

На конференции HighLoad++ 2016 Иван Круглов рассказал про то, как сервис Booking.com развивал свой поиск — одну из центральных функций системы интернет-бронирования отелей.
Всем привет! Я Ваня, пишу на Perl — можете мне посочувствовать. [Лёгкий смех в зале и со сцены.]
Ладно. По-серьёзному, меня зовут Иван Круглов, я из компании Booking.com, из города Амстердам. Там я работаю последние 4 года, где последние года полтора я работал в команде, которая делает наш поиск лучше.
Начать я хочу немного издалека. Вот с этой фразы:

Не удивляйтесь если не знаете автора, это мой коллега Эдуардо Шиота. Почему я хочу её показать? На мой взгляд, она очень точно отражает культуру разработки Booking.com. Её суть — в том, что мы должны обеспечить наилучшее впечатление, наилучший опыт, расти и быстро адаптироваться потребностям наших клиентов.
Здесь есть несколько составляющих, я хочу вкратце пробежаться по каждой из них, заодно рассказать про Booking.com. Мы впервые представлены на HighLoad++. Я думаю, вам будет интересно.
Статистика
Начнём с роста. Растём мы примерно так:

Синий график — это количество объектов размещения, которые на данный момент есть в базе. Объекты размещения — это отели, гостиницы, виллы, апартаменты и так далее. На данный момент их около 1 миллиона. Оранжевая линия — это количество ежедневно забронированных ночей. Через Booking.com ежедневно бронируется более 1 миллиона ночей.
Второе – это быстрое адаптирование. Чтобы адаптироваться, нужно понимать, чего хочет ваш клиент. Как это сделать? Мы пользуемся таким методом: мы делаем некоторое наблюдение, далее мы выстраиваем гипотезу, почему так происходит, и эту гипотезу проверяем. Если что-то пошло не так, значит, наши наблюдения неверны, либо страдает его интерпретация. Идём фиксим, пробуем заново. Таких вариантов большинство. Если наша проверка показала «всё окей», то всё хорошо, можно двигаться дальше, к следующему наблюдению.
Механизм, который мы используем для подтверждения этих гипотез — это A/B тестирование, либо эксперименты. Эксперименты позволяют нам с некой статистической точностью сказать, да или нет.
Экспериментов много, они разные. Эксперименты бывают такие, когда мы меняем что-то графическое на сайте:

Классический пример — цвет кнопочки, либо добавили или поменяли иконочку, либо добавили новую фичу, появился какой-то блок, новый пункт в меню и так далее. Это что-то, что видно пользователю.
Второй вид эксперимента — это когда что-то изменилось внутри. Например, у нас появился новый API, либо какой-то новый сервис, или мы просто проапгрейдили какой-то пакет. В этом случае мы хотим собрать количественные характеристики. Здесь на слайде это распределение времени ответа. Верхнее — это то, что было. Внизу — то, что стало.

Следующий и самый главный пункт — мы хотим подтвердить, что нашему пользователю от нашего нововведения не стало хуже, то есть его experience не ухудшился.
Есть ещё один тип эксперимента, который очень обширный и покрывает всё. Условно его можно изобразить так:

Что я здесь хочу сказать? Понятно, что я немного преувеличиваю, никто вот так сразу код в продакшн не пушит. Но тестирования нет — оно очень минимально, его выполняет сам разработчик.
У нас есть очень хороший мониторинг, есть хороший experiment tool, который позволяет не только запустить наш эксперимент на какой-то части трафика, но и если что-то произошло, мы можем быстро понять, потушить пожар и двигаться дальше. Плюс у нас есть error budget — толерантность к ошибкам, которая существенно снижает моральную нагрузку на девелопера. Набор этих факторов позволяет нам больше уделать внимание бизнес-стороне вопроса, чем качеству его имплементации.
Если посчитать количество экспериментов, которые на данный момент запущены в Booking.com, их получится больше тысячи. Такое количество экспериментов нужно написать, задеплоить. Готовясь к докладу, я посмотрел статистику за последний год. Получилось, что в среднем мы делаем около 70 деплоев в день. Если это положить на стандартный восьмичасовой рабочий день, то получится, что какая-то часть сайта Booking.com меняется каждые 5-10 минут.
Наилучший опыт
Чтобы у нашего пользователя осталось наилучшее впечатление, вся компания — не только IT-отдел — должна собрать большой пазл. В этом пазле есть много элементов, какие-то менее очевидные, какие-то более очевидные, какие-то менее важные, какие-то суперважные. Например, список может выглядеть так:

Понятно, что список неполный, просто пример. Один большой очевидный point, который тут должен быть — это хороший поиск, который, в свою очередь, должен предоставлять две вещи: он должен быть быстрым, он должен давать актуальную информацию. В своём докладе я буду рассказывать про эти две вещи: про скорость и актуальность информации.
Поговорим немного про скорость. Почему важна скорость? Почему мы все делаем наши сайты быстрее?
Кто-то делает, чтобы померяться с конкурентами. Другие делают, чтобы клиенты от них не уходили, была больше конверсия. Если мы спросим Google, то он нам выдаст много статей, которые примерно это и будут говорить. Это всё так, в Booking.com мы это всё делаем. Но мы выделяем для себя еще одну интересную составляющую.
Давайте представим, что у нас есть условная поисковая страница, которая условно занимает две секунды. Представим, что эти две секунды — это наш threshold, после которого нашему клиенту становится плохо. Если в рамках нашей поисковой страницы наша основная поисковая логика занимает 90% времени, то на все фичи, на все остальные эксперименты остаётся всего 10% времени. Если мы вдруг запустили какой-то тяжёлый эксперимент, то он может нас вытолкнуть за пределы двух секунд.
Если мы сделали быстро, поиск стал занимать всего 50% времени, то у нас освободилась куча времени под новые фичи, под новые эксперименты. Одна из вещей, почему мы делаем в Booking.com быстро — мы хотим освободить время под эксперименты, под фичи.
Поиск
Дальше мы поговорим про поиск и что особенного в нём. Мы поговорим про эволюцию поиска, про его текущую архитектуру и заключение.
Я хочу начать с примера. Давайте представим, что у нас есть гость, который хочет поехать в Париж. Он может туда поехать один, с семьей, с друзьями, на машине, если он живёт недалеко (тогда желательно, чтобы у него был паркинг, где он остановится), а ещё он может поехать на общественном транспорте (тогда было бы неплохо, если бы остановка была недалеко). И конечно, он хочет завтрак. Задача Booking.com — помочь ему найти временное место проживания, которое удовлетворяет всем его требованиям.
Как в этом случае выглядит взаимодействие нашего гостя с сайтом? Он в первую очередь заходит на главную страницу. Там есть форма, думаю, все вы её знаете. Он вбивает «Париж». Он сразу начинает взаимодействовать с сервисом autocomplete & disambiguation (уточнение неоднозначностей), цель которого — помочь нам понять, какую именно геопозицию он имеет ввиду.
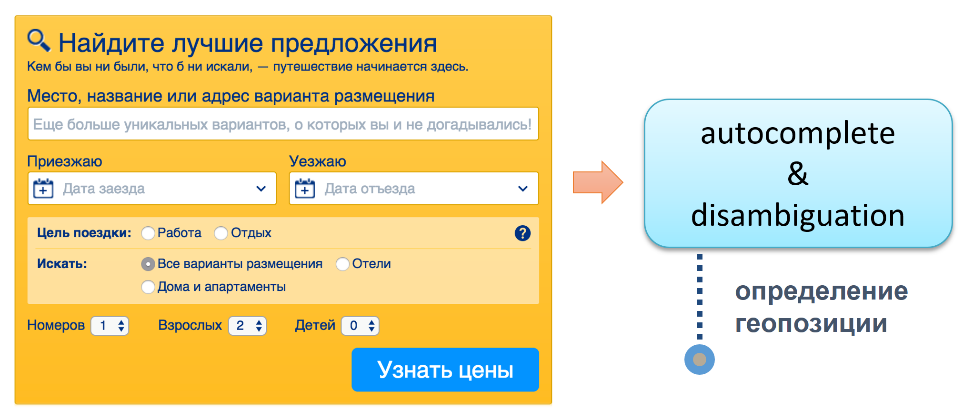
Дело в том, что если просто поискать по слову «Париж», то получится, что Парижей во всём мире порядка 30 штук. Например, деревня Париж, Кигинский район, Республика Башкортостан, Россия. Вряд ли это то, что он имел в виду. Есть еще деревня в Белоруссии, даже две, один остров Тихом океане, штук 10-15 есть в США.
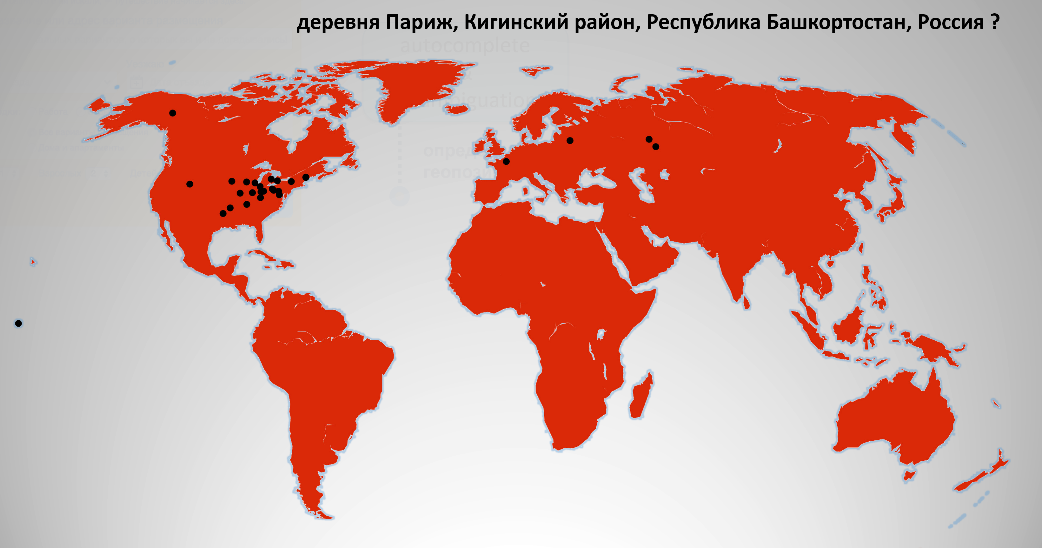
Нашему пользователю начинает показываться такой список, где он может выбрать, что имеется в виду.

