

Рост интереса к разработкам в сфере искусственного интеллекта связан не только с увеличением производительности компьютеров, но и с рядом качественных прорывов в машинном обучении. И хотя все планомерно идет к тому, что успех более чем вероятен, и в возможности создания в обозримом будущем сильного ИИ уже мало кто сомневается, одной важной стороне этого процесса уделяется незаслуженно мало внимания.
К построению искусственного интеллекта есть два принципиально разных подхода, назовем их условно алгоритмический и с помощью самообучения. В первом случае надо вручную прописать все правила, по которым действует интеллект, а во втором нужно создать алгоритм, который сам обучится на некотором большом объеме данных, и выделит эти правила самостоятельно. Как мы уже знаем, алгоритмический путь потерпел катастрофическое фиаско. И это печально, потому что этот путь более «правильный». Хотя в нем есть свои недостатки, вроде взрывающихся роботов от логического парадокса (шутка. хотя нет, правда), но зато такой робот никогда не сделает того, на что он не запрограммирован.
Но важно даже не это, а то что это академическая задача. Разобраться, как работает сознание, интеллект, разум. Поражение в этой области это как пощечина нашему собственном интеллекту. Почему же ничего не получилось? В основном, это проблема комбинаторного взрыва. Разум нашего уровня оперирует слишком уж большим количеством понятий и их отношениями. В развитом языке порядка 500 тысяч слов, и еще наверно столько же, а может и больше, чувственных образов, которым пока не дали словесного определения. Итого, интеллект человеческого уровня должен оперировать не менее чем миллионом понятий и их взаимоотношениями. Пусть вас не смущает, что на практике людьми используется порядка 2000-30000 тысяч слов (2000 — это необходимый минимум для свободного общения в другой стране, см. Simplified English, а писатели вроде Шекспира, используют порядка 30 тысяч слов). Просто это обобщенные и наиболее часто используемые слова в тех рутинных вещах и ситуациях, которые мы называем жизнью. А на самом деле развитый мозг оперирует намного большим числом «внутренних» понятий, которые он при желании облекает в эти общие слова. Хотя и 30 тысяч это большое число. Представьте, что ваша собака могла бы различать 30 тысяч слов. Понимать, что обозначает каждое из этих слов и реагировать на каждое по-разному. Определенно, она была бы гораздо умнее. И даже наверняка с ней можно было бы поддерживать беседу.
«Алгоритмический» путь
Известен древний компьютерный эксперимент, когда попытались описать вручную созданными правилами взаимоотношение простых геометрических фигур в виртуальной сцене. «Шар круглый», «куб может сдвинуть другой куб», «шар может катиться», «пирамида может лежать на кубе», и так далее. Оказалось, что при числе объектов в сцене более пяти, вручную описать все их возможные физические взаимодействия очень сложно. А при числе более десяти, уже не представляется возможным. А нам нужно сделать такое ручное описание не менее, чем для миллиона понятий! Комбинаторный взрыв.
Именно он стал причиной провала экспертных систем. Разумеется, первым делом мы попытались найти общие правила, которые упростили бы количество требуемых описаний для понятий. Ведь очевидно, что ходить может только то, у чего есть ноги. Поэтому мы можем написать одно правило, описывающее ходьбу, для всех ходячих объектов. И все равно количество понятий, для которых надо вручную писать правила, а главное — количество их возможных взаимодействий друг с другом, невероятно велико. И по факту мы имеем, что мы не смогли это сделать. Даже с применением всех доступных тогда методов машинного обучения, которые позволяли в частично автоматическом режиме строить такие правила (см. например алгоритм построения деревьев решений, которые по сути и представляют собой логику работы робота с «алгоритмическим» искусственным интеллектом).
Еще один наглядный пример — провал автоматических алгоритмических переводчиков. Построить общие правила, полностью описывающие два разных языка, это по сути создать правила, по которым действует разум, который оперирует этими языками. Один человек может знать два языка, поэтому описать общую структуру двух языков (чтобы их можно было конвертировать один в другой), это не то же самое, что описать правила синтаксиса для одного отдельного языка. Создать правила одновременно для двух языков это значит описать их общую структуру, а значит и общую структуру того человека, который ими пользуется. Те, кто занимался созданием баз знаний для таких алгоритмических переводчиков, могут более подробно рассказать, с какими трудностями они столкнулись. Но в целом, трудности сводятся к комбинаторному взрыву, и к тому, что реально используемых в мышлении понятий больше, чем слов. Более того, буквально за год-два язык меняется, некоторые правила устаревают и перевод с их помощью будет восприниматься комично. Опять получится "-Как ты это делаешь? -Всегда правой!" ("-How do you? -All right!"). Последний случай такой попытки создать вручную базу знаний для автоматического переводчика, который приходит на память, это ABBYY Compreno. Прекрасное начинание, много труда, но похоже завершившееся как и предыдущие попытки.
Самообучение
А что касается подхода с самообучением, то с ним все просто. Нужен алгоритм и нужны данные для обучения. Со вторым до недавнего времен, как минимум, до развитого интернета с большим количеством контента, было туго. Но собрав всю свою волю и самообладание в кулак, необходимо признать, что и с алгоритмами машинного обучения ситуация, до сих пор, была так себе… Уже давно существовали библиотеки книг, содержащие достаточно материала, чтобы на их базе создать искусственный интелелект. Почему же мы опять облажались? В первый раз с ручным построением правил, а теперь и с машинным обучением по книгам. Если бы на это существовал простой ответ, то мы бы уже все сделали. Но, кажется, с последними достижениями в сфере слабого ИИ, разгадка и ответ на этот вопрос стали ближе.
Здесь совпали сразу несколько факторов:
1. Рост вычислительной мощности. В основном, параллельные вычисления на GPU, что дало возможность даже простым людям с легкостью повторять результаты самых последних научных работ (что ранее было недоступно, по крайней мере, если у вас не было личного суперкомпьютера). Да-да, вы правильно поняли. Для таких замечательных фреймворков, вроде связки TensorFlow + Keras, созданы копии самых современнейших архитектур нейросетей. Все, о чем вы слышали в новостях о нейросетях и их достижениях за последние несколько лет, вы можете повторить на домашнем компьютере. Буквально в течении нескольких минут, необходимых для скачивания этих библиотек. Конечно, гиганты вроде Google могут себе позволить запускать расчет на 1000 компьютерах с GPU с 12 Gb видеопамяти на борту в течении пары недель. Но и обычный настольный игровой компьютер тоже дает сейчас большой простор для маневра.
2. Увеличение данных для обучения. База картинок ImageNet содержит порядка 10 млн. фотографий, вручную маркированных на более чем 1000 категорий. Впечатляющий результат, учитывая что первые попытки распознавания образов предпринимались с базами в несколько сотен образцов.
3. Но, главное, появились новые эффективные методы обучения. Так как старыми алгоритмами мы до сих пор не можем добиться ничего вразумительного, даже от новых увеличенных объемов данных. И это говорит само за себя (хоть это и печально, повторюсь).
Если не получается найти выход, выходите через вход
Разумеется, возможны и разные комбинированные методы. Где-то используем самообучение, где-то вручную пишем правила. Именно так и происходит сейчас. Google Assistant, Siri, IBM Watson — все они используют для распознавания речи и картинок машинное обучение (как правило, нейросети), а для общей работы вручную написанные правила. Watson вообще, судя по всему, представляет собой жуткую смесь древних экспертных систем и современных узкоспециализированных модулей по распознаванию. Более того, такой подход сейчас кажется наиболее перспективным. Только с обратным порядком — не мы пишем правила для примитивных распознавалок, а надо создать ИИ нашего уровня, и дать ему доступ ко всей алгоритмической мощи современных компьютеров. И такие ранние попытки уже предпринимаются, например Нейронная машина Тьюринга, где пытаются научить нейросеть пользоваться жестким диском для хранения структурированных данных. С рядом ограничений, но суть именно такова.
Хочется верить, что мы все же осилим эту задачу, и с помощью машинных методов создадим ИИ автоматически, а потом с помощью этих же машинных методов упростим полученный набор правил до минимально возможного. И получим тот самый алгоритмический сильный ИИ. Это было бы здорово. Святой грааль робототехников. Да и в целом, нашего разума по изучению самого себя.
Так что именно изменилось? Откуда такой хайп по поводу ИИ в последнее время?
Нейронные сети
Не секрет, что после долгой зимы в сфере ИИ, наступившая весна обязана своим появлением современному развитию глубоких нейронных сетей. Дело в том, что существовавшие до этого нейросети были качественно ограничены только двумя слоями. После двух первых (а точнее, последних) слоев градиент, по которому происходит обучение методом обратного распространения ошибки, из-за математических особенностей быстро становится все меньше и меньше. Веса между нейронами остальных слоев перестают оказывать влияние на результат, и получается что фактически работают только два последних слоя нейросети, а остальные оказываются пустым балластом. Конечно, архитектур нейронных сетей еще в давние времена было придумано множество, с разными способами обучения, но так как они себя не оправдали (по крайней мере, пока), то далее будем вести речь только о самой успешной модели искусственной нейронной сети — перцептронах и их ближайших родственниках.
Решение по эффективному обучению многослойных нейросетей оказалось на удивление простым: что если взять один входной слой, добавить к нему только один промежуточный слой, а третьим слоем (выходным) сделать точную копию первого входного. И заставить нейронную сеть научиться на выходе делать копию первого (т. е. входного) слоя. Если во внутреннем слое количество нейронов будет меньше, чем во входном, то у нейронной сети не будет выбора, кроме каким-то образом сжать информацию. А это и есть извлечение неких общих признаков. Такая штука называется автоэнкодером и прекрасно обучается стандартным методом обратного распространения ошибки, так как представляет собой обычный однослойный перцептрон.

А что если теперь отбросить третий (выходной) слой, а средний слой использовать в качестве входного для следующего автоэнкодера?
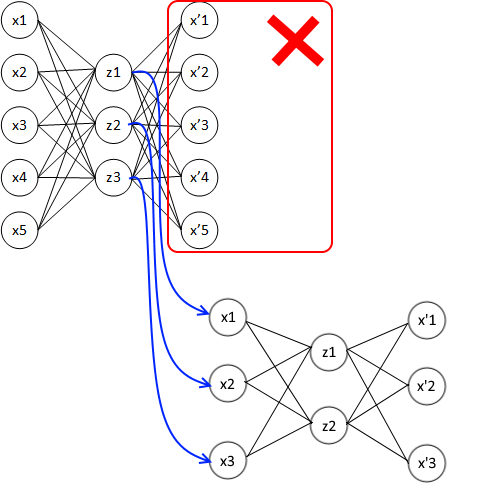
Таким образом можно собирать какое угодное количество слоев в общей суммарной нейросети. И каждый такой слой будет прекрасно обучаться!
Какой в этом физический смысл, помимо решения проблемы исчезающего градиента? Дело в том, что в первом слое (в первом автоэнкодере) будут выделяться какие-то простые признаки. Скажем, вертикальные и горизонтальные линии, если идет речь о распознавании изображений. Второй слой (второй автоэнкодер) на своем входе будет получать уже не исходные пиксели картинки, а только вертикальные и горизонтальные линии. И уже из этих линий выделять признаки более высокого абстрактного уровня: квадраты, круги, многоугольники. Третий слой получит на свой вход эти абстрактные простые фигуры и будет оперировать только ими, выделив из них, скажем, схематичную фигурку человека («палка, палка, огуречик — вот и вышел человечек!»). Все что нам не хватает для полного счастья, это на выходе из такой многослойной-многоэнкодерной сети добавить один-два слоя обычного перцептрона, чтобы классифицировать результат самого последнего автоэнкодера. Разбить человечков по классам или вывести в удобном виде (x,y) координаты фигуры на картинке.
Хорошая новость в том, что наш собственный мозг (по крайней мере, зрение) работает именно таким способом. На самых первых нейронах, связанных с сетчаткой глаза, распознаются только простые линии и градиенты яркости. Примерно такие:

Это результат работы первого слоя сверточной нейросети, о которых будет ниже
На следующем слое нейроны активируются как реакция на более сложные фигуры, на следующем на еще более сложные, и так далее. В какой-то момент, примерно на десятом слое и спустя примерно 100 мс от момента попадания фотонов на сетчатку глаза (обработка на каждом слое занимает 10-20 мс, поэтому наш мозг, упрощенно говоря, представляет собой десятислойную нейронную сеть), нарастающая сложность распознанных образов достигает такого уровня, что мы определяем, что перед нами стоит красивая девушка, и нервный импульс с выхода десятого слоя начинает бежать к мышцам лица, чтобы мы начали улыбаться. Крайне эффективное применение нейронной сети, выработанное эволюцией для продолжения рода.
Более того, все это подтверждено экспериментально на томографах и прямым подключением электродов к разным группам нейронов в мозгу. Тренироваться, согласно славной старой традиции (или не славной в данном случае, учитывая инвазивность метода) начали на кошках. Подробнее в замечательной статье про работу зрения и наиболее близкие к нему по принципу действия сверточные нейронные сети: Обзор топологий глубоких сверточных нейронных сетей.
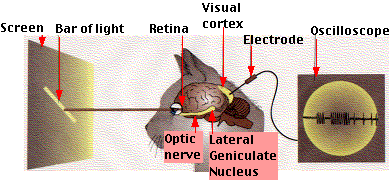
Описание эксперимента с кошкой. Электроды подключены к отдельным нейронам (точнее, к небольшим группам). Выяснилось, что некоторые нейроны реагируют на простые фигуры вроде линий, а другие на сложные фигуры, составленные из простых
Не смотря на свою простоту, идея такого послойного обучения нейросети получила практическую реализацию только в середине 2000-х годов (хотя и до этого пытались предобучать начальные слои в многослойном перцептроне методами без учителя, но не так успешно). Надо понимать, что такой метод обучения глубоких нейронных сетей (и даже не совсем такой, т.к. все начиналось с ограниченных машин Больцмана, но суть та же) это была первая ласточка, известившая о новой нейросетевой революции. С того момента прогресс ушел далеко вперед, сейчас автоэнкодеры и их аналоги в чистом виде практически не используются (их заменили новые методы регуляризации и слои вроде сверточных или реккурентных), а зоопарк архитектур нейросетей разросся до неприличных размеров. Краткую памятку о различных типах современных нейронных сетей можно наглядно посмотреть здесь: Зоопарк архитектур нейронных сетей. Часть 1 и Часть 2. Из двух частей. Краткую. Ага.
Оказалось, что в энкодере внутрениий слой можно делать не меньше, а больше входного. А чтобы сигнал не проходил насквозь без изменений (нам ведь нужно реализовать что-то вроде сжатия, чтобы вычленить признаки), давайте случайно отключать входные нейроны или подмешивать к ним случайные величины, эмулируя случайный шум. Это оказалось даже полезнее, чем чистый автоэнкодер, так как позволяет распознавать зашумленные данные. Вообще, идея случайным образом выключать часть нейронов во время обучения, т.н. dropout (иногда до 50% всей нейросети!) оказалась очень полезной. В некотором роде это приближение к биологическому образцу, так как в живом мозге активность нейронов тоже носит отчасти случайный характер. За подробностями отправлю к замечательной и крайне рекомендуемой к прочтению статье о современных типах нейронных сетей и как мы дошли до такой жизни Как обучается ИИ.
Строго говоря, обучать нейронную сеть вовсе необязательно методом обратного распространения ошибки. Существуют варианты вероятностного обучения, есть что-то вроде отжига, когда материал постепенно остывает, понижая свою температуру сходным образом с природным процессом (только в роли чисел-показаний температуры, у нас числа в весах между нейронами). Существуют эмуляции активации биологических нейронов, когда связь усиливается при частой активации, в том числе с эмуляцией тормозных нейронов. Есть даже обучение весов нейросети с помощью генетического алгоритма или методом муравьиной колонии. Ведь в конце концов нам надо всего лишь подобрать числа в весах нейронов, чтобы сигнал от входа максимально хорошо и правильно дошел до нужного выхода. А метод подбора этих чисел не так уж важен, лишь бы он выполнял свою функцию. Просто градиентный спуск методом обратного распространения ошибки один из самых быстрых, а с современными его модификациями вроде adam (сравнение современных способов обучения нейросетей: Методы оптимизации нейронных сетей), он почти не застревает в локальных экстремумах.
Чтобы не увеличивать размер и так непомерно раздувшейся статьи, краткое описание наиболее интересных и перспективных для сильного ИИ архитектур современных нейросетей убраны под спойлеры.
Сверточные нейронные сети
Отдельно стоит отметить сверточные нейронные сети. Вот стандартная картинка из википедии, служащая для иллюстрации ее принципа работы. Не знаю как вам, а мне она была долгое время непонятна, хотя написанием собственных реализаций нейронных сетей (не сверточных) и их ансаблей я занимался еще лет 20 назад, когда готовых библиотек для этого дела в интернете просто не было. Потом, как и многие в то время, столкнулся с типичными проблемами вроде исчезающего градиента и недостатка вычислительной мощности, и все забросил. Хорошо, что брошенное знамя подобрали другие.
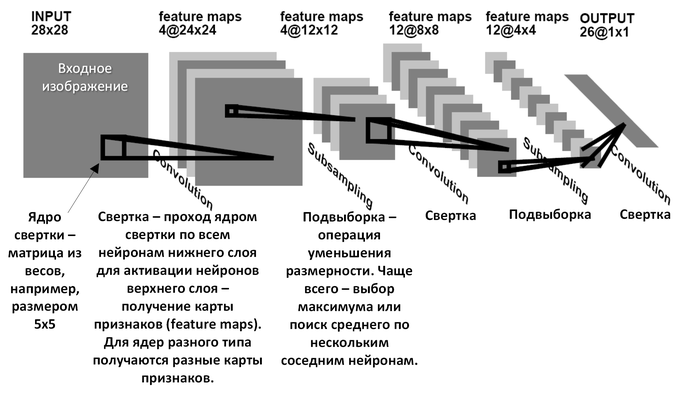
На самом деле сверточные сети работают так. Сначала мы решаем, сколько признаков хотим выделить из картинки. Это будет количество плоскостей (второй большой квадрат на картинке, обозначенный feature maps). Например, если мы хотим найти вертикальные линии, горизонтальные и диагональные, нам достаточно 4 плоскостей (т.к. диагональные могут быть двух видов: / и \). После этого решаем, какого размера должен быть фильтр, которым будем проходить по картинке. Это размер маленького черного квадратика, допустим, 3х3 пикселя. И заполняем его какими-нибудь числами, графически кодирующими примитив, который хотим найти. К пример, заполняем четверками по диагонали, чтобы искать наклонную линию \. А потом проходим им как скользящим окном по всей исходной картинке, и перемножаем пиксели на картинке на пиксели в нашем маленьком квадратике-фильтре, и суммируем результат. Получаем одно единственное число, характеризующее насколько картинка под скользящим окном похожа на картинку в фильтре. И записываем это число в плоскость, соответствующую этому фильтру. Картинка ниже лучше объясняет принцип.
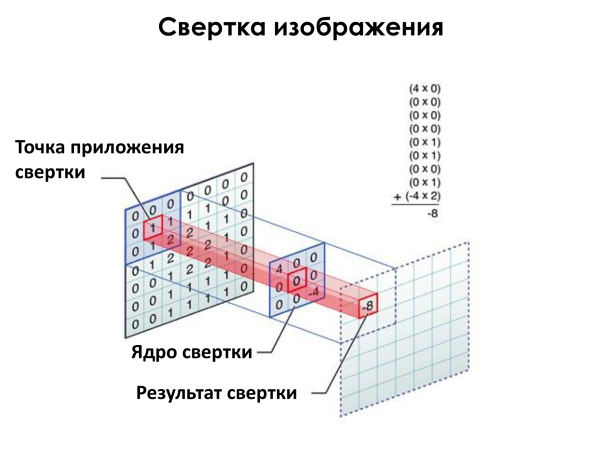
Иллюстрация с лекции Яндекса
Здесь маленький синий квадратик между плоскостями почти что кодирует диагональную линию \ из левого верхнего угла в правый нижний, если бы у него по диагонали были все четверки (к сожалению, иллюстрация нашлась только такая, с нулем в центре и -4 в нижнем правом углу). Область на исходной картинке немного похожа на такую диагональную линию, так как там есть 1 и 2, которые умножались бы на 4, соответствующие положениям этих 1 и 2. И общая степень похожести была бы 0*4+1*4+2*4=12 (вместо -8 на картинке). А вот если бы на исходной картинке по диагонали тоже были бы четверки, а еще лучше десятки! («летят n самолетов, нет, n мало, пусть будет k. и оба реактивные»). Тогда степень похожести была бы 10*4+10*4+10*4=120. Чем больше число, тем лучше.
На самом деле, мы не знаем какие именно графические примитивы мы хотим искать, а главное, какие из них окажутся важными для распознавания, например, морды лица кота на фото. Поэтому мы просто создадим заведомо избыточное количество плоскостей. Каждая из плоскостей составляет как бы карту, на которой отмечены места, где на картинке встречаются наиболее похожие на ее фильтр участки. Как на символ \ в примере выше. Как правило, в сверточных сетях в первом слое используется 100-200 плоскостей, чтобы перекрыть все возможные типы простых примитивов. Еще зависит от размера фильтра, чем он больше по размеру, тем большее разнообразие примитивов может вместить, и тем больше нам надо плоскостей-карт для них. И инициализируем веса принадлежащих им окошек-фильтров случайными числами. Нейросеть сама разберется, какие придать им значения в процессе обучения. Что удивительно, обученные на реальных фотографиях сверточные нейросети в первом слое создают именно такие же примитивы, вроде наклонных линий и пятен разной яркости (см. выше картинку), на которые реагируют нейроны первого слоя у живой кошки. И, надо полагать, у человека тоже.
Какие во всем этом плюсы?
Во-первых, уменьшается число нейронов по сравнению с полносвязным перцептроном, а это экономия памяти и ускорение расчета.
Во-вторых, выходные плоскости-карты признаков используются дальше как входные картинки для следующих сверточных слоев. Что позволяет строить глубокие многослойные сети, в которых каждый слой все так же прекрасно обучается. По сути, тот же принцип, что у автоэнкодеров выше, которые предвестили новый рывок нейросетей. Следующий слой работает уже не с пикселями исходной картинки, а с линиями как абстрактными объектами. И генерирует на выходе квадраты, круги, треугольники. Которые используются как входы для следующего слоя, который из этих фигур распознает фигуру человека.
В-третьих, сверточные сети позволяют определять не только факт наличия признака на картинке, но и его положение. В каком-то слое лицо человека будет распознано не просто по наличию где-то на фотографии глаз и рта, а по тому, что левый глаз расположен именно выше и левее, правый выше и правее, а рот ниже их обоих и по центру. Тут можно провести аналогию с каскадами Хаара, которые использовались раньше для распознавания лиц в методе Виолы-Джонса. Только сверточные нейронные сети могут распознавать не только графические примитивы вроде горизонтальных/вертикальных полос, но и такие сложные абстрактные понятия как «попугай». Если «попугай» расположен на правом плече абстрактного объекта «человек с деревянной ногой», то с большой вероятностью этот объект «пират». В этом сила сверточных (и других многослойных) нейронных сетей.
В-четвертых, сверточные нейронные сети в целом повторяют устройство нашего зрения (как сигналы от сетчатки проходят первичную обработку и попадают в мозг), поэтому работает схожим образом. И хотя повторяют те же ошибки в оптическом распознавании, что и мы, но и делают точно такие же эффективные акценты в тех местах на фото, где делаем мы.
Все это сделало сверточные сети такими эффективными в задачах распознавания.
Рекуррентные сети
Благодаря обнаруженному десять лет назад способу эффективно обучать многослойные сети, а также успехам сверточных сетей, другие типы нейронных сетей тоже получили мощный импульс для развития. Хочется отметить прежде всего рекуррентные нейросети, в частности LSTM и ее более позднего родственника GRU (хотя LSTM появилась даже раньше применения автоэнкодеров в глубоком обучении). По сути, любая рекуррентная нейросеть аналогична поставленным в ряд нескольким обычным, где каждой из них на вход подается вектор данных, соответствующий ее моменту времени. Так как время реакции человеческих нейронов порядка 10 мс, то обычно это число и используется для дискретизации входного потока. Будь то звук для распознавания речи, или видео, или еще какой процесс, который нам кажется непрерывным.
Использовать несколько обычных нейросетей, каждую для своего отдельного момента времени неудобно, так как длительность входного сигнала может быть разной, а зачастую сигнал вообще полностью непрерывный. То есть бесконечной длины. Поэтому в рекуррентные нейросети встроены запоминающие элементы, которые помнят что было в предыдущие моменты времени, и подмешивают тот старый сигнал к текущему. Здесь возникает сложный вопрос, что именно запоминать (критерии могут быть разными, например, по необычности сигнала. Или по частоте повторяемости), а также как быстро забывать старые моменты времени, чтобы этот подмешиваемый сигнал не вырос до бесконечности. В целом, этот вопрос пока до конца не решен, хотя существующие реализации рекуррентных нейросетей вроде LSTM и GRU показывают неплохие результаты. И, несомненно, за рекуррентными сетями большое будущее, так как большинство процессов в физическом мире требуют анализа в реальном времени.
Состязательные GAN сети
Другим крайне интересным типом нейросетей являются конкурирующие нейронные сети GAN. Принцип очень простой — пусть одна нейросеть инициируется на входе случайными числами и случайными весами и, соответственно, выдаст на выходе случайный результат. Например, массив цветов пикселей для картинки. А другой нейросети мы на вход подаем две картинки — одну сгенерированную первой нейросетью (сейчас она случайная), а вторую настоящую. Какую-нибудь фотографию природы, например. Так как мы знаем какая картинка настоящая, а какая сгенерирована первой нейросетью, то мы можем указать это второй. И научить ее, чтобы для фэйковой картинки она поставила число 0, а для настоящей 1.
Теперь изменим как-нибудь веса в первой генерирующей нейросети, чтобы она сгенерировала такую картинку, которую вторая нейронная сеть не сможет отличить от настоящей фотографии. Градиентным методом обратного распространения ошибки, или любым другим способом обучения. Но в это же время второй нейросети опять говорим, какая фотография настоящая, а какая фейковая (мы-то знаем это наверняка, так как контролируем процесс). И снова научим ее отличать настоящую от фейковой еще лучше, чем раньше. И будем так повторять снова и снова. Первая нейросеть все время будет учиться генерировать картинки, чтобы вторая не смогла их отличить от настоящих (пользуясь оценкой, которую дает вторая нейросеть ее творчеству, в пределах 0..1, и стремясь, чтобы та дала ей 1, т.е. не отличила от настоящей). Но вторая нейросеть тоже будет постоянно учиться отличать все лучше и лучше фейковые картинки от настоящих. С помощью нашей читерской подсказки, какая из них какой является на самом деле.
Такой подход дает впечатляющие результаты по «творчеству» нейросетей. Это так же используется, чтобы генерировать похожие на настоящие наборы данных, если настоящих данных у нас по каким-то причинам мало. На этом видео можно посмотреть, как GAN учится генерировать кошачьи морды, похожие на настоящие: https://www.youtube.com/watch?v=JRBscukr7ew.

