
Недостаток зависимостей в веб-приложении приводит к ошибкам в интерфейсе, избыток — снижает производительность. Руководитель отдела разработки интерфейсов Яндекса Азат razetdinov показывает, как библиотека MobX помогает отслеживать минимальный набор изменений и поддерживать консистентность состояния приложений, а также знакомит с инструментом mobx-state-tree, который позволяет совместить всё лучшее из MobX и Redux.
— Меня зовут Азат Разетдинов, я представляю персональные сервисы Яндекса: Почту, Диск, Календарь, Паспорт, управление аккаунтом. Хотел бы рассказать про управление состоянием веб-приложения без боли.
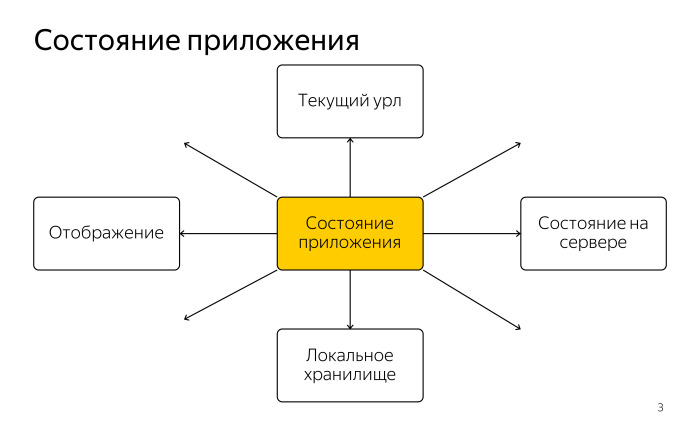
Что такое состояние приложения? Это центральное понятие в архитектуре всего веб-приложения. Там хранится все, от чего зависят остальные компоненты. Например, самое очевидное — отображение, представление состояния приложения в виде дом-дерева, которое вы видите в браузере.
Это самая большая часть, но многие забывают, что есть еще другие части. От состояния приложения также зависит текущий урл в адресной строке. Очень важно, чтобы человек мог скопировать урл на любой странице вашего приложения, отправить другу и там открылось все то же самое. Текущий урл всегда должен соответствовать текущему состоянию и его отражать.
Скорее всего, у вас есть синхронизация состояния приложения на сервер. Важно всегда быть уверенным в том, что все, что у вас меняется на клиенте, так или иначе в итоге попадает на сервер.
Бывают случаи, когда мы хотим какие-то локальные изменения хранить в хранилище, чтобы оттуда потом их доставать. Хранить прямо в браузере. Здесь тоже часто требуется синхронизация состояния приложения с локальным хранилищем. На самом деле частей, которые зависят от состояния приложения, довольно много.
В чем здесь проблема?
Как правило, состояние приложения — дерево, где очень много данных, есть какие-то списки, объекты, хэши, примитивные данные. Большая иерархичная структура.

Проблема не в том, что она иерархичная, а в том, что она живая, она постоянно меняется. Меняется то в одном месте, то в другом. Какую проблему мы хотим решить?
Если вы давно во фронтенде, то, наверное, знакомы с таким паттерном, как ручная подписка на изменения.
Берем текущее состояние, используем его для первоначального отображения компонента, затем подписываемся на изменения и реагируем на них.
Если вспомнить старые фреймворки, это выглядело примерно так в псевдокоде.

Сначала используем текущее состояние, подписываемся на изменения и при каждом изменении выполняем какие-то действия. Либо точечно меняем дом-элементы, как это было модно раньше, либо запускаем заново весь рендер, как это модно сейчас.
У этого подхода две проблемы.
Если вы подписываетесь на изменение любого узла в дереве, то, скорее всего, вы делаете слишком много действий. Скорее всего, ваш текущий компонент не зависит от всего состояния дерева вашего приложения и у вас слишком много лишних операций. Так что в этом месте обычно начинают делать какую-то оптимизацию, пытаются выбрать только те поля состояния приложения, от которых зависит ваш какой-то компонент или какое-то действие.
Но у этого подхода тоже есть проблема.
Поскольку вы это делаете вручную, в проекте, который живет какое-то время, рано или поздно наступает состояние, когда вы где-то что-то забыли, отрефакторили и не добавили зависимость от какого-то поля, которое может повлиять на отображение вашего компонента.
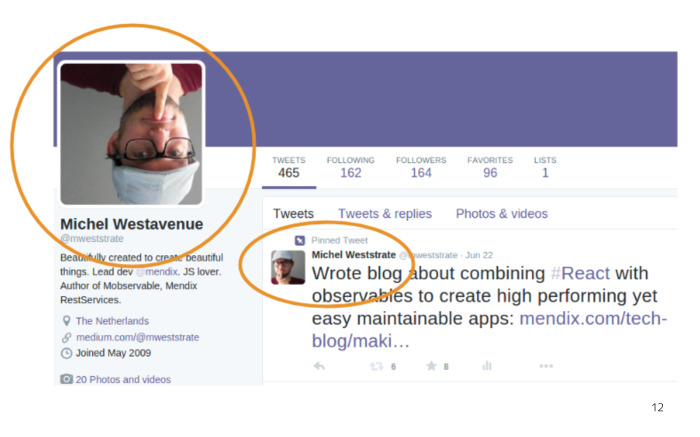
Что здесь произошло? Товарищ обновил свою аватарку, а она обновилась не везде. Оказалось, большая аватарка поменялась, а маленькие аватарки в твитах не подписались на изменения аватарки пользователя и не получили это изменение, не обновили себя. Это самый большой минус, который есть в ручной подписке.
В этом месте к нам на помощь приходит MobX. Он реализует подписку ровно на те поля состояния приложения, которые вы используете.
Чтобы это показать, нужно объяснить, как это устроено изнутри.
Я буду использовать декораторы. Не пугайтесь: все, что написано с помощью декораторов, можно написать с помощью обычных функций оберток. Декораторы здесь только для наглядности и лаконичности.

