
 Недавно мы применили плату Ethond в качестве мини-роутера и запустили на нём OpenVPN.
Недавно мы применили плату Ethond в качестве мини-роутера и запустили на нём OpenVPN.
Но обнаружилось, что процессор часто нагружается на 100%, а скорость не поднимается выше 15-16 Мбит/с. На канале связи 100 мегабит это очень мало, поэтому мы решили ускорить процесс аппаратно.
Ребята из группы FPGA-разработчиков сделали прошивку на базе открытого IP-core для Altera CycloneV с реализацией шифра AES-128, которая умеет шифровать 8 Гбит/сек и дешифровать 700 Мбит/сек. Для сравнения, программа openssl на CPU (ARM Cortex A9) того же CycloneV может обрабатывать лишь около 160 Мбит/сек.
Эта статья посвящена нашему исследованию по применению аппаратного шифрования AES. Мы сжато представим описание криптографической инфраструктуры в Linux и опишем драйвер (исходный код открыт и доступен на github), который осуществляет обмен между FPGA и ядром. Реализация шифрования на FPGA не является темой статьи — мы описываем лишь интерфейс, с которым происходит взаимодействие c акселератором со стороны процессора.
Сейчас мы понимаем, что лучше было бы сначала определить, в чём заключается главный фактор понижения пропускной способности канала: вдруг на самом деле не сам процесс шифрования, а проход через программный стек занимает основную часть времени? Мы этого не сделали, и прирост производительности в результате оказался вовсем не таким, как ожидалось. Однако польза всё равно есть: было интересно изучить, как в Linux зарегистрировать механизм аппаратного ускорения, как к нему можно обратиться из пользовательских программ и, наконец, как заставить популярные вещи вроде openssl и openvpn выбирать ускоренный алгоритм, а не стандартный, реализованный программно.
В будущем мы собираемся ускорить именно OpenVPN на Ethond — тогда ждите от нас очередную статью!
Введение
Чем нас так заинтересовала криптография? На первый взгляд, она не идёт бок о бок с оборудованием, которое мы делаем. Однако, применение для неё мы тоже можем найти. Огромная часть трафика зашифрована, и каждый пользователь Интернета регулярно сталкивается, даже сам того не зная, с криптографией. Например, растёт популярность VPN: согласно исследованию, на начало 2017 года трое людей из десяти используют эту технологию.
Нам пришла мысль сделать свой маленький маршрутизатор, который бы мог на больших скоростях осуществлять шифрование и дешифрование. Идея в том, чтобы по VPN подключался не пользователь со своей машины, а сам роутер. Ну, и просто интересно было попробовать себя в новом.
За счёт чего можно добиться ускорения криптографических алгоритмов? Если их выражать через арифметические и логические операции, получается медленно. В реализации на специализированных цифровых схемах можно добиться намного большей производительности. Хороший набор ссылок по теме можно найти в статье в Википедии про AES instruction set.
Возможно реализовать алгоритм аппаратно на CPU и вызывать его выполнение через специальные инструкции. Известный пример — AES-NI от Intel. Однако процессоры встраиваемых систем часто таким функционалом не обладают или имеют ограничение на экспорт/импорт. В таком случае можно установить дополнительные периферийные устройства, которые сами будут обрабатывать данные. И, конечно, функциональность такой периферии можно реализовать и на FPGA.
Решив перевести возможное в реальное, мы начали исследование аппаратного ускорения шифрования на FPGA.
Теоретические сведения
В ходе исследования способов связки аппаратного шифрования на FPGA и пользовательских программ мы на некоторое время застряли в изучении матчасти и думаем, что имеет смысл изложить здесь некоторые основные моменты.
Ядро Linux
В ядре Linux реализовано множество криптографических алгоритмов: и симметричные шифры, и хеши, и режимы работы блочных шифров. Всё это может использоваться самим ядром: например, для шифрования дисков (dm-crypt) или работы VPN (IPsec). Обеспечением унифицированного доступа к криптографическим функциям занимается Kernel CryptoAPI, котороый позволяет драйверам регистрировать аппаратные реализации соответствующих алгоритмов.
Пользовательские программы также могут обращаться к CryptoAPI. Одним из интерфейсов, предоставляющих такую возможность, является сокет address family AF_ALG и библиотека-обёртка над ним libkcapi. Основной конкурент AF_ALG — модуль ядра cryptodev (доступ к CryptoAPI через символьное устройство /dev/crypto).
По словам авторов cryptodev, их решение намного производительнее, чем AF_ALG (см. сравнение).
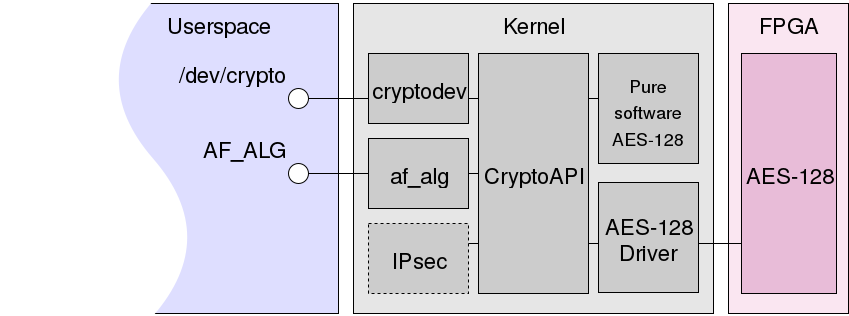
На схеме показано CryptoAPI, где зарегистрированы две реализации AES-128: программная и аппаратная, обращение к которой происходит через соответствующий драйвер.
Осуществить запрос к CryptoAPI могут, к примеру, IPsec, а также модули af_alg.ko и cryptodev.ko. Оба дают пользовательским программам возможность обращаться к криптографической подсистеме ядра, первый — через семейство адресов, второй — через символьное устройство.
Как правило, это выполняется прозрачно: CryptoAPI само, получая запрос, выбирает, какой реализацией пользоваться, однако при желании можно узнать некоторые детали его работы через файл /proc/crypto. В нём заданы, в частности, такие поля:
name— название реализуемого алгоритма.driver— уникальное название отдельной реализации алгоритма. Те из них, которые оканчиваются на-generic, обычно являются стандартными программными реализациями в ядре.priority— приоритет. Если у ядра есть несколько реализаций одного и того же алгоритма, оно выберет реализацию с наивысшим приоритетом. Каждый драйвер сам назначает произвольный приоритет при регистрации алгоритма. Выбирается реализация, у которой значение приоритета наибольшее.
Userspace
CryptoAPI, несмотря на то, что уже является высокоуровневой абстракцией, имеет ещё одну обёртку: в userspace мало кто обращается к нему напрямую и большинство программ предпочитает использование библиотек, к примеру, libcrypto и libssl из проекта openssl. Ими пользуются, например, openssh, opvenvpn и, вполне ожидаемо, openssl. Эти библиотеки поддерживают engines, — то, что обычно называется плагинами, механизмы добавления новых реализаций алгоритмов криптографии.
Разработчиками openssl уже написаны engines для шифрования в ядре через AF_ALG и /dev/crypto. Поэтому множество программ автоматически получают доступ к аппаратной реализации криптоалгоритма, если она зарегистрирована в CryptoAPI.
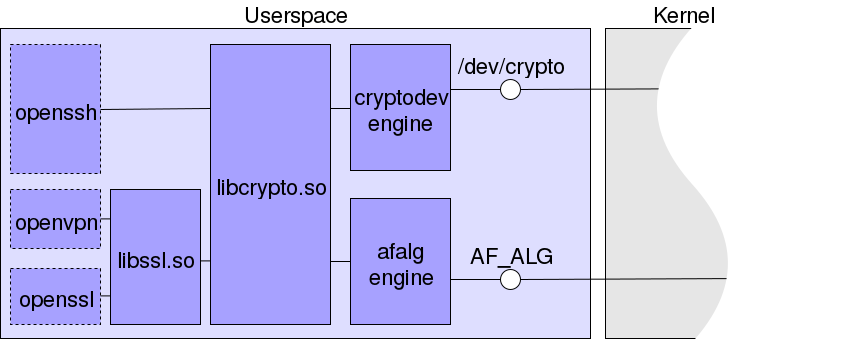
На схеме изображены несколько программ, которые пользуются криптографическими функциями, предоставленными в библиотеках libssl и libcrypto, способных обратиться к CryptoAPI через /dev/crypto или AF_ALG. К примеру, в libcrypto для того и другого заданы cryptodev engine и afalg engine соответственно.
Реальный опыт
Разобравшись с теорией, переходим к суровой реальности: описанию нашего практического опыта.
Цель исследования
При разработке драйвера ускорителя шифрования главный исследовательский вопрос заключался в том, какую пропускную способность между FPGA и пользовательскими программами мы сможем обеспечить на своих платах с CycloneV на борту (например, Ethond или BlueSom). В наших условиях это оказалось важно: когда шифрование происходит настолько быстро, основное время тратится на пересылку данных и синхронизацию происходящего в разных частях системы.
Металл
Наш драйвер практически полностью определяется тем, что нам предоставляет железо. Поэтому начнём с описания аппаратной части.

На схеме упрощённо показана модель взаимодействия процессора и FPGA внутри SoC CycloneV. Для более точного и подробного описания можно обратиться к оригинальному изображению в главе "Introduction to the Hard Processor" из Cyclone V Device Handbook, Volume 3: Hard Processor Technical Reference Manual, увлекательной, но толстой книжки.
Линукс с нашим драйвером запущен на MPU (Microprocessor Unit) внутри HPS (Hard Processor System). Процессор может обращаться к регистрам FPGA через L3 SWITCH по интерфейсу HPS-to-FPGA. Обращения к регистрам на схеме изображены голубыми стрелками.
Устройства, реализованные в FPGA, могут обращаться к SDRAM-памяти через интерфейс FPGA-to-HPS по DMA (зелёные стрелки), а также слать процессору прерывания (красные стрелки). В FPGA реализованы две независимых сущности: ускоритель шифрования и ускоритель дешифрования. Каждый из них состоит из двух связанных блоков, один из которых реализует алгоритм (шифрование/дешифрование), а другой обменивается данными с памятью по DMA.
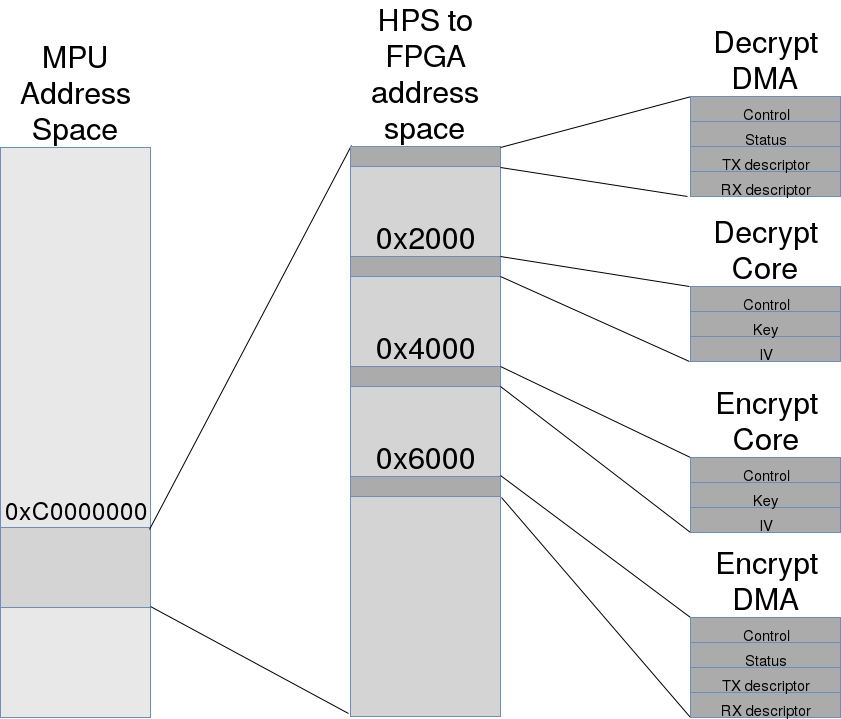
Обе пары "блоков", реализованных в FPGA, имеют свои регистры.
Encrypt Core и Decrypt Core имеют идентичные наборы регистров, которые позволяют задать ключ (Key), вектор инициализации (IV, initialization vector), используемые при следующей операции шифрования/дешифрования.
Decrypt DMA и Encrypt DMA также имеют зеркальную структуру. Через их регистры можно задать адреса и длины отрезков памяти — эти наборы параметров мы названы дескрипторами — в одной части которых находятся исходные данные, а в другую требуется разместить результат применения AES. Также доступна возможность включения и выключения прерываний для оповещения об окончании обработки каждого дескриптора.
Crypto API
Расскажем чуть подробнее о некоторых концепциях криптографической подсистемы Linux.
Одной из её основных сущностей являются "транформации" (transformation) — так называются любые преобразования данных: подсчет хеш-суммы, сжатие, шифрование. Драйвер может самостоятельно "зарегистрировать" трансформацию — предоставить возможность ей пользоваться.
Класс типов трансформаций весьма обширен, однако шифрованием занимается лишь три их типа:
CRYPTO_ALG_TYPE_CIPHER: шифр, оперирующий одиночными блоками (в терминах блочных шифров).CRYPTO_ALG_TYPE_BLKCIPHER: шифр, оперирующий кусками данных с длиной кратной размеру блока, причём синхронный: шифрующая функция не завершается, пока не завершится шифрование.CRYPTO_ALG_TYPE_ABLKCIPHER: от предыдущего отличается тем, что он асинхронный: шифрующая функция используется только для начала шифрования и завершается, не дожидаясь завершения. Об окончании операции сообщает сам драйвер, реализующий шифрование.
В CryptoAPI также можно задавать "шаблоны" (templates) — реализации сложных сущностей, например, определенного режима работы блочного шифра или HMAC, на основе простых трансформаций вроде шифрования одного блока данных или подсчета хеш-суммы.
В частности, существование шаблонов позволяет использовать CRYPTO_ALG_TYPE_CIPHER для реализации блочного шифра, хотя сама трансформация оперирует лишь 16-байтовыми блоками. Однако это сильно нагружает CPU: ядро само осуществляет управление режимом работы шифра. Трансформации CRYPTO_ALG_TYPE_BLKCIPHER и CRYPTO_ALG_TYPE_ABLKCIPHER же берут это на себя, и ядру не приходится применять шаблоны, обеспечивающие режим.
Так как наша прошивка в FPGA сейчас реализует AES-128 в режиме CBC, CRYPTO_ALG_TYPE_CIPHER для нас интереса не представляет: у нас уже реализован требуемый режим работы и со стороны процессора не требуется дополнительных затрат.
Наш драйвер предоставляет трансформацию типа CRYPTO_ALG_TYPE_BLKCIPHER, нам показалось, что её реализовать будет проще.
Трансформация отдаёт CryptoAPI функции для задания IV (initialization vector), ключа, для шифрования и для дешифрования. Всё это указывается драйвером трансформации при её регистрации в полях структуры blkcipher_alg. Так выглядит эта структура:
struct blkcipher_alg {
int (*setkey)(struct crypto_tfm *tfm, const u8 *key,
unsigned int keylen);
int (*encrypt)(struct blkcipher_desc *desc,
struct scatterlist *dst, struct scatterlist *src,
unsigned int nbytes);
int (*decrypt)(struct blkcipher_desc *desc,
struct scatterlist *dst, struct scatterlist *src,
unsigned int nbytes);
const char *geniv;
unsigned int min_keysize;
unsigned int max_keysize;
unsigned int ivsize;
};Рассмотрим самые интересные поля: setkey, callback для установки ключа, и encrypt / decrypt — для шифрования/дешифрования. Структура blkcipher_desc содержит в себе IV для операции шифрования. Параметрами src и dst callback'ов encrypt и decrypt задаются области памяти, из которых нужно взять исходные данные и в которых надо разместить результат.
Варианты стека криптографии на примере Openssl
Теперь мы чуть лучше представляем, как в Линуксе реализован криптографический стек, и можем более ответственно рассмотреть различные варианты его построения с разными сопутствующими преимуществами и недостатками.
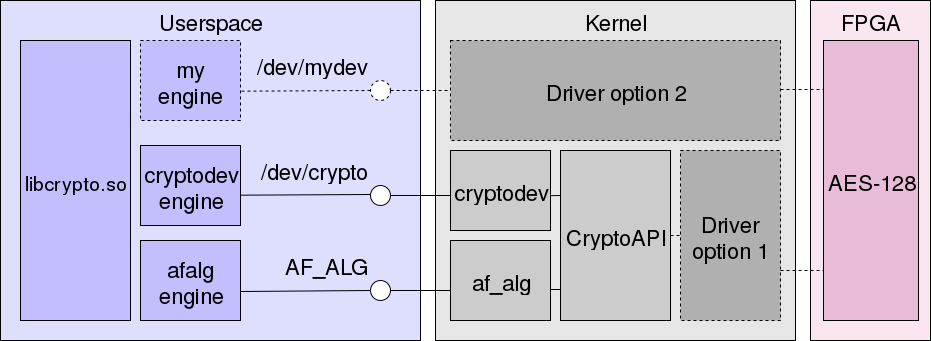
Очевидно, что если драйвер ускорителя шифрования должен использоваться и самим ядром — например, в IPsec — требуется зарегистрировать свою реализацию в CryptoAPI. В таком случае доступ к драйверу имеют как пользовательские програмы, так и Linux. Это отмечено на схеме как "Driver option 1".
Однако существует и альтернативная возможность, обозначенная как "Driver option 2": реализация своего интерфейса для пользовательской среды в обход CryptoAPI и модулей cryptodev и af_alg. Это может показаться неправильным решением: редко уход от стандартизированных механизмов приводит к приятным результатам. Однако мы ещё недостаточно изучили вопрос, чтобы быть уверенными, что наш случай хорошо подходит под CryptoAPI и тот не накладывает существенные ограничения на производительность.
В текущей реализации мы выбрали первый вариант, но готовы попробовать и второй.
Архитектура soc-aes-accel
Когда ядро хочет, чтобы мы зашифровали или расшифровали что-то, оно вызывает наши функции fpga_encrypt и fpga_decrypt. Они имеют идентичные сигнатуры и делают одно и то же, только одна обращается к регистрам шифрующего устройства в FPGA, а вторая — к регистрам дешифрующего.
Эти функции принимают два указателя на массивы из struct scatterlist. Каждый из них хранит последовательность областей памяти: src — откуда взять исходные данные, dst — куда положить результат. Гарантируется, что каждый из таких кусков памяти не пересекает границ одной страницы.
Задача драйвера выглядит тривиальной:
- Отобразить адреса каждой области памяти в соответствующие им шинные адреса — те, по которым устройство сможет совершать обращения по DMA;
- Записать шинные адреса и длины областей памяти в регистры DMA-контроллера;
- Попросить DMA-контроллер послать прерывание после обработки всех кусков;
- Дождаться прерывания.
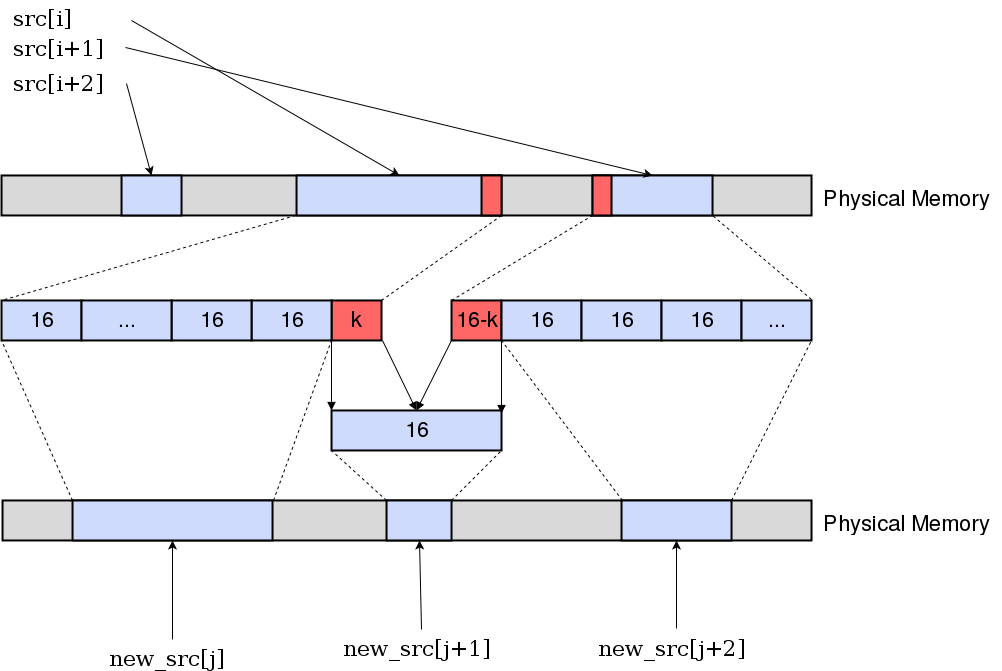
Но дьявол в деталях: версия DMA-контроллера в FPGA, которая у нас реализована, принимает только входные данные, имеющие размер, кратный 16 байтам. Скоро это ограничение будет снято, но пока FPGA-разработчики не успевают изменить прошивку, мы работаем с тем, что есть: копируем имеющие не кратную 16 байтам длину куски памяти в последовательный буфер.
Производительность
Теперь, когда драйвер написан, требуется ответить на животрепещущий вопрос: а насколько он производительный?
Конечно, можно было бы для замеров использовать openssl, однако мы решили написать свою программу openssl_benchmark.c: openssl не предоставляет нам достаточной гибкости. В частности, нельзя установить точный размер одиночного буфера, который будет отослан в libcrypto, поскольку openssl может решить обрабатывать входные данные по частям. Также показатели производительности становится сложнее различить, так как тратится некоторое время на ввод/вывод, выделение памяти, инициализацию openssl и тому подобное.
Наша программа работает просто: она выделяет и зануляет буферы заданного размера в качестве входных данных, а затем отсылает их в libcrypto на обработку указанное число раз. Замеряет она только время, потраченное на вызовы libcrypto. В силу того, что обработка происходит многократно, можно весьма точно установить производительность именно выполнения AES без учёта потерь, вызванных вспомогательными задачами вроде получения входных данных.
С помощью этой программы мы шифровали и дешифровали буферы разной длины (по 1000 операций обоих типов для каждой длины буфера). Потом посчитали пропускную способность в Мбит/сек. Всё это мы проделали дважды: в первом случае libcrypto шифровала наши данные своей софтовой реализацией ("Software" на графиках), во втором — отдавала ядру через cryptodev engine ("Hardware" на графиках).
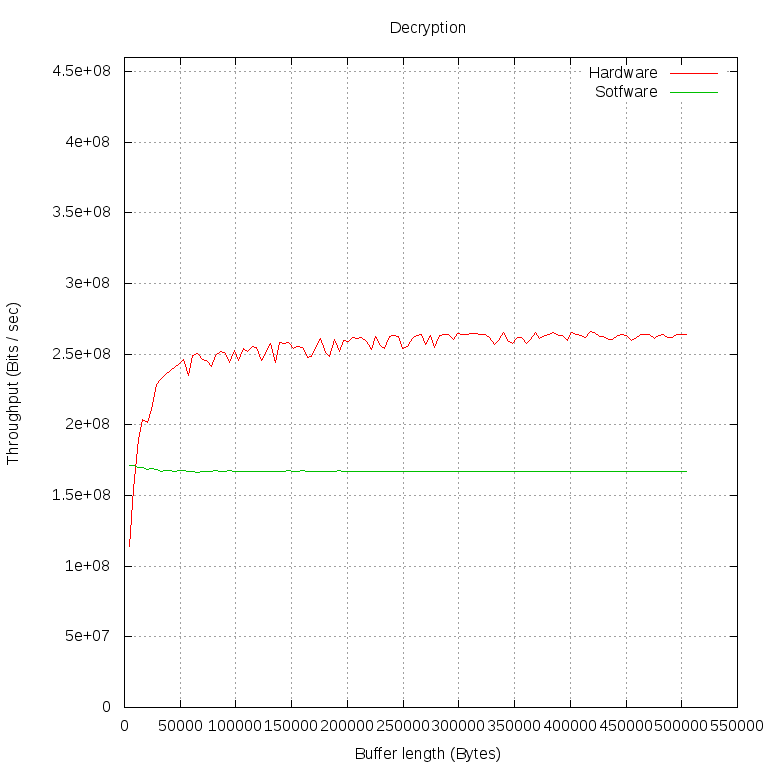
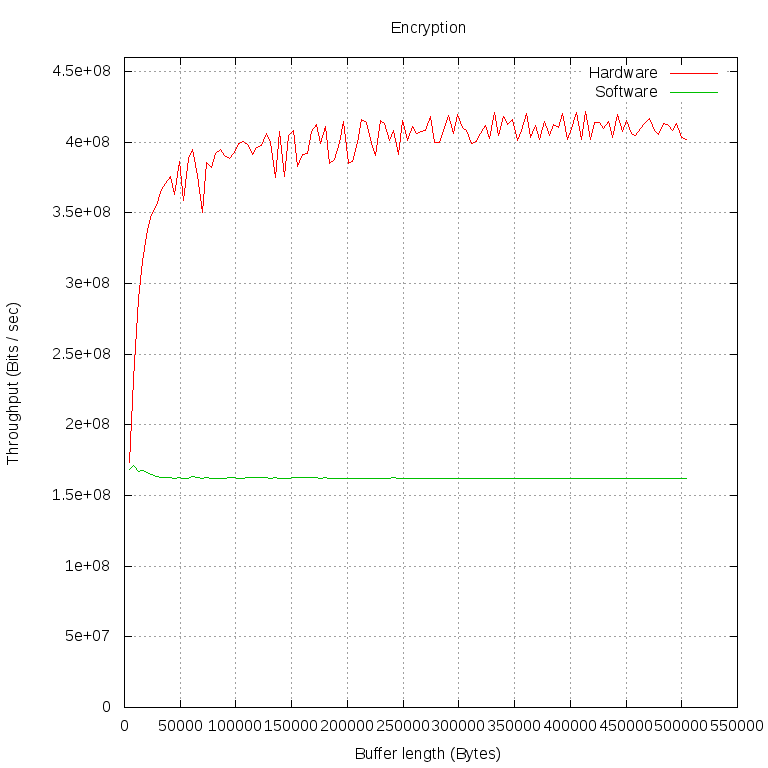
Особый интерес представляет момент, в который аппаратная реализация настигает программную по пропускной способности. Проведём измерения на меньшем промежутке и с меньшими интервалами:
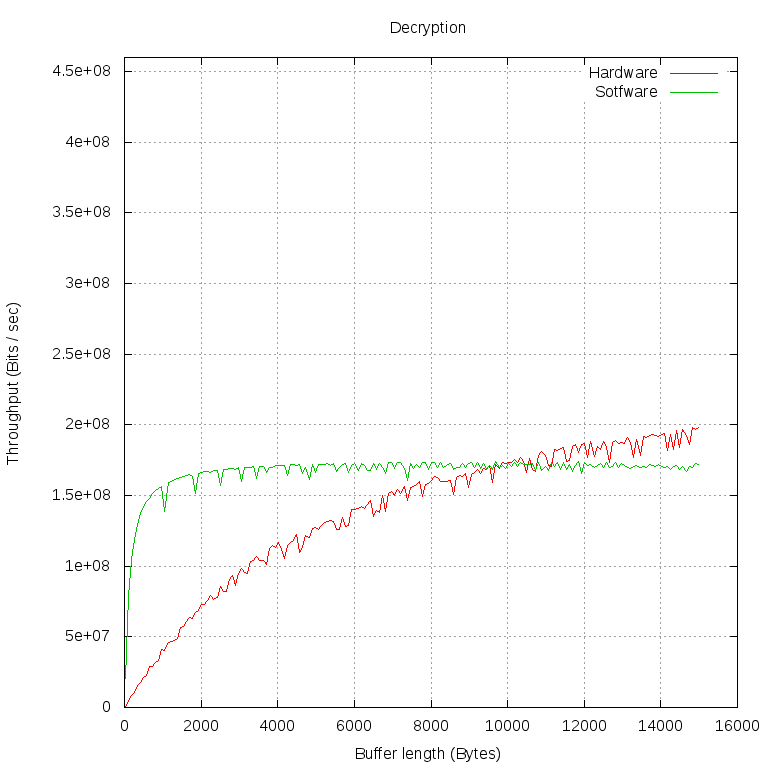
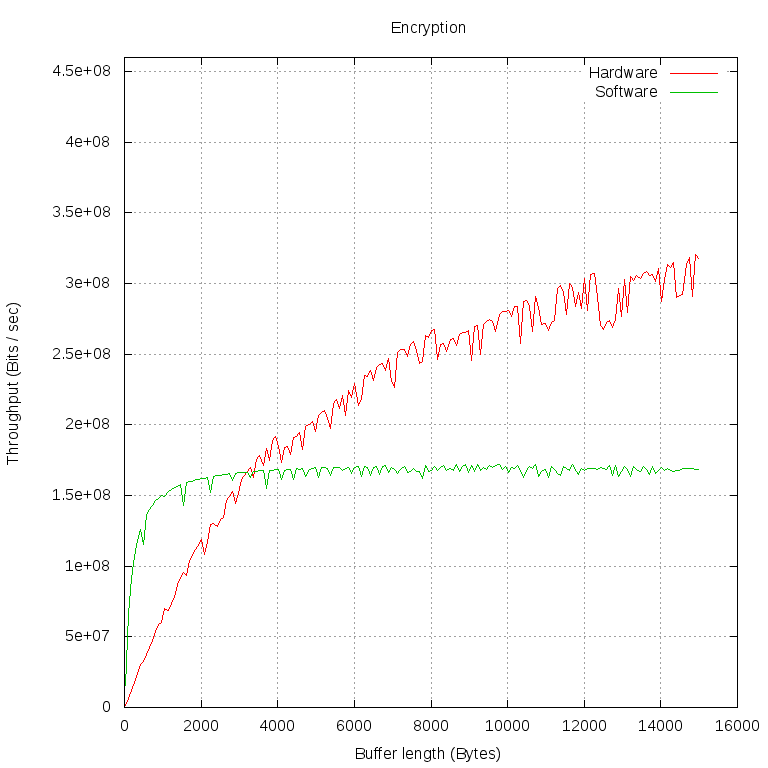
Мы видим, что производительность программной реализации практически не зависит от размера буфера. Это можно объяснить тем, что обмен данными между нашей программой и libcrypto происходит очень быстро и с ростом размера буфера быстро становится незаметной трата времени на вызов функций.
С шифрованием на FPGA ситуация сложнее. Обращение к librypto передается cryptodev engine, тот открывает /dev/crypto, несколькими системными вызовами настраивает сессию для шифрования и только потом передает указатели на буферы для шифрования в модуль cryptodev. Тот, в свою очередь, формирует в виде struct scatterlist * два списка физических страниц, на которые спроецирован пользовательский буфер в его виртуальном адресном пространстве, и передаёт в CryptoAPI. Наш драйвер имеет наивысший приоритет из всех зарегистрированных реализаций AES, поэтому списки получает он. Когда драйвер убеждается в том, что длины всех кусков памяти кратны длине блока AES, он получает соответствующие шинные адреса и записывает их в регистры FPGA.
Мы видим, что между FPGA и пользовательскими программами запросы должны пройти сквозь несколько слоёв и потери времени на них очень велики. Лишь на данных весьма большого объёма на пропускную способность перестаёт сильно влиять время на осуществление запроса. На графике этот момент можно определить по тому, что линия становится почти горизонтальной: основная часть времени тратится именно на обработку данных.
Читатель, который посмотрит не только на форму линий, но и на конкретные числовые значения, конечно, удивится: почему дешифрование стабилизируется на 250 Мбит/с, а шифрование — на 400 Мбит/с? На самом деле драйвер тут совершенно ни при чём, так происходит потому, что в FPGA, несмотря на зеркальный интерфейс, процедуры шифрования и дешифрования реализованы по-разному.
Выясним теперь, насколько нагружается CPU при использовании аппаратного шифрования. С нагрузкой на CPU при работе программной реализации шифрования всё и так очевидно: CPU должен использоваться на сто процентов, так как именно он является узким местом. Беглая проверка показывает, что так и есть.
Мы запустили аппаратное шифрование и дешифрование на буферах разной длины в цикле и тем временем смотрели в соседнем терминале на наргузку на CPU в top. Понятно, что измерения "на глаз" при помощи top будут не самыми точными, но мы решили, что некоторое представление они всё-таки дают.
Вот полученные результаты:
| Размер буфера | ||||||
| 16 | 256 | 1024 | 4096 | 8192 | 450000 | |
| Шифрование | 92% | 89% | 81% | 63% | 53% | 29% |
| Дешифрование | 93% | 91% | 86% | 74% | 64% | 43% |
Дешифрование даёт большую нагрузку на процессор из-за того, что дешифрующая часть в FPGA обрабатывает наши данные с меньшей задержкой и драйверу приходится чаще просыпаться, чтобы загрузить в FPGA новую порцию данных.
Видно, что с ростом объёма данных, отдаваемых драйверу за одно обращение из пользовательского пространства, снижается нагрузка на CPU. Это можно объяснить тем, что на больших объёмах обращения к драйверу происходят реже, избавляя его от лишних накладных расходов.
Заключение
Между молотом FPGA и наковальней программ в пользовательском пространстве живётся на удивление непросто. Основная проблема в положении драйвера заключается в очень высоких требованиях к скорости обмена: лишь на больших объёмах данных становится заметным преимущество аппаратной реализации. Слишком много времени тратится на прохождение запроса через весь стек. Однако начиная с некоторого объёма аппаратная реализация существенно снимает нагрузку с процессора и становится быстрее программной в полтора-два раза.
Комментарии (20)

datacompboy
28.04.2017 20:42А что с многопоточностью шифрования-дешифрования?

YourChief
28.04.2017 22:27+2Для CBC она невозможна. Стоило попробовать для начала использовать многопоточность для CTR средствами основного процессора.
ph14nix
30.04.2017 21:38+1Насколько я помню со слов наших FPGA-разработчиков, ускорители шифрования и дешифрования в FPGA реализованы в виде независимых друг от друга клубков проводов. Поэтому со стороны FPGA никаких препятствий для одновременного шифрования и дешифрования быть не должно. Читая исходники CryptoAPI ядра я тоже не нашёл никаких помех для этого.
Но в драйвере есть несоклько полей структуры, которые используются и шифрующей и дешифрующей функциями. Похоже, что прямо сейчас только это помешает запустить параллельно шифрование и дешифрование. Такое негибкое решение мы реализовали на самых ранних этапах разработки, так как тестировали шифрование и дешифрование только по очереди. Давно собирались переписать, но руки не дошли.