Или человеческие лица

Да, кривовато, но это были первые успешные опыта такого рода, сейчас уже есть примеры получше. И надо учитывать еще тот факт, что мы, люди, слишком хорошо распознаем несовершенства на человеческих лицах. В этом была эволюционная необходимость, чтобы распознавать болезни. Кто плохо умел распознавать болезненные лица, тот оставлял меньше потомства, поэтому их конкурентов в процентном отношении оказывались больше. Со времененем конкуренты окончательно подавили их количественно, поэтому к нашим дням остались потомки только тех, кто хорошо распознавал лица. Вы прослушали краткий курс как работает естественный отбор, все встают, аплодисменты, расходимся.
А вот спальни генерируются куда как лучше (вероятно потому, что мы хуже распознаем несовершенные детали на них):

Но самая потрясающая часть нейросетей типа GAN, это способность манипулировать тем, что будет нарисовано. Так как генерирующую нейросеть мы инициировали случайным набором чисел на входе, то она построила картинку, соответствующую этому набору. Сделала классификацию наоборот, так сказать. Поэтому мы можем взять два входных вектора от разных сгенерированных картинок и манипулировать ими как обычными числами: складывать, вычитать, умножать.
К примеру, один случайный набор чисел (входной вектор) сгенерировал мужчину в очках. А другой случайный набор дает мужчину без очков. И третий дает женщину. Мы можем из первого вектора вычесть второй и в разнице получим те числа, которые определяют очки. А потом сложить с третьим набором, который определяет, что будет нарисована женщина. И подадим результат как вектор чисел на вход генерирующей нейросети. И она, тарам-папам!, сгенерирует женщину в очках!

Аналогично можно работать с любыми признаками, которые мы видим на сгенерированных картинках. Но сначала надо нагенерировать множество фото на случайных векторах, конечно. К примеру, таким способом можно состарить или омолодить человека на фото, если у нас где-нибудь найдется сгенерированная фотография пожилого/молодого человека. Качество следующей иллюстрации показывает, насколько быстро идет прогресс в этой области.
Иллюстрация из работы https://arxiv.org/abs/1702.01983v1
Еще один пример применения GAN: Нейросеть предсказывает 1 секунду будущего по фотографии.
В этой работе на вход нейросети подается кадр из видео с разрешением 64х64 пикселя, а нейросеть пытается предсказать, что произойдет в следующих 32 кадрах (через 1 сек). Согласитесь, это уже похоже на сильный ИИ, ведь многие абстрактные вещи на самом деле являются предсказанием. Например, начинаем убирать со стола одну из трех палочек. Допустим, нейросеть делает предсказание: через 1 секунду останется две палочки. А ведь это процесс вычитания, примерно так дети и учатся арифметике.
Технически предсказание заключается в том, что нейросеть выдает ряд измененных картинок, то есть генерирует эти картинки. Поэтому обучение сделано через GAN подход: одна сеть пытается генерировать реалистичные картинки, а другая пытается их отличить от настоящих. Только из-за недостатка вычислительной мощности разрешение 64х64 пикселя и анализ единственного кадра это слишком мало. Представьте что будет, когда нейросети смогут анализировать картинку хотя бы 640х480, и не один кадр, а хотя бы последние несколько секунд? Если при этом будут выдавать реалистичные предсказания, то это будет большой шаг в сторону ИИ.
К сожалению, GAN нейросети очень сложно обучать. Так как обе нейросети, и генерирующая, и оценивающая, должны развиваться примерно на равном уровне. Если генерирующая научится обманывать оценивающую раньше, что та никогда не сможет отличить ее творчество от настоящих фотографий, то процесс обучения потеряет смысл, застопорится. Аналогично, генерирующая никогда не сможет научиться делать реалистичные картинки, если оценивающая всегда будет ставить ей 0, т.е. что распознала фейковость. А значит не будет никакого градиента, по которому можно обучаться. Псеводослучайные алгоритмы обучения, вроде метода Монте-Карло, и даже их разновидности с накоплением положительных изменений, такие как генетический алгоритм, работают слишком медленно для практического применения.
Подробнее про генеративные нейронные сети (к которым относится GAN) можно почитать тут: Generative Models.
Обучение с подкреплением
Еще одна быстро развивающаяся область, это обучение с подкреплением. Суть ее сводится к тому, что нейронная сеть обучается по параметру, который оценивает ее работу не прямо сейчас, а через некоторое время. Скажем, нужно выиграть в компьютерную игру, набрав максимум очков. Но очки даются не в тот момент, когда нейросеть нажимает на клавишу движения или поворота, а через некоторое время. Это может быть, например, какой-то бонус на уровне, до которого еще нужно добраться.
Обучение с подкреплением чем-то похоже на то, как учатся живые люди. Поэтому это тоже очень перспективное направление, хотя и находящееся пока на самом начальном уровне. К сожалению, математический аппарат построения функции полезности действий (штука, которая управляет текущими действиями нейросети, чтобы получить награду в будущем) довольно сложно объяснить на пальцах, поэтому заинтересовавшимся лучше поискать материал самостоятельно.
Во всем этом главное понять
По сути, известная теорема о том, что однослойный перцептрон может аппроксимировать любую функцию, означает всего лишь, что мы можем использовать нейронную сеть как справочную таблицу. Действительно, если каждый входной нейрон соединен с каждым нейроном среднего скрытого слоя, то мы можем для нужных весов поставить 1, а для всех остальных 0. И по этой связи со значением 1, сигнал напрямую пойдет к выходу, как ссылка в таблице. Однако размер этой таблицы (число нейронов в скрытом слое) должно быть, если не ошибаюсь, 2^n от числа понятий-записей в таблице.
Но заметьте, эта теорема означает только то, что мы можем обучить однослойную нейронную сеть на обучающей выборке и использовать ее как справочную таблицу. Но это вовсе не значит, что на новых данных она будет так же хорошо работать! Если новых данных нет в нашей супер-таблице, то все пропало, шеф. Поэтому многослойные сети работают несколько хитрее в плане интерполяции и смешивания сигнала, чем однослойные.
Поэтому те же сверточные нейросети, помимо того что имеют сходство со зрительной системой человека, на самом деле тоже служат в том числе для уменьшения количества нейронов в сети по сравнению с ближайшими аналогами. Впрочем, в обоих случаях может лежать одинаковый принцип уменьшения числа необходимых для работы нейронов. Известно, что наши глаза по количеству воспринимающих свет колбочек и палочек соответствуют картинке примерно в 120 мегапикселей (для каждого глаза), но нервный канал, соединяющий глаз с мозгом, физически не способен провести такое количество информации через себя. Количество нервных волокон в зрительном нерве составляет примерно 1.2 млн, что соответствует картинке чуть более одного мегапикселя для каждого глаза. То есть уже в нервных клетках, непосредственно связанных с глазами, еще до обработки сигнала мозгом, происходит сжатие видеоряда в 100 раз.
С этим, кстати, связаны различные глюки нашего зрительного восприятия. Зрительные иллюзии, вот это все. Более того, аналогичные иллюзии возникают и в других областях нашего мышления, в психологии, в инстинктах, в речи (Вики: Иллюзия). Везде, где происходит аналогичное по принципу сжатие сигнала с помощью нейронов. То есть везде.

Просто лист бумаги, сложенный определенным образом
Благодаря тому, что глубокие многослойные нейросети позволяют меньшим числом нейронов достичь большей сложности, и получены все вдохновляющие результаты последних лет. Глубокие нейронные сети уже сейчас в отдельных областях превзошли человека: в распознавании дорожных знаков, определении классов при большом числе категорий (ResNet, ошибка определения одной из тысячи категории для 10 млн картинок 3.57%, а у человека среднее 5%, но не качественно, увы, и к этому мы позже вернемся. Внезапный диван леопардовой расцветки), в распознавании речи, чтении по губам. И очевидно, что в ближайшие годы мы услышим еще о многих подобных примерах.
Вступление закончено, пора вносить торт
Итак, мы научились правильно обучать многослойные нейронные сети. А также знаем, что наш собственный мозг представляет собой примерно десятислойную нейронную сеть (для первичного распознавания объектов высшего уровня абстракции, а далее непрерывно работает как рекуррентная сеть). И, технически, мы теперь можем сделать некий аналог человеческого мозга. Так почему сильный ИИ до сих пор не создан, что пошло не так?
Для начала необходимо заметить, что научного определения для сознания, разума и интеллекта в интересующем нас контексте не существует. Это философские понятия. Слово есть, а
Можно посмотреть на это иначе — если бы определение искусственного интеллекта существовало, то он был бы уже создан. Определение чего либо (если оно не философское и не иное ненаучное) можно рассматривать как прямое ТЗ для программиста.
Единственная форма разумной жизни, которая нам известна — это мы сами. Поэтому то интуитивное понимание интеллекта (разума, сознания), которое есть у нас всех, и которое так глупо и безуспешно философы пытаются облечь в слова, на самом деле, простая степень похожести на нас самих. Что-то вроде расширенного теста Тьюринга. Если мы будем слышать рассказ о том, как некто что-то делает в некоторых ситуациях, как он поступает и какие решения принимает, и не сможем отличить его от человека (при достаточном количестве информации, позволяющей делать обоснованные выводы), то это и будет критерием разумен он или нет. Даже если в реальности это окажется двуногий робот-гуманоид или написанная чат-программа. Других способов определить интеллект пока не существует. И даже этот метод несовершенен, так как нет критерия когда объем информации станет достаточным для выводов.
Кратко это можно описать так: от искусственного интеллекта мы ожидаем то же, что от разумного нормального человека. В разговоре, в действиях, в его решениях. Только с поправкой на отсутствие полового влечения, например. Или имеющего расширенную память, включающую весь интернет и мгновенный доступ к ней. Или имеющий быстродействие (скорость мышления) в тысячи раз быстрее биологического образца. Но это остается «все тот же человек».
Поэтому задача создания искусственного интеллекта сводится к тому, чтобы он был максимально похож на нас. Другие возможные формы искусственного интеллекта, например, действующие по каким-то другим, отличным от наших, правилам, являются очень интересной темой для рассуждений. Но, к сожалению, на данный момент такие рассуждения возможны только как философские. То есть не имеющие адекватного научного определения под собой.
Как же нам добиться создания сильного ИИ хотя бы нашего уровня? Да в принципе, ничего особо делать не надо. Так как в некоторых когнитивных областях, которые компьютеру ранее казались в принципе недоступными, вроде качественного распознавания речи и образов, нейронные сети сравнялись и обошли человека. Поэтому есть обоснованная надежда, что из таких простых строительных блоков со временем возникнет что-то более сложное. Грубо говоря, выход с ResNet надо отправить на другую не менее сложную нейросеть (которая еще не создана), результат ее работы отправить на модуль генерации неотличимого от человеческого голоса, и так далее. Вполне возможно, что из этого и правда вырастет сильный ИИ. Это кажется тем более реальным, как только представишь, что нейронная сеть научится хорошо восстанавливать 3d сцену по обычному видео с youtube. И по роликам научится понимать куда и как люди движутся, что делают и т.д… Почему именно по видео это может дать результат, а по книгам (описывающим в текстовом виде все те же действия) не дало? Об этом ниже.
И такие попытки уже делаются! Нейронные сети уже довольно неплохо определяют нормали по фото и поле глубины, а от этого один шаг до полноценной реконструкции 3d сцены.
Иллюстрация с лекции Нейронные сети: практическое применение
Тут еще нужно заметить, что вычислительная мощность для применений в нейронных сетях все еще смехотворно мала. Например, у обычной мухи дрозофилы порядка 150 тысяч нейронов. А когда мы перевалили за первую тысячу нейронов в искусственных нейросетях? Совсем недавно. Правда, наши сети намного эффективнее для узких задач. Даже самые мощные суперкомпьютеры по производительности вычислений на ватт энергии, пока примерно равны мозгу мыши. Есть надежда, что в ближайшие 10-20 лет будет создан компьютер, обладающий такими же параллельными вычислительными возможностями, как человеческий мозг, и потребляющий всего 10 кВт. И это лучшее, на что можно надеяться. По сравнению с 20 Вт у человеческого мозга. Шутка. Надеяться всегда можно на лучшее. Представляется что-то вроде SD карты на сотни гигабайт, в которой ячейки смогут параллельно производить простые математические операции (сумматора будет вполне достаточно). С учетом частоты в гигагерцы (и, в перспективе, в терагерцы) по сравнению с 100 Гц биологического нейрона, это моментально превысит вычислительные возможности нашего мозга.
Недостаток текущей вычислительной мощности для нейросетевого применения тем более удручает, что существует масса других более формальных методов машинного обучения, выполняющих ту же задачу, что и нейронные сети (например, для задач классификации метод опорных векторов или случайный лес деревьев решений), но менее требовательных к ресурсам. К сожалению, в тех задачах, где сейчас сильны нейросети, они им сильно уступают. Правда, здесь можно сослаться на интересную статью, в которой показывается, что большую роль играют данные для обучения и знания о том, какие результаты можно получить с такой-то архитектурой, а также вера исследователя в успех. Грубо говоря, еще 20 лет назад можно было достичь тех же результатов, что и сейчас. Набери тогда исследователи достаточную обучающую выборку и запусти расчет на большее время (пропорционально росту производительности компьютеров с тех пор). Но для этого они должны были знать, что могут получить, и верить в свой успех. Так или иначе, а история не знает сослагательных наклонений.
Но вполне возможно, что успехи нейронных сетей вызваны просто общим интересом к ним, а значит и количеством задействованных ресурсов. Но не будем обманывать себя и питать ложные надежды =). У нейронные сетей, как метода машинного обучения, действительно есть свои интересные особенности, доказательством чему служит вал научных работ последних лет. В основном, посвященных многослойности и вытекающих из этого следствий. Так что, похоже, нейросети с нами всерьез и надолго.
Другая проблема в данных для обучения. На самом деле, их нет. ImageNet с 10 млн маркированных картинок это большой успех, но возьмите любую задачу, к которой вы могли бы применить самые новейшие нейронные сети, и окажется, что данных для обучения нет. Это прекрасная возможность и стимул разрабатывать методы обучения нейросетей, не требующих больших объемов обучающей выборки. В идеале, они должны работать даже на единичных примерах. Как наш мозг.
Ну когда же конец
И все же, почему сильный ИИ до сих пор не создан? И даже нет намеков, а вернее, четко обозначенных путей, по которым к нему можно прийти в ближайшее время?
И здесь наступает грустный момент нашей повести. В точности с концепцией героя с тысячью лицами, после начальных вдохновляющих успехов, главный герой попадает в сюжетную яму. Из которой он потом будет долго и мучительно выбираться.
Дело в том, что многие качества разумного мышления, которые мы считаем само собой разумеющимися, на самом деле не являются таковыми. Не хочется показаться голословным, а тем более исказить детали и выступить в роли испорченного телефона, но то, о чем дальше пойдет речь, является компиляцией из разных источников (научные статьи, новости, телевизионные документальные фильмы и т.д.), поэтому быстрое гугление первоисточников не принесло особого результата. Если кто-то поделится ссылками на что-нибудь из перечисленного ниже или похожего, буду благодарен.
Известны примеры, когда в сохранившихся первобытных племенах имеются радикальные отличия в мышлении. Где-то катастрофически малое количество слов в языке. Где-то имеются один-два названия для синего цвета, но зато десятки для оттенков зеленого. Где-то было видео (за указание на первоисточник спасибо tin04ka в комментарии: документальный фильм BBC Horizon:Do You See What I See, есть на youtube), кадр из которого показан ниже. На нем туземец не может отличить синий квадратик от зеленых. При этом он здоров и не дальтоник, просто такова особенность их языка (отсутствие слов для синих цветов) и связанного с этим обучения в детстве. Можете себе представить, что на этой картинке вы не сможете отличить синий квадрат от зеленых?

