
Доброго времени суток, уважаемые читатели
Не так давно преподаватель дал задание: cкачать данные с некоторого сайта на выбор. Не знаю почему, но первое, что пришло мне в голову — это hh.ru.
Далее встал вопрос: "А что же собственно будем выкачивать?", ведь на сайте порядка 5 млн. резюме и 100.000 вакансий.
Решив посмотреть, какими навыками мне придется овладеть в будущем, я набрал в поисковой строке "data science" и призадумался. Может быть по синонимичному запросу найдется больше вакансий и резюме? Нужно узнать, какие формулировки популярны в данный момент. Для этого удобно использовать сервис GoogleTrends.
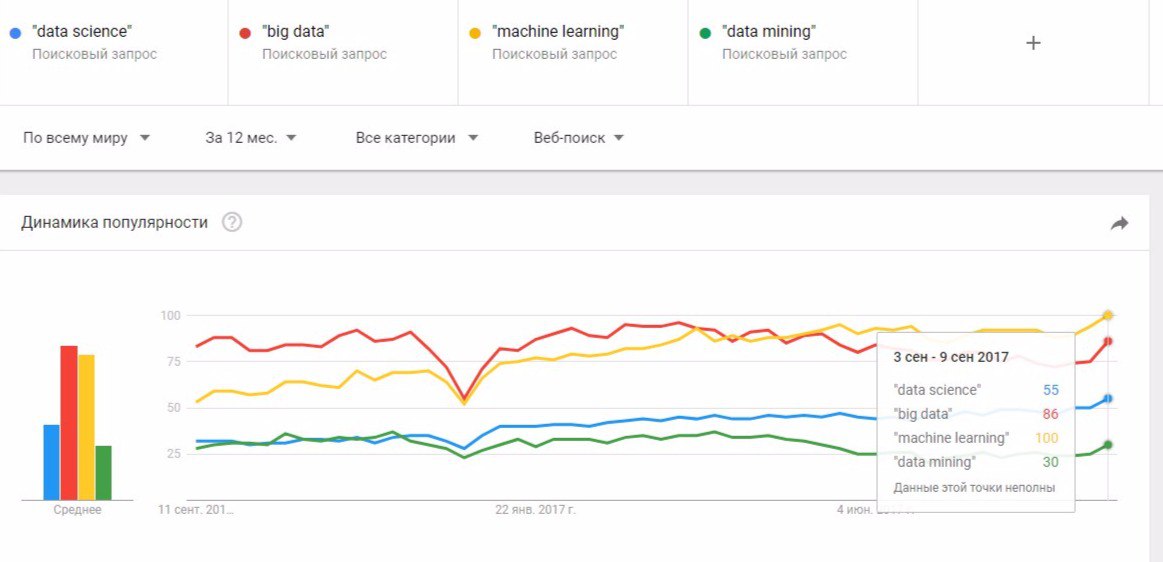
Отсюда видно, что выгоднее всего искать по запросу "machine learning". Кстати, это действительно так.
Соберем вначале вакансии. Их довольно мало, всего 411. API hh.ru поддерживает поиск по вакансиям, поэтому задача становится тривиальной. Единственное, нам необходимо работать с JSON. Для этой цели я использовал пакет jsonlite и его метод fromJSON() принимающий на вход URL и возвращающий разобранную структуру данных.
data <- fromJSON(paste0("https://api.hh.ru/vacancies?text=\"machine+learning\"&page=", pageNum) # Здесь pageNum - номер страницы. На странице отображается 20 вакансий.# Scrap vacancies
vacanciesdf <- data.frame(
Name = character(), # Название компании
Currency = character(), # Валюта
From = character(), # Минимальная оплата
Area = character(), # Город
Requerement = character(), stringsAsFactors = T) # Требуемые навыки
for (pageNum in 0:20) { # Всего страниц
data <- fromJSON(paste0("https://api.hh.ru/vacancies?text=\"machine+learning\"&page=", pageNum))
vacanciesdf <- rbind(vacanciesdf, data.frame(
data$items$area$name, # Город
data$items$salary$currency, # Валюта
data$items$salary$from, # Минимальная оплата
data$items$employer$name, # Название компании
data$items$snippet$requirement)) # Требуемые навыки
print(paste0("Upload pages:", pageNum + 1))
Sys.sleep(3)
}Записав все данные в DataFrame, давайте немного его почистим. Переведем все зарплаты в рубли и избавимся от столбца Currency, так же заменим NA значения в Salary на нулевые.
