

На конференции HighLoad++ 2016 руководитель разработки «М-Тех» Вадим Мадисон рассказал о росте от системы, для которой сотня микросервисов казалась огромным числом, до нагруженного проекта, где пара тысяч микросервисов — обыденность.
Тема моего доклада — то, как мы запускали в продакшн микросервисы на достаточно нагруженном проекте. Это некий агрегированный опыт, но поскольку я работаю в компании «M-Tех», то давайте я пару слов расскажу о том, кто мы.
Если коротко, то мы занимаемся видеоотдачей — отдаём видео в реальном времени. Мы являемся видеоплатформой для «НТВ-Плюс» и «Матч ТВ». Это 300 тысяч одновременных пользователей, которые прибегают за 5 минут. Это 300 терабайт контента, который мы отдаем в час. Это такая интересная задача. Как это всё обслужить?
Про что сама эта история? Это про то, как мы росли, как проект развивался, как происходило какое-то переосмысление каких-то его частей, какого-то взаимодействия. Так или иначе, это про масштабирование проекта, потому что это всё — ради того, чтобы выдержать ещё больше нагрузки, предоставить клиентам ещё больше функционала и при этом не упасть, не потерять ключевых характеристик. В общем, чтобы клиент остался доволен. Ну и немного про то, какой путь мы прошли. С чего мы начинали.

Вот такая стартовая точка, некая такая отправная, когда в Docker-кластере у нас было 2 сервера. Тогда базы данных запускались в том же кластере. Чего-то такого выделенного в нашей инфраструктуре не было. Инфраструктура была минимальна.

Если посмотреть на то, что было в нашей инфраструктуре основного, то это Docker и TeamCity как система доставки кода, сборки и так далее.
Следующей вехой — то, что я называю серединой пути — был достаточно серьезный рост проекта. Когда у нас стало уже 80 серверов. Когда мы построили отдельный выделенный кластер под базы данных на специальных машинах. Когда мы стали переходить к распределенному хранилищу на базе CEPH. Когда мы стали задумываться о том, что, возможно, пора пересмотреть то, как наши сервисы взаимодействуют между собой, и вплотную подошли к тому, что нам пора менять нашу систему мониторинга.
Ну и собственно то, к чему мы пришли сейчас. В Docker-кластере уже несколько сотен серверов — сотни запущенных микросервисов. Сейчас мы пришли к тому, что мы начинаем делить нашу систему на некие сервисные подсистемы на уровне шин данных, на уровне логического разделения систем. Когда этих микросервисов стало слишком много, мы стали дробить систему для того, чтобы лучше ее обслуживать, лучше понимать.
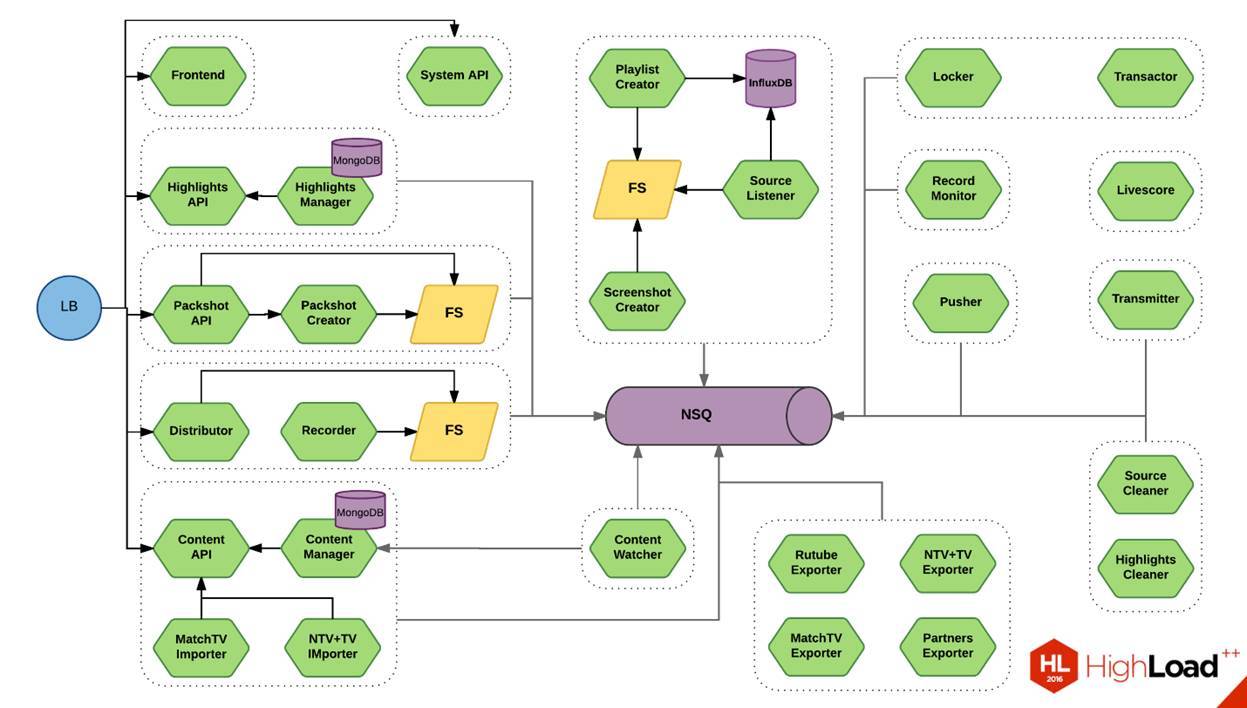
Сейчас на экране вы видите схему. Это один небольшой кусок нашей системы. Это штука, которая позволяет нарезать видео. Похожую схему я показывал полгода назад на «РИТ++». Тогда зеленых микросервисов было, по-моему, 17 штук. Сейчас их здесь 28. Если примерно посмотреть, это 1/20 нашей системы. Можно представить себе примерные масштабы.
Подробности
Один из интересных моментов — это транспорт между нашими сервисами. Классически начинают с того, что транспорт должен быть максимально эффективным. Мы тоже про это подумали, решили, что protobuf — это наше всё.
Выглядело это примерно так:
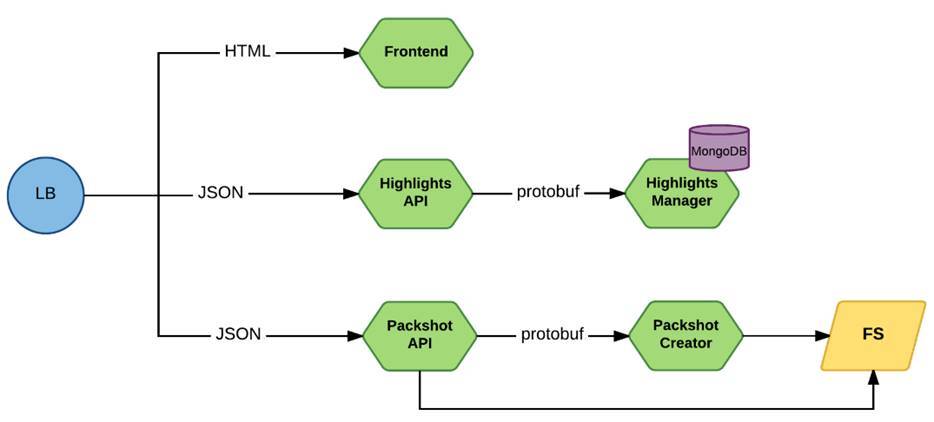
Запрос через Load Balancer приходит на фронтовые микросервисы. Это либо Frontend, либо сервисы, которые предоставляют непосредственно API, они работали через JSON. А ко внутренним сервисам запросы шли уже через protobuf.
Сам по себе protobuf — это такая достаточно неплохая штука. Он действительно дает определенную компактность в messaging. Сейчас уже есть достаточно быстрые реализации, которые позволяют с минимальными накладными расходами сериализовать и десериализовать данные. Можно считать его условно типизированным запросом.
Но если посмотреть в разрезе микросервисов, то заметно, что у вас между сервисами получается некое подобие проприетарного протокола. Пока у вас 1, 2 или 5 сервисов, вы под каждый микросервис можете спокойно выпускать консольную утилиту, которая будет позволять вам обращаться к конкретному сервису и проверять, что она возвращает. Если он что-то затупил — дёрнуть его и посмотреть. Это несколько усложняет работу с этими сервисами именно с точки зрения поддержки.
До какого-то этапа это не было какой-то серьезной проблемой — сервисов было не так много. Плюс ребята из Google зарелизили gRPC. Мы посмотрели, что, в принципе, для наших целей на тот момент он делал всё, что нам было нужно. Мы потихоньку на него мигрировали. И бамс — в нашем стеке появилась ещё одна штуковина.

Здесь тоже достаточно интересная деталь в реализации. Эта штука — на базе HTTP/2. Это вещь, которая реально работает из коробки. Если у вас не очень динамичная среда, если у вас не меняются инстансы, не переезжают по машинам достаточно часто, то это, в общем-то, хорошая штука. Тем более, что в данный момент есть поддержка под кучу языков — как серверных, так и клиентских.
Теперь если взглянуть на это в разрезе микросервисов. С одной стороны, штука хорошая, а с другой — это вещь в себе. Вплоть до того, что когда мы стали стандартизировать наши логи для того, чтобы их агрегировать в единой системе, мы столкнулись с тем, что напрямую в удобном виде из gRPC логи получить нельзя.
В итоге мы пришли к тому, что мы написали собственную систему логирования, подсунули её в gRPC. Она у нас делала парсинг выдаваемых через gRPC сообщений, приводила их к нашему виду, и вот тогда мы могли это засунуть в нашу систему логирования нормально. И плюс ситуация, когда вы описываете сначала сервис и типы к этому сервису, потом их компилируете, повышает зависимость сервисов между собой. Для микросервисов это некая проблема, такая же, как и некая сложность версионирования.
Как вы уже, наверное, догадались, в итоге мы пришли к тому, что мы стали задумываться про JSON. Причём мы сами долгое время не верили в то, что после какого-то компактного, условно бинарного протокола мы вдруг вернёмся в JSON, пока не наткнулись на статью ребят из DailyMotion, которые писали примерно про то же самое: «Блин, мы тоже умеем готовить JSON, его умеют готовить все на свете, зачем мы создаём себе дополнительные сложности?»

