

Евгений Потапов и Антон Баранов из компании ITSumma рассказывают об оптимизации на опережение. Это — расшифровка доклада Highload++.
Мы занимаемся круглосуточной поддержкой и администрированием веб сайтов. Работаем в Иркутске с 2008 года. Сейчас штат 50 человек. Главный офис в Иркутске, есть офис в Санкт-Петербурге и Москве. На данный момент у нас более 200 активных клиентов, с которыми происходит более 100 активных чатов в день. Мы получаем порядка 150 тысяч активных оповещений в месяц о проблемах наших клиентов. Среди наших клиентов — множество разных компаний, есть известные: Lingualeo, AlterGeo, CarPrice, «Хабрахабр», KupiVip, «Наше Радио». Есть много интернет магазинов. Род наших занятий: мы должны в течение 15 минут среагировать на то, что случилась беда, и попытаться её быстро починить.
Откуда берётся беда, эти проблемы на серверах?
- Главная причина — это новая версия приложений. Выложили новую версию сайта, обновили код — что-то сломалось, всё перестало работать, нужно чинить.
- Второе — это проблемы, связанные с ростом нагрузки и масштабированием. Либо это проект, который очень быстро растет, и нужно что-то с этим делать. Либо это проект, который организовал маркетинговую кампанию — чёрная пятница, пришли много людей, не были готовы, всё сломалось — нужно масштабироваться и готовиться к будущему.
- Третья по статистике причина аварий очень интересная. Это аварии, связанные с ошибками планирования архитектуры проекта. То есть беда, которая происходит не из-за того, что пришел трафик и всё упало, не из-за того, что произошла ошибка в коде, а из-за того, что архитектура проекта была устроена так, что она привела к ошибке.
Ошибки планирования архитектуры
Если посмотреть на другие индустрии, то сегодня не происходит так, что после постройки здания оно рушится. Если такое и случается, то довольно редко. После прокладки водопровода не происходит такого, что он немедленно ломается. В IT подобное происходит довольно часто. Строится какая-то архитектура, а когда она релизится, то выясняется, что она не подходит под условия, которые были, либо она очень долго делается, либо возникают другие проблемы.
Сама индустрия IT довольно новая, не наработавшая старые практики, а любые новые решения создают дополнительную сложность, которая уменьшает надежность эксплуатации этих решений. Чем сложнее решение, тем сложнее его эксплуатировать.
Есть, так называемый Закон Луссера. В 40-е годы Германия запускала по Великобритании ракеты «Фау-2». Какие-то долетали точно, какие-то нет. Они решили исследовать в чем причина. Оказалось, что если у вас есть много разных компонентов, и вы усложняете данную систему, то сложность системы (то есть риск того что она может не выдержать) — это не вероятность того, что система попадет в аварию, не самая меньшая вероятность этой системы, не какого-то из компонентов этой системы, а произведение вероятностей риска каждого из компонентов.

Если вероятность аварии с участием одного компонента 5%, а другого — 20%, то общий риск будет не 20%, а 24%. Всё будет очень плохо. Чем больше у вас компонентов, тем больше у вас возникает беды.?
Причины создания сложности
Не каждый день мы видим инженера, который строит офлайн-систему и говорит: «Я сейчас придумаю как сделать сложнее». А в разработке, в эксплуатации мы видим очень много ситуаций, когда мы приходим на смену ребятам или в новую команду и видим систему, которая непонятно зачем так сделана, кроме того, что так было интереснее.
- Первый вариант — решение данной проблемы уникальное. Нельзя нигде найти, как решить эту проблему, что с этим сделать. Мы начинаем придумывать как её решить, наступаем на грабли, понимаем, что это нужно переделать и так далее.
- Иногда случается, что решение есть, но оно нам не известно, а найти мы возможности не имеем. На инженеров в авиастроении учатся долго, а технологии в IТ так быстро меняются, что вуз не может подготовить к проверенным и готовым практикам. Приходится изучать все заново. Иногда при создании какого-то решения, которое когда-то уже было выполнено, что не известно, ты придумываешь всё заново. Поэтому система усложняется, ты приводишь её к риску и всё становится плохо.
