

{kind=link}
В статье под катом мы поговорим о том, как бороться с энтропией в конфигурационных файлах.
Рождение файлов конфигурации
Давным-давно один разработчик написал простое веб-приложение для хранения данных о размерах зарплат сотрудников компании. Он использовал две базы: рабочую с настоящими сотрудниками и зарплатами и тестовую с выдуманными данными.
Однажды поздно ночью он перенес в рабочую базу новую функцию и забыл поменять жестко вбитую ссылку на тестовую базу:
mysql_connect("db-staging.example.com", "admin", "admin");Следующим утром босс зашел в систему и обнаружил, что там вместо сотрудников таинственным образом появились герои диснеевских мультиков.
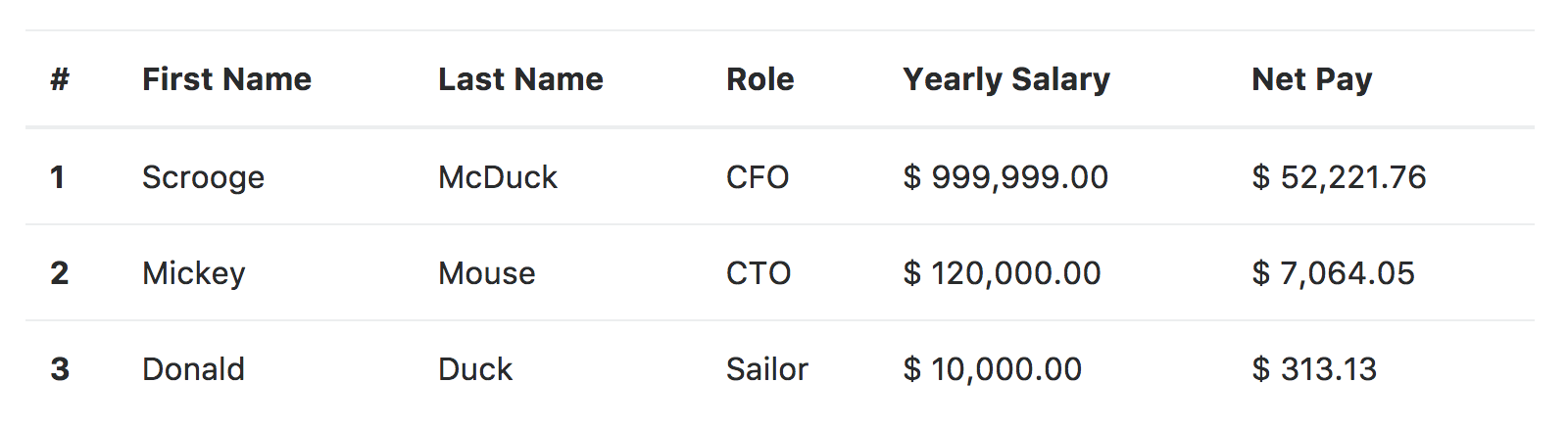
Босса это не порадовало.
Твердо намереваясь больше никогда не повторить эту ошибку, разработчик решил заменить жестко вбитое имя хоста на переменную.
Так родился первый файл конфигурации.
; Не хранить в SVN
[db]
host = db1.example.com
dbname = payrolls
user = admin
pass = s3cur3Прошло несколько лет, и настройки подключения к базам данных все еще остаются первым, что люди стараются поместить в файлы конфигурации. Но теперь у нас также есть API-ключи, токены сторонних систем и другие всевозможные виды необходимой информации, обладающей неприятной особенностью периодически меняться.
Раньше у нас в buildo веб-приложения использовали 2 файла конфигурации.
Серверные API на Scala читали конфигурационные данные из файла application.conf. Это выглядело следующим образом:
app {
db = {
url = "jdbc:postgresql://localhost:5432/app"
user = "postgres"
password = ""
driver = org.h2.Driver
keepAliveConnection = true
queriesTimeoutSeconds = 1
connectionTimeout = 1000
numThreads = 1
}
interface = "0.0.0.0"
port = 8082
allowedHostnames = ["localhost"]
allowedHeaders = ["Content-Type", "Authorization", "Cache-Control", "Pragma"]
#Timeout for reading routine time from file
routineTimeDataTimeout = 1
localBackupPath = "/Users/fra/buildo/app/backup"
serviceEndpoint = "http://localhost:8083"
maximumItemsNumber = 100000000
#Wait 5 seconds before killing all connections
waitBeforeKillingConnectionsMillis = 5000
#Size of the buffer used to read and write files
streamBufferSize = 4096
}Клиенты на JS использовали JSON-файл config.json:
{
"NODE_ENV": "development",
"hostname": "localhost",
"port": 9090,
"apiEndpoint": "https://api-buildo-dev.example.com/v2",
"gMapsAPIKey": "abcdefghijklmnopqrstuvwxyz",
"title": "Yolo",
"username": "test-temp@buildo.io",
"password": "test",
"debug": "state*,react-avenger*"
}Оба файла добавлялись в .gitignore и никогда не попадали в Git.