В итоге мы постепенно начали мигрировать с gRPC на JSON в некой своей реализации. То есть да, мы оставили HTTP/2, мы взяли достаточно быстрые реализации для работы с JSON.
Получили все те плюшки, которые мы имеем. Мы можем обратиться к нашему сервису через сURL. Наши тестеры пользуются Postman, и у них тоже все хорошо. На любом этапе работы с этими сервисами у нас стало все просто. Это та штука, которая с одной стороны, спорное решение, а с другой — в обслуживании действительно сильно помогает.
По большому счету, если посмотреть на JSON, то единственный реальный минус, который ему можно предъявить прямо сейчас — это недостаточная компактность этого описания. Те 30%, которые, как статистически утверждается, являются разницей между тем же MessagePack или еще чем-то, на самом деле по нашим замерам, разница не настолько большая, а также это не всегда настолько критично, когда мы говорим о поддерживаемой системе.
Плюс с переходом на JSON мы получили дополнительные плюшки. Такие, как, например, версионирование протокола. В какой-то момент у нас начала складываться ситуация, что через тот же protobuf мы описываем какую-то новую версию протокола. Соответственно, клиенты, потребители данного конкретного сервиса, тоже должны на неё переехать. Получается, что если у вас несколько сотен сервисов, даже 10% из них должны переехать. Это уже большой каскадный эффект. Вы в одном сервисе поменяли, а ещё 10 нужно переделать.
В итоге у нас начала складываться ситуация, когда разработчик этого сервиса выпустил уже пятую, шестую, седьмую версию, а реально нагрузка в продакшне идёт до сих пор на четвертую, потому что у разработчиков смежных сервисов свои дедлайны и приоритеты. Они просто не имеют возможности постоянно пересобирать сервис, переезжать на новую версию протокола. Реально получилось, что новые версии выпускаются, но они не востребованы. Зато баги в старых версиях мы должны реализовывать какими-то непонятными путями. Это усложняло поддержку.
В итоге мы пришли к тому, что перестали плодить версии протоколов. Зафиксировали некую базовую версию, в рамках которой мы можем добавлять какие-то property, но в каких-то очень ограниченных пределах. И сервисы потребителей стали пользоваться JSON-схемой.
Вот так примерно она выглядит:

Вместо 1, 2 и 3 у нас стала версия 1 и та схема, которая к ней относится.

Вот типичный ответ одного из наших сервисов. Это Content Manager. Он выдал информацию о трансляции. Вот, например, схема одного из потребителей.
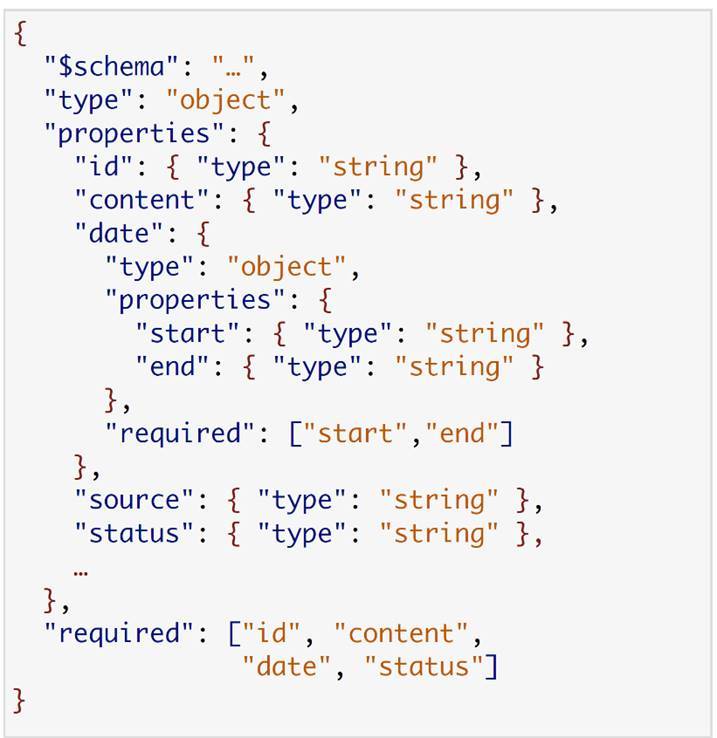
Здесь самая интересная строчка — нижняя, где у нас блок required. Если мы посмотрим, то мы увидим, что этому сервису на самом деле из всех этих данных нужно только 4 поля — id, content, date, status. Если реально применить эту схему, то в итоге сервису потребителя нужны только эти данные.

Они действительно есть в каждой версии, в каждой вариации первой версии протокола. Это упростило переезд на новые версии. Мы стали выпускать новые релизы, и миграция потребителей на них сильно упростилась.
Следующий, немаловажный момент, который возникает, когда мы говорим о микросервисах, да и, в общем-то, о любой системе. Просто в микросервисах это чувствуется сильнее и быстрее всего. Это ситуации, когда система становится нестабильна.
Когда у вас цепочка вызовов 1—2 сервиса, то особых проблем нет. Какую-то глобальную разницу между монолитным и распределённым приложением вы не видите. Но когда у вас цепочка разрастается до 5—7, на каком-то этапе у вас что-то отвалилось. Вы реально не знаете, почему оно отвалилось, что с этим делать. Отлаживать это достаточно сложно. Если на уровне монолитного приложения вы включили debugger, просто прошлись по шагам и нашли эту ошибку, то здесь у вас накладываются такие факторы, как нестабильность сети, нестабильное проведение под нагрузкой и еще что-то. И вот такие вещи — в такой распределенной системе, с кучей таких нод — становятся очень заметны.