- Интересный случай, который возникает достаточно часто. IT это одна из немногих профессий, где людям очень интересно работать. Есть много очень интересных технологий, которые можно попробовать, есть много всего на что хочется посмотреть. Например, давайте попробуем вставить docker в нашем проекте. Очень многие хотят и пытаются придумать где именно его попробовать. В итоге желание попробовать решение из чистого интереса создает особенную сложность. Например, сантехник прокладывая трубу не думает, может быть я её заверну 4 раза, интересно, вдруг вода всё-таки будет идти в кран. В IT мы такое видим достаточно часто.
В итоге, создавая то или иное решение мы думаем, что всё будет круто, но оказывается всё гораздо сложнее.

Мы хотим на основании тех примеров, которые мы видим из жизни, свои практики. Попытаться помочь на какие штуки не стоит наступать и как с этим жить.
Рассмотрим развитие проекта по трём категориям. То есть, как он от самого старта, когда он совсем небольшой или даже идея проекта развивается до какого-то крупного, высоконагруженного проекта, известного по всей стране, по всему миру.
Когда вы создаете проект, как правило, вы предполагаете, что после старта, первых рекламных компаний, в социальных сетях с 25 подписчиками, ваша посещаемость составит 3000-5000 RPS.
Нужно к этому как-то подготовиться, чтобы мощности выдержали эту посещаемость. Тут мы сразу вспоминаем, не даром на каждом углу маркетологи говорят нам про облака. Облака – это очень надежно. Это очень хорошо, замечательно. Буквально везде это слышно.
Чтобы развеять этот миф, мы привели статистику работы uptime'a Amazon'a.

Облако Amazon’a одно из самых быстрорастущих в мире, а также одно из самых крупных. Как вы видите, ничего идеального в этом мире нет. Даже у Amazon’a бывают фейлы, связанные с теми или иными причинами.
Нам всегда говорят, что облако масштабируется. Мы легко можем от одного ядра, от 1 GB до кучи ядер, кучи GB памяти отмасштабировать сервер, на котором находится наш проект. На самом деле все это действительно миф, потому что облака расположены на физических машинах, как и расположено все остальное. Есть лимит, он заключатся в количестве оперативной памяти на этой машине и количестве ядер на этой машине. Вы рано или поздно упретесь в то, что облако не даст вам отмасштабироваться до нужного вам размера. Самый идеальный вариант для вашего проекта, даже на моменте его запуска это отдельный выделенный сервер, ничего надежнее и проще в этом мире пока не придумали. Сейчас железо стоит довольно недорого и за небольшие деньги можно приобрести довольно неплохой выделенный сервер.
Какие же у нас бывают проблемы на выделенных серверах?
В какой-то момент мы понимаем, что проект растет и ждем нагрузку. Сталкиваемся с вопросами, которые возникают. Это горизонтальное масштабирование и резервирование проекта. Нам нужно быть уверенными, что в случае падения основного сервера, проект будет продолжать работать.
Что мы предпринимаем в таких случаях?
Мы балансируем трафик на проект между несколькими веб инстансами. Так же мы делаем несколько инстансов серверов баз данных, которые реплицируются и между которыми нагрузка балансируется.
Основную ошибку, которую допускают в этом случае это то, что все веб сервисы находятся в одной стойке. То есть у нас есть несколько физических веб серверов, которые от всего застрахованы, за одним исключением. Это всё находится в одном дата центре, чаще всего в пределах одной стойки. Конечно же, в случае падения дата центра, это ни от чего не защитит.
В этом случаем мы приходим к выводу что, резервные инстансы, резервные сервера должны находится в другом дата центре. Вторая непреложная истина, которую мы должны понять. Если у нас есть резервные инстансы на которые мы в случае чего можем пустить трафик, это не говорит нам о том, что у нас есть бэкап. Самое главное, что надо понимать, виртуализация — это скорее боль, нежели облегчение страданий. Потому что как правило с виртуализацией связаны свои ощутимые проблемы, мы не рекомендуем с ними работать.