Если нет какого-то элемента в списке, то наш гость будет переадресован на disambiguation, где, по сути, такие же данные, только список немного больше — пара десятков элементов.
Как только наш гость объяснил, чего он хочет (я хочу в тот самый Париж), формируется поисковый запрос в поисковую логику, которая делает следующее:
- Она отбирает отель по атрибутам, например, фильтрует отели, у которых нет паркинга, или в которых нет завтрака.
- Дальше она делает, если необходимо, group fit. Если наш гость путешествует с семьей, семья большая — 6 человек, но у нас нет номера, который вмещает 6 человек, мы можем попробовать поиграться: 3+3, 4+2, 5+1.
- Далее происходит отбор отелей по доступности.
- И в конце концов ранжирование.
Когда поисковый сервис отработал, формируется поисковая страничка, на которой наш гость читает описание и review, смотрит на цены, выбирает. В итоге переходит на финальный этап – бронирование. У Booking.com — новая бронь, успех, всё хорошо.
Здесь я хочу сделать два отступления. Первое — мой дальнейший доклад будет про вот тот квадратик поиска, буду фокусироваться на поисковой логике, что там происходит внутри. Второе — я уже упоминал отбор по доступности. Давайте я расскажу, что я имел ввиду, чтобы было понятно.
Тут нужно определить два термина. Первый — inventory, наличие. Второй — availability, доступность. В чем разница?
Давайте представим, что у нас есть гостинца «Домик с трубой». В ней есть одна комната, и её хозяин хочет сдавать эту гостинцу на новогодние праздники. Он установил такие цены:

С 1 по 2 января – 2000 ?, с 2 по 3 – 1750 ? и так далее. Это те данные, с которыми работает наша гостиница. Отель, комната, дата, цена.
С точки зрения нашего гостя, всё выглядит немного по-другому. Он мыслит так: «Я хочу остановиться в гостинце «Домик с трубой» с 1 по 5 января, её цена для меня будет составлять 6500 ?». Данные одни и те же, представление немного разное. Переход между этими представлениями не всегда тривиальный.
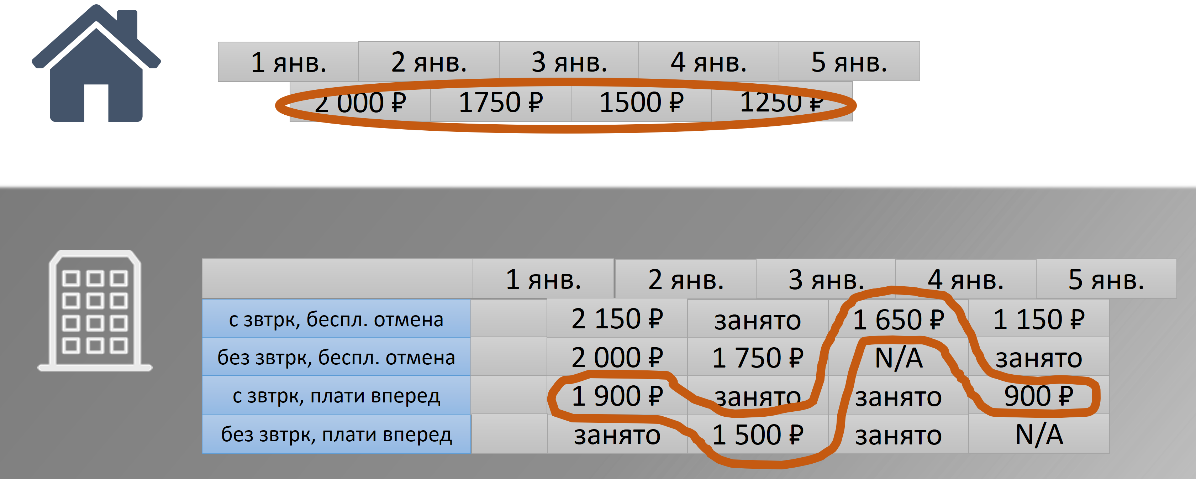
В этом случае он простой, мы просто берём и все их суммируем. А если у нас большая гостиница в которой много номеров, много тарифов, много политик, какие-то номера могут быть заняты, какие-то политики могут быть недоступны? В итоге получается нетривиальная функция вычисления цены.
Эволюция поиска
С введением закончили, с поиском определилась, терминологию я ввел. Поехали в хардкор.
В древние времена, когда у нас в базе было меньше 100 тысяч отелей, Booking.com использовал теплый LAMP-овый стек. LAMP — Linux, Apache, MySQL и P — не PHP, а Perl. Также Booking.com использовал монолитные архитектуры. Бизнес-процессы выглядели следующим образом:
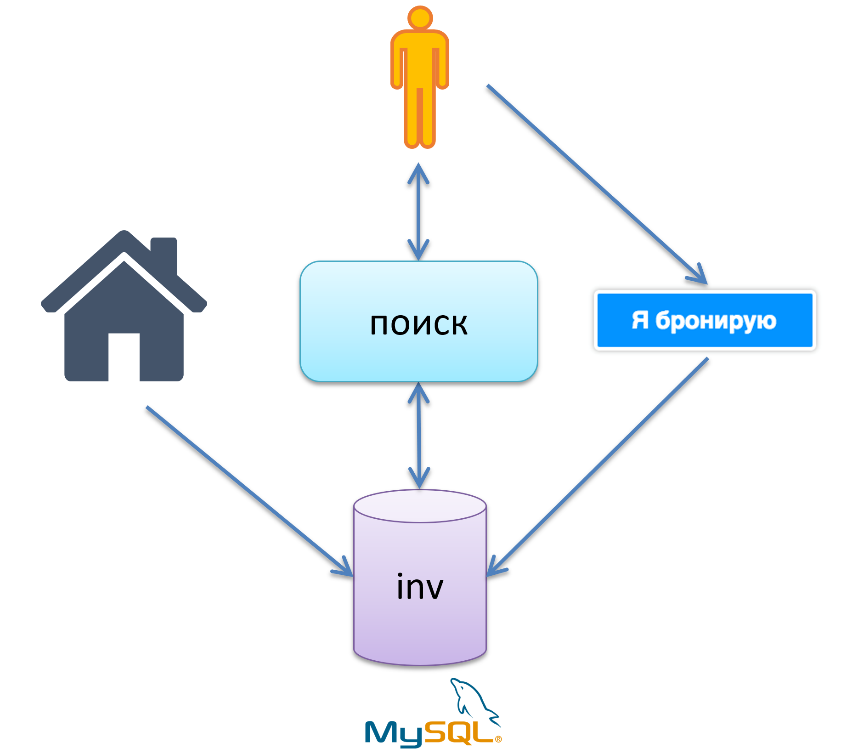
Наш отель. Есть база inventory в MySQL, отель вносит туда данные: я такой-то отель, у меня такая-то комната, на такие-то дни такая моя цена. Далее у нас есть поисковая логика, которая вытаскивает данные из базы inventory, вычисляет availability и отдаёт поисковый результат нашему гостю. Далее гость переходит на этап «я бронирую». Логика этого этапа идёт в базу inventory и делает минус-минус на какую-то запись, говоря, что такого номера больше нет.
В районе 2010 года, когда в базе было порядка 150 тысяч отелей, данный подход себя полностью исчерпал. Проблема была в тяжёлом расчете availability. Эта функция была очень тяжёлая. Чтобы вам лучше понимать, в чём была боль, вот пример:

Если на тот момент в базе было 500 отелей, у каждого в среднем 3 типа комнаты, 2 тарифа, то для того, чтобы нам сделать выборку и отсортировать её по цене, нужно порядка 3 тысяч расчётов. По архивным данным, наш стек мог выдать примерно следующее:

В одну секунду мог посчитать только 1000 цен для проживания в один день и всего 90 для проживания в 30 дней. Чем больше наша длительность проживания, тем больше вариантов нам нужно перебрать.
Кстати, по этой причине в Booking.com какое-то время в 2008 году отсутствовала сортировка по цене. Я лично помню, как первый раз приехал в Амстердам ещё будучи студентом. Денег было немного, хочется найти самый дешёвый отель. Я не смог отсортировать по цене как раз по этой причине. Сейчас с этим всё хорошо.
Что делать?
- Первое, что пришло на ум коллегам – давайте всё закэшируем. Не заработало. Получилось так, что max cache hit ratio был всего лишь 60%.
- Давайте всё перепишем на новую технологию. Решили так не делать. Почему? Во-первых, монолитная архитектура. То есть если переписывать, то нужно переписывать большую часть, на это нужно очень много времени. Во-вторых, пострадает agility. Компании нужно двигаться вперёд. Давайте посмотрим, что есть лучше?
- Давайте попробуем всё материализовать.
Что такое материализация? В данном контексте это примерно следующее. Возвращаясь к примеру, мы берём и просто предрасчитываем все возможные комбинации check-in и длительность проживания. Например, с 1-ого по 2-ое, с 1-го по 3-е, с 1-го по 4-ое, с 1-го по 5-ое, со 2-го по 3-е, со 2-го по 4-ое и т.д. Берём и считаем всё заранее.

Получаем хороший performance, потому что у нас всё рассчитано заранее, нужно только вытащить эту цену. Это получается ровный путь, что важно. У нас нет быстрого пути, когда данные попадают из кэша, например, и медленного, когда они не в кэше. Недостаток — это огромный объем данных. Нам нужно сохранить все эти варианты.
На этом варианте и остановились. Чтобы понять, насколько это огромный объем данных, я покажу вам текущую информацию:

На данный момент 1 миллион отелей, 3 типа комнат, 2 тарифа, от 1 до 30 дней длительность проживания. (В Booking.com нельзя забронировать отель на 2 месяца, максимум на 30 дней.) Данные считаются примерно на полтора года вперёд. Если перемножить все эти цифры, то получится, что в Booking.com на данный момент хранится порядка 100 миллиардов цен.
Бизнес-процессы в случае с материализацией

