
Понимание модели ввода/вывода вашего приложения может привести и к пониманию различий между приложением, работающим с нагрузкой, под которой оно создавалось, и тем, которое лицом к лицу столкнулось с реальным способом своего применения. Возможно, если ваше приложение невелико и не создаёт большой нагрузки, то для него это не так важно. Но по мере роста трафика использование ошибочной модели ввода/вывода может погрузить вас в мир боли.
Как и в большинстве других ситуаций с несколькими возможными решениями, дело не в том, какой из вариантов лучше, дело в понимании компромиссов. В этой статье мы сравним Node, Java, Go и PHP из-под Apache, обсудим модели ввода/вывода в разных языках, рассмотрим достоинства и недостатки каждой модели и прогоним простенькие бенчмарки. Если вас волнует производительность ввода/вывода вашего следующего веб-приложения, то эта статья для вас.
Основы ввода/вывода: освежим знания
Для понимания факторов, относящихся к вводу/выводу, сначала нужно вспомнить некоторые концепции, используемые на уровне ОС. Маловероятно, что со многими из них вам придётся иметь дело напрямую, скорее всего, вы будете работать с ними опосредованно, через runtime-окружение приложения. И подробности играют важную роль.
Системные вызовы
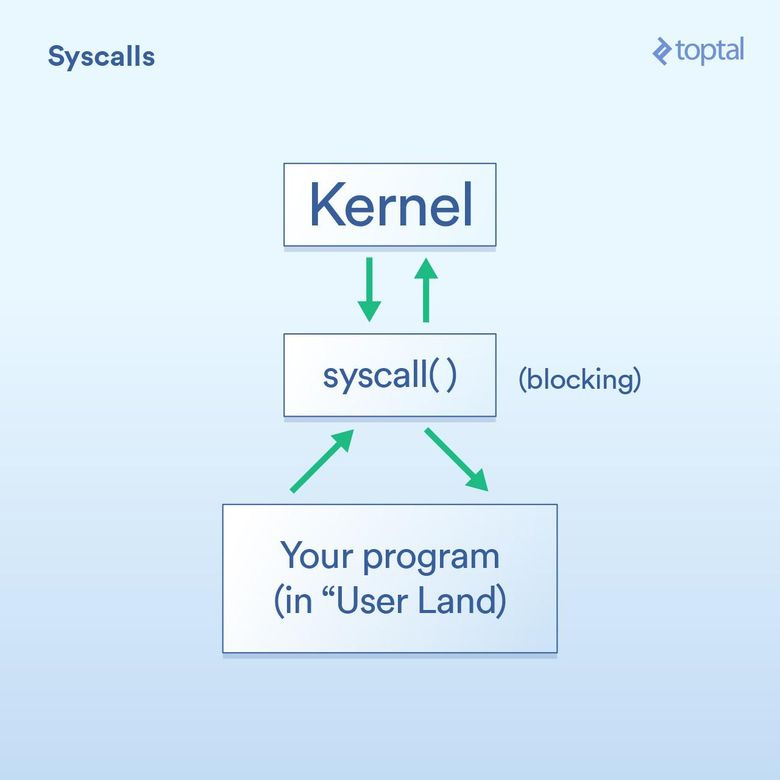
Возьмём сначала системные вызовы, которые можно описать так:
Ваша программа (в так называемом пользовательском пространстве) должна просить ядро операционной системы выполнить операцию ввода/вывода от имени вашей программы.
Системные вызовы — это способ, с помощью которого программа просит ядро что-то сделать. Специфика их реализаций зависит от ОС, но базовый принцип везде один и тот же. Должна быть какая-то конкретная инструкция для передачи управления из вашей программы через ядро (как вызов функции, только со специальной «добавкой» для работы в такой ситуации). В целом системные вызовы блокирующие, т. е. программа ждёт, пока ядро не вернётся к вашему коду.
- Ядро выполняет базовую операцию ввода/вывода на нужном устройстве (диске, сетевой карте и т. д.) и отвечает системному вызову. В реальной жизни ядро может выполнять целый ряд действий после вашего запроса, включая ожидание готовности устройства, обновление его внутреннего состояния и т. д. Но вам об этом не нужно беспокоиться. Это обязанности ядра.
Блокирующие и неблокирующие вызовы
Выше говорилось, что системные вызовы — блокирующие, и в целом это так. Однако некоторые вызовы можно охарактеризовать как неблокирующие. Это означает, что ядро принимает ваш запрос, кладёт его в очередь или какой-то буфер, а затем безо всякого ожидания немедленно возвращается к выполняемому в данный момент вводу/выводу. Так что «блокирование» происходит лишь на очень небольшой период времени, достаточный для постановки вашего запроса в очередь.
Чтобы было понятнее, вот некоторые примеры (системных вызовов Linux):
read()— блокирующий вызов: вы передаёте ему дескриптор (handle), говорящий, какой файл взять и в какой буфер доставить считываемые данные; вызов возвращается, когда данные окажутся в месте назначения. Всё просто и понятно.epoll_create(),epoll_ctl()иepoll_wait()— вызовы, которые, соответственно, позволяют создавать группу дескрипторов для прослушивания; добавлять дескрипторы в группу / удалять их из неё; блокировать до тех пор, пока не появится активность. Это позволяет эффективно управлять большим количеством операций ввода/вывода с помощью одного потока выполнения. Хорошо, что есть такая функциональность, но её довольно сложно использовать.
Важно понимать различия в тайминге. Если ядро процессора работает на частоте 3 ГГц, без каких-либо оптимизаций, то оно выполняет 3 миллиарда тактов в секунду (3 такта в наносекунду). Для неблокирующего системного вызова могут потребоваться десятки тактов, то есть несколько наносекунд. Вызов, блокирующий получение информации по сети, может выполняться гораздо дольше: например, 200 миллисекунд (1/5 секунды). То есть если неблокирующий вызов длится 20 наносекунд, то блокирующий — 200 миллионов наносекунд. Процесс ждёт выполнения блокирующего вызова в 10 миллионов раз дольше.

