от неё зависит балл SplayLatency. Почему? По сути, бенчмарк создаёт огромные косые деревья так, чтобы большинство их узлов выживали и превращались в старое пространство. За это приходится слишком дорого расплачиваться при использовании сборщика мусора, учитывающего поколения объектов (generational garbage collector), как в V8: если программа нарушает гипотезу поколений (generational hypothesis), то это приводит к чрезвычайно большим паузам на полную эвакуацию из нового пространства в старое. Эту проблему хорошо иллюстрирует запуск V8 в старой конфигурации:
$ out/Release/d8 --trace-gc --noallocation_site_pretenuring octane-splay.js
[20872:0x7f26f24c70d0] 10 ms: Scavenge 2.7 (6.0) -> 2.7 (7.0) MB, 1.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 12 ms: Scavenge 2.7 (7.0) -> 2.7 (8.0) MB, 1.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 14 ms: Scavenge 3.7 (8.0) -> 3.6 (10.0) MB, 0.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 18 ms: Scavenge 4.8 (10.5) -> 4.7 (11.0) MB, 2.5 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 22 ms: Scavenge 5.7 (11.0) -> 5.6 (16.0) MB, 2.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 28 ms: Scavenge 8.7 (16.0) -> 8.6 (17.0) MB, 4.3 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 35 ms: Scavenge 9.6 (17.0) -> 9.6 (28.0) MB, 6.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 49 ms: Scavenge 16.6 (28.5) -> 16.4 (29.0) MB, 8.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 65 ms: Scavenge 17.5 (29.0) -> 17.5 (52.0) MB, 15.3 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 93 ms: Scavenge 32.3 (52.5) -> 32.0 (53.5) MB, 17.6 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 126 ms: Scavenge 33.4 (53.5) -> 33.3 (68.0) MB, 31.5 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 151 ms: Scavenge 47.9 (68.0) -> 47.6 (69.5) MB, 15.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 183 ms: Scavenge 49.2 (69.5) -> 49.2 (84.0) MB, 30.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 210 ms: Scavenge 63.5 (84.0) -> 62.4 (85.0) MB, 14.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 241 ms: Scavenge 64.7 (85.0) -> 64.6 (99.0) MB, 28.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 268 ms: Scavenge 78.2 (99.0) -> 77.6 (101.0) MB, 16.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 298 ms: Scavenge 80.4 (101.0) -> 80.3 (114.5) MB, 28.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 324 ms: Scavenge 93.5 (114.5) -> 92.9 (117.0) MB, 16.4 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 354 ms: Scavenge 96.2 (117.0) -> 96.0 (130.0) MB, 27.6 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 383 ms: Scavenge 108.8 (130.0) -> 108.2 (133.0) MB, 16.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 413 ms: Scavenge 111.9 (133.0) -> 111.7 (145.5) MB, 27.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 440 ms: Scavenge 124.1 (145.5) -> 123.5 (149.0) MB, 17.4 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 473 ms: Scavenge 127.6 (149.0) -> 127.4 (161.0) MB, 29.5 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 502 ms: Scavenge 139.4 (161.0) -> 138.8 (165.0) MB, 18.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 534 ms: Scavenge 143.3 (165.0) -> 143.1 (176.5) MB, 28.5 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 561 ms: Scavenge 154.7 (176.5) -> 154.2 (181.0) MB, 19.0 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 594 ms: Scavenge 158.9 (181.0) -> 158.7 (192.0) MB, 29.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 622 ms: Scavenge 170.0 (192.5) -> 169.5 (197.0) MB, 19.5 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 655 ms: Scavenge 174.6 (197.0) -> 174.3 (208.0) MB, 28.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 683 ms: Scavenge 185.4 (208.0) -> 184.9 (212.5) MB, 19.4 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 715 ms: Scavenge 190.2 (213.0) -> 190.0 (223.5) MB, 27.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 743 ms: Scavenge 200.7 (223.5) -> 200.3 (228.5) MB, 19.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 774 ms: Scavenge 205.8 (228.5) -> 205.6 (239.0) MB, 27.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 802 ms: Scavenge 216.1 (239.0) -> 215.7 (244.5) MB, 19.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 833 ms: Scavenge 221.4 (244.5) -> 221.2 (254.5) MB, 26.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 861 ms: Scavenge 231.5 (255.0) -> 231.1 (260.5) MB, 19.