Тогда, в начале, мы пошли классическим путём. Мы решили все замониторить, понять, что и где ломается, пытаться с этим как-то оперативно бороться. Мы стали отправлять метрики с наших микросервисов, собирать их в единую базу. Мы через Diamond стали собирать данные по машинам, что на них происходит через сAdvisor. Мы стали собирать информацию по Docker-контейнерам, все это сливать в InfluxDB и строить dashboards в Grafana.
И вот у нас появилось еще 3 кирпичика в нашей инфраструктуре, которая постепенно разрастается.
Да, мы стали больше понимать, что у нас происходит. Мы стали оперативнее реагировать на то, что у нас что-то развалилось. Но разваливаться оно от этого не перестало.
Потому что, как ни странно, основная проблема микросервисной архитектуры — именно в том, что у вас есть сервисы, которые работают нестабильно. То работает, то не работает, и причин тому может быть масса. Вплоть до того, что у вас сервис перегружен, а вы на него дополнительную нагрузку отправляете, он уходит на какое-то время в down. Через какое-то время из-за того, что он всё не обслуживает, нагрузка с него спадает, и он снова начинает обслуживать. Такая чехарда приводит к тому, что такую систему очень сложно и поддерживать, и понимать, что с ней не так.
В итоге мы постепенно пришли к тому, что лучше, чтобы этот сервис падал, чем он вот так туда-сюда скачет. Вот это понимание привело нас к тому, что мы стали менять свой подход к тому, как мы реализуем наши сервисы.
Первый из важных моментов. Мы стали вводить в каждый наш сервис ограничение по входящим запросам. Каждый сервис у нас стал знать сколько он способен обслужить клиентов. Откуда он это знает, я ещё чуть позже расскажу. Все те запросы, что сверх этого лимита или около его границ, он перестаёт принимать. Он выдаёт честные 503 Service Unavailable. Тот, кто к нему обращается, понимает, что нужно выбрать другую ноду — эта неспособна обслужить.
Тем самым мы уменьшаем время запроса в случае, если с системой что-то не так. С другой стороны, повышаем её стабильность.
Второй момент. Если rate limiting на стороне сервиса назначения, то второй паттерн, который мы стали повсеместно вводить — Circuit Breaker. Это паттерн, который мы, грубо говоря, реализуем на клиенте.
Сервис А, у него есть в качестве возможных точек обращения, например, 4 инстанса сервиса B. Вот он сходил в registry, сказал: «Дай мне адреса этих сервисов». Получил, что их 4 штуки. Сходил к первому, тот ему ответил, что всё ок. Сервис пометил «да», к нему можно ходить. По Round Robin он разбрасывает обращения. Пошел ко второму, тот ему не ответил за нужное время. Всё, мы его баним на какое-то время и идём к следующему. Тот, например, у нас возвращает некорректную версию протокола — неважно, почему. Он его тоже банит. Идёт к четвертому.
В итоге получаются 50% сервисов, они реально способны ему помочь обслужить клиента. К этим двум он будет ходить. Те два, которые по какой-то причине его не устроили, он на какое-то время банит.
Это позволило нам достаточно серьезно повысить стабильность работы в целом. С сервисом что-то не так — мы его отстреливаем, поднимается алерт на то, что сервис отстрелили, и мы дальше разбираемся, что могло быть не так.
В ответ на введение паттерна Circuit Breaker у нас появилась еще одна штуковина в нашей инфраструктуре – это Hystrix.
Ребята из Netflix не только реализовали поддержку этого паттерна, но и сделали наглядно, как понять, если с вашей системой что-то не так:
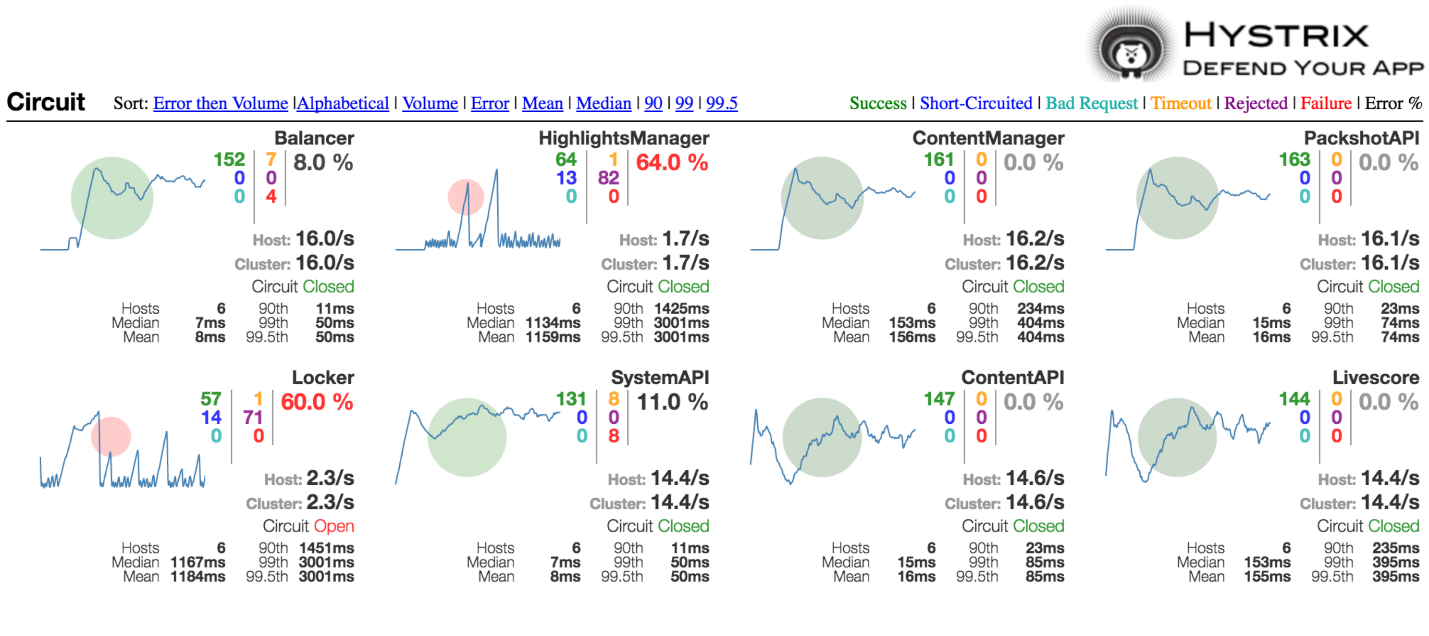
Здесь размер этого кружочка показывает, насколько у вас много трафика относительно других. Цвет показывает, насколько системе хорошо или плохо. Если у вас зеленый кружочек, то, наверное, у вас всё хорошо. Если красный — не всё так радужно.
Примерно вот так выглядит, когда у вас сервис полностью надо отстрелить. На него сработал переключатель.
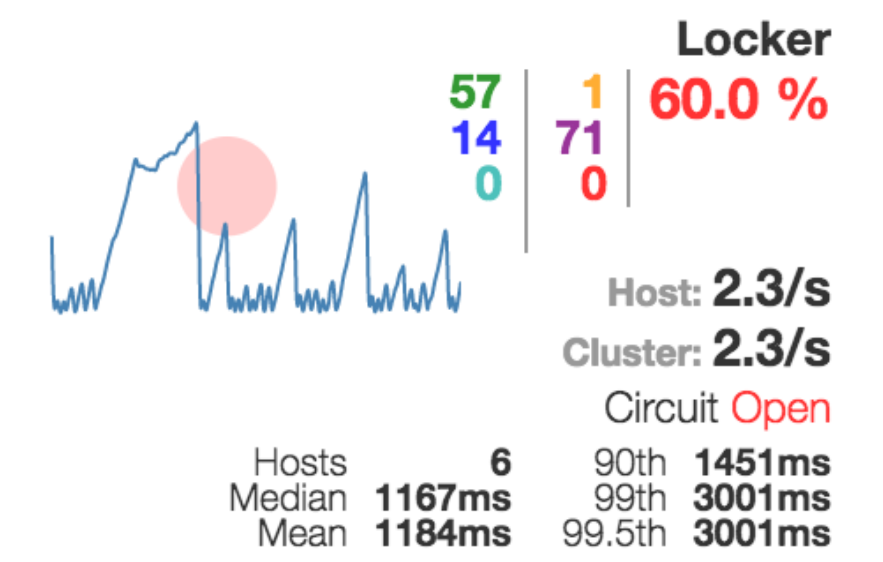
Мы добились того, что у нас система стало более-менее работать стабильно. У нас у каждого сервиса появилось не меньше двух инстансов, чтобы мы могли переключаться, отстреливая один-другой. Но это не дало нам понимания того, что происходит с нашей системой. Если у нас где-то что-то по ходу дела отвалилось при исполнении запроса, то как это понять?
Вот стандартный запрос:
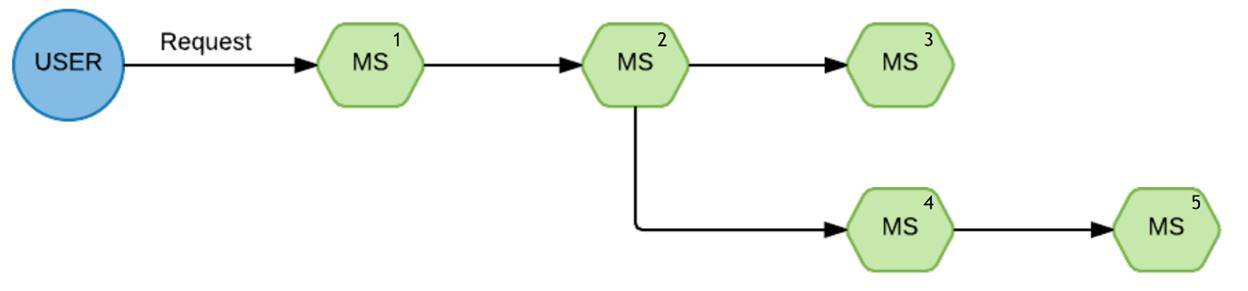
Такая цепочка исполнения. От пользователя пришел запрос на первый сервис, потом на второй, со второго он разошёлся веткой на третий и четвёртый.
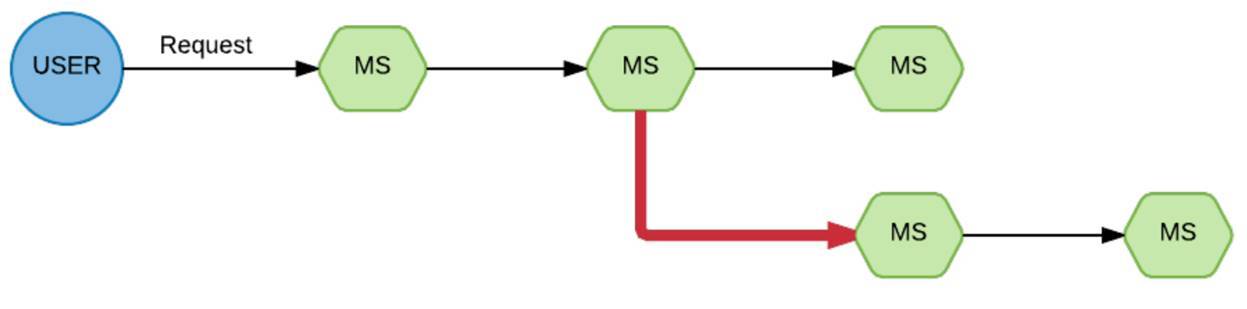
Бац, и у нас одна из веток отпала. Реально непонятно, почему. Когда мы столкнулись с это ситуацией и стали разбираться, что здесь предпринять, как мы можем улучшить видимость ситуации, мы наткнулись на такую штуку, как Appdash. Это сервис трассировки.
Выглядит это вот так:
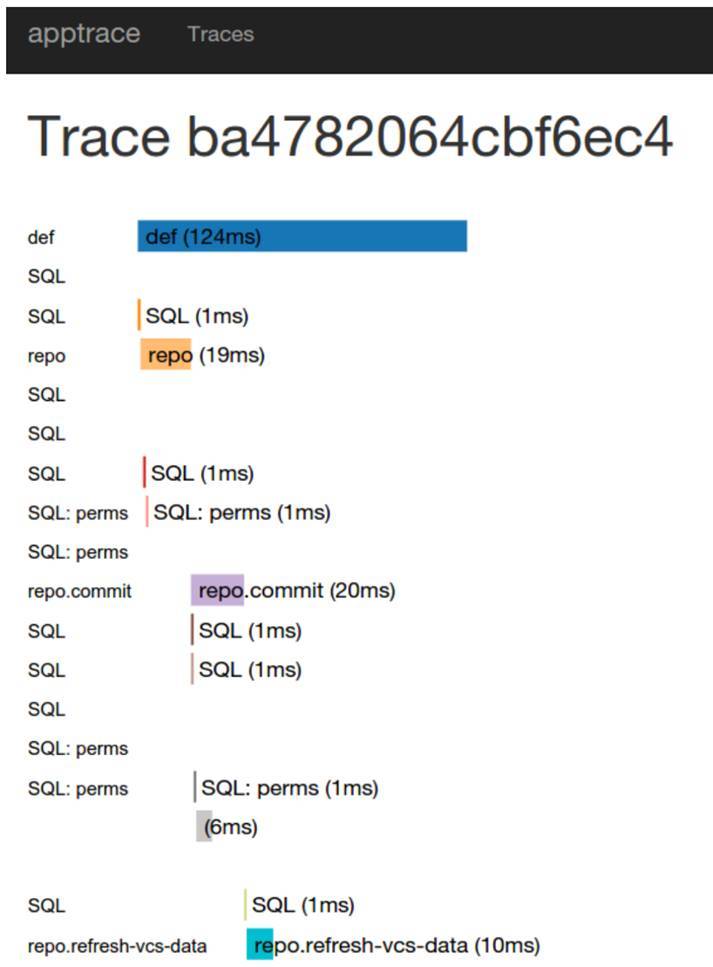
Сразу скажу, это была штука именно на попробовать, понять, то ли это. Имплементировать её в нашу систему было проще всего, потому что мы к тому моменту достаточно плотно перешли на Go. Appdash имел готовую библиотеку для подключения. Мы посмотрели, что да, эта штука нам помогает, но сама реализация нас не очень устраивает.
Тогда вместо Appdash у нас появился Zipkin. Эта та штука, которую сделали ребята из Twitter. Выглядит это примерно так:
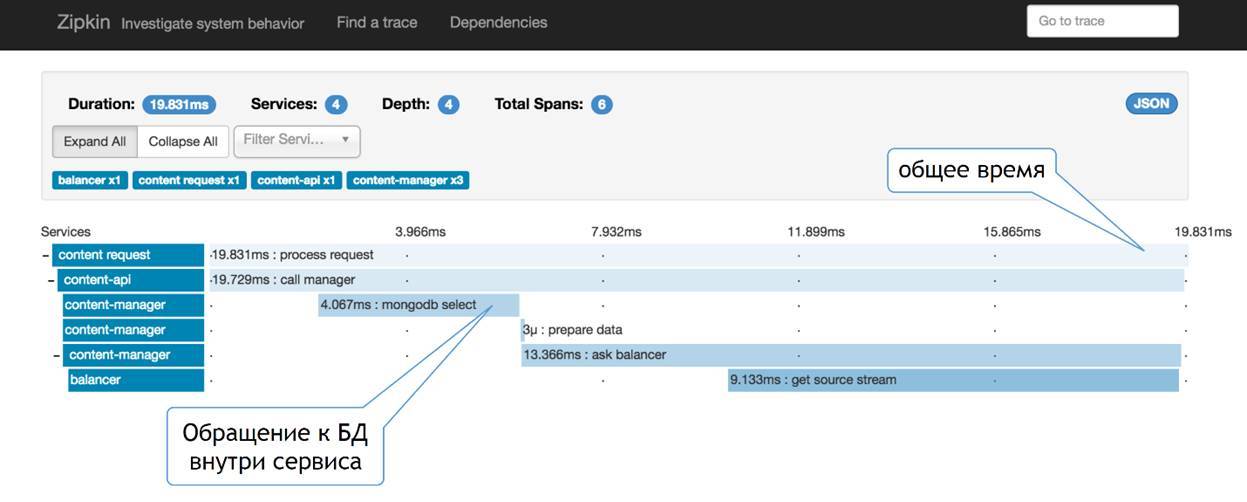
Мне кажется, чуть более наглядно. Здесь мы видим, что у нас есть определённое количество сервисов. Мы видим, как наш запрос проходит по этой цепочке, видим, какую часть в каждом из сервисов этот запрос отъедает. С одной стороны, мы видим некое общее время и деление по сервисам, с другой — никто нам не мешает сюда точно так же добавлять информацию о том, что происходит внутри сервиса.
То есть какая-то полезная нагрузка, обращение к базе, вычитка чего-то там с файловой системы, обращение к кэшам — это всё можно точно так же сюда добавлять и смотреть, что в вашем запросе могло больше всего добавить времени на этот запрос. Та штука, которая позволяет нам этот проброс делать — это сквозной TraceID. Я дальше про него буду немножко говорить.
Вот так мы стали понимать, что у нас происходит в определённом запросе, почему он вдруг падает для какого-то конкретного клиента. У всех всё хорошо и вдруг у кого-то отдельного что-то не так. Мы стали видеть некий базовый контекст и понимать, что у нас происходит с сервисом.
Не так давно на систему трассировки был разработан некий стандарт. Просто некая договорённость между основными поставщиками систем трассировки о том, как нужно реализовывать клиентское API и клиентские библиотеки для того, чтобы можно было эту имплементацию сделать максимально простой. Сейчас уже есть реализация через Opentracing практически под все основные языки. Смело можно пользоваться.
Мы научились понимать, какой из сервисов вдруг не позволил нам обслужить клиента. Мы видим, что какая-то из частей затупила, но не всегда понятно, почему. Контекст недостаточен.
У нас есть логирование. Да, это достаточно стандартная штука, это ELK. Может быть, в небольшой нашей вариации.