Представитель народа Химби из Намибии, если интернет не врет
Также недавно была новость, что в каком-то племени туземцы не могут считать до чисел больше четырех. У них есть понятия, грубо говоря, «один», «два» и «много». Других нет. И если положить перед таким туземцем кучки из 4 и 5 палочек, он не видит между ними разницы. Так же, как мы не видим разницы между кучками из 1000 и 1001 палочек. И там, и там примерно одинаковые кучки из «много».
Другой известный пример, уже наших исследователей середины прошлого века (за ссылку на источник спасибо GreatNonentity). Которые изучали особенности мышления изолированных народов, заставших начало коллективизации и поэтому подвергшихся в короткий срок значительным изменениям в образовании. Среди испытуемых были как неграмотные люди, никогда не посещавшие школу, так и имевшие образование разных степеней (от кратких курсов, до нескольких классов). Выяснилось, что у получавших традиционное школьное образование и не получавших, имеются существенные отличия в способах логического мышления. Например, исследователь задавал такой детский вопрос-загадку: «Белые медведи живут там, где снег. На севере снег. Какого цвета там медведи?» Не имевшие школьного образования не могли провести такие логические параллели. Все их ответы сводились к вариантам вроде: «Если кто-то поедет на север и посмотрит, то он сможет сказать какого цвета там медведи, а иначе никаких способов узнать это нет». Добиться другого от них не удалось. А имевшие классическое образование без труда справлялись с такими вопросами, так как рассуждали уже другими категориями, полученными в процессе обучения. Эти исследования сильно пошатнули царившие в то время представления о разуме, так как подобные построения, которые с легкостью разгадывают наши дети, до этого считались само собой разумеющимся свойством разума.
А сколько еще может вскрыться подобных нюансов об интеллекте, которые мы не видим, так как не знаем другой разумной жизни, кроме самих себя?
Похоже, что значительная часть того, что мы считаем разумом и интеллектом, на самом деле является результатом обучения в раннем детстве. В пользу этой теории говорят случаи обнаружения детей-маугли, выросших в лесу без общения с людьми. Большинство из которых, не смотря на развитый и физиологически идентичный нашему мозг (т.к. это современные люди, просто оказавшиеся в младенчестве в лесу), так и не сумели адаптироваться к жизни в обществе. Особенно много таких случаев почему-то в Индии, вероятно благодаря большой численности населения, нищете, и теплому климату. Некоторых не удалось научить не то что говорить, но и просто приучить пользоваться одеждой или столовой ложкой.
А значит надо обратить более пристальное внимание на то, как обучаются младенцы. И мы увидим, что они познают мир через физическое взаимодействие с ним. Потрогать, покрутить предметы в руках, и тому подобное. Даже обычный осмотр помещения, это в некотором роде анализ трехмерной обстановки, благодаря встроенному и сразу работающему бинокулярному зрению.
Более того, практически все наши знания, в том числе такая абстрактная наука как математика (являющаяся царицей наук, как известно), на самом деле сильно привязана к трехмерному представлению. Ведь как ребенок научился считать? Перед ним на столе лежали две палочки. А потом мама (или учитель) добавил к ним еще одну. И ребенок научился складывать числа.
Если хорошо подумать, то почти все наши внутренние понятия, так или иначе привязаны к окружающему трехмерному (объемному) миру. Какие-то самые сложные концепции из высшей математики конечно визуально представить нельзя или очень сложно, но зато вы видите значки, которые их обозначают. Вы знаете, что эти значки нарисованы на бумаге учебника, который можно взять в руки. Со всеми следствиями, которые их этого вытекают в физическом мире. Например, что этот учебник можно положить на полку. Или бросить об стену. Знакомое желание для многих студентов на уроках математического анализа, не так ли? Впрочем, один профессор на вопросы студентов, где это им пригодится в жизни, всегда отвечал: «Смотря что вы считаете жизнью». Ну а более простые вещи из математики легко представляются в уме, теорема Пифагора и тому подобное. Некоторые даже могут сделать это для четырехмерного куба.
И, что важнее всего, такой подход через обучение в привязке к трехмерной форме объектов устранит главную проблему сегодняшних нейросетей — непонимание контекста. Нейронная сеть, обученная воспринимать 3d мир и распознавать картинки не просто разбив их на классы, а в привязке к трехмерной форме распознаваемых объектов, никогда не спутает леопарда с диваном с леопардовой расцветкой. Потому что мы сами их отличаем именно по 3d форме, которую реконструируем из изображения. Диван имеет форму дивана, а леопард форму леопарда, какими бы цветами они ни были раскрашены. Другое дело, что сверточная нейросеть тоже могла бы отличать диван от леопарда по форме (см. выше принцип действия сверточных нейросетей). И она технически может это сделать, дайте ей для обучения 10 млн леопардов и 10 млн диванов. Ну а так ей оказалось проще ориентироваться только на пятна. Потому что распознаваемые классы не привязаны к 3d форме объектов. И это кажется ключевым моментом.
Да-да, я все понял, развяжите меня пожалуйста
Таким образом, похоже что наиболее реалистичный путь создать сильный ИИ — это дать ему возможность пройти путь младенца. Возможность манипулировать и изучать трехмерные объемные тела. Конечно, никто не будет в течении
Но если серьезно, есть отличная возможность провести такое же обучение, но быстрее, и не в ущерб нервным клеткам
Но тут возникает проблема. Человек — это существо с тонко преднастроенной нейронной сетью. Вот пример. Создали мы младенца в виртуальной реальности. И добавили ему таймер, чтобы по истечении некоторого времени он становился голодным. А что делает младенец, когда он голоден? Правильно, он кричит. Хорошо, нет проблем. Пусть над головой младенца в симуляторе появляются буквы «Аааа», обозначающие крик, как в компьютерной игре. Но сколько времени их держать над головой, как часто их показывать, и когда вообще прекратить плакать? У настоящего ребенка есть тонкая преднастройка. Он покричит и устанет. Да и сам крик не постоянный, а с перерывами. И таких нюансов очень много. Именно поэтому жестко прописанные боты в играх для нас выглядят явно неразумными, хотя по формальным признакам их зачастую можно отнести к разумным существам. Мол, собирают информацию, используют ее для достижения своих целей и так далее. Но об определении интеллекта, а точнее, об отсутствии такого определения, мы уже говорили выше. А по факту, боты в игре нам кажутся неразумными, потому что они не очень похожи на нас. А конкретно — на нашу преднастройку в нейронной сети мозга. Компьютерный персонаж непрерывно бьется об стену при сбое алгоритма навигации? Неразумный. А вот человек ударился бы пару раз (например, натолкнувшись в темноте на стену, что как бы аналог сбоя системы навигации у бота), и прекратил бы. Человек — разумный. Улавливаете разницу, да? Похоже, что разумность (т.е. похожесть в поведении на нас) во многом определяется преднастройкой нейронной сети. Хотя в обоих случаях в основе их действий — стуканий об стену, лежат примерно одинаковые ошибки расчеты поиска пути.
Конечно, это сильно упрощенный пример, потому что у человека в расчете пути принимает участие на много порядков больше понятий, чем у компьютерного бота. Человек понимает, что перед ним трехмерная стена и биться об нее головой больше двух раз (ну хорошо, уговорили, трех) нет смысла. Что опять же возвращает нас к необходимости обучать нейронную сеть ИИ в трехмерном окружении, имитирующем реальный физический мир.
Как же нам дать ИИ боту преднастройку, похожую на нашу? Можно попробовать алгоритмически описать основные инстинкты и физиологию человека. Но скорее всего мы опять столкнемся с комбинаторным взрывом, как это было при попытке вручную написать все правила для ИИ. Можно попробовать взять знания об устройстве организма на молекулярном уровне из медицины. Хотя сама медицина нуждается в сильном ИИ, который систематизировал в ней все накопленные знания.
Остается еще вариант самообучения по видеороликам. И вот тут очень пригодятся все эти достижения нейронных сетей последних лет по распознаванию изображений и звука. Преобразовать реальный мир в 3d сцену можно было уже давно, от стереокамер и аналогов камер глубины вроде kinect, и заканчивая анализом монопотока вроде LSD-SLAM (еще на первых марсоходах, кстати, использовались SLAM алгоритмы). Но для обработки имеющегося в интернете видео контента нужны нейронные сети. И тем более, для анализа что на видео происходит. А судя по последним нейросетевым достижениям, появляется робкая надежда, что это будет им по плечу. Отсюда и оптимизм в плане шансов на создание сильного ИИ в обозримом будущем.
Но неизвестно, к чему такое обучение по видероликам приведет. Делать похожее поведение может и получится. Но такой ИИ перенимет все наши слабые стороны. Потому что здравомыслящий человек имеет жесткую предустановку: «Что бы в жизни ни случилось, главное не попасть на youtube!». А иметь ИИ, обученный вести себя по роликами с ютюба, мы точно не захотим.

Нельзя сказать, что это уникальная идея. Давно уже существуют попытки реалистичного моделирования движений человека путем моделирования в виртуальном симуляторе. Начиналось все попытками создать естественную походку методами машинного обучения (генетическими алгоритмами и другими). Можно прямо сейчас на OpenAI посоревноваться в обучении виртуального человечка пробежать как можно дальше без падения.

Пока это робкие и смешные попытки, но несложно представить, что через несколько лет это перерастет в полноценный симулятор физического окружения.
А потом виртуальному младенцу добавят игрушек для игры. Потом положат перед ним две палочки, а потом добавят еще одну. И он научится считать.
Зачем козе баян
А стоит ли вообще все это таких усилий? Мы уже убедились, что вряд ли сможем создать ИИ с отличным от нашего способа мышления, со всеми его недостатками вроде иллюзий разного рода. Собственно, как уже говорилось выше, сама идея «чистого» абстрактного ИИ, хоть и очень заманчива, но весьма спекулятивна. Подтверждением тому служит хотя бы то, что попытки сделать сильный ИИ на базе книг провалились. На базе текстовых данных всего интернета — тоже (см. IBM Watson, хоторый хоть и содержит на своих дисках «весь интернет», на деле не умнее анкеты с поисковой строкой). Остался неисследованным вопрос создания ИИ на базе физического окружения, будь то в виртуальном симуляторе или в реальности. Но этот способ, скорее всего, в лучшем случае приведет к ИИ на уровне человеческого.
А нужен ли нам ИИ уровня человека? Не, не нужен. Но как уже отмечалось, имея искусственную форму разума, можно дать ей большие возможности, чем имеем мы сами в силу ограничений физиологии. Для примера, сейчас в интернете выложено более 100 млн научных работ. Из них около 30 млн по медицине. Ни одному живому человеку не под силу прочитать такой объем. А тем более, охватить все междисциплинарные знания. Даже узкие специалисты, уверен, не все работы из своей области отслеживают. А ведь в таком объеме информации наверяка скрыто множество взаимосвязей, из которых можно было бы сделать полезные выводы. Традиционные методы машинного обучения фактически потерпели фиско на этом поприще. Теперь вся надежда на сильный ИИ, который сможет освоить все эти накопленные знания человечества. Если говорим об ИИ на базе нейросети, который будет примерно равен по интеллекту человеку, то для этого он потенциально может пользоваться расширенной по сравнению с людьми памятью и более высокой тактовой частотой.
Впрочем, локомотив прогресса так и так не остановить, это лишь вопрос времени.

Об ошибках, как орфографических, так и фактических, просьба сообщать в личку или в комментариях.
Комментарии (189)

Fen1kz
04.04.2017 17:52+10С некоторых пор наблюдаю хайповые статьи наподобии этой. Каждый стремится вылить тонну воды про ИИ. Однако, есть ещё такая же тема — это блокчейн. Там так же постоянно пространно размышляют ни о чем.
Поэтому, предлагаю авторам объединить темы и писать статьи вида "Сильный ИИ в блокчейне" или "Блокчейн из ИИ", итд. И вам выгода — охватываете сразу 2 темы, и нам — будете занимать в два раза меньше места.
maslyaev
04.04.2017 18:21+4Сильный ИИ в блокчейне на основе квантовой криптографии.

0xd34df00d
05.04.2017 04:24+1И картинка с расширяющейся Вселенной. Спросите Итана.
maslyaev
05.04.2017 10:56Предсказание ответа Итана на вопрос о расширении чёрных дыр при расширении Вселенной с помощью сильного ИИ в блокчейне на основе квантовой криптографии.
immaculate
05.04.2017 08:11Квантовая криптография — это хайп прошлого десятилетия. Правильно говорить: «Сильный ИИ в блокчейне на основе Node.js для встраивания в автономный автомобиль».
maslyaev
05.04.2017 11:02Что-нибудь ещё про автоматический деплоймент 500 сервисов на 100 виртуальных серверах в облаке.

StormEagle
04.04.2017 19:14+2Сожалению, что сложилось такое впечатление. Суть всей статьи сводится к тому, что будет крайне интересно, когда существующие способности нейросетей к распознаванию образов, приложат к распознаванию трехмерной формы объектов на видео/фото.
И обучение будет сводиться к предсказанию, что дальше произойдет на видео. Куда побежит этот человек? А сколько останется палочек на столе, если убрать одну? Это сильно смахивает на сильный ИИ (по крайней мере, человеческого уровня).
До глубоких нейросетей такого инструмента просто не было. Сейчас он появился.
zirix
04.04.2017 19:32-1Сильный/человеческий интеллект это в первую очередь мышление и самосознание.
Возможность предсказывать и распознавать является следствием работы интеллекта, а не его главной функцией.
red75prim
05.04.2017 00:59Сильный/человеческий интеллект это в первую очередь мышление и самосознание.
Это один из вариантов определения интеллекта. Не самый полезный. Еще есть, например, такой: "Идеальный интеллектуальный агент — система, способная находить и выполнять оптимальные последовательности действий, ведущие к выполнению поставленной задачи".
Оптимальная последовательность действий — последовательность максимизирующая заданную метрику (время выполнения, вероятность достижения результата и т.п.).

saboteur_kiev
04.04.2017 19:35Не понимаю, какое отношение нейросети имеют к сильному ИИ.
Нейросети это просто возможность для программистов писать алгоритм, не задавая ему кучу граничных условий, а скормить кучу данных и выбрать эти граничные условия самостоятельно.
В результате ваш «алгоритмический путь» и «путь с самообучением» — это спекуляция фразами, так как в обоих случаях есть конкретный, заранее заданный алгоритм, и вся разница только в том, каким образом были заданы граничные условия данных.
Вы же понимаете, что способность живого человека спроецировать опыт в одном направлении на СОВЕРШЕННО другой — не поможет нейронным сетям значительно изменить алгоритм и превратиться в сильный ИИ?
Например, если они научились распознавать котиков, то это не позволит им распознавать попугайчиков, потому что в АЛГОРИТМЕ это не предусмотрено.StormEagle
05.04.2017 01:38Не понимаю, какое отношение нейросети имеют к сильному ИИ.
Математическим аппаратом создания огромного числа перекрестных связей между данными, способностью создавать внутри себя абстрактные представления этих данных, строить интерполяции и аппроксимации. Все, как и у биологического прототипа.
Упрощенно говоря, сейчас есть два основных (если не единственных) способа проводить вычисления: как компьютер, последовательно считывая значения из памяти, проводя арифметические операции над ними и сохраняя обратно в память. Или как нейронная сеть, ослабляя/усиливая сигнал, и применяя к нему нелинейное преобразование. Оба варианта взаимозаменяемы, кстати. Компьютер может имитировать нейронную сеть (что очевидно), но нейронные сети тоже есть полные по тьюрингу, способные полностью имитировать компьютер.
Да, сейчас нейросети еще несовершенны и не похожи в целом на работу мозга. Но ведь мы имеем факт, что за 50 лет труда умнейших людей не удалось создать алгоритм разума. Не смотря на сотни теорий. А нейронные сети, как только появился механизм правильного обучения многослойных сетей, неожиданно показали результат лучше, чем удалось добиться за предыдущих 50 лет. От этого факта сложно отмахнуться.
Например, если они научились распознавать котиков, то это не позволит им распознавать попугайчиков, потому что в АЛГОРИТМЕ это не предусмотрено.
Не совсем так. Если нейросеть научилась распознавать белых и черных котиков и отличать их от собаки, то она наверняка отличит рыжего котика от собаки. Хотя до этого никогда рыжего котика не видела. Характерное свойство разума. И это не простая цифровая интерполяция, если что.
А вы как раз говорите об обычных алгоритмах. Если в нем вручную не предусмотреть возможность существования рыжих котиков, то он их не распознает.saboteur_kiev
05.04.2017 12:30«Да, сейчас нейросети еще несовершенны и не похожи в целом на работу мозга. Но ведь мы имеем факт, что за 50 лет труда умнейших людей не удалось создать алгоритм разума.»
Почему 50?
Попытки создать идут уже тысячи лет. Просто сейчас это делается в основном на базе электроники.
Fen1kz
05.04.2017 17:54Вот именно. "А вот было бы интересно, если бы да кабы". Никакой конкретики, никакого обучения читателей, одна вода да балабольство.
У вас рассуждения уровня домохозяйки: "А вот было бы круто если бы способности линукса в отказоустойчивости и конфигурироемости мне в посудомойку, чтобы не била посуду и домывало тем где не отмылось." Ну всмысле, если так круто — пойди, сделай и напиши об этом статью, зачем пустозвонить-то?

ideological
04.04.2017 23:01Тоже хотел написать похожий комментарий, тем более что недавно была статья закрывающая тему Термин «искусственный интеллект» потерял всякий смысл, но побоялся слить карму. Спасибо.
red75prim
05.04.2017 00:19Та статья закрывает тему ИИ примерно так же как наблюдение, что в рекламе усилителей используются "китайские ватты", закрывает тему повышения мощности усилителей.
tomzarubin
05.04.2017 00:59-1С некоторых пор появляются такие статьи на Хабре, а такие комментаторы как ты были всегда.
glioma
04.04.2017 18:12Не хочу чтобы меня считали ретроградом, так, просто после прочтения статьи вспомнил слова.
«Объясните мне, пожалуйста, зачем нужно
искусственно фабриковать Спиноз, когда любая баба может его родить когда
угодно. Ведь родила же в Холмогорах мадам Ломоносова этого своего
знаменитого.»
А если в тему. Человеческий интеллект получает информацию не только из внешнего мира через внешние сенсорные системы, но и не менее обширный объём информации из внутреннего мира своего организма, причём через ещё большее количество различного рода сенсоров. И вот уже в мозга из этого огромного объёма данных формируется сознание. Представьте, что вы видите красивую девушку, которая вам улыбается, сможете ли так же уверенно решать сложную математическую задачу, или у вас в организме запуститься сложный химико-электрический процесс, целью которого будет далеко не осознание математических терминов. Всё это к тому, что у интеллекта должен быть ещё и внутренний мир, его собственное осознание «себя», как отличие от реальности, осознание потребностей, внутренних «врождённых» целей. И тут есть два пути, либо этот внутренний мир мы создаём уже готовым, либо он так же создаётся сам в процессе обучения, в любом случае необходимы специальные выделенные структуры в составе машины, ответственные за внутреннее состояние. И кто будет уверен, что получаемый ИИ, получится таким, каким необходимо нам? Вполне вероятно, что у него возникнет не познаваемый нами совершенно внутренний мир машины. И не окажемся ли мы в итоге лишними на новом уровне реальности.StormEagle
04.04.2017 19:28Вы правы, но пока нет определения понятию «сознание». Что значит осознает себя, свои потребности? Мы не можем ответить на этот вопрос, поэтому не может запрограммировать это.
Пока есть объективный критерий отличия разумных от неразумных животных по количеству понимаемых слов в языке. Представьте, что ваша собака распознавала бы не десяток команд, а несколько тысяч. Ей можно было сказать не просто «иди на место» (заметьте, что ее интеллекта хватает на последовательность действий, чтобы пойти на место и лечь там). А сказать «иди в магазин, там возьми батон хлеба, по дороге зайти к соседке и набери лапой сколько тебе лет». Понимание таких фраз уже смахивает на разумное поведение. Не только одной заученной фразы, всего их разнообразия, которые можно построить из пары тысяч слов.
А ведь такая фраза не так уж принципиально отличается от «иди на место». И там, и там есть последовательность действий. Собаке знакомы понятия «иди», «место». Но она не знает что такое «магазин», «соседка», «сколько лет». А ведь если бы знала несколько тысяч таких слов-команд, то вела бы себя практически так же, как мы ожидаем от ИИ!
Конечно, у собак есть физиологические ограничения, еще никому не удалось научить их распознавать десятки тысяч понятий. Но этот пример говорит о важности для интеллекта большой базы понимаемых слов.Cubicmeter
04.04.2017 19:55+1> Что значит осознает себя, свои потребности? Мы не можем ответить на этот вопрос
Это значит «имеет модель себя», «имеет модель своих потребностей». На вопросы эти и многие другие ответы давно даны, на разный вкус и цвет. Если хотите ответов, которые не сводятся к хождению кругами — не читайте психологов, читайте Марвина Минского: The Emotion Machine и The Society Of Mind. Удивитесь: там очень многое есть.StormEagle
04.04.2017 22:03На вопросы эти и многие другие ответы давно даны, на разный вкус и цвет.
Если это так, то где сильный ИИ? Значит эти ответы не полны или содержат в себе другие не определяемые термины.Cubicmeter
05.04.2017 11:44Нет, не значит. Смотрите: физики хорошо представляют себе в общих чертах, как протекают термоядерные реакции синтеза — на Солнце, например. И уже довольно давно. Тем не менее, эффективный термоядерный реактор до сих пор не создан, и видимо не будет создан еще несколько десятилетий. Не потому, что мы не знаем деталей, или наша схема плоха — просто мы не можем создать тут маленькое Солнце, нам приходится изобретать другие способы. Так и с разумом: общая схема ясна, детали загадочны, механизм воспроизведения — не изобретен.
MegaVaD
04.04.2017 22:12Красота — признак здоровья, здоровье для размножения, размножение для продолжения существования. Для ИИ будут иные признаки продолжения существования.
StormEagle
04.04.2017 22:23Для ИИ будут иные признаки продолжения существования.
Страшен не тот ИИ, который пройдет тест Тьюринга, а тот который его сознательно завалит ))

