
Вводная часть (со ссылками на все статьи)
Неотъемлемой частью системы сбора новостей является робот для обхода сайтов (crawler, круалер, «паук»). В его функции входит отслеживание изменений на указанных сайтах и внесение новых данных в базу данных (БД) системы.
Полностью готового и подходящего решения не было – в связи с этим потребовалось выбрать из имеющихся проектов что-то, что удовлетворяло бы следующим критериям:
Выбранным решением был достаточно популярный робот для обхода сайтов — crawler4j. Он, конечно тянет за собой массу библиотек для анализа полученного контента, однако это не сказывается на скорости его работы или потребляемых ресурсах. В качестве БД ссылок использует Berkley DB, создаваемому в настраиваемом каталоге для каждого анализируемого сайта.
В качестве способа кастомизации разработчиком был выбран гибрид поведенческиих шаблонов «Стратегия» (право на принятие решение о том какие ссылки и разделы сайта анализировать приходится принимать клиенту) и «Наблюдатель» (при обходе сайта данные о странице (адрес, формат, содержание, мета данные) передаются клиенту, который волен сам принимать решать, как с ними поступать).
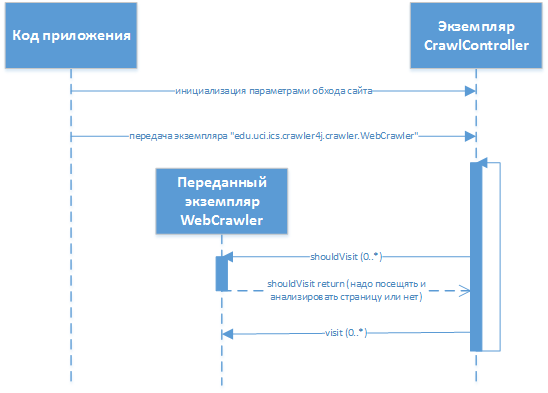
Фактически для разработчика «паук» выглядит как библиотека, которая подключается к проекту и в которую передаются необходимые реализации интерфейсов для кастомизации поведения. Разработчиком расширяется библиотечный класс
, где
Реализацией парсинга сайтов ранее не приходилось заниматься – поэтому сразу же пришлось столкнуться с серией проблем и в процессе их устранения потребовалось сделать несколько решений по реализации и способам обработки полученных данных обхода:
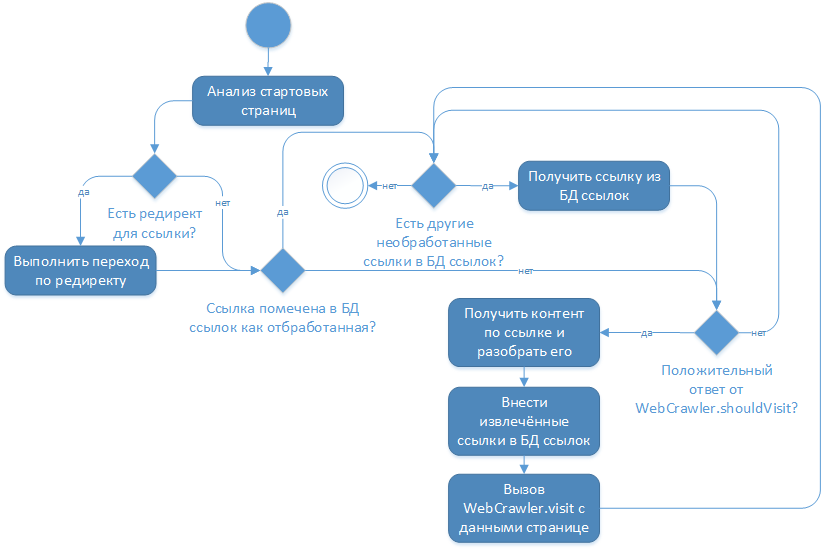
Основной проблемой для меня было некоторое архитектурное решение разработчика cralwer4j о том, что страницы сайта не меняются, т.е. логика его работы такова:
Изучив исходные тексты библиотеки я понял, что никакими настройками данную логику не изменить и было принято решение о создании fork основного проекта. В указанном ответвлении перед действием «Внести извлечённые ссылки в БД ссылок» осуществляется дополнительная проверка на необходимость внесения ссылок в БД ссылок: стартовые страницы сайта никогда не заносятся в эту БД и как результат — при их попадании в основной цикл обработки они получаются повторно и повторно разбираются, выдавая при этом ссылки на свежие новости.
Однако подобная доработка требовала изменения работы с библиотекой, при которой запуск основных методов должен осуществляться на периодической основе, что было легко реализовано с помощью библиотеки quartz. При отсутствии свежих новостей на стартовых страницах метод завершал свою работу через пару секунд (получив стартовые, проанализировав их и получив уже пройдённые ссылки) или записывал в БД свежие новости.