# Сделаем приличные названия столбцов
names(vacanciesdf) <- c("Area", "Currency", "Salary", "Name", "Skills")
# Вместо зарплаты NA будет нулевая
vacanciesdf[is.na(vacanciesdf$Salary),]$Salary <- 0
# Переведем зарплаты в рубли
vacanciesdf[!is.na(vacanciesdf$Currency) & vacanciesdf$Currency == 'USD',]$Salary <- vacanciesdf[!is.na(vacanciesdf$Currency) & vacanciesdf$Currency == 'USD',]$Salary * 57
vacanciesdf[!is.na(vacanciesdf$Currency) & vacanciesdf$Currency == 'UAH',]$Salary <- vacanciesdf[!is.na(vacanciesdf$Currency) & vacanciesdf$Currency == 'UAH',]$Salary * 2.2
vacanciesdf <- vacanciesdf[, -2] # Currency нам больше не нужна
vacanciesdf$Area <- as.character(vacanciesdf$Area)После этого имеем DataFrame вида:

Пользуясь случаем, посмотрим сколько вакансий в городах и какая у них средняя зарплата.
vacanciesdf %>% group_by(Area) %>% filter(Salary != 0) %>%
summarise(Count = n(), Median = median(Salary), Mean = mean(Salary)) %>%
arrange(desc(Count))
Для scraping`a в R обычно используется пакет rvest, имеющий два ключевых метода read_html() и html_nodes(). Первый позволяет скачивать страницы из интернета, а второй обращаться к элементам страницы с помощью xPath и CSS-селектора. API не поддерживает возможность поиска по резюме, но дает возможность получить информацию о нем по id. Будем выгружать все id, а затем уже через API получать данные из резюме. Всего резюме на сайте по данному запросу — 1049.
hhResumeSearchURL <- 'https://hh.ru/search/resume?exp_period=all_time&order_by=relevance&text=machine+learning&pos=full_text&logic=phrase&clusters=true&page=';
# Загрузим очередную страницу с номером pageNum
hDoc <- read_html(paste0(hhResumeSearchURL, as.character(pageNum)))
# Выделим все аттрибуты ссылок на странице
ids <- html_nodes(hDoc, css = 'a') %>% as.character()
# Выделим из ссылок необходимые id ( последовательности букв и цифр длины 38 )
ids <- as.vector(ids) %>% `[`(str_detect(ids, fixed('/resume/'))) %>%
str_extract(pattern = '/resume/.{38}') %>% str_sub(str_count('/resume/') + 1)
ids <- ids[4:length(ids)] # В первых 3х мусорПосле этого уже известным нам методом fromJSON получим информацию, содержащуюся в резюме.