Давайте объявим такой класс — Person, человек. И объявим три поля, и пометим их декоратором observable. Имя, фамилия и кличка.
Когда мы говорим про MobX, очень полезно проводить аналогию с Excel.
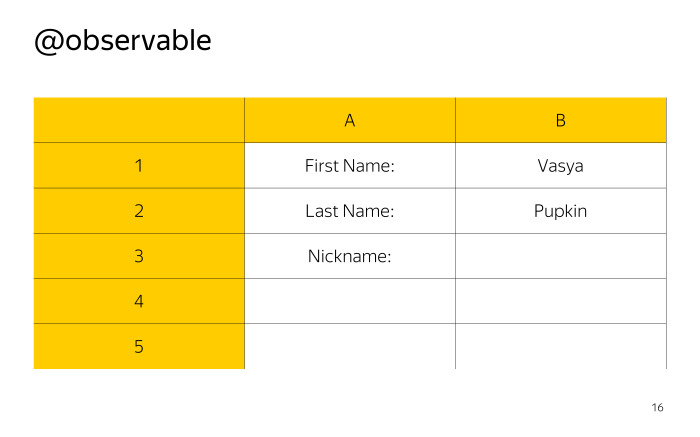
Observable-поля — это просто исходные данные в ячейках.
Они позволяют остальным концепциям следить за изменением себя.
Computed похож на observable тем, что также может уведомлять тех, кто на него подписан, о своем изменении, но при этом не хранит значения внутри себя, а вычисляет их на основе других observable-полей.

В данном случае мы просто конкатинируем имя и фамилию через пробел.
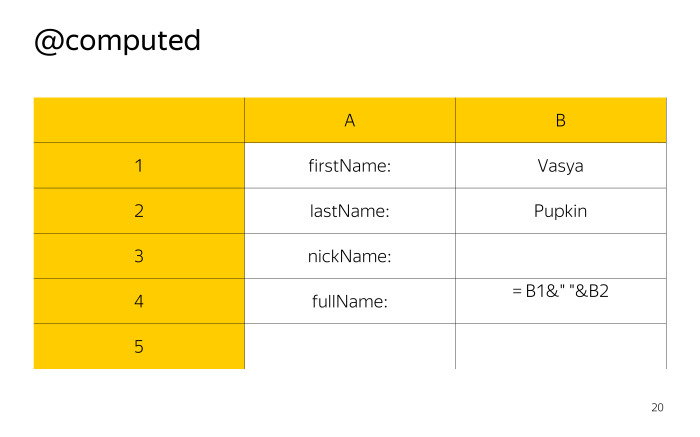
Если проводить аналогию с Excel, это ячейка с формулой. Кажется, пока все просто.
Этот не тот action, который вы, наверное, знаете из Redux, но он очень похож.

В терминах MobX action — просто некая функция. Здесь это метод, но это необязательно. Action не обязан быть методом класса, он может быть в любом месте приложения, главное, чтобы он был помечен декоратором action. Внутри этой функции вы можете изменять observable-поля, которые вы пометили ранее.
Пока все понятно, метод устанавливает nickName.
Теперь начинается магия.
Самая главная концепция MobX — это реакции.
Они похожи на computed, они тоже используют какие-то observable- или computed-поля внутри себя, но они не возвращают никакого значения. Вместо этого они дают побочный эффект.
Самое важное: реакции срабатывают, выполняются или перезапускаются каждый раз, когда меняются исходные данные. При этом не любые, а только те, которые зависят от каждой конкретной реакции.
Самая простая реакция — функция autorun из библиотеки MobX.

Напишем простой autorun, в который передается функция, просто выводящая некое выражение в консоль.

Хорошей аналогии с Excel не получается: реакции не обязаны возвращать какое-то значение, они скорее дают какой-то побочный эффект. Примерно можно сказать, что это еще одна формула в ячейке.
Autorun, как только мы его вызываем, сразу первый раз запускает нашу функцию, которую мы передали в аргументе.
При выполнении этой функции он обращается к observable-полям, в данном случае первым делом к nickName. Здесь срабатывает магия MobX: на самом деле, когда мы объявляли observable, вместо обычного поля был объявлен getter для этого поля.
Когда мы обращаемся, observable-поле nickName у себя ставит инкремент: ага, у меня появился новый слушатель функции, которая завернута в autorun.
Когда у меня что-то изменится, мне нужно этого слушателя уведомить об этом изменении. NickName пустой, поэтому дальше идет обращение к Person fullName. У нас происходит подписка на изменение этого поля. FullName является computed-полем, это getter, который внутри себя обращается к полям firstName и lastName.
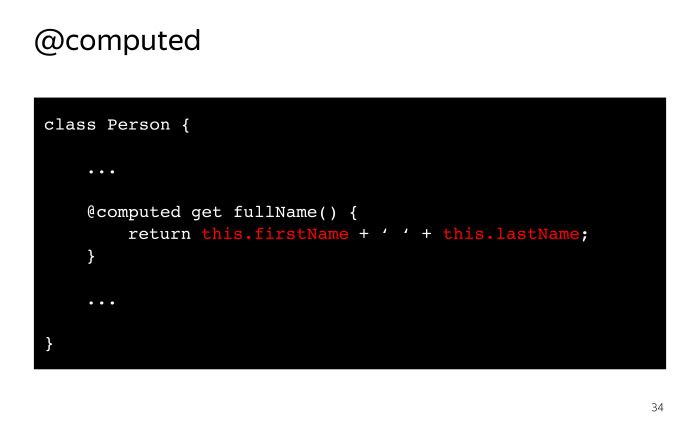
На этом выполнение функции заканчивается, и в этот момент MobX знает, что функция, которую мы передали в autorun, зависит от четырех полей: nickName, fullName, firstName, lastName.
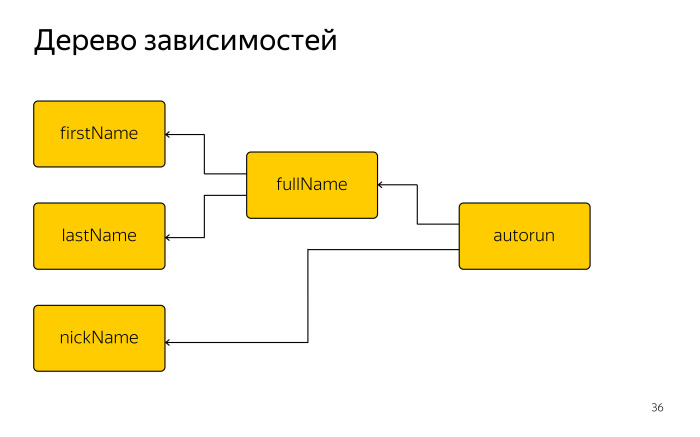
Дерево зависимостей выглядит так. Любое изменение observable-полей в первом столбце запустит заново выполнение autorun.