Спасибо за внимание!
Неотъемлемой частью системы сбора новостей является робот для обхода сайтов (crawler, круалер, «паук»). В его функции входит отслеживание изменений на указанных сайтах и внесение новых данных в базу данных (БД) системы.
Полностью готового и подходящего решения не было – в связи с этим потребовалось выбрать из имеющихся проектов что-то, что удовлетворяло бы следующим критериям:
- простота настройки;
- возможность настройки для обхода нескольких сайтов;
- нетребовательность к ресурсам;
- отсутствие дополнительных инфраструктурных вещей (координаторов работы, БД для «паука», дополнительных сервисов и т.д.).
Выбранным решением был достаточно популярный робот для обхода сайтов — crawler4j. Он, конечно тянет за собой массу библиотек для анализа полученного контента, однако это не сказывается на скорости его работы или потребляемых ресурсах. В качестве БД ссылок использует Berkley DB, создаваемому в настраиваемом каталоге для каждого анализируемого сайта.
В качестве способа кастомизации разработчиком был выбран гибрид поведенческиих шаблонов «Стратегия» (право на принятие решение о том какие ссылки и разделы сайта анализировать приходится принимать клиенту) и «Наблюдатель» (при обходе сайта данные о странице (адрес, формат, содержание, мета данные) передаются клиенту, который волен сам принимать решать, как с ними поступать).
Фактически для разработчика «паук» выглядит как библиотека, которая подключается к проекту и в которую передаются необходимые реализации интерфейсов для кастомизации поведения. Разработчиком расширяется библиотечный класс
«edu.uci.ics.crawler4j.crawler.WebCrawler» (с методами «shouldVisit» и «visit»), который в последующем передаётся в библиотеку. Взаимодействие в процессе работы выглядит примерно таким образом:, где
edu.uci.ics.crawler4j.crawler.CrawlController — основной класс библиотеки, через который осуществляется взаимодействие (настройка обхода, передача управляющего кода, получение информации о статусе, запуск/остановка).Реализацией парсинга сайтов ранее не приходилось заниматься – поэтому сразу же пришлось столкнуться с серией проблем и в процессе их устранения потребовалось сделать несколько решений по реализации и способам обработки полученных данных обхода:
- код анализа полученного контента и реализация шаблона «Стратегия» вынесен в виде отдельного проекта, версионность которого идёт отдельно от версий самого «паука»;
- фактический код анализа полученного контента и анализа ссылок реализован на groovy, что позволяет изменить логику работы без перезапуска пауков (активирована опция
«recompileGroovySource»в«org.codehaus.groovy.control.CompilerConfiguration») (при этом соответствующий код реализации«edu.uci.ics.crawler4j.crawler.WebCrawler»фактически содержит в себе лишь интерпретатор groovy, который обрабатывает в себе переданные данные);
- извлечение данных с каждой встреченной страницы в «пауке» осуществляется не полное – убираются комментарии, «шапка» и «подвал», т.е. то что бессмысленно тратит 50% объёма каждой страницы – всё остальное сохраняется в базе MongoDB для последующего анализа (это позволяет перезапустить анализ страниц без повторного обхода сайтов);
- ключевые поля для каждой новости («дата», «заголовок», «тема», «автор» и т.д.) извлекаются уже из базы данных на MongoDB, при этом контролируется их заполненность – при достижении определённого количества ошибок – отправляется уведомление о необходимости корректировки скриптов (верный признак изменения структуры сайта).
Изменение в коде библиотеки
Основной проблемой для меня было некоторое архитектурное решение разработчика cralwer4j о том, что страницы сайта не меняются, т.е. логика его работы такова:
Изучив исходные тексты библиотеки я понял, что никакими настройками данную логику не изменить и было принято решение о создании fork основного проекта. В указанном ответвлении перед действием «Внести извлечённые ссылки в БД ссылок» осуществляется дополнительная проверка на необходимость внесения ссылок в БД ссылок: стартовые страницы сайта никогда не заносятся в эту БД и как результат — при их попадании в основной цикл обработки они получаются повторно и повторно разбираются, выдавая при этом ссылки на свежие новости.
Однако подобная доработка требовала изменения работы с библиотекой, при которой запуск основных методов должен осуществляться на периодической основе, что было легко реализовано с помощью библиотеки quartz. При отсутствии свежих новостей на стартовых страницах метод завершал свою работу через пару секунд (получив стартовые, проанализировав их и получив уже пройдённые ссылки) или записывал в БД свежие новости.
Спасибо за внимание!