
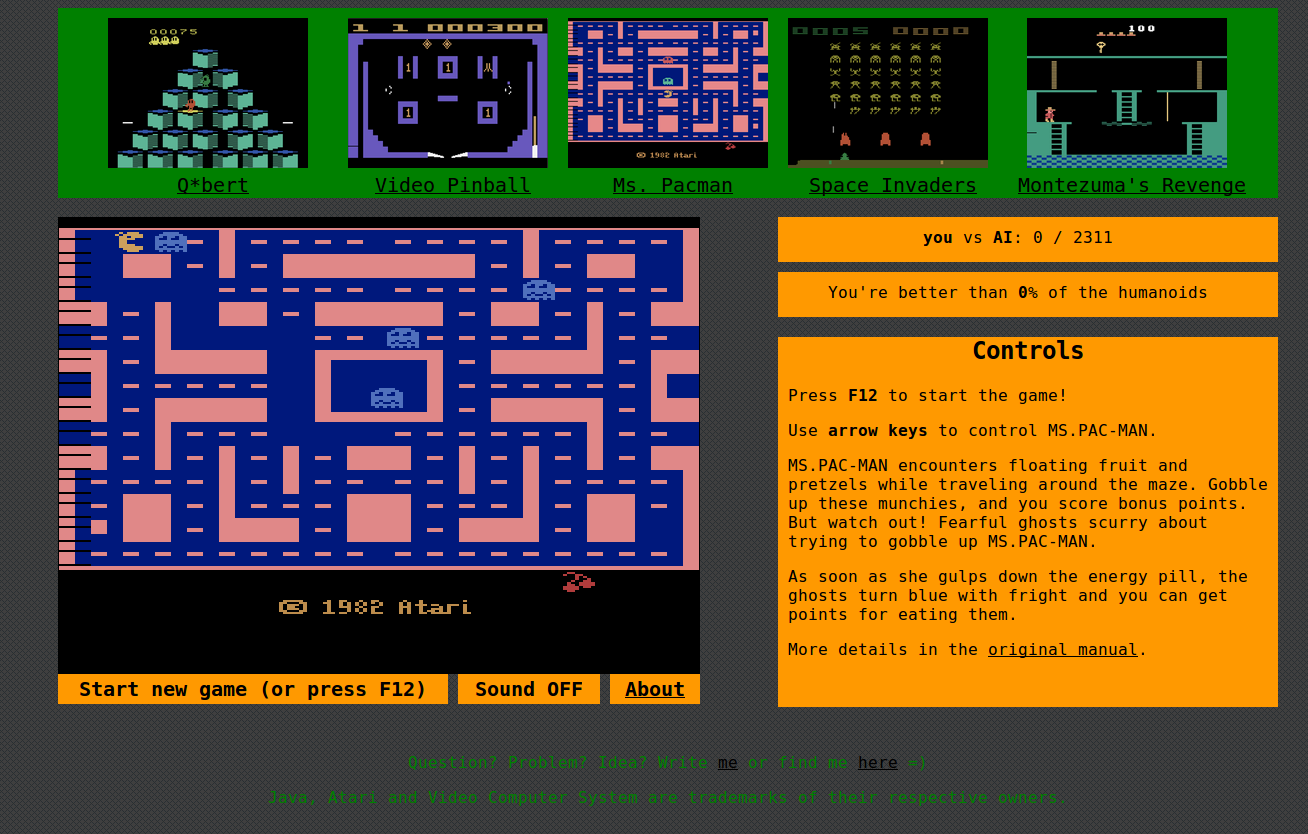
Сайт atarigrandchallenge.com, предназначенный для сбора данных
Всем привет! “Искусственный интеллект победил человека в Го”, “Искусственный интеллект играет в Atari 2600 лучше чем человек”, “Компьютерные боты приблизились по уровню игры в Doom к человеческим игрокам” — последнее время таких заголовков становится всё больше и больше. Появляются многочисленные среды для разработки и тестирования алгоритмов обучения с подкреплением (Reinforcement Learning): OpenAI Universe, Microsoft Minecraft Malmo, DeepMind SCII. И кто знает, что будет завтра?
Для своей магистерской работы я хочу собрать коллекцию реплеев игр для Atari 2600, сыгранных людьми. В дальнейшем я использую ее для обучения ботов и выложу все собранные данные в открытый доступ, чтобы все желающие могли использовать их для своих исследований.
Для этой цели создан сайт atarigrandchallenge.com. По сути, сайт является обёрткой для JavaScript-эмулятора Javatari, которая на каждый кадр игры записывает все нажатия клавиш, а также очки в игре, количество жизней и прочую информацию об игре (например, является ли кадр последним кадром текущей игры).
На основе этой информации будет восстановлена последовательность кадров исходной игры. Бот будет обучаться игре, основываясь только на пикселях экрана и нажатых клавишах.
Если желаете помочь исследованию, просто зайдите на сайт и сыграйте пару игр. Для игры нужна клавиатура. На мобильных устройствах эмулятор не работает.
Если есть какие-то вопросы, идеи или критика, пишите комментарии. Спасибо!
Комментарии (16)