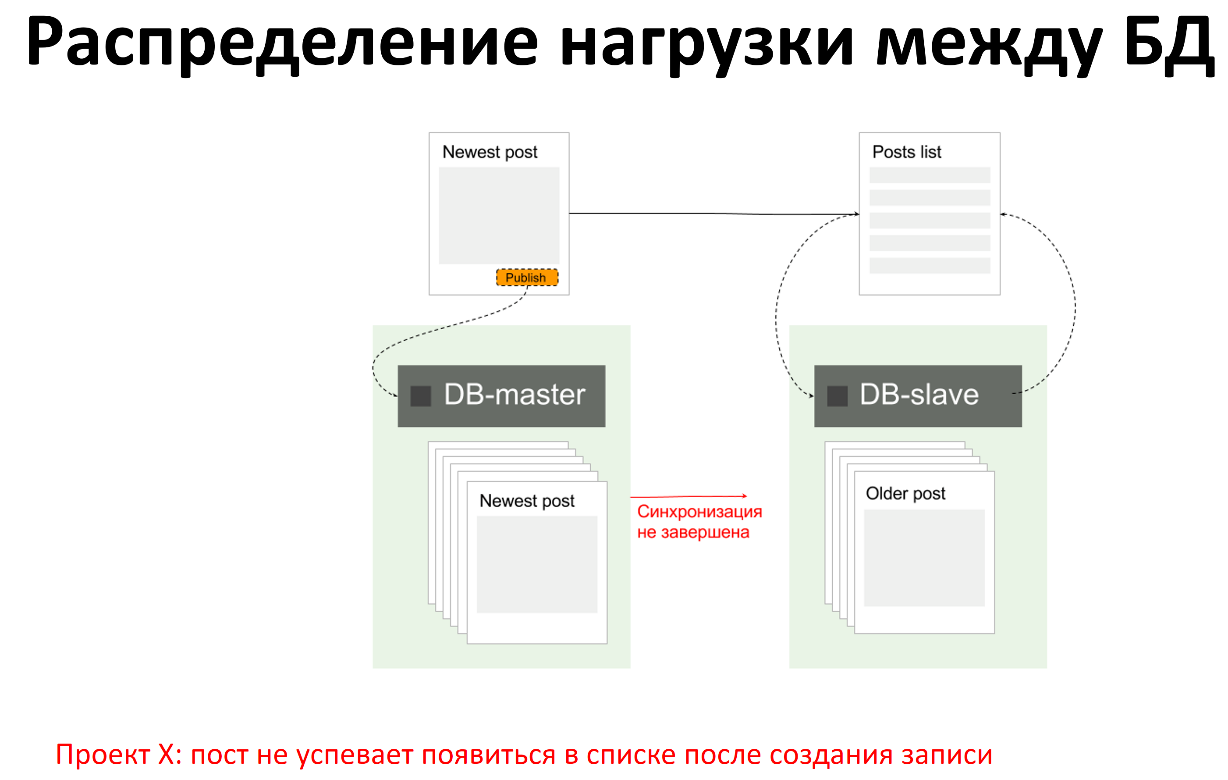
Какие у нас бывают проблемы, когда мы используем несколько инстансов серверов баз данных?
Самая частая проблема, например, когда у нас есть запись на master, есть чтение со slave. Когда мы записали что-то на master, в это время приложение прочитало что-то со slave, но изменения ещё не отреплицировались и slave ещё не знает о том, что мы что-то записали на master. В этом случае мы получим неактуальные данные со slave.
В этом случае мы понимаем, что нам нужно:
- Мониторинг статус репликации (работает она или нет)
- Мониторинг отставания репликации, бывают ситуации что репликация есть, но из-за нюансов и факторов она имеет задержку в сутки или больше
- Мониторинг консистентности репликации (данные на slave соответствуют данным на master)
Синхронная репликация не является достаточным основанием для уверенности в том, что все будет хорошо.
В целом идея записать что-то в master, а затем прочитать это со slave не совсем хорошая, потому что к проблемам с целостностью данных. Но мы довольно часто это видим, хочется этого как-то избегать.
Когда мы используем балансировку нагрузку на веб-проект между несколькими веб-нодами у нас могут возникнуть разные проблемы. Например, в качестве входной точки часто используют единый балансировщик нагрузки, то есть на него указывают А-запись, трафик через него балансируется между веб-нодами. В этом случае балансировщик является точкой отказа. В случае его падения проект схлопнется, потому что некому будет балансировать нагрузку между веб-нодами.
