
Написано в сотрудничестве с Ревазом Бухрадзе и Кириллом Перминовым
1. Введение
Offline oбмен сообщениями сейчас является одним из наиболее популярных способов общения (1, 2, 3) — судя по аудитории способов общения и динамике её роста.
При этом, ключевым требованием при обмене сообщениями всегда будет являться полное соответствие отправленного сообщения – полученному, то есть передача данных не должна необратимо искажать сами данные. Естественное желание – сэкономить привело к созданию алгоритмов сжатия данных, которые, убирают естественную избыточность данных минимизируя объём хранимых и передаваемых файлов.
Максимально достигаемый объём сжатия, гарантирующий однозначное восстановление данных, определяется работами К. Шеннона по теории информации, и в общем-то является непреодолимым так как изъятие не только избыточной, но и смысловой информации не позволит однозначно восстановить исходное сообщение. Стоит отметить, что отказ от точного восстановления в некоторых случаях и не является критически важным и используется для эффективного сжатия графических, видео и музыкальных данных, где потеря несущественных элементов оправдана, однако о общем случае целостность данных, куда важнее их размера.
Соответственно интересным является вопрос о том, можно-ли не нарушая положения теории информации передать сообщение объёмом меньше, чем минимальный объём, который может быть достигнут при самом лучшем сжатии данных.
2. Пример
Поэтому давайте разберём пример, который позволит изучить особенности передачи информации. И хотя в «английской» традиции участников информационного обмена принято именовать Алиса и Боб, мы же в преддверии нового года воспользуемся более знакомыми любителями месседжинга: Матроскиным и Шариком соответственно.

В качестве же сообщения m выберем: «Поздравляю тебя, Шарик, ты балбес!». Длина его в односимвольной кодировке- len(m) — 34 байта.
Можно заметить, что длина сообщения заметно больше количества информации в нём. Это можно проверить вычеркивая из сообщения сначала каждый десятый символ, потом, (опять же из оригинального сообщения) каждый девятый и так далее до каждого четвёртого, результатом чего будет — «Позравяю ебя Шаик,ты албс!»-26 байт. Соответственно степень «загадочности» будет постепенно повышаться, но, догадаться о чём речь, будет достаточно просто. Более того, «Яндекс» распознаёт данное обращение.
Ещё более высокой степени сокращения длины сообщения при сохранении смысла можно добиться отбрасывая гласные и часть пробелов: “Пздрвл тб,Шрк,т блбс!” — 21 байт, стоит отметить, что хотя поисковики и не справляются таким написанием, восстановить фразу труда не составляет.
Если же посмотреть на количество информации I(m) в этом сообщении определяемое более строго через понятие информационной энтропии, то видно, что объём информации передаваемый в этом сообщении, составляет примерно 34*4,42/8=18,795 байт. Здесь: 4.42 бит/символ среднее количество информации в одном байте русского языка (4, 5), а 8 — приведение от битов к байтам. Это показывает, что воспользовавшись самым лучшим способом сжатия данных необходимо будет затратить не менее 19 байт на передачу сообщения от Матроскина Шарику.
Более того, верно и обратное утверждение о том, что передать нужное нам сообщение без потерь меньше чем за 19 байт невозможно (К. Шеннон, Работы по теории информации и кибернетике., изд. Иностранной литературы, Москва, 1963г.) Теорема 4. стр. 458.
3. Дальнейшие рассуждения
Однако продолжим… Пусть у Матроскина и у Шарика есть некоторое дополнительное количество информации k и пара функций, одна из которых m'=E(k,m), рассчитывающая пересечение дополнительной информации k и исходного сообщения m 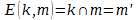 , а вторая D(k,m') =m — обратная к E. Причём количество информации определяемой по Шеннону, удовлетворяет следующему условию:
, а вторая D(k,m') =m — обратная к E. Причём количество информации определяемой по Шеннону, удовлетворяет следующему условию:  . Соответственно, если нам удастся построить определённую выше пару функций E(k,m) и *D(k,m'), такие, что выполняются следующие два условия:
. Соответственно, если нам удастся построить определённую выше пару функций E(k,m) и *D(k,m'), такие, что выполняются следующие два условия:
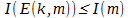 ,
,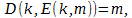
то это будет означать, что для передачи информации между адресатами может потребоваться меньше информации чем содержится в исходном сообщении.

При этом стоит обратить внимание на то, что по определению указанных функций не происходит нарушения утверждений теории информации.