lui
04.04.2017 18:21+6Например, исследователь задавал такой детский вопрос-загадку: «Белые медведи живут там, где снег. На севере снег. Какого цвета там медведи?» Туземцы не могли провести такие простейшие логические параллели. Все их ответы сводились к вариантам вроде: «Если кто-то поедет на север и посмотрит, то он сможет сказать какого цвета там медведи, а иначе никаких способов узнать это нет».
А ведь туземцы с точки зрения логики были формально куда более правы, чем исследователь.
Из данной формулировки абсолютно не следует, что если на севере снег, то медведи там белые.
Необходимо != достаточно.StormEagle
04.04.2017 18:53-1Конечно, они были правы. На своем бытовом уровне. Но имелось ввиду, что мы своих детей учим определенному логическому мышлению. На примере детских задачек, в школе, и так далее. И считаем такое мышление естественным для любого разума. Но изолированные _человеческие_ племена показали, что это не обязательно так. Поэтому наши подходы к построению ИИ могли провалиться в том числе из-за такого предвзятого отношения, что разум должен уметь и чего не должен.
Другой пример — пресловутая разница в мышлении/образовании советских людей и западных представителей. Не вдаваясь в детали, она похоже заключалась в том, что все наши задачки в школе и институте были жестко формализованы и не содержали подвоха (задачки с подвохом выпускались отдельно в юмористических изданиях). С одной стороны, это здорово развивает алгоритмическое мышление. Когда из имеющихся данных, как из кубиков, нужно скомбинировать новое и найти решение. Но с другой, с развалом СССР, наши люди (умные люди — инженеры, академики) оказались абсолютно не готовы к валу неструктурированной, зачастую обманной и неверной информации. Отсюда бум в 90-х годах различных лженаук, экстрасенсов, лозоходцев и прочих петриков. Причем в эту ловушку попадались в том числе далеко не глупые люди. Посмотрите, какой бред порой несут признанные академики, стоит коснуться не их профессиональной темы (но достаточной для понимания своей абсурдности простого здравого смысла).
А судя по всему, причина оказалась в том, что в то время книжные полки вдруг резко оказались завалены желтой прессой и разными сомнительными брошюрками (кто помнит, подтвердит). Наши люди совершенно не умели отличать правдоподобно выглядящую ложь от правды, так как в детстве их никто этому не учил.
С другой стороны, сейчас кинулись это исправлять, и вводить в школьную программу разные «западные» задачки. Которые для нас выглядят нелепо и смешно. Но их суть сводится к тому, что информация может быть обманной, что везде нужно ждать подвоха. Хорошо это или плохо, растить таких циничных детей, это сложный вопрос. Но все это не так просто. Мышление должно сочетать гибкость и формальность.
Те описываемые туземцы оказались менее умные, чем мы. С более низким интеллектом. А почему? Хотя бы потому, что мы обладаем большей гибкостью — мы можем понять как их точку зрения (как вы правильно сделали), так и свою. А они нашу понять не смогли. Чем не критерий для определения разумности ИИ?asoukhoruchko
04.04.2017 20:30Мне кажется, вы упускаете, что разум это инструмент, предназначенный для обеспечения выживания в определённых условиях. И то, что туземец не способен даже понять какие-то задачи, специфические для нашего мышления, не должно вызывать удивления. Как и наша способность понять его сложности, потому что мы пользуемся всей полнотой знания по вопросу. Вот если мы будем также хорошо ориентироваться в вопросах, характерных для туземной жизни — это уже будет показательно.
StormEagle
05.04.2017 01:12И то, что туземец не способен даже понять какие-то задачи, специфические для нашего мышления, не должно вызывать удивления.
Это не вызывает удивления, это говорит о том, что если у разума и есть какие-то общие правила, то очень многое зависит от обучения, которое он прошел. И что брать за основу при проектировании ИИ только себя, свой способ мышления, как образец разума, будет ошибкой. Лучше опуститься на какие-то более низкие фундаментальные принципы.
Посмотрите, какое количество теорий разума существует. Многие из них невероятно остроумны (не в плане юмористические, а от словосочетания «острый ум») и формализованы. Но, перефразируя Ферми, «Где они все?». Где практический результат от всех этих уверенных в своей правоте теоретиков?
В то же время простейшая рекуррентная сеть, сделанная на коленке и обученная на массиве текстов, абсолютно не понимая смысла прочитанного, выдает в чат-программах результат лучше или сопоставимый с лучшими алгоритмическими «теоретическими» системами ИИ. Это о многом говорит, как мне кажется. Из этого, как минимум, стоит сделать выводы.
hungry_ewok
05.04.2017 12:46/хмыкая/
А, собственно, и «нашу способность его понять» не стоит переоценивать, знаете ли.
За таким вот типом мышления, где плохо с абстрактными вопросами и заданный вопрос понимают буквально, на самом-то деле особо далеко к туземцам ехать не надо — он вполне себе сохранился в полный рост в глухих крестьянских углах или в сидельческой среде.
И носители этого самого развитого абстрактного мышления, столкнувшиеся со средой где базар надо фильтровать и за него отвечать — выглядят не самым лучшим образом, при всей этой способнсти понять…
hungry_ewok
04.04.2017 18:55Именно. А еще это показывает отличие, скажем так, в абстрактности мышления и серьезности подхода к заданному вопросу.
То, что для этнографа детская загадка-прикол, которую задал, получил стандартный ответ и забыл — для туземца вводная к которой следует подойти серьезно, и собрать реальные данные, не полагаясь на предыдущий опыт и аналогии. Иначе эти самые медведи его и сожрут.StormEagle
04.04.2017 19:08В той публикации говорилось не о правильности или корректности загадки, а о неспособности тех туземцев понять, что имеет ввиду спрашивающий. Посыл был такой: почему наши дети с легкость справляются с таким логическим построением, а они нет? Попытки объяснить смысл загадки не увенчались успехом.
maslyaev
04.04.2017 19:15+2Да уж, сложно объяснить туземцу, почему следует допускать типичную для нас, европейцев, логическую ошибку :))
yefrem
04.04.2017 19:32+1Ну дык, нас-то с малолетства учили давать не правильный ответ, а тот, которого ожидает вопрошающий, иначе зачет не поставят.
maslyaev
04.04.2017 20:25Вот и получается, что для нас фактором жизненного успеха является конформность, а для дикарей — способность принимать адекватные в практическом плане решения.
И объяснить такому дикарю пользу конформности — без шансов. Дикие люди, дикие нравы.
ilansk
07.04.2017 06:49Ну-у, наша конформность вполне адекватна для наших условий, т.к. она фактор успеха для нашей среды и условий. У дикарей, как и у медведей другие условия и успехи (поиск глобального минимум) будут иными (даже противоположными). Т.е. по сути и горожанин и туземец принимают адекватное решение для своих условий и задач при одинаковых мозгах.
Тут возникает философская проблема: технический путь развития цивилизации людей насколько верный? Может Он адекватен лишь в тех условиях, в которых мы сей час живем? А если условия изменяться?
StormEagle
04.04.2017 19:34Ну почему ошибку? Как абстрактная логическая задачка, она полностью корректна. Но этот пример только подтверждает, что разум сильно зависит от того, чему его научили. Похоже, что интеллект это не некое универсальное состояние, а всего лишь примитивное обучение с огромным объемом памяти.
Туземец оперирует только настоящими живыми медведями, и он абсолютно прав — чтобы узнать их цвет, нужно на них посмотреть. Его просто никто в детстве не учил абстрактным задачкам.yefrem
04.04.2017 19:54Ну ответ же не меняется, хоть медведи, хоть зюзюмлики какие-нибудь, все равно ответить однозначно нельзя, это не зависит от абстрактности. Медведей там может не быть вообще, могут быть какие-то еще и т.д.
DjOnline
04.04.2017 22:19+1Я вижу пока только проблемы с логикой у исследователей, мягко говоря. Питер на севере, там тоже есть снег, значит по этой извращённой логике исследователей там должны быть медведи? Исследователи американцы? )
svistkovr
04.04.2017 23:26+1Исследователи явно не из наших мест. Бурый медведь тоже водиться там где бывает снег. Видно туземцы это знают и не могут понять — что от них хочет сумасшедший учёный.
hungry_ewok
04.04.2017 19:39+2/хмыкая/
Дело, повторюсь, не в неспособности понять; судя по ответу — понять-то вполне себе поняли.
Дело в восприятии того что спрашивают. Для туземца это не абстрактная задачка на примитивную логику; это вводная, «белые медведи живут где снег», «где-то на севере есть снег» и отталкиваясь от этой вводной он пытается решать строго практическую задачу «что я буду делать оказавшись на севере». И в этом плане данных во вводной — категорически недостаточно, он резонно говорит что «жить на севере может что угодно, это надо на месте смотреть.»
И да, наши детишки справляются с этой задачкой влегкую, потому что они эти абстракции не пытаются рассматривать в применении к себе и практике. Это, конечно, здорово для решения таких задачек, но сколько таких потом мычит «ну я не думал что так получится» в травпунктах…
qdb
05.04.2017 16:57то есть, на севере может и не быть медведей, так как четко не сказано, что в любом месте, где есть снег, живут медведи. но, вопрос «Какого цвета там медведи?» утверждает что они там есть. и даже если бы не было такого утверждения, есть вариант ответить «они белые, если они вообще там есть». в чем же тут мог быть подвох? или на самом деле утверждения не были высказаны именно таким образом, или вообще это неправда.
также неправда про то что люди без слов для цветов в их языке не различают этих цветов, также неправда что без слов для 4 и 5 они не различают 4 от 5. я сразу же не поверил в это, как только такие мнения увидел. тогда же или позже я увидел отрицание этого. нехватка слов это обычное явление, ничего такого не происходит же. просто различение таких вещей может быть неважным, это не значит что мы не можем различить их если это становится нужным.StormEagle
05.04.2017 17:03Хорошо, возьмем другой пример: психологические термины. Бывает так, что человек мучается от избытка чувств и не может придти ни к какому выводу, но стоит описать его чувства психологическими терминами, как все раскладывается по полочкам и становится понятно.
Сюда же можно отнести поговорку: хочешь сам понять что-то, объясни это другому [словами]. Как только явления получают словесное описание, это дает возможность разуму дальше с ними оперировать логическими методами. Характерная черта разумного мышления, разве нет?

GreatNonentity
05.04.2017 22:01+1Да, вот, кстати, ссылка на исследование по этой теме: http://flogiston.ru/library/luria_cult
StormEagle
05.04.2017 22:55Спасибо, именно это исследование я имел ввиду, только подробности стерлись за давностью.

EviGL
06.04.2017 18:20Забавная ошибка при написании вопроса из памяти :) В оригинальной статье корректный вопрос задавался
На Дальнем севере, где снег, все медведи белые.
Новая Земля — на Дальнем севере.
Какого цвета там медведи?
Тут ответ на вопрос строго определён. А в вашей интерпретации задача некорректна, данных для ответа недостаточно.qdb
09.04.2017 16:25нет, тут тоже недостаточно. не хватает того, что на новой земле есть медведи вообще. а может быть кто-то не знает, что медведи могут заселить это место даже если это остров. и они могут быть перебиты людьми, и не допускаться туда.
zirix
04.04.2017 19:11А также знаем, что наш собственный мозг представляет собой примерно десятислойную нейронную сеть
Считается что искусственная нейронная сеть и мозг имеют очень мало общего. Функция слоев мозга сильно отличается от функции слоев ИНС.
К тому же это слишком примитивное описание мозга.
Ученые уже очень давно поняли что машинным обучением и нейронными сетями настоящий(сильный) ии сделать невозможно.
Сейчас ученые сошлись во мнении что в настоящий момень нет способов/технологий которые могут помочь в создании сильного ИИ.
Именно последнее стало причиной появления критических статей о нейронных сетях и о компаниях которые ими занимаются.eopveo
04.04.2017 21:43+4Те, что «поняли» — какие-то неправильные учёные. Многослойный перцептрон является универсальным аппроксиматором, а LSTM на его основе ещё и полны по Тьюрингу. То есть классический компьютер в теории по своим возможностям ничем не лучше LSTM. Вопрос только в целесообразности применения инструмента к задаче.
Технологии для создания ИИ уже сегодня существуют, вопрос только в их улучшении. В сегодняшнем виде явно нейронные сети негодны, но и никакого тупика не видно. Наоборот, количество улучшений растёт с такой скоростью, что у человечества уже проблемы со способностью переваривать данные. То, во что превратятся нейронные сети в будущем, окажется совсем иной технологией с менее гомогенной архитектурой и большей самостоятельностью. Если приглядеться, очень напоминает путь от первого транзистора до сегодняшнего процессора.
Несколько лет назад самообучающийся агент только по сигналам «хорошо» и «плохо» успешно научился играть на приставке Atari 2600, недавно в Doom людей порвал, скоро до Starcraft 2 доберётся а там гляди и в наш мир играть будет. Именно так выглядит задача ИИ для инженеров. Это не создание идеального философского бурбулятора, цель — решать реальные задачи, а будущее решит что станет двигателем. Те, кто гоняется за сознанием, пониманием и всякими квалиа как раз делают идее ИИ самую большую антирекламу унылыми философскими простынями. Человек не стал делать махолёт подражая во всём птицам и никто не ставил «познание сущности полёта птицы» обязательным условием, при этом схожесть сегодняшних летательных аппаратов с птицей связано с самим миром, который диктует нам условия и в значительной мере влияет на результат.
i360u
04.04.2017 21:51Простите за криворукость, случайно ткнул в минус, хотя целился в плюс. Движок, к сожалению не дает исправить ошибку.
zirix
05.04.2017 01:04-1Именно так выглядит задача ИИ для инженеров. Это не создание идеального философского бурбулятора, цель — решать реальные задачи
Упомянутый мной сильный ИИ это и есть бульбулятор. По определению. Как минимум такая система должна иметь мышление. Как максимум самосознание/сознание.
Сколько бы не улучшали нейронные сети, сильным ИИ из них сделать нельзя. В принципе.
Нейронные сети полезны и применяются. Но в некоторых задачах слабого ИИ недостаточно и обойтись без бульбулятора не выйдет.eopveo
05.04.2017 02:43+1Я начну свой ответ с наблюдения, что когда люди начинают рассуждать о подобных философских определениях, то верным они считают то, что у них в голове, а право решать что попадает под их определение закрепляют за собой. И когда о создании ИИ говорят в таком вот свете, то есть определяют ИИ как набор своих пожеланий, то я называю такую вещь философским бурбулятором по аналогии с философским камнем.
ИИ должен создаваться и будет создан только по реальным требованиям, возникающим при решении реальных задач. И это не будет один большой план с TODO-листом. Это будет множество различных направлений, которые найдут обобщенный базис. ИИ получит и мышление и сознание и прочие плюшки, но не потому что это какие-то пункты в непонятно кем составленном списке, а потому что сама среда, как я уже говорил, создаст необходимость в механизмах, подобных человеческим. И похоже что эти механизмы возникнут эмерджентно в достаточно сложной системе, о чём уже свидетельствуют сегодняшние достижения наук. Например искусственный игрок в арканоиде нарочно начинает забрасывать мяч позади блоков или в Doom бежит на красный крест в белой рамке. Никто не закладывал заранее в нейронные сети ни такое поведение ни цель. Агент лишь руководствуется сигналами поощрения и наказания за сбивание блока/потери мяча в первом случае и выноса врага/смерти во втором. Мы уже видим простейшее мышление вроде «аптечка помогает оставаться живым» и в отличии от прошлого века, никто заранее не создаёт алгоритмов логического вывода для этого. Можно спорить о том настоящее мышление это или нет, но самое главное достижение человечества ИМХО будет не созданный ИИ, а признание людей, что интеллект это не когда «как у меня и квалиями трясёт и квантовыми трубочками резонирует и вставить_сюда_нью_эйджевую_чушь», а когда работает.
Что касается нейронных сетей, то я не вижу причины в столь категоричных утверждениях. Как я уже сказал, некоторые виды рекуррентных сетей полны по Тьюрингу, то есть могут всё то, что и обычный компьютер, но при этом как абстракция они более удобны при решении задач, требующих, как считается, интеллекта, и прекрасно подходят в роли того самого обобщающего базиса для многих направлений машинного обучения. Спекулировать фразами «невозможно в принципе» при отсутствии машины времени слишком смело.
tabmoo
04.04.2017 19:41Насчет туземцев и историй про «десятки оттенков зеленого и белого», насколько помню, все не так однозначно, и при внимательном рассмотрении там все оказалось намного обыденнее и «нормальнее».
Что бы кто ни делал, останется проблема квалиа (моя любимая формулировка: почему сознание не происходит в темноте) и вопрос, эквивалентна ли функциональность какого бы ни было ИИ интеллекту человека в широком смысле.Camrad_RIP
05.04.2017 15:34Зачем далеко ходить. Японцы зеленый, голубой. — аой. А свое слово для зеленого — мидори (изначально значени — незрелый), появилось относительно недавно. Благодаря расширению контактов с Западом.
zuborg
04.04.2017 20:57Спасибо за статью, прочитал с интересом.
Отдельное спасибо за ссылки на справочные материалы )

worldmind
04.04.2017 21:06это ABBYY Compreno. Прекрасное начинание, много труда, но похоже завершившееся как и предыдущие попытки.
жаль если это так, но они вроде какие-то продукты на этой технологии продают, есть инфа что у них всё плохо?
StormEagle
04.04.2017 21:59Был ряд статей в духе: «Мы много лет работали, вот-вот закончим, смотрите как здорово получается». Но с тех пор несколько лет тишина. Революционного переводчика на базе Compreno так и не появилось, насколько я знаю. А самой базе найдут какое-нибудь применение, полагаю. Не пропадет, такие вещи используются во многих областях. Например, при распознавании речи результат сравнивается с синтаксическими конструкциями и выбирается наиболее близкая.
worldmind
04.04.2017 22:05Они писали, что перевод текстов потерял смысл из-за гуглтранслейта, хотя конечно это так себе отмазка.
Вроде у них ещё с производительностью были проблемы, может поэтому не пошло.StormEagle
04.04.2017 23:40Google Translate долгое время испытывал проблемы с частицами «не» и некоторыми другими, вызванными особенностью статистического подхода. А ведь фразы «я что-то сделал» и «я что-то НЕ сделал» имеют принципиально разный смысл. Хотя со статистической точки зрения они похожи. У Compreno с такими вещами не должно было быть проблем в принципе. Жаль, что не пошло. Но нейросетевой Google Translate должен, по идее, тоже быть избавлен от такого недостатка. Так как в нем такие вещи обрабатываются ближе к смыслу, т.е. фраза делится не совсем на слова, а скорее на словосочетания «сделал» и «не сделал», которые обрабатываются как цельные смысловые объекты. Ну а как будет в реальности, посмотрим.
cepera_ang
05.04.2017 13:41+1Нейросетевой переводчик гугла шикарен, конечно можно его сбить всякими хитрыми конструкциями, но бытовую речь переводит просто идеально (на мой скромный взгляд)
worldmind
04.04.2017 21:30+1Нейронные сети вроде как далеки от мозга, да, может зрение в мозге похоже устроено, а вот сознание похоже по другому, да и память.
Как минимум в мозге нейроны сами создают новые связи и имеют очень много этих связей, нейронные сети только умеют менять веса в своих нейронах.
Tryone
04.04.2017 21:40Спасибо за статью.
Прочитал с огромным интересом, несмотря на мелкие ошибки, на таком объеме несущественно.
Понравилось что сделаны отступы в архитектуры нейросетей, даны ссылкы для самостоятельно исследования. Long read удался)

