

Всем привет! Настало время пополнить наш с вами алгоритмический арсенал.
Сегодня мы основательно разберем один из наиболее популярных и применяемых на практике алгоритмов машинного обучения — градиентный бустинг. Наша задача — основательно разобраться в бустинге, поэтому статья разбита на 2 части: сегодня мы разберем основную теорию алгоритма, а через 2 недели — практику.
О том, откуда у бустинга растут корни и что на самом деле творится под капотом алгоритма — в нашем красочном путешествии в мир бустинга под катом. Рванули!
- Первичный анализ данных с Pandas
- Визуальный анализ данных c Python
- Классификация, деревья решений и метод ближайших соседей
- Линейные модели классификации и регрессии
- Композиции: бэггинг, случайный лес. Кривые валидации и обучения
- Построение и отбор признаков
- Обучение без учителя: PCA, кластеризация
- Обучаемся на гигабайтах c Vowpal Wabbit
- Анализ временных рядов с помощью Python
- Градиентный бустинг, часть 1
- Градиентный бустинг, часть 2
План этой статьи:
- Введение и история бустинга
- GBM алгоритм
- Функции потерь
- Итог про теорию GBM
- Домашнее задание №10
- Полезные ссылки
1. Введение и история появления бустинга
Большинство людей, причастных к анализу данных, хоть раз слышали про бустинг. Этот алгоритм входит в повседневный "джентльменский набор" моделей, которые стоит попробовать в очередной задаче. Xgboost и вовсе часто ассоциируется со стандартным рецептом для победы в ML соревнованиях, породив мем про "стакать xgboost-ы". А еще бустинг является важной частью большинства поисковых систем, иногда выступая еще и их визитной карточкой. Давайте для общего развития посмотрим, как бустинг появился и развивался.
История появления бустинга
Все началось с вопроса о том, можно ли из большого количества относительно слабых и простых моделей получить одну сильную. Под слабыми моделями мы подразумеваем не просто небольшие и простые модели вроде деревьев решений в противовес более "сильным" моделям, например, нейросетям. В нашем случае слабые модели — это произвольные алгоритмы машинного обучения, точность которых может быть лишь немногим выше случайного угадывания.
Утвердительный математический ответ на этот вопрос нашелся довольно быстро, что само по себе было важным теоретическим результатом (редкость в ML). Однако, потребовалось несколько лет до появления работоспособных алгоритмов и Adaboost. Их общий подход заключался в жадном построении линейной комбинации простых моделей (базовых алгоритмов) путем перевзвешивания входных данных. Каждая последующая модель (как правило, дерево решений) строилась таким образом, чтобы придавать больший вес и предпочтение ранее некорректно предсказанным наблюдениям.
По-хорошему, нам следовало бы последовать примеру большинства остальных курсов по машинному обучению, и перед градиентным бустингом тщательно разобрать его предтечу — Adaboost. Однако, мы решили сразу перейти к самому интересному, так как Adaboost все равно в итоге слился с GBM, когда стало понятно, что это просто его частная вариация.
Сам алгоритм имеет очень наглядную визуальную интерпретацию стоящей за ним интуиции взвешивания наблюдений. Рассмотрим игрушечный пример задачи классификации, в которой мы будем пробовать на каждой итерации Adaboost разделить данные деревом глубины 1 (так называемым "пнем"). На первых двух итерациях мы увидим следующую картинку:
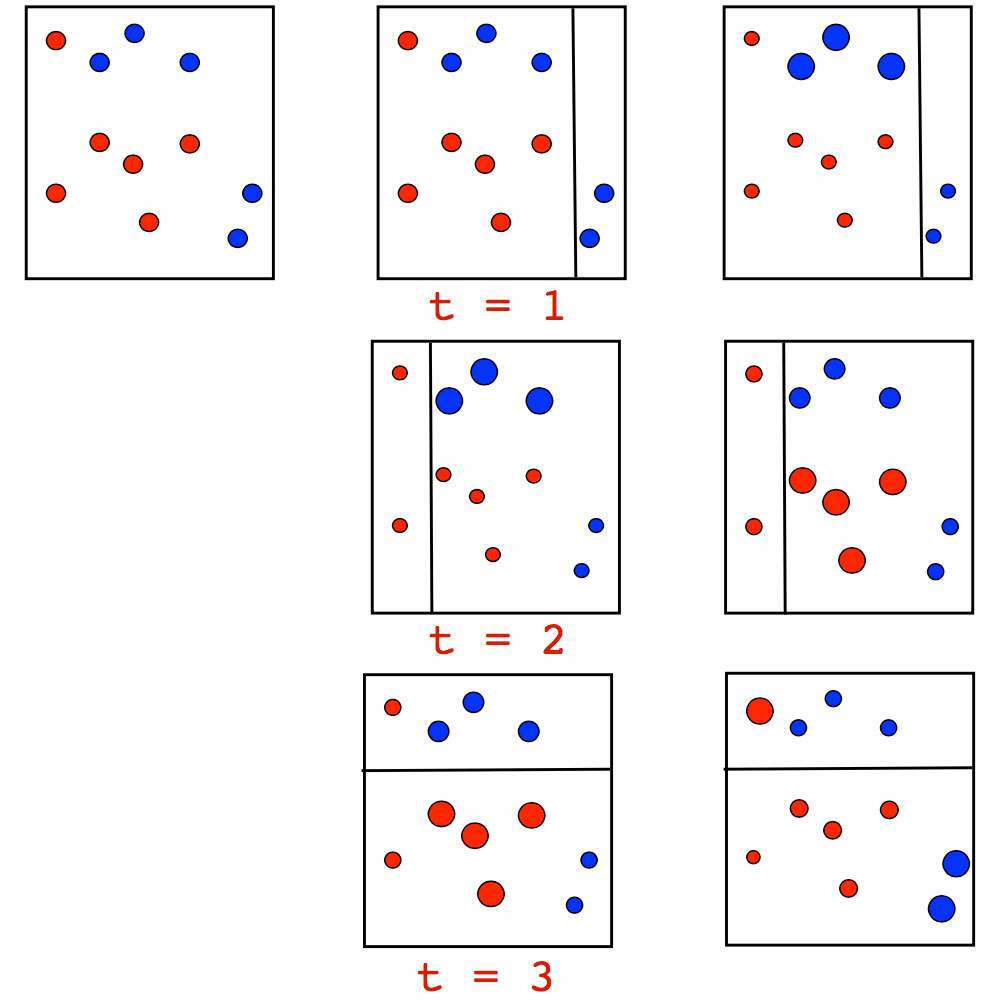
Размер точки соответствует полученному ей весу за ошибочное предсказание. И мы видим, как на каждой итерации эти веса растут — пни не могут в одиночку справиться с такой задачей. Однако, когда мы произведем взвешенное голосование ранее построенных пней, мы получим искомое нами разделение:
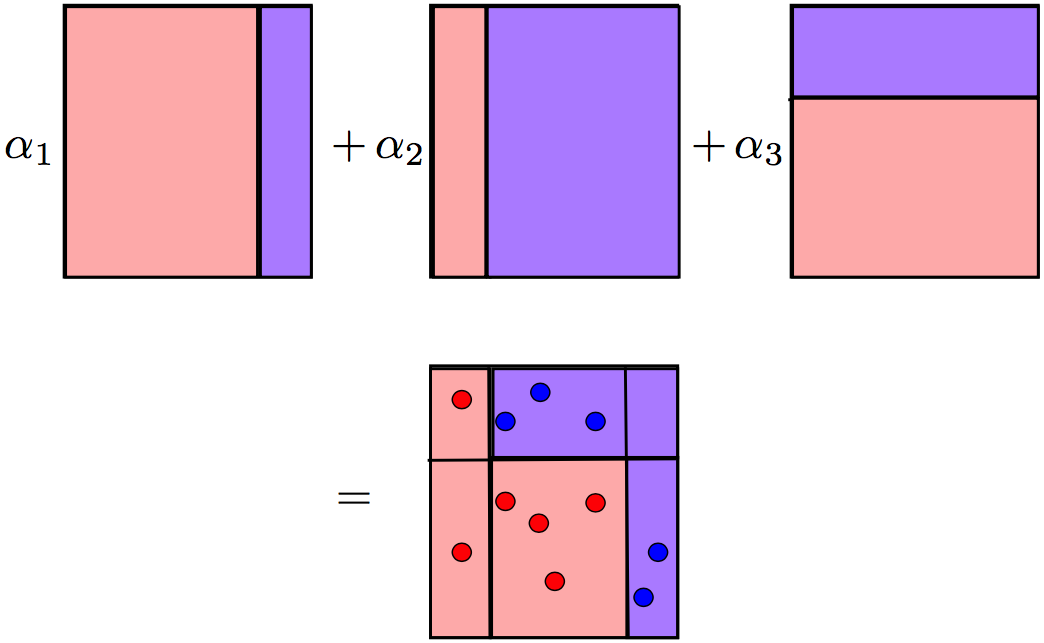
Более подробный пример работы Adaboost, на котором в течение серии итераций видно последовательное увеличение точек, особенно на границе между классами:
Adaboost работал хорошо, но из-за того, что обоснований работы алгоритма с его надстройками было мало, вокруг них возник полный спектр спекуляций: кто-то считал его сверх-алгоритмом и волшебной пулей, кто-то был скептичен и разделял мнение, что это малоприменимый подход с жесткой переподгонкой (overfitting). Особенно сильно это касалось применимости на данных с мощными выбросами, к которым Adaboost оказался неустойчив. К счастью, когда за дело взялась профессура Стэнфордской кафедры статистики, уже принесшая миру Lasso, Elastic Net и Random Forest, в 1999 году от Jerome Friedman появилось обобщение наработок алгоритмов бустинга — градиентный бустинг, он же Gradient Boosting (Machine), он же GBM. Этой работой Friedman сразу задал статистическую базу для создания многих алгоритмов, предоставив общий подход бустинга как оптимизации в функциональном пространстве.