Постойте, вам же нужно использовать переменные окружения!
Возможно, вы знакомы с манифестом Twelve-Factor App, в котором рекомендуется хранить конфигурационную информацию в переменных окружения, а не в файлах конфигурации. Однако, несмотря на то что это удобный, независимый от языка способ хранения конфигурационной информации, он не решает основную проблему. Если приложению нужно несколько параметров конфигурации, вы в итоге создаете файл примерно следующего содержания:
export MY_APP_VAR1="foo"
export MY_APP_VAR2="bar"Поздравляю, вы только что создали универсальный файл конфигурации! Вы также открыли первый закон конфигодинамики:
Значения параметров конфигурации не могут быть созданы или уничтожены, они лишь переходят из одного вида в другой.

https://commons.wikimedia.org/wiki/File:Carnot_heat_engine_2.svg
{kind=link}
Делиться — значит заботиться
Когда я только начинаю работать над проектом и клонирую репозиторий в первый раз, проект часто отказывается запускаться без конфигурационного файла.
$ npm install && npm start
[...]
Error: Cannot find module './config.json'Обычно я задаю вопрос в Slack, и другой разработчик скидывает мне рабочую версию конфига в личный чат (это, конечно, глупо, но доподлинно известно, что мы не единственные, кто так делает).
Еще раз взглянув на два предыдущих примера, можно отметить, что они довольно длинные. Это обусловлено вторым законом конфигодинамики:
Общая длина файла конфигурации со временем может только возрастать.

{kind=link}
На самом деле я пропустил несколько значений из реальных файлов конфигурации, которые пересылал по Slack несколько месяцев назад. Но всегда ли можно быть уверенным, что это правильные настройки, а не какой-то тестовый конфиг?
Единственный способ борьбы со вторым законом — это взять немного энергии (разработчика) и заняться поиском параметров конфигурации, которые меняются достаточно редко. Возможно, вы не хотите жестко вбивать их в код, но никто не запретит залить эти значения в репозиторий в какой-нибудь другой форме.
Для приложений на Scala мы используем Lightbend Config. Он позволяет определить reference.conf с параметрами конфигурации по умолчанию, которые можно спокойно поместить в репозиторий.
Не так давно мы начали обращать более пристальное внимание на то, что происходит в файле reference.conf. Мы хотим быть уверены, что это не просто каркас, а полноценный файл конфигурации, в котором есть все необходимые значения для запуска приложения.
При желании перезаписать эти значения можно либо установить локальные переменные окружения, либо создать файл application.conf, который не будет попадать в коммиты, так как добавлен в .gitignore.
Вот начало нашего reference.conf, оформленного в новом стиле:
# This is the reference config file that contains all the default settings.
# Make your edits/overrides in your application.conf.
app {
interface = "0.0.0.0"
interface = ${?SERVICE_INTERFACE}
port = 8080
port = ${?SERVICE_PORT}
...
}Похожая ситуация складывается и с клиентской частью, где мы теперь всегда создаем файл development.json (попадает в коммит), содержащий значения по умолчанию, которые могут быть переопределены в необязательном файле local.json (не попадает в коммит). Мы также создаем файл production.json, в котором находятся настройки для production. В этом случае мы не используем какую-либо open-source-библиотеку, а написали собственную простую реализацию.
Она позволяет нам преобразовать, например, вот такой старый сборочный CI-скрипт:
echo '{
"NODE_ENV": "production",
"port": 9090,
"apiEndpoint": "/api",
"uglify": true,
"gzip": false,
"title": "Awesome App"
}' > config.json
npm run buildк новому виду:
NODE_ENV=production npm run buildСказание о многих окружениях
Следует стремиться к тому, чтобы у вас была одна загруженная в репозиторий дефолтная конфигурация, которой достаточно для запуска приложения в локальном окружении разработчика.
Отсюда формулируется третий закон конфигодинамики:
Длина идеального файла конфигурации в окружении разработчика равняется нулю.

https://commons.wikimedia.org/wiki/File:Can_T%3D0_be_reached.jpg
{kind=link}
А как же другие окружения? Вы, возможно, захотите развернуть приложение в production. Также вполне вероятно, что у вас есть staging-сервер с небольшими отличиями (например, более подробное логирование).
Сначала нужно сократить количество необязательных различий. Если для окружений подходят одинаковые настройки, их, скорее всего, нужно объединить.
Далее необходимо для каждого окружения создать файлы с их специфическими настройками, перезаписывающими установленные по умолчанию. Храните их в Git в репозитории приложения или в отдельном репозитории “infrastructure”. У ваших разработчиков должна быть возможность быстро найти конфигурации для различных окружений и в случае необходимости применить их в своих окружениях разработки.