Ядро предоставляет средства для выполнения как блокирующих («считай данные из сетевого подключения и дай их мне»), так и неблокирующих («скажи мне, когда в этих сетевых подключениях появятся новые данные») вводов/выводов. И в зависимости от выбранного механизма длительность блокировки вызывающего процесса будет разительно отличаться.
Диспетчеризация (Scheduling)
Диспетчеризация также крайне важна, если у вас есть много потоков выполнения или процессов, которые начинают блокировать.
Для нашей задачи разница между процессом и потоком выполнения невелика. В реальной жизни самое главное отличие между ними с точки зрения производительности заключается в том, что поток выполнения использует одну и ту же область памяти, а процессы получают собственные области. Поэтому отдельные процессы требуют гораздо больше памяти. Но если мы говорим о диспетчеризации, то всё сводится к тому, сколько потокам и процессам нужно времени выполнения на доступных ядрах процессора. Если у вас есть 300 потоков и восемь ядер, то придётся поделить время так, чтобы каждый поток получил свою долю: каждое ядро недолго выполняет один поток, а затем переходит к следующему. Это делается с помощью переключения контекста, когда процессор переключается с одного выполняемого потока/процесса на другой.
Но с этими переключениями контекста связаны определённые затраты — они занимают какое-то время. Иногда это может происходить меньше, чем за 100 наносекунд, но нередко переключение занимает 1000 наносекунд и больше, в зависимости от особенностей реализации, скорости/архитектуры процессора, его кеша и т. д.
И чем больше потоков выполнения (или процессов), тем больше переключений контекста. Если речь идёт о тысячах потоков, когда на переключения с каждого из них уходят сотни наносекунд, то всё выполняется очень неторопливо.
Однако неблокирующие вызовы по существу говорят ядру: «Вызови меня только тогда, когда появятся новые данные или событие в одном из этих подключений». Эти вызовы созданы для эффективной обработки большой нагрузки по вводу/выводу и уменьшения количества переключений контекста.
Ещё не потеряли нить рассуждения? Сейчас начинается самое интересное: мы рассмотрим, что некоторые популярные языки могут делать с вышеописанными инструментами, и сформулируем выводы о компромиссах между простотой использования и производительностью… и другими интересными пикантностями.
В качестве примечания: в статье приведены тривиальные примеры (в некоторых случаях неполные, когда будут показаны только релевантные биты). Обращения к базе данных, внешние системы кеширования (Memcache и т. д.) и многие другие вещи в результате будут выполняться под капотом, но, по сути, это те же вызовы операций ввода/вывода, который окажут то же влияние, что и приведённые в статье простенькие примеры. В сценариях, в которых ввод/вывод описан как блокирующий (PHP, Java), HTTP-запросы и операции чтения и записи сами по себе являются блокирующими вызовами: в системе скрыто немало операций ввода/вывода, что приводит к проблемам с производительностью, которые надо учитывать.
На выбор языка программирования для проекта влияет много факторов. Также немало факторов влияет на производительность. Но если вас беспокоит, что ваша программа в основном упрётся во ввод/вывод, если производительность ввода/вывода жизненно важна для проекта, то вам нужно знать обо всех этих факторах.
В 1990-х многие носили обувь Converse и писали CGI-скрипты на Perl. Затем появился PHP, и хотя его любят критиковать, но этот язык сильно облегчил создание динамических веб-страниц.
PHP использует очень простую модель. Существует ряд вариаций, но среднестатистический PHP-сервер выглядит так.
От пользовательского браузера поступает HTTP-запрос на ваш веб-сервер Apache. Тот создаёт отдельный процесс для каждого запроса, применяя некоторые оптимизации, позволяющие повторно использовать процессы ради минимизации их количества (создание процесса, к слову, задача медленная). Apache вызывает PHP и просит его выполнить соответствующий .php-файл, лежащий на диске. PHP-код выполняется и делает блокирующие вызовы ввода/вывода. Вы вызываете в PHP file_get_contents(), который под капотом выполняет системные вызовы read() и ждёт результаты.
Конечно, реальный код просто встроен прямо в вашу страницу, а операции являются блокирующими:
<?php
// blocking file I/O
$file_data = file_get_contents(‘/path/to/file.dat’);
// blocking network I/O
$curl = curl_init('http://example.com/example-microservice');
$result = curl_exec($curl);
// some more blocking network I/O
$result = $db->query('SELECT id, data FROM examples ORDER BY id DESC limit 100');
?>Вот как это выглядит с точки зрения интеграции в систему:
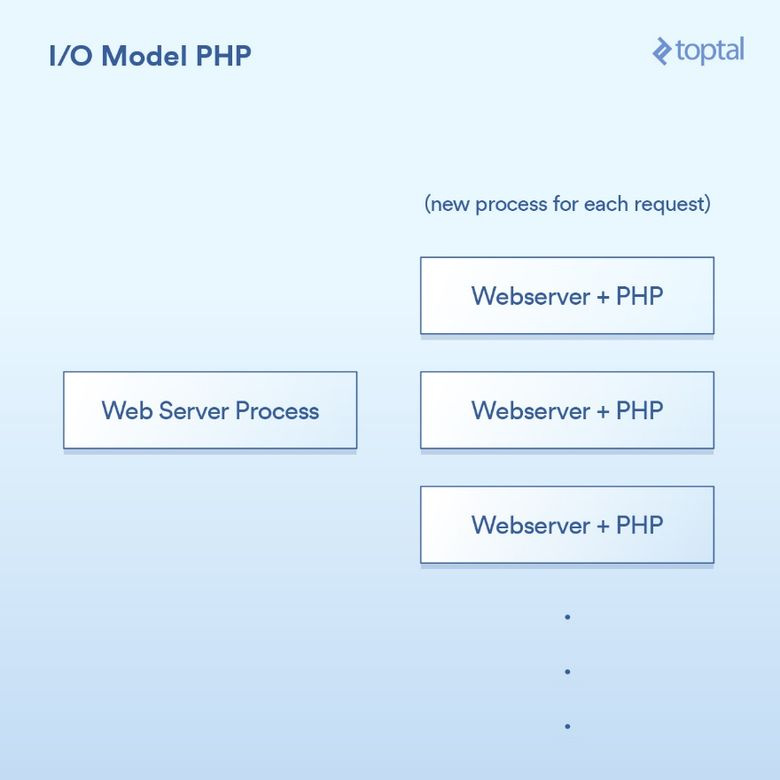
Всё просто: один процесс на запрос. Вызовы ввода/вывода просто блокируют. Достоинства? Схема простая, и она работает. Недостатки? После 20 тысяч параллельных клиентских обращений сервер просто расплавится. Этот подход плохо масштабируем, потому что не используются предоставляемые ядром ОС инструменты для работы с большим объёмом ввода/вывода (epoll и пр.). Ситуацию усугубляет то, что выполнение отдельного процесса на каждый запрос приводит к потреблению большого объёма системных ресурсов, особенно памяти, которая зачастую заканчивается в первую очередь.
Примечание: в Ruby используется очень похожий подход, и в широком, общем смысле в рамках нашей статьи они могут считаться одинаковыми.
Многопоточный подход: Java
Java пришёл в те времена, когда вы как раз купили своё первое доменное имя, и было так круто везде в разговоре вставлять словечки «точка ком». В Java встроена многопоточность (multithreading) — отличная функция (особенно на момент своего создания).
Большинство Java веб-серверов создают новый поток выполнения для каждого поступающего запроса, и уже в этом потоке в конце концов вызывают функцию, которую написали вы, разработчик приложения.
Выполнение ввода/вывода в Java Servlet выглядит так:
public void doGet(HttpServletRequest request,
HttpServletResponse response) throws ServletException, IOException
{
// blocking file I/O
InputStream fileIs = new FileInputStream("/path/to/file");
// blocking network I/O
URLConnection urlConnection = (new URL("http://example.com/example-microservice")).openConnection();
InputStream netIs = urlConnection.getInputStream();
// some more blocking network I/O
out.println("...");
}Поскольку наш метод doGet соответствует одному запросу и выполняется в собственном потоке, то вместо отдельного процесса для каждого запроса, требующего отдельной памяти, мы получаем отдельный поток выполнения. Это даёт приятные возможности, например можно поделиться состоянием или закешировать данные между потоками, потому что они способны обращаться к памяти друг друга. Но оказываемое при этом влияние на взаимодействие с диспетчером почти аналогично тому, что и в примере с PHP. Каждый запрос получает новый поток, и различные операции ввода/вывода блокируют внутри потока до тех пор, пока запрос не будет полностью выполнен. Потоки объединяются (pooled), чтобы минимизировать стоимость их создания и уничтожения, но в любом случае если у нас тысячи подключений, то создаются тысячи потоков, что плохо сказывается на работе диспетчера.
Важным поворотным моментом в Java 1.4 (и значительным апгрейдом в 1.7) стала возможность выполнения неблокирующих вызовов ввода/вывода. Большинство приложений, веб- и прочих, их не используют, но они хотя бы есть. Некоторые Java веб-серверы пытаются как-то применять преимущества неблокирующих вызовов, однако подавляющее большинство развёрнутых Java-приложений всё ещё работает так, как описано выше.

Java из коробки обладает некоторыми хорошими возможностями с точки зрения ввода/вывода, но они всё же не решают проблем, которые возникают в приложениях, активно использующих ввод/вывод и сильно тормозящих из-за обработки многих тысяч блокирующих потоков выполнения.
Неблокирующий ввод/вывод: Node
Node.js снискал себе популярность с точки зрения хорошей производительности ввода/вывода. Любой, кто хотя бы вскользь познакомился с Node, говорит, что он неблокирующий, что он эффективно обрабатывает операции ввода/вывода. И в целом это так. Но дьявол в деталях, точнее в колдовстве, с помощью которого достигается хорошая производительность.
Суть сдвига парадигмы, реализуемого Node, такова: вместо того чтобы сказать: «Напиши здесь свой код для обработки запроса», он говорит: «Напиши здесь свой код для начала обработки запроса». Каждый раз, когда вам нужно использовать ввод/вывод, вы делаете запрос и отдаёте callback-функцию, который Node вызовет по окончании работы.
Типичный код Node для выполнения операции ввода/вывода по запросу выглядит так:
http.createServer(function(request, response) {
fs.readFile('/path/to/file', 'utf8', function(err, data) {
response.end(data);
});
});Здесь есть две callback-функции. Первая вызывается, когда стартует запрос. Вторая — когда становятся доступными данные файла.
По сути, это позволяет Node эффективно обрабатывать ввод/вывод между двумя callback-функциями. Более подходящий сценарий: вызов базы данных из Node. Но я не буду приводить конкретный пример, потому что там используется тот же принцип: вы инициируете вызов базы данных и даёте Node callback-функцию; он с помощью неблокирующих вызовов отдельно выполняет операции ввода/вывода, а когда запрошенные вами данные становятся доступны, вызывает callback-функцию. Этот механизм постановки в очередь вызовов ввода/вывода с последующим вызовом callback-функции называется циклом событий (event loop). И он хорошо работает.
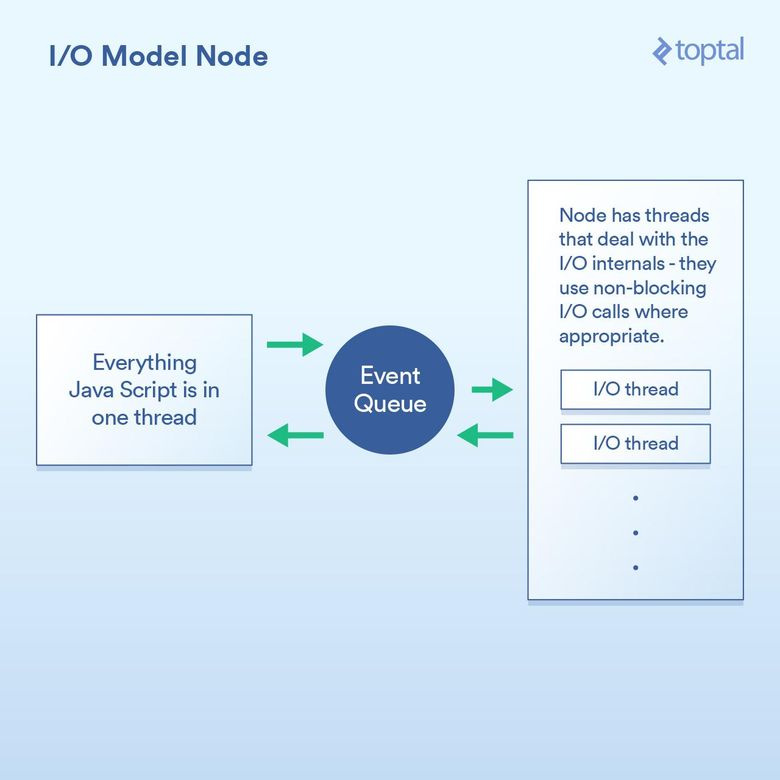
Но под капотом модели есть уловка. По большей части она связана с реализацией JS-движка V8 (JS-движок Chrome, используемый Node). Весь JS-код, который вы пишете, выполняется в одном потоке. Задумайтесь над этим. Это означает, что в то время как ввод/вывод происходит с помощью эффективных неблокирующих методик, ваш JS выполняет все связанные с процессором операции в одном потоке, когда один кусок кода блокирует следующий. Характерный пример того, к чему это способно привести: циклический проход по записям базы данных, чтобы неким образом обработать их, прежде чем отдавать клиенту. Вот как это может работать:
var handler = function(request, response) {
connection.query('SELECT ...', function (err, rows) {
if (err) { throw err };
for (var i = 0; i < rows.length; i++) {
// do processing on each row
}
response.end(...); // write out the results
})
};Хотя Node и обрабатывает ввод/вывод эффективно, но, например, цикл for использует такты процессора внутри одного, и только одного основного потока выполнения. И если у вас 10 тысяч подключений, то этот цикл может убить всё приложение, в зависимости от того, сколько он длится. Ведь в рамках основного потока выполнения нужно поочерёдно уделять процессорное время каждому запросу.
Вся эта концепция основана на предпосылке, что операции ввода/вывода — самая медленная часть, а значит, важнее всего обрабатывать их как можно эффективнее, даже за счёт последовательной обработки всех остальных операций. В каких-то случаях это справедливо, но не во всех.
Другое дело — это лишь мнение, — что может быть весьма утомительным писать кучу вложенных колбэков, и кто-то считает, что это сильно ухудшает читабельность кода. Нередко в Node-коде можно встретить четыре, пять и даже больше уровней вложенности.
И мы снова вернулись к компромиссам. Модель Node хорошо работает в том случае, если основная причина плохой производительности связана с вводом/выводом. Но её ахиллесова пята в том, что вы можете использовать функцию, которая обрабатывает HTTP-запрос, вставить код, зависящий от процессора, и это приведёт к тормозам во всех сетевых подключениях.
Естественное неблокирование: Go
Прежде чем перейти к обсуждению Go, должен сообщить, что я его поклонник. Я использовал этот язык во многих проектах, открыто пропагандирую предоставляемые им выигрыши в производительности, причём отмечаю их роль в своей работе.
И всё-таки давайте посмотрим, как Go работает с операциями ввода/вывода. Одна из ключевых особенностей языка — в нём есть собственный диспетчер. Вместо привязки каждого потока выполнения к одному потоку на уровне ОС Go использует концепцию горутин. В зависимости от задачи, выполняемой горутиной, среда выполнения языка может приписывать горутину к потоку ОС и заставлять исполнять её — или переводить её в режим ожидания и не ассоциировать с потоком ОС. Каждый запрос, поступающий от HTTP-сервера Go, обрабатывается в отдельной горутине.
Схема работы диспетчера:

Под капотом это реализовано с помощью разных ухищрений в runtime-среде Go, которая реализует вызовы ввода/вывода, делая запросы на запись/чтение/подключение и т. д., затем переводя текущую горутину в спящий режим с информацией, позволяющей снова активировать горутину, когда можно будет предпринять следующее действие.
Фактически runtime-среда Go делает нечто, не слишком отличающееся от того, что делает Node. За исключением того, что механизм колбэков встроен в реализацию вызовов ввода/вывода и автоматически взаимодействует с диспетчером. Также Go не страдает от проблем, возникающих из-за того, что вам приходится помещать весь обрабатывающий код в один поток выполнения: Go автоматически распределяет горутины по такому количеству потоков ОС, какое он считает подходящим в соответствии с логикой диспетчера. Код выглядит так:
func ServeHTTP(w http.ResponseWriter, r *http.Request) {
// the underlying network call here is non-blocking
rows, err := db.Query("SELECT ...")
for _, row := range rows {
// do something with the rows,
// each request in its own goroutine
}
w.Write(...) // write the response, also non-blocking
}Как видите, базовая структура кода того, что мы делаем, напоминает структуру более простых подходов, но под капотом использует неблокирующий ввод/вывод.
В большинстве случаев нам удаётся «взять лучшее от двух миров». Для всех важных вещей используется неблокирующий ввод/вывод; при этом код выглядит как блокирующий, но всё же получается более лёгким в понимании и сопровождении. Остальное решается при взаимодействии между диспетчерами Go и ОС. Это неполное описание магии, и если вы создаёте большую систему, то рекомендуется уделить время более глубокому изучению работы с вводом/выводом. В то же время окружение, полученное вами из коробки, хорошо работает и масштабируется.
У Go есть свои недостатки, но в целом они не относятся к работе с вводом/выводом.
Ложь, наглая ложь и бенчмарки
Трудно привести конкретные тайминги переключения контекста при использовании вышеописанных моделей. К тому же эта информация вряд ли была бы вам полезна. Вместо этого предлагаю прогнать простенькие бенчмарки и сравнить общую производительность HTTP-сервера в разных серверных окружениях. Но имейте в виду, что на результирующую производительность «HTTP-запрос/ответ» влияет много факторов, и приведённые здесь данные позволят получить лишь общее представление.
Для каждой из сред я написал код, он считывает 64-килобайтный файл, заполненный случайными байтами, затем N раз применяет к нему хеширование по алгоритму SHA-256 (N определяется в строке URL-запроса, например, .../test.php?n=100) и выводит на экран получившийся хеш в шестнадцатеричном представлении. Это очень простой способ прогнать один и тот же бенчмарк с единообразным количеством операций ввода/вывода и управляемым способом увеличения использования процессора.
Более подробную информацию о тестируемых средах можно почитать здесь.
Сначала рассмотрим примеры с небольшим распараллеливанием (low concurrency). Прогоним 2000 итераций с 300 одновременными запросами и применением только одного хеширования к каждому запросу (N = 1):
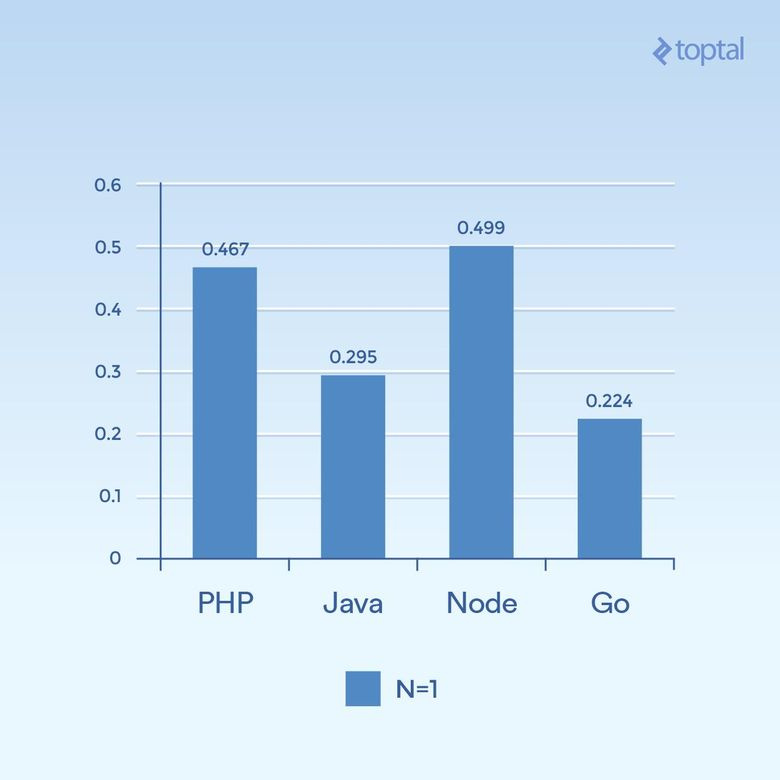
Сколько миллисекунд потребовалось на выполнение всех одновременных запросов. Чем меньше, тем лучше
На основании одного графика трудно делать какие-то выводы. Но создаётся впечатление, что при таком объёме подключений и вычислений мы видим результаты, которые больше похожи на общую продолжительность выполнения самих языков, а не длительность обработки операций ввода/вывода. Обратите внимание, что медленнее всего работают так называемые скриптовые языки (слабая типизация, динамическая интерпретация).
Увеличим N до 1000, оставив 300 одновременных запросов — нагрузка та же, но нужно выполнить в сто раз больше операций хеширования (значительно повышается нагрузка на процессор):
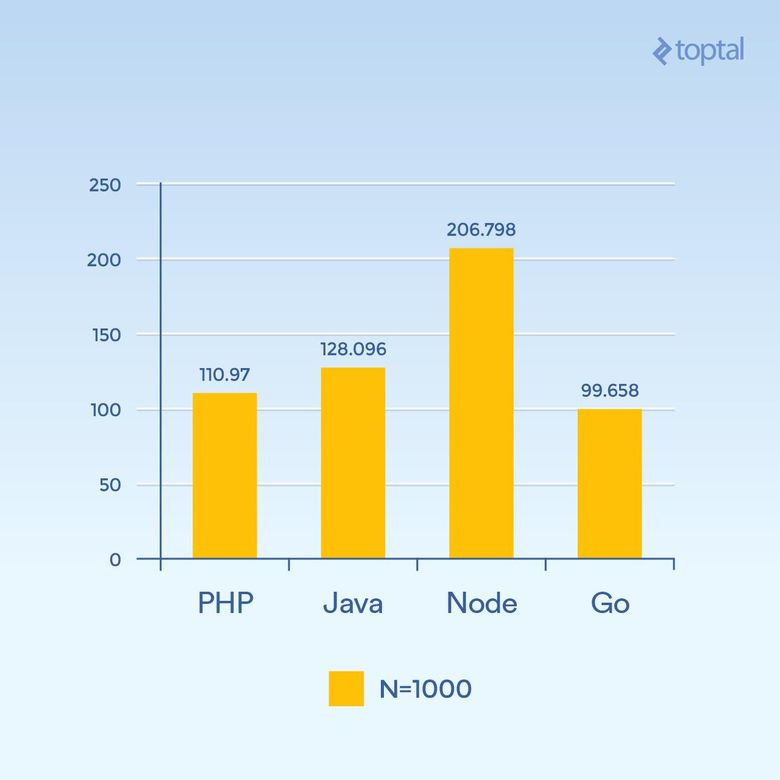
Сколько миллисекунд потребовалось на выполнение всех одновременных запросов. Чем меньше, тем лучше
Неожиданно значительно упала производительность Node, потому что операции, активно использующие процессор в каждом запросе, блокируют друг друга. Любопытно, что PHP стал гораздо лучше по производительности (по сравнению с другими) и обогнал Java. Нужно отметить, что реализация SHA-256 в PHP написана на Си, и в этом цикле путь выполнения (execution path) занимает гораздо больше времени, потому что теперь нам нужны 1000 итераций хеширования.
Теперь сделаем 5000 одновременных запросов (N = 1) или как можно ближе к этому количеству. К сожалению, в большинстве сред частота отказов была значительной. На графике отражено общее количество запросов в секунду.
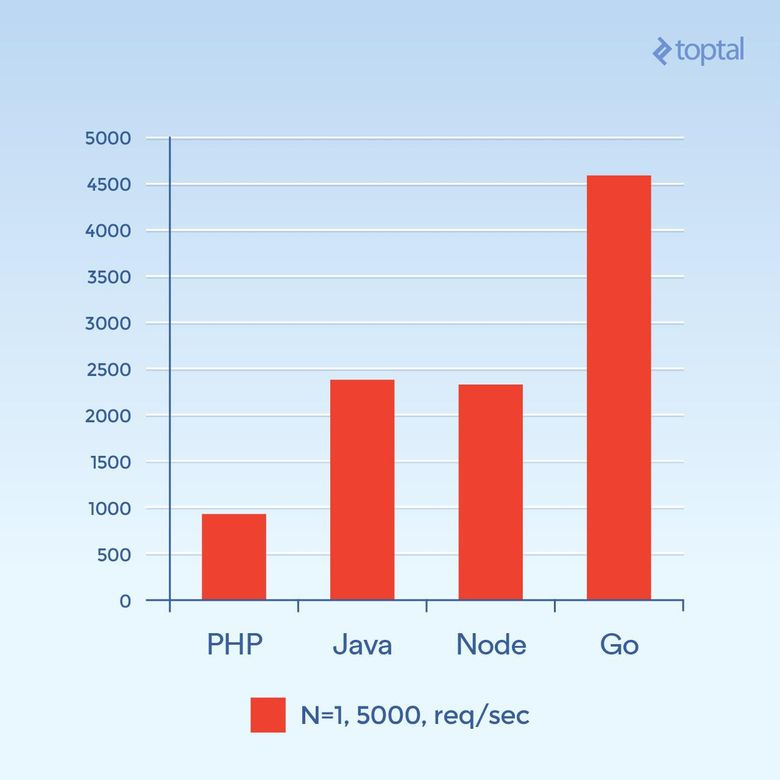
Общее количество запросов в секунду. Чем выше, тем лучше
Картина совсем другая. Это предположение, но похоже на то, что в связке PHP + Apache при большом количестве подключений доминирующим фактором становятся удельные накладные расходы, связанные с созданием новых процессов и выделением им памяти, что негативно влияет на производительность PHP. Go стал победителем, за ним идут Java, потом Node, и последний — PHP.
Несмотря на многочисленность факторов, влияющих на общую пропускную способность, и их варьирование в зависимости от приложения, чем больше вы будете знать о внутренностях протекающих процессов и сопутствующих компромиссах, тем лучше.
В итоге
Подводя итог вышесказанному, очевидно, что по мере развития языков развиваются и решения по работе с масштабными приложениями, обрабатывающими большое количество операций ввода/вывода.
Честно говоря, несмотря на данные в этой статье описания, в PHP и Java есть реализации неблокирующих вводов/выводов, доступных для использования в веб-приложениях. Но они не так распространены, как вышеописанные подходы, и потому нужно принимать в расчёт сопутствующие этим подходам накладные операционные расходы. Не говоря уже о том, что ваш код должен быть структурирован так, чтобы работать в подобных средах. Ваше «нормальное» PHP или Java веб-приложение без серьёзных модификаций вряд ли будет работать в такой среде.
Для сравнения, если выбрать несколько важных факторов, влияющих на производительность и простоту использования, то получается такая таблица:
| Язык | Потоки vs. процессы | Неблокирующие I/O | Простота использования |
|---|---|---|---|
| PHP | Процессы | Нет | |
| Java | Потоки | Доступно | Нужны колбэки |
| Node.js | Потоки | Да | Нужны колбэки |
| Go | Потоки (горутины) | Да | Колбэки не нужны |
С точки зрения потребления памяти потоки выполнения должны быть гораздо эффективнее процессов. Если также учесть факторы, относящиеся к неблокирующим операциям ввода/вывода, то по мере движения вниз по таблице общая ситуация с вводом/выводом улучшается. Так что если бы я выбирал победителя, то предпочёл бы Go.
Но в любом случае выбор среды для создания проекта тесно связан с тем, насколько хорошо ваша команда знакома с той или иной средой, а значит, и с общей потенциальной продуктивностью. Поэтому не для каждой команды будет целесообразно с головой погрузиться в разработку веб-приложений и сервисов на Node или Go. Одна из частых причин неиспользования тех или иных языков и/или сред — необходимость поиска разработчиков, знакомых с данным инструментом. Тем не менее за последние 15 лет многое изменилось.
Надеюсь, всё вышесказанное поможет вам лучше понять, что происходит под капотом нескольких языков и сред, и подскажет, как лучше решать проблемы масштабирования ваших приложений. Удачного ввода и вывода!
Комментарии (159)
oxidmod
23.05.2017 16:03+3Почему пых и апач?