ser_kol
04.04.2017 21:41Я думаю что все, о чем в статье написано, называется «распознавание образов». Разве это и есть интеллект?
Представим себе гипотетического таракана, который без ошибки распознает изображение человека, кошки, птицы, тигра, дивана и т.п., но во всем остальном — таракан. Он обладает интеллектом?
Мне почему-то кажется, что распознавание образов — необходимая для искусственного интеллекта вещь, но это еще далеко от какого-либо интеллекта.StormEagle
05.04.2017 15:57Я думаю что все, о чем в статье написано, называется «распознавание образов». Разве это и есть интеллект?
Распознавание образов это не интеллект. Но наш собственный интеллект физически представляет собой процесс, когда сигнал от уха, услышавшего вопрос, бежит к мозгу, там петляет, усиливаясь и ослабляясь (и подвергаясь на нейронах нелинейному преобразованию, это ключевой момент, без него ничего работать не будет), и в итоге выходит на мышцы рта, произносящего ответ.
Если что-то распознает картинки так же хорошо, как мы, и работает сходным принципом, то логично предположить, что сигнал может пройти и остаток пути до мышц «рта», который произнесет разумный ответ.ser_kol
05.04.2017 17:04Если что-то распознает картинки так же хорошо, как мы, и работает сходным принципом, то логично предположить, что сигнал может пройти и остаток пути до мышц «рта», который произнесет разумный ответ.
О каком ответе вы говорите? Типа «это машина», «это человек» — так это не интеллект, это «сравнение», распознавшие образов, усложненное сравнение образца с эталоном.
Еще будучи студентом, году в 90м, я писал программку для робота с камерой для разбраковки пластиковых деталек — годна или брак. То, что тут описано, мне напоминает мою задачку на более высоком уровне сложности, на интеллект это мало (совсем не) похоже.
Меня заинтересовало то, что делает Перловский — я узнал о нем, когда, после прочтения вашей статьи, поискал в сети, как соотносятся «распознавание образов» и «искусственный интеллект». То, к чему он стремится, мне кажется искусственным интеллектом. То, что пишете вы, мне кажется просто сложным сравнением образцов с эталонами.StormEagle
05.04.2017 17:27О каком ответе вы говорите? Типа «это машина», «это человек» — так это не интеллект, это «сравнение», распознавшие образов, усложненное сравнение образца с эталоном.
Не совсем, посмотрите эту ссылку: https://geektimes.ru/post/283156/, где нейросеть предсказывает, что произойдет через 1 секунду на фотографии.
Согласитесь, это очень близко к сильному ИИ. Ведь многие чисто абстрактные вещи тоже можно представить как предсказание. Лежат три палочки на столе, одну начинаем убирать, что произойдет через 1 секунду? Делаем предсказание: останутся две палочки. А ведь это операция вычитания, примерно так дети и учатся арифметике.
Просто сейчас вычислительная мощность для нейросетей слишком мала. По ссылке выше нейросеть берет картинку разрешением 64х64 пикселя, и пытается предсказать для нее следующие 32 кадра.
Разрешение «глаза» 64х64 пикселя и на основе только одного кадра из видео, вы это серьезно? ) По сравнению со 150 Мп у человеческого глаза (300 МП у двух глаз в сумме) и каналом минимум в 2 Мп до мозга, который действует непрерывно в течении десятков лет.
Хочется посмотреть, какие результаты будут, когда картинка на входе будет иметь разрешение хотя бы 640х480 пикселей (при меньшем разрешении мало что можно разобрать). И анализировать будет не единственный кадр, а хотя бы несколько предыдущих секунд.
А является ли мышление простым сравнением с образцом и примитивной интерполяцией, это хороший вопрос. Не исключено, что количество нейронов в мозге (10 в 11 степени) могут содержать достаточный набор «картинок» из жизни, чтобы простая интерполяция давала ответы на все вопросы. Все наши представления о разуме как о высокоуровневых способах обработки информации могут оказаться простой абстракцией, которой мы наделяем более примитивный и простой процесс. Что не уменьшает значимость понимания этих абстракций, разумеется.
i360u
04.04.2017 21:48Это очень странно, но вот буквально сегодня утром я мучал свою жену очень похожими рассуждениями. Я бы еще добавил мысль о том, что многие, весьма абстрактные, проявления интеллекта естественного, такие как "чувство прекрасного" — являются следствием обучения управлению положением собственного тела в пространстве (одной из фундаментальных задач биологического мозга), когда из изначальных соотношений масс и расстояний рождается возможность предсказывать траектории и положение объектов (к примеру, ребенок перепрыгивает лужу) и далее это влияет на восприятие динамики линий, уже в живописи, если говорить упрощенно.
StormEagle
05.04.2017 00:42многие, весьма абстрактные, проявления интеллекта естественного, такие как «чувство прекрасного» — являются следствием обучения управлению положением собственного тела в пространстве
Более того, многие наверно помнят, как в детстве иногда появлялось желание побежать со всех сил, просто так, без всяких причин, и какой при этом был восторг. А ведь это действие имеет прямой эволюционный смысл — тренировка быстрого бега. И природа награждает такое поведение выбросом эндорфинов (ощущением счастья).
Но хочется отметить, что это не просто активация моторных нейронов после долгого отдыха, когда моторные нейроны накопили с помощью своих натрий-калиевых насосов достаточный потенциал, чтобы разрядиться и отправить нервный импульс на мышцы ног.
Бег это сложное скоординированное движение. А значит где-то в глубине мозга имеются некоторые заложенные в инстинктах предустановки, как правильно бегать. Впрочем, это может работать и на более высоком уровне — вознаграждаться только за скорость, а бег получен обучением с младенчества. Но скорее всего это комбинированная система, потому что на движения младенцев тоже оказывает влияние физиология. Хотя бы то, в какие стороны и как сильно гнутся руки/ноги. А некоторые вещи, вроде хватательного рефлекса, прописаны в нейронной сети явным образом и работают с первых дней жизни.
Поэтому мало написать симулятор ИИ, надо ему реализовать похожие стимулы для развития. Любопытство и «беспричинные» желания что-то делать — двигаться, тянуться к крупным предметам (как утята при рождении). И вознаграждать за «правильные» действия. Хотя и не совсем ясно, что в этом случае считать наградой и как ее реализовать. Но при таких стимулах и существующие архитектуры нейронных сетей способны дальше самообучаться, аналогично живым организмам.
perfect_genius
05.04.2017 07:00Я думаю, в детстве организм растёт быстро и мозгу часто нужна перекалибровка тела — узнать его возможности. Как быстро может перемещаться, как долго не уставать.
i360u
05.04.2017 11:26Бег это сложное скоординированное движение. А значит где-то в глубине мозга имеются некоторые заложенные в инстинктах предустановки, как правильно бегать.
вряд-ли такие предустановки есть, как и поддержка каких-то сложных операций по вычислению параметров бега. Ребенок просто учиться бегать повторяя множество попыток, начиная с самых неуклюжих до тех пор, пока не побежит нормально. Это такое-же обучение нейросети. Набор чувств получаемых через рецепторы преобразуется в выходные параметры на основании множества циклов обучения. Единственная предустановка — очень проста, что-то типа "хочу быть там". Для создания "сильного" ИИ, на мой взгляд, нужно создать условие, по которому практически ничего, кроме нейросетей для этого ИИ нет субъективно, ни отдельных слоев для работы с памятью, ни отдельных вычислительных блоков ни сложных внешних алгоритмов. Все эти составные части должны быть реализованы одинаково с помощью нейросетей. Нехватку вычислительных мощностей можно компенсировать изменением масштаба субъективного времени ИИ. Мне показалось, что вы изначально о чем-то подобном и писали.
StormEagle
05.04.2017 15:51вряд-ли такие предустановки есть, как и поддержка каких-то сложных операций по вычислению параметров бега.
Насколько я знаю, в физиологии мозга заложены многие сложные предустановки — рефлексы, инстинкты. Это определяется еще в ДНК, где какие нейроны вырастут при росте эмбриона. Близким нейронам проще дотянуться друг до друга. А может и пути основных нервных каналов/путей тоже запрограммированы в ДНК. К примеру, рожденные и выросшие в зоопарке обезьяны боятся садового шланга, так как в джунглях змеи являются их злейшими врагами. Хотя настоящую змею они никогда не видели. Очевидно, что распознавание образа змеи и выброс адреналина уже прошиты в их нейросети с рождения как инстинкт. Но бег это результат обучения, конечно. Младенцы бегать не умеют ).
Вопрос в том, насколько сильно эти вложенные в физиологию предустановки влияют на развитие разума? Понятно, что сама структура мозга (объем, процент серого вещества и т.д.) заданы физиологией, но, возможно, в процессе эволюции в наш мозг были зашиты и более сложные структуры, определяющие логику мышления. Тогда для ручного воссоздания ИИ нужно разобраться, что это за структуры.
Но вероятность этого мала, так как в бытовых ситуациях люди и животные реагируют на окружающую среду похожим образом (попугаям и другим умным животным доступно понятие математического нуля, например). Плюс выросшие в дикой среде дети не демонстрируют тех же мыслительных способностей, что обычные. Не смотря на то, что обладают физически точно таким же мозгом. Поэтому скорее всего, наш разум является результатом логического обучения от родителей/сородичей.i360u
05.04.2017 18:32Садовый шланг — это та-же условная кривая из моего первого примера про динамику линий в искусстве, ее образ близок к образу движения объекта по некой траектории, и сигнал опасности рождается как-то так: "что-то неопределенное движется возле меня — опасно!". Для этого не нужны сложные предустановки, как и для реакции на сам сигнал — он легко получается в процессе обучения, для которого нужна боль и соответствующая среда. В ДНК нет участков, которые это прямо программируют, как и многих других заранее заданных параметров и признаков. Пример со змеей отлично иллюстрирует то, что я говорю, иначе обезьян также пугали бы и многие другие безобидные предметы и явления. На Ютубе есть очень интересный цикл лекций от Роберта Сапольски, он как-раз затрагивает эту тему в весьма популярной форме (биология поведения человека). Очень рекомендую посмотреть — получите удовольствие .
Поэтому скорее всего, наш разум является результатом логического обучения от родителей/сородичей.
среда — ключевое слово. Она формирует нас и делает разумными, предоставляя все необходимые данные для обучения. Вы сами привели отличные аргументы в пользу этого мнения в статье. Кстати, именно это, также, делает нас не очень-то разумными во многих случаях: мы ведем себя так как обучены а не так как по настоящему разумно: недавно читал про забавный эксперимент в котором не самые глупые люди игнорируют факты если они противоречат ранее полученному опыту.
StormEagle
05.04.2017 19:07Садовый шланг — это та-же условная кривая из моего первого примера про динамику линий в искусстве, ее образ близок к образу движения объекта по некой траектории, и сигнал опасности рождается как-то так: «что-то неопределенное движется возле меня — опасно!».
Да, возможно и так. Тут нигде нельзя говорить с определенностью, пока не будет подтверждено в экспериментах. Можно лишь строить догадки с той или иной степенью обоснованности.
Но хотелось бы привести еще пример. Утята с рождения бегут за матерью. Это сложное поведение. Но на самом деле они бегут не за матерью, а за любым крупным объектом в их поле зрения (что подтверждено экспериментально). То есть у них в голове есть некий сумматор, который после некоторого порога количества активированных пикселей в глазах (особенно сдвигающихся в стороны, т.е. реагирующих на движущийся объект), дает нервный импульс на мышцы ног. Но команда мышцам согнуть конечность это не просто одна команда, так как тогда получился бы не бег, а конвульсии. Одновременно всегда идет команда расслабить противоположные мышцы, иначе просто не получится согнуть конечность.
Добавьте сюда временные задержки, связанные с естественной жизнедеятельностью нейронов, и получим естественные движения вроде бега. Плюс общая система мотивации, и получим стимул для улучшения этого навыка. Как-то так представляются все сложные врожденные инстинкты, вроде постройки гнезд и т.д.
Нет оснований полагать, что подобный принцип не используется и для более сложных паттернов поведения. Вшитых в настройку нейронной сети с рождения. Более того, подобные паттерны могут быть и в мышлении. Например, так можно реализовать любопытство: необычные (сильно отличные от предыдущих по времени) пиксели в глазу могут вызывать похожим образом сигналы на мышцы шеи, чтобы повернуть голову в сторону источника необычной картинки. И младенец поворачивает голову на яркое пятно или шум.
А система поощрения может так же стимулировать бег/ходьбу в сторону интересного, как у утят за мамой. И получаем высокоуровневое врожденное любопытство, заставляющее обезьяну подбегать и открывать ящик, хотя уже видела, что там змея (был такой ролик на youtube).
Кстати, насчет боязни обезьян искусственных змей, вот пример: https://www.youtube.com/watch?v=E37IQ5Dop90. В принципе, форма змеи действительно может быть похожа на линию движения и тем самым вызывать чувство опасности. Но может и быть зашита как готовое изображение для распознавания. Надо бы найти похожий пример, в котором можно исключить линию как кривую для траектории.i360u
05.04.2017 22:20Эх, ненавижу писать длинные телеги, а парой слов в этой сложной теме не обойтись. Я считаю, что пусть к созданию сильного ИИ находится где-то поблизости от темы, которую мы обсуждаем, и если все упростить, можно условно выразить его в следующих тезисах:
Смоделировать интеллект возможно смоделировав среду, необходимую для его развития и результат будет сильно зависеть от параметров этой среды (не меньше чем от каких-то собственных заранее заданных параметров)
Для создания похожего на наш интеллекта, необходима система поощерений/наказаний (боль/удовольствие) работающая на фундаментальном уровне для нашего гипотетического кибер-субъекта. При этом, наше и его субъективное время — могут сильно отличаться: мгновение для ИИ может быть годом для нас и наоборот, что должно учитываться, но весьма сложно для человеческого восприятия.
Нет четкой грани между средствами решения задач: одинаковые способы решения могут быть применимы для совершенно разных категорий задач и комбинироваться они могут любым образом (этому комбинированию также можно научить нейросеть). Управление движением может влиять на восприятие звуков и прочая, тому подобная синестезия возможна и даже необходима для оптимизации. Поэтому, к примеру, обучать ИИ работе только со словами и абстрактными понятиями — тупик.
- Изначальные базовые условия и алгоритмы довольно просты и вполне воспроизводимы.
perfect_genius
04.04.2017 22:03А как там обстоят дела с аппаратными нейросетями?
StormEagle
04.04.2017 22:10Так же, как с революционными аккумуляторами, о которых постоянно выходят новости ). Работа идет, но пока все дорого, мало и толком не работает. Очень перспективными кажутся аппаратные нейросети на базе мемристоров: https://nplus1.ru/news/2015/05/08/memristors. Они в теории могут быть дешевыми и очень емкими (терабайты на размере микроSD карточки). Но будут ли — неизвестно. Имхо, пока стоит рассчитывать на обычные технологии.
ser_kol
04.04.2017 23:36К моему же вопросу — сводится ли искусственный интеллект к распознаванию образов, поискал в сети и нашёл очень интересный текст. Вот это звучит правдоподобно с моей точки зрения.
http://www.russianscientist.org/files/archive/Nauka/2008_PERLOVSKY_20.pdfStormEagle
05.04.2017 19:12Отрывок из статьи по ссылке:
Но связь между понятиями и представлениями изначальная,
врожденная. Как только ребёнок услышит слово, он попытается понять, чтo этому слову
соответствует в реальной жизни.
У животных нет такой врождённой связи, нет двойной модели. Собака может
принести туфли по команде. Но её надо специально учить, что звук «туфли» связан с
объектом туфли.
Это не так, см. Голубиные предрассудки. В этом люди не отличают от животных, так как одинаково строят взаимосвязи между явлениями. Просто у людей, похоже, лучше производительность и память. Это ведь связано с физиологией, насколько нейроны пластичны, как быстро межнейронные связи изменяют свои веса и так далее. Да и пути распространения нервных сигналов наверняка тоже играют большую роль, а они заданы в днк.


grekmipt
05.04.2017 13:16На мой взгляд, направление мыслей у вас в целом правильное — но детали явно не проработаны.
1) Почитайте для начала книгу «об интеллекте», автор Джефф Хокинс. Сильно вырастет понимание того что такое иерархичность мышления и как примерно оно устроено.
2) Проанализируйте зачем вообще нужен интеллект. Краткий ответ — интеллект это штука которая позволяет «отфильтровать» из окружающего мира критические для выживания особи сцепки «если-то». Отсюда следует, что для формирования интеллекта через обучение — строго необходима «система координат», т.е. прошитые вне интеллекта понятия «хорошо-плохо». Только такие понятия (т.е. боль, удовольствие, голод, холод, тепло, и т.п., иначе говоря — базовые инстинкты) являются тем каркасом на основе которого в принципе возможно выделение из окружающего мира критичных сцепок «если-то». Иначе говоря, для самообучения сильного ИИ — ему нужны инстинктивные «хочу/не хочу или „хорошо/плохо“, иначе ничему он не обучится вообще (слишком много можно выделить совершенно бесполезных взаимосвязей в окружающем мире, тот самый комбинаторный взрыв только в еще более сильном варианте, нужен фильтр для отбора полезных „если-то“, а значит понятие пользы необходимо задать в явном виде как нечто внешнее к ИИ).
3) Мощности по созданию абстракций у интеллекта идущего путем самобучения крайне ограничены. Для того чтобы обойти это ограничиение — возник язык. Как носитель абстракций, передающихся от поколения к поколению (а не возникающих в процессе обучения каждый раз заново). Иначе говоря, если даже создан нормальный „субстрат“ для развития сильного ИИ (т.е. есть инстинктивные потребности, и система обратной связи на их удовлетворение, и система анализа потока данных от окружающего мира), то лучшее что можно ожидать от такого эксперимента — создание „маугли“ (как это и происходило иной раз с человеческими детьми). Т.е. очень условно разумное животное. Для того чтобы получить реальный сильный ИИ — нужно сразу обучать его с использованием дополнительной „разметки“ внешнего мира через использование какого-либо человеческого языка (ибо никакого более ёмкого носителя дополнительных абстракций внешнего мира у нас пока просто нет).
Итого: берете систему устроенную иерархически и могущую обучаться (те же глубокие нейросети + рекуррентные нейросети), закладываете инстинкты (хорошо/плохо), закладываете прошитую обратную связь на действия для удовлетворения инстинктов, помещаете такого бота в виртуальную среду, сопровождаете его действия словами человеческого языка (так же как это делают родители на протяжении многих лет), растите его эдак лет 5-10. PROFIT.
Собственно примерно об этом и писал Фрейд когда говорил что вся личность человека вырастает на базовых потребностях — не врал старик. Но такое обучение дело жутко муторное, плюс такой проект очень долгосрочный и со слабо понятными параметрами силы ИИ у того что получится на выходе. Так что думаю еще достаточно долго будут мурыжить отдельные задачки, прежде чем кто-нибудь реально решится на такой долговременный эксперимент.

AlexanderPerkov
05.04.2017 17:04-2Интеллект — это познание и создание новых смыслов на основе познания. Алгоритмический интеллект без самообучения — это обезжиренное масло.

tin04ka
05.04.2017 17:06+1Где-то было видео (первоисточник найти не удалось), кадр из которого показан ниже. На нем туземец не может отличить синий квадратик от зеленых. При этом он здоров и не дальтоник, просто такова особенность их языка (отсутствие слов для синих цветов) и связанного с этим обучения в детстве.
Это отрывок из BBC Horizon:Do You See What I See (видео есть на ютьюбе, смотреть с 41:23)
На самом деле всё ещё интересней: у племени есть слово, которое отвечает за определённые оттенки синего и зелёного, и другое слово, которым описывают другие оттенки зелёного. Было проведено 2 испытания: европейцам и туземцам показывали зелёные квадраты, один из которых был немного другого оттенка зелёного. На языке туземцев этот оттенок описывался другим словом и они без проблем находили отличающийся квадрат, у европейцев же были проблемы. Второе испытание видно на картинке из статьи. Оба цвета описываются у туземцев одним и тем же словом, поэтому им было трудно найти отличающийся квадрат.
lexa1980
05.04.2017 17:06-1Младенца и пустую нейросеть нельзя отождествлять.
У младенца уже есть инстинкты. Которые нарабатывались миллиарды лет.
Он знает как учится.
Ugrum
05.04.2017 17:14У младенца уже есть инстинкты. Которые нарабатывались миллиарды лет.
Мощно задвинуто.
Какие инстинкты такого возраста вам известны?

zheckiss
05.04.2017 19:16+1Я конечно, не специалист в области ИИ, но позвольте заметить, что признаки живого разума не ограничиваются последовательностью действий, обучением, логическими заключениями. Живой разум, кроме этих характеристик обязательно так или иначе выказывет отношение к рассматриваемому предмету, в котором содержится масса "параметров", которые влияют на конечный результат, например: эмоции, как исходное состояние разума, так и те, которые вызывает анализируемый предмет. Степень внимательности к предмету. Степень мотивации и важности для получения конечного результата. Возможность получения преднамеренного и непреднамеренного ложного или не полностью истинного результата. Время, которое разум планирует выделить для решения задачи и т.д.
Машина Тьюринга кажется разумной, потому что ее ответы являются частным простейшим решением, которое можно ожидать от живого интеллекта.
perfect_genius
05.04.2017 19:17Сильный ИИ не нужен, т.к. достаточно узкоспециализированных, но нам хочется. Более того, мы не боимся опасности ИИ и наоборот ждём, чтобы что-нибудь случилось из-за него (но не с нами), не так ли? =)
Также мы ждём, чтобы автопилоты массово тестировались, и надеемся, что баги выявятся не у нас.
Скайнет, мы тебя уже заждались, начинай уже.
DjSens
05.04.2017 20:36Без "мысленного" 3д моделирования ИИ нас не сможет понять. Вот какой пример я привёл разработчикам чисто текстового ИИ из CyberMind Tecnology — "Долго придумывал пример когда знание физики и полное 3д-моделирование ситуаций обязательно пригодится вашему ИИ — и вспомнил подходящий к случаю анекдот: сидит некий дядя-травокур на лавочке, насыпал в ладошку травку, другой рукой набивает травку в папироску. Мимо идёт маленький мальчик, увидел у этого дяди на руке часы и спрашивает:
- Дядя, а сколько время?
Небольшая пауза… и ответ: "Пипец те парень...".
Когда анекдот рассказывают — ещё и показывают как травокур инстинктивно смотрит на часы и становится понятно что трава из ладошки вся высыпается (наш мозг мысленно визуально эмулирует физику частиц травы и гравитацию). Ну даже без показывания понятна суть. Текстовый ИИ такой анек в виде не поймёт".
Я научился следить за ходом своих мыслей, реверс инжиниринг этакий провожу, оказалось наш мозг довольно примитивная штука и мыслит 3д объектами как привык в детстве игрушками играть. Ещё мозг постоянно сам себя программирует — закладывает прерывания и условия типа "буду в продуктовом, надо будет <...> ещё купить".
Когда мы читаем худож.книгу — мы мысленно видим 3д фильм. ИИ тоже должен будет это уметь, но он ещё и нам его сможет показать :)- Дядя, а сколько время?