Есть такой тонкий, деликатный момент. Балансировка трафика между вашими веб-нодами она должна быть настроена с учетом failover’a. То есть когда мы балансируем, приложение которое осуществляет балансировку оно должно постоянно опрашивать веб-ноды на случай если какая-то из-них откажет, то она должна быть исключена из процесса балансинга. Иначе, может получится нехорошая ситуация, когда у нас половина проекта загрузилась, а половина нет. Потому к половину ресурсов были отбалансированы на ту веб-ноду, которая упала часа 3 назад.
Что же делать с файлами?
В наше время, когда очень много медиа, картинок, видео на проектах. Очень хочется иметь общее хранилище, которое будет подключено ко всем web-nod’ам и каждая web-nod’а сможет по отдельности работать с файлами, записывать, читать. Что же делают в этом случае?
Самым простым и понятным решением кажется использование NFS, этой технологии много лет, много где используется, у каждого на слуху, почему бы и не использовать? Проблем с синхронизаций там не было, настройка проще не куда. Очень часто начинают использовать эту технологию.
С NFS есть проблемы, глобальные. В случае, когда у нас между серверами, между master’ом NFS веб-нодами, на которое это NFS подмонтирована, нарушилась связь. Либо в случае, например, когда нам пришлось перезагрузить NFS master, нам необходимо перезагружать и веб-ноды. Почему? Потому что, монтирование зависает и с этой точкой ничего нельзя сделать, пока сервер не будет перезагружен физически. Эта давняя проблема NFS, она повсеместно встречается, адекватного решения для этого нет, в рамках NFS.
Отдельно интересная тема, это то как организуется деплой проектов. По сути у нас 1-2 сервера, у нас нет сложности выложить код с простого git pull’a и простого скрипта, который сохранит предыдущие версии проекта в одном месте, деплой в новое и сменит всем линк. Но git pull это не очень интересно. CI гораздо интереснее. Очень часто среди наших клиентов, небольшие проекты пытаются внедрять CI раньше, чем им это нужно. На то чтобы создать продвинутую систему деплоя с continuous integration / delivery уходит очень много ресурсов, которые создают дополнительную сложность.
Во-первых, самая частая ошибка, которую мы видим, есть крутая система деплоя. Люди выкладывают новый код и не могут одной кнопкой сделать откат кода, при этом у них обычные реляционные базы, они накатывают миграции, в рамках деплоя не учитывают, что эти миграции могут привести к тому что новая версия БД не сможет работать со старым кодом. После выкладки деплоя выясняется нужно срочно откатиться, потому что всё сломалось. Мы откатываем на старый код, а старый код не может работать с новой базой, но продолжает писать какие-то данные. Мы снова ставим новую версию, чтобы хоть как-то выжить, у нас уже есть данные со старой версии, которые снова записались, данные с новой версии, которые тоже записались, все перемешалось и непонятно как жить. Есть overhead на то чтобы создать, внедрить и поддерживать эту систему.
По сути мы внедряем новую систему, надо проверить что она работает. Проверить, что она сама не выложит код, а не превратит wwwroot в пустое место, как было у некоторых наших клиентов. Дополнительная сложность вовремя деплоя, если мы сделали какую-то систему выкладки и не проверили, что она хорошо работает, тот же самый откат на production’e. Как проверить, что вы откатитесь? Нужно выбрать время, а если этот проект, который начинает приносить деньги, то никто не хочет подвергать проект риску, все думают, что всё будет работать, а когда нужно будет сможем откатиться. В итоге создаются проблемы, обязательно нужно проверить возможность отката и проверить, что у вас всё работает. Лучше на этом этапе придерживаться простых решений, скриптом выкладывать новую версию кода и с этим жить.
На этапе, когда мы подходим к тому, что наш проект, стал среднего размера, уже немаленький, но уже и не крупный. У нас назревает вопрос, что надо что-то делать с NFS, на что её заменить?
Из того, что попадется под руки, это CEPH. Его можно использовать, все хорошо, отзывы положительные. Но CEPH достаточно сложна в настройке, если не знать мелочей, нюансов и тонкостей в настройтре CEPH, то мы на выходе можем столкнуться с тем, что эта файловая система работает не так, как мы от нее ожидаем. Для того чтобы научиться с ней работать нужно затратить много человеко-ресурсов, много времени. Поэтому можно использовать что-то легкое, например, MOOSEFS. Почему нет?