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 892 ms: Scavenge 237.0 (260.5) -> 236.7 (270.5) MB, 26.3 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 920 ms: Scavenge 246.9 (270.5) -> 246.5 (276.0) MB, 20.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 951 ms: Scavenge 252.6 (276.0) -> 252.3 (286.0) MB, 25.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 979 ms: Scavenge 262.3 (286.0) -> 261.9 (292.0) MB, 20.3 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1014 ms: Scavenge 268.2 (292.0) -> 267.9 (301.5) MB, 29.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1046 ms: Scavenge 277.7 (302.0) -> 277.3 (308.0) MB, 22.4 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1077 ms: Scavenge 283.8 (308.0) -> 283.5 (317.5) MB, 25.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1105 ms: Scavenge 293.1 (317.5) -> 292.7 (323.5) MB, 20.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1135 ms: Scavenge 299.3 (323.5) -> 299.0 (333.0) MB, 24.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1164 ms: Scavenge 308.6 (333.0) -> 308.1 (339.5) MB, 20.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1194 ms: Scavenge 314.9 (339.5) -> 314.6 (349.0) MB, 25.0 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1222 ms: Scavenge 324.0 (349.0) -> 323.6 (355.5) MB, 21.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1253 ms: Scavenge 330.4 (355.5) -> 330.1 (364.5) MB, 25.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1282 ms: Scavenge 339.4 (364.5) -> 339.0 (371.0) MB, 22.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1315 ms: Scavenge 346.0 (371.0) -> 345.6 (380.0) MB, 25.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1413 ms: Mark-sweep 349.9 (380.0) -> 54.2 (305.0) MB, 5.8 / 0.0 ms (+ 87.5 ms in 73 steps since start of marking, biggest step 8.2 ms, walltime since start of marking 131 ms) finalize incremental marking via stack guard GC in old space requested
[20872:0x7f26f24c70d0] 1457 ms: Scavenge 65.8 (305.0) -> 65.1 (305.0) MB, 31.0 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1489 ms: Scavenge 69.9 (305.0) -> 69.7 (305.0) MB, 27.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1523 ms: Scavenge 80.9 (305.0) -> 80.4 (305.0) MB, 22.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1553 ms: Scavenge 85.5 (305.0) -> 85.3 (305.0) MB, 24.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1581 ms: Scavenge 96.3 (305.0) -> 95.7 (305.0) MB, 18.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1616 ms: Scavenge 101.1 (305.0) -> 100.9 (305.0) MB, 29.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1648 ms: Scavenge 111.6 (305.0) -> 111.1 (305.0) MB, 22.5 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1678 ms: Scavenge 116.7 (305.0) -> 116.5 (305.0) MB, 25.0 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1709 ms: Scavenge 127.0 (305.0) -> 126.5 (305.0) MB, 20.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1738 ms: Scavenge 132.3 (305.0) -> 132.1 (305.0) MB, 23.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1767 ms: Scavenge 142.4 (305.0) -> 141.9 (305.0) MB, 19.6 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1796 ms: Scavenge 147.9 (305.0) -> 147.7 (305.0) MB, 23.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1825 ms: Scavenge 157.8 (305.0) -> 157.3 (305.0) MB, 19.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1853 ms: Scavenge 163.5 (305.0) -> 163.2 (305.0) MB, 22.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1881 ms: Scavenge 173.2 (305.0) -> 172.7 (305.0) MB, 19.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1910 ms: Scavenge 179.1 (305.0) -> 178.8 (305.0) MB, 23.0 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1944 ms: Scavenge 188.6 (305.0) -> 188.1 (305.0) MB, 25.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1979 ms: Scavenge 194.7 (305.0) -> 194.4 (305.0) MB, 28.4 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 2011 ms: Scavenge 204.0 (305.0) -> 203.6 (305.0) MB, 23.4 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 2041 ms: Scavenge 210.2 (305.0) -> 209.9 (305.0) MB, 23.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 2074 ms: Scavenge 219.4 (305.0) -> 219.0 (305.0) MB, 24.5 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 2105 ms: Scavenge 225.8 (305.0) -> 225.4 (305.0) MB, 24.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 2138 ms: Scavenge 234.8 (305.0) -> 234.4 (305.0) MB, 23.1 / 0.0 ms allocation failure
[...SNIP...]
