
В этом материале мы в команде платежной системы для интернет-магазинов Fondy расскажем, с какими проблемами мы сталкивались при разработке нашего проекта и как их решали.
Инфраструктуру любой ИТ-компании можно условно и довольно грубо разделить на две составляющие: технологии (программное обеспечение, оборудование, сервисы) и бизнес-процессы. Сейчас инфраструктура нашей компании работает довольно стабильно, процессы позволяют нам быстро расти и хотя без сбоев не обходится, случаются они на порядки реже, чем в начале пути:
Но так было не сразу. Когда мы начинали создавать компанию три года назад, у нас был за плечами десятилетний практический опыт работы с технологиями ?— ?как платежными, так и информационными, но не было опыта построения бизнеса и процессов с нуля. В этой колонке мы расскажем, какие ошибки мы допускали, с какими проблемами сталкивались и как их решали в процессе построения инфраструктуры, которую мы имеем сегодня.
На старте все казалось довольно простым и предельно понятным. Мы знали, какие технологии мы будем использовать и какую бизнес-модель испытывать. По обязанностям мы определили, что гендиректор и технический директор закроют основные задачи менеджмента:
А в команду наймем таких специалистов:
Далее мы приступили к поиску нужных сотрудников. И с первыми проблемами мы столкнулись довольно быстро.
Почему-то с самого начала нам не везло с поиском системного администратора. Мы работали с тремя ребятами очень не продолжительными периодами времени, но только через год смогли найти хорошего и надежного специалиста. Весь это год развертывание инфраструктуры наших серверов (среды разработки, продуктовой среды, сборки релизов, системы трекинга задач, системы контроля версии программного кода) шло с переменным успехом и с серьезными задержками, затягивая выпуск MVP.
Дополнительные сложности создавал тот факт, что как платежная платформа мы должны проходить сертификацию по стандартам безопасности, и администратор должен иметь соответствующие знания и опыт, чтобы разработать и внедрить аппаратную архитектуру.
Отнеситесь к поиску ключевых специалистов очень ответственно. Лучше наймите HR-агенство, которое будет искать кандидатов по описанным требованиям и квалификации, а вам останется только провести интервью. Если на этапе создания команды у вас не хватает компетенции прособеседовать специалиста, попросите кого-то из ваших друзей, знакомых, партнеров с нужной квалификацией сделать это для вас.
Стоит помнить, что команда бежит со скоростью самого медленного участника, и наняв низкоквалифицированного или без подходящего опыта специалиста, вы рискуете тем, что работа остальной части команды будет сильно замедлена.
Запуск минимально работающего продукта мы запланировали в четырехмесячный срок. Но как бы мы детально не декомпозировали задачи и не обсуждали сроки реализации с разработчиками, любая задача затягивалась на период в 2-3 раза больше от заявленного.
Нам никак не удавалось загрузить сотрудников работой хотя бы на 50%. Постоянно где-то возникало узкое горлышко: то задача еще не описана, то не готов сервер для развертывания среды разработки и тестирования, то команда не понимает приоритета задач.
В системе учета задач не было четких процессов, а все задачи валились одной кучей, из которой разработчик выбирал либо произвольную задачу, либо ту, которая ему больше всего нравится. Большинство задач зависали на «последней миле»? — ?вроде бы все подзадачи сделаны, но собрать все «кирпичики» не получается.
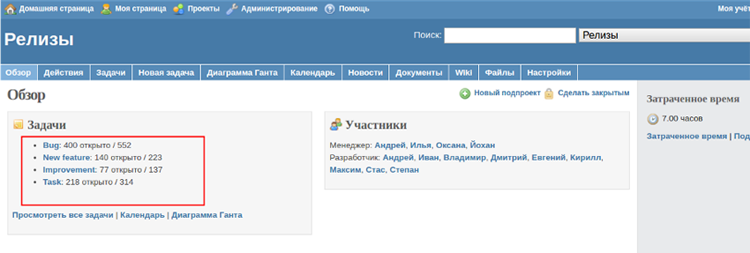
На скриншоте отлично видно соотношение не закрытых задач (400) к общему их количеству (552)
Сначала вам кажется, что что-то не так с командой, и видимо вы наняли слабых специалистов, и стоит многих уволить или заменить. Но на самом деле основная проблема — это отсутствие бизнес-процессов.