Мы не собираем напрямую через кучу forward в виде Logstash. Мы сначала передаём это в Syslog, с помощью Syslog мы это агрегируем на собирающих машинах. Оттуда уже через forward кладём в ElasticSearch и в Kibana. Относительно стандартная штука. В чём фишка?
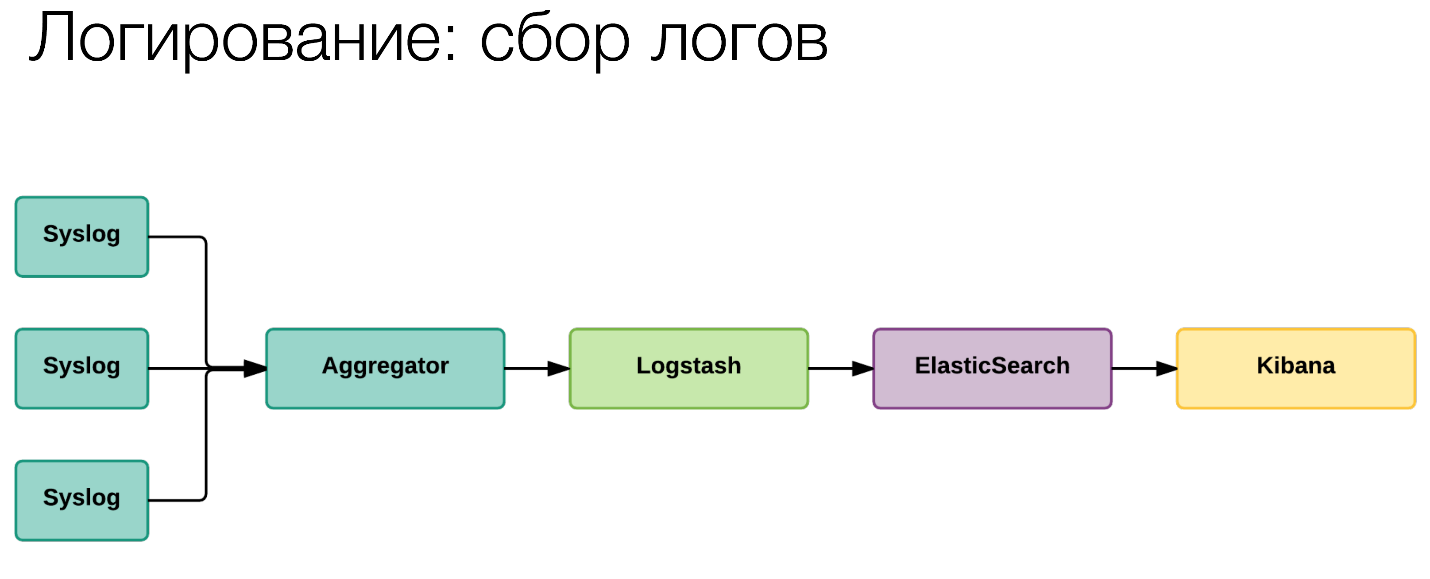
В том, что везде, где это возможно, где мы реально понимаем, что это реально относится к именно этому конкретному запросу, мы в эти логи стали добавлять тот самый TraceID, который я показывал на скрине с Zipkin.
В итоге, мы в логах видим на Dashboard в Kibana полный контекст исполнения по конкретному пользователю. Очевидно, что если сервис попал в prod, то он условно уже рабочий. Он прошёл автотесты, на него уже посмотрели тестировщики, если надо. Он должен работать. Если он в какой-то конкретной ситуации не работает, то, видимо, были какие-то предпосылки. Эти предпосылки в этом подробном логе, который мы видим при такой фильтрации по конкретному trace для конкретного запроса, помогают гораздо быстрее понять, что конкретно в этой ситуации не так. В итоге у нас достаточно серьёзно сократилось время понимания причин проблемы.
Следующий интересный момент. Мы ввели динамический debug mod. В принципе, у нас сейчас не такое дикое количество логов — порядка 100—150 гигабайт, не помню точную цифру. Но это — в базовом режиме логирования. Если бы мы писали вообще супер-подробно, это были бы терабайты. Обрабатывать их было бы безумно дорого.
Поэтому, когда мы видим, что у нас проявилась какая-то проблема, мы заходим на конкретные сервисы, включаем на них через API debug mod и смотрим, что происходит. Иногда мы сначала смотрим, что происходит. Иногда мы отстреливаем сервис, который создает у нас проблему, не выключая его, включаем на нем debug mod и тогда уже разбираемся, что с ним было не так.
В итоге это довольно серьёзно нам помогает с точки зрения ELK-стека, который достаточно прожорлив. На некоторых критичных сервисах мы дополнительно делаем агрегацию ошибок. То есть сервис сам понимает, что для него очень критичная ошибка, что — средне критичная, и сбрасывает это всё в Sentry.
Она достаточно умно умеет агрегировать эти ошибки, сводить по определенным метрикам, делать фильтры по базовым вещам. На ряде сервисов мы это используем. Причем мы это начали использовать со времён, когда у нас были монолитные приложения, которые и сейчас есть. Сейчас вводим на каких-то сервисах именно на микросервисной архитектуре.
Самая интересная штука. Как мы всю эту кухню масштабируем? Здесь нужно рассказать некую вводную. К каждой нашей машине, которая обслуживает проект, мы относимся как некому чёрному ящику.
У нас есть система оркестрации. Мы начали с Nomad. Хотя нет, на самом деле мы начинали с Ansible, со своих скриптов. В какой-то момент этого стало не хватать. К тому времени уже была какая-то версия Nomad. Мы посмотрели, она подкупила нас своей простотой. Мы решили, что это та штука, на которую сейчас можем переехать.
Попутно с ней появился Consul, как registry для service discovery. Также Vault, в котором мы храним секретные данные: пароли, ключи, всё секретное, что нельзя хранить в Git.
Таким образом у нас получилось, что все машины стали условно одинаковы. На машине есть Docker, на ней есть Consul-агент, Nomad-агент. Это, по большому счёту, готовая машина, которую можно брать и копировать один в один, в нужный момент вводить в строй. Когда они становятся не нужны, можно выводить из эксплуатации. Тем более, если у вас cloud, то вы в пиковые моменты машину заранее можете подготовить, включить. А когда нагрузка упала обратно, выключить. Это достаточно серьезная экономия.
В какой-то момент Nomad мы переросли. Переехали на Kubernetes, а Consul стал играть роль системы центральной конфигурации для наших сервисов со всеми вытекающими.
Мы подошли к тому, что у нас сложился какой-то стек для того чтобы автоматически масштабироваться. Как мы это делаем?
Первый шаг. Мы ввели некоторые лимиты по трём характеристикам: память, процессор, сеть.
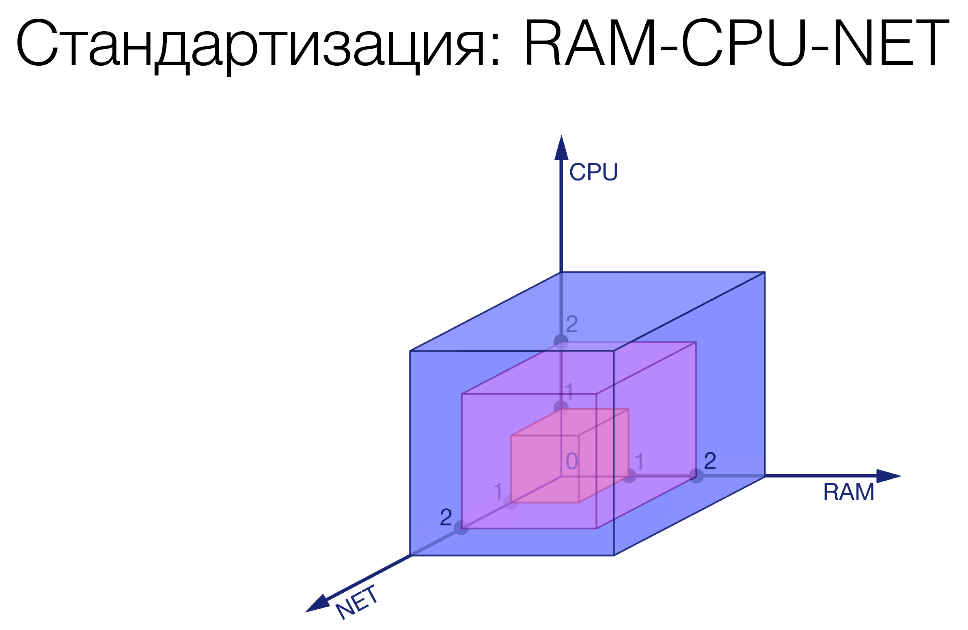
Мы зафиксировали три градации по каждой из этих величин. Нарезаем некие кирпичики. Как пример:
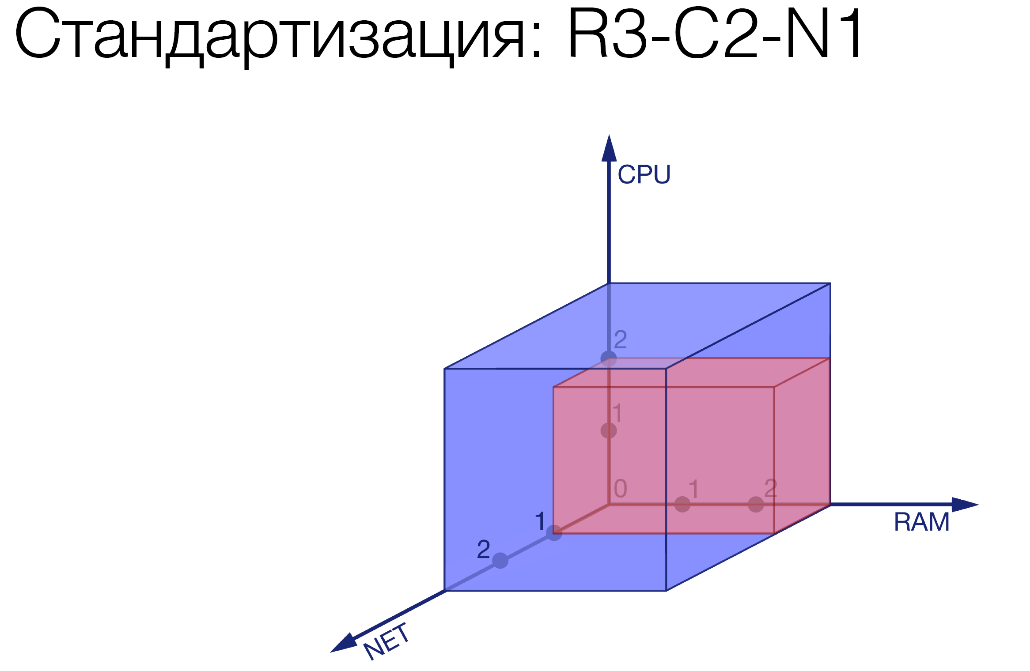
R3-C2-N1. Мы некий сервис ограничили, дали ему совсем чуть-чуть сети, чуть больше процессора и много памяти. Там какой-то прожорливый сервис.
Мы вводим именно мнемоники, потому что конкретные значения мы можем динамически подкручивать достаточно в широком диапазоне уже в нашей системе, который мы называем decision service. На текущий момент эти значения примерно такие:
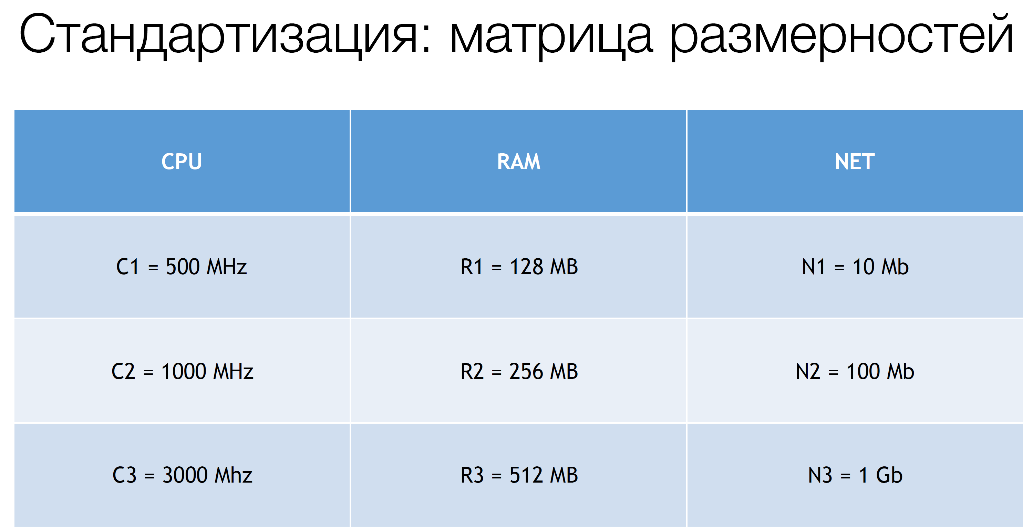
На самом деле у нас есть еще C4, R4, но это те значения, которые совсем выходят за рамки вот этих стандартов. Они оговариваются отдельно.
Это выглядит примерно так:

Следующий подготовительный этап. Мы смотрим, какой тип масштабируемости у этого сервиса.
Самый простой — это когда у вас сервис полностью независим. Вы этот сервис можете линейно клепать. Пришло в 2 раза больше пользователей — вы в 2 раза больше инстансов запустили. У вас снова всё хорошо.
Второй тип — это когда у вас масштабируемость зависит от внешних ресурсов. Грубо говоря, этот сервис входит в базу. У базы есть определенная возможность обслужить какое-то количество клиентов. Вы должны это учитывать. Либо вы должны понимать, когда у вас начнётся деградация системы и больше инстансов вы не сможете добавлять, либо просто каким-то образом понимать, насколько вы в это уже сейчас можете упереться.
И третий, самый интересный вариант — это когда вы ограничены какой-то внешней системой. Как пример — внешний биллинг. Вы знаете, что более 500 запросов он никак не обслужит. И хоть ты 100 своих сервисов запусти, всё равно 500 запросов в биллинг, и привет!
Эти лимиты мы тоже должны учитывать. Вот мы поняли, к какому типу у нас относится сервис, поставили соответствующий тэг и дальше смотрим, как это проходит по-нашему пайплайну.
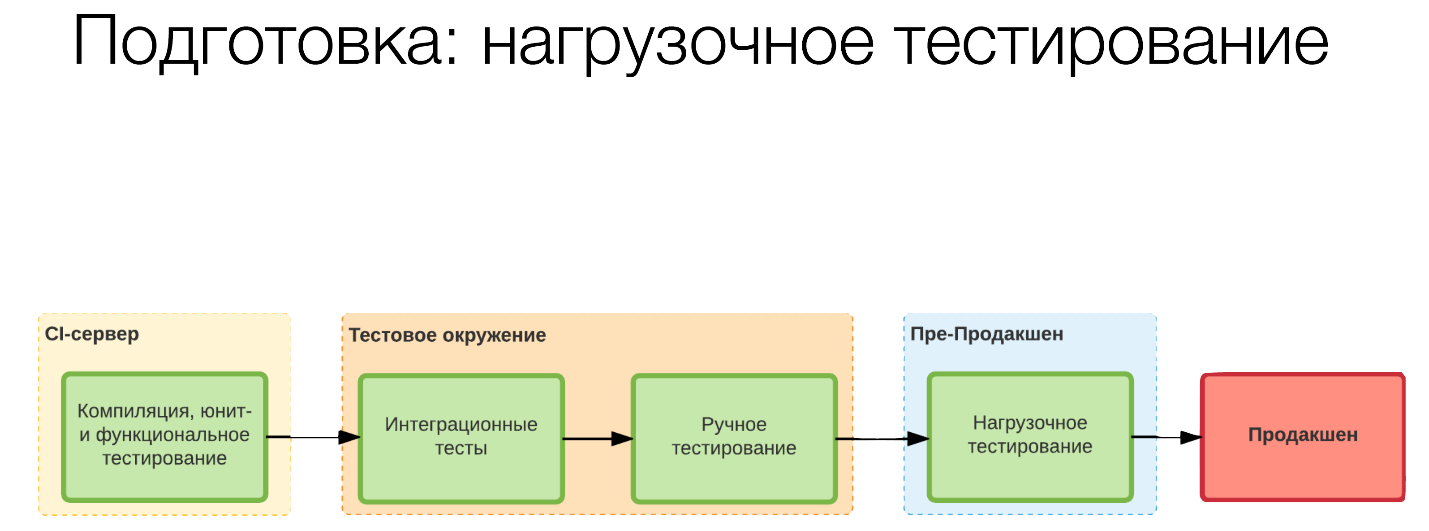
Стандартно мы на CI-сервере собрали, запустили какие-то юнит-тесты. На тестовом окружении у нас у нас прошли интеграционные тесты, у нас тестировщики что-то проверили. Дальше мы перешли к нагрузочному тестированию в пре-продакшне.
Если у нас сервис первого типа, то мы берём инстанс, его запускаем в этой изолированной среде и даём на него максимальную нагрузку. Делаем несколько раундов, берём минимальное число из полученных значений. Кладём его в InfluxDB и говорим, что это тот предел, который в принципе возможен для этого сервиса.
Если у нас сервис второго типа, то здесь мы запускаем эти инстансы в прирастании в каком-то количестве, пока не увидим, что началась деградация системы. Мы оцениваем, насколько она быстрая или медленная. Здесь мы делаем выводы, если мы знаем какую-то определенную нагрузку на наши системы, то достаточно ли этого вообще? Есть ли запас, который нам нужен? Если его нет, то мы уже на этом этапе ставим алерт и этот сервис не выпускаем в продакшн. Мы говорим разработчикам: «Ребята, вам либо нужно что-то шардировать, либо еще вводить какой-то инструментарий, который позволил бы более линейно масштабировать этот сервис».