$ Главное наблюдение: размещение узлов косых деревьев напрямую в старом пространстве позволит избежать практически любых избыточных расходов на копирование объектов и снизит до минимума количество незначительных циклов сборки мусора (то есть уменьшит паузы на сборку). Так мы пришли к механизму, который называется allocation site pretenuring. При запуске в базовом коде он пытается динамически собирать обратную связь из точек размещения (allocation sites), чтобы решить, выживет ли определённая доля размещённых объектов. Если да, он генерирует оптимизированный код для прямого размещения объектов в старом пространстве — pretenure объектов.
$ out/Release/d8 --trace-gc octane-splay.js
[20885:0x7ff4d7c220a0] 8 ms: Scavenge 2.7 (6.0) -> 2.6 (7.0) MB, 1.2 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 10 ms: Scavenge 2.7 (7.0) -> 2.7 (8.0) MB, 1.6 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 11 ms: Scavenge 3.6 (8.0) -> 3.6 (10.0) MB, 0.9 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 17 ms: Scavenge 4.8 (10.5) -> 4.7 (11.0) MB, 2.9 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 20 ms: Scavenge 5.6 (11.0) -> 5.6 (16.0) MB, 2.8 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 26 ms: Scavenge 8.7 (16.0) -> 8.6 (17.0) MB, 4.5 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 34 ms: Scavenge 9.6 (17.0) -> 9.5 (28.0) MB, 6.8 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 48 ms: Scavenge 16.6 (28.5) -> 16.4 (29.0) MB, 8.6 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 64 ms: Scavenge 17.5 (29.0) -> 17.5 (52.0) MB, 15.2 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 96 ms: Scavenge 32.3 (52.5) -> 32.0 (53.5) MB, 19.6 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 153 ms: Scavenge 61.3 (81.5) -> 57.4 (93.5) MB, 27.9 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 432 ms: Scavenge 339.3 (364.5) -> 326.6 (364.5) MB, 12.7 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 666 ms: Scavenge 563.7 (592.5) -> 553.3 (595.5) MB, 20.5 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 825 ms: Mark-sweep 603.9 (644.0) -> 96.0 (528.0) MB, 4.0 / 0.0 ms (+ 92.5 ms in 51 steps since start of marking, biggest step 4.6 ms, walltime since start of marking 160 ms) finalize incremental marking via stack guard GC in old space requested
[20885:0x7ff4d7c220a0] 1068 ms: Scavenge 374.8 (528.0) -> 362.6 (528.0) MB, 19.1 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 1304 ms: Mark-sweep 460.1 (528.0) -> 102.5 (444.5) MB, 10.3 / 0.0 ms (+ 117.1 ms in 59 steps since start of marking, biggest step 7.3 ms, walltime since start of marking 200 ms) finalize incremental marking via stack guard GC in old space requested
[20885:0x7ff4d7c220a0] 1587 ms: Scavenge 374.2 (444.5) -> 361.6 (444.5) MB, 13.6 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 1828 ms: Mark-sweep 485.2 (520.0) -> 101.5 (519.5) MB, 3.4 / 0.0 ms (+ 102.8 ms in 58 steps since start of marking, biggest step 4.5 ms, walltime since start of marking 183 ms) finalize incremental marking via stack guard GC in old space requested
[20885:0x7ff4d7c220a0] 2028 ms: Scavenge 371.4 (519.5) -> 358.5 (519.5) MB, 12.1 / 0.0 ms allocation failure
[...SNIP...]
