
Недавно JetBrains провели исследование среди пользователей языка Kotlin. Простой опрос об ожидаемых новых функциях дал неожиданные результаты. Вместе с организатором опроса мы решили расследовать, почему так могло произойти.
В итоге получилась история о статистике, твитах, конформности, внушении и скидках на одежду.

Рисунок 1. Фотографии с результатами опросов
Статья может быть интересна тем, кто занимается опросами и исследованиями пользователей.
Итак, весной прошли международные опросы пользователей языка Kotlin о функциях, которые они хотели бы увидеть в следующем релизе. Позже в блоге Kotlin появился пост с результатами исследования и ссылкой на сырые данные.
Исследование проводилось в 2 этапа. Часть пользователей языка голосовали на митапах, посвященных Kotlin 1.1, вторая часть заполняла on-line анкеты. В результате получилось 2 рейтинга с 3 явными фаворитами в каждом (рис. 2). И фавориты не совпали.

Рисунок 2. Рейтинги ожидаемых новых функций в Kotlin 1.2: результаты off-line и on-line опросов
Почему результаты двух опросов так отличаются друг друг от друга?
Организаторы предложили 2 объяснения:
1. Отличия групп. Участники митапов отличаются от остальных пользователей Kotlin.
2. Предвзятость. На off-line голосовании участники видели, за какую функцию голосуют другие, и это могло повлиять на их мнение.
Попробуем подробнее разобраться, почему результаты отличаются. Проведем маленькое расследование и ответим на вопросы:
1. Действительно ли между участниками митапов и остальными пользователями есть различия?
2. Действительно ли на голоса участников митапов повлияло мнение коллег?
3. Одинаково ли воспринимали условия голосования участники митапов и остальные пользователи?
4. Почему в рейтинге on-line голосования первая тройка набрала существенно больше голосов, чем остальные функции?
Для начала, восстановим, как проходило исследование.
Опрос состоял из 2 частей.
Off-line часть заполнялась участниками митапов. Большинство митапов прошло в одно время, 23 марта, в 21 стране мира (всего 30 митапов). Их участники смотрели прямую трансляцию демонстрации функций Kotlin 1.1, а после могли проголосовать за появление новых функций. Некоторые митапы голосовали до демонстрации (рис. 3). Для этого им раздали по 3 круглых оранжевых стикера, которые нужно было прикрепить к карточкам с описанием функций. Можно было использовать по 1 стикеру за функцию, или проголосовать двумя, или всеми тремя стикерами за одну функцию. Сейчас невозможно восстановить, сколько человек принимало участие в голосовании в каждом митапе, так как каждое сообщество назвало организаторам исследования только рейтинг: общее количество стикеров, оставленных за каждую функцию. Свои рейтинги передали 22 сообщества.
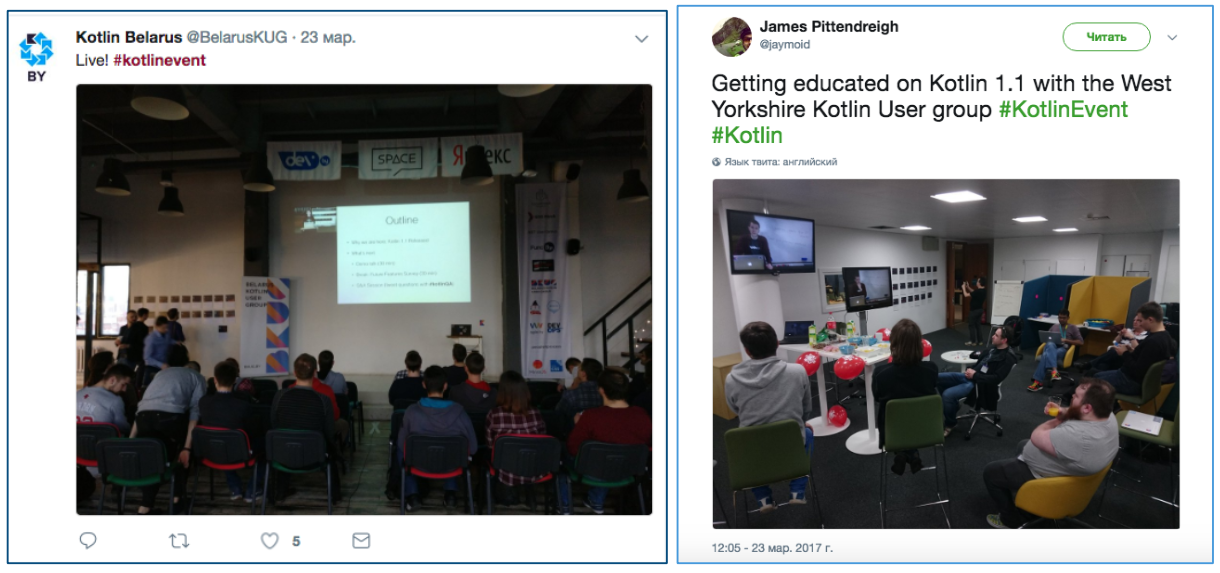
Рисунок 3: Фотографии из твитов сообществ Kotlin (на стенах видны карточки для голосования)
On-line часть опроса прошла после off-line части. В блоге Kotlin появилась статья с видео-записью трансляции и рассказом об опросе, проведенном в сообществах. В статье было написано, что опрос привлек много внимания, и теперь создатели предлагают пройти его on-line всем желающим и «высказать свое мнение о будущем Kotlin».
Участникам предлагалась on-line анкета с такими же, казалось бы, вопросами – об ожидаемых функциях языка. В конце анкеты были приложены такие же карточки с описанием каждой функции, которые были использованы после митапов. Дополнительно в анкету добавили вопрос о самой нежелательной функции. На on-line анкету был получен 851 ответ.
Данные обоих опросов обрабатывались простым суммированием. В результате получилось 2 списка – on-line и off-line рейтинги с 3 явными фаворитами в каждом (рис. 2), фавориты не совпали.
Только функция #18 «Truly immutable data» попала в первую тройку одновременно в обоих опросах. Более-менее совпала первая шестерка, с перемешанным порядком, за исключением двух функций: функция #4 «Private members accessible from tests» в on-line опросе оказалась всего лишь на 12 строчке и набрала максимум голосов против, а функция #9 «Inline classes/Value classes» в off-line опросе оказалась на 17 строчке.
Итак, лидерами в обоих опросах стали:
#18 Truly immutable data
#1: Multi-catch
#13: SAM conversions for Kotlin interfaces
#6: Collection literals
#8: Slices for lists and arrays
1. А есть ли на самом деле различия?
На диаграммах различия явно видны. Но это первая ловушка, о которой предупреждают исследователей: вывод о различиях между группами не делается по простому подсчету средних, или частот. Здесь должна быть шутка про «среднее по больнице». На фото карточек off-line голосования видно, что на разных митапах лидерами мнений оказывались разные функции. А вдруг, мнения участников сильно различались, и получившиеся рейтинги – просто результат случайных колебаний?