Похожие, алгоритмы предусматривающие замену передаваемой информации её хешем, активно используются в системах оптимизации сетевого трафика. При этом, однако, в отличие от описываемого алгоритма, для того, чтобы эффективно использовать данный вид оптимизации требуется хотя бы однократная передача данных.
Ввиду того, что сообщения на естественном языке содержат объём данных, больший чем объём информации, то если предварительно сжать исходное сообщение при помощи какого-либо из алгоритмов, обеспечивающих эффективное устранение избыточности, например, арифметического кодирования.
Обозначим применение операции сжатия m’= Ar(m) такой, что 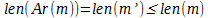 . Если теперь использовать определённую выше функцию E над предварительно сжатым сообщением, то можно заметить, что и объём передаваемых данных и количество информации передаваемых между адресатами могут оказаться меньше объёма данных и количества информации в исходном сообщении.
. Если теперь использовать определённую выше функцию E над предварительно сжатым сообщением, то можно заметить, что и объём передаваемых данных и количество информации передаваемых между адресатами могут оказаться меньше объёма данных и количества информации в исходном сообщении.
То есть, обобщая: в предположении, что существует обратимое преобразование D(k,E(k,m)) =m, такое, что 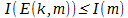 применение операций устранения избыточности даёт возможность передать объём и количество информации в объёме не превосходящие соответствующие параметры (длина len(m) и количество информации I(m)) исходного сообщения.
применение операций устранения избыточности даёт возможность передать объём и количество информации в объёме не превосходящие соответствующие параметры (длина len(m) и количество информации I(m)) исходного сообщения.
В общем осталось только подобрать функции…..
Комментарии (81)
michael_vostrikov
31.12.2016 08:05+1В общем осталось только подобрать функции
Например, одинаковый словарь у отправителя и получателя. Передаем только индексы слов, получаем уменьшение размера сообщения.
В русском языке несколько миллионов словоформ. То есть, достаточно около 3 байт на слово. Старший бит можно сделать признаком знаков препинания, для них достаточно одного байта.
000000 80 000001 81 000002 81 000003 80 000004 82 (20 байт)
Пздрвл тб,Шрк,т блбс! (21 байт)
Можно еще биты поэкономить.
Rumyantsev
31.12.2016 15:35Да, при этом мы размениваем рост размера словаря на объём передаваемой информации и т.к.формула энтропии устроена так, что в балансируются вероятности появления символов, то мы сможем оптимизировать алгоритм арифметического сжатия. Но при этом мы полностью передадим информацию содержащуюся в сообщении. Мне же думается, что можно построить функции, одна из которых сначала частично отбросит не только данные, но и информацию, а другая восстановит её. И такая, что пригодна не только к осмысленным текстам, но и к данным т.е. переложить на C++/
michael_vostrikov
31.12.2016 16:27Отбрасывание и угадывание информации — это частный случай способа со словарем, только на более высоком уровне — на уровне семантики, а не данных. В этом примере словарем выступает мультфильм «Простоквашино».
Информацию в осмысленном тексте можно восстановить по семантике соседних слов, для произвольных данных это невозможно (00 ?? — какой следующий байт я загадал). Всегда будет какое-то подмножество сообщений, размер которых после применения всех функций увеличится.Rumyantsev
31.12.2016 16:42:) Конечно по такому маленькому "хвосту" восстановить нереально. Но насчёт невозможности не уверен т.к. противоречий с теорией информации нет.
Спасибо за комментарии и, кстати, с наступающим.

Singapura
03.01.2017 21:55Можно и по «Пифагорить».
C^2+остаток = (А^2 +B^2) +остаток = (огромный 1011001110001......)+(остаток ...011)= files.txt
Подмена «блока» файла
С^2=(А^2 + B^2) числом (A^2-B^2), получим (мелкий ...10001)+(остаток ...011)=files.arh
только нужны большие и «чистые» Пифагоровы числа вида 3;4;5, и чтобы разность была
A-B=1 для минимальности(архива) и однозначности(распаковки). Даже тут на «мелочи»
экономия 40%
25 = 1 1 0 0 1,
7 = 1 1 1Rumyantsev
03.01.2017 22:01Правильно понимаю тему, что экономия возникает, за счёт того, что разность представима числом заметно меньшей размерности чем каждое из слагаемых?
Singapura
03.01.2017 22:22Да.И это показуемо ) примерно так…
10^2 — 9^2 — 8^2 — 7^2 — 6^2 — 5^2 — 4^2 — 3^2 — 2^2 — 1^2 — 0^2
… 19 17 15 13 11 9 7 5 3 1
… однозначность результатов на это можно оперется.