Знакомый отель, знакомая база inventory. Появляется новая база availability и процесс материализации, который материализует цены и складывает их в БД availability. Поисковая логика использует предрасчитанные цены, а логика бронирования по-прежнему изменяет данные в первоначальной базе inventory. Получается, что inventory — это наша первичная база данных, в которой лежит вся правда, а availability — некоторый её кэш, в котором всегда hit ratio составляет 100%.
С такой схемой есть два challenge. Самое главное: как сделать так чтобы не испортить user experience? Как не сделать так, чтобы мы сначала в поисковой логике сказали, что такой отель есть, такой номер есть, а потом, когда перешли на этап бронирования, сказали, что его нет? Нам нужно поддерживать две наши базы данных в консистентном виде.
Для того, чтобы порешать эту проблему, сделали следующее наблюдение. Возвращаю вас к диаграмме, которую я уже показывал, как происходит взаимодействие нашего пользователя с сервисом.
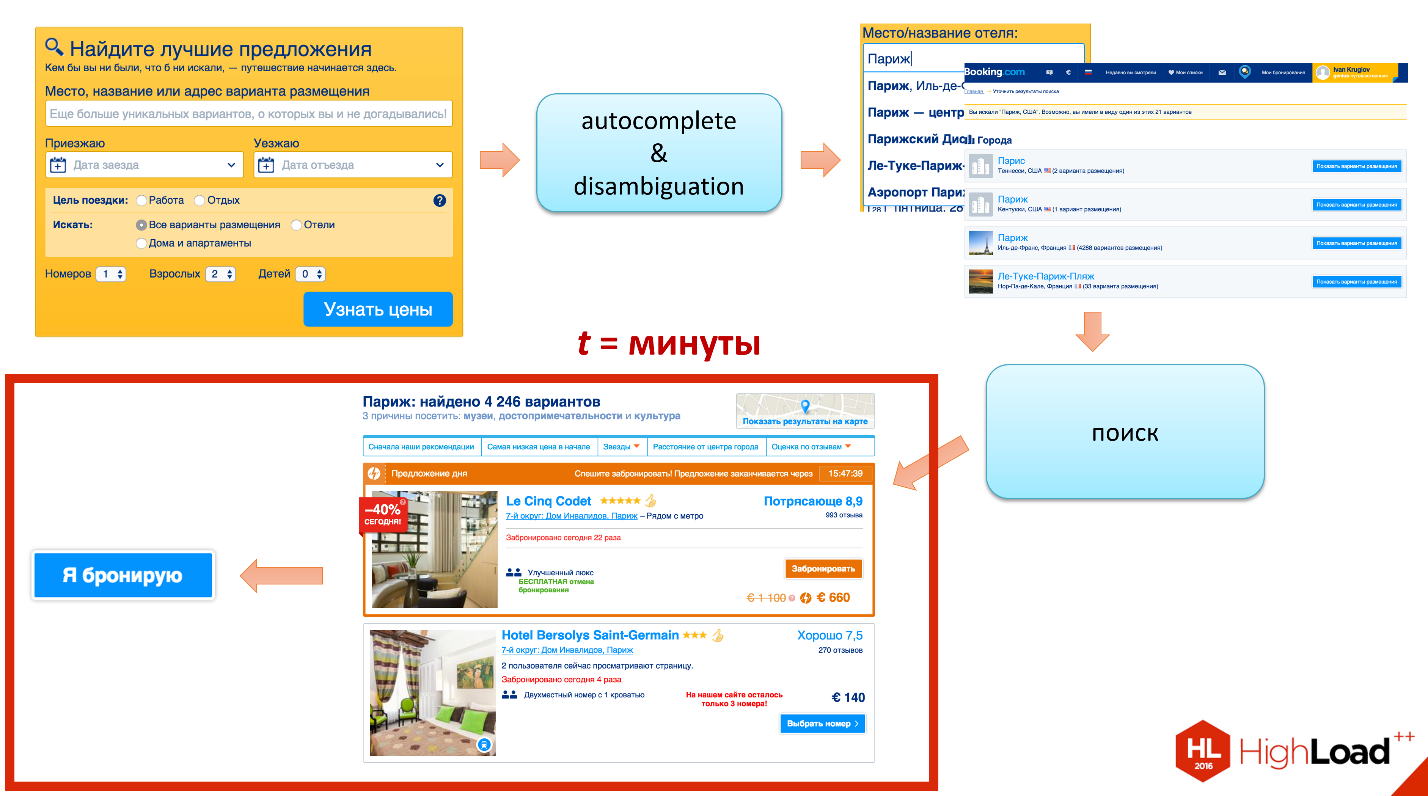
Посмотрите на эту часть, когда отдалась поисковая выборка, переход на этап «я бронирую». Здесь можно заметить, что то время, которое тут проводит пользователь, занимает минуты: 5-10 минут, пока мы читаем review, пока мы читаем description. Получается, когда наш гость перешёл на этап бронирования, может случиться так, что та последняя комната, которую он хотел забронировать, уже ушла. Есть некоторая естественная неконсистентность бизнес-модели.
Даже если мы сделаем две наши базы данных абсолютно консистентными, всегда будет процент ошибок на этапе «я бронирую» просто потому, что такова природа. Мы подумали, зачем нам тогда делать данные абсолютно консистентными? Давайте сделаем так, чтобы они были неконсистентными, но уровень ошибок, который возникает в связи с этой неконсистентностью, будет не выше того порога, который есть в силу бизнес-процессов.
Pipeline
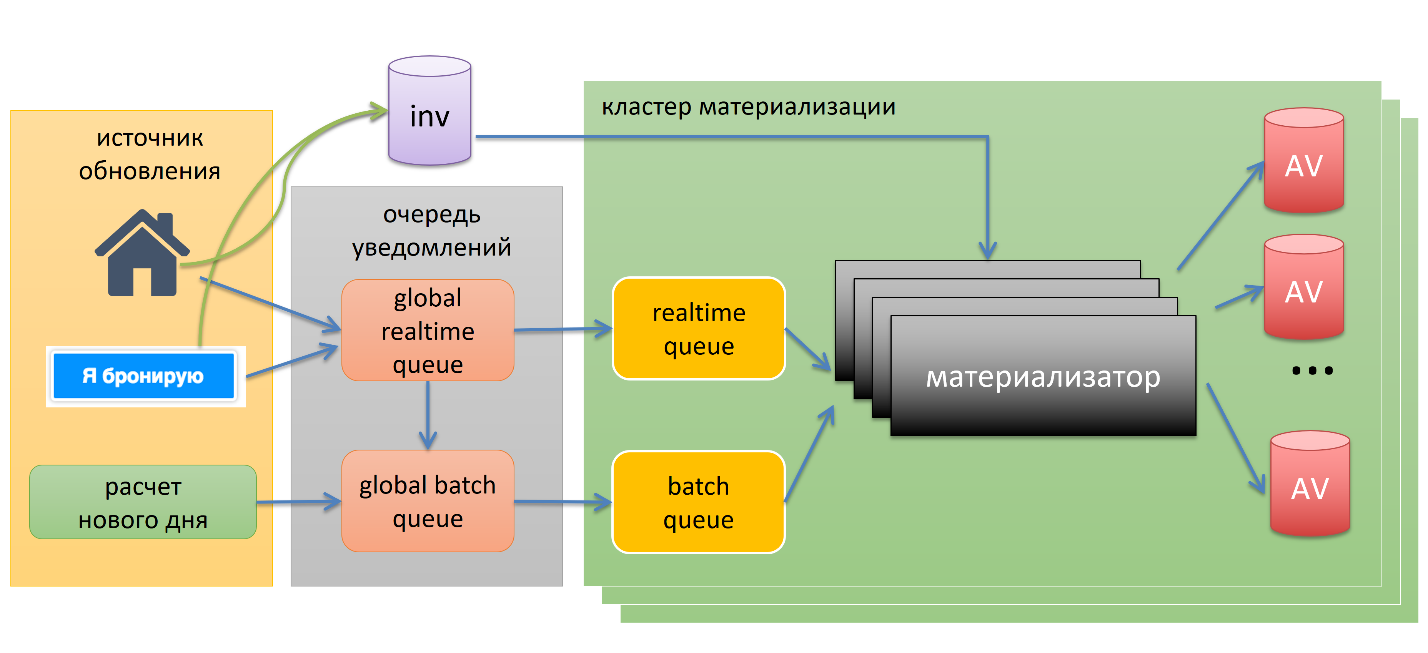
В первую очередь у нас есть источники обновлений. Всегда, когда они вносят какое-то изменение в inventory, они посылают уведомление в одну из глобальных очередей. Уведомление — это, например, «такой-то отель, у него забронировали комнату» или «такой-то отель изменил цену».
Очередей две, одна — realtime, другая — batch, это backlog. Это сделано, чтобы выставлять некоторые приоритеты. Если у нас бронь произошла на завтра, есть смысл пересчитать быстрее, чем бронь на год вперёд.
Далее уведомления перетекают в один из кластеров материализации, где есть много материализаторов. Они специально сделаны over capacity, чтобы в случае какой-то проблемы мы могли быстро наброситься на нашу очередь, быстро всё посчитать и быстро всё сложить в базу availability. Они вытягивают данные с базы inventory, перебирают все возможные варианты и складывают в availability.
Тут один интересный момент. Синенькая кнопка «я бронирую» посылает notification не только в случае успешного бронирования, но в случае неуспешного бронирования, в случае ошибки. В случае ошибки мы знаем, что потенциально есть некоторая неконсистентность — давайте на всякий случай её посчитаем, то есть такой self-healing механизм.
Последний элемент – это расчёт нового дня. Грубо говоря, availability — это такое движущееся окно с размером в полтора года. Каждый день нам нужно рассчитать один год и один день вперёд, например. Они всегда идут через batch queue по понятным причинам.
Хранение данных