Допустим, мы решили задать нашему человечку кличку Васек.

Этот метод, который является action, совершает внутри себя операцию присваивания.
Когда вы вызываете эту операцию, срабатывает сеттер, и он внутри проходит по списку подписчиков и уведомляет всех: я изменился, тебе нужно как-то валидировать свое состояние, перевыполниться или переадресоваться.

Autorun получает уведомление, что что-то изменилось, надо заново перезапуститься. Запускает выполнение функции, обращается к полю nickName.
На сей раз оно уже не пустое. На этом выполнение функции прекращается.

Смотрите, как изменился список наблюдаемых полей. Поскольку мы обращались только к полю nickName, он остается в списке наших зависимостей. Все остальные три поля из списка зависимостей тоже вылетают. Если посмотреть на дерево, оно теперь выглядит так.
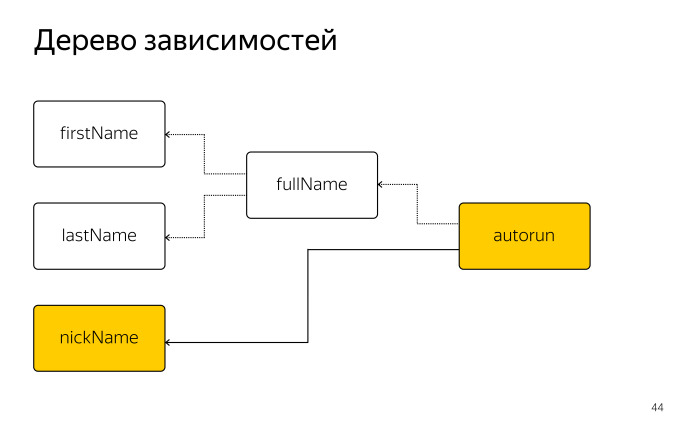
До тех пор, пока не изменится nickName, autorun вообще будет игнорировать любые изменения полей firstName и lastName, потому что код устроен таким образом, что пока nickName не пустой, до поля fullName дело даже не дойдет никогда.
Очень важно понимать, что реакции при каждом выполнении заново собирают список своих зависимостей. Список полей, от которых зависит ваш компонент или ваша побочная реакция, собирается не статически, не в коде вы ее пишете. Массив из полей, которые мне нужно отслеживать — он собирается динамически на основе анализа кода, который исполняется. Минимальный набор подписок может быть получен только тогда, когда они собираются в рантайме.
Autorun — не единственный пример реакции. Есть реакция observer. Это helper для React.
Если наш пример переписать в виде React-компонента, он будет выглядеть примерно так.
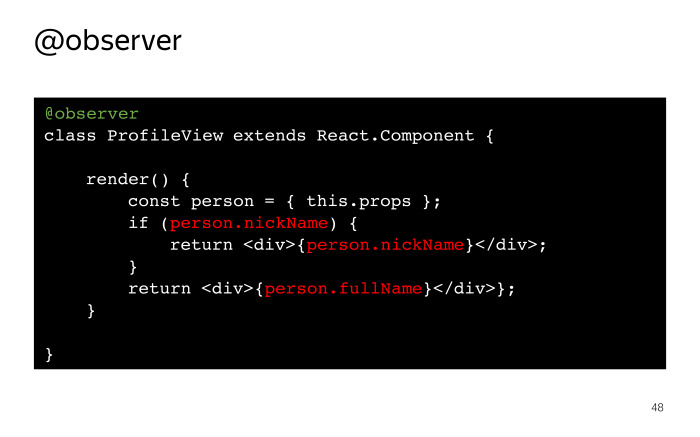
Мы используем декоратор observer. Напомню: можно использовать обычные обертки здесь. Внутри метода render мы обращаемся сначала к nickName. Если он пустой, тогда уже к fullName. Ровно та же логика. Единственное, при использовании observer мы не выполняем функцию autorun, а вместо этого он при любом изменении полей, на которые мы подписаны, запускает переадресовку вашего компонента.
Автоматическая подписка компонентов плюс observer позволяет кардинально минимизировать количество перерисовок React-компонентов.

Есть часто наблюдаемый код, когда имеется какой-то флаг, который мы проверяем в самом начале метода render. Если он не выполняется, мы просто возвращаем null. Здесь очень помогает магия React. До тех пор, пока изменения у нас false, изменения любых полей, которые используются ниже, где написано много кода, observer будет игнорировать. Но как только флаг загорится, во время очередного перерендера он выполнит очередной код и подпишется на изменения полей, которые там используются.
Если React экономит нам операции с домом, то MobX экономит нам операции с виртуальным домом. Чем меньше перерисовок даже в виртуальном доме, тем быстрее наше приложение.
Расскажу об еще одной оптимизации, которая встроена в MobX, — кэшировании computed.

Здесь наш fullName простой, но вообще они бывают и довольно сложные: какие-то фильтры, reduce, сложные вычисления. Возникает вопрос: если каждый раз обращаться к этому геттеру, не будет ли у нас излишнего выполнения всех этих операций, каждый раз мы будем одну и ту же операцию выполнять? Почему нельзя в кэш положить?