Я, наверное, всё же доберусь до починки этого в ближайшие пару недель. Ждите тогда новые графики.
datacompboy
01.05.2017 00:09Оу, вот этого не ожидал. Вопрос был что относительно параллельной работы двух декрипторов или энкрипторов — как они обрабатываются. Все ли данные, включая контекст для CBC потокобезопасны…
Но наличие лока между криптом и декриптом, да еще и в драйвере, это нежданчик.

VBKesha
28.04.2017 21:12+2Спасибо за статью!
Как всегда очень интеренесо!
PS. Можете как нибудь прокоментировать вот этот вопрос #comment_10195914

YourChief
28.04.2017 22:23-1Читатель, который посмотрит не только на форму линий, но и на конкретные числовые значения, конечно, удивится: почему дешифрование стабилизируется на 250 Мбит/с, а шифрование — на 400 Мбит/с? На самом деле драйвер тут совершенно ни при чём, так происходит потому, что в FPGA, несмотря на зеркальный интерфейс, процедуры шифрования и дешифрования реализованы по-разному.
Это и без комментария понятно, что по-разному, и ничего не объясняет.YourChief
28.04.2017 22:58-1Кстати, это ещё более дико смотрится в том разрезе, что шифрование в CBC нельзя параллелизовать (без внесения изменения в схему CBC), а вот расшифровку как раз таки можно параллелизовать. Можете прокомментировать этот феномен?
YourChief
28.04.2017 23:14Вот ещё идея для вас: в OpenVPN с версии 2.4.0 зарелизили поддержку режима GCM, в котором и проверка целостности, и шифрование могут быть реализованы параллельно. И при этом ещё оверхед от паддинга исчезает. Если ваш ARM-процессор многоядерный и вам удастся добиться параллелизма, то вполне вероятно вы сможете выйти на полную канальную скорость безо всяких аппаратных изысков даже в тесте с одним соединением.
ph14nix
30.04.2017 22:06+3Идея интересная, но, боюсь, нежизнеспособная.
Я нашёл свои старые измерения, того, на что тратится процессорное время при работе
iperfчерезopenvpnс софтовой релизациейAES-128-CBC: flame graph. О том, как интерпретировать flame graph, читайте http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html .
Эта (кликабельная) картинка, была построена по
perf.data, полученному командойperf record -a -g -- iperf -c some.host.
По ней можно понять, что на шифрование уходит меньше 20% процессорного времени. Кучу времени процессор провёл в системных вызовах (
send,recv,poll) и в функцииsha1_block_data_order. Кажется, проще перейти на Blowfish, чем AES ускорять :) .
К распараллеливанию на многоядерном процессоре тоже есть вопросы. Я не знаю, умеют ли
libcrypto,libsslили ещё какие-то криграфические библиотеки распараллеливаться из коробки.datacompboy
01.05.2017 00:14ну во-1х, 20% это не мало :)
во-2х, 20% у aes_encrypt и 17% у sha1_block — даже если их просто сколлапсить, это уже 17% экономия. а если еще и оба упадут на fpga, так что в итоге суммарно в 4 раза быстрее чем на сру — то вместо 37% получам 5% — что даёт ускорение на треть.
нет, распараллеливать из коробки они не умеют.
{kind=link}
OlegYch_real
30.04.2017 22:10+1спасибо, я хоть никогда серьезно ниже jvm не писал, но прочел с удовольствием
вопрос — отчего графики перфоманса хардверной реализации такие рваные?
yuklimov
30.04.2017 22:10+2Правильно ли я понял, что скорость (400Мбит/с для шифрования) ограничивает не столько самой реализация AES в FPGA (блоки и размножить можно) (8Гбит/с), сколько скорость обмена данных? Не измеряли чистую скорость обмена данных (с учетом всего стека, конечно)?
ph14nix
30.04.2017 22:19У драйвера между моментами, когда он отдавал в FPGA адреса буфферов с данными, было время спать. Особенно это заметно при больших объёмах данных. Это значит, что со своей задачей он справлялся и у FPGA всегда были данные для обработки. Я пока не уверен, думаю, нам стоит дождаться ответа авторов прошивки FPGA, чтобы можно было ответить на вопрос о том, чем сейчас ограничивается скорость.
yuklimov
01.05.2017 22:17Было бы интересно!
Я занимаюсь разработкой проекта на SoC Xilinx Zynq 7020 (аналог Вашего). И скорости взаимодействия ARM и FPGA части интересны, т.к. они временами нас ограничивают…
datacompboy
01.05.2017 00:43К вопросу о производительности — не рассматривали вариант удвоения ширины энкриптора/декриптора?
Слышал краем уха, что впихивание ширины во всё доступное (кратное блоку) давало выигрыш по энергоэффективности (ну и кратное ускорение, разумеется).
Сколькитактное ядро, к слову, получили? Может, оттуда разница в пиковой производительности?
Cobolorum
А какова цена вопроса Metrotek EthOnd?
ladynoname
Добрый день, по поводу цены можно узнать через запрос у нас на сайте. Есть опции, так же от количества цена зависит.