Если же мы говорим о сервисе третьего типа, то мы знаем его предел, мы запускаем одну копию нашего сервиса, точно так же даём нагрузку и смотрим, сколько этот сервис может обслужить. Если мы знаем, например, что предел того же биллинга — 1000 запросов, 1 инстанс обслуживает 200, то мы понимаем, что 5 инстансов — это тот максимум, который сможет это корректно обслужить.
Всю эту информацию в InfluxDB мы сохранили. Появляется Decision service. Он смотрит 2 границы: верхнюю и нижнюю. По переходу за верхнюю границу он понимает, что нужно добавлять инстансы, а может, даже машины для этих инстансов. Также верно и обратное. Когда нагрузка падает (ночь), нам не нужно так много машин, мы можем на каких-то сервисах уменьшить количество инстансов, выключить машины и тем самым сэкономить немножко денежек.
Общая схема выглядит примерно так:
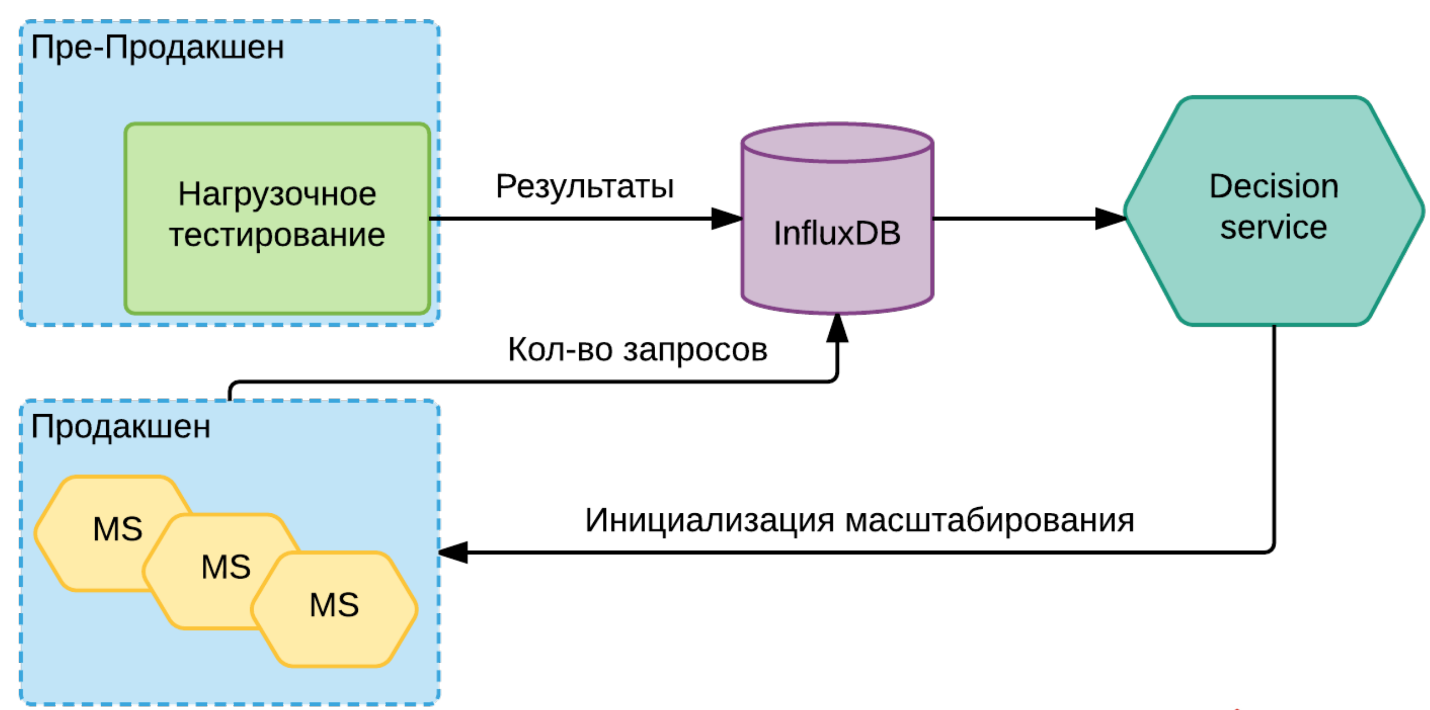
Каждый сервис через свои метрики регулярно говорит, какая на нём текущая нагрузка. Она уходит в ту же InfluxDB. Когда Decision service видит, что для этой конкретной версии этого конкретного инстанса мы подходим к порогу, он уже даёт команду Nomad или Kubernetes на то, что нужно добавлять новые инстансы. Возможно, он перед этим инициирует новый сервис в cloud, возможно, ещё какую-то подготовительную работу делает. Но суть в том, что он инициирует то, что нужно поднять новый инстанс.
Если видно, что мы скоро достигнем предела по каким-то лимитированным сервисам, то он поднимает соответствующий алерт. Да, мы условно с этим ничего не можем делать, кроме как копить очередь или еще что-то, но по крайней мере мы знаем, что у нас скоро может быть такая проблема и уже можем начинать к ней готовиться.
Это вот то, что касается масштабирования в каких-то общих вещах. И вся эта петрушка с кучей сервисов, она в итоге привела к тому, что мы посмотрели на еще такую штуку немного сбоку — это Gitlab CI.
Традиционно мы собирали наши сервисы через TeamCity. В какой-то момент мы поняли, что у нас есть один шаблон на все сервисы, потому что каждый сервис уникален, он сам знает, как себя закатать в контейнер. Плодить вот эти проекты стало достаточно сложно, их стало много. А описать это в yml-файле и положить вместе с самим сервисом оказалось достаточно удобно. Поэтому эту штуку мы постепенно внедряем, пока на совсем чуть-чуть, но перспективы интересные.
Ну собственно то, что хотелось бы сказать себе, когда мы начинали всю эту штуку.
Во-первых, это то, что если мы говорим о разработке именно микросервисов, то первое, что я бы посоветовал — это начинать сразу с какой-то системы оркестрации. Пусть самой простой, как тот же Nomad, который вы запускаете с командой
nomad agent -dev и получаете полностью готовую систему оркестрации, сразу с поднятым Consul, с самим Nomad и всей этой кухней.Это даёт понимание, что вы работаете в некоем чёрном ящике. Вы стараетесь сразу отойти от того, чтобы завязываться на конкретную машину, привязываться к файловой системе на конкретной машине. Что-то такое, это сразу несколько перестраивает ваше мышление.
И, естественно, сразу на этапе разработки у вас должно быть заложено, что у каждого сервиса — не меньше двух инстансов, иначе вы не сможете так легко и безболезненно отстреливать какие-то проблемные сервисы, какие-то вещи, которые создают вам сложности.
Следующий момент — это, конечно же, некие архитектурные вещи. В рамках микросервисов одна из самых важных таких вещей — это шина сообщений.
Классический пример: у вас есть регистрация пользователя. Как её сделать самым простым образом? Для регистрации нужно создать аккаунт, завести пользователя в биллинге, нужно сделать ему аватарку и что-то ещё. Вот у вас некое количество сервисов, у вас приходит запрос в некий такой суперсервис, а он уже начинает раскидывать запросы всем своим подопечным. В итоге он каждый раз все больше и больше знает о том, какие сервисы ему нужно дернуть для того, чтобы полностью сделать регистрацию.
Гораздо проще, надёжнее и эффективнее это сделать по-другому. Оставить 1 сервис, который делает регистрацию. Он зарегистрировал пользователя. Затем вы в эту общую шину выбрасываете event «я зарегистрировал пользователя, ID такой-то, минимальная информация такая-то». И это получат все сервисы, которым эта информация полезна. Один пойдёт аккаунт в биллинге сделает, другой приветственное письмо отошлёт.
В итоге у вас система потеряет такую жёсткую связность. У вас не будут появляться такие суперсервисы, которые знают про все и про всех. Это на самом деле очень упрощает оперирование с такой системой.
Ну и то, что я уже упоминал. Не нужно пытаться чинить эти сервисы. Если у вас с каким-то конкретным инстансом проблема, постарайтесь её локализовать, перевести трафик на другие, может быть, только что поднятые инстансы. А затем уже разбираться, что не так. Жизнеспособность системы от этого значительно улучшится.
Естественно, для того, чтобы понять, что происходит с вашей системой, насколько она эффективна, нужно собирать метрики.
Здесь важный момент: если вы не понимаете какую-то метрику, если вы не знаете, как её использовать, если она вам ни о чем не говорит, то не надо её собирать. Потому что в какой-то момент этих метрик становится миллиард. Вы тратите кучу процессорного времени просто на то, чтобы в них выбрать то, что вам нужно, тратите тонны времени на то, чтобы отфильтровать то, что вам не нужно. Оно лежит мертвым грузом.
Вы понимаете, что какая-то метрика вам нужна — начинайте её собирать. Что-то не нужно — не собирайте. Это очень сильно упрощает оперирование этими данными, потому что их реально очень быстро становится безумно много.
Если вы видите какую-то проблему, то не нужно на каждый чих бросаться что-то делать. В большинстве случаев система должна сама как-то отреагировать. Вам реально нужен алерт только в той ситуации, когда он требует какого-то вашего действия. Если вам не нужно среди ночи бежать что-то там делать, то значит это не алерт, а некий такой warning, который вы приняли к сведению и в каком-то условно-штатном режиме сможете обработать.
Ну собственно всё. Спасибо.
Микросервисы: опыт использования в нагруженном проекте
Комментарии (64)

aml
04.03.2017 05:35После того, как вы пересели на Kubernetes, пользуетесь ли вы kube-proxy или по-прежнему свою библиотеку для «бана» не отвечающих инстансов?