До тех пор, пока данные, которые использует computed, не поменялись, computed первый раз выполняет свои вычисления, кладет значение в кэш, и каждый раз, когда к нему кто-то обращается, он отдает его сразу из кэша.
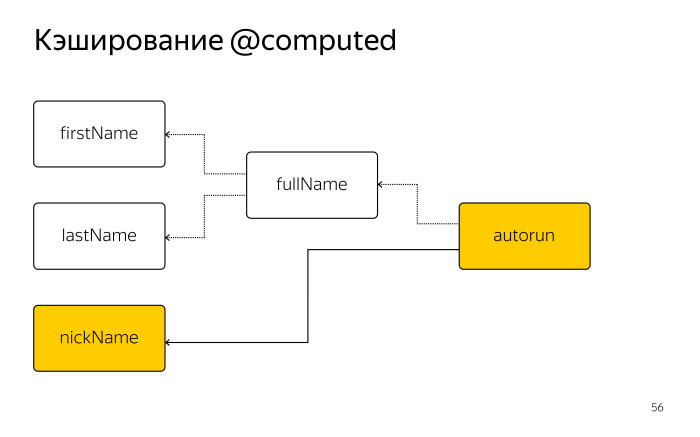
Но если мы задаем поле nickName, и autorun отписывается от fullName, в этот момент fullName понимает, что у него больше не осталось подписчиков, выкидывает кэш, который потом собирается через garbage collector и работает просто как обычный геттер.
Кэширование всегда зависит от наличия подписчиков, которых всегда может быть больше, чем один.
Небольшой пример того, как можно работать с асинхронными данными при таком подходе.
Можно руками запускать метод load, запускать флаг isLoading True или False, но у MobX есть такой хелпер, который называется fromPromise.

Мы объявляем некое поле, заворачиваем асинхронную операцию в хелпер fromPromise, и в этом поле появляется два сабполя — state и value.
В React-компоненте можно сначала проверять, что state pending. Тогда мы показываем какой-то loading. Если fullfilled, тогда обращаемся к полю value и рисуем наш компонент дальше.
Итого, плюсы MobX.

Уже слышу вопрос из зала. Я этого человечка называю Reduxman, это человек, который написал много кода на Redux. Какой вопрос он задает?

А как же netability? Это что же, у вас можно методами прямо полями модели менять? Ну ни фига себе.
А как же time travel? Мне же нужны не модели с методами, а простые plain JavaScript-объекты, чтобы можно было с их помощью делать undo, redo и прочие вкусные штуки.
Как же мой любимый devtools, к которому я уже привык, чтобы можно было делать реплей действий, которые производил пользователь?
Расскажу немного про Redux. Основные изменения, которые он произвел в головах разработчиков.

Он отошел от ООП в сторону функционального программирования. Вместо моделей стали использоваться immutable-структуры. Вместо методов теперь есть экшены и редьюсеры. Вместо нормальных связей, ссылок между моделями теперь есть нормализация и селекторы.
И это очень круто, я тоже нежно люблю Redux, но меня смущает один момент: очень много бойлерплейта, очень много всего приходится писать руками. Когда мне нужно добавить какое-то действие, у меня есть экшен, редьюсер, часто еще нужен селектор. И возникает ощущение, что я обезьянью работу выполняю.
Когда я начал думать, чем Redux отличается от MobX, у меня возникла такая аналогия.

Все любили этот мультик? А чем отличаются мультики, которые смотрит молодое поколение? Они вот такие.

Знаете, в чем разница? «Том и Джерри» рисовали таким образом, брали кадры и каждый рисовали по отдельности.
Ничего не напоминает? Immutable store в Redux-приложении. Каждый раз есть какой-то отпечаток, который мы руками конструируем, используем для этого библиотеку immutable или Object.assign или spread operator. Каждый раз мы дорисовываем руками состояние приложения на текущий момент. Если нужно откатиться, мы берем и обратно откатываем. Это все круто, только очень много кода получается. Я не люблю писать код, я люблю его удалять. Код — это зло. Самый быстрый код — это тот, который не выполняется.
А новые мультики рисуют вот так.

Рисуют трехмерную модель, программно ее поворачивают, берут кадр, поворачивают в другую сторону, берут кадр. Управляют живой моделью, и потом просто берут ее проекцию на экран.
То, что мы руками пытаемся работать с immutable-данными, — это необязательно. Immutable-состояние нашего приложения — это еще один вид, еще одно представление, еще одно отображение. Можно использовать живую модель, просто каждый раз в любой момент времени получить его плоскую проекцию.
Давайте покажу, как это сделать. Авторы MobX написали такую отдельную штуку. Это уже более opinionated-подход, который диктует вам, как писать приложение, но взамен дает много плюшек.
Давайте напишем небольшой store, объявим класс Todo, для этого используется хелпер types, у которого есть метод model. Пока он пустой.

Добавим title.
Здесь мы объявляем, что это строка.
Добавим опциональное булево поле isCompleted. Кстати, здесь есть возможность написать это короче. Если вы присваиваете какой-то примитив, то mobx-state-tree понимает, что это опциональное примитивное поле с дефолтным значением.

Добавим reference. Это означает, что в folder будет лежать id какого-то другого объекта, но при создании модели mobx-state-tree по этому id достанет этот объект из некоего store и поставит его в этом поле. Пример я покажу чуть позже.


Чтобы вся магия работала, нам нужно объявить класс Folder, у которого обязан быть id с типом types.identifier. Это как раз для того, чтобы связывать ссылки с объектами store по идентификатору.