Всё идеально, конфигурируется элементарно, в ней копятся какие-то данные, хранилище размазано по нескольким nod’ам, которые отведены только для хранения файлов, везде всё примонтировано, всё замечательно и работает. Но, внезапный сбой по питанию. В дата центре отрубился основный канал, генератор подхватил, но немного позже, чем надо было для того чтобы сервер не вырубился.
Что же у нас случается?
У нас случается ситуация, когда у нас несколько десятков терабайт статики, которые размазаны по нескольким серверам, они должны друг с другом синхронизироваться после сбоя по питанию, после того как они поднялись и т.д. Прошло 2 дня, мы думаем, много файлов, думаем, что нужно еще немного подождать, прошло 4 дня, на 90% синхронизация MOOSEFS упала и начала синхронизироваться заново. Проект уже 5 дней без статики, это не очень хорошо. Мы начинаем искать решение проблемы. Мы находим решение проблемы на китайском форуме, на котором три поста в треде посвящено тому, как починить эту файловую систему в подобной ситуации. Там всё на китайском, все доходчиво, есть образцы конфигов, всё хорошо расписано.
Онлайн переводчик немного переврал смысл, но скорее всего всё хорошо. Мы не можем работать с такой файловой системой, у которой такая поддержка. Поэтому мы по-прежнему работаем с MOOSEFS, в случае сбоев по питанию, мы молимся и плачем. Вопрос с выбором замены до сих пор открытый.
У нас к этому моменту уже есть система деплоя, более-менее отлаженная. Это могут быть скрипты, может быть это CI и это всё работает. Но у нас есть ошибки деплоя, в production проскакивают иногда. Бывает, что prod валяется с 500 ошибкой из-за бага в коде. С чем это может быть связано?
Например, у нас есть база данных на dev и на prod окружениях, за одним тонким нюансом. На prod окружении в базе данных у нас 10 гигабайт данных, а на dev окружении 50 мегабайт. Например, на dev’e тысяча записей в табличках, с которыми мы работаем, а на prod’e миллион. Соответственно, когда у нас запросы выполняется на dev’e он отрабатывает за сотые доли секунды, а на prod’e он может занимать десятки секунд.
Еще один тонкий момент. Когда мы тестируем код на dev окружении, мы тестируем код на окружении, на котором работает только тестирование этого кода. Там нет сторонней нагрузки. На prod’e нагрузка всегда есть. Поэтому всегда стоит учитывать, что те результаты, которые вы получили на dev’e без нагрузки, на prod’e могут быть другими. То есть когда нагрузка от вашего нового кода совпадет с общей нагрузкой системы, результаты могут вас не порадовать.
Так же часто случается. На dev’e все оттестировали, всё работает, базы данных одинаковые, всё замечательно, всё должно работать, нагрузка не должна пошатнуться, все хорошо, за одним тонким исключением, мы деплоимся на prod, а у нас ошибка 500. Почему так? Потому что у нас не установлен какой-то модуль или какое-то расширение, настройка где-то не прописана. У нас разная конфигурация ПО. Это также стоит учитывать.
Это встречается реже, но встречается. Например, у нас скрипт работает на dev сервере на одном ядре, оно, например, 4 ГГц, на нем быстренько отработал и всё хорошо. А prod’e ядер много, но они все по 2 ГГц, время исполнения кода на одном ядре не тоже самое, что было на dev сервере. Такие нюансы в различие конфигураций железа dev и prod серверов тоже стоит учитывать и делать на них скидку.
?
Камень преткновения — это высокая нагрузка на базы данных
Это одна из самых наиболее встречаемых задач в нашей практике. Как же избавится от нагрузки на базу данных?
Первое, что приходит на ум это поставить более мощное железо. Более мощный процессор, больше памяти, быстрые диски и проблема решится сама. На самом деле нет. Потому что рано или поздно мы упремся и в это железо и наступит какой-то потолок.
