
В конце июля 2016 года в корпоративном блоге Uber появилась поистине историческая статья о причинах перехода компании с PostgreSQL на MySQL. С тех пор в жарких обсуждениях этого материала было сломано немало копий, аргументы Uber были тщательно препарированы, компанию обвинили в предвзятости, технической неграмотности, неспособности эффективно взаимодействовать с сообществом и других смертных грехах, при этом по горячим следам в Postgres было внесено несколько изменений, призванных решить некоторые из описанных проблем. Список последствий на этом не заканчивается, и его можно продолжать еще очень долго.
Наверное, не будет преувеличением сказать, что за последние несколько лет это стало одним из самых громких и резонансных событий, связанных с СУБД PostgreSQL, которую мы, к слову сказать, очень любим и широко используем. Эта ситуация наверняка пошла на пользу не только упомянутым системам, но и движению Free and Open Source в целом. При этом, к сожалению, русского перевода статьи так и не появилось. Ввиду значимости события, а также подробного и интересного с технической точки зрения изложения материала, в котором в стиле «Postgres vs MySQL» идет сравнение физической структуры данных на диске, организации первичных и вторичных индексов, репликации, MVCC, обновлений и поддержки большого количества соединений, мы решили восполнить этот пробел и сделать перевод оригинальной статьи. Результат вы можете найти под катом.
Введение
На ранней стадии развития архитектура Uber состояла из монолитного серверного приложения на Python, которое использовало Postgres для хранения данных. С тех пор многое изменилось: была применена модель микросервисов, а также новые платформы обработки и хранения данных. В частности, раньше во многих случаях мы использовали Postgres, а теперь перешли на Schemaless — новую распределенную систему хранения данных, работающую поверх MySQL. В этой статье мы поговорим о некоторых недостатках Postgres и объясним, почему мы решили построить Schemaless и другие сервисы на базе MySQL.
Архитектура Postgres
Мы столкнулись с несколькими недостатками Postgres, среди которых:
- неэффективность архитектуры в плане выполнения записи,
- неэффективная репликация данных,
- случаи повреждения таблиц,
- проблемы с MVCC на репликах,
- трудности с обновлением.
Мы рассмотрим эти ограничения, проанализировав то, как Postgres размещает данные таблиц и индексов на диске, особенно в сравнении с подходом MySQL, реализуемым с помощью подсистемы хранения данных InnoDB. Обратите внимание: представленный здесь анализ по большей части основан на нашем опыте работы с достаточно старой версией Postgres 9.2. Но, насколько мы знаем, внутренняя архитектура, которую мы обсуждаем в этой статье, в новых релизах Postgres серьезно не изменилась. Более того, базовые принципы представления данных на диске, которые используются в версии 9.2, значительно не изменились как минимум с Postgres 8.3 (то есть им практически 10 лет).
Формат представления данных на диске
Реляционная СУБД должна обеспечивать выполнение нескольких ключевых задач:
- выполнение операций insert/update/delete;
- внесение изменений в схему данных;
- реализацию механизма управления параллельным доступом с помощью многоверсионности (multiversion concurrency control, MVCC), который позволяет разным соединениям с базой использовать транзакции при работе с данными.
Взаимодействие вышеперечисленных механизмов в значительной степени определяет то, как СУБД будет хранить данные на диске.
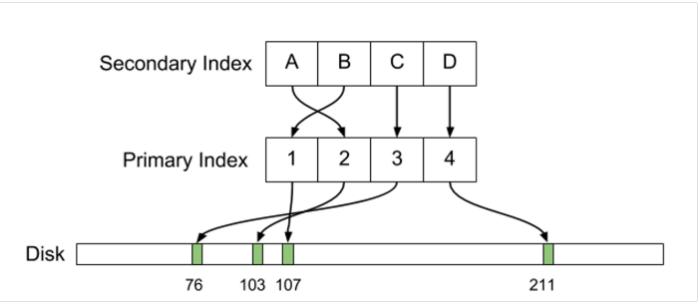
Одним из ключевых аспектов дизайна Postgres являются неизменяемые строки. На языке Postgres они называются кортежами (tuples). У кортежей есть уникальные идентификаторы — ctid, которые по сути представляют определенное место на диске (т. е. смещение на физическом носителе). Несколько ctid потенциально могут описывать одну строку (например, в случае существования нескольких версий строки в рамках MVCC или когда место, занимаемое старыми версиями строки, еще не было освобождено с помощью autovacuum). Организованная коллекция кортежей образует таблицу. У таблиц есть индексы, имеющие определенную структуру данных (обычно это B-деревья), с помощью которой поля индекса сопоставляются с данными, идентифицируемыми ctid.
Пользователь обычно не сталкивается со ctid, однако понимание этих идентификаторов позволит лучше разобраться с тем, как Postgres хранит данные на диске. Чтобы получить ctid строки, нужно добавить в запрос колонку “ctid”:
uber@[local] uber=> SELECT ctid, * FROM my_table LIMIT 1;
-[ RECORD 1 ]--------+------------------------------
ctid | (0,1)
...здесь выводятся другие поля...Давайте в качестве примера рассмотрим простую таблицу пользователей. В каждой строке есть автоматически увеличивающийся первичный ключ id, имя, фамилия и год рождения. Мы также создадим вторичный составной индекс по полному имени (имени и фамилии) и еще один вторичный индекс по году рождения. DDL-инструкции по созданию такой таблицы могут выглядеть следующим образом:
CREATE TABLE users (
id SERIAL,
first TEXT,
last TEXT,
birth_year INTEGER,
PRIMARY KEY (id)
);
CREATE INDEX ix_users_first_last ON users (first, last);
CREATE INDEX ix_users_birth_year ON users (birth_year);Обратите внимание: эти инструкции создают три индекса: индекс для первичного ключа и два вторичных индекса.
Заполним таблицу данными известных математиков:
| id | first | last | birth_year |
| 1 | Blaise | Pascal | 1623 |
| 2 | Gottfried | Leibniz | 1646 |
| 3 | Emmy | Noether | 1882 |
| 4 | Muhammad | al-Khwarizmi | 780 |
| 5 | Alan | Turing | 1912 |
| 6 | Srinivasa | Ramanujan | 1887 |
| 7 | Ada | Lovelace | 1815 |
| 8 | Henri | Poincare | 1854 |
Как было упомянуто ранее, каждая строка содержит уникальный, не отображающийся по умолчанию ctid. Внутреннее представление таблицы может выглядеть следующим образом:
| ctid | id | first | last | birth_year |
| A | 1 | Blaise | Pascal | 1623 |
| B | 2 | Gottfried | Leibniz | 1646 |
| C | 3 | Emmy | Noether | 1882 |
| D | 4 | Muhammad | al-Khwarizmi | 780 |
| E | 5 | Alan | Turing | 1912 |
| F | 6 | Srinivasa | Ramanujan | 1887 |
| G | 7 | Ada | Lovelace | 1815 |
| H | 8 | Henri | Poincare | 1854 |
Индекс по первичному ключу, с помощью которого сопоставляются идентификаторы id и ctid, определен так:
| id | ctid |
| 1 | A |
| 2 | B |
| 3 | C |
| 4 | D |
| 5 | E |
| 6 | F |
| 7 | G |
| 8 | H |
B-дерево (B-tree) построено на основе поля id, и каждый его узел содержит значение ctid. Обратите внимание: в данном случае очередность записей индекса совпадает с очередностью записей в таблице. Это обусловлено автоинкрементом поля id, но так бывает не всегда.
Вторичные индексы выглядят похожим образом. Основное отличие в том, что записи хранятся в другом порядке, поскольку B-дерево должно быть организовано лексикографически. Индекс (first, last) начинается с имен, расположенных в алфавитном порядке:
| first | last | ctid |
| Ada | Lovelace | G |
| Alan | Turing | E |
| Blaise | Pascal | A |
| Emmy | Noether | C |
| Gottfried | Leibniz | B |
| Henri | Poincare | H |
| Muhammad | al-Khwarizmi | D |
| Srinivasa | Ramanujan | F |
Индекс birth_year кластеризован по возрастанию:
| birth_year | ctid |
| 780 | D |
| 1623 | A |
| 1646 | B |
| 1815 | G |
| 1854 | H |
| 1887 | F |
| 1882 | C |
| 1912 | E |
В отличие от первичного индекса по id, в обоих вторичных индексах значения поля ctid лексикографически не возрастают.
Предположим, что надо обновить одну из записей таблицы. Изменим год рождения al-Khwarizmi’s на 770. Как мы упоминали ранее, строковые кортежи неизменяемы. Таким образом, чтобы обновить запись, нужно добавить новый кортеж к таблице. У него будет новый ctid, назовем его I. Postgres должен уметь отличать новый активный кортеж I от старой версии D. Для этого в каждом кортеже есть поле с номером версии и указатель на предыдущий кортеж (если такой есть). Соответственно, обновленная таблица выглядит следующим образом:
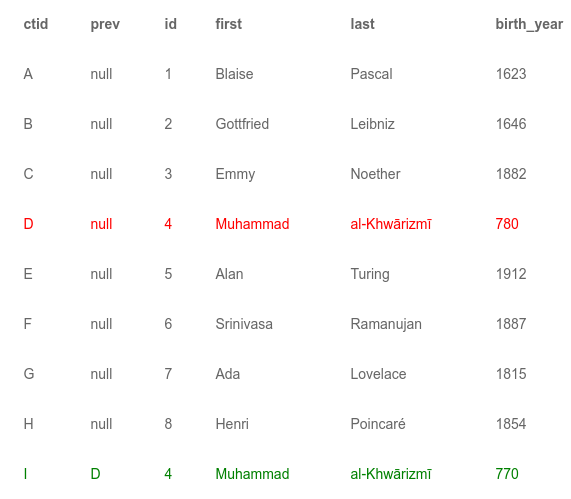
Поскольку у нас теперь есть две строки с al-Khwarizmi, индексы должны содержать записи для каждой из них. Для краткости мы опустим индекс по первичному ключу и покажем только вторичные индексы:

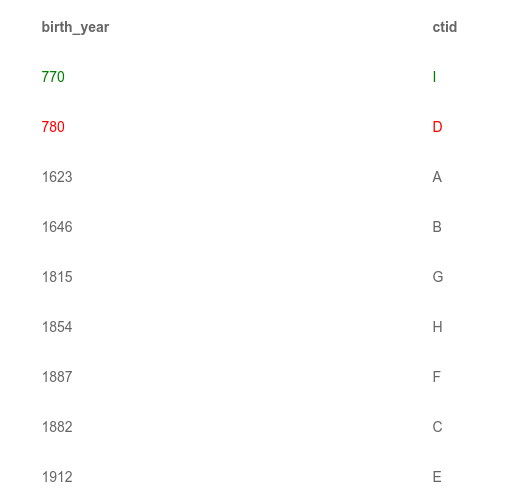
Старая версия выделена красным цветом, а новая — зеленым. Под капотом Postgres есть еще одно поле, в котором хранится версия кортежа. Это поле позволяет СУБД показывать транзакциям только те строки, которые им положено видеть.
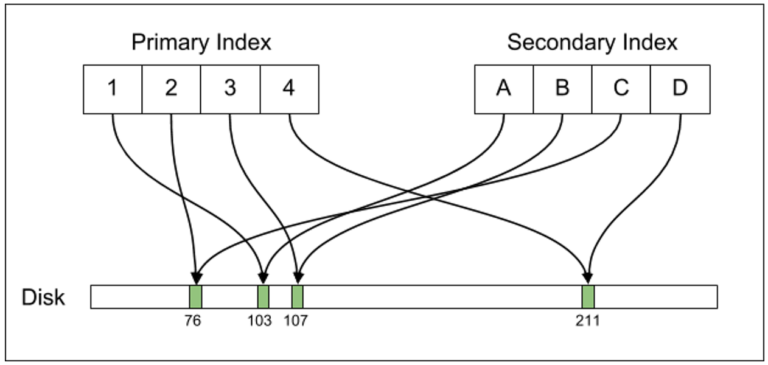
В Postgres первичный и вторичный индексы прямо указывают на физические смещения кортежей на диске. При изменении расположения строки индексы необходимо обновить.
Репликация
Если в Postgres настроена потоковая репликация, то, например, при вставке в таблицу новой строки такое изменение нужно реплицировать. Для целей восстановления после сбоев в СУБД встроен журнал упреждающей записи (write-ahead log, WAL), который используется для выполнения двухфазной фиксации (two-phase commit). СУБД должна вести WAL даже при отключенной потоковой репликации, поскольку WAL также нужен для соответствия принципам атомарности (atomicity) и надежности (durability) требований ACID.
Чтобы лучше понять WAL, рассмотрим случай незапланированного завершения работы СУБД, который может произойти, например, при отключении питания. В WAL заносятся все изменения, которые СУБД планирует сделать в содержимом таблиц и индексов на диске. Демон Postgres после запуска сравнивает WAL с данными на диске. В том случае если в WAL есть что-то, еще не записанное на диск, СУБД вносит изменения, приводя в соответствие данные на диске и содержимое журнала упреждающей записи. Затем СУБД откатывает те инструкции в WAL, которые относятся к незафиксированным транзакциям.
Потоковая репликация в Postgres реализована путем пересылки WAL с мастера на реплики, которые фактически работают в режиме восстановления после сбоя, постоянно применяя обновления WAL точно так же, как это бы делалось в случае запуска системы после некорректного завершения работы. Единственным отличием потоковой репликации от восстановления после сбоя является то, что реплики работают в режиме горячего резерва (hot standby), обслуживая запросы на чтение параллельно с применением потоковых изменений, тогда как база данных Postgres, находящаяся в режиме восстановления, обычно отказывается обслуживать какие-либо запросы до тех пор, пока процесс восстановления не будет закончен.
Поскольку WAL был разработан для целей восстановления, в него записывается низкоуровневая информация об обновлении данных на диске. Содержимое WAL находится на уровне фактического представления данных кортежей на диске, включая их физические смещения (т. е. значения ctid). Если приостановить мастер и полностью синхронизированную с ним реплику, фактическое расположение данных на дисках обеих систем будет идентичным буквальной байт в байт. Таким образом, инструменты типа rsync могут использоваться для восстановления данных реплики, если она сильно отстала от мастера.
К чему приводят особенности дизайна Postgres
Особенности Postgres привели к трудностям и снижению эффективности работы с данными в Uber.
Усиление записи
Первая проблема дизайна Postgres связана с усилением записи. Обычно этот термин упоминается в связи с особенностями работы SSD-дисков: логически небольшое обновление (скажем, запись нескольких байт) становится гораздо более серьезной и ресурсоемкой операцией на физическом уровне. Похожая проблема есть и в Postgres. В нашем предыдущем примере, когда мы сделали логически небольшое обновление, изменив год рождения al-Khwarizmi, физически система должна была выполнить как минимум четыре операции:
1) записать новый кортеж в табличное пространство,
2) обновить индекс по первичному ключу, добавив запись для нового кортежа,
3) обновить индекс (first, last), добавив запись для нового кортежа,
4) обновить индекс birth_year, добавив запись для нового кортежа
На самом деле эти четыре пункта отражают лишь изменения, сделанные в основном табличном пространстве (main tablespace), но они также должны быть учтены в WAL, поэтому общее число операций записи еще больше.
Стоит отдельно упомянуть пункты 2 и 3. После того как мы обновили год рождения al-Khwarizmi, не изменились ни первичный ключ записи, ни значения имени и фамилии. И все же индексы приходится обновлять, поскольку в базе данных появился новый кортеж. Для таблиц с большим количеством вторичных индексов эти дополнительные шаги могут приводить к значительным накладным расходам на запись. Например, для таблицы с десятком индексов обновление поля, покрытого лишь одним индексом, должно быть распространено на остальные девять, поскольку необходимо прописать в них ctid новой строки.
Репликация
Проблема с усилением записи затрагивает и репликацию, которая выполняется на уровне представления данных на диске. Вместо передачи небольшой логической записи, такой как, например, «Изменить год рождения для ctid D, установив его в 770», СУБД должна переслать все элементы WAL, касающиеся четырех вышеупомянутых операций, сопровождающих запись. Таким образом, проблема усиления записи переходит в проблему усиления репликации, и поток репликационных данных Postgres очень быстро становится настолько значительным, что может занять большую часть доступной пропускной способности сети.
В тех случаях, когда репликация выполняется в пределах одного датацентра, проблем с пропускной способностью, вероятнее всего, не возникнет. Современное сетевое оборудование способно справится с большими объемами данных, а многие хостинг-провайдеры взимают незначительную плату за передачу данных внутри датацентра либо предоставляют эту услугу бесплатно. Однако, когда требуется настроить репликацию между машинами в разных датацентрах, проблемы могут начать расти как снежный ком. Например, в Uber сначала использовались физические серверы в колокейшн-центре на Западном побережье. На случай аварийного восстановления мы разместили несколько реплик на дополнительных серверах на Восточном побережье.