Объявим главный рутовый TodoStore, в котором будет два массива: todos и folders. Здесь можно видеть, как используется types.array, передаем в качестве аргумента класс, и MobX понимает, что это массив instance этого класса.
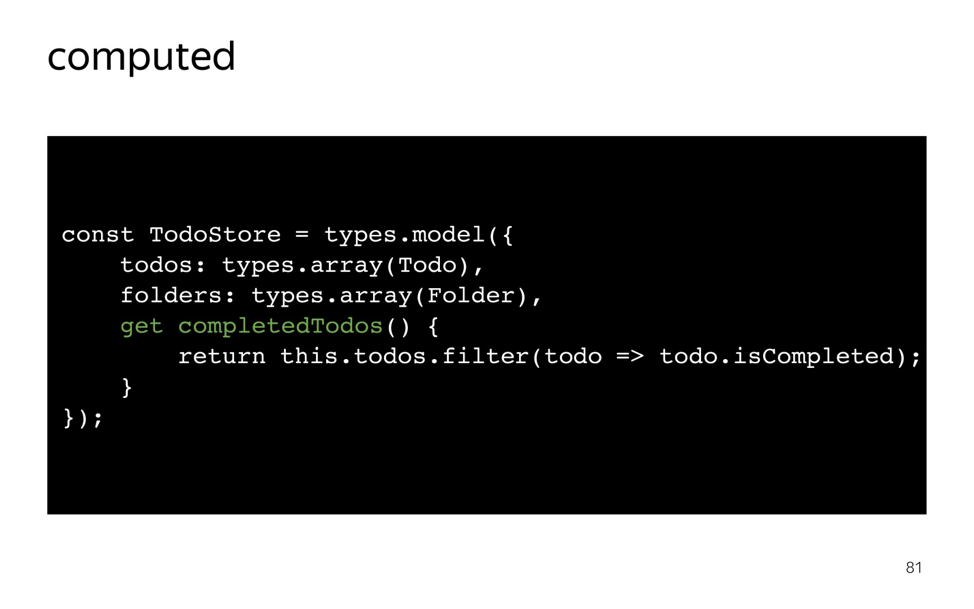
Если мы объявляем геттер, он автоматически становится computed из терминологии MobX, как мы смотрели раньше. Здесь у меня есть геттер completedTodos, который просто возвращает список всех выполненных todo. Он кэшируется, и пока есть хоть один подписчик, он всегда возвращает закэшированное значение. Не бойтесь так писать, писать сложные выражения, все это будет закэшировано.
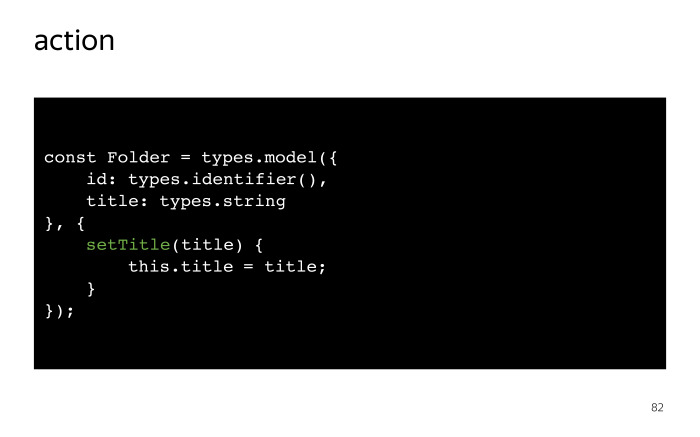
Вот так создаются экшены. Первый объект в декларации — свойства и computed, во втором объекте перечислены экшены. Здесь и не надо их уже объявлять, mobx-state-tree по умолчанию считает, что все, что вы передаете вторым объектом, — экшены.

Давайте попробуем создать store. У нас есть данные, допустим, они пришли с сервера, видите, они в нормализованном виде, у нас в folder лежит 1, а в списке folders есть объект с идентификатором 1.

Создаем, используем.
Первая строчка — все нормально, я использую поле title объекта todo.
Во второй строчке уже магия: поскольку folder объявлен как reference, то MobX при создании модели автоматически, в первую очередь, положил folder в массив folders, а в моделях todo по ссылке, по идентификатору, добавил ссылку на этот объект. То, где в Redux мы бы писали селектор, здесь работает из коробки. Можно спокойно обращаться ко вложенным полям ваших ссылок, ваших референсов. И это работает, это очень удобно писать в компонентах без всяких селекторов и прочих map state to props.
Мы собрали какую-то 3D-модель. Давайте попробуем запустить ее. Камера, мотор.
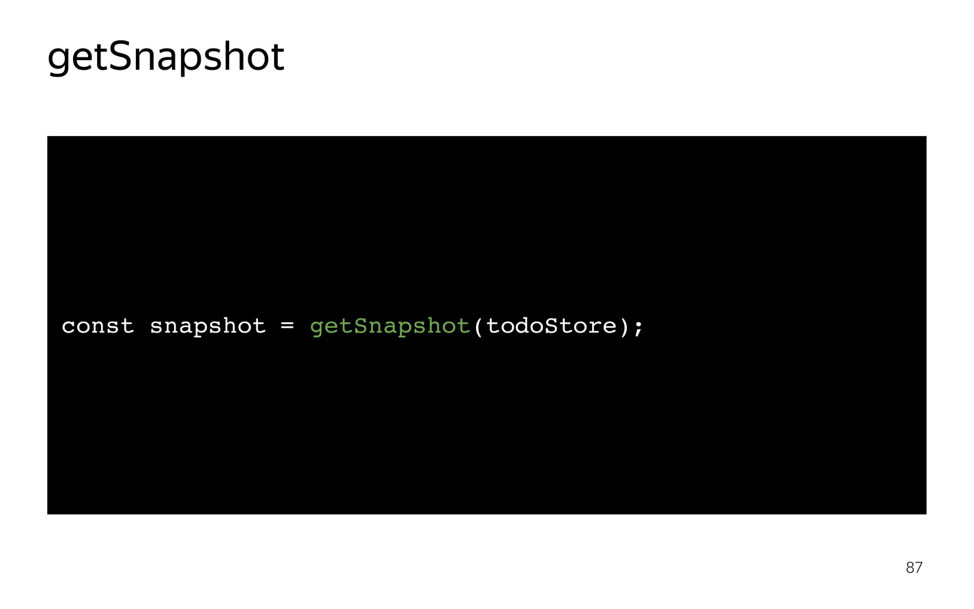
Для начала попробуем получить обратно данные, которые мы в модель положили. Для этого есть хелпер getSnapshot. Передаем туда модель, получаем snapshot в виде обычного JS-объекта, как все редаксмены любят. Получил и получил, но у меня же модель постоянно меняется, как мне подписаться на изменения?

Очень просто: есть хелпер onSnapshot, который позволяет подписаться на изменение любого поля в модели, при этом в качестве параметра он всегда передает новый snapshot, который он генерирует, но не просто так, иначе было бы глупо каждый раз новый объект генерировать. Он так же, как React, использует immutable.
Если какие-то части менялись, он их реиспользует, запускает механизм structural sharing.
Для изменившихся создает новые объекты.