Для построения инфраструктуры, в которой разработка идет быстро, задачи проходят каждый этап (постановка, разработка, тестирование, релиз) в кратчайший срок важно привлечь в проект специалистов, имеющих за плечами опыт в командах, работавших по гибким методологиям, таким как Agile, Scrum, XP.
С высокой степенью вероятности в чистом виде ни одна методология разработки вам может не подойти и придется искать золотую середину. Чтобы не потратить на набивание шишек слишком много бесценного для бизнеса времени, постарайтесь привлечь к наладке процессов опытных специалистов.
Когда процессы постепенно у нас начали налаживаться, появляться первые клиенты, обороты расти, очередным испытание для нас стало выделение ресурсов на автоматизацию процессов.
Большaя часть стартапов закрываются на этапе быстрого роста из-за непропорционального увеличения затрат на обслуживание бизнеса. Когда мы автоматизировали систему подключения новых клиентов к сервису, выяснилось, что наша бухгалтерия перестает справляться с финансовыми отчетами и сведением балансов, а юристы с формированием договоров и проработкой юридических аспектов.
Перед нами стала дилемма?—?с одной стороны мы не могли остановить разработку релизов и бросить и без того небольшие ресурсы разработки на автоматизацию бэкофисных операций, с другой, если бы количество наших клиентов увеличилось в десять раз, нам бы пришлось нанять еще 10–20 специалистов, что съело бы все наши доходы и загнало в большой минус.
Уверены, что многие интернет-предприниматели сталкивались с проблемой, когда бухгалтер или юрист начинает корректировать вектор развития бизнеса, требуя сместить приоритеты с фронтофиса и направить их на бэкофис: например, отказаться от разработки значимой функциональности, которая нужна клиентам на сайте или в основном продукте, и сосредоточиться на разработке автоматизации операционных задач.
На этом этапе предприятию важно понимать, что бэкофис не может руководить бизнесом, но и игнорировать его потребности нельзя. Стоит скорректировать приоритеты и постараться автоматизировать самые массовые рутинные операции?—?в будущем, когда ваши конкуренты будут вручную высылать договоры и акты выполненных работ клиентам, допуская ошибки человеческого фактора и растрачивая кредит доверия, вы оцените важность того, что сделали.
После года работы мы начали подсчитывать, сколько нам обходится серверное оборудование и программное обеспечение. И здесь нам на руку сыграл большой опыт и выверенное годами решение.
Мы не стали покупать собственное железо и строить аппаратную инфраструктуру, а для размещения серверов выбрали облако Amazon AWS, которое представлено в 38 зонах доступности по всему миру и соответствует десяткам стандартов, норм, сертификатов безопасности, имеет защиту от DDoS и физического доступа сторонних лиц и организаций.
Общее количество серверов Amazon, по данным сторонних аналитиков, уже в 2012 году составляло почти полмиллиона, что дает практически неограниченные возможности для масштабирования. Страшно подумать, сколько нужно ресурсов и времени потратить, чтобы обеспечить хотя бы малую часть того, что делает Amazon в инфраструктуре своего проекта собственными силами.

На этапе разработки продукта нам такой выбор дал большие преимущества? — ?первые полгода всё серверное оборудование нам стоило не более $300 в месяц. Этого времени нам хватило для разработки MVP и проверки гипотезы нашей бизнес-модели.
С точки зрения затрат на программное обеспечение? — ?мы всегда были сторонниками открытого ПО. Существует ошибочное мнение, что open-source-продукты менее безопасны из-за своего открытого программного кода и несут большие риски для бизнеса с точки зрения уязвимости, стабильности и качества технической поддержки. Но как компания, которая проходит ежегодный аудит безопасности и ежеквартальное внешнее сканирование на попытки вторжения, мы можем утверждать?—?открытое ПО ничуть не уступает именитым проприетарным продуктам известных софтверных гигантов, а в некоторых аспектах даже превосходит.
При развертывании собственной аппаратной инфраструктуры обратите внимание на облачные решения. Они как правило дешевле в эксплуатации при небольших объемах и проще в конфигурации и поддержке. В нашей ситуации один системный администратор в состоянии обеспечивать поддержку более 30 серверов без ущерба общей эффективности. Также существенно сокращают расходы open-source-продукты: базы данных, серверы приложений, CMS, CRM, системы контроля версий кода и трекинга задач.