Вообще, команда Стэнфордской кафедры статистики причастна и к CART, и к bootstrap, и еще ко многим вещам, заранее внеся свои имена в будущие учебники статистики. По большому счету значительная часть нашего повседневного инструментария появилась именно там, и кто знает, что еще появится. Или уже появилось, но еще не нашло достаточного распространения (как, например, glinternet).
С самим Friedman-ом не так много видеозаписей. Однако, с ним есть очень интересное интервью про создание CART, и вообще про то, как решали статистические задачки (которые мы бы отнесли к анализу данных и data science) 40+ лет назад:
Из серии познавательной истории анализа данных, есть также лекция от Hastie с ретроспективой анализа данных от одного из участников создания наших с вами ежедневно используемых методов:
 По сути, произошел переход от инженерно-алгоритмических изысканий в построении алгоритмов (так свойственных в ML) к полноценной методологии, как такие алгоритмы строить и изучать. С точки зрения математической начинки, на первый взгляд изменилось не так много: мы всё также добавляем (бустим) слабые алгоритмы, наращивая наш ансамбль постепенными улучшениями тех участков данных, где предыдущие модели "не доработали". Но при построении следующей простой модели, она строится не просто на перевзвешенных наблюдениях, а так, чтобы лучшим образом приближать общий градиент целевой функции. На концептуальном уровне это дало большой простор для фантазии и расширений.
По сути, произошел переход от инженерно-алгоритмических изысканий в построении алгоритмов (так свойственных в ML) к полноценной методологии, как такие алгоритмы строить и изучать. С точки зрения математической начинки, на первый взгляд изменилось не так много: мы всё также добавляем (бустим) слабые алгоритмы, наращивая наш ансамбль постепенными улучшениями тех участков данных, где предыдущие модели "не доработали". Но при построении следующей простой модели, она строится не просто на перевзвешенных наблюдениях, а так, чтобы лучшим образом приближать общий градиент целевой функции. На концептуальном уровне это дало большой простор для фантазии и расширений.
История становления GBM
Свое место в "джентльменском наборе" градиентный бустинг занял не сразу — на это потребовалось больше 10 лет с момента появления. Во-первых, у базового GBM появилось много расширений под разные статистические задачи: GLMboost и GAMboost как усиление уже имеющихся GAM моделей, CoxBoost для кривых дожития, RankBoost и LambdaMART для ранжирования. Во-вторых, появилось много реализаций того же GBM под разными названиями и разных платформах: Stochastic GBM, GBDT (Gradient Boosted Decision Trees), GBRT (Gradient Boosted Regression Trees), MART (Multiple Additive Regression Trees), GBM как Generalised Boosting Machines и прочие. К тому же, сообщества machine learner-ов были достаточно разобщены и занимались всем подряд, из-за этого отследить успехи бустинга достаточно сложно.
В то же время бустинг начали активно применять в задачах ранжирования выдачи поисковых систем. Эту задачу выписали с точки зрения функции потерь, которая штрафует за ошибки в порядке выдачи, так что стало удобно просто вставить ее в GBM. Одними из первых внедрили бустинг в ранжирование AltaVista, а вскоре за ними последовали Yahoo, Yandex, Bing и другие. Причем, говоря о внедрении, речь шла о том, что бустинг на годы вперед становился основным алгоритмом внутри работающих движков, а не еще одной взаимо-заменяемой исследовательской поделкой, живущей в рамках пары научных статей.
 Главную роль в популяризации бустинга сыграли ML соревнования, в особенности kaggle. Исследователям давно не хватало общей платформы, где было бы достаточно участников и задач, чтобы в открытой борьбе за state of the art соревновались люди с их алгоритмами и подходами. Сумрачным немецким гениям, вырастившим у себя в гараже очередной чудо-алгоритм стало нельзя все списывать на закрытые данные, а реальные прорывные библиотеки наоборот получали отличную площадку для развития. Именно это и произошло с бустингом, который прижился на kaggle почти сразу (стоит искать GBM в интервью победителей с 2011 года), а xgboost как библиотека быстро завоевал популярность вскоре после своего появления. При этом xgboost — это не какой-то новый уникальный алгоритм, а просто крайне эффективная реализация классического GBM с некоторыми дополнительными эвристиками.
Главную роль в популяризации бустинга сыграли ML соревнования, в особенности kaggle. Исследователям давно не хватало общей платформы, где было бы достаточно участников и задач, чтобы в открытой борьбе за state of the art соревновались люди с их алгоритмами и подходами. Сумрачным немецким гениям, вырастившим у себя в гараже очередной чудо-алгоритм стало нельзя все списывать на закрытые данные, а реальные прорывные библиотеки наоборот получали отличную площадку для развития. Именно это и произошло с бустингом, который прижился на kaggle почти сразу (стоит искать GBM в интервью победителей с 2011 года), а xgboost как библиотека быстро завоевал популярность вскоре после своего появления. При этом xgboost — это не какой-то новый уникальный алгоритм, а просто крайне эффективная реализация классического GBM с некоторыми дополнительными эвристиками.
И вот мы здесь, в 2017 году, пользуемся алгоритмом, который прошел очень типичный для ML путь от математической задачи и алгоритмических поделок через появление нормальных алгоритмов и нормальной методологии к успешным практическим приложениям и массовому использованию через годы после своего появления.