$Это и в самом деле помогло полностью решить проблему с бенчмарком SplayLatency и улучшить результат на 250 %!
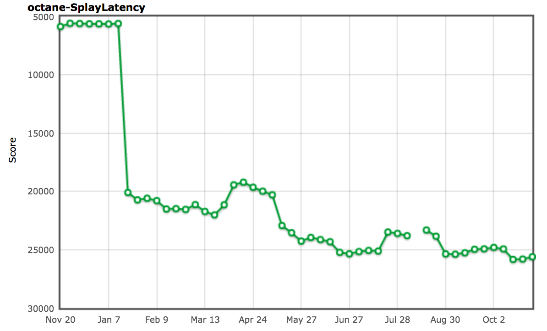
Источник: arewefastyet.com.
Как говорится в статье про SIGPLAN, у нас были причины верить, что allocation site pretenuring может быть хорошим решением для реальных проектов. И мы хотели увидеть улучшения в этом механизме, а также получить возможность применять его не только к объектам и литералам массивов. Но вскоре поняли (1, 2, 3), что allocation site pretenuring может плохо повлиять на производительность реальных проектов. Мы получили много негативных отзывов, в том числе бурление говн от разработчиков Ember.js (правда, не только из-за allocation site pretenuring).
Главная проблема allocation site pretenuring, как мы выяснили, — фабрики классов, которые сегодня используются очень часто (в основном из-за фреймворков, но и по ряду других причин). Допустим, фабрика изначально применялась для создания долгоживущих объектов, формирующих вашу объектную модель и виды, она в фабричном(-ых) методе(-ах) переводит точку размещения (allocation site) в состояние tenured, а всё размещённое из фабрики немедленно попадает в старое пространство. Тогда после начальной настройки ваше приложение начинает что-то делать, в том числе размещает временные объекты из фабрики, которые засоряют старое пространство, что в итоге приводит к дорогим циклам сборки мусора и прочим негативным побочным эффектам вроде слишком раннего запуска инкрементальной маркировки (incremental marking).
Поэтому мы начали искать подходящие решения. В итоге, пытаясь улучшить сборку мусора, пришли к Orinoco. Одним из результатов наших изысканий стал проект унифицированной кучи (unified heap), с помощью которого мы пытаемся избежать копирования объектов, если на странице выживает почти всё. На верхнем уровне: если новое пространство заполнено живыми объектами, то все его страницы помечаются принадлежащими старому пространству, после чего создаётся свежее новое пространство с пустыми страницами. Возможно, в бенчмарке SplayLatency это не даст такого же результата, но так гораздо лучше для реальных проектов. К тому же этот подход автоматически масштабируется под конкретную ситуацию. Также мы рассматриваем использование одновременной маркировки (concurrent marking) для вынесения работы по маркировке в отдельный тред, что ещё больше снизит отрицательное влияние инкрементальной маркировки на задержку и пропускную способность (throughput).
Заключение
Надеюсь, теперь вам понятно, почему сегодня использование бенчмарков в целом неплохая идея, но только до какого-то предела. И, выйдя за границы полезной конкуренции, вы начнёте попусту тратить время своих разработчиков, а то и навредите производительности реальных проектов! Пора оценивать браузеры по их настоящей производительности, а не по способности побеждать в бенчмарках четырёхлетней давности. Пора обучать журналистов, а если не получится, то игнорировать их.

Источник: Битва браузерных бенчмарков в октябре 2016-го: Chrome vs. Firefox vs. Edge, venturebeat.com.