Помимо этого стоит уделить особое внимание корпоративной безопасности. В последнее время большое количество кибератак направлены именно на бизнес. С этой точки зрения стоит доверить свою безопасность специализированным компаниям и инструментам, например, системам защиты от DDoS, обнаружения вторжения, внешнего сканирования на уязвимости.
Вообще-то от падений приложений, выхода из строя оборудования, обрыва связи и других форс-мажорных ситуаций избавиться невозможно. Даже самые надежные системы дают сбой. Например, удар молнии в 2011 году вывел из строя часть оборудования Amazon и много сайтов ушло в офлайн.
Стоит всегда ожидать, что в любой момент любая часть вашей инфраструктуры может выйти из строя: сервер, приложение, линия телефонной связи колл-центра, магистральный интернет-провайдер. Поскольку мы подписываем с нашими клиентами контракт (Service Level Agreement), который гарантирует уровень сервиса 99,95%, то чтобы его в полной мере выполнять мы постарались максимально зарезервировать все критические узлы нашей инфраструктуры и придерживаемся стратегии «пускай падает»? — ?на случай падения у нас всегда есть резервные копии сервисов, которые в большинстве случаев включаются в работу автоматической системой мониторинга.
Также в компании разработан Disaster recovery plan?—?документ, который описывает матрицу эскалации ИТ-инцидентов (куда бежать, что делать, каким специалистам звонить) а также зоны ответственности сотрудников и топ-менеджеров по бизнес-процессам, которые были нарушены.
Шаг 1: настройте мониторинг ваших сервисов?—?есть несколько бесплатных приложений, которые позволяют, например, уведомлять в Telegram или Slack, если ваш сайт стал недоступен.
Шаг 2: постарайтесь в первую очередь зарезервировать те узлы, которые требуют наименьших ресурсов для этого: основной сайт, приложения, базу данных. Если есть возможность, сделайте так, чтобы основная база данных и резервная находились в разных географических зонах или датацентрах (вспоминаем историю с молнией в Amazon).
Шаг 3: проработайте матрицу эскалации инцидентов. Разграничьте разные возможные ситуации по их критичности и назначьте ответственных сотрудников. Определите для них максимальные сроки реакции, например, если основной сайт компании не доступен, то:
На данный момент основной проблемой, с которой мы, как предприятие, ставшее на «рельсы» бизнес-процессов боремся?—?это разработка инноваций в том же темпе, который мы набрали на старте. Увеличивая обороты мы постепенно начинаем погружаться в ежедневные операционные задачи, которые порой занимают столько ресурсов, что основное время команды приходится тратить на поддержку текущих процессов, а не созидание нового.
С целью адаптации к быстро меняющимся требованиям бизнеса и финтех-индустрии мы сейчас разделяем нашу команду на два подразделения: Innovation и Operation Team. Основные задачи Operation Team заключаются в поддержании уровня сервиса текущего бизнеса и обеспечение доходов существующей бизнес-модели.
В свою очередь, первоочередным для Innovation Team является поддержка быстрых изменений?—?генерация новых идей и продуктов, внедрение инноваций, следование трендам рынка и потребностям бизнеса. Мы верим, что и с этой проблемой нам также удастся справиться.

Инфраструктуру любой ИТ-компании можно условно и довольно грубо разделить на две составляющие: технологии (программное обеспечение, оборудование, сервисы) и бизнес-процессы. Сейчас инфраструктура нашей компании работает довольно стабильно, процессы позволяют нам быстро расти и хотя без сбоев не обходится, случаются они на порядки реже, чем в начале пути:
- 35 сотрудников обеспечивают работу офисов в России, Украине, Латвии, Чехии, Великобритании, Словакии и Казахстане, покрывая тем самым две больших юрисдикции: EC и СНГ.
- Более 30 серверов обеспечивают гарантированную работоспособность (Service Level) системы на уровне 99,95% (не более 20 минут запланированного, а также непредвиденного простоя в месяц) и готовы к многократному росту нагрузки.
- Разработка выполняется по методологии Continuous Integration с применением автоматизированного тестирования, что позволяет устанавливать обновления на production систему по несколько раз в день, не боясь получить большое количество ошибок.
- Бизнес-процессы построены так, что каждая новая функциональность проходит этап от идеи до реализации за 2-3 недели, а запуск нового проекта не более 3-4 месяцев.
Но так было не сразу. Когда мы начинали создавать компанию три года назад, у нас был за плечами десятилетний практический опыт работы с технологиями ?— ?как платежными, так и информационными, но не было опыта построения бизнеса и процессов с нуля. В этой колонке мы расскажем, какие ошибки мы допускали, с какими проблемами сталкивались и как их решали в процессе построения инфраструктуры, которую мы имеем сегодня.
Начало
На старте все казалось довольно простым и предельно понятным. Мы знали, какие технологии мы будем использовать и какую бизнес-модель испытывать. По обязанностям мы определили, что гендиректор и технический директор закроют основные задачи менеджмента:
- гендиректор — бизнес-процессы, операционные, финансовые, юридические задачи, создание продуктов;
- технический директор — технологическая архитектура, разработка ПО, проектный менеджмент.
А в команду наймем таких специалистов:
- системный администратор;
- два backend-разработчика;
- два frontend-разработчика;
- тестировщик для ручного и автоматизированного тестирования;
- бухгалтер;
- юрист;
- специалист финансового мониторинга;
- специалист антифрод-мониторинга.
Далее мы приступили к поиску нужных сотрудников. И с первыми проблемами мы столкнулись довольно быстро.
Проблема 1. Поиск сотрудников
Почему-то с самого начала нам не везло с поиском системного администратора. Мы работали с тремя ребятами очень не продолжительными периодами времени, но только через год смогли найти хорошего и надежного специалиста. Весь это год развертывание инфраструктуры наших серверов (среды разработки, продуктовой среды, сборки релизов, системы трекинга задач, системы контроля версии программного кода) шло с переменным успехом и с серьезными задержками, затягивая выпуск MVP.
Дополнительные сложности создавал тот факт, что как платежная платформа мы должны проходить сертификацию по стандартам безопасности, и администратор должен иметь соответствующие знания и опыт, чтобы разработать и внедрить аппаратную архитектуру.
Совет
Отнеситесь к поиску ключевых специалистов очень ответственно. Лучше наймите HR-агенство, которое будет искать кандидатов по описанным требованиям и квалификации, а вам останется только провести интервью. Если на этапе создания команды у вас не хватает компетенции прособеседовать специалиста, попросите кого-то из ваших друзей, знакомых, партнеров с нужной квалификацией сделать это для вас.
Стоит помнить, что команда бежит со скоростью самого медленного участника, и наняв низкоквалифицированного или без подходящего опыта специалиста, вы рискуете тем, что работа остальной части команды будет сильно замедлена.
Проблема 2. Запуск MVP в запланированные сроки
Запуск минимально работающего продукта мы запланировали в четырехмесячный срок. Но как бы мы детально не декомпозировали задачи и не обсуждали сроки реализации с разработчиками, любая задача затягивалась на период в 2-3 раза больше от заявленного.
Нам никак не удавалось загрузить сотрудников работой хотя бы на 50%. Постоянно где-то возникало узкое горлышко: то задача еще не описана, то не готов сервер для развертывания среды разработки и тестирования, то команда не понимает приоритета задач.
В системе учета задач не было четких процессов, а все задачи валились одной кучей, из которой разработчик выбирал либо произвольную задачу, либо ту, которая ему больше всего нравится. Большинство задач зависали на «последней миле»? — ?вроде бы все подзадачи сделаны, но собрать все «кирпичики» не получается.
На скриншоте отлично видно соотношение не закрытых задач (400) к общему их количеству (552)
Сначала вам кажется, что что-то не так с командой, и видимо вы наняли слабых специалистов, и стоит многих уволить или заменить. Но на самом деле основная проблема — это отсутствие бизнес-процессов.
Совет
Для построения инфраструктуры, в которой разработка идет быстро, задачи проходят каждый этап (постановка, разработка, тестирование, релиз) в кратчайший срок важно привлечь в проект специалистов, имеющих за плечами опыт в командах, работавших по гибким методологиям, таким как Agile, Scrum, XP.