trong
04.03.2017 14:59+3По-прежнему пользуемся нашей библиотекой. У нас причин для бана сервиса больше, чем просто «не отвечает». Это может быть и не совместимая схема данных или не приемлемое время ответа (метрика приемлемости может варьироваться)

alexander_v_pryadko
04.03.2017 06:32+2Спасибо! Копаешь, копаешь, а выходит что еще копать — не перекопать :)
namwen
04.03.2017 06:32+1Перечитал дважды, шикарный контент, однозначно в избранное. Продукты Hashicorp удивили, раньше слышал, но обходил стороной, сейчас и Nomad и Vault решено попробовать…

vdshat
04.03.2017 09:46+1Хорошая статья. Выводы, однозначно, сделаны правильно, но почему они появили так поздно? Ведь это шаблоны проектирования SOA?
Интересно еще узнать какие стандартные поротоколы рассматривались, какие шины? Народ не рекомендует InfluxDB на большой нагрузке как она у вас себя ведет?trong
04.03.2017 15:09+1Ну выводы тут скорее, не как выводы из всей истории, а как рекомендации в дополнение к остальному повествованию ))
Мы смотрели protobuf, thrift, msgpack. У каждого свои плюшки, но мы в итоге пришли к тому, что с json многие вещи проще, понятнее, прозрачнее.
Про influxdb тоже слышал, что не рекомендуют, но у нас нет каких-либо проблем, ну или у нас не достаточно большая нагрузка — тут все относительно.namwen
06.03.2017 17:27+3С протоколами понятно, расскажите про общую для сервисов шину (где собственно и происходит event driven магия), пожалуйста, как организована, на чем, что с устойчивостью самой шины?

heathen
07.03.2017 16:51Я бы тоже почитал об этом. Из первого рисунка рождается предположение, что используется NSQ.
Если можно, я бы попросил ещё комментарии о том, как решается вопрос с дедупликацией\идемпотентностью при доставке сообщений. Ну, и отсутствие гарантии порядка доставки сообщений не мешает?
namwen
07.03.2017 23:28А вы внимательны, да, действительно на первом рисунке в качестве шины NSQ указан. Присоединяюсь к вашим вопросам.
braska
06.03.2017 23:56+2А шины? Я так понимаю, говоря о них вы говорили о MQ. Какие именно реализации пробовали/использовали?

Dreyk
04.03.2017 12:28Доклад замечательный.
Хотелось бы от кого-то услышать, как люди решают задачу, когда для рендера страницы пользователю нужна инфа от N сервисов? Синхронные запросы? Или локальный (для микросервиса) кеш + его асинхронное обновление? Что еще?

Fesor
04.03.2017 13:50Хотелось бы от кого-то услышать, как люди решают задачу, когда для рендера страницы пользователю нужна инфа от N сервисов?
ставите над сервисами еще один сервис-агрегатор который делает нужные выборки из других сервисов и склеивает все.
В случае с рендрингом страниц, у вас скорее всего будет один микросервис который полностью отвечает за страницу в целом, а отдельные блоки (например реклама) можно уже отдельно запросить и вставить.
trong
04.03.2017 14:52+1За оценку доклада — спасибо!
У нас через микросервисы реализуется только API, прямого рендеринга в HTML — нет. Клиент (не важно будь то single-page application или iOS/android приложение) делает асинхронные вызовы к API и строит результат.
Но, отвечая на ваш вопрос, все зависит от специфики — оба варианта имеют право на жизнь:
- Синхронные запросы — как уже писали, строится сервис который делает синхронные запросы к дочерним сервисам, собирает результат для рендеринга и кеширует, если это возможно. Прокисание кеша или по времени, или по событиям из общей шины данных
- Фоновая сборка данных — сервис держит 2-е копии данных: основная — этими данными сервис отвечает на запросы в текущий момент, вторая — собирается по событиям из шины и в момент полной готовности данных она становится основной. Таким образом сервис всегда готов к ответу, но не всегда актуальными данными
VolCh
04.03.2017 16:01+1Ещё асинхронные запросы с рендерящего страницу сервиса к N сервисам сразу (предполагая, что они не зависят друг от друга), предварительная обработка ответов (от десериализации джсона до рендеринга отдельных фрагментов страницы, хотя можно ничего не делать предварительно) от них, и окончательный рендеринг страницы когда все ответы придут (или отвалятся по таймауту — обязательно нужно обрабатывать, какие-то ответы могут быть некритичными и можно вывести заглушку, а без каких-то нет смысла рендерить, а рано или поздно ответы перестанут приходить).
trong
04.03.2017 16:06Да, понимание того какие данные критичны для ответа, а без каких можно обойтись — очень важно — помогает избежать эффекта домино. Хотя это важно в любой распределенной системе и в особенности в системе с внешними ресурсами.
http3
04.03.2017 13:44Это трансляции на сайте НТВ?
У вас 80 ГБит каналы?
Для 300к человек нужно ж порядка 300 ГБит при юникасте.
Можно их как-то себе на сайт поставить (трансляции)?trong
04.03.2017 14:55+1300к человек — это 700-1200 Гбит в зависимости от качества.
По поводу поставить на сайт — напишите мне в личку.
dgstudio
04.03.2017 15:49+2Уфф, всю статью читал в напряжении, дойдете вы до шины данных с выбрасыванием эвентов, или нет. С этого надо было начинать :)
Респектище за статью и архитектуру, молодцы!

vdshat
05.03.2017 23:27Интересно еще узнать как вы АД зависимостей версий сервисов разруливаете? У нас в свое время проблема была, что никто не хотел вкладываться в надежную систему поставок сервисов, с горем пополам сделали, но далеко от идеала. Вообще интересно как у вас система поставок устроена.
trong
05.03.2017 23:40+2А мы как раз делаем все, чтобы от зависимости версий уйти. И переход на json — один из таких шагов. Суть микросервисов как раз в их независимости, в том числе при деплое. Если у вас деплой одного сервиса вызывает каскадный деплой еще 40, то это проблема.
У нас практически каждый сервис в любой момент времени может быть выкачен в продакшен с новой версией.
Каждый сервис сообщает о себе в том числе версию базового протокола в рамках которой у сервиса гарантированно есть в наличии нужные данные, если же это не так, то ошибка проверки по json-схеме у получателя включит механизм circuit breaker и для конкретного клиента этот инстанс уйдет в бан.
mad_nazgul
06.03.2017 07:25Здравствуйте.
А были случат когда для клиента все инстансы нужного микросервиса уходили в бан?
Насколько я понимаю, от этого должен защитить механизм circuit breaker.
Но он работает «с лагом», поэтому возможна ли такая ситуация.trong
06.03.2017 10:12+1Да, были. В случае, когда инстансев определенного типа становится доступно меньше определенного порога поднимается алерт — это нештатная ситуация близкая к аварийной.
От такой ситуации не защищает паттерн circuit breaker (предохранитель) — он как раз косвенный виновник этой ситуации.
Смотрите — есть сервис А, который должен обратиться к сервису B. Он идет в реестр сервисов и просит адреса доступных инстансев сервиса В. Получает, например, список из 2-х адресов. Далее вступает в игру реализация предохранителя. Мы обращаемся к первому инстансу — он не отвечает за нужное нам время и мы в сервисе А делаем пометку — к этому не обращаться 1 мин — это и есть бан сервиса В в сервисе А. Далее мы идем ко второму инстансу — он ответил, но схема данных не подходит, мы его так же баним по причине несовместимости данных. В итоге получаем, что у нас для сервиса А нет доступных инстансев сервиса B. При этом с сервисом C инстансы сервиса В могут быть прекрасно совместимы и для него с сервисом В будет все в порядке.
vdshat
06.03.2017 00:07Интересен как раз вопрос с зависимыми сервисами и проверка, что измененный сервис по прежнему «независим» или отвечает заявленной спецификации. Мы, например, гоняем BDD интеграционные тесты.
trong
06.03.2017 10:25+3Мы в любой момент времени исходим из того, что сервисы у нас независимы. Поэтому у нас гарантированно нет завязки на версию самого сервиса. С версией протокола данных, поставляемых сервисом мы делаем так:
1. Сервис при деплое поставляется с мажорной версией протокола данных
2. Сервис-потребитель имеет json-схему проверки корректности данных с его точки зрения
3. Новый релиз сервиса мы выкатываем не как замену текущей версии, а как дополнение. Т.е. в какой-то момент времени у нас работает и версия сервиса 1.2 с протоколом данных версии 6 и версия 1.3 с протоколом данных версии 7.
4. Если новый релиз не совместим по схеме в сервисе-потребителе, то мы в потребителе его баним через паттерн circuit breaker
5. И мы мониторим переезд на новые релизы от каждого сервиса
Таким образом мы не отключаем старые релизы сервисов пока они используются и видим, что на новые никто не переехал по причине не совместимости протоколов данных. Как следствие — работа системы не нарушается. И если мы уверены, что новая версия сервиса должна быть совместима по данным, но этого не наблюдается, то идем и разбираемся с этим конкретным случаем.
В итоге никакого ада с версиями у нас нет, он намечался когда у нас было все на protobuf/grpc, но мы от этого ушли перейдя на json и введя схему данных для каждого сервиса-потребителя, который теперь проверяет только, что в ответе есть те данные которые нужны именно ему, а на остальное он не обращает вниманиеvdshat
06.03.2017 16:23Вот то, что хотел услышать: «в какой-то момент времени у нас работает и версия сервиса 1.2 с протоколом данных версии 6 и версия 1.3 с протоколом данных версии 7». Круто — как и должно быть.


grossws
06.03.2017 13:11Вы в итоге остановились на использовании opentracing api + zipkin'овская реализация? Какой транспорт от zipkin-reporter'а до сервера используете?
Попробовал вариант с libthrift и очень удивился пачке ошибок при работе
Senderа на localhost'е (версия libthrift, естественно, одинаковая на обоих сторонах).