Singapura
03.01.2017 22:27Число 181 = 10110101 можно заменить 19 = 10011
Rumyantsev
03.01.2017 22:40Для понимания
1) если представляем 181 = 10^2+9^2 => 10^2-9^2 => 19
2) 147 = 9^2+8^2+2 => 9^2-8^2+2 = 19
или какая-то другая схема?
Singapura
03.01.2017 22:56Хвостики это «часть первого результата», когда с огромным числом закончатся преобразования,«хвостики»(лего) станут следующим числом для работы
Singapura
03.01.2017 23:17В смысле «Хвостик числа», это «остаток» или как в химии «осадок 1», ....., «осадок N», и легообразно «склеившись» по правилам, они ведь «не размешаны» значит могут выступать как следующее рабочее число.
Rumyantsev
04.01.2017 00:06Т.е. правильно понял алгоритм
на примере 15||2
- Вариант 1 15||2 => 15^2||2 => 113^2-112^2||2 => 113^2||2 => 12769||2 =>12771- это и есть исходное сообщение. должно работать ввиду однозначности троек такого типа
- Вариант 2 15||2 => (2*7+1)||2 => (8^2-7^2)||2 =>(8^2+7^2)||2 = 113||2 => 115
Singapura
04.01.2017 00:40А теперь плавно можно перейти к теме «инструкция в „код-цвет“», который объяснит компрессору сколько раз нужно приложиться этим методом к «Гамлету» Шекспира (12771), чтобы получился Бедный Йорик(15II2)....)))
Singapura
04.01.2017 01:01Я представлял это как 12771=>12769||2 => 113^2||2 =>
=> 8^2 + 7^2||2 => 8^2 — 7^2||2 => 15||2 и обратно
Singapura
03.01.2017 22:37Много-много раз пропустив число через этот компресс можно получить желаемое сжатие.
webhamster
31.12.2016 13:44> Ввиду того, что сообщения на естественном языке содержат объём данных, больший чем объём информации, то если предварительно сжать исходное сообщение при помощи какого-либо из алгоритмов, обеспечивающих эффективное устранение избыточности, например, арифметического кодирования.
… то что?
Такое впечатление, что в этом предложении демонстрируется передача информации с потерей большей, чем допустимая по информационной емкости.Rumyantsev
31.12.2016 15:52Тут скорее высказывается предположение, о том, что можно можно можно сократить не только объём данных, но и объём информации в передаваемом сообщении. Почему это может быть интересно — усложнить восстановление без ключа, который нужен не только для того, чтобы закодировать, но и для того, чтобы выделить общую с исходным сообщением информацию и не передавать её.
Почему вроде бы можно: в некоторых случаях человек это может сделать, не нарушается теория информации.
А вот вопрос как алгоритмизировать восстановление именно отброшенной информации- пока вопрос.

icoz
31.12.2016 14:18Много достаточно очевидных заявлений, приправленных формулами.
Так в чем основная суть статьи?Rumyantsev
31.12.2016 15:55Чутка выше написал — предположение, о том, что можно можно можно сократить не только объём данных, но и объём информации в передаваемом сообщении. Почему это может быть интересно — усложнить восстановление без ключа, который нужен не только для того, чтобы закодировать, но и для того, чтобы выделить общую с исходным сообщением информацию и не передавать её.
Почему вроде бы можно: в некоторых случаях человек это может сделать, не нарушается теория информации.
А вот вопрос как алгоритмизировать восстановление именно отброшенной информации- пока вопрос.icoz
31.12.2016 16:30Алгоритмизировать для кого? Для человека или для машины.
В вашем контексте этого непонятно. Под ключом вы понимаете словарные таблицы или что?
Я бы предложил вам начать с терминологии. И многое само встанет на места.Rumyantsev
31.12.2016 16:48Спасибо за уточнения — надо будет написать более строго. Под ключом понимаю
- для сжатия по объёму данных словарь;
- для отбрасывания информации некую строку с более или менее равномерно распределенными символами [0,1].
А так да, для компьютера конечно. Человеческий фактор — для примера.
С наступающим.

ThunderCat
31.12.2016 15:40В свое время, когда интернет был маленьким, думал о видеокодеке на похожем принципе, с базой готовых паттернов из набора n*n пикселей, пусть бы весил под гиг, зато фильмы весили бы пару мб.