Данных много, преобладают запросы на чтение и поисковые запросы. Поэтому оптимизировали под чтение. Использовали хитрый кластеризованный primary key index, хранили в MySQL.
Почему кластеризованный? Почему по геопозиции? Всегда, когда выполняется поиск, он выполняется на группе отелей, которые находятся близко друг к другу — есть свойство локальности. Было бы хорошо, если бы те отели, которые географически близко в реальности, были близко в БД. Чтобы нашему бедному MySQL не надо было бегать по нашему диску в разные стороны. Чем компактнее данные лежат на диске, тем лучше.
Для этого использовали прием Z-order curve, не буду на нём останавливаться, там всё очень просто. Подробнее по ссылке.
Делали шардинг по check-in. Записей много: одна запись в inventory может вызвать тысячи изменений записей в availability. Поэтому приходилось использовать SSD — жесткие диски не держали нагрузку. Нагрузка была в 4 тысячи IOPS.
Результаты
- Получили ускорение расчета availability в 50-100 раз. Нам ничего не нужно считать, всё посчитано, просто берём и вытягиваем нужное.
- За счёт хитрого кластеризованного MySQL-индекса получили быстрый холодный старт. Все данные лежат близко друг к другу, нужно мало страничек подтягивать с диска.
- Получили время материализации в норме меньше минуты. На практике — десятки секунд.
- Для того, чтобы убедиться, что наше начальное предположение валидно, мы обложили систему с ног до головы всевозможными метриками и алертами. Ключевой метрикой был quality check. Quality check — это какой-то внешний процесс, который делает выборку из availability, делает выборку из inventory, на основании этих данных считает availability и сравнивает. Если наши данные совпадают — всё хорошо. Если нет и данные разные, либо и тут записи нет, и там тоже, мы посылаем notification, какой-то alert. Такие алерты есть всегда, но критично, чтобы они не выходили за некоторый threshold.
Материализация решала проблему на достаточно продолжительный промежуток времени. За это время немного сменился стек, стали использовать uWSGI + Nginx + Perl + MySQL.
В районе 2014 года в базе было около полумиллиона отелей, был рост бизнеса, появились новые фичи, появился поиск по странам и регионам. Например, в Италии — 100 тысяч отелей.
Мы упёрлись в ту же самую проблему, только немного с другой стороны. Проблема заключалась в том, что у нас есть Perl, он однопоточный. Один запрос обрабатывается одним воркером. Не в состоянии он переварить все эти выборки, сортировки и так далее.
Что делать? Решили распараллелить всё это дело по Map-Reduce схеме. Написали свой Map-Reduce фреймворк. Перешли на сервис-ориентированную архитектуру. И получили следующие результаты: у нас большие запросы стали быстрее. За счет этого наш запрос бьется на более маленькие, он посылается на воркер, воркер считает свои маленькие части, посылает данные обратно в главный воркер, он всё это дело мержит и строит финальный результат.
Большие запросы стали быстрее, но при этом поиск по миру стал занимать порядка 20 секунд. По-прежнему не очень хорошо, но лучше, чем было. Контррезультатом стало то, что маленькие запросы стали медленнее. Причина этого — большие IPS overheads, в частности, на сериализацию и передачу данных между процессами. Perl — однопоточный, и сериализовать мы можем только с помощью множества процессов.
Это примерно то время, когда стали думать над сменой архитектуры, которая привела нас к той архитектуре, которую мы используем на данный момент.
Текущая архитектура
Мы понимали: если модернизировать то, что у нас было, подкрутить, поднастроить, поменять workflow, то в прицепе его можно заставить работать какое-то время. Но стек был близок к исчерпанию своих возможностей. Наш верблюд немножко подустал.
Хотелось отказаться от устаревших подходов. Архитектура строилась на подходах, под которые закладывался фундамент 5-10 лет назад, когда было 50—100 тысяч отелей в базе. Те подходы, которые применялись тогда, очень плохо подходят, когда у нас в базе 500 тысяч или даже миллион отелей, как в настоящий момент.
Хотелось сохранить MapReduce, хотелось сохранить сервис-ориентированную архитектуру. Хотелось, чтобы наш сервис имел быстрый доступ к availability и всем другим данным, которые нужны для выполнения поискового запроса. Хотелось быструю базу данных, в которую можно быстро писать. Для нас update availability. Хотелось иметь дешевый параллелизм.
Посмотрели вокруг. Нам понравился Tarantool, мы попробовали его. Это было примерно полтора года назад. Однако решили его не использовать по следующим причинам.
В первую очередь нас сильно смущало то, что если мы переходим на Tarantool, то нам придётся всю бизнес-логику писать на Lua. Мы не очень хорошо её знаем, даже несмотря на то, что она хорошо учится. Одно дело, когда у вас какой-то скрипт, маленькая хранимая процедура, другое дело — вся бизнес-логика на Lua. Второе — тот код, который мы взяли и сходу написали на Lua, у нас работал не так быстро, как хотелось бы. У нас была параллельная имплементация на Java. На Java код работал быстрее.
В итоге мы решили, что переходим с Perl на Java. Java даёт дешёвый multithreading, меньше константный фактор. Java в принципе быстрее, у нее внутренние overheads меньше. Решили, что все данные у нас in-memory для быстрого доступа. Решили, что переходим с MySQL на RocksDB.
Архитектура