С высокой степенью вероятности в чистом виде ни одна методология разработки вам может не подойти и придется искать золотую середину. Чтобы не потратить на набивание шишек слишком много бесценного для бизнеса времени, постарайтесь привлечь к наладке процессов опытных специалистов.
Проблема 3. Быстрый рост, масштабирование и автоматизация процессов
Когда процессы постепенно у нас начали налаживаться, появляться первые клиенты, обороты расти, очередным испытание для нас стало выделение ресурсов на автоматизацию процессов.
Большaя часть стартапов закрываются на этапе быстрого роста из-за непропорционального увеличения затрат на обслуживание бизнеса. Когда мы автоматизировали систему подключения новых клиентов к сервису, выяснилось, что наша бухгалтерия перестает справляться с финансовыми отчетами и сведением балансов, а юристы с формированием договоров и проработкой юридических аспектов.
Перед нами стала дилемма?—?с одной стороны мы не могли остановить разработку релизов и бросить и без того небольшие ресурсы разработки на автоматизацию бэкофисных операций, с другой, если бы количество наших клиентов увеличилось в десять раз, нам бы пришлось нанять еще 10–20 специалистов, что съело бы все наши доходы и загнало в большой минус.
Совет
Уверены, что многие интернет-предприниматели сталкивались с проблемой, когда бухгалтер или юрист начинает корректировать вектор развития бизнеса, требуя сместить приоритеты с фронтофиса и направить их на бэкофис: например, отказаться от разработки значимой функциональности, которая нужна клиентам на сайте или в основном продукте, и сосредоточиться на разработке автоматизации операционных задач.
На этом этапе предприятию важно понимать, что бэкофис не может руководить бизнесом, но и игнорировать его потребности нельзя. Стоит скорректировать приоритеты и постараться автоматизировать самые массовые рутинные операции?—?в будущем, когда ваши конкуренты будут вручную высылать договоры и акты выполненных работ клиентам, допуская ошибки человеческого фактора и растрачивая кредит доверия, вы оцените важность того, что сделали.
Проблема 4. Где размещать серверное оборудование, какое ПО выбирать и сколько это должно стоить
После года работы мы начали подсчитывать, сколько нам обходится серверное оборудование и программное обеспечение. И здесь нам на руку сыграл большой опыт и выверенное годами решение.
Мы не стали покупать собственное железо и строить аппаратную инфраструктуру, а для размещения серверов выбрали облако Amazon AWS, которое представлено в 38 зонах доступности по всему миру и соответствует десяткам стандартов, норм, сертификатов безопасности, имеет защиту от DDoS и физического доступа сторонних лиц и организаций.
Общее количество серверов Amazon, по данным сторонних аналитиков, уже в 2012 году составляло почти полмиллиона, что дает практически неограниченные возможности для масштабирования. Страшно подумать, сколько нужно ресурсов и времени потратить, чтобы обеспечить хотя бы малую часть того, что делает Amazon в инфраструктуре своего проекта собственными силами.
На этапе разработки продукта нам такой выбор дал большие преимущества? — ?первые полгода всё серверное оборудование нам стоило не более $300 в месяц. Этого времени нам хватило для разработки MVP и проверки гипотезы нашей бизнес-модели.
С точки зрения затрат на программное обеспечение? — ?мы всегда были сторонниками открытого ПО. Существует ошибочное мнение, что open-source-продукты менее безопасны из-за своего открытого программного кода и несут большие риски для бизнеса с точки зрения уязвимости, стабильности и качества технической поддержки. Но как компания, которая проходит ежегодный аудит безопасности и ежеквартальное внешнее сканирование на попытки вторжения, мы можем утверждать?—?открытое ПО ничуть не уступает именитым проприетарным продуктам известных софтверных гигантов, а в некоторых аспектах даже превосходит.
Совет
При развертывании собственной аппаратной инфраструктуры обратите внимание на облачные решения. Они как правило дешевле в эксплуатации при небольших объемах и проще в конфигурации и поддержке. В нашей ситуации один системный администратор в состоянии обеспечивать поддержку более 30 серверов без ущерба общей эффективности. Также существенно сокращают расходы open-source-продукты: базы данных, серверы приложений, CMS, CRM, системы контроля версий кода и трекинга задач.