Akon32
01.01.2017 22:16Наверно, при кодировании без потерь номер паттерна будет иметь ту же длину, что и сам паттерн.
ThunderCat
04.01.2017 23:25думал использовать принцип схожий с жпег кодированием, подбор близких паттернов, + светлее/темнее.
c00nst
02.01.2017 00:49Рекурсия… Создание серии энциклопедий — паттернов, кто кому что сказал. На основе этих энциклопедий — компиляция, и отсылка. И получение с декомпиляцией. Допустима подмена энциклопедий, что создаёт механизм вариантности.



Mogwaika
01.01.2017 17:37+1Эти средние числа не могут дать никаких точных оценок для конкретного сообщения. Какое-то нельзя за 19 байт передать, а какое-то и за 18 можно. У Шеннона много оговорок про бесконечные величины, и одно конкретное сообщение всегда можно уложить в 1 бит, а вот как ваш алгоритм будет работать с любым сообщением любой длины… И ссылочки про энтропию сомнительны, там почему-то 32, а не 33 буквы рассматривают, а тут ещё знаки препинания, а потом и нерусские слова многие любят использовать в русской транскрипции.
Mogwaika
01.01.2017 18:02Более того, если вы попробуете архиватором сжимать стенограмму этого мультика, получается лучше, чем 4,42 бит/символ… Однако никаких теорем Шеннона архиватор не нарушит.
Rumyantsev
01.01.2017 18:23Вечер!
Т.к. текст в принципе легко сжимаем, то хотелось нестрого "на пальцах" показать, что
- вопрос сжатия меньше предела, который можно добиться при помощи алгоритмов архивирования ставить корректно
- если построить обратимую функцию, которая выделяет общую информацию у передаваемых данных и ключа, то эти данные нет необходимости передавать.
- если нет необходимости что-то передавать, то и нет возможности это перехватить
Mogwaika
01.01.2017 18:350) Текст легко сжимаем, т.к. он закодирован с большим избытком… там 6 бит из 8 для текста точно достаточно.
2) Я бы хотел уточнить, что такое «ключ» это словарь, шифроблокнот или алгоритм, который нужно знать всем?
3) Кто-то не знающий алгоритм/словарь/блокнот не должен что-то перехватить?Rumyantsev
01.01.2017 19:012) Ключ скорее, похоже на шифроблокнот т.е. данные которые есть только у обменивающихся сообщениями, хотя шифроблокнот, наверное, слишком громкий термин.
3) Да, не должен.Mogwaika
01.01.2017 19:08Идея описания на пальцах состоит в том, чтобы использовать имеющиеся всем понятные термины, которые есть у всех (пальцы), без введения новых.
Таким образом Вы предлагаете, Шарику и Матроскину обменяться словарём русского языка и словарём типовых фраз из кинофильмов, при этом, оставив в секрете для Печкина структуру этих словарей?Rumyantsev
01.01.2017 19:26Не совсем так.
Если просто обменяться словарями, то придётся передавать код слова, что никак не влияет на количество информации и активно используется для сжатия трафика.
Если же не заменять слово его кодом, а отбрасывать его часть, то тот кто знает что отбрасывали может восстановить исходное сообщение. Т.к. язык штука мощная — видимо, зря такой пример использовал — по контексту легко восстанавливаем.
Давайте предположим, что речь идёт не об осмысленном тексте, а об обмене данными между софтами и если что-то выкинуть из отправляемого сообщения, получатель, если не предпримет дополнительных усилий по восстановлению исходного сообщения, то и принять его не сможет.
В общем поэтому и попытался обойтись без "многоматематики".
Mogwaika
01.01.2017 19:31Чтобы на приёме можно было распарсить сжатие нужно иметь этот словарь (ну там или нейросеть обученную на этом словаре, что суть та же).
Имея просто даже словарь, будем иметь кучу вариантов от «Прфсср, кнчн»:
-профессура окончена
-профессор конечн
-профессора иконочная
Кто знает алгоритм со словарём поймёт всё.

FreeMind2000
01.01.2017 22:31«если что-то выкинуть из отправляемого сообщения, получатель, если не предпримет дополнительных усилий по восстановлению исходного сообщения, то и принять его не сможет.»