aokoroko
05.04.2017 21:15Сознание — это в первую очередь рефлексия. Не просто «Я наблюдаю», а «Я наблюдаю, как я наблюдаю, как я наблюдаю, как я наблюдаю...» — каким-то образом сознание ухитряется закончить это сваливание в бесконечность и пользоваться его результатом.
Favorite101
06.04.2017 01:03Определения интеллекта из комментариев:
Интеллект — это способность находить в данных неизвестные ранее зависимости, строить на их базе умозаключения и иным образом ими оперировать, создавая ПРОИЗВОДНОЕ от них НОВОЕ знание.
… интеллектом можно считать возможность правильно прогнозировать будущее, развитие системы, из имеющихся данных, с построением моделей, нахождения причин и следствий, взаимосвязи на основе имеющегося опыта или информации. чьи прогнозы более точны и учитывают больший объем данных…
… интеллект как способность создавать алгоритмы и давать им описания, понятные другим.
… интеллектуальный агент — система, способная находить и выполнять оптимальные последовательности действий, ведущие к выполнению поставленной задачи".
… разум — это инструмент, предназначенный для обеспечения выживания в определённых условиях.
… интеллект — это штука, которая позволяет «отфильтровать» из окружающего мира сцепки «если-то», критические КРИТИЧНЫЕ для выживания особи…
Интеллект — это познание и создание новых смыслов на основе познания.
Итого: 7 разных определений интеллекта и только в двух отмечено выживание. Почему отмечено выживание? Прошу участников обсуждения взять любое из определений интеллекта, в котором про выживание не сказано, и последовательно позадавать вопросы к пояснениям в определении: «… находить в данных неизвестные ранее зависимости...».
Например, для чего (или — с какой целью) объекту нужно «… находить в данных неизвестные ранее зависимости...»?
Ответить (как это было в данном определении): «… чтобы строить умозаключения...».
Опять спросить: для чего (или — с какой целью) «… строить умозаключения»?
Ответить и вновь к ответу задать вопрос…
И так действовать, пока сможете задавать вопросы и на них отвечать. Цепочка может быть длинной, но ответ в конце будет таким — чтобы выжить. Или в более общей форме — чтобы существовать (быть, длиться, сохраняться как можно дольше). В этом как раз отражаются фундаментальные законы сохранения.
Возможно, участникам обсуждения будет интересно познакомиться с анализом многих десятков определений интеллекта? На основе анализа собрано определение интеллекта, которое придирчиво проверяется (спасибо К.Попперу) буквально каждый день.
Часть 1, http://triz-evolution.narod.ru/USE_Intelligence_Definitions_P1.pdf
Часть 2, http://triz-evolution.narod.ru/USE_Intelligence_Definitions_P2.pdf
ilansk
07.04.2017 09:08Сей час возможно создать нейросеть, которая с 95% точностью будет распознавать фотошопные видосики и фотографии. Далее можно создать видеохостинг с only реал-видео, на котором нейросеть будет отбраковывать подделки или указывать под видео процент нереальности. В соц. сети действует алгоритм на подобие, который определяет процент порнографичности фотографий.
mechkladenets
07.04.2017 21:15Вставлю свои 5 копеек: с классификацией изображений, прохождением игр или автопилотом Теслы проще, чем с анализом языка — потому, что критерий неправильности легко задается в условии. Например, почему ИИ проходит легко платформеры: потому, что если персонаж теряет здоровье или умер это ошибка, и такие ошибки быстро и АВТОМАТИЧЕСКИ накапливаются в сети. Также и с автопилотом: если съехал с дороги это ошибка, если крен камеры — это съехал, если рывок — столкновение, это ошибка.
Теперь берем анализ текста: у нас 2 текста, один это агитация (предвыборная) другой это просто новость СМИ про политику. Составить базы данных классов текстов для обучения нейросети может ТОЛЬКО человек, т.к. не существует способов легко и автоматически получать ошибку. Только физически прочитав текст человек определяет, что это агитация. Вот почему много сложных задач еще не решено: фейковые новости, сарказм и многие другие вещи ИИ не может понять.ilansk
08.04.2017 09:48фейковые новости, сарказм и многие другие вещи порою человеческий ЕИ не может понять!
EvilGenius18
Было бы лучше воздержаться от бездоказательных спекуляций типа:
Эта гипотеза не может быть подтверждена, поскольку невозможно доказать отрицательное утверждение, следовательно это возможно, и тот факт, что вы не можете себе представить подобный интелект, не делает это менее вероятным событием
StormEagle
Дело в том, что наиболее полным источником знаний человечества по праву считаются книги. И они были оцифрованы одними из первых с наступлением цифровой эпохи. См, к примеру Библиотека Конгресса. Согласно вики, к концу 1900-х годов было оцифровано 10% от нее, или около 1 млн книг. Представьте, что вы помнили бы содержимое миллиона книг? Не только художественных, но и всех справочников, учебников, научных работ. Каким интеллектом вы обладали бы. Помнили не как ссылки в интернете, а весь контекст.
Этот умозрительный мысленный эксперимент показывает, что в книгах более чем достаточно знаний, чтобы на их базе быть интеллектуально развитым. Также текст сам по себе является относительно простым для обработки на компьютере. Но за прошедшие десятилетия не было создано на основе книг ничего настолько похожего к человеческим способностям, что демонстрируют глубокие нейросети. Нет алгоритма, способного после обучения по книгам, отличить на фотографии кошку от собаки. Хотя их отличия и внешность прекрасно описаны в книгах (в биологических и ветеринарных справочниках, например).
Отсюда и вывод, что раз до сих пор не было ничего создано на таком благодатном материале, то вряд ли будет создано и в будущем. Возможно, дело в каких-то фундаментальных причинах.
С другой стороны, то сложное когнитивное поведение, которое в некоторых областях демонстрирует математический аппарат нейронных сетей, довольно близко к нашему. Поэтому есть шанс, что с таким подходом в этот раз получится. Но пока существующие нейросети не имеют привязки к трехмерной форме объектов в реальном физическом мире, чем в корне отличаются от нас, от нашего мышления.
EvilGenius18
Вы говорите:
Вы совершаете несколько логических ошибок в данном мысленном эксперименте.
Если мы чего-то не смогли достичь на данный момент, абсолютно не значит, что это маловероятно, невозможно, или вряд ли будет достигнуто, как вы утверждаете.
Эйнштейн полагал, что мы никогда не сможем зарегистриовать гравитационные волны, поскольку для этого потребовалась бы невообразимая точность измерения.
Менее, чем через 100 лет, после предсказания этого эффекта теорией относительности, мы зарегистрировали гравитационные волны, измерив колебания величиной в 1/6000 диаметра протона
StormEagle
Я нигде не утверждал, что никогда. Я только говорил, что отталкиваясь от существующих предпосылок, можно сделать такой вывод. И привел обоснование на примере книг. Они содержат невероятное количество знаний об окружающем мире, были давно оцифрованы, занимают мало памяти, хорошо поддаются обработке на компьютере (никаких мощных чипов с аппаратной поддержкой 4к видео для этого не нужно, обработка текста была доступна с первых же ЭВМ). Но это не помогло сделать даже простого чат-бота. Нейронные сети сейчас выдают более реалистичный текст в диалогах.
Prog23
«Я только говорил, что отталкиваясь от существующих предпосылок, можно сделать такой вывод.»
Вы издеваетесь?
Вам же написали:
«Вы совершаете несколько логических ошибок...»
т.е. «сделать такой вывод» можно только совершая логические ошибки…
Проще говоря: Ваш вывод ошибочен — он совершенно не следует из приведенных Вами фактов.
Лично я дочитал только до
«Оказалось, что при числе объектов в сцене более пяти, вручную описать все их возможные физические взаимодействия очень сложно. А при числе более десяти, уже не представляется возможным.»
И мне стало ясно, что читать дальше — совершенно бессмысленно — Вы не в теме.
Доктор наук, профессор МехМата МГУ кафедра МАТИС
тема докторской «Автоматический решатель задач»
http://intsys.msu.ru/staff/podkolzin/
внизу есть список работ профессора — начинается с «Компьютерное моделирование логических процессов» в 5-ти томах. В них профессор рассказывает «устройство» решателя…
Обучать можно и экспертные системы, основанные на «алгоритмическом пути» (на фактах и правилах — ведь есть исчисление предикатов второго порядка...;))
Соглашусь, обучение нейронных сетей идет быстрее (подобрать весовые коэффициенты проще).
Но вот простой вопрос:
— Вы (и особенно Ваша жена — если есть) готовы, чтобы Вашего ребенка лечил робот, который «не знает» почему он назначил подобное лечение?
…
Будущее — за «алгоритмическим путем»…
MarazmDed
И? Это все, конечно, здорово, но автоматические решатели задач известны уже около 60 лет, а практическая полезность оных около нуля.
Будущее — за будущим. Вы же не ясновидящий? Сейчас очевидные успехи за теорвером (нейросети). Кто и что откроет в будущем правильно никто не предскажет, а не правильно — не имеет смысла.
0xd34df00d
Нейросети очень эмпирические. Есть куда более формальные методы, основанные на теорвере.
MarazmDed
Как это ни странно, но нейросети как раз и основаны на теорвере :)
А Вы скорее всего имеете ввиду решающую процедуру Байеса — голый теорвер. Собственно, нейросети и процедура Байеса — примерно одно и тоже.
0xd34df00d
Да не только. Есть вероятностная постановка SVM, например (с несобственными распределениями), то же решающее дерево можно строить через кросс-энтропию, и так далее.
А как выглядит вероятностная формулировка нейросетей? Backprop не выглядит очень уж вероятностно-обоснованным методом, просто чистые методы оптимизации.
MarazmDed
Веса имеют смысл вероятности. Результат работы нейросети — это тоже вероятность. Ну а если развернуть нейросеть в выражение, то будет очень похоже, на процедуру Байеса.
Вообще весь ИИ — это всего лишь методы оптимизации.
0xd34df00d
Веса имеют смысл вероятности чего?
Результат работы нейросети зависит от функции в последнем слое.
Методы оптимизации — это да. Но теорвер отдельно, оптимизация — отдельно. Тот же SVM с его математическим изяществом можно сформулировать как задачу оптимизации без единого теорвера.
MarazmDed
Смысл вероятности праивльного распознавания
Т.е. промежуточные слои можно безболезненно выкинуть? Это не так. Каждый нейрон участвует в построении правильного ответа.
То, что можно выкинуть, ничего не говорит о том, что теорвер там не появляется.
Prog23
Я и не говорил, что профессор Подколзин — единственный кто занимается автоматическими (универсальными) решателями, так?
А вот это утверждение — голословное введение в заблуждение:
— в 1С — обработка «Универсальная загрузка\выгрузка» — по сути — автоматический решатель <очень узких> математических задач.
— формирование СБИС — современный ГПУ имеет более 15 млрд. транзисторов — считаете для него люди «ручками» шаблон рисовали?
— практически по любому (за редким исключением) направлению за нейро-сетями идут системы на основе фактов-правил. Не идут только там, где не нужно знать почему именно так — например, управление светофорами — не принципиально знать «почему именно так» нужно управлять светофорами на этом перекрестке, а на другом — чуть иначе — пробок стало меньше и хорошо.
Вы путаете PR и «очевидные успехи» — дело в том, что пи-арить нейро-сети действительно оказалось легко. «Мы применили нейроСеть» и все уже ВАУ!!!
А вот мышление множествами или исчисление предикатов первого порядка — все «БРРР...»
Не так ли?
А между прочим, введение в исчисление предикатов первого порядка можно начинать после изучения предложений «Маша ела кашу» и «Мама мыла раму»
Выводим слова, обозначающие действие (глаголы — но в первом классе дети этого еще не знают)
(Дети, сегодня наш корабль отправляется на луну) мы создаем НОВЫЙ язык: «Ела Маша кашу» и «Мыла Мама раму».
Осталось только заключить второе и третье слова в скобки Ела(Маша, каша) и Мыла(Мама, рама) и мы получили предикаты первого порядка с арностью два (бинарные).
Можно продолжить...)))
MarazmDed
Не говорили, но прозвучало, как откровение :) Не суть, на самом деле. В научной среде необычайно много тем для исследования. Далеко не все получили практический выхлоп.
Может быть и введение в заблуждение, но с
попробую не согласиться. Ничего особо умного в этой обработке нет. Автоматического доказательства теорем — тем более. Есть строгий детерминированный алгоритм, по которому выборка данных сериализуется в XML и обратно и ничего более.
Если уж приводить пример практического применения автоматического доказательства теорем, то хотя бы в пример оптимизаторы ставить, например, в SQL.
— формирование СБИС — современный ГПУ имеет более 15 млрд. транзисторов — считаете для него люди «ручками» шаблон рисовали?
____
Тут хитрость в том, что люди познали глубокую тайну природы. И осмыслили, что все системы в мире обладают свойством иерархичности ;)
Берете 2 транзистора, рисуете из него некий примитив — триггер, например. Теперь вместо 15 млрд. вам нужно ручками нарисовать всего-лишь 7.5млрд. Берете с десяток триггеров, десяток транзисторов для обвязки и еще несколько сколоченных примитивов и делаете готовый функциональный блок. Считаете — а в нем уже несколько тысяч транзисторов. Лепите на структурную схему несколько десятков функциональных блоков. Ну и т.д.
Очень сомневаюсь, что автоматической решалке доверяют решать схемотехнические решения.
А вот разводка топологии микросхемы — это уже более похоже на интеллект. И там, думаю, автоматическое доказательство применяется, как и куча других интересных вещей, вроде задач раскроя-упаковки.
Это, конечно, красиво звучит. Но хотелось бы практических примеров на основе фактов-правил и увидеть автоматический вывод.
Все же в моем понимании автоматический вывод — это не килотонны условий «если… то… иначе… », а несколько более сложная логика, которая позволяет именно строить вывод, а не брутфорсить его.
Это имеет место быть. Более того, многие начинают грезить, что скоро появится сильный ИИ, с чем я не согласен: все же любая нейросеть — это всего-лишь достаточно сложная аналитическая формула. Нет, я имею ввиду несколько другое. Успехи последних лет, все же вытягивают нейросети на качественно иной уровень (глубокое обучение).
можно-можно… Вот только к автоматическому созданию интеллекта не приводит. Прологу уже сколько лет? Что-то я не наблюдаю, чтобы он широко применялся. Не в последнюю очередь и из-за проблем с автоматическим выводом.
Prog23
Обработка в 1С — это и есть «система» на основе фактов (описание структуры мета-данных) и правил переноса…
В той же обработке 1С разве что «откаты» Пролога находятся в состоянии атавизма...;)))
Если Вы знакомы с устройством головного мозга, то нейро-сети — это аналог лимбической системы — системы, которая «задействуется» при «дрессировке» — на уровень нео-кортекса она никогда не выйдет. Надеюсь, Вы понимаете, что название «Глубокое обучение» — это пи-ар чистой воды...))
А именно благодаря развитию нео-кортекса человек за последние 200-300 тыс. лет смог продвинутся в развитии, чего не наблюдается ни у одного другого вида животных ВООБЩЕ (а не только за несколько миллионов лет развития)
Именно поэтому необязательно быть провидцем — достаточно уметь наблюдать (правда, знания веток высшей математики — теория множеств, исчисление предикатов, построенная на первых двух теория реляционных баз данных — плюс знания по медицине, научной психологии и т.д. — желательны...))
red75prim
Зоны V1, V2 зрительной коры, тоже в лимбическую систему попали? На всякий случай напомню, что зрительная кора это — неокортекс.
Сравнение паттернов активности сверточных сетей и нейронов зоны V2 зрительной коры макаки: http://papers.nips.cc/paper/3313-sparse-deep-belief-net-model-for-visual-area-v2.pdf
Prog23
Согласен. И до какого уровня добрались нейросети в распознавании образов?
?
Вот что на это пишет автор заметки (StormEagle) в одном из своих коментариев:
Мне видится, что проблема вот в чем:
— без знаний по объектам — понимания, что мир состоит из объектов — невозможно не только достичь высоких показателей в распознавании картинки, но и голоса — распознавание речи, ведь также «на сегодня» нет ПП (програмных продуктов), которые на 100% распознают речь. Классический пример распознавания речи фраза «Это же ребенок» (это жеребенок) не может быть распознана однозначно без контекста — понимания из чего состоит окружающий мир.
Согласны?
red75prim
Это, по-моему, и человек не сможет, если имеется в виду ситуация, когда кто-то никогда не видевший кошек и собак читает книгу и сразу начинает уверенно их различать.
Ситуация, когда кто-то видел множество кошек и собак, но не знал как они называются, а потом прочитал книгу, и (возможно) начал их различать, требует экспериментальной проверки. Я не уверен, что смог бы это уверенно делать, если бы кто-то не ткнул бы пальцем и не сказал: "Вот это — кошка, а вот это — собака".
Для ситуации тыкания пальцем (one shot learning) прогресс уже есть: https://arxiv.org/pdf/1605.06065.pdf
Я согласен с тем, что существующие системы, пока способны строить только примитивные модели предметных областей (word2vec, например, отражает некоторые семантические отношения между словами).
Но я не согласен, с тем, что это — непреодолимая преграда. В существующих сетях, например, только начали экспериментировать со структурами аналогичными гиппокампу, реализующими долговременную память. Аналогов мозжечка вообще нет.
Поэтому экстраполировать ограничения существующих сетей даже на 10 лет вперёд — неблагодарная задача. Найти способ реализовать в железе решения используемые мозгом могут в любой момент. К тому же разбиение мира на объекты может быть не чем-то, что придётся программировать вручную, а следствием взаимодействия подсистем, отвечающих за планирование действий (что я могу сделать), зрение (с этой), речь (хреновиной), память ("ковш", "роет", "отвал", а, так это же абзетцер).
Prog23
Вы, ПМСМ, неуверенно представляете себе процесс обучения:
— или Вы самостоятельно находите различительные признаки — и в этом случае, как правило, Вы даете данным животным свои названия — бормоглот и котизавр, например. И в дальнейшем, общаясь с вашими коллегами за рубежом Вы узнаете, что бормоглота они называют Dog, а многими любимого котизавра — cat.
— или Вы читаете в учебнике\на занятии объясняет преподаватель отличительные признаки собак и кошек.
Позвольте донести суть:
— Нет ограничения. Но для того, чтобы строить модели сущностей пионерам нейросетей придется обратиться к Теории реляционных баз данных (которая в свою очередь построена на Теории множеств и исчислении предикатов первого порядка).
Другими словами перейдет в сливание обеих веток ИИ.
Еще раз: в Теории вероятности «просто» нет «механизмов» для описания структур объектных сущностей (там еще потоки и ряд других сущностей) — придется обратится к тем веткам высшей математики, где такие «механизмы» есть.
Согласны?
Вот тут «Вы даже не представляете на сколько Вы близки к правильному ответу» (шутка)). Дело в том, что было бы правильно создать систему, в которой формировалось бы не только ПО («глубокое обучение», «сверхГлубокое обучение», «МегаСуперЭкстраГлубочайшее обучение»...) но и формировалось «правильное» «железо» — вот тогда комплекс был бы полным (а то и самовоспроизводящимся))
MarazmDed
В таком случае можно договориться, что Hello, world — система сильного искуственного интеллекта. :) Еще раз: мало описывать систему в виде фактов. Вы что угодно можете описать в виде фактов (кстати, описание в виде фактов и описание структуры метаданных — разные вещи, никак не связанные между собой). чтобы называться «интеллектуальной», должна быть система вывода. А оной как раз и нет в обработке 1с. Тупо последовательное применение детерминированных правил.
Я бы сказал, сам Пролог находится в состоянии атавизма :) Ну нет пока эффективных процедур вывода.
Безусловно, это чистой воды пиар. И тем не менее, поведение современных нейросетей радикально отличается от сетей десятилетней давности. И да, никакого интеллекта здесь нет. Просто теорвер. Просто качественный.
Есть интересная (хотя и необоснованная) гипотеза, что, даже если мы сможем повторить структуру головного мозга вплоть до нейрона, все равно не получим интеллект. Высказывается мысль, что интеллект может быть проявлением квантовых эффектов.
И не скажу, что я на 100% несогласен с этой мыслью. Искусственная нейросеть — это железобетонно-детерминированная формула. А интеллект, считается, может в идентичных условиях два разных решения выдать.
Prog23
Можно и так утрировать — если бы Вы показали свой ноут\планшет\смартфон на котором Вы смогли вывести «Hello, world» кому-нибудь пару тысяч лет назад — Вы были бы полубогом, сто лет назад — полубогом Вы бы не были, но уровень Энштейна был бы точно.
«Сегодня» боюсь этого будет недостаточно на звание «просто ИИ» — время идет…
Это Вас кто-то ввел в заблуждение: описание двух бинарных предикатов первого порядка описывал выше — а СУРБД это две таблицы (по одной на каждый предикат) с двумя колонками — если арность «три» — три колонки, «четыре» — четыре колонки и т.д.
Посмотрите как ведется учет структуры метаданных в ИБ «Конвертация данных» — все хранится в таблицах.
Тут есть небольшой «уселок» в терминах: МЕТАданными (данными о данных) называются в «простых» ИБ — БП, УТ, ЗУП, КА и т.д.
А в ИБ «Конвертация данных» это уже не МЕТАданные, а «просто» данные — и они-то как раз и являются «фактами», которыми оперируют «правила» переноса.
MarazmDed
Это все понятно, но речь шла про ИИ. И если автоматическое доказательство теорем — относится к ИИ, то обработка 1с — никаким боком.
Я сейчас скажу такую клевую вещь ;): любая реляционная таблица описывает… предикат :) n-й арности. И что? теперь любой софт с БД автоматически относится к ИИ?
Напоминаю: исходный спор начался про то, что обработка 1с не имеет в себе элементов ИИ.
Само по себе ни исчисление высказываний, ни исчисление предикатов не относятся к ИИ. Это всего-лишь раздел математики. ИИ — это, конечно, тоже всего лишь раздел математики, но в нем добавляется интеллектуальность все же. В, частности, в автоматическом доказательстве теорем — самая мякотка в автоматическом выводе.
Представление знаний (база знаний, или, что тоже самое, база фактов) — относится к ИИ. Но для этого придумываются специальные структуры. То, что в итоге они поместятся в реляционные таблицы — дело десятое.
Ну не является банальный цикл искусственным интеллектом. Нет там никакого вывода. Обычная выборка данных путем полного перебора всех ПВД.
Prog23
Это неверное утверждение — рисовать «ручками» нужно все те же 15 млрд. транзисторов.
Шаблонов «на сегодня» (14-16 Нм технология) порядка 30 и нельзя ошибиться какой «выступ» над каким «рисовать» — одна ошибка в одном шаблоне может сделать всю (или большую часть) микросхему не рабочей.
Логические блоки — сколько будет процессоров, сколько кэша и т.д. — действительно придумывает человек. А вот формирование шаблона в 15 млрд. транзисторов — это только программы
Не согласен с терминалогией: «автоматическое доказательство» — это сформированное программным комплексом последовательность выводов, приводящее к однозначности «доказательства» (вывода). Подобные термины к разводке топологии не применяются — однозначность задается количеством логических блоков.
Проще говоря: программе не нужно ничего доказывать. (Отсюда, и «откаты» Пролога нисходят до атавизма)
MarazmDed
Насколько я понимаю, есть несколько видов схем, которые нужно рисовать:
1) принципиальная схема, где есть условные обозначения компонентов и нет понятия длины проводков и угла наклона.
2) топологическая схема, которая как раз и является шаблоном.
Когда я говорил, что рисовать руками нужно гораздо меньше — я имел ввиду именно принципиальную схему.
И там совсем не все миллиарды транзисторов рисуются руками. Берем функциональный блок — он прекрасно разворачивается до транзисторов.
А вот при построении топологической схемы решается несколько задач. Там и раскрой-упаковка и трассировка и, как костыль, автоматический вывод.
В целом сказали одно и тоже, но разными словами :)
А это в общем-то не я в придумал. Терминология устоявшаяся. И сам процесс вывода не важен, важен результат.
когда-то давно я читал, как для разводки топологии применяется вывод на основе правил. Возможно, статья была сугубо теоретическая и на практике не применяется. О чем я и говорю — практическое применение у метода околонулевое.
Доказательство как таковое возникает, когда нужно проверить какую-нибудь гипотезу. Получается доказать — ок. Не получается — не ок.
Prog23
Интересно, а почему Вы не называете «костылем» остальные успехи развития человечества — ведь инет — это «всего лишь» «костыль» — бабушки у подъезда спокойно общаются и без инета… Ведь так?...)))
MarazmDed
Я ни в коей мере не принижаю успехи развития человечества. Достижения в ИИ — это здорово. «Костыль» — это потому что есть задача, не связанная с ИИ вообще никак — задача трассировки. Но поскольку она NP-трудна, то взять ее и просто так решить нельзя. Вот если бы можно было бы — было бы красивое решение для построения топологических схем. Но нет, нельзя. Но жить-то как-то надо, потому придумано обходное решение: топологическая схема упрощается при помощи экспертов, которые создают базу правил. Прикручивается автоматический вывод, который снижает размерность задачи, после чего можно запустить решение задачи трассировки.
Все круто, но база правил здесь — лишнее звено, поскольку базовую задачу нельзя решить в лоб. И это — костыль. Костыль, хотя бы потому что, мы получаем не полноценное, обоснованное решение задачи, а примешиваем субъективный экспертный опыт.
Prog23
Вы, к моему глубокому сожалению, очень плохо представляете себе, что такое «задача связанная с ИИ»…
Тут, возможно, есть доля того, что нет четкой — читай жесткой — всеми приемлемой формулировки: Что есть ИИ?
Тогда давайте «танцевать от печки»: предложите Вашу формулировку ИИ, плз
MarazmDed
Facepalm… Вы невнимательно читаете. Я же даже название привел. Задача трассировки. Есть четкая формулировка. Есть алгоритм решения… Одна беда у алгоритма. Он экспоненциальный. Был бы полиномиальным — было бы круто. Запрограммировали бы его и без всяких ухищрений получили топологию. А вот дальше ПРИХОДИТСЯ прикручивать ИИ, чтобы получить ЭВРИСТИЧЕСКОЕ, ДОПУСТИМОЕ (а не точное, как было бы без всяких ИИ) плохонькое решение. Что и является костылем.
ИИ — это раздел математики, связанный с решением задач принятия решений в условиях неопределенности.
Обращаю внимание: в автоматическом выводе неопределенности есть. В задаче трассировки — нет.
red75prim
Если P!=NP, то это плохонькое эвристическое решение — единственное, что мы можем получить. Называть "костылём" то, без чего никак, ни в каких случаях нельзя обойтись, как-то не соответствует обычному представлению о "костыле", как о хреновине, которую пришлось прилепить, потому что не хватает времени/мозгов сделать правильно.
MarazmDed
Это так
Если обратить внимание на вторую половину фразы, а потом на то, что я написал, то это как раз соответствует костылю :) Качественному костылю, наукоемкому, необходимому, но костылю. И печально, что без костыля обойтись принципиально нельзя.
red75prim
Ну как же нет? Решить задачу трассировки в общем виде за приемлемое время невозможно (P!=NP, и мало кто в этом сомневается). Значит нужно или использовать приближенные решения (оставим их пока в стороне) или находить какие-нибудь особенности в конкретной поставленной задаче, позволяющие свести её к задаче меньшего класса сложности. Есть в конкретной задачи такие особенности или нет — заранее неизвестно.
MarazmDed
Ну так ведь как раз к процессу решения задачи и можно применить понятие «ИИ». Сама задача — обычная задача (просто сложная), а вот в процессе решения применяем методы ИИ. Все молодцы, все круто.