pinguinjkeke
23.05.2017 16:21+2Действительно, есть cli, fpm

dovg
23.05.2017 16:44-2Принципиальной разницы не будет: все равно 1 процесс (пусть и реиспользуемый) на 1 запрос.
oxidmod
23.05.2017 17:32+8а вы бы попробовали чтоли)
dovg
23.05.2017 17:35-7что попробовать?
То, что фпм работает в целом быстре, чем пхп как модуль апача — это общеизвестный факт. Но на принцип работы (который автор указал в результирующей таблице) это никак не влияет.
Каждый запрос так или иначе будет выполняться в своем процессе. Неблокирующего i/o нет.
Я php ни в чем не обвиняю, если что. Просто применительно к этому тесту принципиальной разницы между fcgi vs mod_php не будет.
prounixadmin
24.05.2017 09:16А как именно он быстрее модуля работает? Там какой-то принципиально другой более быстрый код?
Правильнее указать, что связка nginx + php-fpm работает быстрее (не намного и не всегда) и меньше памяти потребляет, но это не заслуга php-fpm, а nginx. Применительно к этому тесту грамотно настроенный nginx + php-fpm на третьем графике позволит получить лучший результат.VolCh
24.05.2017 10:19А вы знаете, что обозначает FPM? Помнится делал бенчмарки и apache+php-fpm показывал лучшие результаты чем apache+mod_php
mayorovp
24.05.2017 10:27-1Fastcgi process manager. Слово "Fast" здесь — часть названия протокола взаимодействия с веб-сервером, и оно само по себе не означает более быструю работу, если вы намекали на это.
VolCh
24.05.2017 10:44+1Имеено, протокол взаимодействия. Нет, намекал я на то, что скорость работы php-fpm не зависит от того, apache или nginx перед ним.
prounixadmin
24.05.2017 10:34Это менеджер процессов FastCGI, который в связке с апачем в принципе не может быть быстрее модуля. Если у вас есть результаты исследований, то прикладывайте пожалуйста ссылку на них.
VolCh
24.05.2017 10:42В принципе как раз может: ОС не нужно форкать apache+mod_php, а только apache.
Результаты в другой стране и не актуальны — php5.2 емнип там был
prounixadmin
24.05.2017 10:53+1А вы знаете что означает prefork? Тесты от боевого сайта могут очень сильно отличатся, в реальных условиях при верной настройке лишних форков не будет.
Movimento5Litri
31.05.2017 10:27Чукча не читатель?
в связке PHP + Apache при большом количестве подключений доминирующим фактором становятся удельные накладные расходы, связанные с созданием новых процессов и выделением им памяти, что негативно влияет на производительность PHP
Это серьёзное обвинение и, как говорится, needs to be backed with hard numbers.
А дефолтная конфигурация sudo apt-get install lamp-server^ никак не тянет на hard numbers…
UPD: А! Он ещё ПХП 5.4 использовал! 2017 год на дворе, блжад!

madkite
23.05.2017 19:37+5Наверно потому же, почему и Java тестировали на сервлетах, хотя есть Grizzly/Netty. Типа это более популярно. Хотя если кто-то только смотрит на финальные каритинки, не читая текст, в надежде выбрать более "крутую" технологию для нового проекта, то может сложиться немного неадекватное предстваление. Ведь и на PHP, и на Java можно сделать оптимальнее. Даже касательно Node.js, если задача напряжная для CPU (как здесь — подсчёт контрольных сумм), то можно запустить несколько процессов и баллансировать между ними nginx-ом/haproxy/etc. Это позволит загрузить все ядра процессора. Так сравнивать некорректно. Но Go всё же рулит.

maxru
23.05.2017 16:18Образец для тестов PHP был без использования reactphp, насколько я понял?

nazarpc
23.05.2017 16:19-1И без HHVM. ReactPHP под HHVM показывает совсем другие цифры:)
maxru
23.05.2017 16:34Между 7 и hhvm на базе 5.6 критической разницы не заметил, кстати.
nazarpc
23.05.2017 16:37-3Я говорил о ReactPHP. После прогрева его JIT компилятор показывает очень интересные результаты, которых может не быть при использовании в более традиционном сценарии использования.
maxru
23.05.2017 16:39+2Какой ещё JIT-компилятор у reactphp, это просто набор PHP-классов?
hhvm с ядром 5.6 от php 7.0.x отличается на пару процентов даже с прогревом.nazarpc
23.05.2017 16:42JIT компилятор в HHVM, он хорошо проявляет себя когда функции вызываются без перезапуска много раз, что и происходит при запуске HTTP сервера с ReactPHP поверх HHVM.
Не знаю о каком ядре 5.6 идет речь, HHVM поддерживает обе версии одновременно с некоторыми нюансами.
maxru
23.05.2017 16:48+2На реальном примере я не заметил между ними такой разницы, ради которой стоило бы перелезать на hhvm.
На момент теста поддержки 7 у hhvm ещё не было, 7 только релизнулась.
pure_evil
24.05.2017 14:36Коротко о HHVM: Symfony 4: End of HHVM support.
Пруф: http://symfony.com/blog/symfony-4-end-of-hhvm-support
nazarpc
23.05.2017 16:18+1Сравнение производительности на Apache2? Почему не Nginx?

kilgur
23.05.2017 19:54-2Для Nginx выпустили ngx_http_php_module? Можно ссылку? А то на официальном сайте никаких упоминаний…
nazarpc
23.05.2017 20:03+1А модуль-то вам зачем О_о? Есть же php-fpm.
kilgur
23.05.2017 21:02-3Ну, вы же спросили про Nginx… Если бы вы спросили:
Сравнение производительности на Apache2? Почему не php-fpm?
, то и я, наверное, не полез бы со своим сарказмом…
php-fpm или apache — это выбор между тем, кто будет запускать php. А nginx может стоять перед любым из них.VolCh
24.05.2017 10:21-1Apache вполне поддерживает php-fpm.
kilgur
24.05.2017 12:44Нас сейчас тут совсем заминусуют хранители святого грааля «nginx + php-fmt»…
Да, я тоже некорректно выразился — под «apache» я подразумевал «apache+php_module». И да, согласен, можно перед php-fpm поставить и apache (с fast_cgi модулем) вместо nginx, только лучше выбрать mpm event или worker. Правда, я большой разницы в производительности на своих неправильных тестах не увидел, единственное — apache больше оперативки съел.