maaGames
29.12.2016 15:25Пытался внести свой вклад в исследование… ниасилил. Пробел не желает стрелять. Видимо, что-то в настройках ФФ мешает. Но стрелочки работают.

FaceHoof
29.12.2016 15:45У меня тоже были странности в работе кнопки «пробел». Такое ощущение, что после его нажатия следует подождать около секунды, прежде чем можно будет нажать ещё раз. Но я думал, что это особенности самих игр.
maaGames
29.12.2016 15:47Нажимал и вообще не отпускал. Никакого результата. Подозреваю, что это из-за динамического поиска, но отключать его ради игрушки не хочется.

Vitalykurin
29.12.2016 16:56А F12/Start Game нажимали? В Space Invaders, например, для начала игры нужно нажать.
maaGames
29.12.2016 16:59Да, дело было в этом. После нажатия F12 стрелять заработало. Надо было читать инструкцию.)

ooptimum
29.12.2016 15:30Вы хотите использовать Supervised learning там, где действительно нужно использовать Reinforcement learning, упомянутый в начале заметки. Для Reinforcement learning не нужно иметь никаких данных о нажатиях в той или иной игровой ситуации. Все, что вам нужно — научиться считывать с экрана текущее количество набранных очков, всему остальному бот научится сам.
Vitalykurin
29.12.2016 16:58+1Reinforcement learning разный бывает. Есть даже Inverse Reinforcement Learning, где имея данные о том, как вёл себя человек, мы должны восстановить reward function.
Что касается нашего случая, то мы собираемся проверить, насколько использование данных о поведении людей в exploration фазе, позволит ускорить обучение.ooptimum
30.12.2016 11:14Есть даже Inverse Reinforcement Learning
Есть, да. Но Inverse Reinforcement Learning совсем не то же самое, что Reinforcement learning, несмотря на общие слова в названии, т.к. они предназначены для решения разных проблем. Зачем вам восстанавливать reward function, если она явно дана вам в виде очков на экране?
Что касается ускорения обучения, то я очень сомневаюсь, что в данном случае исследование поведения людей вам что-то даст. Во-первых, нет никаких гарантий того, что люди знают/избирают оптимальную стратегию. Во-вторых, вам все равно нужно делать исследовательские ходы. В-третьих, игра не симметрична в том смысле, что игрок играет против компьютера, а не другого игрока, как в го, шахматах и т.д. В-четвертых, на изучение поведения людей вы так же будете тратить время и его тоже надо учитывать в плане оценки «ускорения обучения».
Vitalykurin
30.12.2016 13:22+1Я привёл IRL для примера того, что RL не всегда предпологает только использование данных среды. В данном случае reward function восстанавливать нам не нужно, да.
Что касается ускорения обучения, то я очень сомневаюсь, что в данном случае исследование поведения людей вам что-то даст.
Ну вот и посмотрим =) С первым и вторым, четвёртым пунктами согласен. Не понял, при чём тут третий.

ex4sperans
30.12.2016 20:51+2Ну, в AlphaGo первая часть обучения тоже чисто в supervised режиме (предсказание хода), и что? В любом случае такие данные явно не бесполезны. Как минимум, можна проанализировать разницу в том, как играет человек, и как в итоге научилась играть машина, и т.д.
FaceHoof
Как же прекрасно, когда можно поиграть в прикольные древние игрушки и при этом кому-то помочь =)
Только что ж так мало игр?Vitalykurin
Добавить больше игр не проблема, только тогда данных по каждой игре будет меньше, и это плохо скажется на обучении. Если наберём много данных, то добавить еще игру дополнительно — дело одного часа.
unxed
А для NES такое можно замутить? У каждого свои любимые игры детства :)
Vitalykurin
Это сделать реально, но нужно будет весь проект делать с самого начала. Да и игры там сложнее, поэтому будет сложнее экспериментировать.