2. GBM алгоритм
Постановка ML задачи
Мы будем решать задачу восстановления функции в общем контексте обучения с учителем. У нас будет набор пар признаков и целевых переменных , , на котором мы будем восстанавливать зависимость вида . Восстанавливать будем приближением , а для понимания, какое приближение лучше, у нас также будет функция потерь , которую мы будем минимизировать:
Пока что мы не делаем каких-либо предположений ни о типе зависимости , ни о модели наших приближений , ни о распределении целевой переменной . Разве что функция должна быть дифференцируемой. Так как задачу надо решать не на всех данных в мире, а только на имеющихся в нашем распоряжении, перепишем все в терминах матожиданий. А именно, будем искать наши приближения так, чтобы в среднем минимизировать функцию потерь на тех данных, что есть:
К сожалению, функций в мире не просто много — само их функциональное пространство бесконечномерно. Поэтому чтобы хоть как-то решить задачу, в машинном обучении обычно ограничивают пространство поиска каким-нибудь конкретным параметризованным семейством функций . Это сильно упрощает задачу, так как она сводится к уже вполне решаемой оптимизации значений параметров:
Аналитические решения для получения оптимальных параметров в одну строку существуют достаточно редко, поэтому параметры обычно приближают итеративно. Сначала нам надо выписать эмпирическую функцию потерь , показывающую, насколько хорошо мы их оценили по имеющимся у нас данных. Также выпишем наше приближение за итераций в виде суммы (и для наглядности, и чтобы начать привыкать к бустингу):
Дело за малым — осталось только взять подходящий итеративный алгоритм, которым мы будем минимизировать . Самый простой и часто используемый вариант — градиентный спуск. Для него нужно выписать градиент и добавлять наши итеративные оценки вдоль него (со знаком минус — мы же хотим уменьшить ошибку, а не нарастить). И все, надо только как-то инициализировать наше первое приближение и выбрать, сколько итераций мы эту процедуру будем продолжать. В нашем неэффективном по памяти виде хранения приближений наивный алгоритм будет выглядеть следующим образом:
- Инициализировать начальное приближение параметров
- Для каждой итерации повторять:
- Посчитать градиент функции потерь при текущем приближении
- Задать текущее итеративное приближение на основе посчитанного градиента
- Обновить приближение параметров :
- Посчитать градиент функции потерь при текущем приближении
- Сохранить итоговое приближение
- Пользоваться найденной функцией по назначению
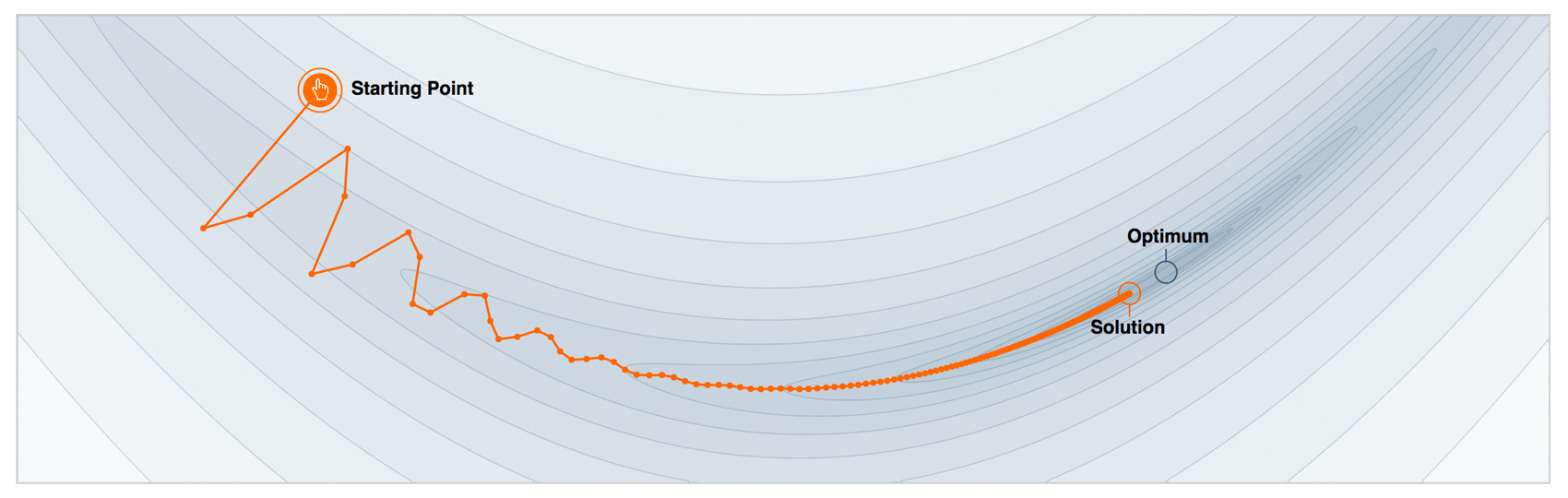
Функциональный градиентный спуск
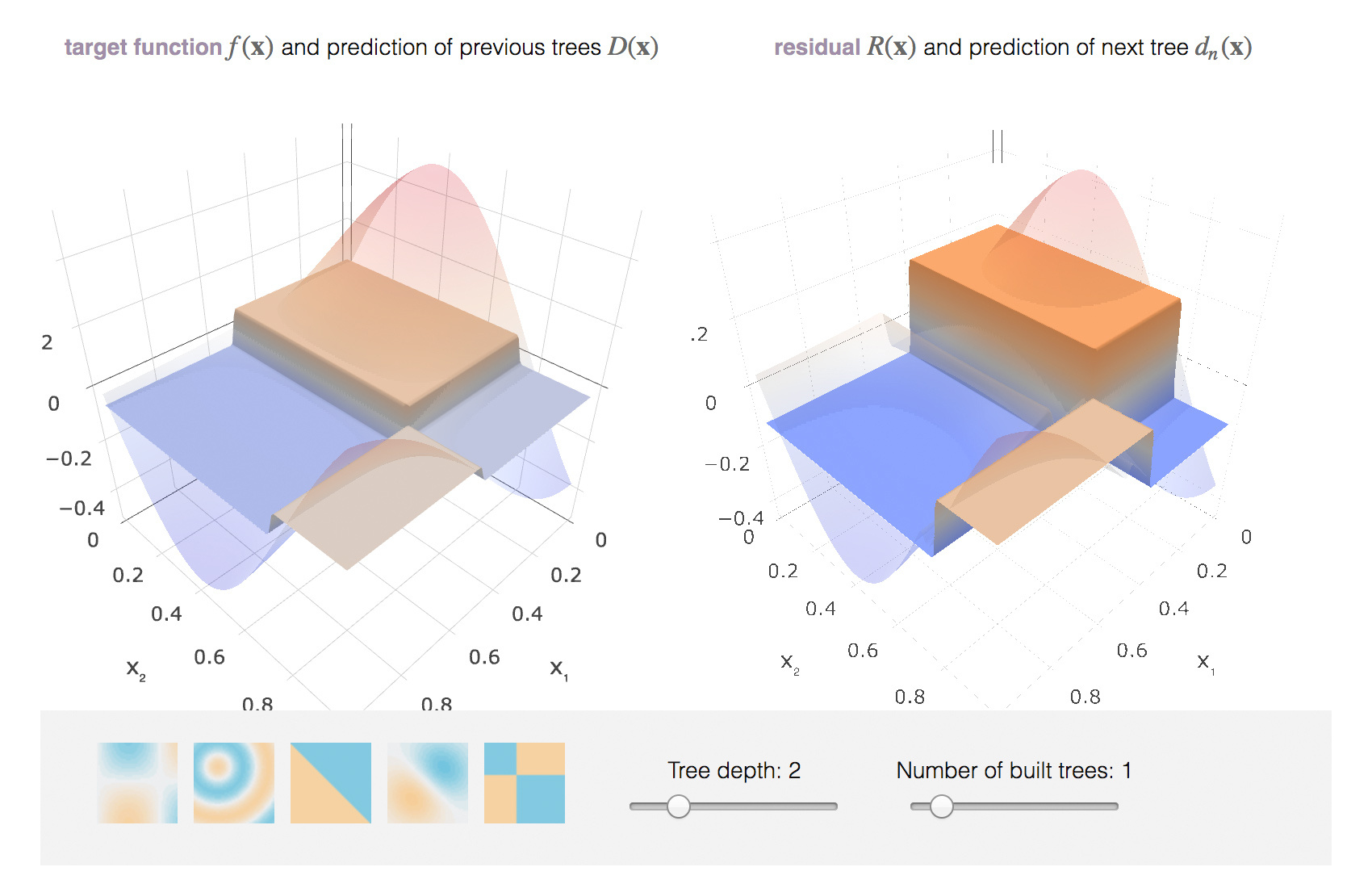
Расширим сознание: представим на секунду, что мы можем проводить оптимизацию в функциональном пространстве и итеративно искать приближения в виде самих функций. Выпишем наше приближение в виде суммы инкрементальных улучшений, каждое из которых является функцией. Для удобства сразу будем считать эту сумму, начиная с начального приближения :
Магии пока не случилось, мы просто решили, что будем искать наше приближение не в виде одной большой модели с кучей параметров (как, например, нейросеть), а в виде суммы функций, делая вид, что таким образом мы двигаемся в функциональном пространстве.
Чтобы решить задачу, нам все равно придется ограничить свой поиск каким-то семейством функций . Но, во-первых, сумма моделей может быть сложнее чем любая модель из этого семейства (сумму двух деревьев-пней глубины 1 уже не приблизить одним пнем). Во-вторых, общая задача все еще происходит в функциональном пространстве. Сразу учтем, на каждом шаге для функций нам понадобится подбирать оптимальный коэффициент . Для шага задача выглядит следующим образом:
А вот теперь время магии. Мы выписывали все наши задачи в общем виде, словно мы можем просто так брать и обучать какие угодно модели относительно каких угодно функций потерь . На практике это крайне сложно, поэтому был придуман простой способ свести задачу к чему-то решаемому.
Зная выражение градиента функции потерь, мы можем посчитать его значения на наших данных. Так давайте обучать модели так, чтобы наши предсказания были наиболее скоррелированными с этим градиентом (со знаком минус). То есть будем решать задачу МНК-регрессии, пытаясь выправлять предсказания по этим остаткам. И для классификации, и для регрессии, и для ранжирования под капотом мы все время будем минимизировать квадрат разности между псевдо-остатками и нашими предсказаниями. Для шага итоговая задача выглядит следующим образом:

Классический GBM алгоритм Friedman-а
Теперь у нас есть все необходимое, чтобы наконец выписать GBM алгоритм, предложенный Jerome Friedman в 1999 году. Мы все так же решаем общую задачу обучения с учителем. На вход алгоритма нужно собрать несколько составляющих:
- набор данных ;
- число итераций ;
- выбор функции потерь с выписанным градиентом;
- выбор семейства функций базовых алгоритмов , с процедурой их обучения;
- дополнительные гиперпараметры , например, глубина дерева у деревьев решений;
Единственный момент, который остался без внимания — начальное приближение . Для простоты, в качестве инициализации используют просто константное значение . Его, а также оптимальный коэффициент находят бинарным поиском, или другим line search алгоритмом относительно исходной функции потерь (а не градиента). Итак, GBM алгоритм:
- Инициализировать GBM константным значением
- Для каждой итерации повторять:
- Посчитать псевдо-остатки
- Построить новый базовый алгоритм как регрессию на псевдо-остатках
- Найти оптимальный коэффициент при относительно исходной функции потерь
- Сохранить
- Обновить текущее приближение
- Посчитать псевдо-остатки
- Скомпоновать итоговую GBM модель
- Покорять kaggle и мир обученной моделью (предсказания там делать, сами разберетесь)
Пошаговый пример работы GBM
Попробуем на игрушечном примере разобраться, как работает GBM. Будем с его помощью восстанавливать зашумленную функцию .