Помимо этого стоит уделить особое внимание корпоративной безопасности. В последнее время большое количество кибератак направлены именно на бизнес. С этой точки зрения стоит доверить свою безопасность специализированным компаниям и инструментам, например, системам защиты от DDoS, обнаружения вторжения, внешнего сканирования на уязвимости.
Проблема 5. Как обеспечить стабильность инфраструктуры и защититься от падений
Вообще-то от падений приложений, выхода из строя оборудования, обрыва связи и других форс-мажорных ситуаций избавиться невозможно. Даже самые надежные системы дают сбой. Например, удар молнии в 2011 году вывел из строя часть оборудования Amazon и много сайтов ушло в офлайн.
Стоит всегда ожидать, что в любой момент любая часть вашей инфраструктуры может выйти из строя: сервер, приложение, линия телефонной связи колл-центра, магистральный интернет-провайдер. Поскольку мы подписываем с нашими клиентами контракт (Service Level Agreement), который гарантирует уровень сервиса 99,95%, то чтобы его в полной мере выполнять мы постарались максимально зарезервировать все критические узлы нашей инфраструктуры и придерживаемся стратегии «пускай падает»? — ?на случай падения у нас всегда есть резервные копии сервисов, которые в большинстве случаев включаются в работу автоматической системой мониторинга.
Также в компании разработан Disaster recovery plan?—?документ, который описывает матрицу эскалации ИТ-инцидентов (куда бежать, что делать, каким специалистам звонить) а также зоны ответственности сотрудников и топ-менеджеров по бизнес-процессам, которые были нарушены.
Совет
Шаг 1: настройте мониторинг ваших сервисов?—?есть несколько бесплатных приложений, которые позволяют, например, уведомлять в Telegram или Slack, если ваш сайт стал недоступен.
Шаг 2: постарайтесь в первую очередь зарезервировать те узлы, которые требуют наименьших ресурсов для этого: основной сайт, приложения, базу данных. Если есть возможность, сделайте так, чтобы основная база данных и резервная находились в разных географических зонах или датацентрах (вспоминаем историю с молнией в Amazon).
Шаг 3: проработайте матрицу эскалации инцидентов. Разграничьте разные возможные ситуации по их критичности и назначьте ответственных сотрудников. Определите для них максимальные сроки реакции, например, если основной сайт компании не доступен, то:
- сотрудник мониторинга должен позвонить системному администратору в течение пяти минут;
- если в течение 20 минут дозвониться не удалось, или проблема не решается?—?позвонить техническому директору;
- если еще в течение 1 часа проблема не устранена?—?сообщить топ-менеджменту посредством SMS;
- если еще в течение двух часов проблема не устранена?—?сообщить топ-менеджменту в режиме телефонного звонка с организацией конференц-кола с остальными участниками матрицы эскалации.
Проблема 6. Как не погрязнуть в операционной рутине и продолжать производить инновации
На данный момент основной проблемой, с которой мы, как предприятие, ставшее на «рельсы» бизнес-процессов боремся?—?это разработка инноваций в том же темпе, который мы набрали на старте. Увеличивая обороты мы постепенно начинаем погружаться в ежедневные операционные задачи, которые порой занимают столько ресурсов, что основное время команды приходится тратить на поддержку текущих процессов, а не созидание нового.
С целью адаптации к быстро меняющимся требованиям бизнеса и финтех-индустрии мы сейчас разделяем нашу команду на два подразделения: Innovation и Operation Team. Основные задачи Operation Team заключаются в поддержании уровня сервиса текущего бизнеса и обеспечение доходов существующей бизнес-модели.
В свою очередь, первоочередным для Innovation Team является поддержка быстрых изменений?—?генерация новых идей и продуктов, внедрение инноваций, следование трендам рынка и потребностям бизнеса. Мы верим, что и с этой проблемой нам также удастся справиться.
Поделиться с друзьями
Комментарии (3)

olegbukatchuk
29.04.2017 19:57Благодарю за пост! Скажите у вас на превью-картинке изображен интерфейс интересной визуализации запросов к распределённой сети, что это?
GLMichael
Отличная статья. Но как мне показалось многими из перечисленных проблем должен заниматься человек который называется Бизнес-аналитик. Это я к тому, что в перечисленных нанимаемых людях вы не указываете этого человека. Хотя на мой взгляд при хорошем подборе, это тот человек который должен избавлять от многих перечисленных проблем. мое мнение…