Тюнинг сервера. Отлично решение проблемы, когда программисты приходят к системным администраторам и говорят, что сервер базы данных настроен не оптимально. Если подправить эти настройки, то всё образуется, запросы станут выполнятся быстрее и всё станет лучше.
Все наши проблемы будут исправлены с помощью перехода на другую СУБД. То есть, например, у нас MySQL тормозит, если мы перейдем на PostgeSQL, а лучше на MariaDB мы все эти проблемы исправим как класс, всё будет работать быстро, идеально и т.д. Проблему искать стоит искать не в СУБД, а копнуть глубже логически.
Что мы делаем, чтобы понять в чем у нас камень преткновения?
С чем связно то, что база данных начала генерировать довольно большую нагрузку и железо не справляется. Нам надо собрать статистику, для начала понять какие запросы выполняются дольше всего. Мы накопили некий пул запросов для того, чтобы их проанализировать. Какие-то запросы сформировать, чтобы выявить общие черты и т.д.
Также необходимо составить статистику по числу запросов. Например, если у нас база данных тормозить только с 3 до 4 по полуночи, то возможно в этот момент происходит импорт где у нас количество insert’ов в базу данных возрастает на порядок. Так же стоит задуматься о кластеризации данных. Яркий пример, у нас есть табличка со статистикой. Допустим, она хранится за последний год. Мы постоянно делаем из неё выборки, 95% этих выборок касаются только последней недели. Возможно, имеет смысл данные из этой таблицы кластеризовать таким образом, чтобы у нас было 12 разных табличек, каждая из них бы хранила данные за конкретный месяц. В этом случае, когда мы будем делать какую-то выборку у нас будут браться данные из одной таблички, где будет условно в 12 раз меньше записей.
Самое интересное – это то, что происходит на крупных проектах
Поскольку там не технологические ошибки, которые мы видим часто, а там есть несколько течений. Проект вырос, хочется экспериментировать, хочется, чтобы всё работало само по себе, и мы могли с этим жить.
Первое, что мы видим это любовь технических специалистов к новым технологиям. Проект большой, всё работает понятно, задачи регулярные, хочется придумать что-то действительно новое. Поскольку люди хотят, чтобы работать им было интересно. Есть несколько цитат, которые, мы берем в свои игры чата техподдержки, где людям хочется использовать какую-то технологию, но не знают для чего её применять. Хотим использовать docker и consul в своём проекте. Раскидаем сервисы по docker’y, будем через consul понимать кто, куда будет ходить. Consul положим в один из docker’ов, если consul упадет мы всё потеряем, но с этим можно жить.
Давайте обновлять конфигурацию только через chef, если нам срочно придется раскидать какую-то конфигурацию и где-то chef клиенты у нас упадут, нам придется сначала наладить chef клиент, но мы сможем централизованно обновлять конфигурации. Но обновить отдельно что-то по серверам будет сложно, но это будет хорошо.
Давайте сделаем кластер. Это интересная шутка, когда людям хочется сделать кластер из чего-то. Давайте сделаем кластер из RabbitMQ и будем читать данные оттуда и оттуда и всё будет отказоустойчивое. Если один из RabbitMQ упадет, второй будет жить, на самом деле нет, но ничего страшного.
Любовь к новым технологиям
Нельзя использовать технологии ради технологий. Прекратите это в какой-то мере, но я уверен, что это не прекратится, потому что нам всем хочется пробовать новое, но иногда нужно пытаться удержать себя.
В большом проекте простые действия становятся гораздо сложнее. Если мы знаем, что хотим всегда использовать новый софт, если на каком-то старом нашем проекте, где один сервер всё было хорошо, то на новом все обновить это сложные операции и это занимает не 2 часа, а может занимать несколько недель, особенно плохо, если мы решим это сделать в production силами разработчиков, а не слаженной командой, которая продумала как это обновлять.
Вторая болезненная штука, которая становится модной сейчас это вера в то что автоматизация работает и админы не нужны. Наш кластер будет отказоустойчивым, мы будем балансировать между всеми веб серверами, а наши load-балансеры будут работать. Если мы это делаем в amazon web service, у нас падает весь регион, падает все балансеры, все инстансы, всё становится плохо.