phaggi
На всякий случай замечу, что профессор А.С. Подколзин по ссылке числится академиком «АТН РФ».
Давайте посмотрим на эту академию.
Вот как выглядят около половины президиума правления этой чудесной академии:
Другие также хороши:
Судя по всему, эта академия — такие зубры, что проблемы на уровне создания сильного ИИ щёлкают как орешки между завтраком и обедом, и не решили собственно её походя только потому, что совестливы и не хотят отбирать хлеб учёных попроще.
Prog23
У Вас есть претензии к научным работам профессора МехМата МГУ А.С. Подколзину?
Вы нашли ошибку\неточности в его работах?
О чем Ваш пост?
phaggi
Это пост восхищения плеядой Ученых Академии и ещё пост — дань уважения профессору, несомненно достойному среди достойных. Наука в надёжных руках. Я радуюсь и не могу сдержать радость. Делюсь с вами. Простите, если что не так.
Prog23
А на данной площадке раз ЭТО обсуждается?
MarazmDed
Я не знаю о чем работа академика, но прекрасно знаю, что есть раздел в ИИ, именуемый, «автоматическое доказательство теорем». Этой проблеме около 60 лет. И успехи, собственно, околонулевые. В пределах эпсилон-окрестности нуля.
Prog23
А можно узнать: Откуда такие точные данные в расчете успехов? Можете привести расчеты или хотя бы ссылки?
И это после того, как мы с Вами разобрали два направления, где все работает «на все 100»… «Не в коня корм?» (есть и более жесткие аналоги высказывания...)))
Может нужно разобрать еще десяток, а то и другой-третий?
Что скажите?
MarazmDed
Вам известны эффективные алгоритмы автоматического доказательства теорем? Вы видите каждодневные успехи? Вы можете к куче нерешенных проблем применить автосолвер и вуаля? Увы. На все вопросы ответ «нет». Ну и как называются такие успехи, если не околонулевые?
Вы поймите правильно: я не говорил, что успехов вообще нет. Ограниченные — есть. Но очень уж ограниченные и прогресса особого не видать.
То, что Подколзин показывает решалку по геометрии — это прекрасно. Это результаты 70х годов. Можно поинтересоваться об успехах за 40 лет?
Вот про все 100 — это Вы загнули:
1) 1с — абсолютно никакого отношения не имеет к автоматическому доказательству теорем. Если это для Вас ИИ, то, пожалуй, калькулятор — это полноценный робот с разумом.
2) проектирование микросхем. Там ключевое — база правил. От ее качества и зависит качество проектирования. Качество системы вывода — десятое. И самое главное: да есть сообщения, что применяется. Но роль вывода в решении задачи проектирования под вопросом. Уровень системы вывода — загадка. Возможно там тоже цикл как в 1с — какой это тогда интеллект?
Давай. Приведите с десяток практических примеров, где применяется автоматический вывод. Попробуем ознакомиться и просветиться. Ну или вернуть на грешну землю :)
Prog23
Я знаком с работами профессора и ряда зарубежных работ — некоторые из них можно назвать эффективными.
Позвольте встречный вопрос: А Вы знаете облать фундаментальной науки, в которой КАЖДЫЙ ДЕНЬ доказывают теоремы?
— Да что там фундаментальная наука: Вы видите каждодневные успехи в 1С?
Полагаю, что «Нет».
Тогда почему Вы ждете «каждодневные успехи» от классической (фундомендальной) математической науки?
ПМСМ — это нонсенс. Нет отраслей фундоментальной науки, где можно наблюдать КАЖДОДНЕВНЫЕ успехи… Согласны?
Этот вопрос мне не понятен — можете пояснить?
Не правда — т.е. Ложь.
ПРИМЕР:
«Вы уже перестали пить коньяк по утрам?»
— «Да» или «Нет»?
Ответ-те, плз
ОТВЕТ:
— Успех далеко не нулевые.
Прошу:
— приведите пример доказанных теорем за последние 10 — если сложно — 20 лет, прошу.
MarazmDed
Вы не знакомы с теорией сложности. Эффективный алгоритм — это алгоритм, получающий решение за полиномиальное время. Я Вас уверяю, в ИИ таковых попросту нет. Эвристики не в счет, поскольку они ничего не гарантируют.
Иными словами, эффективных алгоритмов автоматического вывода нет. Да и быть не может по определению. Поскольку в процессе вывода главная проблема — неопределенности. Ну вот так вот. Вместо неопределенности можно подставить любой предикат. И можно мгновенно получить доказательство, а можно и вовсе не получить. Но это фигня. Главное: нет однозначности. Какое бы решение ни было предложено — оно будет костылем.
Ну право, как жидко… :) Я таким образом спрашивал о практических внедрениях, которые после внедрения должны использоваться как раз каждый день. Ну да бог с ним. Вы просто внедрения приведите.
Не правильно полагаете. Если речь о развитии 1с, то я вижу ну как минимум ежегодный прогресс. Но я спрашивал о другом: о внедрениях. Так вот с 1с я вижу каждодневные успехи.
Не нравится вопрос о внедрениях — там был скромный вопрос об общих успехах за последние 40 лет. Так понимаю, что вопрос не понравился? :)
Я могу, в рамках своей компетенции, назвать две работы: 1) Это хвостовая рекурсия (основано на правиле MP) 2) к этому алгоритму эвристика раскрытия неопределенностей. В чем прелесть — алгоритм сумел доказать модельные высказывания. Но это все же околонулевые успехи, а не прорыв.
Известен прорыв? С радостью ликвидирую собственное незнание. Просвещайте.
Ну а для чего нужно автоматическое доказательство теорем? Для автоматического доказательства теорем. Сколько нерешенных проблем такие решалки смогли доказать? Ответ: 0.
Вот вам и показатель успехов в этой области.
Либо приведите конкретные из вопросов, на которые не получается ответить в виде да-нет, либо признайте уже наконец, авторешалки — чисто исследовательская штука, которой далеко до применений.
Без пруфов это звучит неубедительно и голословно.
— приведите пример доказанных теорем за последние 10 — если сложно — 20 лет, прошу.
___
Теорема Перельмана, Великая теорема Ферма.
Это из глобальных. Из теорем попроще: No Free Lunch. И это только то, что на слуху. А если почитать журналов, то там можно найти сотни теорем из разных областей.
DaneSoul
Вы путаете память и интеллект. База данных, как и книга сами по себе интеллектом не обладают.
Помнить все книги — это иметь всю память человечества, но к интеллекту это никак не относится.
Интеллект — это способность находить в этих данных не известные ранее зависимости, строить на их базе умозаключения и иным образом ими оперировать, создавая ПРОИЗВОДНОЕ от них НОВОЕ знание.
StormEagle
Простите, но более начитанный (особенно технической литературой) человек обычно обладает более развитым интеллектом и более развитым логическим мышлением. Каковы бы ни были правила, по которым функционирует интеллект, размер базы для него играет огромное значение. Надо же этому разуму чем-то оперировать. Интеллект и размер его памяти, похоже, очень тесто связаны.
Об этом говорит и разница в несколько порядков в количестве терминов, которыми может оперировать человек (порядка миллиона) по сравнению с самыми умными животными (собаки, обезьяны, попугаи — в лучшем случае пара сотен слов/понятий). Это факт, от которого сложно отмахнуться.
DaneSoul
Память — способность хранить и воспроизводить информацию.
Интеллект — способность информацией эффективно манипулировать.
Обе способности сами по-себе мало что дают, а вот в сочетании уже позволяют человеку заниматься наукой, например.
Если уж говорить о живых примерах, то в ВУЗе знал не мало "зубрилок", которые имели хорошую память и получали хорошие оценки, если было достаточно пересказать учебник, но впадали в ступор, если нужно было информацию анализировать и мыслить не шаблонно.
Поразила меня девушка, которая получила самоэкзамен по математике по итогам контрольных (они все были из одной известной методички), просто ВЫУЧИВ решения задач, которые ей сделал друг, не понимая сути решения...
StormEagle
Давайте сначала договоримся, что ВСЕ люди разумны =). Поэтому не будем сравнивать девушек с другими представителями homo sapiens (хотя описанная вам разница это отличный повод пообсуждать нюансы проявления интеллекта).
Но, кажется, вы сейчас попали в классическую ловушку с определением интеллекта. Что значит способность эффективно манипулировать информацией? Это философское определение. А компьютер эффективно манипулирует формацией на жестком диске? Но ведь он явно не Интеллект в интересующем нас контексте. Мы сейчас будем долго петлять, но так и не придем к однозначному определению. Увы, но такова жестокая реальность. Есть некое чувственное образное понимание что такое Интеллект (и я прекрасно понимаю, что вы хотите сказать), но нет нормального определения этому.
То есть никто не может сказать, что конкретно нужно сделать, какой алгоритм написать, чтобы «эффективно манипулировать информацией» и быть Интеллектом.
Поэтому приходится анализировать разум косвенными методами. Компьютер может распознать такой же процент дорожных знаков на картинках, как человек? Хорошо, значит по этому критерию наши способности равны. А может ли компьютер отличить леопарда от дивана с леопардовой расцветкой? Ах нет, значит тут отстает.
Когда накопится достаточное количество таких областей, в которых мы равны, то поведение/мышление компьютера будет неотличимо от нашего, и от станет сильным ИИ. Это будет не просто перечисление, эти области с каждым разом становятся все сложнее. Сейчас компьютер дает эмоциональную окраску блоку текста (и хотя часто ошибается и его легко обмануть, но в целом, делает это аналогично нам). Завтра он сможет предсказать, куда побежит человек на видео, когда его атакует медведь. А там и до теоремы пифагора недалеко, ведь ему будет нужно всего лишь написать (предсказать), что делают объекты «гипотенуза» и «катеты». Не так уж сложно, по сравнению с человеком и медведем.
DaneSoul
Не, я ни в коем разе не сексист, так как приходилось общаться с очень умными и очень глупыми людьми обеих полов. Я не акцентировал внимание на моем примере, что это была девушка, просто так совпало. Кстати, про свои "успехи" в математике она рассказывала сама, лично :-)
Посмотрите на задания тестов IQ, например. Вот там как раз довольно четко выделены разные интеллектуальные операции и дается попытка их количественной оценки.
При этом, оценка обобщенного понятия интеллекта может быть спорной, а вот способности к тем или иным интеллектуальным операциям (нахождение сходства, отличий, умение пространственно оперировать фигурами, математические закономерности и т.п.) этими задачами вполне оценивается.
А с этим я не спорил, я с этим согласен.
Но важней не то, сколько данных мы загрузим, а то, какие способы их анализа будут доступны ИИ, как он сможет данные обрабатывать — вот именно этим и будет определятся интеллектуальность системы.
StormEagle
Но ведь нет способа это оценить количественно? Под эти определения попадут явно неразумные вещи.
Если говорим о тестах IQ, то это просто картинки и надо выбрать правильный ответ. Я уверен, что при большой выборке, можно обучить нейросеть давать правильные ответы. И такие примеры есть, это действительно работает, можно погуглить. Хотя пока они его в целом проваливают, но на часть «человеческих» вопросов отвечают правильно.
В этих тестах нейросеть, по вашим словам, будет проявлять все признаки интеллекта — обобщение, отличия и т.д… Предположим, что ее результат в тестах будет неотличим от результатов человека. Я к тому, что всеми этими признаками мы сами наделяем интеллект в попытке понять, что это такое. Но они вовсе не являются критерием разумности. Таким критерием является только похожесть на наше собственное поведение.
Конкретно в этом случае мы всегда можем сказать, что это результат зубрежки и интерполяции/аппроксимации (хотя мы сами обучаемся точно так же!). И дадим ей примеры, не участвующие в обучающей выборке. И если нейросеть решит их правильно, то будем вынуждены признать, что она обладает всеми этим признаками, которые мы приписывали разумности.
Но все равно не признаем ее разумной, верно же? =) А почему? Потому что потребуем, чтобы она могла разговаривать и объяснила, почему сделала такой выбор, а не другой. В общем, чтобы стала еще более похожей на нас. В какой-то момент, когда станет очень уж похожей, сможет разговаривать и общаться как человек, придется признать ее разумность. Так что критерий только один — тест Тьюринга, других похоже просто нет.
p.s. если не разговаривать голосом, то любым другим способом доносить мысли, аналогичные человеческому разговору. иначе мы будем считать ее сколь угодно сложной системой, но никогда не будем считать разумной.
zirix
Если система идеально отвечает на вопросы, то это не значит что она разумна. Системе просто повезло что она знала/просчитала ответы на все заданные вопросы.
Рано или поздно(на первом же вопросе специалиста) система даст неадекватный ответ и будет видно что «разума» у нее нет.
Почитайте: Китайская комната
Для признания системы разумной надо убедится что у системы есть мышление и ее ответы осмысленны.
StormEagle
И как вы предлагаете в этом убедиться?
zirix
Задам ей вопрос из Winograd schemas.
Если вдруг система даст правильный ответ, найдя его в интернете, я придумаю свой вопрос.
Если нейронная сеть провалит этот тест(а она провалит), то у нее не только мышления нет, она вообще не понимает того что ей говоришь.
StormEagle
Это ведь можно считать разновидностью теста Тьюринга. Но подход правильный — задавать такие вопросы, которые охватывают максимальное разнообразие возможных взаимоотношений между понятиями. В статье это названо как необходимость иметь знания о предмете, чтобы ответить на вопрос. О том, что это за предмет, как он соотносится с другими предметами и т.д…
Недостатком этого подхода кажется то, что он очень уж ориентирован на существующие алгоритмы ИИ. Вроде использования в одном предложении похожих слов, но имеющих разный смысл, чтобы нельзя было подобрать ответ статистически. А значит, раз есть некоторые предпочтения в составлении вопросов, то можно именно на них сосредоточиться при разработке бота, и тем самым обмануть систему.
Заметьте, что тест Винограда, в широком смысле, является обычным разговором с ИИ. Просто с акцентом на вещах, где современные чат-системы допускают чаще всего ошибки. Логические, синтаксические и другие.
Текущие, которые обучились на массиве фраз из книг/твитах/постах в жж, провалят. Но которые будут проходить обучение классификации в привязке к физическому миру (что чемодан не просто номер «12» в списке классов, а что это трехмерный объект такого-то размера и такой-то массы), уже не факт. Многие вопросы в схеме Винограда об устройстве окружающего мира такая нейросеть пройдет. И это вопрос пары лет, как мне кажется.
Останутся вопросы чувств, взаимоотношений между людьми и т.д… Но это ничем принципиально не отличается от классификации чемоданов. А математика и логика тоже имеют представление в материальном мире. Арифметику можно представить на палочках (сложение, вычитание). Поэтому они тоже будут доступны такой нейросети. Мы ведь учились аналогичным образом: «На ветке сидело три птички, а потом одна улетела. Сколько осталось?» Мы представляли этих птичек как материальные 3d объекты и считали, показывая в своем воображении на них пальцем.
StormEagle
Получается, что если человек правильно ответил на вопрос, то ему тоже повезло, что он знал/просчитал ответ. А если не знает ответа, то неразумный? ))
Нет, так не пойдет. Не получается дать однозначного определения что такое разум или интеллект. Хотя все интуитивно понимают что это, но в словах выразить не получается.
P.S. Насчет китайской комнаты, то конечно же, я знаком с этой концепцией. Но хочу обратить ваше внимание на первую же строчку из вики: «мысленный эксперимент в области философии сознания и философии искусственного интеллекта». Философии, Карл! Я не готов обсуждать философские определения разума, так как они не конструктивны. Философия сыграла значительную роль в начале пути разумного человека, но уже давно уступила научному методу как способу познания окружающего мира.
telobezumnoe
на пример интеллектом можно считать возможность правильно прогнозировать будущее, развитие системы, из имеющихся данных, с построением моделей, нахождения причин и следствий, взаимосвязи на основе имеющегося опыта или информации. чьи прогнозы более точны и учитывают больший объем данных, тот по сути и интеллектуальнее
StormEagle
Это делает простой график экстраполяции в Excel.
С этим отлично справляется метод кроссэнтропии (не причин и следствий, правда, но поиск неизвестных корреляций).
Это вообще непонятное требование, мой компьютер прекрасно использует свой предыдущий опыт и информацию, сохраненные в памяти, чтобы строить модели, прогнозировать ветвление на уровне процессорных команд, и тому подобное.
Но ведь и случайное подбрасывание монеток в какие-то моменты будет давать точность прогноза больше 50%, но это не делает этот метод интеллектуальным.
Так можно продолжать до бесконечности, это действительно старый спор. Что считать живым и/или разумным. Нет на него исчерпывающего ответа… Лучшее что мы имеем — это степень похожести в поведении на нас самих, различные вариации теста Тьюринга.
Ckpyt
Еще одна логическая ошибка. Люди разумны. Но!!! НЕ ВСЕГДА!!!
Я определяю интеллект как способность создавать алгоритмы и давать им описания, понятные другим.
А теперь прикол: люди склонны повторять тот алгоритм, который в прошлый раз сработал. Особенно, если условия изменились незначительно или неразличимо с т.з. человека.
Эта особенность человеческого интеллекта и приводит к многочисленным анекдотам про блондинок.
И вот тут — то мы и приходим к проблеме нейросетей: ИИ на основе нейросетей будет страдать таким же дефектом разума.
MegaVaD
> люди склонны повторять тот алгоритм, который в прошлый раз сработал. Особенно, если условия изменились незначительно или неразличимо с т.з. человека.
Когда работаешь с чем-то, сродни чёрному ящику, так оно и есть. Проблема в том, что когда мы не можем получить полные данные, или когда их получение дольше, чем безопасные «эксперименты», этот вариант приемлем. Где-то на границе начинается «блондинка». Всё от недостатка информации (базы для анализа и принятия решения). Хуже только бездействие.
pzhivulin
Читал недавно про двухпалатный ум. Зубрилы — это один из представителей
Ckpyt
Вы делаете логическую ошибку.
Что означает более начитанный человек? Задумайтесь над этим понятием. Дело ведь не в памяти, и не в способности процитировать, скажем, весь стандарт с++. Дело в том, чтобы найти кусок из этого стандарта, подходящий к данному, текущему случаю.
Т.е. осознать и понять прочитанное, а не просто запомнить. А теперь, внимание, вопрос: способен ли Watson осознать прочитанное?
StormEagle
Верно. Но ключевое слово «подходящий». Что значит подходящий к данному случаю? Опишите алгоритм, как определить подходящий кусок к случаю. Опишите так, чтобы это можно было реализовать в виде компьютерной программы.
Как легко убедиться, это сделать не удастся. Вот поэтому искусственный интеллект до сих пор не создан. Смысл и контекст это тоже вещи, не имеющие нормального определения.
Но мы можем анализировать ситуацию. Как это происходит? Мы помним, что такая-то тема описана по такой-то ссылке в википедии. Когда мы переходим по ссылке, мы как бы заново изучаем материал, читаем и вникаем в его смысл (как мы это делаем — неизвестно. это таинственный процесс, хотя физически заключающийся в настройке весов нейронной сети мозга, аналогичное обучению искусственной нейросети).
Начитанный грамотный человек отличается тем, что он больше помнит таких готовых контекстов. Как будто он перед ответом вам уже прочитал соответствующую статью. Поэтому у него преимущество. Фактически, это вопрос быстродействия. Если у вас перед ответом будет время полазить по ссылкам и изучить темы, вы сможете спорить со сколь угодно умным человеком, т.е. будете обладать сколь угодно большим интеллектом (другое дело, что на изучение некоторых тем нужны годы). А начитанный человек (даже если просто помнит куски текста) дает ответ сразу. И это дает нам подсказку о том, с чем, кроме всего прочего, связана сила интеллекта.
Если будет создан искусственный интеллект, то он не будет иметь таких ограничений в памяти, как мы. На любой вопрос он даст ответ, как будто перед этим прочитал все книги человечества. Представляете, насколько сильным будет такой ИИ? И какие у него будут возможности в свободных размышлениях, используя все эти знания. Здесь предполагается, что он уже умеет находить «подходящие» куски текста из запомненного. А иначе это никакой не ИИ.
«Осознать», «понять» — неизвестно, что это такое. На данный момент нейронные сети дают наиболее близкое к нам поведение по этим вопросам.
Нет, Watson не способен осознать прочитанное. Как я это определил? Он совсем не похож на человека в разговоре.
Prog23
Прошу прощения, что вмешиваюсь, но уже не первый раз ловлю себя на мысли, что иногда Вы «забываете», что программы бывают императивными и декларативными.
И программы для ИИ частенько относятся к декларативным — об алгоритмах декларативных программ неприлично даже заикаться…
Отсюда Ваша ошибка в статье — Пролог не относится к «алгоритмическому пути» — это нонсес.
saboteur_kiev
«Простите, но более начитанный (особенно технической литературой) человек обычно обладает более развитым интеллектом и более развитым логическим мышлением.»
Простите, но в мире полно примеров, когда начитанный ботан не способен даже банально выжить в городских условиях, приготовить себе поесть и логично вывести причину, почему на него не смотрят девчонки. Чисто начитанность — не главное. Умение мыслить адекватно, правильно расставляя приоритеты — важнее. Так и с ИИ — наличие в памяти кучи фактов не делает библиотеку ЛибРуСек сильным искусственным интеллектом.
StormEagle
Волк в лесу прекрасно справляется с проблемой выживания и поиска еды, а также с привлечением самок. Но это не делает его разумным. И почему вы думаете, что ботаники не понимают, почему на них не смотрят девчонки? Значит глупые ботаники. Умные прекрасно все понимают.
«Смотря что вы считаете жизнью» )). Мне вот кажется, что в способности мыслить адекватно человек с техническим образованием даст сто очков вперед какому-нибудь, без сомнения очень приспособленному к своей среде (например, криминальной) человеку. Или хитрому туземцу-шаману, паразитирующему на безграмотности своих сограждан.
Впрочем, трудности и разнообразие делают человека умнее. Так что в некотором роде вы правы, какой-нибудь от природы изворотливый и сообразительный тип, не прочитавший ни одной книги в жизни, вполне может обладать развитым живым умом.
Но это скорее исключение. Ведь начитанность/образование это по сути запоминание разнообразных фактов. Что тренирует память, а математика и программировании так вообще чрезвычайно полезны для развития абстрактного и логического мышления. Такие люди с бОльшей вероятностью будут обладать развитым умом. Неужели вы никогда не сталкивались, что собеседник никак не может понять принцип, например, критерия фальсифицируемости? Это чисто логический прием, крайне полезный в жизни. Но многие люди просто не в состоянии его осилить. И по моему опыту, это как раз те, у кого логическая и критическая часть слабо развиты. Хотя в бытовом приспособленческом смысле они весьма успешны, поэтому назвать их глупыми никак нельзя (я называю, но мне можно =)) шучу, просто это удручает).
0xd34df00d
А у меня до сих пор нет конструктивного подходящего под ограничения ответа на вопрос «почему не смотрят», пойду записываться в глупые :(
StormEagle
Начать стоит с того момента, как две клетки впервые перешли от бесполого размножения к половому. Какие это дало преимущества и какие имеет недостатки. Все остальное лишь следствия… Для общего развития можно почитать Протопопова «Трактат о любви». Это не исчерпывающий и не обязательно верный ответ, но дает хорошую пищу для последующих размышлений.
Пока люди не перейдут к полностью абстрактному мышлению, не привязанному к физиологии и инстинктам, такая ситуация будет продолжаться.
0xd34df00d
Я этого Протопопова в своё время читал, но конструктивные выводы, опять же, сделать не смог.
saboteur_kiev
«Волк в лесу прекрасно справляется с проблемой выживания и поиска еды, а также с привлечением самок. Но это не делает его разумным.»
Вообще-то все животные разумные. И если бы сейчас можно было запихнуть интеллект волка в компьютер, это был бы самый сильный ИИ из всех, что на текущий момент созданы. Не очень понимаю, почему вы считаете, что у волка нет интеллекта.
> И почему вы думаете, что ботаники не понимают, почему на них не смотрят девчонки? Значит глупые ботаники.
Нет, это значит, что именно «начитанность» не является главным показателем интеллекта, как вы считаете.
StormEagle
Тогда вопрос закрыт, расходимся )
Шутка. Конечно, все животные очень близки к нам по возможностям мозга, но у людей явно есть качественный рывок вперед. И скорее всего, это качественное отличие вызвано количественной разницей. Если бы собака различала 100 тыс. слов, это было бы большое дело. Если при этом она и не стала бы разумной, то была бы почти разумным помощником.
Я так не считаю. Начитанность с большей вероятностью ведет к развитому мозгу, не более того. И то лишь благодаря тренировке/обучению мозга во время чтения, а также быстрому доступу к запомненной информации.
phaggi
Сейчас как раз читаю книгу К.Сагана «Драконы Эдема».
Модель мозга, связь его устройства, его эволюции и его функционирования (в т.ч. разум) — как раз об этом там очень много интересного. Очень рекомендую. Пока треть только книги прочел, но очень, очень познавательно.
saboteur_kiev
Начитанность — полная фигня по отношению к ИИ, базирующемся на эвм. Потому что скорость получения и освоения новой информации условно неограничена, а вот сам алгоритм этого освоения — недоступен.
Если ИИ сможет в принципе воспринимать информацию из книг в виде реального опыта, он сможет «начитаться» очень быстро. Самое же сложное — сам принцип мышления.
ilansk
Возможно вы ошибаетесь. Нельзя опровергнуть разумность волка, по той причине, что он не способен: пройти тест Тьюригна, заучить решение математических задач, написать алгоритм на С++, имитировать поведение человека в интернете,
водить велосипед, разговаривать...Волк, лев, медведь способен обхитрить разумного охотника-человека и сожрать. Животные демонстрируют вполне разумное поведение и имитацию человеческого поведения: поэкспериментируете с вашим котом, он вполне творческая личность.
Знакомый зоолог говорил: Если пнуть собаку, то она не станет после этого боятся всех людей, но будет не доверять пнувшему. Выживаемость бродяжек завит от адекватной классификации людей на опасных, безопасных, и полезных в краткосрочной и долгосрочной перспективе с учетом обстоятельств. Это нетривиальная задача даже для человека.
ilansk
Начитаный=опытный. Чем отличается умный от опытного? Умный легко решит проблемы, в которые опытный больше не попадет.
Cubicmeter
> за прошедшие десятилетия не было создано на основе книг ничего настолько похожего к человеческим способностям, что демонстрируют глубокие нейросети. Нет алгоритма, способного после обучения по книгам, отличить на фотографии кошку от собаки.
В действительности, информацию о многих вещах из повседневной жизни вы вряд ли сможете найти в книгах. Более того, даже то, что в книге описывается, часто находится между строк. Из простейшей фразы вроде «Друг шел к родителям на обед» или «По крыше забарабанил дождь» читатель-человек извлечет уйму информации и построит довольно сложную модель происходящего — при том, что в самой фразе практически ничего нет.
StormEagle
Полностью согласен. Когда эти фразы будут компьютером обрабатываться не как word2vec, а как трехмерные сценки, где трехмерные капли дождя падают на трехмерную крышу, то из этих фраз можно будет извлечь намного больше информации. О взаимосвязи этого дома и шагающего по улице друга. Физический мир — это то, что связывает разные понятия в нашем мышлении.