За счет использования каскадной репликации нам удалось уменьшить объем пересылаемых между датацентрами данных до значений, необходимых для репликации между одним мастером и одной репликой. Однако «многословность» Postgres-репликации все равно может привести к необходимости передачи слишком больших объемов, если используется много индексов. Покупка высокоскоростных каналов передачи данных, соединяющих разные концы страны, — дорогое удовольствие. Но даже когда деньги не проблема, получить скорости, сравнимые с локальными сетевыми соединениями датацентов, просто невозможно. Эта проблема с пропускной способностью также создает трудности при архивации WAL. В дополнение к пересылке обновлений WAL с Западного на Восточное побережье мы архивировали его в веб-хранилище файлов. Эти архивы могли быть использованы как в случае необходимости аварийного восстановления, так и для развертывания новых реплик. Во время пиковых нагрузок пропускной способности сетевого соединения с хранилищем файлов было просто недостаточно, чтобы успевать передавать обновления WAL, создаваемые в процессе работы с базой данных.
Повреждение данных
Во время стандартной операции по увеличению емкости базы данных, при которой использовался механизм повышения роли реплики, мы столкнулись с ошибкой в Postgres 9.2. Реплики некорректно обрабатывали переключение шкалы времени (timeline switch), в результате чего некоторые из них неверно применяли обновления WAL. Из-за этой ошибки некоторые записи, которые должны были быть деактивированы механизмом версионирования, не получили соответствующую пометку, то есть остались активны.
С помощью следующего запроса можно проиллюстрировать, как эта ошибка отразится на нашем примере с таблицей пользователей:
SELECT * FROM users WHERE id = 4;Запрос вернет две записи: исходную строку для al-Khwarizmi с годом рождения, равным 780, а также новую запись с birth_year = 770. Если мы добавим в запрос колонку ctid, то получим отличающиеся значения этих идентификаторов, как у двух разных строк.
Эта проблема оказалась для нас крайне неприятной по нескольким причинам. Во-первых: было невозможно точно сказать, сколько строк было затронуто. В некоторых случаях дубликаты приводили к сбоям в работе приложения. В итоге нам пришлось добавить в код приложения инструкции для обнаружения подобных ситуаций. Во-вторых: поскольку ошибка проявлялась на всех серверах, каждый из них портил разные строки, то есть на одной реплике строка X могла быть повреждена, а Y нетронута, но на другой реплике строка X могла быть в порядке, а Y — повреждена. На самом деле мы точно не знали, на скольких репликах были поврежденные данные, а также проявлялась ли эта проблема на мастере.
Насколько мы поняли, на всю базу обычно повреждалось лишь несколько строк, но все же мы были крайне обеспокоены, поскольку индексы могли оказаться полностью испорченными из-за того, что репликация осуществляется на физическом уровне. Существенной особенностью B-деревьев является необходимость их периодической перебалансировки, и эта операция может полностью изменить структуру дерева, поскольку поддеревья перемещаются в другие места на диске. При перемещении поврежденных данных значительные части дерева могут оказаться некорректными.
В итоге мы смогли найти ошибку и, проанализировав ее, выяснить, что на реплике, которая становилась новым мастером, строки не повреждались. Путем повторной синхронизации со свежим снимком мастера мы исправили данные на всех репликах. Это был весьма трудоемкий процесс, поскольку в то время мы могли позволить себе одновременно изъять из рабочего пула балансировки нагрузки лишь несколько реплик.
Найденная ошибка проявлялась в некоторых релизах Postgres 9.2 и теперь уже давно исправлена. Однако мы очень обеспокоены тем фактом, что такое вообще оказалось возможно. В любое время можно ожидать выхода новой версии Postgres с подобной ошибкой, и из-за особенностей механизма репликации проблема может распространиться на все базы данных в репликационной иерархии.
MVCC на репликах
Postgres фактически не поддерживает MVCC на репликах. Поскольку на репликах применяются обновления WAL, на них в любой момент времени находится копия базы с таким же, как и на мастере, представлением данных на диске. Для Uber это серьезная проблема.
Чтобы обеспечить работу механизма MVCC, СУБД необходимо хранить старые версии строк. Если на реплике, использующей потоковую репликацию, открыта транзакция, то обновления захваченных ею строк будут заблокированы. В такой ситуации Postgres приостанавливает применение изменений WAL до тех пор, пока транзакция не будет завершена. Если транзакция выполняется длительное время, это становится проблемой, поскольку происходит значительное отставание реплики от мастера. На этот случай в Postgres есть специальный таймаут: если транзакция блокирует применение WAL в течение определенного времени, Postgres ее прерывает.
Такая особенность Postgres приводит к тому, что отставание реплик от мастера на секунды начинает происходить регулярно. Также становится проще написать такой код, который будет приводить к прерыванию работы транзакций. Эта проблема может быть неочевидной для разработчиков приложений, пишущих код, в котором начало и конец транзакции не указываются в явном виде. Скажем, разработчик создает модуль, отправляющий пользователю чек по электронной почте. Такая программа может неявно начать транзакцию и не фиксировать ее до тех пор, пока письмо не будет отправлено. Безусловно, не нужно писать код, который держит открытыми транзакции во время выполнения несвязанного блокирующего ввода-вывода, но реальность такова, что многие программисты не являются экспертами по базам данных и не всегда понимают суть проблемы, особенно при использовании ORM, которая скрывает низкоуровневые детали, в том числе и связанные с транзакциями.
Обновление Postgres
Поскольку репликация работает на физическом уровне, оказывается невозможным реплицировать данные между серверами, имеющими разные версии Postgres. Мастер с Postgres 9.3 не сможет реплицировать данные на реплику под управлением Postgres 9.2; точно так же не будет работать и репликация с 9.2-мастера на 9.3-реплику.
Чтобы обновиться с одного релиза на другой, необходимо проделать указанные действия:
- Остановить мастер.
- На мастере для обновления данных запустить pg_upgrade. На больших базах данных это может занять несколько часов, в течение которых мастер не будет обслуживать запросы.
- Запустить мастер.
- Сделать снимок мастера. На этом шаге копируются все данные мастера, что для больших баз может снова занять несколько часов.
- Очистить реплики и восстановить на них новый снимок мастера.
- Вернуть все реплики в репликационную иерархию. Дождаться, пока реплики догонят мастера, применив все обновления, которые произошли на нем за время восстановления реплик.
Мы начали с Postgres 9.1 и успешно выполнили все шаги для обновления на 9.2. Этот процесс занял много часов, и мы бы не смогли себе позволить выполнить его еще раз. К тому времени, когда вышел Postgres 9.3, объем наших данных значительно увеличился, так что обновление заняло бы еще больше времени. Поэтому оставшиеся в строю экземпляры Postgres до сих пор используют версию 9.2, несмотря на то, что уже вышел релиз 9.5.
При использовании Postgres версии 9.4 или более поздней есть возможность применить инструмент типа pglogical, который реализует логическую репликацию в Postgres. С помощью pglogical можно реплицировать данные между разными версиями Postgres, что делает возможным обновление, например, с 9.4 на 9.5 с минимальным временем простоя. Но эта функциональность не включена в основу Postgres, поэтому ее нужно применять с осторожностью. А для тех, кто до сих пор работает на более старых релизах Postgres, pglogical вообще не вариант.
Архитектура MySQL
В дополнение к описанию ограничений Postgres мы хотели бы объяснить, почему MySQL стал важным для Uber Engineering инструментом в таких проектах, как, например, Schemaless. Во многих случаях оказывалось, что MySQL подходит нам лучше всего. В этом разделе мы проанализировали архитектуру MySQL и ее отличия от Postgres. Особое внимание было уделено работе InnoDB, которая, возможно, является самой популярной подсистемой хранения данных для MySQL.
InnoDB — представление данных на диске
Как и Postgres, InnoDB поддерживает MVCC и другие продвинутые функции. Исчерпывающее описание формата представления данных на диске, реализуемого InnoDB, выходит за рамки данной статьи. Вместо этого мы сконцентрируемся на отличиях от Postgres.
Наиболее важное архитектурное отличие заключается в том, что Postgres напрямую сопоставляет записи индекса с адресами на диске, а в InnoDB есть дополнительная структура, в рамках которой записи индекса содержат не указатель на место на диске (как ctid в Postgres), а указатель на значение первичного ключа. Таким образом, ключи вторичных индексов в MySQL ассоциированы со значениями первичного ключа:
| first | last | id (primary key) |
| Ada | Lovelace | 7 |
| Alan | Turing | 5 |
| Blaise | Pascal | 1 |
| Emmy | Noether | 3 |
| Gottfried | Leibniz | 2 |
| Henri | Poincare | 8 |
| Muhammad | al-Khwarizmi | 4 |
| Srinivasa | Ramanujan | 6 |
Чтобы выполнить поиск по индексу (first, last), необходимо выполнить два действия: найти первичный ключ записи в таблице, а затем в индексе по первичному ключу отыскать расположение строки на диске.
Такое конструктивное решение ставит InnoDB в менее выгодное положение по сравнению с Postgres, поскольку предполагает выполнение дополнительной операции по поиску ключа. Однако, так как данные нормализованы, при обновлении строк затрагиваются только те индексы, которые построены по изменившимся полям. Также InnoDB обычно выполняет обновления строк прямо на месте. Если каким-либо транзакциям в рамках механизма MVCC необходима старая версия строки, MySQL копирует ее в специальную область под названием сегмент отката (rollback segment).
Давайте посмотрим, что происходит при обновлении года рождения al-Khwarizmi. При наличии свободного места новое значение будет записано прямо в исходную строку с id=4 (на самом деле такое обновление в любом случае произойдет «на месте», так как в данном случае birth year — это целочисленная колонка, значение которой занимает фиксированное количество байт). Индекс по полю birth year также обновляется «на месте», а старая версия строки копируется в сегмент отката. Индекс по первичному ключу обновлять не нужно (как и индекс (first, last)). Даже если у таблицы много индексов, нам нужно обновить только те из них, которые построены по полю birth_year. Поэтому, если, скажем, у нас были бы индексы по полям signup_date, last_login_time и т. д., они бы остались нетронутыми, тогда как в Postgres их пришлось бы обновить.
Такой дизайн также делает более эффективными процедуры очистки (vacuum) и уплотнения (compaction). Например, все строки, которые надо очистить, можно найти в сегменте отката. Для сравнения: в Postgres для поиска удаленных строк autovacuum должен просканировать всю таблицу целиком.

В MySQL используется дополнительный уровень абстракции: записи вторичных индексов ссылаются на первичный индекс, который, в свою очередь, содержит ссылки на расположение данных на диске. При изменении смещения строки обновляется только основной индекс.
Репликация
MySQL поддерживает несколько различных режимов репликации:
- При statement-based-репликации передаются логические SQL-выражения (в нашем примере будет в буквальном смысле слова реплицировано выражение:
sql UPDATE users SET birth_year=770 WHERE id = 4). - При row-based-репликации пересылаются изменившиеся строки.
- При смешанной (mixed) репликации используются оба вышеперечисленных способа.
У каждого из этих режимов есть свои плюсы и минусы. Statement-based-репликация обычно самая компактная, но от реплик может потребоваться выполнение ресурсоемких операций для обновления небольших объемов данных. С другой стороны, row-based-репликация, которая похожа на репликацию с использованием WAL в Postgres, «многословнее», но приводит к более предсказуемому и эффективному обновлению данных на репликах.
В MySQL на дисковые смещения данных строк ссылается только основной индекс, что имеет важные последствия для репликации. Поток репликационных данных в этом случае должен содержать лишь информацию о логических обновлениях строк. Репликационные обновления имеют вид «Изменить timestamp строки X с T_1 на T_2». При этом реплики автоматически выполняют необходимые изменения индексов.
В Postgres поток репликационных данных, напротив, содержит физические изменения, такие как «Записать байты XYZ по смещению 8,382,491». Каждое физическое изменение данных должно быть включено в поток WAL. Небольшие логические изменения (такие как, например, обновление timestamp) приводят к существенным изменениям на диске: создается новый кортеж и обновляются все индексы. Таким образом, в поток WAL должно быть включено большое количество изменений. Это различие в архитектуре системы приводит к тому, что используемый для репликации бинарный лог MySQL гораздо компактнее потока WAL PostgreSQL.
Особенности репликации также оказывают существенное влияние на работу механизма MVCC на репликах. Поскольку MySQL реплицирует логические изменения, реплики могут использовать настоящую MVCC-семантику, в результате чего запросы на чтение данных не будут блокировать репликацию. Напротив, в Postgres поток репликационных данных содержит физические изменения на диске, поэтому реплики не могут применить обновления, конфликтующие с выполняющимися запросами на чтение, то есть по сути не могут реализовать MVCC.
Реализация репликации в MySQL устойчива к повреждениям данных в таблице, и катастрофический сбой маловероятен. Поскольку репликация делается на логическом уровне, такие операции, как перебалансировка B-дерева, никогда не приведут к повреждению индекса. Для MySQL типичны проблемы репликации, при которых SQL-инструкция может быть пропущена (или реже применена дважды). Это может привести к потере или порче данных, но не вызовет недоступности базы целиком.
Наконец, в MySQL очень просто реплицировать данные между базами, работающими под управлением разных релизов этой СУБД. MySQL увеличивает номер версии на единицу только в том случае, если меняется формат репликации, а для разных релизов в рамках одной версии это не характерно. Логическая репликация также позволяет добиться того, что изменения формата хранения данных на диске не влияют на формат репликации. Типовой способ перехода на новый релиз MySQL — постепенное обновление реплик, а затем, когда все они будут обновлены, повышение одной из них до мастера. Такая операция выполняется практически без простоя и облегчает поддержание MySQL в актуальном состоянии.
Другие преимущества архитектуры MySQL
До этого момента мы преимущественно рассматривали особенности архитектур Postgres и MySQL, связанные с хранением данных на диске. Но есть и другие важные аспекты дизайна MySQL которые помогают этой СУБД работать значительно лучше, чем Postgres.
Пул буферов
В двух рассматриваемых СУБД кеширование устроено по-разному. Postgres выделяет некоторое количество памяти для внутренних кешей, но ее размер обычно намного меньше общего объема оперативной памяти машины. Для увеличения производительности Postgres позволяет ядру автоматически кешировать содержимое диска с помощью страничного кеша (page cache). Например, наши самые мощные реплики Postgres оснащены 768 Гб ОЗУ, но на RSS-память, выделенную процессам Postgres, приходится только 25 Гб. Таким образом, более 700 Гб памяти остается страничному кешу Linux.
Проблема заключается в том, что доступ к данным с помощью страничного кеша является более ресурсоемким по сравнению с RSS. Для поиска данных на диске Postgres использует системные вызовы lseek(2) и read(2). Каждый из них подразумевает переключение контекста, что менее эффективно по сравнению с работой с основной памятью напрямую. На самом деле Postgres есть что оптимизировать даже в рамках используемой методики: эта СУБД не использует pread(2), который объединяет операции поиска и чтения (seek + read) в один системный вызов.
При этом подсистема хранения InnoDB реализует собственный LRU под названием пул буферов (buffer pool) InnoDB. Этот механизм похож на страничный кеш Linux, но он реализован в пространстве пользователя. Будучи гораздо более сложным по сравнению с решением от Postgres, пул буферов InnoDB имеет несколько преимуществ:
- Появляется возможность написать собственный LRU. Например, можно реализовать механизм выявления способов обращения к кешу, негативно влияющих на его эффективность, а также принимать соответствующие меры по минимизации последствий.
- Снижается количество переключений контекста. Доступ к данным с помощью пула буферов InnoDB не требует переключений контекста пользователь—ядро. В худшем случае мы сталкиваемся с промахами TLB, которые, однако, относительно недороги и могут быть минимизированы с помощью huge pages.
Управление соединениями
В MySQL на каждое соединение создается отдельный поток (thread). Это приводит к сравнительно небольшим накладным расходам: на каждый поток уходит немного памяти в стеке, а также выделяется несколько буферов в куче. Нередко встречаются системы, в которых MySQL обслуживает до 10 000 параллельных соединений. Некоторые из наших серверов MySQL в настоящее время близки к этому значению.
В Postgres на каждое соединение создается отдельный процесс. По сравнению с использованием потоков это более ресурсоемкое решение. На создание нового процесса требуется больше памяти, нежели на порождение нового потока. Более того, IPC между процессами также является более ресурсоемким, чем между потоками. Postgres 9.2 использует примитивы System V IPC вместо легковесных фьютексов (futexes), которые быстрее по той причине, что во многих случаях, когда за мьютекс нет соперничества, нет и необходимости переключать контекст.
Помимо вышеперечисленных проблем, похоже, в Postgres не лучшим образом реализовано управление большим количеством соединений. Даже в тех случаях, когда памяти было более чем достаточно, мы испытывали серьезные проблемы с масштабированием Postgres после достижения порога в несколько сотен соединений. В документации (хотя мы не смогли найти этому точного объяснения) настоятельно рекомендуется использовать внешний пул (connection pooler) для обслуживания большого количества соединений. Для этих целей мы достаточно успешно применяли pgbouncer. Однако периодически проявлялась ошибка, которая приводила к открытию большего количества активных соединений (обычно в статусе “idle in transaction”), чем было нужно. В итоге это приводило к увеличению времени простоя.
Заключение
Postgres хорошо послужил нам на ранних этапах развития Uber, но по мере роста компании мы столкнулись с серьезными проблемами масштабирования систем, основанных на этой СУБД. На текущий момент у нас в строю осталось несколько экземпляров Postgres, но основная масса баз данных работает под управлением MySQL (по большей части на уровне Schemaless), а в несколькоих особых случаях применяются NoSQL-базы, такие как Cassandra. В целом мы весьма довольны MySQL и в будущем планируем написать еще несколько статей об интересных и сложных случаях использования этой СУБД в Uber.
Evan Klitzke является штатным специалистом (инженером) по программному обеспечению в группе базовой инфраструктуры Uber Engineering. Он также с энтузиазмом занимается базами данных, а к Uber присоединился в сентябре 2012.
Комментарии (51)

Edison
07.03.2017 12:37+25А за три года до этого, Убер перешел с MySQL на PostgreSQL

gekk0
07.03.2017 12:52+5Да, есть такое дело.
Тот же самый автор — Evan Klitzke — писал об этом переходе: https://www.yumpu.com/en/document/view/53683323/migrating-uber-from-mysql-to-postgresql
Он, видимо, всё никак он не определится.


reforms
07.03.2017 13:49Интересно еще бы узнать порядок цифр ежедневного объема обрабатываемых данных и финансовые выгоды/затраты при миграции с одной СУБД на другую
chabapok
07.03.2017 14:45+2Немножко неочевидно вот это утверждение: "В Postgres на каждое соединение создается отдельный процесс. По сравнению с использованием потоков это более ресурсоемкое решение. На создание нового процесса требуется больше памяти, нежели на порождение нового потока."
Насколько знаю, fork() на сегодняшних компьютерах не копирует всю память — а только лениво копирует только те страницы, в которых что-то изменяется. Где-то на ютубе была лекция, в которой рассказывали, что это очень быстро и эффективно и используется в некоторых базах данных для практически мгновенного создания атомарного слепка базы: делаем fork- и имеем атомарный слепок, которых потихоньку пишем на диск, и при этом основной процесс может менять свою область памяти не опасаясь изменить еще не записанные данные.
youROCK
07.03.2017 15:24+3Чем больше резидентная память процесса, тем дольше будет идти форк. На одном из тестовых серверов с более-менее современными процессором я намерял, что форк 1-гигабайтного процесса занимает порядка 7мс:
$ php -r '$a = str_repeat("ololo", 200 * 1024 * 1024); var_dump(getrusage()["ru_maxrss"]); $start = microtime(true); $pid = pcntl_fork(); if ($pid == 0) die; echo (microtime(true) - $start) . " sec\n";' int(1031604) 0.0074088573455811 sec
Если у вас резидентный набор процесса будет 100 гигабайт, то это будет уже 750 мс.chabapok
08.03.2017 01:33По всей видимости, чтобы пометить каждую страницу памяти как copy-on-write — их надо все пробежать, возможно с подтягиванием каждой страницы в L0. Это конечно не копировать — но все равно какое-то время.
Навскидку:
#include <stdint.h> #include <stdio.h> #include <inttypes.h> #include <stdlib.h> #include <sys/types.h> #include <unistd.h> __inline__ uint64_t rdtsc() { uint64_t x; __asm__ volatile ("rdtscp\n\tshl $32, %%rdx\n\tor %%rdx, %%rax" : "=a" (x) : : "rdx"); return x; } void test(size_t size){ char * mem = (char *) malloc(size); uint64_t p; for(p=0; p<size; p++){ mem[p] =(char) p%17; } uint64_t x = rdtsc(); pid_t pid = fork(); uint64_t diff = rdtsc() - x; free(mem); if (0==pid) exit(0); printf("%" PRIu64 "M -> %" PRIu64 "\n", size/(1024*1024), diff); } int main(){ int i; for(i=0; i<14; i++) test(1024*1024LL*(1<<i) ); return 0; }
результат(в тиках):
1M -> 378173
2M -> 421121
4M -> 429324
8M -> 438039
16M -> 447977
32M -> 477917
64M -> 554516
256M -> 980945
512M -> 1457601
1024M -> 2484345
2048M -> 4366125
4096M -> 7856287
8192M -> 15170437
Начиная с некоторого размера fork() с ростом размера время растет линейно. Когда размер памяти мал, то вероятно, работают кэши. На самом деле это может означать, что мой тест некорректен в этой части, но вцелом суть зависимости — ясна.youROCK
08.03.2017 01:41Еще было бы неплохо проверить, не включены ли transparent huge pages и просто huge pages. Потому что с большими страницами время форка будет минимально, но зато изменение любого участка памяти в чилде или в родителе будет приводить к копированию огромного (по сравнению с 4к) куска памяти, и соответственно будет быстрее кончаться память в системе, да и производительность будет оставлять желать лучшего.
chabapok
08.03.2017 20:31худжпэджэсы не включены.
Что означает в этом контексте «да и производительность будет оставлять желать лучшего»? Про особенности копирования вы рассказали, очевидно, вы предполагали нечто еще.
Насколько понял из моей тестовой проги, производительность проседает после хипа 4гб: 8гиг заполнялось раз 10дольше, чем 4. Видимо, аппаратная TLB-таблица, или какая-то другая таблица заканчивается — и оно переходит на полусофтварный способ трансляции физических адресов в логические.
Только вот, с форком это уже никак не связано. Но очевидно, гигансткие хипы тормозные сами по себе. Интересно, где этот порог у ксеонов.

netch80
11.03.2017 08:41+1Кэши собственно данных, типа L0, в этом не участвуют, читать-писать основное содержимое страниц не нужно. А вот создать копию VM map процесса — задача достаточно затратная, включая карты physical maps с инкрементом счётчиков использования (вот тут наверняка кэш и насилуется).
youROCK
07.03.2017 15:29+2Плюс к этому, при форке вся память помечается, как copy-on-write, и если будет, например, следующее, то рано или поздно родителя (или чилда) прибьют SIGKILL по OOM:
— системе доступно 10 Гб ОЗУ
— процесс жрет 8 Гб ОЗУ
— процесс форкается
— чайлд долго пишет свой снапшот на диск
— родительский процесс достаточно быстро модифицирует свою память и в итоге свободная память в системе кончается
vadv
07.03.2017 23:58fork, copy-on-write поможет
популярное заблуждение, посмотрите на популярность pgbouncer — это костыль именно для решения проблемы fork и вымывания набраного бакендом кэша (например дескрипторы открытых файлов ), но pgbouncer не решает проблемы полностью, например приходиться отказываться от prepared-statement
Bozaro
07.03.2017 14:56+2В репликации MySQL много недостатков.
На эту тему мне очень нравится статья: https://habrahabr.ru/company/oleg-bunin/blog/313594/

Dethrone
07.03.2017 17:35так же детали обсуждаются в этом эпизоде SE Radio
https://softwareengineeringdaily.com/2016/09/09/ubers-postgres-problems-with-evan-klitzke/

alexey_kozin
07.03.2017 17:35-6имхо мое мнение человека не являющегося спецом ни в PostgreSQL ни в MySQL
вывод о недостатках при потерях быстродействия при модификациях данных входящих в кластерный индекс весьма надуманы т.к. назначение кластерного индекса физический порядок хранения данных, то есть в кластерный индекс нужно первично заложить константу, то есть данные которые не будут изменяться, при построении любого индекса предусматривающего модификации нужно запланировать необходимый процент заполнения, т.е. свободного места необходимого под быстрые модификации до процедуры реиндексации.
в противном случае все эти выводы с употреблением высокопарных научных терминов выглядят как некое самооправдание.но сработает оно только «для начальства». любой спец подвох раскусит.
а вот если постгри допускает вывод дублирующей записи при условии нарушения уникальности заданного для таблицы ключа — то это недочет критического уровня. если этот баг реально есть -значит эту субд просто нельзя использовать вообще нигде и никогда.
я полагаю что поле id определенное как примари кей в постгри предоплагает что оно уникально без каких либо дополнительных действий (как это в других, нормальных субд)

Falseclock
07.03.2017 19:28+7очень и очень много ковырял приложения как водительское так и пользовательское… могу сказать, что код писали индусы… криво, косо, не эффективно и иногда вообще адски! Планирую об этом статью написать
Nakosika
07.03.2017 21:48Довольно сложно убедить продакт овнера что тебе нужен месяц на переписывание всего сетевого стека. Так и растет кодбейз, ужасая новичков. Когда компания руководится не самыми лучшими спецами то и хорошие программисты будут говнокод шлепать.

zBit
07.03.2017 19:49-1Я как вспомню необходимость использования в качестве PK не автоинкрементируемое число, а строку (GUID) и метод LAST_INSERT_ID() — так мурашки по коже идут и плакать хочется. Возможно сейчас ситуация совсем другая, давно не использовал MySQL.
Не понял почему инженеры из Uber не воспользовались Slony или Bucardo для репликации…
Беглым поиском не смог найти информацию об объёмах данных с которыми им приходится работать, количество запросов к БД на чтение/запись. А интересно было бы знать такое :)
Думаю, следует ждать через несколько лет статью о том как они мигрировали с MySQL на PostgreSQL.Falseclock
07.03.2017 20:13вы слишком сложно ударились в тему.
Вот для примера:
когда вы пассажир и смотрите в приложение, то вам показывается как движется автомобиль. На самом деле данные не реалтайм, а построены на фильтре Калмана. Слава богу что они додумались его использоваться. Но вместо того, чтобы открывать сокет и передавать в него данные, водительское приложение через HTTP запрос передает свои координаты, а сервер ему возвращает поллинг интервал когда сообщить в следующий раз.
В итоге получаем, что водитель уже на месте, а у пользователя по фильтру калмана водитель проехал дальше на пару километров вперед. А все потому что сервер ответил водителю передать свои координаты через 3 минуты, допустим. И это самый банальный пример.
А вы тут про guuid и инкременты.
struvv
07.03.2017 21:17+3Проблемы, о которых говорит Убер актуальны и Убер по моему не единственный, кто был вынужден мигрировать с постгри. До тех пор, пока есть один сервер, всё хорошо. Когда появляется реплика, возникают проблемы, бОльшая часть это рассинхрон реплики/мастера и особенно два datasource вместо одного и сложности с распределением нагрузки на slave. Хотя vacuum в 9.5-9.6 больше не влияет на накатывание лога в реплике благодаря новому праметру feedback_как_его_там, всё равно могут возникать остановки наката лога из-за длительно выполняющихся запросов на чтение в реплике, что делает репликацию на чтение не особо полезной. Таким образом пока проект не вырос выше одного мастера, всё отлично работает. Но дальше при необходимости репликации начинаются большие трудности

norguhtar
14.03.2017 13:36В любой РСУБД надо понимать, что master-slave нужен для сохранения горячего резерва и использование реплики для получения всегда актуальных данных это из области фантастики. В том числе и в случае MySQL.

seregamorph
07.03.2017 23:08Большой ли смысл держать на одном сервере БД более сотни соединений (не говоря уже о тысячах)? TPS от этого не вырастет, зато накладные ресурсы от переключений контекстов и расхода памяти будут весьма велики (что в форках, что в потоках).
youROCK
08.03.2017 00:42+1Если у вас сотни веб-серверов и сотни серверов баз данных, то даже один персистент коннект с каждого из веб-серверов приведет к сотням коннектов на каждой постгре. Так что, начиная с некоторого масштаба, это не такая уж надуманная проблема. Вон ютьюб вообще сделал прокси перед мускулем на го, чтобы держать по 100к коннектов на каждом узле.