Наконец, обеспечьте автоматическое развертывание на серверы своих артефактов, которые версионированы в Git. Всячески сопротивляйтесь искушению зайти на сервер по SSH и поправить конфиг вручную. Используйте Ansible, Chef или другой инструмент управления конфигурацией; или берите Packer, собирайте новые AMI и разворачивайте их с помощью Terraform. Используйте наиболее удобный для себя инструмент, но всегда держите свои файлы в синхронизированном состоянии.
Мощь Docker
Мы используем Docker для упаковки приложений, и это упрощает работу с файлами конфигурации за счет уменьшения различий между окружениями.
Следующий файл Docker Compose нормально отработает и на MacBook, и на production-сервере. Имя API-хоста всегда будет api, хоста с базой — db, а Docker позаботится о связывании этих имен с правильными контейнерами. Теперь не нужно прописывать разные имена хостов для разных окружений!
services:
web:
image: quay.io/buildo/app-frontend
ports:
- "80:5000"
links:
- api
api:
image: quay.io/buildo/app-backend
links:
- db
db:
image: postgresЧтобы собирать специфические для окружений настройки в один файл, мы используем функциональность множественных compose-файлов Docker. Взглянув на testing.yml, можно сразу заметить, что тестовое окружение использует нестандартные HTTP-порты, включает development-токен и загружает другую конфигурацию базы данных.
services:
web:
ports:
- 8008:5000
api:
environment:
- "USE_DEVELOPMENT_TOKEN=true"
ports:
- 8005:8080
db:
volumes:
- ./config/postgres/staging.conf:/usr/share/postgresql/postgresql.conf.sampleТаким образом, наши Docker-образы абсолютно одинаковы для всех окружений, и мы используем Compose-файлы для установки специфичных для окружений настроек с помощью переменных окружения или файлов конфигурации.
В большинстве случаев лучше использовать переменные окружения, поскольку значения параметров конфигурации для разных (микро)сервисов могут быть с легкостью включены в один Compose-файл, который затем сохраняется в Git. Как показано в примере выше, если вы считаете, что файл конфигурации в каком-то случае лучше, его можно подключить с помощью Docker-тома. Но не забывайте, что все файлы конфигурации, которые упомянуты в Compose-файле, должны быть также сохранены в Git.
Как хранить секреты
Иногда параметры файлов конфигурации слишком чувствительны для того, чтобы их можно было хранить в Git даже в том случае, если это частный репозиторий. Это могут быть, например, ключи для AWS, токены production API и т. д. Diogo Monica недавно заявил, что эти данные также не стоит хранить в переменных окружения.
В buildo для шифрования конфиденциальной информации мы чаще всего пользуемся git-crypt, поэтому эту информацию можно сохранять в Git, но доступ к ней без PGP-ключа из белого списка получить невозможно.
Более навороченные решения типа Vault или Docker secrets обладают определенными преимуществами. Однако эти инструменты пока находятся у нас в разработке, и, возможно, мы напишем о них в будущих статьях…
Заключение
Пожалуйста, запомните следствия трех законов конфигодинамики:
- перемещение параметров конфигурации в переменные окружения не решает проблему;
- необходимо регулярно проводить поиск необязательных настроек;
- важно обеспечить запуск приложения без файлов конфигурации.
Знание этих законов позволяет уменьшить конфигурационную энтропию и в итоге сэкономить значительное количество времени.
Следующее утверждение иногда зовется нулевым законом конфигодинамики:
Если конфигурация A сохранена в Git и скачана двумя разработчиками B и C, тогда B и C будут находиться в состоянии конфигурационного равновесия.
http://hyperphysics.phy-astr.gsu.edu/hbase/thermo/thereq.html#c2
Ссылки:
- Оригинал: The three laws of config dynamics.
vlreshet
А почему бы просто не хранить примеры конфигов в гите? То есть, храним example.config.json в гите. В нём абсолютно рабочий конфиг (в плане структуры), только все ключи в стиле «123abcde», а коннекты к разным базам и апи в стиле «user@password:port». И всё, проблема решена: разработчик загружает себе проект из гита, быстро создаёт рабочий конфиг из примера, и запускает проект. И все шаманства из передачей конфига в слаке не нужны.
bogolt
Проблема та же, что и с документаций — нужны дополнительные усилия чтобы пример конфига всегда был актуален ( в идеале он должен содержать все возможные значения, равные своим значениям по умолчанию ).
Поэтому очень удобно когда программа умеет по специальному ключу командной строки вывести все ключи конфига ( и более того не принимает ключи не зарегистрированные подобным образом). Получается конфиг актуальнось которого гарантируется кодом.
samizdam
CI и тесты разных уровней в помощь.
В репозитории хранятся конфиги по умолчанию, которые используются при тестировании. Для рабочих экземпляров приложения есть возможность переопределить любой параметр добавок нужный файл.
Переменные окружения это тема, но не для всего. Конфигурация, которая ближе к бизнес-логике, чем к окружению, часто может содержать нескалярные структуры данных и тут .yml удобнее чем .env.
Оба эти формата хорошо расширяемы как в docker-compose так и парсерах когфигов на всех платформах.