«Оно само перебалансируется в случае аварии». Очень частая штука, которую мы видим, когда автоматическая балансировка приводит к тому, что с одного места на другое должны перекинуться, но почему-то перекидываться на тот же код, который уже тормозит, либо начинает перекидываться между инстансами, которые все тормозят вместе, либо просто в никуда. Проект начинает идти в систему, которой не существует.
Наш стэк технологий полностью исключает такую ситуацию. Решение, про которое мы прочитали на stackoverflow, reddit’e и Хабрахабре, не может врать.
Буквально года два назад я здесь делал доклад про наш опыт использования OpenStack, когда очень много компаний хотели использовать OpenStack, потому что классно использовать штуку, которая позволит тебе взять несколько больших машин и спокойно как в amazon’e на них раскидывать виртуалки, очень просто и удобно. К сожалению, в OpenStack’e того времени, когда ты запускаешь инстанс и удаляешь его, то после этого нельзя будет не запускать, не удалять до тех пор, пока ты не перезапустишь несколько daemon’ов OpenStack’a.
Нам было интересно в какой момент это происходит. У некоторых работает, у других нет. Потому что ребята, которые сказали, что у нас OpenStack работает отлично, у нас есть 4 человека на fulltime’e которые его поддерживают. Они регулярно смотрят, что он OpenStack работает, если не работает начинают его быстро чинить. Те люди, которые говорят, что та или иная технология работает, у них либо есть достаточные ресурсы для этого чтобы эту технологию использовать, либо не знают, что эта технология может сломаться и верят в это, либо возможно они зарабатывают на этом деньги, тот же docker получает огромные инвестиции.
Как же с этим жить?
Я предпочитаю не верить в то, что оно может само не падать, что так или иначе оно никогда не сломается и само будет перебалансироваться. Кроме того, как быть параноиком мы советов дать не можем.
Очень интересная вещь в работе больших проектах. Выкладки идут постоянно, бизнес хочет постоянных изменений. Мы сделали хороший проект, который живет, там нечему особо тормозить, поэтому мы забываем про регулярные оптимизации. У одного из клиентов на одной из выкладок в итоге произошла выкладка где на одной из страниц генерировала 8 тысяч запросов sql.
Частые деплои. Они настолько частные что не видно изменений.
Что получается на практике?
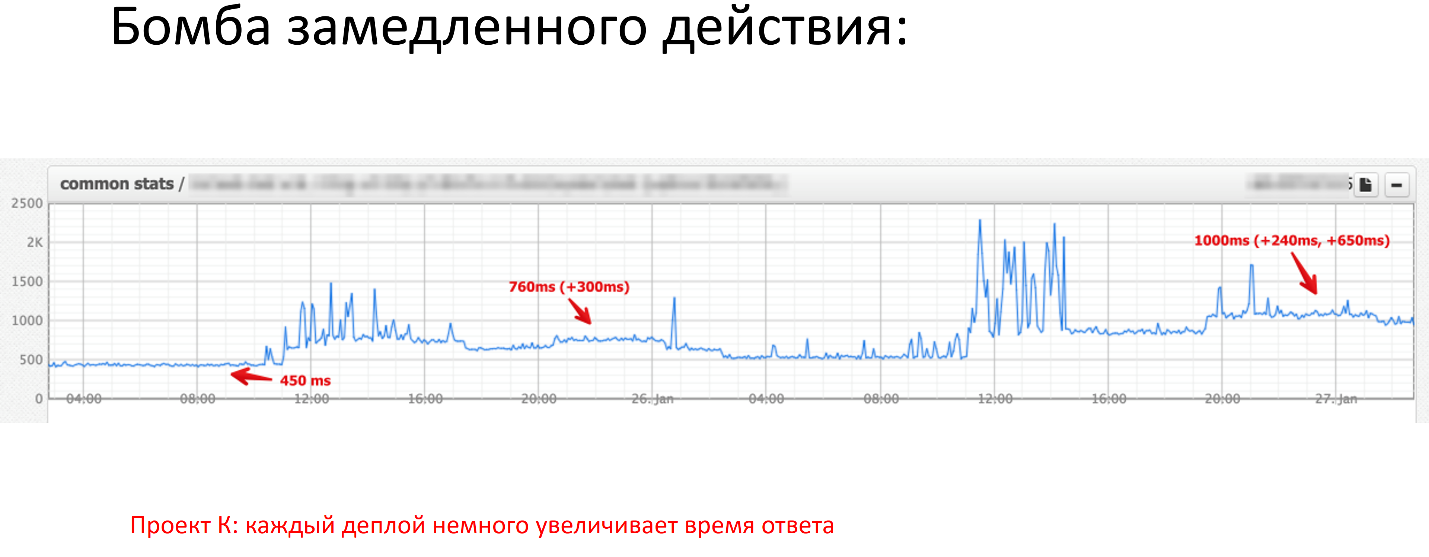
Если мы посмотрим на график за последние несколько часов, у нас было 3 деплоя. Первый деплой сделал лишь немного, добавив 300 миллисекунд к 450 миллисекундному ответу, следующий деплой добавил еще 240 миллисекунд, следующий уже суммарно 650 миллисекунд.