Как сделать time travel? Мы гуляем по истории и хотим какой-то snapshot применить к модели. Есть хелпер applySnapshot, передать модель, передать и snapshot. Он сравнивает то, что вы передали, и то, что сейчас в модели, берет диф и обновляет только те части, которые изменились.
При этом он реиспользует модели, если у них совпадают идентификаторы. Если в модели лежит какой-то folders с id = 1, в snapshot тоже передается folders с id = 1. Он не пытается его перезатереть, а просто обновляет данные самого folder, если они изменились.
Инстанция внутри модели не перезатирается, если вы правильно задали идентификаторы.
Пожалуй, самая яркая иллюстрация того, как работают живые модели и snapshots.
Есть живая модель, и мы в любой момент времени можем снять с нее snapshot.
Наконец, бонус, специально для редаксменов. Есть для адаптера для работы с Redux. Если у вас уже есть большое приложение, написанное в Redux style, то вы можете переписать только store и из mobx-state-tree store получить reduxStore просто методом asReduxStore.

Если вы привыкли работать с ReduxDevtools, можно просто использовать хелпер connectReduxDevtools, передать туда модель, store в виде mobx-state-tree, и все будет работать.

Старые добрые ООП-модели вместо immutable-структур. Вообще-то, когда мы от них отказывались, кажется, мы выкинули ребенка вместе с водой. Они вообще-то были удобные, когда у вас есть данные и методы для работы с ними.
Живые ссылки вместо селекторов. Вы можете вкладывать модели друг в друга сколько угодно, делать референсы и работать просто через точку. Todo.folder.parent и так далее, как хотите. При этом, когда вы будете сериализовывать, все будет автоматически обратно сериализовываться в нормализованный вид.
Дешевое получение снэпшотов всего дерева с реиспользованием частей, которые не изменились. Применение снэпшотов с реконсайлингом, прямо как в React. Если объекты совпадают по идентификаторам, они будут реиспользованы. И — адаптеры для Redux Store и Redux Devtools.