resumes <- fromJSON(paste0("https://api.hh.ru/resumes/", id))hhResumeSearchURL <- 'https://hh.ru/search/resume?exp_period=all_time&order_by=relevance&text=machine+learning&pos=full_text&logic=phrase&clusters=true&page=';
for (pageNum in 0:51) { # Всего 51 страница
#Вытащим id резюме
hDoc <- read_html(paste0(hhResumeSearchURL, as.character(pageNum)))
ids <- html_nodes(hDoc, css = 'a') %>% as.character()
# Выделим все аттрибуты ссылок на странице
ids <- as.vector(ids) %>% `[`(str_detect(ids, fixed('/resume/'))) %>%
str_extract(pattern = '/resume/.{38}') %>% str_sub(str_count('/resume/') + 1)
ids <- ids[4:length(ids)] # В первых 3х мусор
Sys.sleep(1) # Подождем на всякий случай
for (id in ids) {
resumes <- fromJSON(paste0("https://api.hh.ru/resumes/", id))
skills <- if (is.null(resumes$skill_set)) "" else resumes$skill_set
buffer <- data.frame(
Age = if(is.null(resumes$age)) 0 else resumes$age, # Возраст
if (is.null(resumes$area$name)) "NoCity" else resumes$area$name,# Город
if (is.null(resumes$gender$id)) "NoGender" else resumes$gender$id, # Пол
if (is.null(resumes$salary$amount)) 0 else resumes$salary$amount, # Зарплата
if (is.null(resumes$salary$currency)) "NA" else resumes$salary$currency, # Валюта
# Список навыков одной строкой через ,
str_c(if (!length(skills)) "" else skills, collapse = ","))
write.table(buffer, 'resumes.csv', append = T, fileEncoding = "UTF-8",col.names = F)
Sys.sleep(1) # Подождем на всякий случай
}
print(paste("Скачал страниц:", pageNum))
}Также почистим получившийся DataFrame, конвертируя валюты в рубли и удалив NA из столбцов.

Найдем топ — 15 навыков, чаще остальных встречающихся в резюме
SkillNameDF <- data.frame(SkillName = str_split(str_c(
resumes$Skills, collapse = ','), ','), stringsAsFactors = F)
names(SkillNameDF) <- 'SkillName'
mostSkills <- head(SkillNameDF %>% group_by(SkillName) %>%
summarise(Count = n()) %>% arrange(desc(Count)), 15 )
Посмотрим, сколько женщин и мужчин знают machine learning, а так же на какую зарплату претендуют
resumes %>% group_by(Gender) %>% filter(Salary != 0) %>%
summarise(Count = n(), Median = median(Salary), Mean = mean(Salary)
И напоследок, топ — 10 самых популярных возрастов специалистов по машинному обучению
resumes %>% filter(Age!=0) %>% group_by(Age) %>%
summarise(Count = n()) %>% arrange(desc(Count))
Комментарии (13)

lxsmkv
12.09.2017 17:08Получение данных через API не называется «scraping».
Scraping это когда нет интерфейса и приходится данные «выскребать» любыми другими методами. Я бы назвал это скорее «Агрегация данных через hh.ru API с помощью R»
atikhonov
12.09.2017 17:15это в части вакансий — API, в части резюме общедоступного API нет,
поэтому там scraping с сайта hh.lxsmkv
12.09.2017 18:00спасибо за замечание, читал невнимательно :( Оставлю однако свой комментарий, так как в прошлом столкнулся с тем, что понятие web scraping имеет немного размытое определение. И при поиске информации в интернете по технологии/методкике, для человека не знакомого с этой областью, важно использовать правильные ключевые слова.
S_IT_NIK_OFF
12.09.2017 19:13Интересно, спасибо. А еще вопрос как название вакансии на русском сделать?

pdepdepde Автор
12.09.2017 19:15Здравствуйте, пожалуйста.
Названия вакансий загружались в том виде, в каком они лежат на сайте. Часть из них на русском, а часть на английском.
OlegUV
> топ — 10 самых популярных возрастов
будет лучше выглядеть, если весь диапазон возрастов разбить на группы, например с шагом 5 лет, и посчитать количества уже для групп
очень интересно бы было почитать про скрапинг динамических страниц, как в статье про Клинцы (там был довольно универсальный метод), но более подробно
atikhonov
возможно, лучше сразу визуализировать данные на различных диаграммах: рассеяний или плотностей, например, как в этом посте
pdepdepde Автор
Полностью согласен, осталось лишь разобраться с ggplot2)
pdepdepde Автор
К сожалению, не сталкивался с данной статьей.
atikhonov
можно еще так: