

Примерно так выглядит первая инсталляция CEPH на реальном железе.
Вы установили цеф, но он тормозит и падает непонятно почему? Тогда вы пришли по адресу! Я прокачаю ваш CEPH.
Вы послушали своих друзей и поставили первые попавшиеся диски на свою колымагу, а потом удивляетесь, что она не делает рекорд круга на местном картадроме, а вы мечтали о Нюрбургринге? Правильно! Так не бывает, от физики никуда не уйдешь, поэтому перед построением кластера вы должны посчитать IOPS-ы (хотя бы примерно), требуемый объем и под это подбирать диски. Если вы думаете забить кластер 8ТБ дисками, то не стоит ожидать от него сотен тысяч IOPS. Что такое IOPS-ы и их примерное значение для разных типов дисков приведено здесь.
Еще одна вещь, на которую стоит обратить внимание — это журналы.
Для тех, кто не в курсе: ceph сначала пишет данные на журнал, а через какое-то время переносит их на медленный OSD. Сразу же появляются любители сэкономить, взять одну или две SSD побыстрее и сделать их журналом для 20-25 OSD. Во-первых, IOPS-ы у вас несколько просядут. Во-вторых, это работает до первой смерти SSD. Тогда у вас падают все OSD, что были на этом SSD. К настройке журналов надо подходить очень внимательно. В рекомендациях на сайте ceph.com указано, что необходимо не больше 5-6 OSD на один SSD, но при этом не указано, какой размер журнала указать и какой параметр filestore max sync interval выбрать. К сожалению, данные параметры индивидуальны для каждого кластера, поэтому подбирать их вам нужно будет самостоятельно путём многочисленных тестов.
Второе, что бросается в глаза, в нашей колымаге, это два больших дивана вместо сидений. Вы же не будете в 2017 году ставить в свою машину два дивана вместо сидений?

Применительно к CEPH мы сейчас говорим о пулах.
Обычно делают один большой пул и на этом останавливаются, но это неправильно. Один большой пул ведет к проблемам с удобством управления и апгрейдом. Как апгрейд связан с размером пула? А вот так: апгрейдить живой кластер на лету очень опасно, поэтому есть смысл развернуть новый небольшой рядом, отреплецировать данные в новый пул и переключить. Из этого выходит рекомендация: поделить данные на логические сущности. Если у вас openstack, то есть смысл отталкиваться от зон openstack. При большом количестве серверов размазывайте их по стойкам и рулите правилами crushmap.
Теперь залезем под капот.

Если мы проектируем систему не под десятки тысяч IOPS, то процессор можно поставить начального уровня. Однако учтите: чем больше дисков на один сервер и чем больше они могут отдать IOPS, тем сильнее нагрузка. Поэтому, если у вас сверхбюджетная конфигурация из 2-3х JBOD-ов на один сервер (что само по себе плохая идея), то процессор у вас будет грузиться сильно. Мы же с одним JBOD и 30-ю дисками процессор в полку еще не загоняли. А вот «проводку» меняем. Нет, конечно и на 1гбит\сек оно заведется, но при падении OSD начинается ребаланс и тут уже канал загружается по полной. Поэтому interconnect между нодами CEPH 10гбит/сек обязательно. Правило хорошего тона делать LACP.
«Подвеску» лучше усилить. Ставим памяти, исходя из рекомендованных 1 гигабайт RAM на 1тб данных. Можно и больше. По оперативной памяти CEPH достаточно прожорлив.

Теперь о быстрой езде на том, что построили.
В CEPH имеется проверка целостности данных — так называемые scrub и deep scrub. Их запуск сильно влияет на IOPS, поэтому запускать их лучше скриптом ночью, ограничив количество проверяемых PG.
Ограничьте скорость ребаланса параметрами osd_recovery_op_priority и osd_client_op_priority. Вполне можно пережить днём медленный ребаланс, а ночью, в моменты минимальной нагрузки, запустить его на полную.
Не заполняйте кластер под завязку: ограничение 85% не просто так создано. Если нет возможности увеличения места в кластере новыми серверами, то используйте reweight-by-utilization. Учтите, что у этой утилиты есть параметр по умолчанию 120%, а также что при её запуске начинается ребаланс.
Параметр weight тоже влияет на заполнение, но косвенно. Да, в CEPH есть weight и reweight. Обычно weight делают равным объему диска.

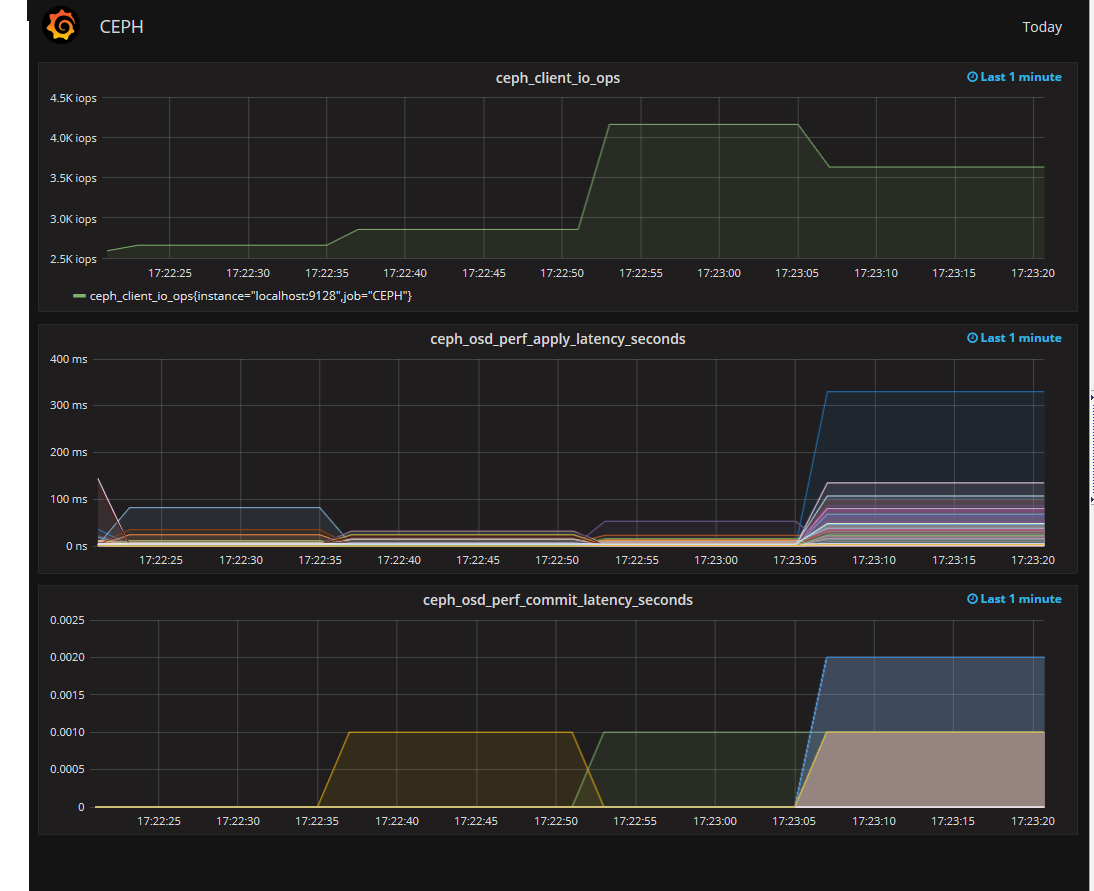
Итак, наш CEPH почти прокачан, осталось только приделать монитор. Мониторить можно чем угодно, но особо интересен мониторинг вывода ceph osd perf. Более всего интересен fs_apply_latency. Именно он показывает нам, какая из OSD долго отвечает и снижает производительность кластера. Притом, что SMART на этих OSD может быть вполне себе хорошим.
Выглядит это примерно так.

Итак, съемки превращения старой колымаги закончены. Пора показать backstage и опровергнуть о мифы, которые я слышал:
- Нормально делай — нормально будет. При грамотном проектировании CEPH не нужна большая команда админов на его поддержку.
- Баги есть. Видели ООМ на ОСД. Просто пришёл ООМ, убил ОСД, потом еще одну. На этом остановилось. Обновили CEPH, пару раз еще приходил ООМ, но потом так же внезапно прекратился. Отдебажить не удалось.
- Местами CEPH очень прожорлив по swap. Возможно надо править настройки swappiness.
- Переход с двойной на тройную репликацию это печально и долго, так что всё же хорошо подумайте.
- Используйте однотипные сервера, одну ОС в кластере и одну версию CEPH, вплоть до минорной. Теоретически, CEPH заведется на всём, но зачем потом индивидуально дебажить каждую железку?
- В CEPH меньше багов, чем кажется. Если вы думаете, что нашли баг, то для начала внимательнее почитайте документацию.
- Заведите один тестовый стенд на физическом железе. Не всё можно проверить в виртуальных машинах.
Отдельно хочу сказать о том, что не надо делать:
- Не вынимайте диски из разных нод плоского кластера со словами «это же цеф, чего ему будет?». Health error будет. В зависимости от количества данных в кластере и уровня репликации.
- Двойная репликация — путь экстремалов. Во-первых, больше шансов потерять данные, во-вторых, медленнее ребаланс.
- Dev релизы пусть тестируют разработчики, особенно всякие новые с bluestore. Оно, конечно, может работать, но когда грохнется, то как вы будете доставать данные из непонятной файловой системы?
- FIO с параметром engine=rbd может врать. Не стоит на неё полагаться при тестах.
- Не тащите сразу в прод всё то новое, что вы нашли в документации. Сначала проверьте на физическом стенде.
Спасибо за внимание.
Комментарии (18)

kataklysm
20.03.2017 16:44+3Простите, Enter сорвался :). Дополняю… а редактировать нет возможности.
Если у вас такой громкий заголовок статье, то почему нет параметров для оптимизации, а так же тесты и графики до и после?
Ну начнем по вашей же статье :)
Для тех, кто не в курсе: ceph сначала пишет данные на журнал, а через какое-то время переносит их на медленный OSD.
Вы очень сильно ошибаетесь, самое простое сравните количество чтение и записи на дисках с журналами.
какой размер журнала указать и какой параметр filestore max sync interval выбрать.
10Gb, значение filestore max sync interval по умолчанию подходит в 99.9% случаях.
Один большой пул ведет к проблемам с удобством управления и апгрейдом. Как апгрейд связан с размером пула?
Абсолютно ни как не связан.
поэтому есть смысл развернуть новый небольшой рядом, отреплецировать данные в новый пул и переключить.
Если понимать с вопроса «развернуть новый кластер?»
Не рассказывайте пожалуйста про rbd-mirror никому, т.к для прода он не готов и между разными версиями кластеров, в данный момент, в принципе не работает.
Если понимать с вопроса «развернуть новый пул?»
Риски от этого не изменяться, т.к. сервера с MON нужно обновлять до OSD. Отсюда следует, что изменение CRUSH-карты и распределение пула по определенным OSD нодам, ни чего полезного не даст.
с одним JBOD и 30-ю дисками
МММ? ;)
между нодами CEPH 10гбит/сек обязательно
C 30 дисками и 40Гбит/сек будет недостаточно, если использовать значения по умолчанию.
CEPH имеется проверка целостности данных — так называемые scrub и deep scrub.
Все очень хорошо крутится с параметрами:
«osd_scrub_sleep»: «0.5», можно увеличивать
«osd_disk_thread_ioprio_class»: «idle»,
«osd_scrub_load_threshold»: «1»,
«osd_disk_thread_ioprio_priority»: «7»
С использованием cfq scheduler на хостах с OSD.
Ограничьте скорость ребаланса параметрами osd_recovery_op_priority и osd_client_op_priority. Вполне можно пережить днём медленный ребаланс
Уверен на 146%, что не переживете, если бы вы хорошо протестировали, вы бы это поняли.
переживете с помощью:
«osd_recovery_delay_start»: ">0",
«osd_max_backfills»: «1»,
«osd_recovery_threads»: «1»,
«osd_recovery_max_active»: «1»,
Не заполняйте кластер под завязку
то используйте reweight-by-utilization.
Вы сами себе противоречите, т.к. reweight-by-utilization выставляет «высоты» OSD, количество данных в кластере от этого не поменяется.
интересен мониторинг вывода ceph osd perf.
Из своего опыта могу смело сказать, что лучше анализировать через сокеты, более подробно: ceph --admin-daemon /var/run/ceph/ceph-osd.N.asok perf dump
Видели ООМ на ОСД. Просто пришёл ООМ, убил ОСД
Местами CEPH очень прожорлив по swap. Возможно надо править настройки swappiness.
Смотрим в сторону sysctl.conf: vm.min_free_kbytes = 1024000 я думаю, что решит вашу проблему.
FIO с параметром engine=rbd может врать.
Говорит правду, просто нужно учитывать что на клиенте по умолчанию: rbd_cache = true
KorP
20.03.2017 18:10+2По-моему вам пора нести истину по Ceph в массы :) Особенно с высоты видимого опыта.
kataklysm
20.03.2017 20:13Видимо скоро придется это осуществить истину :). Предлагайте тему/ы ;)
KorP
20.03.2017 20:57Вот мне кажется, что автор хорошо уже начал и введение у него неплохое, надо как то развивать эту тему и развеивать миф, что Ceph это сложно, по тому что я и сам это довольно часто слышу. Так же интересует производительность на небольших системах (или с малым кол-вом репликаций), aka бюджетных и тд
SinTeZoiD
20.03.2017 23:44Главный миф, который стоит развеить после умирания cloudmouse это стабильность CEPH и его готовность к production. И я буду крайне рад, если мне его будут помогать развеивать. Вы же своим желанием сделать кластер «с малым количеством репликаций» лишь увеличиваете шансы пойти путём cloudmouse. К сожалению у CEPH есть нижнее ограничение по объему и количеству серверов. Этого нигде не пишут, но это выходит логически. И в некоторых случаях уж лучше взять старый добрый drbd со всеми его проблемами.
KorP
21.03.2017 08:24Касательно малого кол-ва репликаций — вопрос сводился к теме производительности системы, а не в плане надёжности.

trong
20.03.2017 21:07Предлагаю — расскажите как мониторить CEPH: как мониторить кластер, как завести графики производительности, заполненности в кибану/графану и т.д.

farcaller
20.03.2017 21:30https://github.com/digitalocean/ceph_exporter классный – экспортит в prometheus, а оттуда уже и графана, и алерты.
kataklysm
20.03.2017 21:43+1На самом деле средств для мониторинга более чем предостаточно. Нужно их просто поискать на github'е. Мы сами пользуемся zabbix'ом а далее уже используем модуль zabbix'а для grafana
trong
21.03.2017 07:52Мониторить <> завести в zabbix/графану/ etc
Тут вопрос более комплексный: какие метрики собирать, на что обращать внимание, что выводить на графики и как эти графики трактовать. Как различать — вот тут оно само починится, а тут уже админам звонить. Или вот тут вроде само чинится, но что-то идет не так.
SinTeZoiD
20.03.2017 23:3710Gb, значение filestore max sync interval по умолчанию подходит в 99.9% случаях.
Только вот по умолчанию значение журнала 5Gb + в оф доке есть формула для расчёта размера журнала. Зачем тогда оно надо, если всем подходит?
Если понимать с вопроса «развернуть новый кластер?»
Не рассказывайте пожалуйста про rbd-mirror никому, т.к для прода он не готов и между разными версиями кластеров, в данный момент, в принципе не работает.
Если понимать с вопроса «развернуть новый пул?»
Риски от этого не изменяться, т.к. сервера с MON нужно обновлять до OSD. Отсюда следует, что изменение CRUSH-карты и распределение пула по определенным OSD нодам, ни чего полезного не даст.
А что, разве есть что-то лучше, чем синхронизировать пулы и переключить клиентов?
Нет, есть второй вариант выдать блочники клиентам из нового кластера и попросить их самих смигрировать в новый кластер, но если у вас публичное облако, то «ой».
МММ? ;)
Что вас смущает? Нет это не один такой сервер, если вы про общий конфиг.
C 30 дисками и 40Гбит/сек будет недостаточно, если использовать значения по умолчанию.
Совет про 10Гбит/сек был про то, что это надо минимум, а не вообще.
С использованием cfq scheduler на хостах с OSD.
Чем вызван выбор именно этого планировщика?
Уверен на 146%, что не переживете, если бы вы хорошо протестировали, вы бы это поняли.
переживете с помощью:
«osd_recovery_delay_start»: ">0",
«osd_max_backfills»: «1»,
«osd_recovery_threads»: «1»,
«osd_recovery_max_active»: «1»
Ок, на кластере у нас это есть но в посте нет. Косяк.
Из своего опыта могу смело сказать, что лучше анализировать через сокеты, более подробно: ceph --admin-daemon /var/run/ceph/ceph-osd.N.asok perf dump
Лучше, чем что? чем вывод ceph osd perf может быть, однако тем же ceph_exporter к prometheus это банально удобнее.
Говорит правду, просто нужно учитывать что на клиенте по умолчанию: rbd_cache = true
Интересное заявление, хотелось бы пруфов.
kataklysm
21.03.2017 08:52Только вот по умолчанию значение журнала 5Gb + в оф доке есть формула для расчёта размера журнала. Зачем тогда оно надо, если всем подходит?
Не уточнил, мой косяк. Это для HDD-10Gb и этого более чем достаточно. Об этом же, в качестве примера, написано в документации.
А что, разве есть что-то лучше, чем синхронизировать пулы и переключить клиентов?
Нет, есть второй вариант выдать блочники клиентам из нового кластера и попросить их самих смигрировать в новый кластер, но если у вас публичное облако, то «ой».
Лучше миграция на новый кластер, но точно не создание логических пулов. Мигрировать те же самые виртуалки клиентов — абсолютно ни каких проблем, просто на это нужно чуть больше времени. Если же публичное облако RGW, то можно использовать RGW multisite.
Что вас смущает? Нет это не один такой сервер, если вы про общий конфиг.
Я подумал про JBOD/Pass-through Mode…
Чем вызван выбор именно этого планировщика?
Тем что написано в документации:
ceph cfqosd disk thread ioprio class
Description: Warning: it will only be used if both osd disk thread ioprio class and osd disk thread ioprio priority are set to a non default value. Sets the ioprio_set(2) I/O scheduling class for the disk thread. Acceptable values are idle, be or rt. The idle class means the disk thread will have lower priority than any other thread in the OSD. This is useful to slow down scrubbing on an OSD that is busy handling client operations. be is the default and is the same priority as all other threads in the OSD. rt means the disk thread will have precendence over all other threads in the OSD. Note: Only works with the Linux Kernel CFQ scheduler. Since Jewel scrubbing is no longer carried out by the disk iothread, see osd priority options instead.
Type: String
Default: the empty string
osd disk thread ioprio priority
Description: Warning: it will only be used if both osd disk thread ioprio class and osd disk thread ioprio priority are set to a non default value. It sets the ioprio_set(2) I/O scheduling priority of the disk thread ranging from 0 (highest) to 7 (lowest). If all OSDs on a given host were in class idle and compete for I/O (i.e. due to controller congestion), it can be used to lower the disk thread priority of one OSD to 7 so that another OSD with priority 0 can have priority. Note: Only works with the Linux Kernel CFQ scheduler.
Type: Integer in the range of 0 to 7 or -1 if not to be used.
Default: -1
o_serega
20.03.2017 23:37Если в кластере пару петабайт данных, сколько будет идти миграция? Это к рекомендации обновлять ceph переносом данных в новый кластер.
SinTeZoiD
20.03.2017 23:38Ну так пару петабайт надо бить на пулы поменьше. Об этом и был разговор. Один пул на пару петабайт это путь в сторону боли.
o_serega
20.03.2017 23:39У вас пулы в пределах одно кластера? тогда никакой разницы — ибо из одного кластера надо, все равно, перегнать пару петабайт данных в другой, даже если они на разные пулы побиты

kataklysm
Вы конечно меня простите, но что вы хотели сказать/рассказать в статье? Честно, я лично не понял…
Все что здесь указано и перечислено, пережевано рассылкой и документаций еще пару лет назад, а часть еще и самим хабром.
SinTeZoiD
Здравствуйте.
Хотел объеденить в одном месте основные вопросы по приготовлению CEPH. Как показала практика не все готовы читать maillist, а вопросы возникающие в статье возникают довольно часто.
Если Вам есть что рассказать, то присоединяйтесь к нашей группе в телеграм по ссылке https://t.me/ceph_ru, будем рады.