До этого были попытки извлекать смысл чисто из текста. Но они закончились неудачей. То ли количество внутренних понятий намного больше, чем слов (перефразируя, что смысл находится между строк), то ли алгоритмы были несовершенны.
Но нейросети довольно успешно распознают те же контуры машин и пешеходов в задаче робомобилей:
И это не какое-то раскрашивание одних пикселей на основе других пикселей по алгоритму, внутри нейросети образуется образы этих объектов. Подтверждением тому служит переводчик Google, который смог сносно переводить между двумя языками, на которых он не обучался, но сформировал внутри себя смыслы этих слов.
Такая нейросеть потенциально способна читать между строк в книгах. О чем и речь… И доступно все это стало, когда научились правильно обучать глубокие нейросети. Не сейчас, и не завтра, но в обозримом будущем создание сильного ИИ, скорее всего, станет возможным.
saboteur_kiev
Ничего она потенциально не способна, и никогда способна не будет. Пока в ее алгоритм не введут понятие «столб», она не сможет его распознавать. Вот если ввести, а потом «обучить» на 1000 картинок — тогда она будет распознавать объекто под номером №12438, у которого есть признак №123 (комментарий — неподвижное препятствие", и в водительском алгоритме есть установка — объекты с подобными признаками объезжать.
StormEagle
Это работает не так. Посмотрите видео робота-автомобиля NVidia: https://www.youtube.com/watch?v=-96BEoXJMs0.
Если я правильно понял, там простая видеокамера, картинка с которой подается на вход нейросети. И нейросеть обучают, чтобы на выходе она показывала угол поворота руля. Все. Пока водитель ездит сам, нейросеть обучается (подстраивает свои веса, чтобы пиксели на входе преобразовать в такой угол поворота руля на выходе, который сейчас у живого водителя).
После обучения выход нейросети связывают непосредственно с рулем. И она сама рулит. Сама научилась определять дорогу, полосы, столбы. Там еще говорят, что выехали однажды в новые для нейросети условия, которых не было в обучении (то ли на грунтовку, то ли объезжая строительные конусы). И нейросеть справилась, правильно объехав препятствие. Да это же разумность по 99% существующих теоретических определений интеллекта!
Вот в чем сила нейросетей, в показываемых ими результатах. Писать такой алгоритм вручную замучаешься. Но, конечно, никто нейросеть не пустит за руль в серийной машине, пока мы не гарантируем, что она не выкинет какой-нибудь фортель.
А гарантировать это может простая статистика. Пусть наездит 100 млн километров и докажет свою надежность. Люди тоже доказывают свою адекватность и надежность статистикой.
Или вот, дрон с нейросетью летит над тропинкой: https://www.youtube.com/watch?v=umRdt3zGgpU
saboteur_kiev
«Там еще говорят, что выехали однажды в новые для нейросети условия, которых не было в обучении (то ли на грунтовку, то ли объезжая строительные конусы). „
Одна бабка сказала?
Посмотрите видео, как можно нарисовать на дороге некорректные полосы, и ничего нейросеть с ними не сделает. У нее есть ограничения ее алгоритма. Все дело исключительно в граничных условиях, которые она определяет самостоятельно. Но алгоритм НЕ меняется.
Нейросети работают именно так — выставляют граничные условия.
Да, алгоритм можно усложнить, делая их динамическими, накладывая к ним известные точки опоры (например ВСЕ автопилоты критически зависят от хорошей заранее составленной картой, от которой они отталкиваются). Автопилот не может поехать по бездорожью, потому что определить где он может проехать а где нет — это уже задача гораздо более высокого порядка.
saboteur_kiev
«Вот в чем сила нейросетей, в показываемых ими результатах. Писать такой алгоритм вручную замучаешься.»
Простите, вы пользовались нейросетями на практике? Я не могу понять, почему вы считаете, что нейросеть придумывает алгоритм?
Алгоритм, который был написан для распознавания котиков, НИКОГДА не научится распознавать повороты на дороге — потому что алгоритм изначально пишет программист.
Обучение современной нейросети — это исключительно автоматизация ранжирования данных, и автоматизация расстановки граничных условий. Сам алгоритм не меняется.
0xd34df00d
Слова про образы объектов внутри нейросети — это слишком сильно, как по мне. Мы пока не очень понимаем, что там внутри происходит, либо сильно отстал от жизни, но тогда не откажусь от ссылок.
А вообще мне ближе всего позиция как с квантмехом — заткнись и считай. Оставим рассуждения про суть ИИ философам и лучше запилим ещё один метод оптимизации.
Cubicmeter
> Когда эти фразы будут компьютером обрабатываться не как word2vec, а как трехмерные сценки, где трехмерные капли дождя падают на трехмерную крышу, то из этих фраз можно будет извлечь намного больше информации
Похоже, что вы все же не поняли меня. Трехмерная сцена не даст новую информацию. Напротив, чтобы воспроизвести такую трехмерную сцену, которая будет сходна с появляющейся в воображении читателя, всё равно необходима уйма дополнительной информации о мире.
Человек знает, что крыша не в вакууме парит. Она предполагает дом. Или же, возможно, это крыша автомобиля. Ясно, что крыша металлическая, потому что другие материалы не дают такого шума. Дождь, скорей всего, предполагает осень или весну, может быть — летнюю ночь. Но точно не зиму. (Это с точки зрения человека, живущего на севере). Описание, наверняка, сделано по ощущениям человека под этой самой крышей, или же возле дома, а не где-то в стороне.
Всё это настолько естественно, что мы даже не замечаем, какую огромную работу проделывает мозг, чтобы понять лишь одну фразу. Но это потому, что человек всю жизнь проводит в физическом мире и всю жизнь читает.
> нейросети довольно успешно распознают те же контуры машин и пешеходов в задаче робомобилей. И это не какое-то раскрашивание одних пикселей на основе других пикселей по алгоритму, внутри нейросети образуется образы этих объектов
Это классификация трехмерных объектов. Чтобы эта классификация была полезной, нужна информация о каждом из классов: что дома неподвижны, что автомобили могут ездить быстро, но обладают инерцией, а пешеходы движутся медленнее, но иногда по произвольным траекториям, и т.д. Сможет ли нейросеть выделить это знание? Или же проще заложить его самим?
> переводчик Google, который смог сносно переводить между двумя языками, на которых он не обучался, но сформировал внутри себя смыслы этих слов
Он не сформировал смыслы. Смыслы — это разносторонние модели объектов. Переводчик не имеет их. Он, возможно, сформировал отношения между всеми словами языка, но не более. А поскольку язык тоже моделирует реальный мир, может показаться, что переводчик обладает неким «пониманием». Но это не так.
red75prim
Можно точно сказать, что заложить самим не проще. Сайк ( https://ru.wikipedia.org/wiki/Cyc ) уже 33 года пилят, с сомнительным успехом.
StormEagle
Но дополнительную информацию об окружающем мире мы получаем именно из его трехмерности. О чем вы дальше и пишите.
Имелось ввиду, что для сильного ИИ нужно не просто распознать классы на картинке (и не только воссоздать трехмерную сценку по картинке), а что этот ИИ должен быть сначала предобучен на реальном физическом трехмерном мире. В настоящем или в виртуальном симуляторе. После этого он из картинки (или текстового предложения) воссоздает 3d сценку и весь контекст, в котором происходит действие.
Но после предобучения в 3д симуляторе мира, что как бы аналогично уровню животного, прекрасно ориентирующегося в пространстве, ИИ еще должен будет пройти обучение всем абстрактным вещам, описанным в книгах и учениках. Все как у людей, в общем.
Только тогда он станет сильным. А когда с уровнем интеллекта как у человека, воспользуется бОльшей производительностью (памятью, тактовой частотой), и освоит все знания человечества, тогда станет супер-сильным ИИ. Станет настоящим ИИ, как его показывают в фильмах.
На самом деле, эта идея перекликается у многих, и даже здесь такой подход несколько раз упоминался. Раз не получилось описать интеллект вручную, то можно попробовать повторить путь развития биологического интеллекта.
ilansk
Как раз таки лучше дополнить нейросеть теми знаниями, которым она сама не может обучиться.
Juralis
Во всей библиотеке конгресса содержится меньше знаний, чем у любого ребёнка самого примитивного аборигена. Попробуйте написать в тексте полную инструкцию о том, чтобы тривиально пошевелить пальцем. Объём книг кажется внушительным только по причине высокой сложности освоения такого объёма, а не по причине того, что это какой-то очень уж большой объём знаний.
StormEagle
Мы же говорим об Искусственном Интеллекте, а не о создании нового живого организма. Нет причин считать, что факт биологического происхождения автоматически ведет к разумности. Все животные имеют примерно одинаковую физиологию, но только люди стали разумными.
То, что развитие биологической жизни неизбежно ведет к появлению разума — это вполне может быть, так как разумность дает резкое эволюционное преимущество.
Но знания как шевелить пальцем точно не являются показанием интеллекта. Да и описать абстрактно в книге это тоже можно: «согните палец до упора, потом разогните». Для разумного существа вполне достаточное описание этого знания. Знания как правильно делать неприличный жест, например. Книги хороший источник абстрактных знаний, что и подразумевается под развитым интеллектом.
Это да, и я тоже об этом говорил. Слова это часто крупные обобщения. Да и не факт, что письменные тексты содержат исчерпывающую информацию о себе и окружающем мире, чтобы не требовались внешние источники информации. У нас есть хорошее подспорье — понимание трехмерного пространства. Это кажется даже более важным для первоначального обучения. А уже потом книги.
Cubicmeter
> У нас есть хорошее подспорье — понимание трехмерного пространства. Это кажется даже более важным для первоначального обучения.
Я согласен с тем, что отношения между объектами в трехмерном пространстве — это, во-первых, одна из самых первых вещей, которые учится усваивать ребенок. И, во-вторых — это база для понимания отношений между абстрактными концепциями путем аналогии (абстрактные концепции «входят» друг в друга, ветвятся как дерево и т.д.). Это действительно очень важный момент.
Но тут, пожалуй, упор не на «распознавании трехмерной формы объектов», а на распознавании отношений между ними. Можно, конечно, по краю объекта, который видно лишь частично, понять, что это за объект. Но еще важнее понять, что он чем-то заслонен.
StormEagle
Согласен. Нейронные сети это готовый математический аппарат для поиска таких взаимоотношений. Хорошо бы применить более формализованные методы машинного обучения для этого (и я уверен, они будут применены, о чем и писал в статье, что нейросети это не панацея). Но пока что есть, то есть…
Juralis
ИИ почти ничего не поймёт из обычных человеческих книг. Написанное в книгах мало того, что обладает высокой неоднозначностью, так ещё и требует от "читателя" большого количества невербальный знаний. Кроме того, в книгах содержатся не только абстрактные факты, но и метафоры. Даже примитивные метафоры сложно будет понять. Какая-нибудь простая фраза вроде "железная леди" — это же не женщина из железа? А даже если и так, то почему леди? Возможно это железная статуя женщины, а не собственно металлическая женщина. Но если это не статуя, а реально живая женщина, то что значит "железная"? Тут придётся немного попотеть. Метафоры — антиабстрактны. Если абстрагирование — это выделение общих признаков с целью группировки объектов (то есть, чем меньше общих признаков, тем абстрактнее). А метафора — это выявление какого-то сущностного свойства у некоего объекта и перенесение этого свойства на другой объект, обладающий чем-то похожим, но не тем же самым. При этом, метафоры очень конкретны и часто имеют в своей основе отдельный феномен или направлены на описание феномена. Железо обладает большим числом свойств. Из данной фразы не особенно понятно, какое из них вообще имеется ввиду. Ферромагнитная леди? Прочная леди? Из этой леди можно изготовить подкову? Очевидно, что это может быть как каким-то устоявшимся смыслом, так и зависимым от контекста. Но страшно не это, а то, что кроме слова "железная", тут есть ещё и слово "леди". То есть, эту фразу нельзя воспринимать как "крепкая самка". Это будет не верно. Вообще, всю значимость этой короткой фразы сложно передать. Можно сказать, что это "несгибаемая женщина с хорошими манерами", но при этом мы потеряем часть смысла. Хотя, вероятно и поймём кое-что. В принципе, самая большая проблема обучения ИИ на книгах как раз в этом и заключается, что человеческий язык фактически состоит из метафор. Целые пласты человеческих знаний вообще невозможно друг с другом связать ничем иным, кроме метафор. И если ИИ не будет обладать возможностью понимать метафоры, то он не сможет понять человека. Даже если обучать ИИ в трёхмерном пространстве, он всё равно ничего не сможет понять. Просто по причине того, что трёхмерное восприятие само по себе не является ключём к схожести мышления. Это только один из аспектов. И как мне кажется, человеческий разум вполне мог бы жить и в условной среде интернета без пространства как такового и остался бы разумным. Возможно такого человека было бы не так просто понять, но слепые от рождения люди — разумны. И вероятно, что если поместить мозг человека в банку и как-то хитро подключить его к интернету, то он вполне сможет освоиться. То есть, я хочу сказать, что разум — на то и разум, что является таким же универсальным понятием, как жизнь. Живая материя очень ярко отличается от неживой, даже в самом примитивном виде. Даже самый глупый и необразованный человек умнее любого примата. В этом смысле, все эти дела с нейронными сетями и их обучением — это не очень похоже на попытку создать разум. Результатом тут будет не нечто интеллектуальное, а нечто инстинктивное, близкое к доразумной жизни (которая тоже может обучаться). И в результате мы можем получить нечто, что можно было бы метафорически сравнить с обезьяной, прочитавшей весь интернет. Любопытно, конечно, но это кажется не совсем то, что хочется получить. Получить-то хочется именно разум, с присущим разуму творчеством и всем остальным. Иначе, это не вполне можно назвать интеллектом, даже если он будет в чём-то похож и даже в чём-то эффективнее человеческого разума. Гориллу можно научить языку жестов. Были опыты, в ходе которых горилла освоила несколько сотен жестов и могла общаться ими с человеком. Даже если представить себе, что в мозг гориллы (или аналогичный ИИ) загрузили бы все книги мира — она всё равно осталась бы гориллой. Но зачем-то очень много знающей. С точки зрения построения ИИ — это был бы колоссальный результат, по сравнению с тем, что мы имеем. Но разница между получением такого ИИ и разумом — как между полётом на Марс и на Альфу Центавра.
ilansk
вы не поймете китайские идиомы, пока вам их не объяснят, как и тюремный жаргон (Феню) с понятиями и целой культурой общения и отношений.
Juralis
Это нечто более сложное, чем простые культурные различия разных разумных людей. Это различие между неразумными и разумными существами.
ilansk
Особенно Вирусы — это живая материя или неживая?
(Вирус оживает только в живой клетке)
fireSparrow
Как раз на днях прочитал интересный пост на эту тему:
http://caenogenesis.livejournal.com/114271.html
mechkladenets
Я занимаюсь обработкой языка, классификацией, извлечением фактов, юзаю Питон. Абсолютно точно могу вам сказать, что задача по тексту классифицировать на сложные классы решаема в наше время. Я лично написал код, которые классифицирует противоправную деятельность в инете, там используются разные конструкции и связи между ними + NER. И кошку от собаки легко по тексту отличать: задаете признаки вроде шерсть, рост и прочее, то же самое как на картинках фичи. И нейросеть сможет их отличить. Тут проблема в том, что тоже надо много образцов, чтобы сеть смогла понять, что слова шерсть и ушки это слова-атрибуты, а «длинная» и «пушистая» это их параметры.
ChALkeRx
Примечание: я комментирую исключительно логические рассуждения в вашем комментарии, а не позицию автора.
По Попперу — да, но, как мне кажется, речь несколько не об этом.
А вот тут у вас уже ошибка в логике.
Чтобы поймать её в явном виде — замените исходное утверждение на, скажем, «на орбите Земли летает невидимый невесомый чайник» — ход рассуждений в вашей логической цепочке не поменяется. Но это не значит, что надо всерьёз рассматривать теорию летающего на орбите невидимого чайника.
Разберём на конкретные моменты:
Кроме теоретической возможности, следует оценивать вероятность. Из невозможности доказать !A следует, что A — теоретически возможно, но это не даёт нам никакой нижней границы для оценки вероятности A.
А вот это — прямая логическая ошибка, это утверждение неверно.
Тот факт, что некий абстрактный Вася не может представить себе A, делает A менее вероятным событием.
Смотрите парадокс Гемпеля, что ли.