SilenceAndy
09.03.2017 14:42Если у вас сотни веб-серверов...
То нужно использовать PgBouncer, о чём написано в каждой доке по развертыванию постгреса в продакшене.youROCK
09.03.2017 20:09Так убер же написал, что итак используют pgbouncer, разве нет? И даже пишут об этом:
Accordingly, using pgbouncer to do connection pooling with Postgres has been generally successful for us. However, we have had occasional application bugs in our backend services that caused them to open more active connections (usually “idle in transaction” connections) than the services ought to be using, and these bugs have caused extended downtimes for us.
Собственно, странно зачем нужен отдельный pgBouncer, если можно было встроить это прямо в БД?
vadv
11.03.2017 12:05+1Вообщем ребят, проблема не в fork, потому что fork происходит от супервизора с минимумом памяти, проблема в LoadCriticalIndex и кучей других кэшей которые бакенд загружает при старте.

geekmetwice
11.03.2017 14:56«Усиление записи» — несуразный термин, ближе по смыслу говорить «раздувание записи».
gekk0
12.03.2017 17:34Согласен, «раздувание записи» по смыслу ближе, но мне лично слух режет.
«Усиление записи» достаточно часто встречается в Интернете (в том числе на Хабре, Гиктаймс, 3dnews и др.): https://yandex.ru/search/?lr=11&msid=1489328416.72813.22886.28344&text=«усиление записи».
Мне этот термин по душе, хоть и не очень точно отражает суть.
У англичан amplification, судя по http://www.oxfordlearnersdictionaries.com/definition/english/amplification?q=amplification, имеет два основных значения: «усиление» и «добавление комментариев, пояснений». Какой смысл они имели в виду при создании термина write amplification? Мне кажется, что у них это тоже «усиление» в переносном смысле.
Как вариант, у генетиков можно позаимствовать вариант «амплификация».
VaalKIA
12.03.2017 20:04Раздувание, мне тоже режет слух, может быть что-то вроде «избыточная запись» или какой-то синоним?


customtema
14.03.2017 10:25-1MySQL давно не free. Звонили из Oracle и требовали денег, кроме шуток. Перешли на Percona.
Переход в Uber проплаченный — ради шумихи, стопудов.
Платили конечно не Uber, а кому-то из разработчиков.
Moldovich
14.03.2017 11:18Вы об этом?
Коммерческая лицензия позволяет производителям оборудования, независимым поставщикам и реселлерам распространять коммерческие исполняемые файлы программного обеспечения MySQL с их собственным коммерческим программным обеспечением, не подвергая, что программное обеспечение с лицензией GPL и его требование распространять исходный код.
[машинный перевод]
Источник.
Fesor
14.03.2017 11:20Мне вот тоже интересно. Единственный случай при котором они имеют право требовать деньги — нарушение GPL лицензии. То есть переход на Percona ситуацию не меняет так как будет то же нарушение.
AdVv
16.03.2017 12:55Есть еще люди, которые думают, что свободное ПО = бесплатное ПО. Это совсем не так.
Percona — не MySQL, и это меняет ситуацию в корне.

stalkerg
14.03.2017 13:21+5Старая тема но соображения такие:
- Да, проблеммы у Postgres есть, и Uber наткнулся только на маленькую часть. Но конкретно их проблемму вполне можно было бы сильно уменьшить если общаться с сообществом. (уже сейчас улучшения есть)
- Но главная проблемма Postrges которую никто не пытается исправить это дизайн >20 летней давности. Postgres развивается небольшими шажками без серьёзных рефакторингов из-за этого, код это ужасная лапша и архитектура сильно устарела, а у сообщество не может и не хочет что то менять. Отчасти из-за архитектуры и языка Си, развите postrges сейчас крайне сложное дело. Архитектурные пробелы это процессы, а не потоки и самопальный буфер менеджер вместо iommap. Не говоря уже про организацию tuple. На данный момент в аналитических запроссах большая часть времени уходит на процесс разбора тюплов. heap (сторадж данных) прибит гвоздями, индексы отваязаны но с ограничениями.
Простите за этот сумбур, я думаю тут надо писать целую статью, но общий вывод в том что postgres распространяется под BSD лицензией и его развитие это мягко говоря политическая игра между несколькими игроками… из-за этого реально нужные вещи просто не делаются.
PS но при этом, это хорошая СУБД и наверное одна из самых лучших, особенно что касается фичь SQL и расширябельности. Только вот насколько долго она такой останется?
norguhtar
14.03.2017 13:38+2Когда люди начинают писать мы начали использовать schemaless то сразу возникает вопрос зачем вам РСУБД?
stalkerg
14.03.2017 16:51+1Судя по профилю их нагрузки, им нужен был redis + что то для логов. (это если брать именно обновление позиции машины и статуса заказа) Им просто в большей части нагрузки MVCC нафиг не упёрся.

Razaz
14.03.2017 17:10В свое время, решал такую же задачу — стали писать в Cassandr'у. Нафига им РСУБД — непонятно.

NoRegrets
14.03.2017 22:02+2многие программисты не являются экспертами по базам данных и не всегда понимают суть проблемы, особенно при использовании ORM
поперхнулся чаем. Убер программисты.
Для MySQL типичны проблемы репликации, при которых SQL-инструкция может быть пропущена (или реже применена дважды). Это может привести к потере или порче данных, но не вызовет недоступности базы целиком
Это в конечно итоге приведет к тому, что репликация сломается. Веселенькие дела, у тебя 2 базы, оба мастера и один вдруг не может в репликацию, потому что видите-ли, у него вот этой строки нет. И сидишь и думаешь что, блин, значит нет этой строки, у вас тут давеча репликация была или дискотека?
novoxudonoser
можно ссылку на то, где их препарируют?
gekk0
Вот несколько навскидку:
* http://use-the-index-luke.com/blog/2016-07-29/on-ubers-choice-of-databases
* https://blog.2ndquadrant.com/thoughts-on-ubers-list-of-postgres-limitations/
* http://rhaas.blogspot.ru/2016/08/ubers-move-away-from-postgresql.html
Fesor
Еще крайне интересно почитать мэйлинг лист postgresql по этому поводу:
https://www.postgresql.org/message-id/579795DF.10502@commandprompt.com
gekk0
Действительно интересно, спасибо!
Только дискуссия у них что-то быстро заглохла: проблемы признали, а что делать не решили.