— Мысль интересная, но это больше относится к шифрованию, а не архивированию. Вы пытаетесь не передавать часть информации, «защищая» ее, подразумевая, что у отправителя и получателя уже имеется ключ (последовательность недостающих бит или алгоритм ее генирирующий), добавив который к исходному сообщению — получим/восстановим всю информацию в нем. При этом, надо понимать, что отправитель создавая сообщение, создает и ключ, который тоже должен быть передан получателю, что в сумме никак не уменьшает общее кол-во информации переданной получателю (в сравнении с обычной передачей архивированной информации).
В случае же с архиваторами, такие ключи либо сразу имеются у отправителя и получателя (открытые одинаковые словари) либо ключ/словарь передается открыто вместе с сообщением.
Поэтому:
1. вопрос сжатия меньше предела, который можно добиться при помощи алгоритмов архивирования ставить корректно
— Верно
2. если построить обратимую функцию, которая выделяет общую информацию у передаваемых данных и ключа, то эти данные нет необходимости передавать.
— Не верно, т.к.
если ключ это одинаковые словари у отпр/получ — то индексы слов передавать в любом случае надо.
если ключ это набор недостающей информации — то ключ тоже надо передавать иначе восстановление будет невозможно.
если ключ это просто дополнительный набор бит-информации, то теоретически, можно в нем найти повторяющиеся элементы и создать словарь ключа, заменяя в сообщении некоторые слова индексами не из общего словаря, а индексами из словаря ключа. Это и есть ваша обратимая ф-ция. Но, не забывайте, что ключ все равно как-то надо передавать получателю. Т.е. мы просто словарь разбиваем на открытый и закрытый, сокращая по нему кол-во передаваемых данных как в обычном архиваторе, что кол-во передаваемых данных никак не уменьшает по сравнению с обычным словарем.
3. если нет необходимости что-то передавать, то и нет возможности это перехватить
Это, конечно верно :)
Rumyantsev
02.01.2017 01:02К п.2 могу добавить, что здесь в любом случае ключ передавать придётся — если по открытому каналу — то будет просто сжатие, если отдельно от сообщения — получается, что защита информации возможна, как доп. нагрузка.
Что касается словаря — то думал — в чистом виде не очень применимо, т.к. Вы верно заметили, что его тоже сначала надо бы передать.
Сейчас вроде бы получается доказать, что можно обойтись без словаря, воспользовавшись тем, что сумма последовательности "0" и "1" является возрастающей (если совсем строго, то неубывающей ) и, соответственно может превзойти некоторые наперёд заданные значения, а если в этих позициях стоят подряд, например, 2 единицы и в ключе единица, то первую "1" можно отбросить и не передавать. Соотв. потом восстановить можно т.к. у получателя тот же ключ. Если же в очередной позиции ключа "0" соотв. последовательность можно инвертировать "0"<=>"1", что позволяет провести те же рассуждения. Вот то, что строго сейчас надо будет описать.
michael_vostrikov
02.01.2017 05:58Ага, только при этом надо еще передать признак — инвертировали бит в этом месте или нет.
Rumyantsev
02.01.2017 19:45Не надо — это может быть либо регулярная операция (т.е., например, когда сумма равна N), либо данные в ключе.
michael_vostrikov
03.01.2017 05:1811101100 - сообщение 10101010 - ключ 110 100 - отбросили дублирующиеся единицы, там где в ключе 1 10101010 110100 - приняли сообщение 10101010 - ключ первый бит 1, в ключе 1, добавляем единицу 1110100 10101010 третий бит 1, в ключе 1, добавляем единицу 11110100 - восстановленное сообщение 11101100 - исходное сообщение упсRumyantsev
03.01.2017 17:12Видел эту тему немного по другому (пример, понятно подстроен под возможность восстановления):
- "11101100" — сообщение
- "1" — ключ
- устанавливаем пороговую сумму = 4 и считаем когда мы её превысим
- соотв. "11101^100" — вот здесь можно выкинуть 1 => "1110100"
- дальше обратное преобразование при той же пороговой сумме получаем, что "1" надо добавлять "1110^100"
Так вроде совпадает исходное и конечное.
michael_vostrikov
03.01.2017 18:07Ок, мы получили сообщение 1110100000000000. Как узнать, надо ли туда добавлять 1 при превышении порога 4, или оно такое и было?
Rumyantsev
03.01.2017 19:27Никак. Контрпример — чего :). Неправ и с примером и с алгоритмом. Т.к. нарушается однозначность восстановления.
Некорректно пересёк текст и ключ.
- "11101100" — сообщение
FreeMind2000
02.01.2017 11:45Проблема в том, что передаваемые данные в общем случае не зависят от ключа, а вы как раз таки пытаетесь восстанавливать обрезанные биты сообщения по ключу, что приводит к неоднозначности интерпретации обрезанного сообщения.