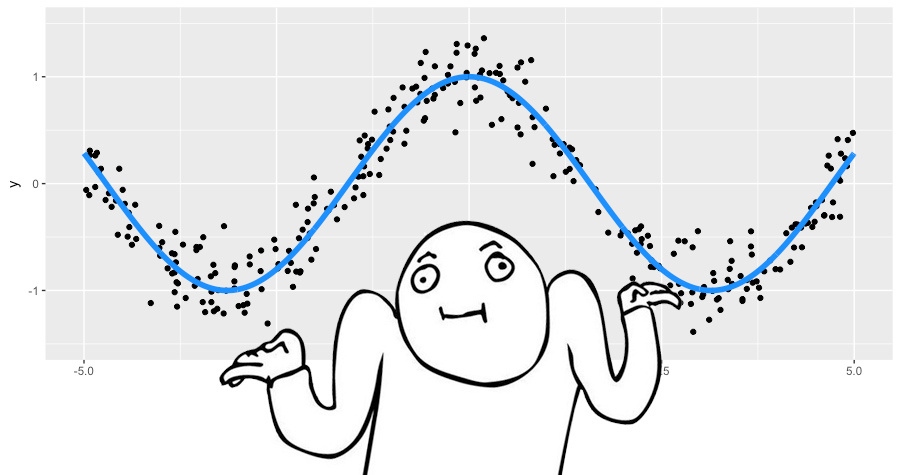
Это задача регрессии на вещественную целевую переменную, поэтому воспользуемся средне-квадратичной функцией потерь. Самих пар наблюдений мы сгенерируем 300 штук, а приближать будем деревьями решений глубины 2. Соберем вместе все, что нам нужно для применения GBM:
- Игрушечные данные ?
- Число итераций ?;
- Среднеквадратичная функция потерь ?
Градиент loss это просто остатки ?; - Деревья решений в качестве базовых алгоритмов ?;
- Гиперпараметры деревьев решений: глубина деревьев равна 2 ?;
У среднеквадратичной ошибки все просто и с инициализацией и с коэффициентами . А именно, инициализировать GBM мы будем средним значением , а все равны 1.
Запустим GBM и будем рисовать два типа графиков: актуальное приближение (синий график), а также каждое построенное дерево на своих псевдо-остатках (зеленый график). Номер графика соответствует номеру итерации:
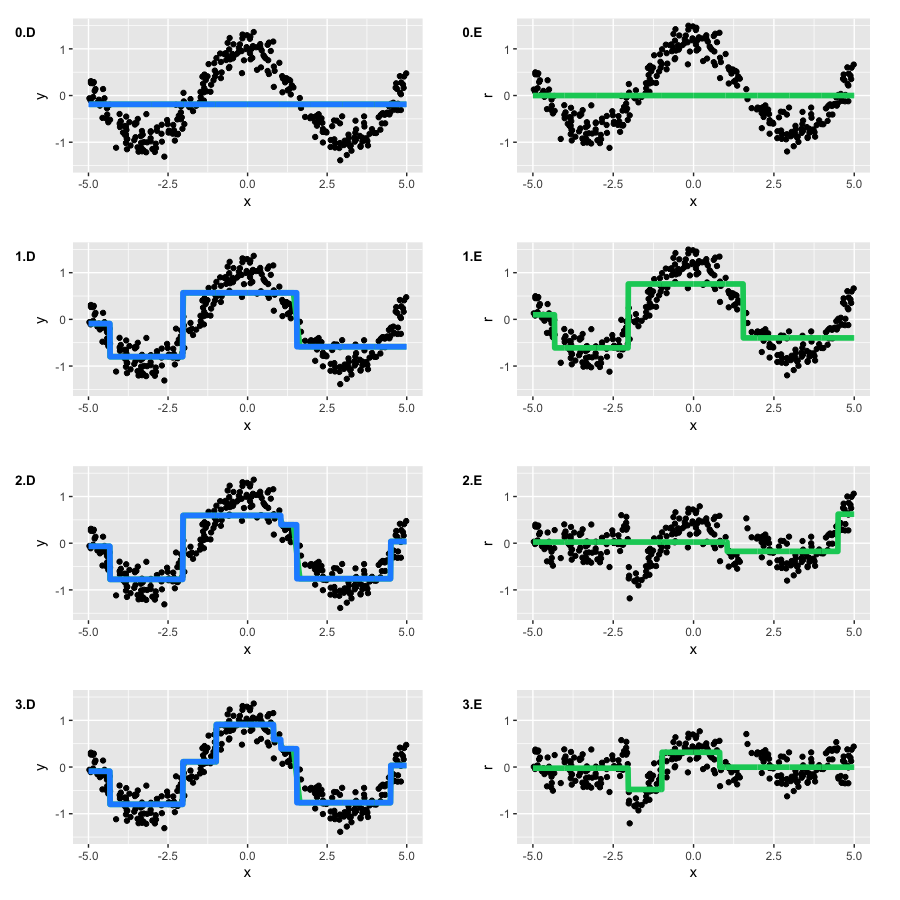
Заметим, что ко второй итерации наши деревья повторили основную форму функции. Однако, на первой итерации мы видим, что алгоритм построил только "левую ветвь" функции (). Так получилось банально потому, что нашим деревьям не хватило глубины, чтобы построить симметричную ветку сразу, а ошибка на левой ветви была больше. Так что, правая ветвь "проросла" только на второй итерации.
В остальном процесс прошел так как мы и ожидали: на каждом шаге наши псевдо-остатки уменьшались, а GBM все ближе приближал исходный косинус. Однако, деревья по построению не могут приблизить непрерывную функцию, поэтому на этом примере GBM полезен, но не идеален. Чтобы самим поиграться с тем, как GBM приближает функции, в блоге Brilliantly wrong есть офигенная интерактивная демка:
3. Функции потерь
Что делать, если мы хотим решать не обычную среднеквадратичную регрессию, а, скажем, задачу бинарной классификации? Нет проблем, надо только выбрать соответствующую задаче и целевой переменной функцию потерь . Это самый важный верхнеуровневый момент, определяющий что именно мы будем оптимизировать, и какие свойства ожидать от нашей итоговой модели.
Как правило, самим нам ничего придумывать и выписывать не надо — исследователи уже все сделали за нас. Сегодня мы разберем функции потерь двух самых часто встречающихся задач: регрессии и бинарной классификации . Что делать с многоклассовой классификаций, рангами, а также всякими промежуточными случаями вроде целочисленной регрессии, расскажем в другой раз.
Функции потерь регрессии
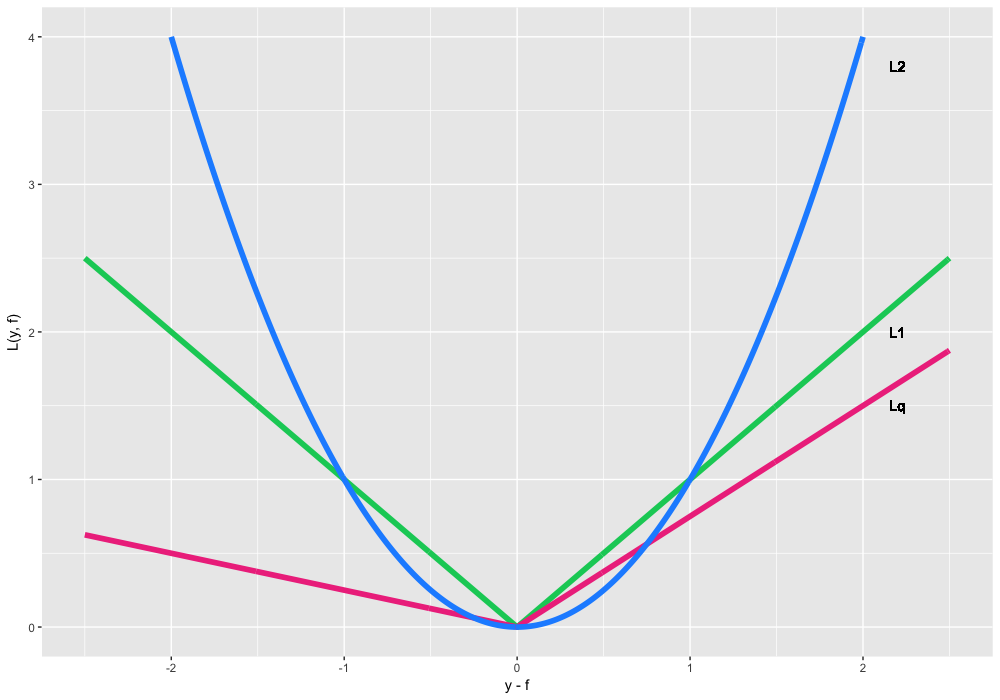
Сначала разберемся с регрессией . Выбирая функцию потерь в этом случае, мы прежде всего решаем, какое именно свойство условного распределения мы хотим восстановить. Наиболее частые варианты:
- , оно же loss, оно же Gaussian loss. Это классическое условное среднее, самый частый и простой вариант. Если нет никакой дополнительной информации или требований к устойчивости (робастности) модели — используйте его.