Проверим гипотезу
Такие догадки проверяют статистикой. Но в нашем случае получилось 2 разных вида сырых данных: номинальные данные в on-line голосовании и количественные в off-line голосовании. Поэтому попробуем посмотреть просто на корреляции итоговых списков. Если получится, что корреляция между двумя списками сильнее, чем корреляции между списками митапов, это будет значить, что среди участников разных митапов согласия меньше, чем между всеми участниками митапов и участниками on-line голосования. А это будет значить, что нельзя делать вывод о том, что участники митапов и участники on-line голосования – это две существенно разные группы.
Коэффициент корреляции Спирмена между on-line и off-line голосованиями получился таким: r=0,680, p=0,001. В классификации Дж. Коэна для социальных исследований это довольно высокий показатель взаимосвязи (>0,5 – значительная корреляция).
Теперь посмотрим, как оценки митапов коррелируют между собой. Оказалось, что между списками митапов нет ни одной корреляции, превышающей значение 0,680. Самая сильная корреляция (0,618) проявилась между Бельгией и Берлином. Более того, были даже отрицательные корреляции (например, -0,454 между Лимой и Будапештом: интересно было бы узнать, есть ли объяснение этих отличий).
Другими словами, участники митапов в разных странах меньше согласны друг с другом, чем в общем согласны с on-line пользователями.
Вроде, о глобальных различиях между группами теперь можно не говорить. Но остается вопрос: почему результаты распределились именно так, почему в рейтингах есть явные фавориты, набравшие существенно больше голосов? Что еще могло повлиять на голоса участников?
2. Участники влияли друг на друга?
По мнению организаторов исследования, совместное голосование на митапах могло повлиять на ответы участников, изменить их мнение.
Если бы это было так, ответы внутри групп распределялись бы скученно, с маленьким разбросом (в группах все бы проголосовали примерно одинаково).
Проверим гипотезу
Попробуем восстановить, как проходили голосования. Поищем в твиттере. Здесь под хештегами #kotlin и #kotlinevent можно обнаружить много фотографий митапов и голосований (рис. 4). Действительно, на фото видно, что участники голосовали вместе и, возможно, обсуждали свои оценки.
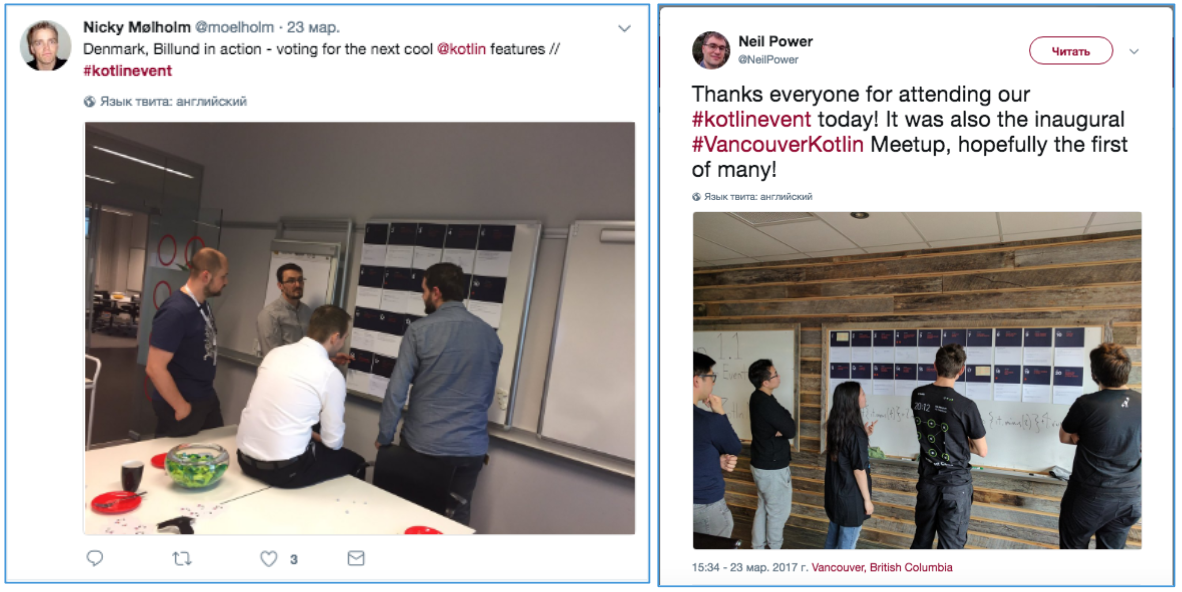
Рисунок 4. Твиты участников митапов с фотографиями голосований
Отобразим на одной диаграмме голосования митапов (рис. 5). Визуально оценить, как проголосовал каждый митап, здесь сложно, зато хорошо видно, как по-разному рапределились оценки (это распределение еще раз подтверждает и нашу гипотезу о слабой взаимосвязи между группами).
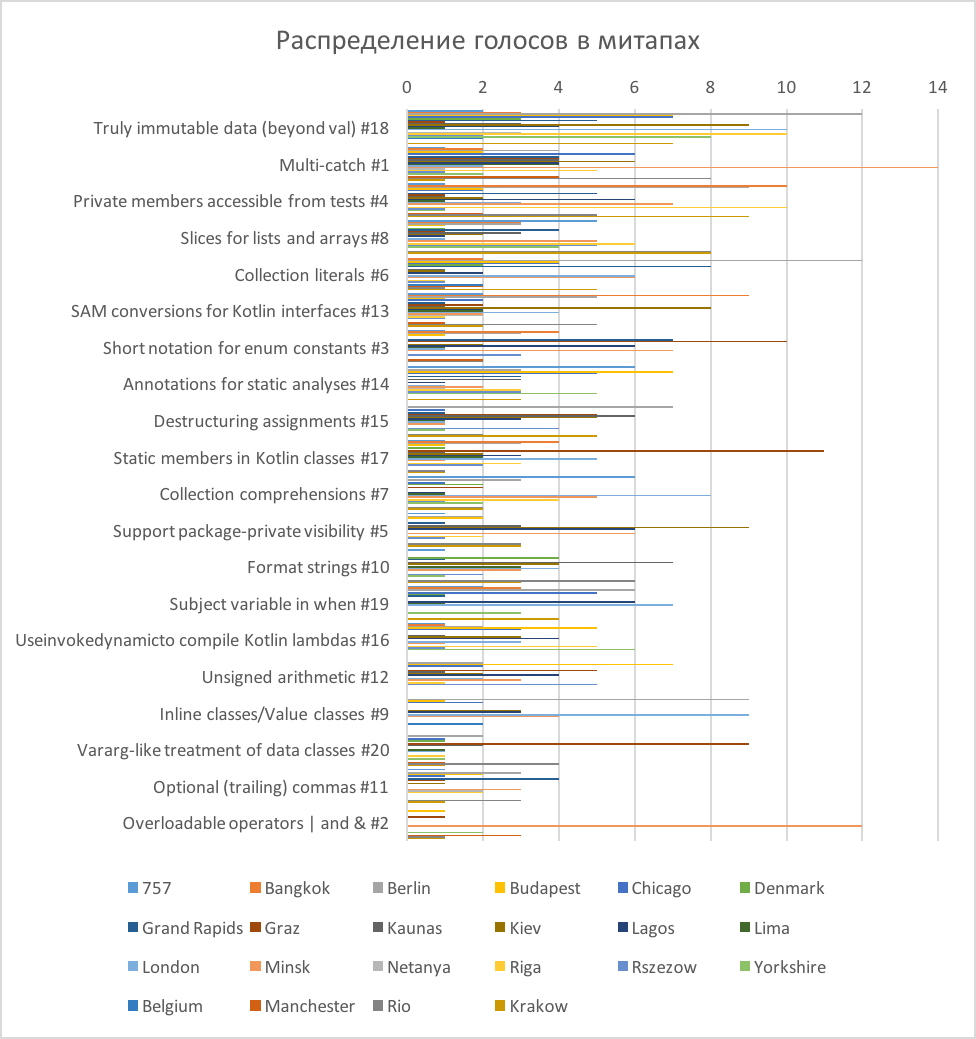
Рисунок 5. Распределение голосов в митапах
На диаграмме видно, что оценка «1» ставилась чаще остальных. То есть, во всех группах, за исключением Берлина и Бельгии, были функции, за которые проголосовал один человек одним стикером. В Бельгии участвовало всего 6 голосов (они распределились по 2 голоса за 3 функции), а в Берлине было просто много участников (90 голосов). Итак, почти во всех сообществах были участники, чье мнение не совпадало с большинством.