В центре всего стоит поисковая нода, у нее локально встроена база данных availability. Это значит, что база данных находится в том же namespace, что и ваш процесс. У этой ноды есть in-memory индексы, есть in-memory база данных, которая persisted.
Нод много, они объединены в кластер. По строкам — шарды, по колонкам — реплики. Мы применяем статический шардинг, к каждой ноде мы ручками назначаем, какой шарде она принадлежит. Количество шардов такое, что все наши данные помещаются в память ноды. Данные мы размазываем с помощью простой операции «деление с остатком», hotel_ id mod N. Все реплики эквивалентны. У нас нет master, у нас все peer, нет никакого взаимодействия между нодами.
Теперь наш поисковый запрос попадает на один из координаторов, их много. Задача координатора — сделать scatter-gather, когда мы берём запрос и транслируем его на все шарды. Каждая шарда, обработав свои локальные данные, посылает запрос обратно координатору, который мержит эти данные и формирует финальный результат.
Внутри шарды реплика выбирается рандомно. Если реплика недоступна, мы берём и пробуем другую. Координаторы постоянно пингуют все ноды, чтобы понимать актуальное состояние нашего кластера.
По сути, это стандартный поисковый движок, тот же Yandex или Google работают примерно так же. У есть тут вишенка в виде availability, нам нужно обновлять встроенные базы данных, нужно обновлять их в realtime, потому что availability меняется постоянно.
Для этого мы использовали нашу существующую наработку, основанную на Perl и MySQL. Использовали тот же Pipeline с небольшим изменением: вместо того чтобы писать данные напрямую в базы, мы писали в материализованную очередь availability. Почему она материализованная? У нас внутри чёрного квадрата материализации все очереди были только notifications, то есть оранжевые очереди — это сами данные, само мясо.
Как мы обновляем данные availability? Каждая нода независимо от кого-либо берёт и читает эту очередь, применяет update к своему локальному состоянию. Мы посчитали данные один раз, что очень дорого, а применяем их много раз. В этой очереди данные хранятся за последние часы. Если нода отстала, она смогла бы догнать.
С такой схемой у нас кластер получается eventually consistent. В конечном итоге если все ноды не будут работать с одной скоростью, мы остановим наши изменения, то они все придут к одному и тому же состоянию.
Нас такая ситуация устраивает. Мы здесь полагаемся на принцип, который мы использовали при построении материализации: у нас нет необходимости делать нашу базу абсолютно консистентной. Нам нужно только убедиться в том, чтобы этот уровень ошибок не выходил за допустимое значение.
Тут опять же есть quality check, плюс мы используем одну метрику: следим за каждой надой, следим, насколько далеко она отстала от конца очереди. Если она отстала слишком далеко, мы берём и вытаскиваем её из кластера. Это автоматизированный процесс.
Давайте посмотрим, что происходит внутри. У нас есть входные данные:
- Геопозиция: Париж;
- Атрибуты поиска: парковка, завтрак и так далее;
- Check-in, check-out;
- Состав «команды» (например, семья из 6 человек).
На входе делается первичная фильтрация тех отелей, которые удовлетворяют нашим критериям на основе инвертированных индексов. У нас есть индекс, ключом являются города, value — это все отели этого города. Например, Париж и все отели, которые находятся в Париже. Есть второй список, например, те отели у которых есть паркинг. Далее если мы пересечём эти два списка — операция дёшевая и быстрая, — мы получим те отели которые в Париже и с парковкой.
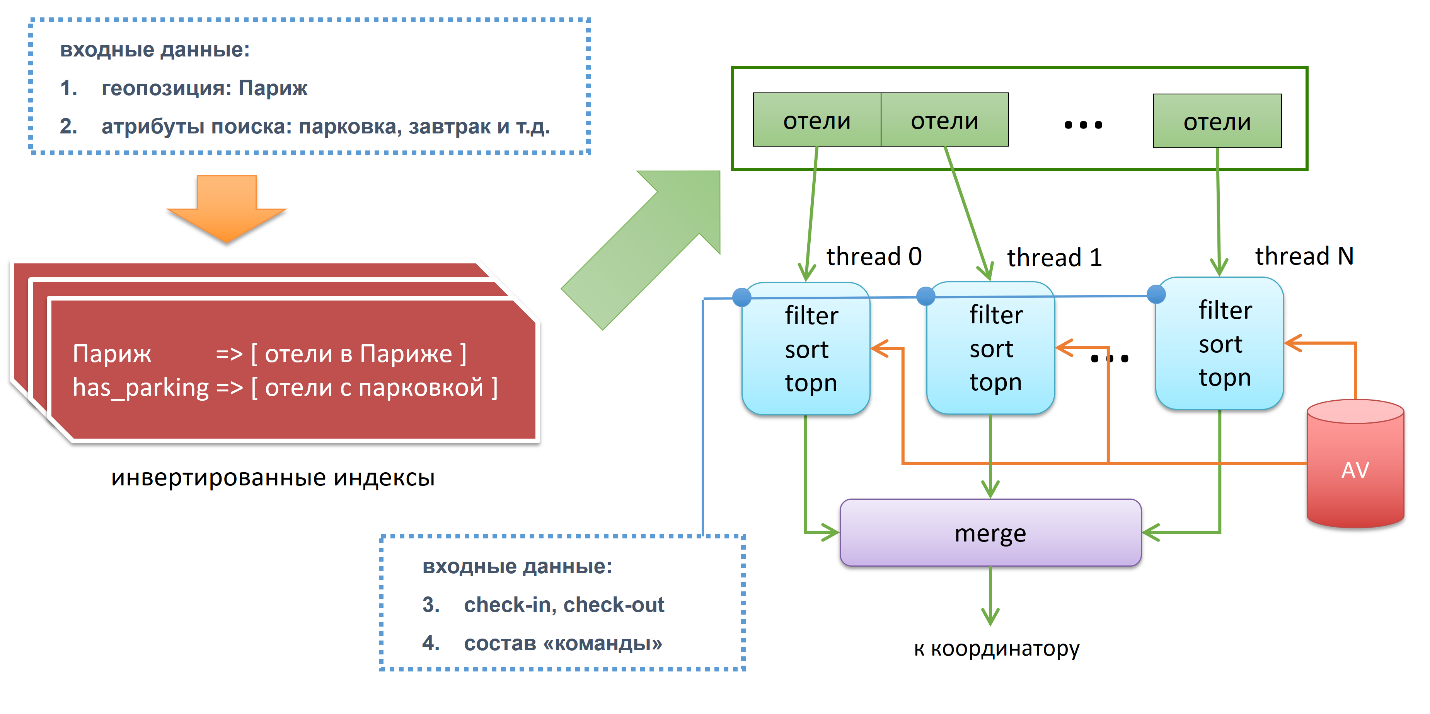
Получили первичный отфильтрованный список отелей, поделили его на кусочки, каждый кусочек скормили треду, который делает три шага. Первое: он делает вторичную фильтрацию на основе availability, он проверяет этот отель, доступна ли комната, если да, то по какой цене. Также здесь делается group fit. Дальше мы идём на этап сортировки. В конце концов вычисляется topn.
Например, если наш поисковый запрос сказал «я хочу первую страницу», на страничке 15 запросов. То есть каждый из тредов вытащит только top15 и пошлет эти данные в главный тред, который сделает merge. Merge он делается следующим образом: берет данные от всех n-тредов, получается ntop15 и от них получается top15. Потом посылает данные координатору, который в свою очередь ждёт результаты от всех шард. От каждой шарды он получил top15 и опять же делает top15. Получается каскадное уменьшение данных. Так это работает внутри.
Я обещал вам рассказать, почему мы остановились на RocksDB. Для этого нужно ответить на два подвопроса. Почему встроенная база данных? Почему именно RocksDB?
Почему встроенная база данных? Хочу продемонстрировать такую табличку:
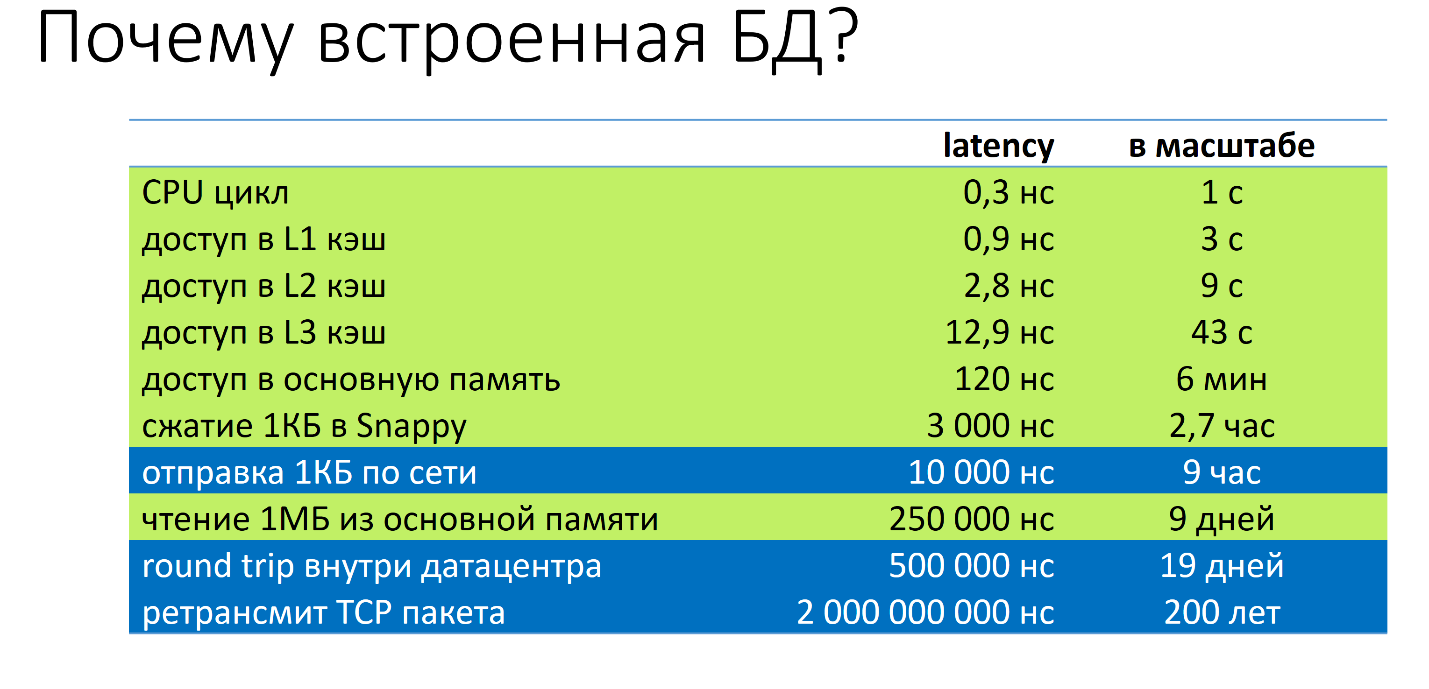
Здесь есть некоторый event из мира серверов и их latency. Для лучшего понимания я отмасштабировал их до понятных величин. Самое быстрое событие — это цикл центрального процессора. Он занимает 0,3 наносекунды. Что бы было, если бы была 1 секунда? В этом случае у нас доступ в L1 кэш будет 3 секунды, доступ в L3 кэш — 43 секунды, доступ в основную память — 6 минут, отправка одного килобайта по сети — 9 часов, round trip внутри датацентра — 19 дней, ретрансмит TCP пакета — 200 лет.
Если мы говорим про встроенные базы данных, мы говорим про свойства, которые ближе к верху, которые выделены зелёным цветом. Если мы говорим про базы данных, которые ходят по сети — неважно какая это база данных, MySQL, Cassandra, что угодно — то мы говорим про нижние строчки. Вот почему мы выбрали встроенные.
Если просмотреть бенчмарки RocksDB, которые есть на GitHub, если просмотреть бенчмарки Tarantool, который имеет встроенную базу данных, то там у них transaction, то есть QPS (Queries per second), все измеряются миллионами. Это одно из тех свойств, почему так происходит.
Почему RocksDB? Тут очень нехитрая история. Нам нужна была база данных, которая выдержала бы нашу нагрузку. Фич никаких нам особо не надо было, просто key-value, просто store, get, delete. Мы попробовали разные варианты: MapDB, Tokyo/Kyoto cabinet, leveldb. Как пробовали? Мы просто брали с ставили их в боевые условия: датасет в pagecache, 80% чтение + 20% запись, чтение существенно преобладает. RocksDB показал нам наиболее стабильный random read performance при random writes. Рандомная запись — это наш update availability, а радномное чтение — это наши поисковые запросы. Мы на этом и остановились.
Интересный момент: создатели RocksDB — Facebook. Они позиционируют её как SSD optimized по причине write and space amplification. На практике она прекрасно работает на наших обычных жёстких дисках. В нашем случае она прекрасно держит полторы тысячи записей в секунду.
Получили мы примерно следующее:

Сверху табличка – это время ответа поискового сервиса, то, что до, и то, что после. Видно, что в некоторых случаях мы улучшили скорость поискового запроса на три порядка. Что немаловажно, стали быстрее как большие запросы (в частности Адриатическое побережье, в котором 30 тысяч отелей), так и маленькие (София, где всего 300 отелей).
Нижний график я вам уже показывал, только не сказал, что это те результаты, которые мы получили, когда внедрили текущую архитектуру. Сверху — это то, что было, среднее время — это примерно 2 секунды. Нижний график — это то, что стало, 1,3 секунды. Мы улучшили скорость странички на 700 миллисекунд, которые мы можем потратить на новые фичи, эксперименты. Это очень хорошо.
Заключение
В заключение хочу сказать: ребят, у каждого свой путь. Смотрите, пробуйте, что подходит вам. Тот же самый тест RocksDB — я специально не выкладываю никакие бенчмарки, потому что мы взяли в наших боевых условиях, под нашу конкретную задачу, под наш конкретный workload. Мы взяли, потестировали, попробовали разные варианты, и он просто заработал. В вашем случае он может не подойти, попробуйте, это занимает не так много времени.
Второе. Работая над этим проектом, я для себя сделал ряд выводов. В первую очередь, скорость — это не только про конверсию, это про то, что сколько фич у вас может быть на страничке, сколько экспериментов вы можете запускать на страничке.
Посмотрите на материализацию. Современный процесс или современная система хранения данных могут хранить огромный объём информации. Те же 100 миллиардов цен, которые я показал — это какие-то жалкие 800 гигабайт. Максимум — по 8 байт на цену. 800 гигабайт влазит в память современных топовых конфигураций серверов, не говоря уже про кластеры машин. Это всё осуществимо, это всё работает. И это всё работает очень быстро, потому что всё посчитано.
Обязательно смотрите на ваши бизнес-процессы. Ваши бизнес-процессы могут вам рассказать многое, они могут существенно упростить жизнь. В нашем случае мы говорим, что нам нет смысла поддерживать консистентность данных между двумя базами данных, потому что в бизнес-процессе есть заложенная неконсистентность. Главное — чтобы тот уровень ошибок, который был, не выходил за некоторый threshold.
На этом у меня всё, спасибо большое, что пришли! Надеюсь, я рассказал что-то полезное.
Иван Круглов — Архитектура поиска в Booking.com
Комментарии (31)

unabl4
02.03.2017 23:46Спасибо. Очень интересно. Даже какое-то девавю. Работая в смежной индустрии, я однажды столкнулся с точно такой же проблемой. И при первых же серьёзных затыках в подсчёте и цены и доступности (availability), идея самого решения была очень схожней, но от реализации отказались ввиду тогда казавшейся сложности и отсутствия ресурсов (как технических, так и людских). Видимо зря )

mrobespierre
03.03.2017 02:23+1booking мигрирует на java, «российские гиганты» мигрируют на go, Perl окончательно маргинализируется, печально это