Tiendil
06.03.2017 15:23+1Большое спасибо за статью. Очень полезна.
Есть пара вопросов:
— Правильно ли я понял, что сейчас у вас больше 500 разных типов микросервисов?
— Есть ли у этих микросервисов общий код (какой-нибудь общий фреймворк)?
— Если есть, то как он разрабатывается: отдельной командой или каждый вносит свою лепту? Как осуществляется переход на его новые версии?
— Если нет, то как это сказывается на процессах разработки?trong
06.03.2017 15:38+3— Правильно ли я понял, что сейчас у вас больше 500 разных типов микросервисов?
Точную цифру не скажу, но много :)
— Есть ли у этих микросервисов общий код (какой-нибудь общий фреймворк)?
Фреймворка нет, есть общий шаблон из которого мы на начальном этапе генерим болванку микросервиса, а дальше кодовая база у каждого сервиса уникальна. У этого шаблона есть мейнтейнер которому каждая команда может отправить пул-реквест с доработками/улучшениями.Tiendil
06.03.2017 15:45общий шаблон из которого мы на начальном этапе генерим болванку микросервиса
А что в него входит (примерно)?trong
06.03.2017 16:12+4Общие для всех сервисов компоненты:
- конфигурация приложения/обращение к сервису единой конфигурации
- хелсчек/рэдичек
- логгирование
- трассировка
- дебаг
- работа с метриками
- реализация circuit breaker
- реализация rate limit
- + специфичные для нас штуки
Инфраструктурные штуки:
- болванка сборки приложения в контейнер
- болванка документации сервиса
- тестирование
Может быть что-то еще, но это основноеTiendil
06.03.2017 16:19— Как распространяются изменения в шаблоне? Допустим, исправили критическую ошибку в логировании, каким образом изменения появятся в зупущенных сервисах и появятся ли они вообще?
— Как появился этот шаблон: вырос самостоятельно, введён директивно мейнтейнером, etc?trong
06.03.2017 22:11+1— Как распространяются изменения в шаблоне? Допустим, исправили критическую ошибку в логировании, каким образом изменения появятся в зупущенных сервисах и появятся ли они вообще?
Если прям критическое, то выпускается патч и рассылается всем командам, если не критичное, то каждая команда принимает решение об апдейте самостоятельно
— Как появился этот шаблон: вырос самостоятельно, введён директивно мейнтейнером, etc?
Самостоятельно, по мере накопления опыта выделились общие части каждого микросервиса, которые и стали сборкой для шаблона


peterdemin
06.03.2017 16:50+1Расскажите, пожалуйста, про тот момент, когда Nomad вы переросли и переехали на Kubernetes. Как раз сейчас переезжаем на Nomad.
trong
06.03.2017 22:13+1Для нас основной аргумент для миграции был в том, что на тот момент Nomad не умел работать с внешними volume и имел серьезные проблемы с запуском/остановкой сервисов в случае переименования job-а

quex
06.03.2017 18:16+1Спасибо за доклад.
Не могли бы вы рассказать о некоторых тонкостях, в частности интересует:
1. Как собираете образы? На каждый микросервис свой образ или же вся кодовая база в одном образе и при старте контейнера передаете аргументом название микросервиса? Или как-то еще?
2. Как выполняете, например, миграции? При деплое стартует микросервис, который выполняет необходимые действия и затем умирает?
3. Как структурирован проект? При таком количестве микросервисов, подозреваю, что все это хранятся не в одном репозитории. Тогда как решаете необходимость переиспользования кода в разных микросервисах (общие модели и т.д.)? Подмодулями? Как?
Спасибо.trong
06.03.2017 22:21+11. Как собираете образы? На каждый микросервис свой образ или же вся кодовая база в одном образе и при старте контейнера передаете аргументом название микросервиса? Или как-то еще?
1 микросервис — 1 репозиторий — 1 контейнер. Каждый репозиторий самодостаточен, у каждого своя кодовая база.
2. Как выполняете, например, миграции? При деплое стартует микросервис, который выполняет необходимые действия и затем умирает?
Нет, миграции — это часть процесса деплоя, сервис поставляется с файлами миграции, которые запускаются системой деплоя в момент раскатки в среду (прод/стэйдж/лоад/...)
3. Как структурирован проект? При таком количестве микросервисов, подозреваю, что все это хранятся не в одном репозитории. Тогда как решаете необходимость переиспользования кода в разных микросервисах (общие модели и т.д.)? Подмодулями? Как?
Есть шаблон микросервиса — из него генерится новый микросервис на старте разработке, далее у него полностью своя кодовая база, которая развивается самостоятельно. Если какой-то функционал из шаблона должен получить критическое обновление — выпускается общий патч.

Karloid
06.03.2017 18:16+1Спасибо за доклад. А с помощью как у вас реализована шина сообщений?
trong
06.03.2017 22:26+2Пожалуйста! Для шины используется NSQ, RabbitMQ — как реализация event bus и Kafka для агрегированного сбора данных в аналитические БД
vazir
08.03.2017 18:39Не совсем понятно, NSQ (nsqd) вроде как сам по себе демон для events — вы дополнительно к нему пристегиваете Rabbit сбоку, или вы их как-то подружили по другому? Или вообще используются отдельно, каждый для своей задачи?
trong
08.03.2017 18:42Нет, как я говорил в докладе — у нас не одна шина на все, а есть шина общего обмена и шины групп сервисов.
vazir
08.03.2017 18:45Ага, т.е. Rabbit отдельно, NSQ отдельно. Не поделитесь Rabbit для каких типов задач? И что более нагружено в плане кол-ва сообщений, Rabbit или NSQ?
trong
08.03.2017 18:52Там не конкретные типы задач, просто каким-то командам ближе NSQ, каким-то RabbitMQ, микросервисная архитектура и кластеризация это позволяют.
По нагрузке точно не скажу кто нагружен сильнее, но могу сказать, что в ситуации обмена сообщения между датацентрами мы используем NSQ.vazir
08.03.2017 19:25Еще, в приведенном Вами примере о создании аккаунта, в ситуации с АПИ — обычно нужно иметь на выходе результат — причем интерактивно (аккаунт создан, или произошла ошибка — пароль плохой, мейл уже используется и т.д.). При использовании NSQ — мы отправляем эвент и, поскольку это не RPC — мы не знаем какие микросервисы отработали, и создан ли был аккаунт в конце концов. Возможно вы применяете NSQ там где надо именно notify сделать, без опоры на результат? В таких случаях возможно лучше применять Rabbit или, допустим, ZMQ. Интересно как в Вашем случае?
trong
08.03.2017 19:46Event Bus — это по определению notify, в противном случае вы создаете сильную связанность между сервисами и теряете возможность их независимой разработки и поддержки. Поэтому речь тут идет именно о NSQ и RabbitMQ, а не, скажем, о Gearman.
А ситуацию с контролем нужно рассматривать несколько иначе: входная точка — это корректное создание аккаунта. Если создание прошло, значит есть отправная точка и предварительная проверка корректности данных. Далее у нас есть UserID к которому делается привязка остальных частей — заведение в биллинге, подготовка аватары и тп. И тут вступает в игру такой паттерн как «eventual consistency» — т.е. мы даем системе какое-то время, чтобы собраться к конечному состоянию в правильном виде и получить итоговый статус «регистрация полностью завершена». Если же этого не происходит, то сервис контроля инициирует процедуру отката. И вот наличие этой процедуры отката — один из вопросов при проектировании распределенной системы. Эта ситуация характерна не только для микросервисов — это вопрос именно к любой распределенной многокомпонентной системе.vazir
09.03.2017 09:38Ну в таком случае можно генерить чтото типа taskid и некий сервис проверки результата может откатить если статус fail… Спасибо за статью :)
heathen
09.03.2017 14:32Правильно ли я понимаю, что сервис контроля в этом случае должен знать, какие подтверждения должны быть получены, т.е. сильно связан с контролируемыми сервисами? Т.е. в любом случае не получится изменить состав операций, скажем, при создании пользователя, просто убрав или добавив новый микросервис — придётся изменить ещё и сервис контроля, а затем протестировать его работу вместе со всеми остальными сервисами в этой связке (а не только новый микросервис, как было бы в идеале).
Вообще, посоветуете, что почитать по архитектуре из того, чем вдохновлялись сами?
Спасибо.
lega
09.03.2017 14:57Event Bus — это по определению notify, в противном случае вы создаете сильную связанность между сервисами и теряете возможность их независимой разработки и поддержки.
Но вроде никто не жалуется когда используют БД в режиме RPC. Очень часто в проектах нужен как раз RPC вместо event/notify (хоть event тоже часто нужен, но это не значит что надо RPC заменить на event везде).
Например, создание аккаунта, через RPC или event, связность одинаковая, а сложность с RPC ниже.
vazir
08.03.2017 18:52+1И еще вопрос, а зачем было использовать NSQ, если так-же используете Rabbit? (в смысле того что NSQ по функционалу типа как сабсет раббита, и раббите есть то что есть в NSQ). Производительность в привязке к задаче PUB/SUB?

KolyaniuS
06.03.2017 18:16Спасибо за полезный материал, особенно за рекомендации по декомпозиции задач на различные микросервисы (про регистрацию пример) и за советы по аналитическому подходу к построению архитектуры проекта.
Стал замечать по своему опыту, что хочется относительно маленький проект сразу превратить в google|twitter|uber — way и т.п., а потом после изучения и детального тестирования тех или иных решений приходишь к выводу что всему свое время! :)

dkorablinov
06.03.2017 18:16Очень интересный доклад, спасибо!
Не могли бы вы рассказать чуть подробнее про использование Hystrix:
- Реализуете ли вы каждый раз новую Hystrix-команду для обращения к микросервису в конкретном месте кода, или circuit breaker «вшит» где-то на инфраструктурном уровне?
- Как вы управляете конфигурацией circuit breaker'ов: список инстансов микросервиса, допустимые таймауты и процент ошибок, время бана микросервиса и т.п.
- Как вы «подружили» Hystrix с кодом на Go?
trong
06.03.2017 22:39+1Реализуете ли вы каждый раз новую Hystrix-команду для обращения к микросервису в конкретном месте кода, или circuit breaker «вшит» где-то на инфраструктурном уровне?
Не уверен, что правильно понял вопрос, но… каждый вызов внешнего сервиса делается посредством обертки хистрикса
Как вы управляете конфигурацией circuit breaker'ов: список инстансов микросервиса, допустимые таймауты и процент ошибок, время бана микросервиса и т.п.
У нас для всех сервисов единая точка конфигурирования на базе KV-хранилища Consul-а. В нем хранится вообще все, что касается конфигурации сервисов в целом и каждого в частности. Каждый сервис на момент инициализации знает только свой ID, версию и то, как достучатся до Consul-а, чтобы забрать из него конфигурацию
Как вы «подружили» Hystrix с кодом на Go?
Использовали вот эту библиотеку: https://github.com/afex/hystrix-go
conf
Потрясающий доклад! Огромное спасибо.
trong
Пожалуйста