Чтобы проверить единогласие участников в каждом сообществе, оценим разброс оценок в группах. Из-за специфического типа данных, применить среднеквадратичное отклонение внутри групп не получится. Зато получится посмотреть, сколько оценок, отличных от 0, было поставлено в каждой группе. Так мы узнаем, в каких группах участники голосовали примерно за одни и те же функции, а в каких – за разные (Таблица 1).
Таблица 1. Количество функций и общее число голосов в голосованиях митапов.
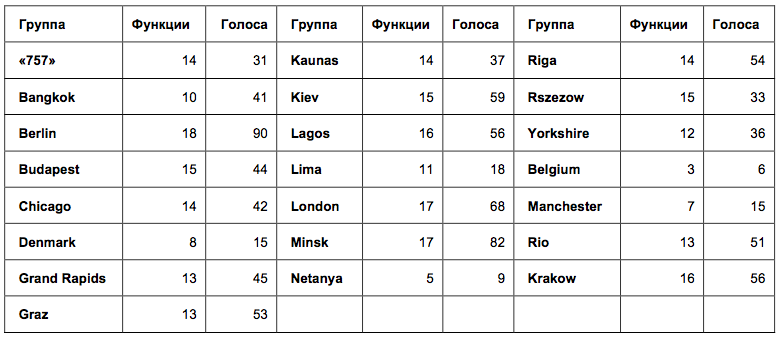
В таблице названий митапов цифры означают: количество функций, за которые были отданы голоса, и общее количество голосов от митапа. Чем больше первая цифра, тем меньше согласия было между участниками. Оказалось, что во всех группах, кроме 3 самых малочисленных, голоса отдавались за более, чем 10 разных функций. Такой разброс оценок наводит на мысль, что участники голосовали вполне независимо. Если бы они подражали друг другу, голоса отдавались бы, например, за 3 одинаковые функции.
Итак, по распределению голосов можно сделать вывод о независимом голосовании участников митапов. И вначале я с готовностью сделала такой вывод. Но затем, обсудив свой вывод с организаторами исследования, я получила закономерный вопрос: действительно ли выбор в группе 10 функций из 20 (то есть, всего половины из предложенных) свидетельствует о большом разбросе голосов? Достаточно ли этих данных для того, чтобы сделать вывод, что голосование участников не было согласованным?
Чтобы это проверить, посмотрим на данные по-другому. На диаграмме видно, что во многих митапах были выбросы: некоторые функции получали значительно больше баллов, чем остальные, за них голосовало большинство участников. Проверим нормальность распределения оценок в митапах с помощью критерия Колмогорова-Смирнова. При использовании критерия Колмогорова-Смирнова отклонение от нормального распределения считается существенным при значении р < 0,05.
Итак, близким к нормальному оказалось распределение оценок только в группах Лаоса, Лондона, Минска, Рио и Кракова (на границе, p=0,047). В остальных группах оценки существенно сместились. Чтобы лучше рассмотреть эти выбросы, я подсчитала, сколько участников митапа предположительно проголосовали за одну функцию.
Если допустить, что каждый участник голосовал одним стикером за одну функцию, то можно приблизительно посчитать процент участников, выбравших одну и ту же функцию:
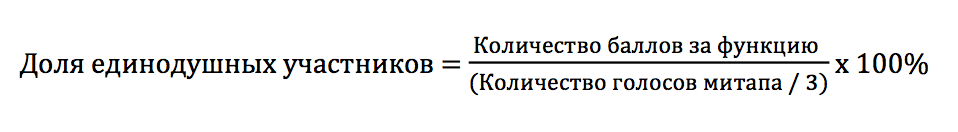
Посмотрим теперь, какая доля участников проголосовала за самую популярную функцию в каждом митапе (Таблица 2).
Таблица 2. Максимальные оценки и доли проголосовавших за них участников митапов*.
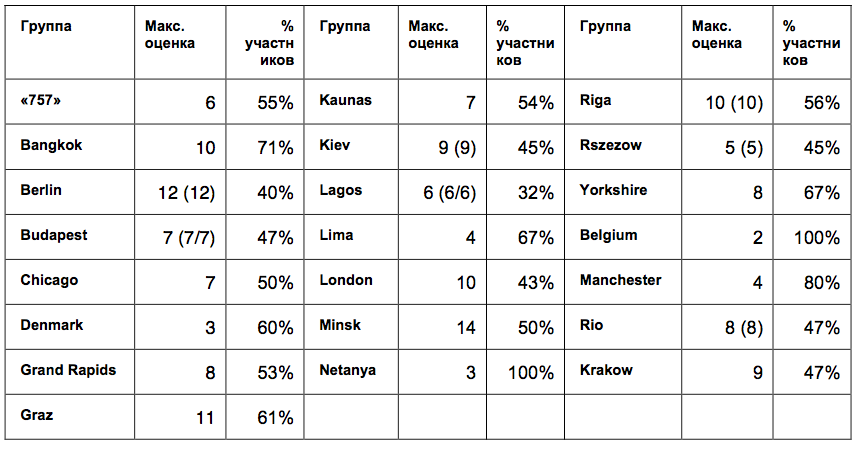
* В скобках – повторяющиеся значения, если высшая оценка была поставлена нескольким функциям
Выходит, почти во всех группах больше половины участников голосовали за одну и ту же функцию. В самых малочисленных группах доля единогласных участников достигала самых высоких значений: Бангкок – 71% из 14 участников; Манчестер – 80% из 5 участников, Нетания – 100% из 3 участников; Бельгия – 100% из 3 участников. А в крупных группах, наоборот, согласованность была более низкой: Берлин – 40% из 30 участников; Лондон – 43% из 23 участников; Лаос – 32% из 19 участников, но на их фоне Минск оказался довольно согласованным при большой группе – 50% из 28 участников.