На мой взгляд есть только один способ изъять информацию из сообщения и потом восстановить ее. Это возможно только при условии, что данная информация ВСЕГДА присутствует в сообщении. Например, мы знаем, что 10й бит в сообщении всегда 1, тогда да, этот бит можно не передавать и длина сообщения уменьшится на 10%. Но естественно, мы должны один раз сообщить об этом получателю, либо он должен обладать этой информацией по умолчанию.
Еще пример, договорится, что 10ым битом сообщения всегда должен быть некоторый циклически перебираемый по порядку бит ключа, тогда этот бит можно убрать из сообщения. Соответственно, тогда любое сообщение мы отправить в исходном виде не сможем, нам надо будет его «подготовить» в соответствии с нашей договоренностью. При этом и сам ключ должен быть передан получателю.
Философский смысл здесь такой — мы можем исключить из сообщения только ту информацию, которая уже есть у получателя.Singapura
02.01.2017 22:49«Философский смысл здесь такой — мы можем исключить из сообщения только ту информацию, которая уже есть у получателя.»…
Алфавит!))
Rumyantsev
02.01.2017 23:26Вот по этому и написал, что исключать надо не то, что есть у получателя — в этом нет смысла, а пересечение того, что есть у двух сторон и того, что надо передать.
^^Выше писал^^Сейчас вроде бы получается доказать, что можно обойтись без словаря, воспользовавшись тем, что сумма последовательности "0" и "1" является возрастающей (если совсем строго, то неубывающей ) и, соответственно может превзойти некоторые наперёд заданные значения, а если в этих позициях стоят подряд, например, 2 единицы и в ключе единица, то первую "1" можно отбросить и не передавать. Соотв. потом восстановить можно т.к. у получателя тот же ключ. Если же в очередной позиции ключа "0" соотв. последовательность можно инвертировать "0"<=>"1", что позволяет провести те же рассуждения. Вот то, что строго сейчас надо будет описать.
FreeMind2000
03.01.2017 01:27Ну если получается, то конечно пробуйте продолжать :)
Просто на то, что вы писали выше, я выше же и ответил… Поясню еще раз: передаваемые данные не зависят от ключа, соответственно от пересечения с ключом они тоже не зависят.
То, что в предлагаемом вами варианте есть коллизии писал и я и michael_vostrikov.
Подумайте, вот мы пытаемся восстановить переданное сообщение, посчитали заранее заданное значение и видим в сообщении 1 в ключе тоже 1, по описанной вами логике мы должны добавить(восстановить пропущенную 1), но представьте, что в исходном сообщении за 1 изначально следовал 0 (т.е. 2х подряд 1ц не было) и мы ничего не обрезали, а значит и добавлять/восстанавливать 1цу не должны. Вот и вопрос — как без доп.информации вы можете утверждать, надо ли восстанавливать 1цу или не надо???
Rumyantsev
03.01.2017 17:19В случае если критерии удаления не выполняются, ничего не удаляем, — бежим по сообщению дальше. Соотв. не надо удалять 1. По тому же критерию единицу не надо будет восстанавливать.
FreeMind2000
03.01.2017 19:51«По тому же критерию единицу не надо будет восстанавливать. „
— к сожалению, вы пока никак не поймете, что такого критерия нет.
Хм, похоже пока не закончите свое доказательство, вам возникающую проблему трудно воспринять :) Просто попробуйте следуя своей же логике передать и восстановить 2 сообщения:
[Исходное]->[Передаваемое]->[Восстановленное]
1) 111101000 -> 111101000 -> 111101000
2) 111101100 -> 11110100 -> 111101?00
Так называемое наперед заданное значение = 5
По какому критерию определяется наличие/отсутствие 1цы на месте знака вопроса?Rumyantsev
03.01.2017 21:56Ок, Вы правы, так информации недостаточно. Хотя может быть сам факт передачи будет служить признаком того, что сообщение удовлетворяет критерию изъятия т. е., например, при пределе =5
1) 111101000 — ждём последующих символов
2) 1111011 || 00 -> 111101 -> 1111011
00 — ждём
При пределе = 4
1) 111101|| 000 -> 11110 -> 111101
000 — ждём
2) 111101 ||100 -> 11110 -> 111101
100 — ждём
При пределе = 3 — аналогично 4
При пределе = 2
1) 111||101000 -> 11 -> 111
101000 — ждём
2) 111||1011||00 -> 11||101 -> 111||1011
00 — ждём
Хотя так не очень понятно, что делать с последним сообщением.