amberovsky
03.03.2017 03:21+1Возможно, глупый вопрос — а вы elasticsearch рассматривали?
Sioln
03.03.2017 10:23Тоже удивился конечной реализации. Столько всего вручную сделали. Эластик — первое, что я бы в такой ситуации попробовал. География — есть, кластер из коробки и распределение нагрузки — есть, производительность на очень высоком уровне.
Да, он не встраиваемый… но и нафига, если за счёт богатого языка запросов можно уложиться в минимум общения с сервером.
Sioln
03.03.2017 12:16+1В трансляции доклада есть вопрос про эластик.
Ответ:
1. На тот момент, когда пробовали, продукт был сырой и нестабильный.
2. Они не смогли внедрить поддержку своих экспериментов (я так понимаю — изолировать одни данные от других)
vian
06.03.2017 16:31Да рассматривали, и была реализация. Тут правда стоит отступить и сказать что всех подробностей я не приведу т.к. занимался не я. Могу сказать, что его пробовали и для автокомплита (о чем я кратко упомянул отвечая на вопрос из зала) и для основного поиска. В основном поиске уперлись в то, что эластик не справлялся с входящим объемом availability апдейтов.
Если интересуют более подробные детали, спрашивайте. Я могу уточнить.
cmdx
03.03.2017 03:21+7Жаль в статье не рассказано, что будет после вашего заказа, это же самое интересное!
Вы только что вернулись из отпуска в Казани?
Отлично! Тогда мы через два дня пришлем вам письмо с предложением снова туда съездить.
Не хотите? Только чемоданы распаковали?
Может тогда через четыре дня? Снова нет? Странно… Вам же там понравилось, вы 5 звезд поставили?
Что, у вас следующий отпуск только через полгода?
А, ну ничего страшного, за это время найдем для вас и пришлем вам на почту 91 вариант где его можно провести.
Оставайтесь с нами, ваш Booking.
CAJAX
03.03.2017 12:42+1Внизу писем есть ссылка для отписки, а при заказе есть чекбокс «подписаться на спам».
Хотя один косяк я заметил вчера — букинг держит этот чекбокс выбранным даже в Европе, где это запрещено законом.
Al-Vas
03.03.2017 04:53+1Было интересно прочитать, НО когда недавно искал отзыва об конкретных отелях во Вьетнаме, то долго плевался от «удобство» поиска. Куча фильтров по которым можно искать, но по названию не получается, либо это так завуалировано, что не попалось на глаза.
Хотелось просто ввести название отеля и получить ссылку на него — не получилось.
А если перейти в рубрику отели, то вообще будет вывален список всего что есть, но уже же без поиска, если там не один десяток вариантов, то поиск нужного доставляет массу удовольствия.
nikitanaz
03.03.2017 16:10Пока они не перестанут искать UX-дизайнеров, которые должны выдавать качественную вёрстку, этот момент вряд ли станет лучше. Но статья не про юзабилити всё-таки, эти притензии надо другим людям адресовывать -)
Al-Vas
04.03.2017 19:09Да я им и на сайте писал, может ту заметят, тем более в тему. Хочется чтобы сервис стал еще удобнее, но порой складывается впечатление что многие разработчики сами не пользуются своим продуктом иначе они бы уже давно поправили кучу неудобных моментов.
ElectroGuard
03.03.2017 06:23+1Много езжу, постоянно заказываю отели в букинге, являюсь genius путешественником. При всём уважении к огромной проделанной работе, но поиск пока всё еще работает далеко неидеально. Насколько я помню — то нельзя найти отель по названию, и нельзя найти отель поблизости от указанного места (могу ошибаться, так как уже почти год назад последний раз использовал — летом). Опять же — куча пост-спама с предложениями съездить туда же, где я уже был, раздражает.
В любом случае — спасибо за статью, было очень интересно!Sioln
03.03.2017 10:25Отель поблизости от указанного места ищется при помощи карты. Это не очевидно, но в поиске внизу есть карта. Её разворачиваете и скролите. Фишки отелей будут обновляться на карте.
alex3535
03.03.2017 09:53+2Для меня единственный ресурс, который постоянно на глазах меняется в лучшую сторону- это букинг. Год назад снес ихнее приложение Пульс как бесполезное, сейчас установил обратно — совершеннно другое дело, то что надо, помогает работать.
То же самое с поиском на сайте. Про то что нет поиска по каким-либо параметрам- надо понимать есть тут коммерческие моменты. В моем частном случае айрбнб за прошлый год сильно просел в бронировании, а букинг занял эти дни и добавил очень серьезно, суточно.ру и остальные вообще погоды пока не строят, к сожалению. Думаю весь секрет как раз в волшебных календарях и availability, который только у букинга в адеквате. Модель букинга по монетизации- стоит на стороне клиента. А, допустим, Суточно.ру — тупиковая модель, по сути сайта с обьявлениями.
Что не нравится — отзывы на букинге сплошь восторженные. Если ехать приходится, я на них вообще не смотрю, только по негативу пытаюсь определиться.
Antelle
03.03.2017 21:36Бывает, что и не восторженных отзывов много. Можно отсортировать их от плохих к хорошим, тогда они будут вначале.
immaculate
03.03.2017 11:31Спасибо, пользуюсь booking эпизодически, полезное приложение. И статья интересная.
Честно говоря, часто пользуюсь booking, чтобы оценить, где больше всего отелей и какова средняя цена. Потом приезжаю в нужное место, и беру номер уже на месте. Заранее бронирую редко по двум причинам:
- когда приезжаю и смотрю на месте, номера могут серьезно отличаться от того, что на картинках. Личное впечатление ничто не заменит
- если не забронировал номер заранее, то можно торговаться. В Таиланде один раз удалось так снять комнату в три раза дешевле (!), чем цена на booking
Понимаю, что от таких как я, booking'у один лишь вред. :) Но я все же изредка бронирую заранее… Допустим, кто-то, чьему мнению я доверяю, говорит мне: «Приедешь в такое-то место, там есть замечательный отель YYY». Личному отзыву доверяю больше, чем отзывам в Интернете, потому что когда читаешь отзывы на booking о тех отелях, где бывал, возникает только каша в голове.
Кто-то бывал до этого только в 5* отелях, и если ему не меняют ежедневно 4 полотенца, напишет, что это ужасная грязная клоака. А кто-то совершенно неприятязательный, жил до этого в индийских мотелях для дальнобойщиков за 100 рупий в день, и пишет паршивому отелю отличный отзыв. Короче, в отзывы даже перестал смотреть, так как они не сообщают никакой полезной информации.
Ivan22
03.03.2017 15:58+1ну уж и бесполезные. Есть реально объективные отзывы вида — на заднем дворе свалка и воняет, номера с окнами туда -не брать. или вайфай в 3-м корпусе не ловит совсем, надо идти в лобби, а в 1и 2м корпусах — в любом номере отличных. Ну и т.д.
ElectroGuard
05.03.2017 12:44+1Понятно, что отзывы будут субъективными. Но то, что они 'живые' огромный плюс. В реальности из уже, наверно, 30ти забронированных через букинг отелей, мы 'напоролись' только на одно несоотвествие ожидаемому. И то — нужно было внимательнее смотреть на картинки. Это по Европе, как в других частях мира — сложно сказать.
ElectroGuard
05.03.2017 12:51По поводу торга — так Азия :) там торговаться — милое дело. Реально можно цены в разы скинуть, видимо даже на отели :)
Sioln
03.03.2017 11:48+2https://youtu.be/VdRmsOAvv0A?t=2370
Очень показательный кадр.
Человек 40 минут рассказывает, как они оптимизировали БД, говорит, что разница в производительности составила до 3х порядков… И что в итоге?
Среднее время ответа в поиске было 2 секунды, стало 1.3 секунды…
Они то, вообще, оптимизировали? (Ну или не обманывают ли себя где-то в методике замера результата)
И ещё, какой смысл в InMemory DB, если их координатор вынужден по сети опрашивать N нод и собирать с них ответ?
0x0FFF
03.03.2017 14:40+3Коллега, есть такое понятие как «tail latency». Нельзя судить о времени отклика нагруженного сервиса только по среднему, зачастую та же 95-я и 99-я перцентили намного важнее.
Sioln
03.03.2017 16:57Само собой. И однозначно видно, что они сделали лучше, чем было.
Но, показывая такой кадр, стоило чётко пояснить, а где остальные ~60% нагрузки оседают.
Даже не так. Хорошим примером было бы:
1. Мы воспользовались профайлером и увидели, что…
2. Мы решили начать оптимизацию с… потому что.
А так выглядит, будто взялись за самое очевидное место, а результат оказался далёк от ожидаемого (зрителем).vian
06.03.2017 16:51Справедливое замечание. Поясню. Остальные 60% ответа поисковой страницы это обвязка поиска. Те же самые эксперименты, вытягивание инфы по отелям, ревью и т.д. Там много легаси и все на перле. Брались мы за оптимизацию именно поисковой выборки, а не всей странички.
Смысл in-memory в том, что каждая нода обрабатывая запрос много раз ходит в БД за availability. И ходить в память ближе чем ходить по сети.

anathem
03.03.2017 16:42И снова читаю всю статью и в конце вижу, что можно было посмотреть-послушать %)
uelkfr
03.03.2017 20:38А почему вы не сделаете такую фичу, чтобы еще больше нивелировать недостаток неконсистентности availability. Фича заключаются в следующем: делаем AJAX Polling/WebSocket канал, создаем специальные кэширующие сервера для обработки последних изменений материализованной очереди availability, и через этот канал с помощь JavaScript динамически меняем состояние кнопки «Забронировать» на «Не доступно».
vian
06.03.2017 16:56+1Здравствуйте. Я редко пишу за хабре по этому представлюсь. Я Ваня. На видео это я вам рассказываю :-). Если есть вопросы по теме я готов ответить.
crezd
Спасибо, интересное чтиво.