Мы уже получили секундный ответ, всё плохо
Большие проекты не проверяют то, как в итоге это все будет на production’e не только тестирование деплоя, но и повышением нагрузки каким-то тестированием. На самом деле многие хотят это сделать и научиться это делать, но мало кто действительно это делает. Будет классно если многие большие проекты научатся нагрузочно тестировать хотя бы мажорные версии выкладок кода.
Вместо выводов
- Не всё новое – хорошее.
- Не всё что интересно – нужное.
- Не всё что крутое – полезное.
Во многой мудрости много печали, потому что новые технологии крутые, когда мы хотим что-то использовать иногда это, действительно помогает. Иногда не стоит бояться нового.
Дополнение по поводу паранойи в деплое в крупных проектах. Когда у вас много трафика вы имеете возможность протестировать свой деплой, каким образом? Вы можете новый код выкатить на сервера, куда направите часть ваших посетителей, условно 10%, посмотрите не возникнет ли резких пиков нагрузки от того, что пользователь начнет тыкать какую-то кнопочку и т.д. подобная схема деплоя, когда мы делаем разделение клиентов и часть отправляем в качестве фокус группы отправляем на новый код, это довольно широко применяется и может помочь избежать довольно многих проблем основной части клиентов. Гораздо лучше протестировать на 10%, чем на 100%.
Евгений Потапов и Антон Баранов — Преждевременная оптимизация архитектуры
Комментарии (9)

ntkj666
21.02.2017 05:45-60.2*0.05=0.01

Alexprintme
21.02.2017 12:29Произведением событий А и В называется событие АВ, которое наступает тогда и только тогда, когда наступают оба события: А и В одновременно. Вы нашли вероятность двух неполадок одновременно.
ntkj666
22.02.2017 03:42В статье — «сложность системы (то есть риск того что она может не выдержать) — это не вероятность того, что система попадет в аварию, не самая меньшая вероятность этой системы, не какого-то из компонентов этой системы, а произведение вероятностей риска каждого из компонентов».
mkll
21.02.2017 17:05+1Удивился, узнав, что кто-то использует NFS вместо CDN. Не — серьезно?
Удивился, что облака не масштабируются, потому что облачный VPS находится на физическом сервере с конечными параметрами, при этом утверждается, что как раз физический сервер масштабируется прекрасно. Что начинать проект надо прям сразу с физического сервера (при этом, надо полагать, закладывая его параметры сразу под будущий предел масштабирования?). С виртуализацией работать не надо — с ней одни только проблемы. Ну и вообще по тексту таких мини-удивлений было изрядно.
Прям мировоззрение перевернулось.

catanfa
21.02.2017 17:43сложность системы — это… произведение вероятностей риска каждого из компонентов.
Похоже на ошибку. В примере с 0.2 (20%) и 0.05 (5%) ответ 24% получается так
1 - (1 - 0.2) * (1 - 0.05)
но никак не "произведением вероятностей"

KorP
23.02.2017 21:10Про облака — поржал. ИМХО если вам требуется сервер под какую то одну задачу на 100+ ядер и более 1,5Пт памяти — вы что то делаете не так :)
Сейчас наоборот все говорят о том, что приклад нужно дробить на множество мелких частей, и в данном случае виртуализация как раз и решает.
VMichael
Немного не коррелирует заголовок, в остальном отличный доклад.