FreeMind2000
04.01.2017 00:24Хм, ну тут у вас уже троичная система вводится [ (0),(1),(||) ]
При таком раскладе маркером изъятия 1 как раз и служит задержка, являющаяся 3им состоянием линии связи. А в троичной системе сообщение можно представить гораздо короче без изъятий 111101100 -> 200020 или в вашем представлении: || 000 || 0. Если захотим изымать и отсюда, то придется вводить еще один тип задержки 4е состояние, которое в четверичной системе опять будет проигрывать по длине представления… и т.д… Это бесперспективный путь. Примерно тоже самое, что создать дополнительную линию связи по которой передавать только признаки изъятия типа:
1111011000 -> 111101000 ->
----------------------------------> 1111011000
-------------------000001000 ->
Вместо того чтобы, передавать информацию по обеим линиям повышая скорость передачи в 2 раза
1111011000 -> 11110 ->
----------------------------------> 1111011000
--------------------11000 ->
Думаю, идею с изъятием информации из сообщения и последующем восстановлении можно реализовать только в том смысле, о котором я писал ранее выше в сообщениях. Но вполне возможно, что есть еще варианты.
Singapura
01.01.2017 18:06«Соответственно интересным является вопрос о том, можно-ли не нарушая положения теории информации передать сообщение объёмом меньше, чем минимальный объём, который может быть достигнут при самом лучшем сжатии данных.»
МОЖНО!… Взглядом!))… когда сообщение одной цифрой через «шрифт» и «цвет» будет указывать на сервис взглядов жён!)))… а там за каждым номером туча алгоритмов!)))Rumyantsev
01.01.2017 18:25:) Если воспринимать шрифт и цвет как разные символы, то количество информации по сути то же!!! :)
Singapura
01.01.2017 18:46Допустим, каждая буква цвет-кода указывает на метод сжатия применимый к информации как-бы #4145A т.е применён алгоритм 4, затем 1,… А и получилось в остатке число 10100101. В ответе останется архив с содержанием 10100101+#4145A.servis.opps(пример)
Singapura
01.01.2017 18:33«Поздравляю тебя, Шарик, ты балбес!» можно описать как «Пт, Ш, тб!+код цвета(указатель на группу алгоритмов сервиса специального сервера)»
Rumyantsev
01.01.2017 18:41Если эти данные войдут в ключ- да.ок.
Раз уж новый год, то всё жду когда напишут "Прфсср, кнчн, лпх, но ппртр пр нммм, пр нммм! Кк слшн?" :)
Mogwaika
01.01.2017 18:52Хотите ещё поле для деятельности, у нас был один преподаватель, который предлагал следующий метод сжатия для телевидения:
Иметь у каждого пользователя огромный магазин звуков и изображений, а передавать ему только сценарий фильма, типа идёт дождь (подгружаем звук дождя из базы), актёр1 говорит актёру2: " *** ** " (генерируем голос из текста)…
Однако передача информации с такими потерями мало кому нужна, краткое содержание Войны и мира для школьников и то полезнее.Singapura
01.01.2017 19:07… и кстати, что делать с «кратким содержанием» это забота онлайн-сервера. У пользователя только хэши (номера инструкций сервера на добавление и раздувание числа +осадок числа)
Singapura
01.01.2017 19:26… и сервер может вернуть пользователю уже эксклюзивный набор методов для распаковки его файла на его «машине».
Akon32
01.01.2017 22:57Соответственно интересным является вопрос о том, можно-ли не нарушая положения теории информации передать сообщение объёмом меньше, чем минимальный объём, который может быть достигнут при самом лучшем сжатии данных.
Насколько хорошо ваше "самое лучшее сжатие данных"?
По опыту знаю, что если обработать исходные данные примитивным сжатием с учётом специфики данных (дельта-кодированием, или просто удалить повторяющиеся нули, наподобие RLE; или в некоторых случаях записать матрицы по столбцам, а не по строкам), то архиваторы начинают справляться лучше (иногда — сильно лучше). Так что, если ваше "самое лучшее сжатие" не обеспечивает теоретического минимального объёма, то ответ — "можно".
Чтобы получить близкий к теоретически минимальному объём, нужно кодировать сообщения с существенным учётом контекста.
Как минимум, если это речь — нужно кодировать семантику, а не слова (что-то вроде Лингва Технис у Адептус Механикус, хотя это вымышленный язык).