- , оно же loss, оно же Laplacian loss. Эта, на первый взгляд, не очень дифференцируемая вещь, на самом деле определяет условную медиану. Медиана, как мы знаем, более устойчива к выбросам, поэтому в некоторых задачах эта функция потерь предпочтительнее, так как она не так сильно штрафует большие отклонения, нежели квадратичная функция.
- , оно же loss, оно же Quantile loss. Если бы мы, допустим, захотели не условную медиану с , а условную 75%-квантиль, мы бы воспользовались этим вариантом с . Можно видеть, что эта функция ассиметрична и больше штрафует наблюдения, оказывающиеся по нужную нам сторону квантили.
Давайте попробуем воспользоваться функцией потерь на наших игрушечных данных, пытаясь восстановить условную 75%-квантиль косинуса. Соберем все воедино:
- Игрушечные данные ?
- Число итераций ?;
- Квантильная функция потерь ?;
- Градиент — индикаторная функция, взвешенная нашим . Мы будем обучать деревья чему-то, очень похожему на классификатор:
?; - Деревья решений в качестве базовых алгоритмов ?;
- Гиперпараметры деревьев решений: глубина деревьев равна 2 ?;
У нас есть очевидное начальное приближение — просто взять нужную нам квантиль . Однако, про оптимальные коэффициенты нам ничего не известно, так что воспользуемся стандартным line search. Посмотрим, что у нас получилось:
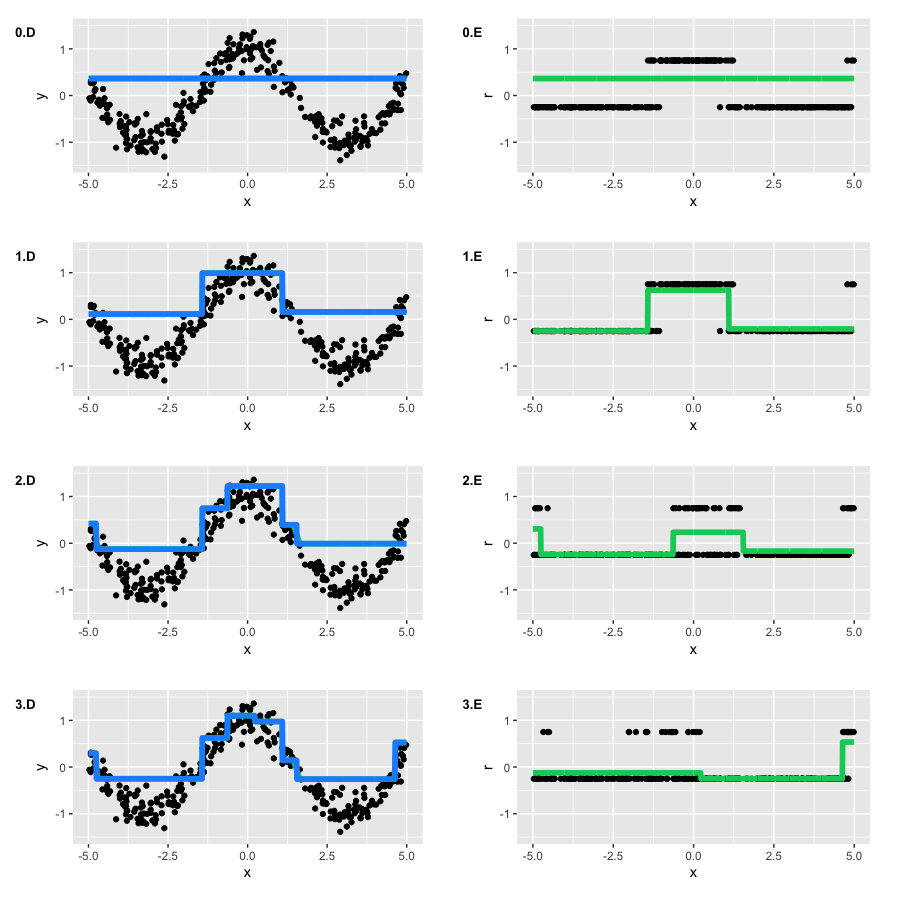
Непривычно видеть, что по факту мы обучаем что-то очень непохожее на обычные остатки — на каждой итерации принимают только два возможных значения. Однако, результат работы GBM достаточно похож на нашу исходную функцию.
Если оставить алгоритм обучаться на этом игрушечном примере, мы получим почти такой же результат, что и с квадратичной функцией потерь, смещенный на . Но если бы мы искали квантили выше 90%, могли бы возникнуть вычислительные трудности. А именно, если соотношение числа точек выше нужной квантили будет слишком мало (как несбалансированные классы), модель не сможет качественно обучиться. Про такие нюансы стоит задумываться, решая нетипичные задачи.
Для задачи регрессии разработано достаточно много функций потерь, в том числе с дополнительными свойствами робастности. Один такой пример — функция потерь Губера, она же Huber loss. Суть функции в том, что на небольших отклонениях она работает как , а с заранее заданного порога, начинает работать как . Это позволяет уменьшить вклад выбросов и следующих за ними квадратично-больших ошибок на общий вид функции, при этом не акцентируя внимание на мелких неточностях и отклонениях.
Можно посмотреть, как работает эта функция потерь на следующем игрушечном примере. За основу возьмем игрушечные данные функции , к которым был добавлен специальный шум: смесь из Гауссовского распределения и распределения Бернулли, выступающего в роли одностороннего генератора выбросов. Сами функции потерь приведены на графиках A-D, а соответствующие им GBM — на графиках F-H (на графике E — исходная функция):
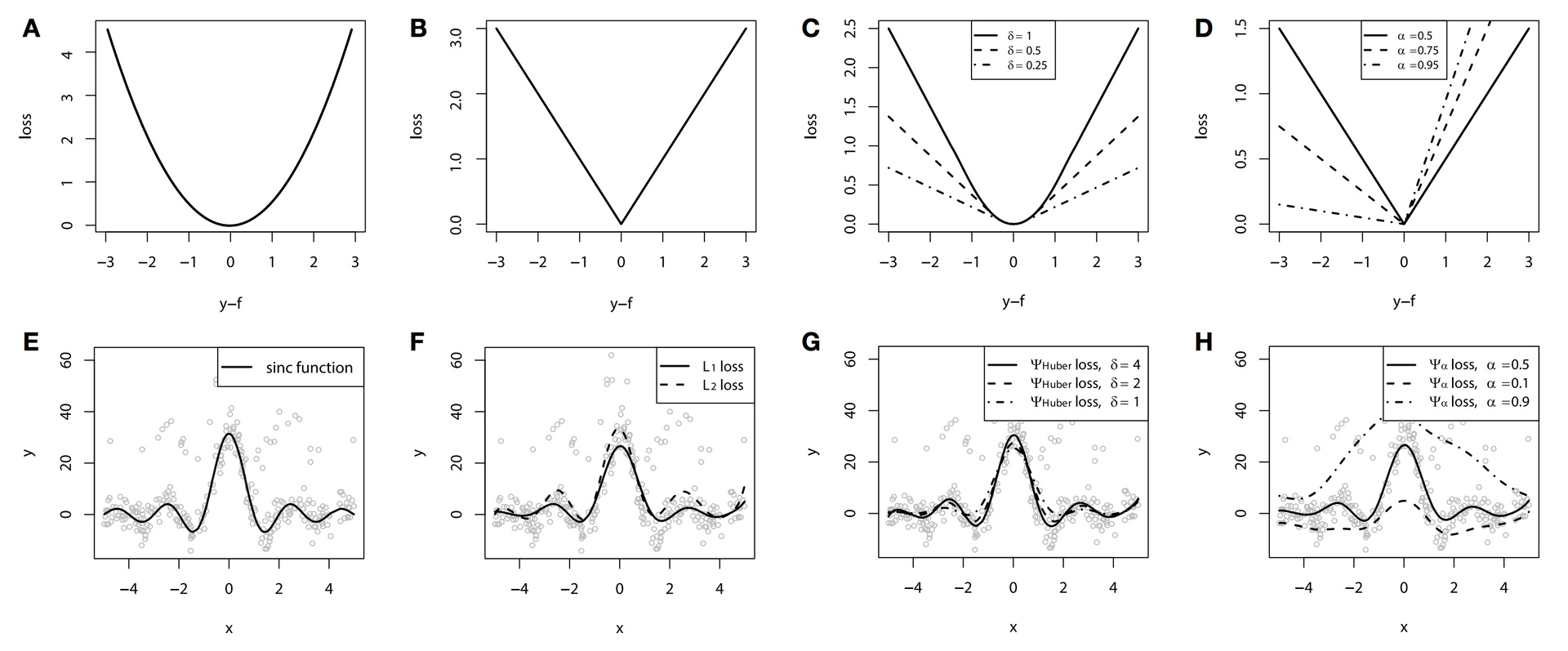
В этом примере в качестве базовых алгоритмов для визуальной наглядности были использованы сплайны. Мы ведь уже говорили, что бустить можно не только деревья? О том, какие базовые алгоритмы чаще используются в бустинге и какие у них свойства, мы расскажем в следующей статье про GBM (часть 2). Мы все равно находимся в бонусной секции курса, куда заглянут только самые стойкие, так что легкие спойлеры позволительны.
По результатам примера, из-за искусственно созданной проблемы с шумом разница между , и Huber loss достаточно заметна. При грамотном подборе параметра Huber loss мы даже получим наилучшую аппроксимацию функции среди наших вариантов. А еще на этом примере хорошо видна разница в условных квантилях (10%, 50% и 90% в нашем случае).
К сожалению, функция Huber loss реализована не во всех современных библиотеках (в h2o реализована, в xgboost еще нет). Это же касается и других интересных функций потерь, включая и условные квантили, и такие экзотические вещи как условные экспектили. Но в целом, достаточно полезно знать о том, что такие варианты существуют и ими можно пользоваться.
Функции потерь классификации
Теперь разберем бинарную классификацию, когда . Мы уже видели, что с помощью GBM можно оптимизировать даже не очень дифференцируемые функции потерь. И вообще, можно было бы, не задумываясь, попытаться решить этот случай как еще одну задачу регрессии с каким-нибудь loss, но это будет не очень правильно (хотя и возможно).
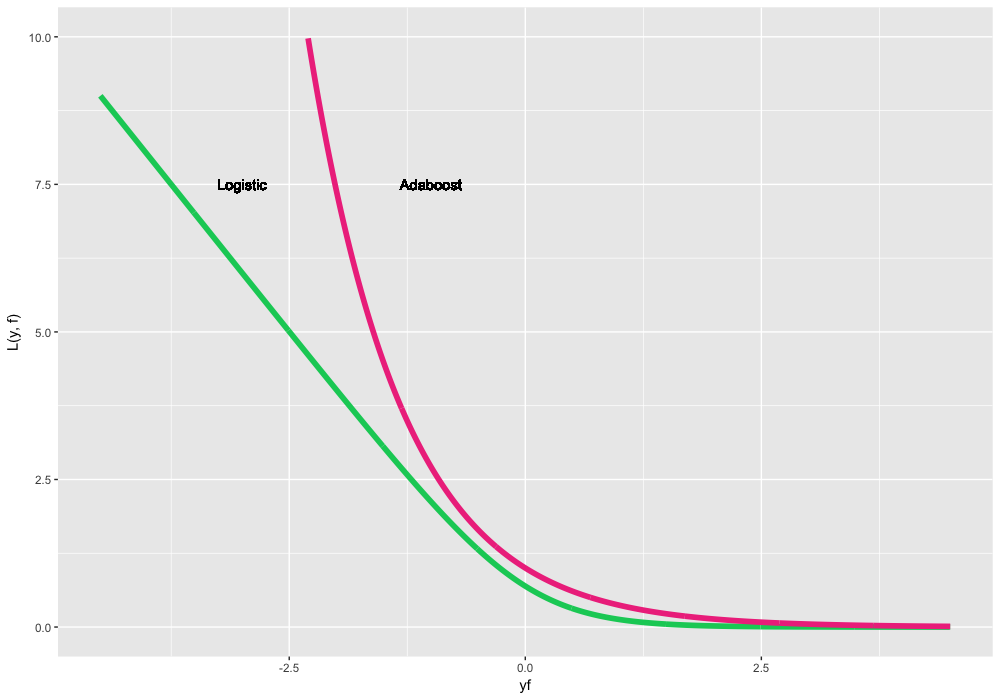
Из-за принципиально другой природы распределения целевой переменной, будем предсказывать и оптимизировать не сами метки классов, а их log-правдоподобие. Для этого переформулируем функции потерь над перемноженными предсказаниями и истинными метками (не спроста же мы выбрали метки разных знаков). Наиболее известные варианты таких классификационных функций потерь:
- , она же Logistic loss, она же Bernoulli loss. Интересное свойство заключается в том, что мы штрафуем даже корректно предсказанные метки классов. Нет, это не баг. Наоборот, оптимизируя эту функцию потерь, мы можем продолжать "раздвигать" классы и улучшать классификатор даже если все наблюдения предсказаны верно. Это самая стандартная и часто используемая функция потерь в бинарной классификации.
- , оно же Adaboost loss. Так получилось, что классический Adaboost алгоритм эквивалентен GBM с этой функцией потерь. Концептуально эта функция потерь очень похожа на Logistic loss, но имеет более жесткий экспоненциальный штраф на ошибки классификации и используется реже.
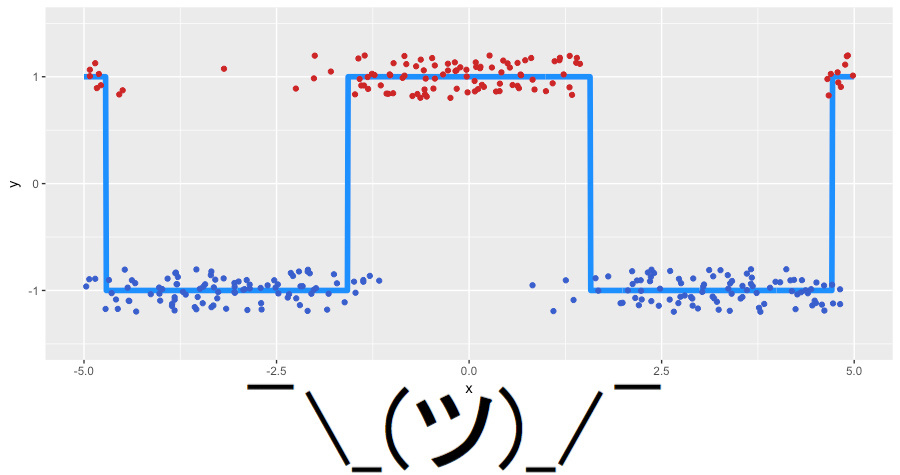
Сгенерируем новые игрушечные данные для задачи классификации. За основу возьмем наш зашумленный косинус, а в качестве классов целевой переменной будем использовать функцию sign. Новые данные выглядят следующим образом (jitter-шум добавлен для наглядности):
Воспользуемся Logistic loss, чтобы посмотреть, что же мы на самом деле бустим. Как и прежде, соберем воедино то, что будем решать:
- Игрушечные данные ?
- Число итераций ?;
- В качестве функции потерь — Logistic loss, ее градиент считается так:
?; - Деревья решений в качестве базовых алгоритмов ?;
- Гиперпараметры деревьев решений: глубина деревьев равна 2 ?;
В этот раз с инициализацией алгоритма все немного сложнее. Во-первых, наши классы несбалансированы и разделены в пропорции примерно 63% на 37%. Во-вторых, аналитической формулы для инициализации для нашей функции потерь неизвестно. Так что будем искать поиском:
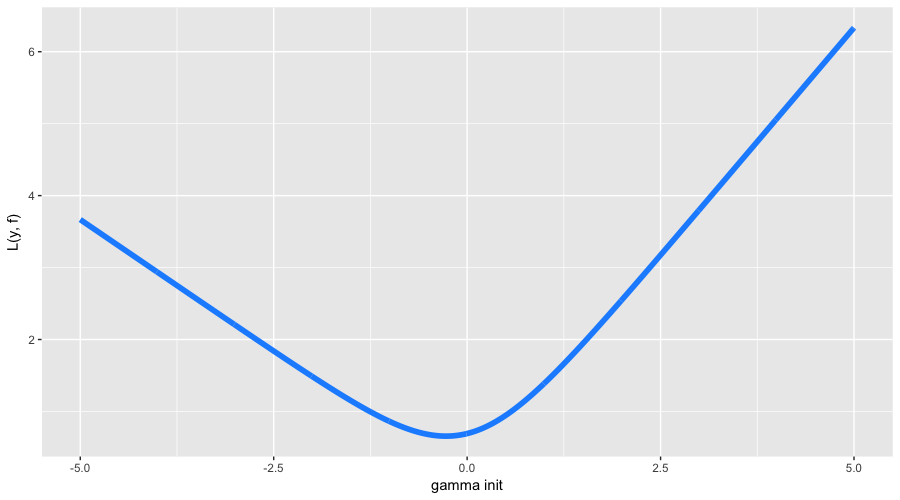
Оптимальное начальное приближение нашлось в районе -0.273. Можно было догадаться, что оно будет отрицательным (нам выгоднее предсказывать всех наиболее популярным классом), но формулы точного значения, как мы уже сказали, нет. А теперь давайте наконец уже запустим GBM и посмотрим, что же на самом деле происходит под его капотом:
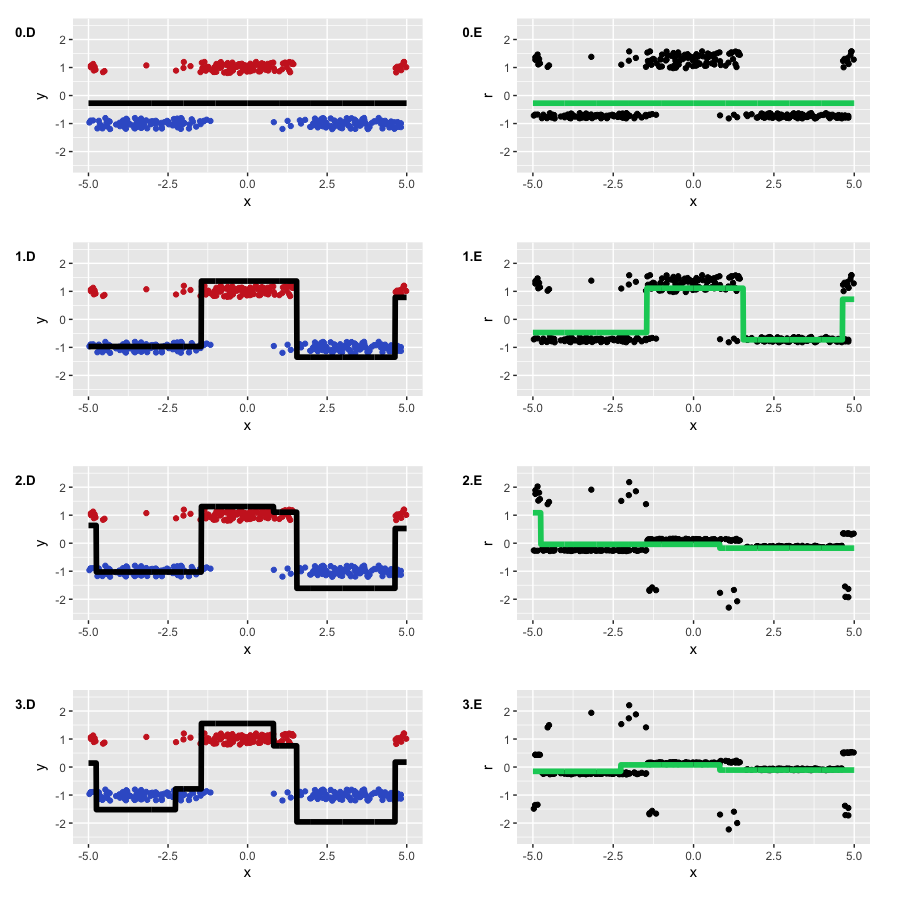
Алгоритм отработал успешно, восстановив разделение наших классов. Можно видеть, как отделяются "нижние" области, в которых деревья больше уверены в корректном предсказании отрицательного класса, и как формируются две ступеньки, где классы были перемешаны. На псевдо-остатках видно, что у нас есть достаточно много корректно классифицированных наблюдений, и какое-то количество наблюдений с большими ошибками, которые появились из-за шума в данных. Как-то выглядит то, что на самом деле предсказывает GBM в задаче классификации (регрессия на псевдо-остатках логистической функции потерь).
Веса
Иногда возникает ситуация, когда для задачи хочется придумать более специфичную функцию потерь. Например, в предсказании финансовых рядов мы можем захотеть придавать больший вес крупным движениям временного ряда, а в задаче предсказания клиентского оттока — лучше предсказывать отток у клиентов с высоким LTV (lifetime value, сколько денег клиент нам принесет в будущем).

Истинный путь статистического воина — придумать свою функцию потерь, выписать для нее производную (а для более эффективного обучения, еще и Гессиан), и тщательно проверить, удовлетворяет ли эта функция требуемым свойствам. Однако, высока вероятность где-то ошибиться, столкнуться с вычислительными трудностями, да и в целом потратить непозволительно много времени на исследования.
Вместо этого был придуман очень простой инструмент, о котором редко вспоминают на практике — взвешивание наблюдений и задание весовых функций. Простейший пример такого взвешивания — задание весов для балансировки классов. В общем случае, если мы знаем, что какое-то подмножество данных, как во входных переменных , так и в целевой переменной имеет большую значимость для нашей модели, мы просто задаем им больший вес . Главное — выполнить общие требования разумности весов:
Веса позволяют существенно сократить время на подстройку самой функции потерь под решаемую задачу, а также поощряют эксперименты с целевыми свойствами моделей. Как именно задавать эти веса — исключительно наша творческая задача. С точки зрения GBM алгоритма и оптимизации, мы просто добавляем скалярные веса, закрывая глаза на их природу:
Понятно, что для произвольных весов мы не знаем никаких красивых статистических свойств нашей модели. В общем случае, привязывая веса к значениям , мы можем прострелить себе колено. Например, использование весов, пропорциональных в функции потерь — не эквивалентно loss, так как градиент не будет учитывать значения самих предсказаний .
Мы обсуждаем все это, чтобы лучше понимать наши возможности. Давайте придумаем какой-нибудь очень экзотический пример весов на наших игрушечных данных. Зададим сильно асимметричную весовую функцию следующим образом:
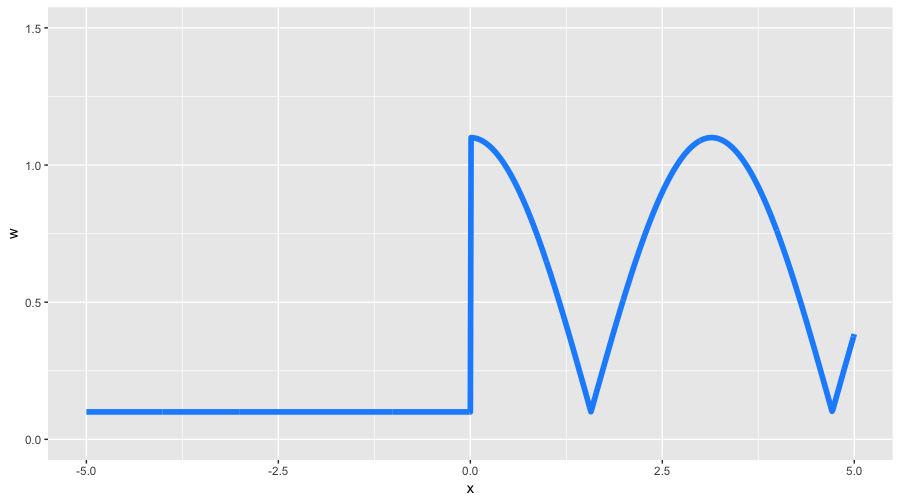
С помощью таких весов мы ожидаем увидеть два свойства: меньшую детализацию на отрицательных значениях , а также форму функции, в большей степени похожую на исходный косинус. Все остальные настройки GBM мы берем из нашего предыдущего примера с классификацией, включая line search для оптимальных коэффициентов. Посмотрим, что у нас получилось:
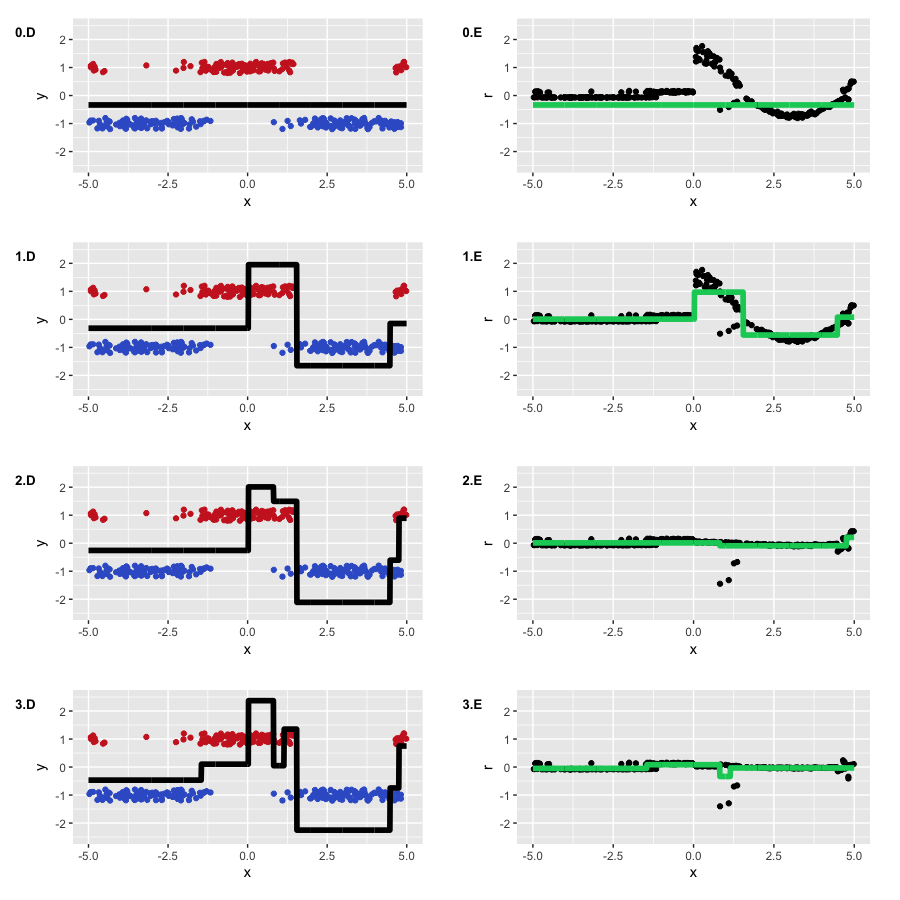
Результат получился, какой мы и ожидали. Во-первых, видно, насколько сильно у нас стали отличаться псевдо-остатки, на начальной итерации во многом повторяя наш исходный косинус. Во-вторых, левая часть графика функции была во многом проигнорирована в пользу правой, имевшей большие веса. В-третьих, полученная нами функция на третьей итерации получила достаточно много деталей, став больше похожей на исходный косинус (а также, начав легкую переподгонку).
Веса — это мощный инструмент, который, на наш страх и риск, позволяет существенно управлять свойствами нашей модели. Если вы хотите оптимизировать свою функцию потерь, стоит сначала попробовать решить более простую задачу, но добавив в нее веса наблюдений по своему усмотрению.
4. Итог про теорию GBM
Сегодня мы разобрали основную теорию про градиентный бустинг. GBM — это не просто какой-то конкретный алгоритм, а общая методология, как строить ансамбли моделей. Причем методология достаточно гибкая и расширяемая: можно обучать большое количество моделей с учетом различных функций потерь и при этом еще и навешивать на них разного рода весовые функции.
Как показывает и практика, и опыт соревнований по машинному обучению, в стандартных задачах (все кроме картинок и аудио, а также сильно разреженных данных), GBM очень часто является самым эффективным алгоритмом (не считая stacking-а и верхнеуровневых ансамблей, где GBM почти всегда является неотъемлемой их частью). При этом существуют адаптации GBM под Reinforcement Learning (Minecraft, ICML 2016), а алгоритм Виола-Джонса, до сих пор используемый в компьютерном зрении, основан на Adaboost.
В этой статье мы специально опустили вопросы, связанные с регуляризацией GBM, стохастичностью, а также связанными с ними гиперпараметрами алгоритма. Неспроста мы везде выбирали маленькое число итераций алгоритма, . Если бы мы выбрали не 3, а 30 деревьев, и запустили GBM как описали выше, результат вышел бы не таким предсказуемым:

О том, что делать в подобных ситуациях, и как взаимосвязаны друг с другом параметры регуляризации GBM, а также гиперпараметры базовых алгоритмов, мы расскажем в следующей статье. В ней же мы разберем современные пакеты — xgboost, lightgbm и h2o, а также попрактикуемся в их правильной настройке. А пока мы предлагаем вам поиграться с настройками GBM в еще одной очень крутой интерактивной демке Brliiantly wrong:

5. Домашнее задание №10
Сегодня мы разбирались с теорией GBM и функциями потерь. Так как мы еще не рассказали про GBM на практике и реальных задачах, задание будет привязано только к пройденной теории.
Вам необходимо самостоятельно реализовать GBM алгоритм, пользуясь готовыми функциями для построения деревьев. Также необходимо реализовать обучение GBM для RMSLE и RMSPE метрик, самостоятельно выписав соответствующие им функции потерь (и их градиенты).
Ссылки на домашнее задание будут выданы комментарием к этой статье в течение суток с момента публикации.
6. Полезные ссылки
- Оригинальная статья про GBM от Jerome Friedman
- Глава в Elements of Statistical Learning от Hastie, Tibshirani, Friedman (стр. 337)
- Wiki статья про Gradient Boosting
- Frontiers tutorial статья про GBM (лайтовый самопиар)
- Видео-лекция Hastie про GBM на h2o.ai конференции
- Видео-лекция Владимира Гулина про композиции алгоритмов от Техносферы
- Видео-лекции Константина Воронцова (часть 1, часть 2) про композиции алгоритмов от Школы Анализа Данных
Особая благодарность yorko (Юрию Кашницкому) за ценные комментарии, а также bauchgefuehl (Анастасии Манохиной) за помощь с редактированием.
Комментарии (10)

vylyky
19.05.2017 16:00+1Алексей, понимаю что это мелочи, но все же, у Вас в тексте статьи не отобразились пару формул. Статья хорошая, не все ещё понял, буду разбираться. Спасибо.

natekin
19.05.2017 16:02+1Спасибо :)
Мы попробовали пофиксить этот косяк, но к сожалению, на мобильной версии Хабра ломаются \begin{equation} формулы. Сперва думали, что дело в переносах строк, но это не помогло.

yorko
20.05.2017 18:50+1Участникам курса
Продублирую здесь информацию по окончанию курса. Что еще нас ожидает:
- Домашняя работа №10 (~ 22 мая появится, времени на нее – неделя)
- Тьюториалы, которые вы сами можете написать. Подробности тут (до 31 мая)
- Соревнования Kaggle Inclass (до 29 мая)
Встреча в московском офисе Mail.ru Group, посвященная финалу курса, пройдет 10 июня (а не в мае, как раньше предполагалось)
yorko
20.05.2017 18:55+1И еще ~ 1 июня выйдет 2 часть по бустингу, уже без домашнего задания либо с заданием по желанию.
yorko
20.05.2017 19:05+2Финальный рейтинг складывается из:
- текущего рейтинга
- 10 домашки (макс. 10 баллов)
- тьюториалов (макс. 40 баллов)
- соревнований (макс. по 40 баллов за каждое из двух)
В веб-форме 10 домашки спросим, кто готов посетить митап 10 июня в московском офисе Mail.ru. Отвечать "да" стоит, если Вам это интересно, есть возможность приехать в Москву, а также если Вы попадаете в топ 200 рейтинга. Приглашены будут топ 100 по рейтингу, но очевидно, кто-то откажется, поэтому ставьте "да", если попадаете в топ 200.
Программа митапа 10 июня будет оглашена позже, но там точно будет лекция и практика по нейронным сетям (CNN и RNN), будут рассмотрены приложения к задачам текстовой аналитики.

Phaker
25.05.2017 23:39+1А зачем в logistic loss двойка?
log(1 + exp(-2yf))
Я понимаю, что это ни на что принципиально не влияет, просто масштабный коэффициент, но всё же обычно обходятся без него.
natekin
26.05.2017 15:11Двойка действительно мало на что влияет, кроме исторически сложившегося описания через odds ratio. Даже, вообще говоря, двух обоснований: и через биномиальное лог правдоподобие, и через кросс-энтропию (да, оптимизируем то же самое).
Я хотел подчистую скопипастить оригинальный вывод из Elements of Statistical Learning, там ровно одна страница 346 (365 в pdf), "10.5 Why Exponential Loss?". Но чтото у меня ТеХ в комментах не работает :(
А с инженерной точки зрения, эта двойка ни на что не влияет, кроме сравнения разных реализаций (чтобы числа одинаковые в обучении получались).
Gewissta
По-моему, замечательно. Просьба, Алексей, когда будете писать вторую часть, затронуть такую интересную штуку, как partial dependency plots, особенности интерпретации таких графиков. И сразу вопрос, планируете затронуть настройки класса H2OGradientBoostingEstimator для scikit-learn?
natekin
Спасибо :)
Да, PDP планируются. И да, настройки H2O GBM тоже разберем. По-крайней мере, основные. H2O просто сильно угарели, и запилили штук 30 дополнительных настроек и небольших твиков. Все настройки перебирать смысла нет, обычно достаточно дергать 3-4 ручки (как именно как раз и будем разбираться).