nerumb
23.05.2017 16:19+4… и Java есть реализации неблокирующих вводов/выводов, доступных для использования в веб-приложениях. Но они не так распространены, как вышеописанные подходы..
Это спорное утверждение. И, как мне кажется, если привести статистику с неблокирующими вызовами на Java то она будет уж точно не хуже Go (а может даже лучше).
afanasiy_nikitin
23.05.2017 16:57+3Netty 4?
nerumb
23.05.2017 18:07-4Netty не чисто на Java написан, там и нативного кода хватает (насколько я знаю)
xhumanoid
23.05.2017 18:53+5неправильно знаете =)
нативный код может быть в 2 случаях:
1) если вам не нравится стандартный java nio вы можете попросить epoll из линукса
2) если не устраивает скорость ssl в java и вы используете обертку поверх openssl
во всех остальных случаях чистая java которую хоть на android запускай.
в 99% использований нетти всегда укладываются в стандартную java.

gurinderu
23.05.2017 19:12-1Ну давайте сходим и посмотрим https://github.com/netty/netty
nerumb
23.05.2017 22:51+4Давайте:
https://github.com/netty/netty/tree/4.1/transport-native-epoll
https://github.com/netty/netty/tree/4.1/transport-native-kqueue
https://github.com/netty/netty/tree/4.1/transport-native-unix-common
xhumanoid сверху уже ответил, что в проекте действительно по сути одна только Java. Но все же в репозитории полно нативного кода.xhumanoid
24.05.2017 08:37+41% если точнее =) а то у людей может сложиться предвзятое отношение после слова «полно»
gurinderu
24.05.2017 10:59+5Все эти модули являются необязательными. netty вполне работает и без них.

youROCK
23.05.2017 17:08-9А уж если использовать github.com/valyala/fasthttp, то вряд ли получится догнать го в любом бенчмарке :)
nerumb
23.05.2017 17:13+6Где-нибудь уже сравнивалась производительность? Есть публичные бенчмарки? Вы сами сравнивали производительность с аналогичным решением на других языках?
Просто поражает, откуда такая пустословная уверенность в быстроте go…
JekaMas
23.05.2017 18:22Go шустрая, но отнюдь не панацея от всех бед. Java, c#, c++ и прочие тоже не пальцем деланные.
Если говорить именно о том, что с fasthttp будет сильно круче, то не уверен, несколько быстрее будет. Fasthttp выделяет намного меньше памяти и соответственно GC меньше съест. Правда код на нем, по личному опыту, трудно поддерживать: неинформативные ошибки, попытка почитать код приводит к чтению функций по 200-400 строк…
Бенчмарки можно посмотреть тутDjOnline
30.05.2017 20:27Слишком устаревший, php7 нет, максимум php5.
JekaMas
31.05.2017 01:47эээ нет. попробуйте навести на строчку вроде php-raw: «PHP-raw [php-raw7] (None; nginx on Linux; MySQL on Linux; Raw database connectivity, Platform class; Realistic approach) [Test #475]»
DjOnline
31.05.2017 15:26Спасибо, теперь вижу. Искал по ctrl+F php7, поэтому не нашёл.
Странно, что оно там медленнее php5.

SirEdvin
23.05.2017 18:44Просто поражает, откуда такая пустословная уверенность в быстроте go…
Скорее всего, потому что из коробки go и правда быстрее. Как минимум потому, что впитал новые идеи, в то время как старые языки базируются на старых. Просто проблема в том, что люди, которые работают с языком (например, Java) знают, что решения, которые из коробки предлагает Java в основном не используются, если вам нужна скорость, но зато используются во всех туториалах и там, где не особо важна скорость чтения (например, десктопное приложение).
А когда кто-то пилит такой бенчмарк, то ищет мануалы и находит решения из коробки.
gurinderu
23.05.2017 19:28+3Наличие новых идеи в языке совсем не значит, что runtime будет работать быстрее. И напомню, что самые производительные решения пишутся на дедушка (c,asm). К тому же с чего вы взяли, что Java не используется, если вам нужна скорость? Скорость чего? Старта? Отклика? Каков критерий то?
Я боюсь спрашивать у автора бенчмарка, а сколько у Java потоков работало? И почему не взяли netty, который является монстром по обработке, который написан на чистой java?
P.S.На мои взгляд сравнение совершенно некорректное.SirEdvin
23.05.2017 21:05-1Вы немного меня не поняли. Я говорю, что базовые решения для Java не используются, если вам нужна скорость, а например, используются netty.
А в случае с go, используется стандартный функционал go, который написан с учетом идей, которые использовали те же библиотеки на java, например.
Скажем, если сравнивать работу с потоками с Java c Go из коробки быстрее на Go, потому что на Java нет легких потоков. Я не прав?
Optik
23.05.2017 22:39+3Нет. Вы просто повторяете маркетинговый буклет при том, что дьявол всегда в деталях.
- Сравнивая разные модели вычислений, вывод почему-то перенесся целиком на рантаймы.
- Почти всегда в вопросах производительности заложен как минимум один трейдофф. Этим всегда пользуются маркетологи, рисуя один кейс и игнорируя другие. «Уверовавшие»потом ходят и продолжают их дело, рассказывают про эдем, эликсир вечного перформансного счастья и т.д. (чем ниже порог входа тем проще и больше можно привлекать людей, «жизнь коротка, ты и так уже потратил 15 минут на обучение, ты теперь можешь всё!»)
gurinderu
23.05.2017 23:54+1Давайте будем объективными. Java thread мапится 1 к 1 на native thread. А что происходит под капотом go я не знаю, но думаю что все равно вся магия горутин посроена вокруг threads. В java вам тоже никто не мешает взять какой-нибудь ForkJoinPool и делать execute на какие-нибудь задачи, что по сути тож самое)

grossws
25.05.2017 15:52+2Или использовать netty/akka-http/undertow/mina или более высокоуровневый vert.x, например. И в процессе шедулить задачи как принято в конкретной библиотеки на FJP или обыкновенный ThreadPool.
У Go обычно фиксированное число потоков, так что если загрузить их достаточным количеством cpu-bounded работы он будет не сильно отличаться от nodejs или java в аналогичных условиях.
youROCK
23.05.2017 22:16Ну, честно говоря, публичных бенчмарков у fasthttp хватает. Например вот:
https://github.com/valyala/fasthttp/tree/master/examples/fileserver
fasthttp, например, в полтора раза быстрее nginx при раздаче файлов :)nerumb
23.05.2017 23:06https://github.com/valyala/fasthttp/tree/master/examples/fileserver
Ну себя они в плохом свете точно выставлять не будут…
Я не против этого сервера, как и не против Go. Просто с трудом верится в такой разрыв, по сравнению с nginx, и других бенчмарков быстро не удалось найти…youROCK
23.05.2017 23:17Ну так вам же скинули огромный и очень экстенсивный бенчмарк: https://www.techempower.com/benchmarks/#section=data-r14&hw=ph
Там очень много разделов и частей, и во многих случаях fasthttp выигрывает, ну или по крайней мере занимает топовые места.nerumb
23.05.2017 23:38Ну, кстати, в этом бенчмарке light-java обходит во многих случаях fasthttp. Nginx, да, проигрывает.
Но все же хотелось бы видеть чистое сравнение на разных нагрузках, разных количествах одновременных подключений и т.д.

Miraage
24.05.2017 16:16А каким образом NodeJS может быть быстрее Lua(JIT)? Или я чего-то не знаю?
mayorovp
24.05.2017 16:35+1А в чем, собственно, проблема интерпретатору одному интерпретируемого языка с динамической типизацией быть быстрее интерпретатора другого языка?
NodeJS по умолчанию использует интерпретатор v8, который тоже относится к классу JIT
SirEdvin
23.05.2017 16:31-1Я многого не понимаю в веб приложениях, но зачем нам там много операций чтения в них?
msts2017
23.05.2017 16:47-9Смысл подобных статей непонятен, ежу понятно что GO будет быстрее, ведь он специально разработан для решения таких задач.
nerumb
23.05.2017 16:52+11… ведь он специально разработан для решения таких задач
Не аргумент.
В этой статье весьма спорное решение использовалось для других языков, в частности для Java. Либо приведите конкретные пруфы, либо не бросайтесь словами.msts2017
23.05.2017 17:01-8на что нужны пруфы?
и где я бросаюсь словами?nerumb
23.05.2017 17:03+9ежу понятно что GO будет быстрее
Чем можете подтвердить это утверждение?msts2017
23.05.2017 19:04-4прочтите что я написал, максимум что можно требовать это пруф на «он специально разработан для решения таких задач», вот
https://golang.org/doc/faq#What_is_the_purpose_of_the_project
Go is fully garbage-collected and provides fundamental support for concurrent execution and communication.
By its design, Go proposes an approach for the construction of system software on multicore machines.
«ежу понятно что GO будет быстрее» следует из логики, инструмент заточенный под конкретные условия будет быстрее, банально потому что оверхеда меньше, то что другие инструменты создавались под другие условия общеизвестно, наследственность давлеет над ними несмотря на многолетнее развитие.
Пруфы на условия
PHP — https://en.wikipedia.org/wiki/PHP
Java — https://en.wikipedia.org/wiki/Java_(programming_language)
Node.js — https://en.wikipedia.org/wiki/Node.js
На всякий случай даю пруф на логику — https://en.wikipedia.org/wiki/Logicnerumb
23.05.2017 22:56+6инструмент заточенный под конкретные условия будет быстрее, банально потому что оверхеда меньше
Из того что инструмент заточен под конкретные условия еще ничего не следует. Это лишь говорит о том на что будут направлены усилия разработчиков, но никак не о том что получится в итоге.
наследственность давлеет над ними несмотря на многолетнее развитие
Она же еще и позволяет убрать кучу детских болячек и вылизать все технические решения
А последнюю ссылку вам бы не мешало проштудировать самому, а может даже и сделать конспектmsts2017
24.05.2017 00:58-5Из того что инструмент заточен под конкретные условия еще ничего не следует. Это лишь говорит о том на что будут направлены усилия разработчиков, но никак не о том что получится в итоге.
выражение — инструмент заточен — означает что он уже соответствует заданным условиям а не когдато будет.
наследственность давлеет над ними несмотря на многолетнее развитие
Она же еще и позволяет убрать кучу детских болячек и вылизать все технические решения
выражение — наследственность давлеет — означает что есть что-то с чем приходится мирится а не исправлять. исправление возможно если выкинуть существующее и написать заново но это уже не наследственность.
так что логику надо еще подкачать.
mayorovp
23.05.2017 17:04+4Почему для Node.js не был задействован модуль cluster? Это как бы изкоробочная функциональность.
Про ReactPHP уже говорили (кстати, без кластера он должен был показать во втором тесте столь же плохой результат что и нода).
ilnuribat
24.05.2017 10:20ну да
кстати, не сказано, сколько ядер в машине тестовой
и было бы логично создать столько же форков на ноде и распределить нагрузку между ними, хотя я где-то и такой бенчмарк уже видел

sumanai
23.05.2017 17:09+4PHP из-под Apache
Дальше не читал. Кто-то ещё использует PHP под Apache в 2017?Dimash2
23.05.2017 19:17-4Наилучшая связка для классических задач Apache + Nginx одновременно.
oxidmod
23.05.2017 19:49+3Давно уже не так. Просто .htaccess очень удобен для говно хостингов. Если бы не это то давно бы его уже небыло. Да в редких кейсах Апач будет предпочтительней, но для большинства цмс, бложиков и магазинчиков Апач не упал ниразу
Dimash2
24.05.2017 22:10-1Интересно минусют ) Мы с админами проводити тесты настроек, nginx побеждал в отдаче статических файлов, а apache помогал выживать под сильной одновременной нагрузкой, когда nginx возращал ошибки.
AleksandrChernyavenko
23.05.2017 17:11+2node.js поумолчанию использует только один процессор.
Получается что графики иллюстрируют сравнение 1-го ядра для node.js против 4-х для всех остальных языков :(
(посмотрел исходники по ссылке из статьи )AlfaStigma
23.05.2017 17:39GO тоже использует один логический процессор по умолчанию. В примерах кода этот параметр не изменялся. Так что он тоже работает на одном ядре). Дабы распараллелить выполнение задач требуется установка GOMAXPROCS.

Warlock_29A
23.05.2017 17:57+7У вас какие то устаревшие сведенья, уже давно (вроде с 1.5) по умолчанию GOMAXPROCS равно кол-во CPUs.
AlfaStigma
23.05.2017 19:17+1Перепроверил, действительно сведения явно устаревшие, спасибо за информацию. Насколько я помню, дефолтное значение в 1 логический процессор использовалось в связи с тем, что при увеличении количества ядер увеличивались накладные расходы на общение и переключение контекстов. Эта проблема еще актуальна?

t0pep0
23.05.2017 18:13Немного не верное утверждение. Сейчас по дефолту GOMAXPROC=NUMCPU.
Я буду обновлять комментарии перед отправкой. Я буду обновлять комментарии перед отправкой. Я буду обновлять комментарии перед отправкой.

wert_lex
23.05.2017 17:12+25Это я пропустил, или автор в самом деле сравнивает перфоманс:
- многопоточной непрогретой JVM, с JSP в Томкате
- PHP, который сидит за непонятным дефолтным конфигом Apache (в целом тоже многопоточном)
- и однопоточную node.js


freeart
23.05.2017 17:14+2Конечное спорное сравнение, могу прокоментировать nodejs, отдача файла должна была быть потоком, а не чтение в буфер, а потом его преобразование в string и отдача по сети (тут оверхеад на лицо). А второе это циклы, они должны быть неблокирующие через функции/лямбды, будет падение производительности в этом случае, но блокировок не будет. Ну про встроенную возможность кластерности я молчу. Я не знаю какая была цель теста, можно представить что это было условие. Резюмируя: nodejs выжрет оч. много памяти, но произвоительность будет как у java (сейчас как раз оптимизирую высоконагруженный сервис, переписывая части на java).
mayorovp
23.05.2017 17:17-1Ничего из перечисленного вами (кроме кластера) не поможет в CPU-bound задаче (тест 2), скорее даже помешает.
freeart
23.05.2017 17:21Я ничего не писал про конкретные тексты, как вы заметили. Что из написаного мною не является истинной? Что странно приводить буфер к строке и отдавать его, а на яве открывать стрим? Или то что циклы for (> 1000 элементов) нельзя использовать в ноде?
mayorovp
23.05.2017 18:58Зато я писал про конкретный тест.
Сильнее всего нода просела именно во втором. И именно там ваши предложения лишь замедлят работу.
freeart
23.05.2017 19:07Мой коммент был не защита ноды. Ну мы же хотим правдивый тест? Разумеется перебор массива for-ом на одном ядре это для ноды плохо, а при миллионах элементов — еще и смерть, но что уж тут поделаешь. Мне кажется лучше сравнивать рабочие варианты.
mayorovp
23.05.2017 19:10Когда нас интересует лишь средняя производительность, а не время отклика, или же когда все задачи одинаковые — то как раз перебор массива for-ом оказывается наилучшим способом даже на одном потоке.
freeart
23.05.2017 19:23Но ведь один цикл for заблокирует все одновременные подключения, пока не закончится цикл, какой же прок от этого теста? Я могу на erlang написать код, который даст самые плохие результаты из всех языков, но ведь это лишь покажет как я плохо на нем пишу, а не реальное сравнение. Нужно же учитывать особенности языков, и писать адаптированный правильный код.
mayorovp
23.05.2017 21:31Да какая разница сколько подключений блокировано, если задача — cpu-bound? Ее физически невозможно выполнить быстрее чем она уже выполняется!
freeart
23.05.2017 21:46+1Да разница большая, имеем 1000 подключений одновременных, в случае с блокирующим for наш сервер отвечает одному или нескольким, остальные отваливаются по таймауту, в случае «неблокирующего for» мы отвечаем медленно, но всем.
mayorovp
23.05.2017 23:16-4Как можно отвечать "медленно, но всем", когда ответ — это 64 байта плюс заголовки?

XenonDev
29.05.2017 18:26+3А как мы ответим "медленно, но всем"? Допустим у нас такие условия: у нас есть 10 входящих реквестов, каждый реквест выполняет цикл длительностью 1 сек, таймаут на ответ = 9 сек. При таких условиях 1й клиент получит ответ через 1 сек, 2й — через 2 сек… 10й клиент получит таймаут. Если мы делаем одновременное выполнение всех запросов, то исполниться они должны примерно одновременно, т.е. все через 10 сек, т.е. все клиенты получат таймаут. Или разве не так?

cyber_ua
23.05.2017 17:28оффтоп вопросНе доскажите как лучше поступить? Есть node сервер, при определеном запросе нужно запустить node функцию (к примеру) которая будет выполнять синхронные операции с файловой системой (из за того что это может подвесить основной сервер, нужно запустить это в отдельном процессе). Как это красивее сделать?
Сейчас это выглядит так:
//fnc.js function fileSystemOperation() { //... }
const proc = cp.fork("./fnc.js", [args], { execArgv: [] });
и дальше через process.send комуникация. Не подскажите более просто решение?
halfcupgreentea
24.05.2017 12:55Не очень понятно, что такое синхронные операции с fs, их почти все можно делать асинхронно, оперируя стримами. Но уж если там абстрактная число-молотилка, то кроме форка и ipc ничего не придумаешь, можно только взять какую-нибудь библиотечку по удобнее чем
cp.fork
А операции совсем дорогие, можно подумать про какую-нибудь очередь, живущую вообще отдельно от сервера.
cyber_ua
25.05.2017 18:06Да, там не стандартные операции из fs которые можно использовать асинхронно.
Спасибо за ответ.
AlexLeonov
23.05.2017 17:24+10Существует ряд вариаций, но среднестатистический PHP-сервер выглядит так.
От пользовательского браузера поступает HTTP-запрос на ваш веб-сервер Apache.
Я знаю, что такой комментарий уже был выше. Но повторюсь: дальше нет смысла читать. Никакого. Автор весьма далек от современной разработки на PHP.
Плюс еще автор умудрился взять самую, пожалуй, старую доступную ему конфигурацию тестового стенда: «PHP v5.4.16; Apache v2.4.6» А что не PHP 4 сразу?
Берем Форд модель Т и Volvo XC90. Устраиваем гонки. Вольво выигрывает. Форд — дрянь? ))Gemorroj
23.05.2017 17:32+11Поддержу. Такое ощущение, что человек, либо абсолютно далек от php, либо специально подогнал окружение под желаемые результаты.
хотябы php7.x + php-fpm + nginx.
не говоря уже про react/php-pm/swooleAlexLeonov
23.05.2017 17:56+1Думаю, что это специально сделано. Слишком велик был соблазн включить время, затраченное на дорогущий форк процесса Апача в общее время тестов и показать, насколько плох PHP.
Уверен, что там еще и префорк на нуле специально был, иначе сложно объяснить смысл последнего графика.
sumanai
23.05.2017 18:04Да и вообще с php-fpm за nginx можно на последний переложить задачу по отдаче файлов, которую он будет выполнять намного лучше любого упомянутого тут языка. А файлы самого приложения должны лежать в Opcache.

ainu
23.05.2017 18:09+3Надо. Например, уже есть бенчмарк reactPHP vs node: https://gist.github.com/nkt/e49289321c744155484c. ReactPHP проигрывает раз в пять (а не в два раза, как в посте).
Если верить другому бенчмарку (http://marcjschmidt.de/images/reactphp-benchmark-requests.png), то react может работать наравне обычного hhvm или phpfpm+nginx.
Если верить третьему бенчмарку (http://hostingadvice.digitalbrandsinc.netdna-cdn.com/wp-content/uploads/2015/03/nodejs-vs-php-performance-requests-per-second.png), то php 5.5 + opcache сильно медленнее ноды, а hhvm — наравне.
По большому счёту, быстрый гуглинг говорит о том, что кардинально картина не меняется от манипуляций с reactphp, поднимая результаты максимум в два раза (неважно, используется react, hhvm или php7+opcache+php-fpm).
Но тогда и для Golang вместо net/http делать fasthttp (что на порядок быстрее может быть, чем обычный net/http).
raidhon
23.05.2017 20:28+3PHP 7.1 + Swoole 2.0 в 10 -15 раз быстрее чем Node.js 7.9.0 в бенчмарках, в реальных приложения в раза в три.
(Плюс PHP 7.1 до двух рах быстрее node.js в синхронных операция)
Конечно же потому что Swoole написан как С расширение к PHP и работает на тех же coroutine что и Go.
В Python 3 ситуация аналогична благодаря asyncio, uvloop
и таким библиотекам как aiohttp, можно писать асинхронные приложения и они тоже до двух раз быстрее чем node.js.
Да и у Ruby есть concurrent-ruby, Eventmachine и Celluloid все это с Ruby 2.4 вполне работоспособно и можно в продакшен.
Особенно на concurrent-ruby можно любую хрень собрать с параллелизмом.
Так что на node.js в плане асинхронности и неблокирующим операциям свет клином не сошелся.
Ну я все равно пишу на hapi свой микросервис ))ilnuribat
24.05.2017 10:39раз на то пошло, давайте addon-ы на Си писать для ноды)
кстати, я как раз редко встречаю такую практику, даже в яндексе на ноде пишут простенькие http-рендеры, тяжелые операции выполняются на java
Навреное потому, что обычно на ноде пишут сервисы, суть в которых минимальная обработка данных(циклами, хэши считать), и по максимуму работа с I/O.
но в некоторых npm библиотеках встречал node-gyp зависимости, и однажды проект не установился, когда gcc был версии меньше 4.4, требовал 4.8. Видимо, в узких местах пишут на Си.raidhon
24.05.2017 13:09+1Так и пишут.
Тот же node-sass почти в каждом проекте, никому не хочется тащить ruby sass.
Что тут говорить есть обертки над некоторыми частями boost, opencv даже qt пытались обернуть.
Куча расширений к react-native, NativeScript, Cordova, библиотеки к Raspberry Pi, просто обертки на чем угодно включая свои реализации event loop.
Не знаю как там в yandex, но я использую node.js на полную катушку.
Сейчас в разработке сайт на Sails, микросервис на hapi, два мобильных приложения одно на Cordova другое на React-native. Не говоря уже о мелких сервисах типа воркерах очередей или консольных приложениях.
Плюс node сейчас не в асинхронности, а в огромной инфраструктуре библиотек позволяющих писать почти что угодно.
Tavee
24.05.2017 17:35Swoole — сишный сервер для пхп? Тогда пхп становится просто языком сценариев для этого сервера в асинхронной среде.
С таким же успехом к ноде можно прикрутить серверную часть от nginx(это будет просто — у обоих асинхронщина в крови, оба на этом взлетели), ой, тогда получится lua script для nginx). Но и этим никто не заморачивается в ноде, она и так прекрасна — сетевой стек весь на js, полный контроль над соединением начиная с tcp.
Ой. Что я вижу. И эти люди мне рассказывали про каллбэк-хэлл:) Ну и эвент-дравен во всей красе. Только в ноде это родное все, а в пхп — попытка прикрутить асинхронщину.
$client = new swoole_redis; $client->connect('127.0.0.1', 6379, function (swoole_redis $client, $result) { echo "connect\n"; var_dump($result); $client->set('key', 'swoole', function (swoole_redis $client, $result) { var_dump($result); $client->get('key', function (swoole_redis $client, $result) { var_dump($result); $client->close(); }); }); });
raidhon
24.05.2017 21:05Я так понимаю что вы фреймворк для реализации параллельных и асинхронных приложений от web сервера отличить не можете.
Там вроде написано вверху.
Asynchronous & concurrent & distributed networking framework for PHP.
Для справки это то на чем пишут web сервер.
Swoole практически полностью закрывает потребности PHP программистов в создании асинхронных и параллельных приложений.
Аналогично Node.js появился для того чтобы закрыть потребность JavaScript программистов в создании серверных и заодно асинхронных приложений. ( позже была добавлена возможность создания мобильных и десктопных приложений)
Так что это вполне нормальная практика создавать фреймворки и программные платформы для решения нужных и важных задач.
И просьба фразы <<ой пхп>> оставляйте при себе.
Как показывает практика программисты выражающиеся подобным образом дальше написания hello world в данном языке не уходили и понятия не имеют о чем говорят.Tavee
25.05.2017 00:16Не первая и не последняя попытка прикрутить асинхронщину туда, где ее не было. Что-то не припомню годных примеров из продакшена.
raidhon
25.05.2017 12:20+3Вверху я уже перечислял, могу ещё раз.
Java — Netty, Undertow, Akka
Python c 3.5 завез в стандартную библиотеку — asyncio, так же присутствуют uvloop и библиотек на их основе — aiohttp, asynq, Curio
Ruby — concurrent-ruby, Eventmachine и Celluloid
И наконец PHP — у него есть свой awesome — https://github.com/elazar/asynchronous-php
Где есть все что нужно для асинхронности.
Включая промисы https://github.com/guzzle/promises, на грабли callback hell никто не хочет наступать.
Все эти библиотеки(конечно их намного больше ) реализуют возможность как асинхронного так и конкурентного программирования( coroutine, Actor ) и активно используются в продакшен в том числе и мной.
Tavee
26.05.2017 14:49Осталось прикрутить программистам асинхронщину и параллельное программирование в голову. Вот с этим возникают проблемы, то что есть либы под любой язык и любой подход — не новость.
DjOnline
30.05.2017 20:40swoole — это примерно то же самое что старый добрый phpDaemon, призванный отойти от концепции always die?

Fesor
30.05.2017 23:15Есть еще ayres, kraken, php-pm, php fastcgi daemon и тд.
DjOnline
31.05.2017 01:46Ну и ReactPHP. Было бы интересно прочитать про сравнение их всех между собой.

SerafimArts
31.05.2017 02:14Ну раз php-pm приводится в качестве примера, тогда уж и appserver можно за компанию.
VolCh
24.05.2017 10:28-2Хотя бы apache+php-fpm, поскольку остальные тоже работают из-под апача.
mayorovp
24.05.2017 10:30+1"Остальные" — это кто?
VolCh
24.05.2017 10:46В этой статье мы сравним Node, Java, Go и PHP из-под Apache
Разве это не означает, что Apache стоит перед всеми?
mayorovp
24.05.2017 11:01-1Правильно читать вот так:
В этой статье мы сравним (Node), (Java), (Go) и (PHP из-под Apache)
Как минимум нода в отдельном веб-сервере точно никогда не нуждалась. Для Java существует AJP, но это дополнительная возможность, а не основная. Про Go не скажу.
VolCh
24.05.2017 11:43-1Как мне казалось, мало того выпускает наружу голые (Node), (Java), (Go) и (PHP), ставят перед ними Apache, nginx, lighthttpd и, даже, прости господи, IIS, чаще всего еще и статику ими раздавая, оставляя на апп-сервер только динамику.
raidhon
23.05.2017 18:30+1<<So this is how DUMB top 3% developers selected by TopTal are! bravo!>>
Мне вот тоже не понятно как он залез в 3% TopTal
PHP 5.4 под Apache в 2017 году, когда есть php 7 и существуют такие библиотеки как ReactPHP и Recoil.
Node.js без модуля cluster, на нужен callback ответ — есть async await и промисы.
Java без Netty и Undertow.
Да и зачем все это когда есть https://www.techempower.com/benchmarks/#section=data-r14&hw=ph

webmasterx
23.05.2017 19:15+1$file_data = file_get_contents(‘/path/to/file.dat’);
InputStream fileIs = new FileInputStream("/path/to/file");
я даже заглянул в код. Думаю очевидно что чтение файла и открытие дескриптора на него — это две совершенно разные вещи.
AloneCoder зачем вы это вообще переводили?
AloneCoder
23.05.2017 20:47Да, разные, но вы плохо заглядывали в код бенчмарков, и там и там файл полностью считывается с диска, ссылка на листинги есть в статье, продублирую ее и здесь
А переводил затем, что любая статья про бенчмарки всегда неоднозначна и порождает дискуссию, обмен мнениями и реальным опытом, что прекрасно и ценно

Staltec
23.05.2017 19:40+12Вредная статья, нарочно (или по незнанию) вводящая в заблуждение. Зачем сравнивать производительность node на задачах блокирующих event loop? Причём автор сам же написал в начале что это слабая сторона ноды. Она же просто не для этого.
Тесты в итоге выгдядят так: берём собаку, медведя, слона и кита. Смотрите — кит передвигается хуже всех. Еле по земле ползает.
И вредность данной статьи в том, что потом ходят толпами люди глубоко не разбирающиеся в условиях применения особенностей языков и тычут пальчиком вот в такие «статьи» — node дескать отстой. Mail.ru на Хабре доказало!

jehy
23.05.2017 21:24+4Добавлю к некорректному сравнению php и node.js ещё то, что в ноде никто уже несколько лет не пишет на коллбэках. Ну и отдельное удивление вызывает, что в статье не указаны версии движков. Как бы php5 очень сильно отличается по скорости от php7, то же самое с нодой.
Переводчик написал, что это некое мнение для порождения дискуссии, но статья представляет собой ровно то, что является одним из заголовков — "ложь, наглая ложь и бенчмарки". К тому же невооружённым взглядом заметно, что автор тащиться от Go, и видимо поэтому был готов натянуть козу на слона, чтобы показать, как хорош его любимый язык. Стыдно должно быть за такие статьи.
SerafimArts
23.05.2017 22:13+1Что касается PHP:
1) php nts (fpm) — работает в многопроцессовом режиме, php ts (mod apache) работает в многопоточном режиме, так что нельзя утверждать, что пых клонит процессы. Т.к. использовался апач — скорее всего использовался, mod + ts, т.е. многопоточный режим.
2) В пыхе есть неболкирующее I/O, в том числе и встроено в сам язык, к пример асинхронные запросы к mysqli, про react + event loop на основе какого-нибудь ev я уже не говорю, т.к. выборка будет не репрезентативна, т.е. это библиотеки, а не stdlib.
3) Не показаны версия и настройки опкеша. По-умолчанию конфиг содержит отключённый опкеш, но стоит его включить и отключить ревалидацию (т.е. избавиться от лишних запросов на жёсткий диск) — можно крайне сильно удивиться (я уж не говорю про jit-сборки, т.к. опять же, выборка не репрезнативна будет).AlexLeonov
24.05.2017 00:22+2О чем вы говорите, если на тестовом стенде использовался Apache и PHP 5.4? Какой тут ZTS? Автор теста и слов-то таких не знает…

fogone
23.05.2017 23:25+7Большинство Java веб-серверов создают новый поток выполнения для каждого поступающего запроса, и уже в этом потоке в конце концов вызывают функцию, которую написали вы, разработчик приложения.
Потоки объединяются (pooled), чтобы минимизировать стоимость их создания и уничтожения, но в любом случае если у нас тысячи подключений, то создаются тысячи потоков, что плохо сказывается на работе диспетчера.
Это неправда, никто не создает новый поток для каждого выполнения. Потоки всегда в пуле, как это дальше написано и именно по-этому их не создается тысячи, потому что везде уже давно используется ивент-луп для обработки соединений и io-операций и на каждое соединение новые потоки тоже не создаются.
Большинство приложений, веб- и прочих, их не используют, но они хотя бы есть. Некоторые Java веб-серверы пытаются как-то применять преимущества неблокирующих вызовов, однако подавляющее большинство развёрнутых Java-приложений всё ещё работает так, как описано выше.
Не знаю ни одного современного веб-сервера на джаве, который бы не использовал неблокирующее io и ивент-луп так или иначе. И да, как описано выше соответственно сейчас никто не работает, кроме может быть каких-то самопальных поделок сделанных людьми, которые прочли статьи вроде этой.
Прежде чем перейти к обсуждению Go, должен сообщить, что я его поклонник.
Почему-то когда я прочел эти откровенные домыслы, мне подумалось, что дальше будет что-то вроде, «а вот го-то, он совсем другой..» — и точно. Наверное потому, что именно об этом языке появляется много таких совершенно профанских статей, которые кроме фейспалма ничего не вызывают.
Нужны колбэки
Нет, у джавы для неблокирющего io есть каналы из nio, которые прекрасно работают без колбэков и позволяют эффективно реализовать ивентлуп.
Бенчмарки вообще уморили: какие-то дефолтные конфиги и jsp для обработки запроса. Выбраны почему-то именно сервлеты, запускаются «бэнчмарки» без прогрева; когда один раз запускалось, томкат за указанное время еще и жсп поди успел скомпилировать. От реализации рассчета хеша вообще слезы на глаза наворачиваются. Не буду ничего говорить про другие языки, уверен, что там так же ляп на ляпе. А ведь кто-то возможно посмотрит и сделает какой-то вывод далекий от реальности.

DeLuxis
24.05.2017 07:33В PHP7 появились же threads. Да и у Node.js есть cluster.
У java тоже есть что-то такое.
Короче как всегда, реализация хромает. Я тоже люблю Go, но нужно как-то адекватней быть при сравнении. Изучить инструменты и библиотеки.
dab00
24.05.2017 08:33+3Два слова в «защиту» Node.js vs Go:
1) Начиная с версии 1.5 GOMAXPROCS = количество CPU, по-моему равные условия можно создать если в тестовом приложении Node.js использовать cluster https://nodejs.org/api/cluster.html
2) В Node.js как fs так и crypto (в частности crypto.randomBytes и crypto.pbkdf2) выходят в libuv thread pool http://docs.libuv.org/en/v1.x/threadpool.html, на мой взгляд результат мог бы быть иным если установить UV_THREADPOOL_SIZE=128 (максимум)

ACPrikh
24.05.2017 10:07+4Что хотел сказать автор, но запутался в буквах.

Показатель = sort.(v3/(v1*v2))
Чем больше, тем лучше

Scrobot
25.05.2017 17:22-1Спасибо за статью, комментарии честно признаюсь, не прочитал, может быть, кто-то что-то подобное уже высказал, поэтому выскажу субъективное пожелание.
Хотел бы увидеть более полную версию статьи, основанную на дополнительных данных, ввиде:
1. Дополнить данные схемы языками Ruby и Python, хотя бы потому-то что они тоже довольно популярны в виде бэкенда
2. И добавить еще одну ветку сравнений, в виде использования фреймворков. Т.е. как бы было на нативе и на ФВ. Не знаю как вы, но я ооочень редко встречал поддерживаемые велосипедные проекты)) Обычно(самые распрастранненые варианты)
when(lang) { Java -> Spring PHP -> Laravel Python -> Django Ruby -> Ruby on Rails NodeJs -> Express.js }
Было бы любопытно посмотреть на цифры и объективное исследование)grossws
25.05.2017 22:14Прочитайте лучше комментарии, от них пользы гораздо больше, чем от самой "статьи".

Borro
28.05.2017 23:49+1Ради интереса сделал тесты:
go 1.8.3 на виртуальном стенде в 4 ядра и 1 ГБ памяти лучший результат:
ab -n 10000 -c 5000 'http://127.0.0.1:4000/test?n=1'Server Software:
Server Hostname: 127.0.0.1
Server Port: 4000
Document Path: /test?n=1
Document Length: 64 bytes
Concurrency Level: 5000
Time taken for tests: 2.776 seconds
Complete requests: 10000
Failed requests: 0
Write errors: 0
Total transferred: 1810000 bytes
HTML transferred: 640000 bytes
Requests per second: 3602.04 [#/sec] (mean)
Time per request: 1388.102 [ms] (mean)
Time per request: 0.278 [ms] (mean, across all concurrent requests)
Transfer rate: 636.69 [Kbytes/sec] received
Connection Times (ms)
min mean[±sd] median max
Connect: 0 300 390.9 132 1012
Processing: 1 365 352.5 195 1623
Waiting: 1 360 347.8 192 1622
Total: 1 664 436.5 700 1927
Percentage of the requests served within a certain time (ms)
50% 700
66% 1024
75% 1074
80% 1095
90% 1192
95% 1273
98% 1354
99% 1437
100% 1927 (longest request)sumanai
29.05.2017 02:05fastcgi://127.0.0.1:9000
А почему не сокеты?Borro
29.05.2017 08:56С сокетами получилось больше, но и ошибок больше:
4046.81 #/sec но и ошибок 2797 из 10000Server Software: nginx/1.13.0
Server Hostname: 127.0.0.1
Server Port: 80
Document Path: /test.php?n=1
Document Length: 64 bytes
Concurrency Level: 5000
Time taken for tests: 2.471 seconds
Complete requests: 10000
Failed requests: 2797
(Connect: 0, Receive: 0, Length: 2797, Exceptions: 0)
Write errors: 0
Non-2xx responses: 2797
Total transferred: 2620813 bytes
HTML transferred: 1000813 bytes
Requests per second: 4046.81 [#/sec] (mean)
Time per request: 1235.542 [ms] (mean)
Time per request: 0.247 [ms] (mean, across all concurrent requests)
Transfer rate: 1035.73 [Kbytes/sec] received
Connection Times (ms)
min mean[±sd] median max
Connect: 0 439 445.8 226 1306
Processing: 81 394 212.7 389 990
Waiting: 1 349 202.5 365 969
Total: 110 833 491.5 626 1975
Percentage of the requests served within a certain time (ms)
50% 626
66% 865
75% 1323
80% 1356
90% 1759
95% 1862
98% 1872
99% 1875
100% 1975 (longest request)sumanai
29.05.2017 16:18Requests per second: 4046.81 [#/sec] (mean)
Больше чем у Go?Borro
29.05.2017 18:10Это из-за ошибок. Когда происходит ошибка, то выдаётся всё очень быстро и тоже идёт в зачёт. Вообще ab не самая классная тулза. Вечером попробую siege'ом.
Borro
29.05.2017 22:59Самый адекватный без ошибок получилось с конкурентностью 1000:
Go 3786.41 [#/sec]Server Software:
Server Hostname: 127.0.0.1
Server Port: 4000
Document Path: /test?n=1
Document Length: 64 bytes
Concurrency Level: 1000
Time taken for tests: 2.641 seconds
Complete requests: 10000
Failed requests: 0
Write errors: 0
Total transferred: 1810000 bytes
HTML transferred: 640000 bytes
Requests per second: 3786.41 [#/sec] (mean)
Time per request: 264.102 [ms] (mean)
Time per request: 0.264 [ms] (mean, across all concurrent requests)
Transfer rate: 669.28 [Kbytes/sec] received
Connection Times (ms)
min mean[±sd] median max
Connect: 0 5 10.7 1 53
Processing: 1 247 133.2 230 868
Waiting: 1 243 132.0 226 856
Total: 1 252 131.5 233 869
Percentage of the requests served within a certain time (ms)
50% 233
66% 289
75% 328
80% 353
90% 422
95% 504
98% 590
99% 644
100% 869 (longest request)
Fesor
29.05.2017 10:39А если через wrk?
Borro
30.05.2017 00:50Ничего особо не изменилось
php 4140.13 r/secRunning 30s test @ http://127.0.0.1/test.php?n=1
12 threads and 400 connections
Thread Stats Avg Stdev Max ± Stdev
Latency 100.20ms 63.06ms 542.07ms 76.27%
Req/Sec 348.20 110.88 0.85k 72.45%
124513 requests in 30.07s, 32.06MB read
Requests/sec: 4140.13
Transfer/sec: 1.07MB
vril
30.05.2017 02:12+5Невероятно непрофессиональный подход и просто типичнейший фанбой-булшит. Ничего толком о тестовой конфигурации, ни о железе, ни о софте, ни о версиях. Прогретая джава, не прогретая? Абстрактный аппач с пхп — как минимум странно. Тестирование на разном железе с разным объемом оперативки и количеством ядер? Где?
Мейлру студенческие работы стало переводить?


{kind=link}
{kind=link}
malinichev
Интересное сравнение… Правда мне кажется тут не совсем уместен Java
nerumb
Вы не могли бы пояснить свою точку зрения, почему считаете что Java тут неуместна?
koeshiro
Не знаю на повод java, но asp здесь нужен.
nerumb
Зачем тогда вообще Java упоминаете? Если про нее ничего сказать не можете…
nerumb
Поспешил с ответом. Не обратил внимание что ответ от другого человека.
malinichev
Потому-что считаю что Java к вебу очень косвенно относится… Тут был-бы уместен Python
nerumb
Тут вы ошибаетесь
Посмотрите хотя бы:
https://en.wikipedia.org/wiki/Programming_languages_used_in_most_popular_websites
Да разнообразие и популярность фрейморков для веба в Java говорит об обратном:
Spring, Dropwizard, Spark, Vert.x и т.д.
shishmakov
Вы на Java и не пишите похоже
malinichev
Ну именно на Java я не пишу, я сейчас Kotlin штрудирую третий месяц
shishmakov
Загляните за обратную сторону Луны — там Web и Java почти синонимы. N-лет назад был популярен GWT, Джавнее уж некуда. Web-пауки пишут на Java в том числе.
malinichev
Я почему-то всегда думал что Python популярнее Java в плане веба