Например, «Поздравляю тебя, Шарик, ты балбес!», может кодироваться как
( :обращение-к=Шарик :истинность=:сарказм :я :поздравляю :тебя ( :ты :есть :балбес))
где : слово — некоторые понятия из известного обоим сторонам словаря. Подобным способом можно однозначно и без потерь закодировать любое выражение языка, любую мысль. (а вот мой пример получился неоднозначным)
Контекстное кодирование может дополнительно уменьшить объём данных, например, если речь идёт о том, произошли ли события А, В, С,D то достаточно 4х бит, если есть дополнительные известные обоим сторонам причинно-следственные связи, то может быть достаточно меньшего числа бит.
Арифметическое кодирование дополнительно может упаковать сообщения с нецелым количеством бит информации.
А слова из букв идеально не сжать, по крайней мере без знания языка архиватором. Они сами по себе имеют избыточность; для архиватора, не имеющего хорошей модели языка, сложно её обработать корректно и полностью.
Rumyantsev
02.01.2017 01:13Спасибо.
Под "самым лучшим сжатием" имел ввиду не столько достижение теоретического предела, сколько возможность легально перейти эту грань.
Скажите пожалуйста, есть ли нормальные материалы по кодированию семантики? Т.к. нашёл либо работы лингвистов-теория, либо программистов — нейросети, а вот на стыке пока не нашёл.

napa3um
02.01.2017 04:23Можно начать с «Теории фреймов» Минского (краткая «реклама» фреймового подхода для ваших задач: http://www.rusnauka.com/17_APSN_2009/Philologia/48463.doc.htm)
indestructable
Думаю, здесь имеет место не сжатие, а хэширование, т.к. однозначно восстановить фразу человеку, не смотревшему "Простоквашино", будет невозможно.
Rumyantsev
В общем-то да. Тут скорее расчёт на то, что и смотрели и мультфильм вполне новогодний и фраза простая.
А если серьёзно, то получается так, что если и в тексте и в ключе можно выделить общую информацию, которую можно отбросить, то восстановить данные, по информации меньшей чем минимум достигаемый сжатием, не имея ключа, довольно сложно.
Sergey_Kovalenko
Может быть, стоит определиться сначала с тем, что подразумевается под количеством информации? Если Шарик знает, что никаких других сообщений он получить не может, то количество информации 0, если его могут еще поздравить верблюдом, то 1. Информация в классическом понимании — мера разнообразия вероятных исходов. В постановке задачи этот математический термин используется спекулятивно, хотя нельзя не признать и присутствия разумного зерна в поднятом вопросе.
ainoneko
Для уменьшения длины при сохранении смысла можно выбросить обращение: своё имя Шарик и так знает.
Rumyantsev
Если сообщения идут только Шарику, то да, можно. Если же есть, скажем, Дядя Фёдор — словарь надо расширять.
svboobnov
Насколько я понимаю, арабы пишут, выкидывая гласные (в алфавите только Алеф (алиф) — гласная). Так что, запись только согласных — хороший способ сэкономить папирус, пергамент и байты на диске.
Ссылка — Арабское письмо
Rumyantsev
Просто всегда хочется подумать, а можно ли ещё сэкономить.
AnutaU
Арабский язык хорошо приспособлен под запись без гласных. Русский текст записать таким способом без потерь не получится.
Но если интересно, почитайте про Китабы — тексты на белорусском языке, записанные арабицей :)
Rumyantsev
Прочитал, что нашёл помимо wiki, — вот, вот и вот. Но тут тема такая, что меняется по сути только алфавит, что как кажется сохраняет информацию.
Или не так Вас понял?
AnutaU
Да, меняется только алфавит (какие-то звуки передаются даже точнее, какие-то хуже), в целом информация сохраняется. Но я хотела сказать, что сократить количество знаков для записи за счёт выкидывания гласных в русском вряд ли получится, потому что будет много неоднозначностей (кот, кит, заря, зеро — так, от балды придумала примеры. Можно более показательные найти, думаю).
Арабским я не владею, поэтому совсем точно не скажу, но встречала такую аналогию: у нас почти никогда на письме не указывается ударение, но трудности при этом мы испытываем редко. У арабов примерно то же с гласными: их как бы не пишут, но прочитать не проблема: это особенность языка. А там, где нужно железно точно передать чтение, всё равно используются огласовки.
С Китабами я похоже запутала немного, просто это очень интересная штука, которая к слову пришлась :)