Как сказал Дэниел Эрвикер, MobX — это как React, только для данных. Здесь есть несколько ссылок, которые вы можете потом посмотреть:
На этом спасибо.
То, что мы руками пытаемся работать с immutable-данными, — это необязательно. Immutable-состояние нашего приложения — это еще один вид, еще одно представление, еще одно отображение. Можно использовать живую модель, просто каждый раз в любой момент времени получить его плоскую проекцию.
— Меня зовут Азат Разетдинов, я представляю персональные сервисы Яндекса: Почту, Диск, Календарь, Паспорт, управление аккаунтом. Хотел бы рассказать про управление состоянием веб-приложения без боли.
Что такое состояние приложения? Это центральное понятие в архитектуре всего веб-приложения. Там хранится все, от чего зависят остальные компоненты. Например, самое очевидное — отображение, представление состояния приложения в виде дом-дерева, которое вы видите в браузере.
Это самая большая часть, но многие забывают, что есть еще другие части. От состояния приложения также зависит текущий урл в адресной строке. Очень важно, чтобы человек мог скопировать урл на любой странице вашего приложения, отправить другу и там открылось все то же самое. Текущий урл всегда должен соответствовать текущему состоянию и его отражать.
Скорее всего, у вас есть синхронизация состояния приложения на сервер. Важно всегда быть уверенным в том, что все, что у вас меняется на клиенте, так или иначе в итоге попадает на сервер.
Бывают случаи, когда мы хотим какие-то локальные изменения хранить в хранилище, чтобы оттуда потом их доставать. Хранить прямо в браузере. Здесь тоже часто требуется синхронизация состояния приложения с локальным хранилищем. На самом деле частей, которые зависят от состояния приложения, довольно много.
В чем здесь проблема?
Как правило, состояние приложения — дерево, где очень много данных, есть какие-то списки, объекты, хэши, примитивные данные. Большая иерархичная структура.
Проблема не в том, что она иерархичная, а в том, что она живая, она постоянно меняется. Меняется то в одном месте, то в другом. Какую проблему мы хотим решить?
Если вы давно во фронтенде, то, наверное, знакомы с таким паттерном, как ручная подписка на изменения.
Берем текущее состояние, используем его для первоначального отображения компонента, затем подписываемся на изменения и реагируем на них.
Если вспомнить старые фреймворки, это выглядело примерно так в псевдокоде.
Сначала используем текущее состояние, подписываемся на изменения и при каждом изменении выполняем какие-то действия. Либо точечно меняем дом-элементы, как это было модно раньше, либо запускаем заново весь рендер, как это модно сейчас.
У этого подхода две проблемы.
Если вы подписываетесь на изменение любого узла в дереве, то, скорее всего, вы делаете слишком много действий. Скорее всего, ваш текущий компонент не зависит от всего состояния дерева вашего приложения и у вас слишком много лишних операций. Так что в этом месте обычно начинают делать какую-то оптимизацию, пытаются выбрать только те поля состояния приложения, от которых зависит ваш какой-то компонент или какое-то действие.
Но у этого подхода тоже есть проблема.
Поскольку вы это делаете вручную, в проекте, который живет какое-то время, рано или поздно наступает состояние, когда вы где-то что-то забыли, отрефакторили и не добавили зависимость от какого-то поля, которое может повлиять на отображение вашего компонента.
Что здесь произошло? Товарищ обновил свою аватарку, а она обновилась не везде. Оказалось, большая аватарка поменялась, а маленькие аватарки в твитах не подписались на изменения аватарки пользователя и не получили это изменение, не обновили себя. Это самый большой минус, который есть в ручной подписке.
В этом месте к нам на помощь приходит MobX. Он реализует подписку ровно на те поля состояния приложения, которые вы используете.
Чтобы это показать, нужно объяснить, как это устроено изнутри.
Я буду использовать декораторы. Не пугайтесь: все, что написано с помощью декораторов, можно написать с помощью обычных функций оберток. Декораторы здесь только для наглядности и лаконичности.
Давайте объявим такой класс — Person, человек. И объявим три поля, и пометим их декоратором observable. Имя, фамилия и кличка.
Когда мы говорим про MobX, очень полезно проводить аналогию с Excel.
Observable-поля — это просто исходные данные в ячейках.
Они позволяют остальным концепциям следить за изменением себя.
Computed похож на observable тем, что также может уведомлять тех, кто на него подписан, о своем изменении, но при этом не хранит значения внутри себя, а вычисляет их на основе других observable-полей.
В данном случае мы просто конкатинируем имя и фамилию через пробел.
Если проводить аналогию с Excel, это ячейка с формулой. Кажется, пока все просто.
Этот не тот action, который вы, наверное, знаете из Redux, но он очень похож.
В терминах MobX action — просто некая функция. Здесь это метод, но это необязательно. Action не обязан быть методом класса, он может быть в любом месте приложения, главное, чтобы он был помечен декоратором action. Внутри этой функции вы можете изменять observable-поля, которые вы пометили ранее.
Пока все понятно, метод устанавливает nickName.
Теперь начинается магия.
Самая главная концепция MobX — это реакции.
Они похожи на computed, они тоже используют какие-то observable- или computed-поля внутри себя, но они не возвращают никакого значения. Вместо этого они дают побочный эффект.
Самое важное: реакции срабатывают, выполняются или перезапускаются каждый раз, когда меняются исходные данные. При этом не любые, а только те, которые зависят от каждой конкретной реакции.
Самая простая реакция — функция autorun из библиотеки MobX.
Напишем простой autorun, в который передается функция, просто выводящая некое выражение в консоль.
Хорошей аналогии с Excel не получается: реакции не обязаны возвращать какое-то значение, они скорее дают какой-то побочный эффект. Примерно можно сказать, что это еще одна формула в ячейке.
Autorun, как только мы его вызываем, сразу первый раз запускает нашу функцию, которую мы передали в аргументе.
При выполнении этой функции он обращается к observable-полям, в данном случае первым делом к nickName. Здесь срабатывает магия MobX: на самом деле, когда мы объявляли observable, вместо обычного поля был объявлен getter для этого поля.
Когда мы обращаемся, observable-поле nickName у себя ставит инкремент: ага, у меня появился новый слушатель функции, которая завернута в autorun.
Когда у меня что-то изменится, мне нужно этого слушателя уведомить об этом изменении. NickName пустой, поэтому дальше идет обращение к Person fullName. У нас происходит подписка на изменение этого поля. FullName является computed-полем, это getter, который внутри себя обращается к полям firstName и lastName.
На этом выполнение функции заканчивается, и в этот момент MobX знает, что функция, которую мы передали в autorun, зависит от четырех полей: nickName, fullName, firstName, lastName.
Дерево зависимостей выглядит так. Любое изменение observable-полей в первом столбце запустит заново выполнение autorun.
Допустим, мы решили задать нашему человечку кличку Васек.
Этот метод, который является action, совершает внутри себя операцию присваивания.
Когда вы вызываете эту операцию, срабатывает сеттер, и он внутри проходит по списку подписчиков и уведомляет всех: я изменился, тебе нужно как-то валидировать свое состояние, перевыполниться или переадресоваться.
Autorun получает уведомление, что что-то изменилось, надо заново перезапуститься. Запускает выполнение функции, обращается к полю nickName.
На сей раз оно уже не пустое. На этом выполнение функции прекращается.
Смотрите, как изменился список наблюдаемых полей. Поскольку мы обращались только к полю nickName, он остается в списке наших зависимостей. Все остальные три поля из списка зависимостей тоже вылетают. Если посмотреть на дерево, оно теперь выглядит так.
До тех пор, пока не изменится nickName, autorun вообще будет игнорировать любые изменения полей firstName и lastName, потому что код устроен таким образом, что пока nickName не пустой, до поля fullName дело даже не дойдет никогда.
Очень важно понимать, что реакции при каждом выполнении заново собирают список своих зависимостей. Список полей, от которых зависит ваш компонент или ваша побочная реакция, собирается не статически, не в коде вы ее пишете. Массив из полей, которые мне нужно отслеживать — он собирается динамически на основе анализа кода, который исполняется. Минимальный набор подписок может быть получен только тогда, когда они собираются в рантайме.
Autorun — не единственный пример реакции. Есть реакция observer. Это helper для React.
Если наш пример переписать в виде React-компонента, он будет выглядеть примерно так.