Получается, что ответы более половины участников в каждом митапе были согласованными, но при этом отличались между митапами, что исключает возможность предпочтения какой-то одной функции всеми пользователями Kotlin. А это наводит на мысль, что внутри митапов пользователи все-таки ориентировались на какую-то общую точку зрения насчет функций. И чем меньше была группа, тем более похожими были ответы ее участников.
Итак, есть основания считать, что участники сообществ выражали согласованное мнение. И согласованность ответов была тем выше, чем меньше был состав группы. Но эти вычисления приблизительны, так как мы допустили, что каждый участник голосовал один раз за каждую функцию. Участники видели, как голосуют другие. На что еще это могло повлиять? Вероятно, участники могли копировать не только ответы, но и манеру голосования.
Если, например, в некоторых сообществах первые отвечающие использовали 2, или 3 стикера за одну функцию, такую модель голосования могли повторить другие, что повлияло бы на распределение ответов. Обсудим это подробнее.
3. Одинаковые ли были условия исследования?
Это более интересный, с точки зрения методологии исследований, вопрос. У двух распределений есть 3 явных фаворита. Почему они выделились, если разброс оценок был большим? Насколько одинаковыми были условия у обоих групп? И было ли это одно исследование, или два совершенно разных исследования?
Представим, как проходило голосование.
Когда участникам митапов давали по 3 круглых оранжевых стикера, у них была возможность использовать их, как монетки: голосовать двумя, или тремя стикерами за одну функцию. А условия on-line исследования могли восприниматься по-другому. Хотя в инструкции было написано, что одну функцию можно выбрать дважды, или трижды, формулировки вопросов («The most expected feature 1», «The most expected feature 2», «The most expected feature 3»), похоже, чаще вызывали желание выбрать в каждом вопросе новую функцию (первую, вторую, третью).
Проверим гипотезу
В сырых данных on-line опроса видно, что дважды проголосовали за одну функцию всего только 10 человек, а трижды – 8 человек из 851. При этом, 11 участников не использовали все возможности голосования, ответив только на 2 вопроса из 3.
А что было в off-line голосованиях? Из сырых данных мы можем делать только косвенные выводы. Например, из 22 митапов у 10 итоговое количество голосов не кратно 3. То есть, в 10 митапах (как минимум) один, или несколько участников тоже использовали при голосовании не все стикеры.
Далее, в рейтингах митапов видно, что в 20 митапах из 22 есть функции с 1 голосом (за них проголосовал один участник одним стикером). Значит, на митапах тоже были люди, отдававшие не все свои голоса за одну функцию. Но сколько таких людей было по сравнению с on-line голосованием, из данных понять сложно.
Мы спросили у нескольких митапов, насколько часто участники голосовали за одну функцию двумя, или тремя стикерами, и получили ответы пока только из Киева и Минска. Организаторы сказали, что участники редко клеили несколько стикеров за функцию. Обычно голосовали одним стикером за одну функцию.
Так что, пока нельзя подтвердить, или опровергнуть гипотезу о том, что участники митапов и участники on-line опроса по-разному понимали инструкцию голосования. Пока аргументы указывают на то, что в обоих случаях участники чаще голосовали за три разных функции, независимо от способа голосования.
4. «Тройка – семерка – туз». А может, было внушение?
Меня не оставляет вопрос: почему в on-line голосовании выделились именно такие лидеры: #6 (с отрывом) – #13 – #18?
128 человек из 851 выбрали в качестве первой функции, 98 человек в качестве второй и 60 – третьей. Из них только двое выбрали функцию #6 дважды. 15 человек проголосовали за нее, как за нежелательную. То есть, за функцию #6 проголосовало положительно 284 участника, или каждый третий участник голосования.
При этом, в off-line голосовании в половине групп за нее никто, или почти никто не голосовал: в 10 группах функция #6 получила 0, или 1 голос. Однако, в 1 группе она получила больше всего голосов и в двух других группах разделила первое место с функцией #18. Общее количество голосов, отданных за #6 в off-line голосованиях, оказалось 60 из 941. Значит, максимум 19% участников в off-line голосованиях выбирали функцию #6. На самом деле, их было меньше, так как не все использовали по 3 голоса, а некоторые могли голосовать за функцию повторно.
Почему on-line голосовали именно за #6, если в off-line опросах она оказалась только на 6 месте в общем рейтинге? Может, еще что-то повлияло на ответы участников?
Проверим гипотезу
Для начала, проверим, действительно ли характер on-line рейтинга отличается от off-line? Визуально распределение оценок в off-line рейтинге кажется более плавным. Сравним распределения оценок с нормальным распределением с помощью статистического критерия Колмогорова-Смирнова.
Действительно, ошибка отклонения от нормального распределения в off-line рейтинге p=0,087, в то время как в on-line рейтинге ошибка значительно меньше, p=0,016. Значит, оценки в off-line опросе распределились нормально, а в on-line опросе 3 функции были оценены существенно выше. Визуальная оценка не подвела.
Итак, остается понять, почему именно эти функции: #6 – #13 – #18 победили в голосовании с таким отрывом.
Оценим еще раз условия on-line опроса.
В блоге Kotlin публикуется пост, в котором написано, что off-line опрос привлек много внимания. Затем читателей приглашают также принять участие в голосовании и размещают ссылку на on-line опрос.
Посмотрим еще раз, как был оформлен пост в блоге Kotlin. Но перед этим я попрошу вас припомнить, рассматривали ли вы первую картинку к статье, которую сейчас читаете? Обратили ли вы внимание, на каких карточках было больше всего оранжевых стикеров? Если вы знакомы с языком Kotlin и обеспокоены тем, какие функции будут добавлены в v.1.2, вероятно, эти карточки для вас что-то значат. Будь я разработчиком, я бы точно рассматривала их и пыталась бы понять, почему люди за них проголосовали.
Итак, я специально выбрала заглавной картинкой к статье тот же коллаж из фотографий, который был размещен в блоге Kotlin прямо над приглашением принять участие в опросе. Рассмотрим его подробнее (рис. 6). Оказывается, на самом первом (левом) и самом крупном снимке отчетливо видно, что больше всего голосов отдано за функции #6, #13 и #18. Карточки размещены именно в таком порядке, карточка #6 видна лучше других и считывается первой.