Мы не боимся конкуренции, но игры с потенциально сломанными бенчмарками — не самое полезное занятие. Можно сделать гораздо больше, подняв JavaScript на новый уровень. Давайте ориентироваться на более осмысленные тесты производительности, которые поспособствуют конкуренции там, где это полезно для конечных пользователей и разработчиков. И заодно давайте продвигать полезные улучшения в серверном и инструментальном коде, выполняющемся в Node.js (как и на V8, и на ChakraCore)!

Завершающий комментарий: не используйте традиционные JavaScript-бенчмарки для сравнения телефонов. Это самое бесполезное, что можно сделать. Производительность JavaScript часто сильно зависит от программного обеспечения, а вовсе не от железа. К тому же новые версии Chrome выходят каждые шесть недель, так что мартовские сравнения будут неактуальны уже в апреле. А если вам никак не избежать браузерных сравнений, то хотя бы используйте свежие полноценные браузерные бенчмарки, например Speedometer, которые выполняют что-то похожее на реальные задачи.
Спасибо!
Комментарии (12)

Deosis
27.12.2016 07:26На диаграмме разница между Firefox и Edge около 10%, а не вдвое, если судить по высоте столбцов.

poxu
27.12.2016 08:25+2сегодня JavaScript является ключевой технологией в вебе, доминирует в серверной/облачной сфере (благодаря Node.js)
Джаваскрипт доминирует в облачной сфере? Странно. Посмотрим оригинал.
JavaScript is at the core of not only the web today, but it’s also becoming the dominant technology on the server-/cloud-side (via Node.js)
Ну да, точно. Идёт к доминированию, а не доминирует.

QtRoS
27.12.2016 08:46+3Как на самом деле выглядят бенчмарки джаваскриптовых фреймворков…
googleusercontent

am-amotion-city
27.12.2016 11:59+1идет к доминированию в серверной/облачной сфере (благодаря
Node.js)Вот так одна-единственная слишком громкая фраза в самом начале убивает весь труд: после нее читать будут только совсем упоротые джойсисты.
sdwvit
27.12.2016 12:53Титаническая работа. Спасибо, было интересно. Очень не хватает в комьюнити жс правильных подходов к тестированию производительности.

AfterGen
27.12.2016 13:27+1Но несмотря на очевидные недостатки, сегодня JavaScript является ключевой технологией в вебе, идет к доминированию в серверной/облачной сфере (благодаря Node.js), а также проникает в интернет вещей.
Вот почему-то всегда сразу возникает вопрос: зачем JS нужен там где он не нужен? Все же на самом деле прекрасно понимают, что ему место не дальше веба, потому что он уже на своем месте. Но нет же, людишкам нужно выворачиваться наизнанку, ради чего…
Eljoy
27.12.2016 15:06+1Это интересный вопрос. Но у меня еще более интересный вопрос к вам: кто решил, что js на своем месте и это самое «его место» ограничивается только вебом? Вы? А на каком основании собственно? Очевидно, у вас много не согласных, которые расширяют понятие «место js» и делают это успешно, судя по популярности js-решений.
AfterGen
27.12.2016 16:09делают это успешно
Но так же успешно они рассуждают о плохой производительности, если говорить о ресурсозатратных вычислениях. Со стороны все это выглядит неубедительным. Для таких целей есть более пригодные средства. А js создавался в основном как легковесный «api» для удобства встраивания в клиентские приложения.
stardust_kid
29.12.2016 13:23+1Хотелось бы ближе с Вами познакомиться, редко удается встретить человека, который может говорить от имени всех. Как там у всех дела?


rinatr
27.12.2016 15:34Он простой. Этим и подкупает. Простой, но вот какой-то убогий. Хак на хаке, хаком погоянет.
И картинка доставляет.
snnrman
Вся суть в последнем абзаце.