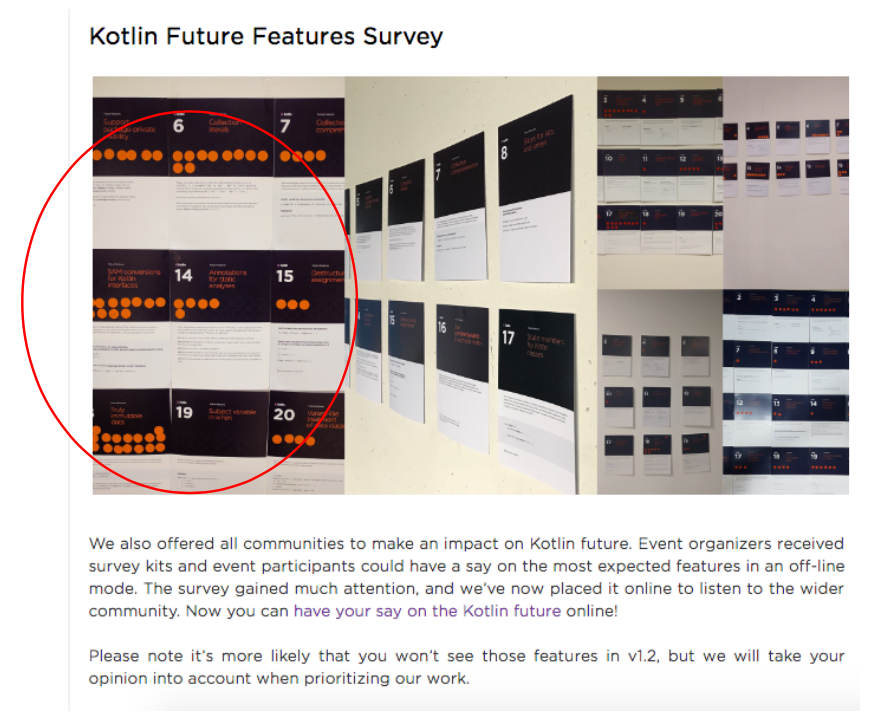
Рисунок 6. Фрагмент поста в блоге Kotlin, приглашающего к on-line тестированию
Таким образом, фотография с результатами опроса могла оказать влияние на оценки участников (осознаваемое, или неосознаваемое) и изменить распределение голосов. Это похоже на действие «эффекта привязки», о влиянии которого на анкетные исследования я писала в одной из прошлых статей.
Сложно поверить, что программисты, работающие с языком Kotlin, подражали ответам, которые увидели на случайной фотографии. С другой стороны, влияние «эффекта привязки» на ответы в анкетных опросах давно описано в науке и фотография не была такой уж случайной. Так что, можно допустить, что на некоторых участников фотография могла оказать влияние. Как бы то ни было, эта гипотеза останется непроверенной, так как для ее доказательства пришлось бы организовать дополнительное исследование.
Ответим на вопросы, поставленные в начале статьи:
1. Действительно ли между участниками митапов и остальными пользователями есть различия? – Такой вывод сделать нельзя, так как в голосованиях участников митапов обнаружилось больше различий, чем между голосованиями всех участников митапов и остальных пользователей.
2. Действительно ли на голоса участников митапов повлияло мнение коллег? – При некоторых допущениях можно сделать вывод, что участники митапов голосовали согласованно. И согласованность ответов была тем выше, чем меньше был размер группы.
3. Одинаково ли воспринимали условия голосования участники митапов и остальные пользователи? – Разные условия исследования могли привести к разной манере голосования, из-за чего двойные и тройные голоса за дну функцию чаще отдавались в митапах, а не при on-line голосовании. Для того, чтобы это доказать, не достаточно данных. Напротив, косвенные аргументы свидетельствуют, что большинство участников предпочитали голосовать за 3 разные функции.
4. Почему в рейтинге on-line голосования первая тройка набрала существенно больше голосов, чем остальные? – Три функции в рейтинге on-line голосования (#6 – #13 – #18), действительно, существенно выше оценены участниками. Возможно, это связано с действием «эффекта привязки» из-за публикации в приглашении к on-line опросу фотографии, на которой карточки с такими номерами были оценены выше других.
Пока это все, что мне удалось обнаружить. Если у вас есть другие идеи, или рекомендации по выбору методов статистики, буду рада им в комментариях.
Если у вас есть случаи исследования пользователей, или сотрудников, вызывающие вопросы, присылайте: проведем расследование.
Я благодарна Алине Долгих за предоставленные материалы и критическое обсуждение статьи, а также участникам facebook-сообщества «Статистика и анализ данных» за готовность помочь в выборе методов статистики.
В итоге получилась история о статистике, твитах, конформности, внушении и скидках на одежду.
Рисунок 1. Фотографии с результатами опросов
Статья может быть интересна тем, кто занимается опросами и исследованиями пользователей.
Итак, весной прошли международные опросы пользователей языка Kotlin о функциях, которые они хотели бы увидеть в следующем релизе. Позже в блоге Kotlin появился пост с результатами исследования и ссылкой на сырые данные.
Исследование проводилось в 2 этапа. Часть пользователей языка голосовали на митапах, посвященных Kotlin 1.1, вторая часть заполняла on-line анкеты. В результате получилось 2 рейтинга с 3 явными фаворитами в каждом (рис. 2). И фавориты не совпали.
Рисунок 2. Рейтинги ожидаемых новых функций в Kotlin 1.2: результаты off-line и on-line опросов
Почему результаты двух опросов так отличаются друг друг от друга?
Организаторы предложили 2 объяснения:
1. Отличия групп. Участники митапов отличаются от остальных пользователей Kotlin.
2. Предвзятость. На off-line голосовании участники видели, за какую функцию голосуют другие, и это могло повлиять на их мнение.
Попробуем подробнее разобраться, почему результаты отличаются. Проведем маленькое расследование и ответим на вопросы:
1. Действительно ли между участниками митапов и остальными пользователями есть различия?
2. Действительно ли на голоса участников митапов повлияло мнение коллег?
3. Одинаково ли воспринимали условия голосования участники митапов и остальные пользователи?
4. Почему в рейтинге on-line голосования первая тройка набрала существенно больше голосов, чем остальные функции?
Для начала, восстановим, как проходило исследование.
Процедура исследования
Опрос состоял из 2 частей.
Off-line часть заполнялась участниками митапов. Большинство митапов прошло в одно время, 23 марта, в 21 стране мира (всего 30 митапов). Их участники смотрели прямую трансляцию демонстрации функций Kotlin 1.1, а после могли проголосовать за появление новых функций. Некоторые митапы голосовали до демонстрации (рис. 3). Для этого им раздали по 3 круглых оранжевых стикера, которые нужно было прикрепить к карточкам с описанием функций. Можно было использовать по 1 стикеру за функцию, или проголосовать двумя, или всеми тремя стикерами за одну функцию. Сейчас невозможно восстановить, сколько человек принимало участие в голосовании в каждом митапе, так как каждое сообщество назвало организаторам исследования только рейтинг: общее количество стикеров, оставленных за каждую функцию. Свои рейтинги передали 22 сообщества.
Рисунок 3: Фотографии из твитов сообществ Kotlin (на стенах видны карточки для голосования)
On-line часть опроса прошла после off-line части. В блоге Kotlin появилась статья с видео-записью трансляции и рассказом об опросе, проведенном в сообществах. В статье было написано, что опрос привлек много внимания, и теперь создатели предлагают пройти его on-line всем желающим и «высказать свое мнение о будущем Kotlin».
Участникам предлагалась on-line анкета с такими же, казалось бы, вопросами – об ожидаемых функциях языка. В конце анкеты были приложены такие же карточки с описанием каждой функции, которые были использованы после митапов. Дополнительно в анкету добавили вопрос о самой нежелательной функции. На on-line анкету был получен 851 ответ.
Результаты исследования
Данные обоих опросов обрабатывались простым суммированием. В результате получилось 2 списка – on-line и off-line рейтинги с 3 явными фаворитами в каждом (рис. 2), фавориты не совпали.
Только функция #18 «Truly immutable data» попала в первую тройку одновременно в обоих опросах. Более-менее совпала первая шестерка, с перемешанным порядком, за исключением двух функций: функция #4 «Private members accessible from tests» в on-line опросе оказалась всего лишь на 12 строчке и набрала максимум голосов против, а функция #9 «Inline classes/Value classes» в off-line опросе оказалась на 17 строчке.
Итак, лидерами в обоих опросах стали:
#18 Truly immutable data
#1: Multi-catch
#13: SAM conversions for Kotlin interfaces
#6: Collection literals
#8: Slices for lists and arrays
Обсуждение
1. А есть ли на самом деле различия?
На диаграммах различия явно видны. Но это первая ловушка, о которой предупреждают исследователей: вывод о различиях между группами не делается по простому подсчету средних, или частот. Здесь должна быть шутка про «среднее по больнице». На фото карточек off-line голосования видно, что на разных митапах лидерами мнений оказывались разные функции. А вдруг, мнения участников сильно различались, и получившиеся рейтинги – просто результат случайных колебаний?
Проверим гипотезу
Такие догадки проверяют статистикой. Но в нашем случае получилось 2 разных вида сырых данных: номинальные данные в on-line голосовании и количественные в off-line голосовании. Поэтому попробуем посмотреть просто на корреляции итоговых списков. Если получится, что корреляция между двумя списками сильнее, чем корреляции между списками митапов, это будет значить, что среди участников разных митапов согласия меньше, чем между всеми участниками митапов и участниками on-line голосования. А это будет значить, что нельзя делать вывод о том, что участники митапов и участники on-line голосования – это две существенно разные группы.
Коэффициент корреляции Спирмена между on-line и off-line голосованиями получился таким: r=0,680, p=0,001. В классификации Дж. Коэна для социальных исследований это довольно высокий показатель взаимосвязи (>0,5 – значительная корреляция).
Теперь посмотрим, как оценки митапов коррелируют между собой. Оказалось, что между списками митапов нет ни одной корреляции, превышающей значение 0,680. Самая сильная корреляция (0,618) проявилась между Бельгией и Берлином. Более того, были даже отрицательные корреляции (например, -0,454 между Лимой и Будапештом: интересно было бы узнать, есть ли объяснение этих отличий).
Другими словами, участники митапов в разных странах меньше согласны друг с другом, чем в общем согласны с on-line пользователями.
Насчет этого эффекта есть интересный пример из социальной психологии.
Несмотря на традиционные представления, научные исследования показывают, что различия между группами (между мужчинами и женщинами) часто оказываются менее существенными, чем различия внутри гендерных групп (например, только между женщинами).
Так, в разных странах проводились исследования математических способностей у мальчиков и девочек. В части стран лучше успевали мальчики, в других странах – девочки. Везде различия были статистически значимыми. И если бы мы знали только об одном таком исследовании, это бы могло сформировать наше представление о математических способностях мужчин и женщин. Но ученые провели мета-исследование и проверили разбросы внутри групп. В большинстве стран различия между мальчиками и девочками оказались меньше, чем различия внутри групп мальчиков и девочек (D. Baker, D. Jones, 1993).
Часто группы, которые нам кажутся очевидно разными, внутри имеют даже больший разброс. Особенно интересно узнавать про такие исследования внутри расовых групп (Zuckerman, 1990).
Вроде, о глобальных различиях между группами теперь можно не говорить. Но остается вопрос: почему результаты распределились именно так, почему в рейтингах есть явные фавориты, набравшие существенно больше голосов? Что еще могло повлиять на голоса участников?
2. Участники влияли друг на друга?
По мнению организаторов исследования, совместное голосование на митапах могло повлиять на ответы участников, изменить их мнение.
Если бы это было так, ответы внутри групп распределялись бы скученно, с маленьким разбросом (в группах все бы проголосовали примерно одинаково).
Проверим гипотезу
Попробуем восстановить, как проходили голосования. Поищем в твиттере. Здесь под хештегами #kotlin и #kotlinevent можно обнаружить много фотографий митапов и голосований (рис. 4). Действительно, на фото видно, что участники голосовали вместе и, возможно, обсуждали свои оценки.
Рисунок 4. Твиты участников митапов с фотографиями голосований
Отобразим на одной диаграмме голосования митапов (рис. 5). Визуально оценить, как проголосовал каждый митап, здесь сложно, зато хорошо видно, как по-разному рапределились оценки (это распределение еще раз подтверждает и нашу гипотезу о слабой взаимосвязи между группами).
Рисунок 5. Распределение голосов в митапах
На диаграмме видно, что оценка «1» ставилась чаще остальных. То есть, во всех группах, за исключением Берлина и Бельгии, были функции, за которые проголосовал один человек одним стикером. В Бельгии участвовало всего 6 голосов (они распределились по 2 голоса за 3 функции), а в Берлине было просто много участников (90 голосов). Итак, почти во всех сообществах были участники, чье мнение не совпадало с большинством.
Чтобы проверить единогласие участников в каждом сообществе, оценим разброс оценок в группах. Из-за специфического типа данных, применить среднеквадратичное отклонение внутри групп не получится. Зато получится посмотреть, сколько оценок, отличных от 0, было поставлено в каждой группе. Так мы узнаем, в каких группах участники голосовали примерно за одни и те же функции, а в каких – за разные (Таблица 1).
Таблица 1. Количество функций и общее число голосов в голосованиях митапов.
В таблице названий митапов цифры означают: количество функций, за которые были отданы голоса, и общее количество голосов от митапа. Чем больше первая цифра, тем меньше согласия было между участниками. Оказалось, что во всех группах, кроме 3 самых малочисленных, голоса отдавались за более, чем 10 разных функций. Такой разброс оценок наводит на мысль, что участники голосовали вполне независимо. Если бы они подражали друг другу, голоса отдавались бы, например, за 3 одинаковые функции.
Итак, по распределению голосов можно сделать вывод о независимом голосовании участников митапов. И вначале я с готовностью сделала такой вывод. Но затем, обсудив свой вывод с организаторами исследования, я получила закономерный вопрос: действительно ли выбор в группе 10 функций из 20 (то есть, всего половины из предложенных) свидетельствует о большом разбросе голосов? Достаточно ли этих данных для того, чтобы сделать вывод, что голосование участников не было согласованным?
Чтобы это проверить, посмотрим на данные по-другому. На диаграмме видно, что во многих митапах были выбросы: некоторые функции получали значительно больше баллов, чем остальные, за них голосовало большинство участников. Проверим нормальность распределения оценок в митапах с помощью критерия Колмогорова-Смирнова. При использовании критерия Колмогорова-Смирнова отклонение от нормального распределения считается существенным при значении р < 0,05.
Итак, близким к нормальному оказалось распределение оценок только в группах Лаоса, Лондона, Минска, Рио и Кракова (на границе, p=0,047). В остальных группах оценки существенно сместились. Чтобы лучше рассмотреть эти выбросы, я подсчитала, сколько участников митапа предположительно проголосовали за одну функцию.
Если допустить, что каждый участник голосовал одним стикером за одну функцию, то можно приблизительно посчитать процент участников, выбравших одну и ту же функцию:
Посмотрим теперь, какая доля участников проголосовала за самую популярную функцию в каждом митапе (Таблица 2).
Таблица 2. Максимальные оценки и доли проголосовавших за них участников митапов*.
* В скобках – повторяющиеся значения, если высшая оценка была поставлена нескольким функциям
Выходит, почти во всех группах больше половины участников голосовали за одну и ту же функцию. В самых малочисленных группах доля единогласных участников достигала самых высоких значений: Бангкок – 71% из 14 участников; Манчестер – 80% из 5 участников, Нетания – 100% из 3 участников; Бельгия – 100% из 3 участников. А в крупных группах, наоборот, согласованность была более низкой: Берлин – 40% из 30 участников; Лондон – 43% из 23 участников; Лаос – 32% из 19 участников, но на их фоне Минск оказался довольно согласованным при большой группе – 50% из 28 участников.
Получается, что ответы более половины участников в каждом митапе были согласованными, но при этом отличались между митапами, что исключает возможность предпочтения какой-то одной функции всеми пользователями Kotlin. А это наводит на мысль, что внутри митапов пользователи все-таки ориентировались на какую-то общую точку зрения насчет функций. И чем меньше была группа, тем более похожими были ответы ее участников.
Поведение окружающих, действительно, оказывает влияние на взрослых здравомыслящих людей. Это описывают многие эксперименты конформности. Но бывают случаи, когда не только групповое давление, но и просто модель поведения других людей меняет действия человека.
В эксперименте С. Милгрэма на оживленной улице Нью-Йорка сообщники экспериментатора останавливались и начинали смотреть в одну точку, подняв головы. Оказалось, что число присоединившихся к ним прохожих росло по мере увеличения группы. Обычные люди тоже останавливались и начинали смотреть вверх, не зная, куда смотрят остальные. Эксперимент проводился с разным количеством сообщников. Чем больше их было (от 1 до 5), тем больше подражателей они привлекали. Но после того, как размер группы сообщников превышал 5 человек, рост подражателей останавливался. Группа становилась больше, но подражателей больше не становилось.
В других исследованиях – Герарда (1968) и Розенберга (1961) – также было показано, что увеличение группы сверх 5 человек приводит к снижению конформности.
Итак, есть основания считать, что участники сообществ выражали согласованное мнение. И согласованность ответов была тем выше, чем меньше был состав группы. Но эти вычисления приблизительны, так как мы допустили, что каждый участник голосовал один раз за каждую функцию. Участники видели, как голосуют другие. На что еще это могло повлиять? Вероятно, участники могли копировать не только ответы, но и манеру голосования.
Если, например, в некоторых сообществах первые отвечающие использовали 2, или 3 стикера за одну функцию, такую модель голосования могли повторить другие, что повлияло бы на распределение ответов. Обсудим это подробнее.
3. Одинаковые ли были условия исследования?
Это более интересный, с точки зрения методологии исследований, вопрос. У двух распределений есть 3 явных фаворита. Почему они выделились, если разброс оценок был большим? Насколько одинаковыми были условия у обоих групп? И было ли это одно исследование, или два совершенно разных исследования?
Представим, как проходило голосование.
Когда участникам митапов давали по 3 круглых оранжевых стикера, у них была возможность использовать их, как монетки: голосовать двумя, или тремя стикерами за одну функцию. А условия on-line исследования могли восприниматься по-другому. Хотя в инструкции было написано, что одну функцию можно выбрать дважды, или трижды, формулировки вопросов («The most expected feature 1», «The most expected feature 2», «The most expected feature 3»), похоже, чаще вызывали желание выбрать в каждом вопросе новую функцию (первую, вторую, третью).
Проверим гипотезу
В сырых данных on-line опроса видно, что дважды проголосовали за одну функцию всего только 10 человек, а трижды – 8 человек из 851. При этом, 11 участников не использовали все возможности голосования, ответив только на 2 вопроса из 3.
А что было в off-line голосованиях? Из сырых данных мы можем делать только косвенные выводы. Например, из 22 митапов у 10 итоговое количество голосов не кратно 3. То есть, в 10 митапах (как минимум) один, или несколько участников тоже использовали при голосовании не все стикеры.
Далее, в рейтингах митапов видно, что в 20 митапах из 22 есть функции с 1 голосом (за них проголосовал один участник одним стикером). Значит, на митапах тоже были люди, отдававшие не все свои голоса за одну функцию. Но сколько таких людей было по сравнению с on-line голосованием, из данных понять сложно.
Мы спросили у нескольких митапов, насколько часто участники голосовали за одну функцию двумя, или тремя стикерами, и получили ответы пока только из Киева и Минска. Организаторы сказали, что участники редко клеили несколько стикеров за функцию. Обычно голосовали одним стикером за одну функцию.
Так что, пока нельзя подтвердить, или опровергнуть гипотезу о том, что участники митапов и участники on-line опроса по-разному понимали инструкцию голосования. Пока аргументы указывают на то, что в обоих случаях участники чаще голосовали за три разных функции, независимо от способа голосования.
4. «Тройка – семерка – туз». А может, было внушение?
Меня не оставляет вопрос: почему в on-line голосовании выделились именно такие лидеры: #6 (с отрывом) – #13 – #18?
128 человек из 851 выбрали в качестве первой функции, 98 человек в качестве второй и 60 – третьей. Из них только двое выбрали функцию #6 дважды. 15 человек проголосовали за нее, как за нежелательную. То есть, за функцию #6 проголосовало положительно 284 участника, или каждый третий участник голосования.
При этом, в off-line голосовании в половине групп за нее никто, или почти никто не голосовал: в 10 группах функция #6 получила 0, или 1 голос. Однако, в 1 группе она получила больше всего голосов и в двух других группах разделила первое место с функцией #18. Общее количество голосов, отданных за #6 в off-line голосованиях, оказалось 60 из 941. Значит, максимум 19% участников в off-line голосованиях выбирали функцию #6. На самом деле, их было меньше, так как не все использовали по 3 голоса, а некоторые могли голосовать за функцию повторно.
Почему on-line голосовали именно за #6, если в off-line опросах она оказалась только на 6 месте в общем рейтинге? Может, еще что-то повлияло на ответы участников?
Проверим гипотезу
Для начала, проверим, действительно ли характер on-line рейтинга отличается от off-line? Визуально распределение оценок в off-line рейтинге кажется более плавным. Сравним распределения оценок с нормальным распределением с помощью статистического критерия Колмогорова-Смирнова.
Действительно, ошибка отклонения от нормального распределения в off-line рейтинге p=0,087, в то время как в on-line рейтинге ошибка значительно меньше, p=0,016. Значит, оценки в off-line опросе распределились нормально, а в on-line опросе 3 функции были оценены существенно выше. Визуальная оценка не подвела.
Итак, остается понять, почему именно эти функции: #6 – #13 – #18 победили в голосовании с таким отрывом.
Оценим еще раз условия on-line опроса.
В блоге Kotlin публикуется пост, в котором написано, что off-line опрос привлек много внимания. Затем читателей приглашают также принять участие в голосовании и размещают ссылку на on-line опрос.
Посмотрим еще раз, как был оформлен пост в блоге Kotlin. Но перед этим я попрошу вас припомнить, рассматривали ли вы первую картинку к статье, которую сейчас читаете? Обратили ли вы внимание, на каких карточках было больше всего оранжевых стикеров? Если вы знакомы с языком Kotlin и обеспокоены тем, какие функции будут добавлены в v.1.2, вероятно, эти карточки для вас что-то значат. Будь я разработчиком, я бы точно рассматривала их и пыталась бы понять, почему люди за них проголосовали.
Итак, я специально выбрала заглавной картинкой к статье тот же коллаж из фотографий, который был размещен в блоге Kotlin прямо над приглашением принять участие в опросе. Рассмотрим его подробнее (рис. 6). Оказывается, на самом первом (левом) и самом крупном снимке отчетливо видно, что больше всего голосов отдано за функции #6, #13 и #18. Карточки размещены именно в таком порядке, карточка #6 видна лучше других и считывается первой.
Рисунок 6. Фрагмент поста в блоге Kotlin, приглашающего к on-line тестированию
Таким образом, фотография с результатами опроса могла оказать влияние на оценки участников (осознаваемое, или неосознаваемое) и изменить распределение голосов. Это похоже на действие «эффекта привязки», о влиянии которого на анкетные исследования я писала в одной из прошлых статей.
«Эффект привязки» был описан в одном из исследований Д. Канемана. Если одну группу испытуемых спросить: «Дожил ли Ганди до 114 лет? В каком возрасте он умер?», а другую: «Дожил ли Ганди до 35 лет? В каком возрасте он умер?», то первая группа оценит жизнь Ганди как гораздо более долгую, чем вторая.
Чаще всего эффект привязки используется в торговле, когда пишется самая низкая цена в группе товаров без уточнения, что остальные товары стоят дороже (рис. 7). Или, наоборот, когда вначале выставляются самые дорогие товары, чтобы скидки на остальные товары воспринимались более существенными.
Рисунок 7. Эффект привязки часто используют в магазинах одежды, указывая над стойкой самую низкую цену, или самую большую скидку, соответствующую, однако, не всем вещам, висящим на стойке
Интересно, в исследованиях было доказано, что эффект привязки продолжает действовать, даже если человек знает о нем.

Сложно поверить, что программисты, работающие с языком Kotlin, подражали ответам, которые увидели на случайной фотографии. С другой стороны, влияние «эффекта привязки» на ответы в анкетных опросах давно описано в науке и фотография не была такой уж случайной. Так что, можно допустить, что на некоторых участников фотография могла оказать влияние. Как бы то ни было, эта гипотеза останется непроверенной, так как для ее доказательства пришлось бы организовать дополнительное исследование.
Выводы
Ответим на вопросы, поставленные в начале статьи:
1. Действительно ли между участниками митапов и остальными пользователями есть различия? – Такой вывод сделать нельзя, так как в голосованиях участников митапов обнаружилось больше различий, чем между голосованиями всех участников митапов и остальных пользователей.
2. Действительно ли на голоса участников митапов повлияло мнение коллег? – При некоторых допущениях можно сделать вывод, что участники митапов голосовали согласованно. И согласованность ответов была тем выше, чем меньше был размер группы.
3. Одинаково ли воспринимали условия голосования участники митапов и остальные пользователи? – Разные условия исследования могли привести к разной манере голосования, из-за чего двойные и тройные голоса за дну функцию чаще отдавались в митапах, а не при on-line голосовании. Для того, чтобы это доказать, не достаточно данных. Напротив, косвенные аргументы свидетельствуют, что большинство участников предпочитали голосовать за 3 разные функции.
4. Почему в рейтинге on-line голосования первая тройка набрала существенно больше голосов, чем остальные? – Три функции в рейтинге on-line голосования (#6 – #13 – #18), действительно, существенно выше оценены участниками. Возможно, это связано с действием «эффекта привязки» из-за публикации в приглашении к on-line опросу фотографии, на которой карточки с такими номерами были оценены выше других.
Пока это все, что мне удалось обнаружить. Если у вас есть другие идеи, или рекомендации по выбору методов статистики, буду рада им в комментариях.
Если у вас есть случаи исследования пользователей, или сотрудников, вызывающие вопросы, присылайте: проведем расследование.
Я благодарна Алине Долгих за предоставленные материалы и критическое обсуждение статьи, а также участникам facebook-сообщества «Статистика и анализ данных» за готовность помочь в выборе методов статистики.
Поделиться с друзьями
UbuRus
Надеюсь данное иследование помогло правильно расставить приоритеты Котлин команды. Чувствую личную ответсвенность за 6-13-18. Мне кажется это далеко не лучший набор фич из списка (https://bkug.by/wp-content/uploads/2017/03/Future_Features_Cards.pdf) :)
TamaraK
В посте с приглашением к исследованию организаторы написали: «Please note it’s more likely that you won’t see those features in v1.2, but we will take your opinion into account when prioritizing our work.»
И еще обсуждение результатов опросов собрало много комментариев в блоге Kotlin
Так что, создатели языка получили много мнений :)