Мы используем декоратор observer. Напомню: можно использовать обычные обертки здесь. Внутри метода render мы обращаемся сначала к nickName. Если он пустой, тогда уже к fullName. Ровно та же логика. Единственное, при использовании observer мы не выполняем функцию autorun, а вместо этого он при любом изменении полей, на которые мы подписаны, запускает переадресовку вашего компонента.
Автоматическая подписка компонентов плюс observer позволяет кардинально минимизировать количество перерисовок React-компонентов.
Есть часто наблюдаемый код, когда имеется какой-то флаг, который мы проверяем в самом начале метода render. Если он не выполняется, мы просто возвращаем null. Здесь очень помогает магия React. До тех пор, пока изменения у нас false, изменения любых полей, которые используются ниже, где написано много кода, observer будет игнорировать. Но как только флаг загорится, во время очередного перерендера он выполнит очередной код и подпишется на изменения полей, которые там используются.
Если React экономит нам операции с домом, то MobX экономит нам операции с виртуальным домом. Чем меньше перерисовок даже в виртуальном доме, тем быстрее наше приложение.
Расскажу об еще одной оптимизации, которая встроена в MobX, — кэшировании computed.
Здесь наш fullName простой, но вообще они бывают и довольно сложные: какие-то фильтры, reduce, сложные вычисления. Возникает вопрос: если каждый раз обращаться к этому геттеру, не будет ли у нас излишнего выполнения всех этих операций, каждый раз мы будем одну и ту же операцию выполнять? Почему нельзя в кэш положить?
До тех пор, пока данные, которые использует computed, не поменялись, computed первый раз выполняет свои вычисления, кладет значение в кэш, и каждый раз, когда к нему кто-то обращается, он отдает его сразу из кэша.
Но если мы задаем поле nickName, и autorun отписывается от fullName, в этот момент fullName понимает, что у него больше не осталось подписчиков, выкидывает кэш, который потом собирается через garbage collector и работает просто как обычный геттер.
Кэширование всегда зависит от наличия подписчиков, которых всегда может быть больше, чем один.
Небольшой пример того, как можно работать с асинхронными данными при таком подходе.
Можно руками запускать метод load, запускать флаг isLoading True или False, но у MobX есть такой хелпер, который называется fromPromise.
Мы объявляем некое поле, заворачиваем асинхронную операцию в хелпер fromPromise, и в этом поле появляется два сабполя — state и value.
В React-компоненте можно сначала проверять, что state pending. Тогда мы показываем какой-то loading. Если fullfilled, тогда обращаемся к полю value и рисуем наш компонент дальше.
Итого, плюсы MobX.
Уже слышу вопрос из зала. Я этого человечка называю Reduxman, это человек, который написал много кода на Redux. Какой вопрос он задает?
А как же netability? Это что же, у вас можно методами прямо полями модели менять? Ну ни фига себе.
А как же time travel? Мне же нужны не модели с методами, а простые plain JavaScript-объекты, чтобы можно было с их помощью делать undo, redo и прочие вкусные штуки.
Как же мой любимый devtools, к которому я уже привык, чтобы можно было делать реплей действий, которые производил пользователь?
Расскажу немного про Redux. Основные изменения, которые он произвел в головах разработчиков.
Он отошел от ООП в сторону функционального программирования. Вместо моделей стали использоваться immutable-структуры. Вместо методов теперь есть экшены и редьюсеры. Вместо нормальных связей, ссылок между моделями теперь есть нормализация и селекторы.
И это очень круто, я тоже нежно люблю Redux, но меня смущает один момент: очень много бойлерплейта, очень много всего приходится писать руками. Когда мне нужно добавить какое-то действие, у меня есть экшен, редьюсер, часто еще нужен селектор. И возникает ощущение, что я обезьянью работу выполняю.
Когда я начал думать, чем Redux отличается от MobX, у меня возникла такая аналогия.
Все любили этот мультик? А чем отличаются мультики, которые смотрит молодое поколение? Они вот такие.
Знаете, в чем разница? «Том и Джерри» рисовали таким образом, брали кадры и каждый рисовали по отдельности.
Ничего не напоминает? Immutable store в Redux-приложении. Каждый раз есть какой-то отпечаток, который мы руками конструируем, используем для этого библиотеку immutable или Object.assign или spread operator. Каждый раз мы дорисовываем руками состояние приложения на текущий момент. Если нужно откатиться, мы берем и обратно откатываем. Это все круто, только очень много кода получается. Я не люблю писать код, я люблю его удалять. Код — это зло. Самый быстрый код — это тот, который не выполняется.
А новые мультики рисуют вот так.
Рисуют трехмерную модель, программно ее поворачивают, берут кадр, поворачивают в другую сторону, берут кадр. Управляют живой моделью, и потом просто берут ее проекцию на экран.
То, что мы руками пытаемся работать с immutable-данными, — это необязательно. Immutable-состояние нашего приложения — это еще один вид, еще одно представление, еще одно отображение. Можно использовать живую модель, просто каждый раз в любой момент времени получить его плоскую проекцию.
Давайте покажу, как это сделать. Авторы MobX написали такую отдельную штуку. Это уже более opinionated-подход, который диктует вам, как писать приложение, но взамен дает много плюшек.
Давайте напишем небольшой store, объявим класс Todo, для этого используется хелпер types, у которого есть метод model. Пока он пустой.
Добавим title.
Здесь мы объявляем, что это строка.
Добавим опциональное булево поле isCompleted. Кстати, здесь есть возможность написать это короче. Если вы присваиваете какой-то примитив, то mobx-state-tree понимает, что это опциональное примитивное поле с дефолтным значением.
Добавим reference. Это означает, что в folder будет лежать id какого-то другого объекта, но при создании модели mobx-state-tree по этому id достанет этот объект из некоего store и поставит его в этом поле. Пример я покажу чуть позже.
Чтобы вся магия работала, нам нужно объявить класс Folder, у которого обязан быть id с типом types.identifier. Это как раз для того, чтобы связывать ссылки с объектами store по идентификатору.
Объявим главный рутовый TodoStore, в котором будет два массива: todos и folders. Здесь можно видеть, как используется types.array, передаем в качестве аргумента класс, и MobX понимает, что это массив instance этого класса.
Если мы объявляем геттер, он автоматически становится computed из терминологии MobX, как мы смотрели раньше. Здесь у меня есть геттер completedTodos, который просто возвращает список всех выполненных todo. Он кэшируется, и пока есть хоть один подписчик, он всегда возвращает закэшированное значение. Не бойтесь так писать, писать сложные выражения, все это будет закэшировано.
Вот так создаются экшены. Первый объект в декларации — свойства и computed, во втором объекте перечислены экшены. Здесь и не надо их уже объявлять, mobx-state-tree по умолчанию считает, что все, что вы передаете вторым объектом, — экшены.
Давайте попробуем создать store. У нас есть данные, допустим, они пришли с сервера, видите, они в нормализованном виде, у нас в folder лежит 1, а в списке folders есть объект с идентификатором 1.
Создаем, используем.
Первая строчка — все нормально, я использую поле title объекта todo.
Во второй строчке уже магия: поскольку folder объявлен как reference, то MobX при создании модели автоматически, в первую очередь, положил folder в массив folders, а в моделях todo по ссылке, по идентификатору, добавил ссылку на этот объект. То, где в Redux мы бы писали селектор, здесь работает из коробки. Можно спокойно обращаться ко вложенным полям ваших ссылок, ваших референсов. И это работает, это очень удобно писать в компонентах без всяких селекторов и прочих map state to props.
Мы собрали какую-то 3D-модель. Давайте попробуем запустить ее. Камера, мотор.
Для начала попробуем получить обратно данные, которые мы в модель положили. Для этого есть хелпер getSnapshot. Передаем туда модель, получаем snapshot в виде обычного JS-объекта, как все редаксмены любят. Получил и получил, но у меня же модель постоянно меняется, как мне подписаться на изменения?
Очень просто: есть хелпер onSnapshot, который позволяет подписаться на изменение любого поля в модели, при этом в качестве параметра он всегда передает новый snapshot, который он генерирует, но не просто так, иначе было бы глупо каждый раз новый объект генерировать. Он так же, как React, использует immutable.
Если какие-то части менялись, он их реиспользует, запускает механизм structural sharing.
Для изменившихся создает новые объекты.
Как сделать time travel? Мы гуляем по истории и хотим какой-то snapshot применить к модели. Есть хелпер applySnapshot, передать модель, передать и snapshot. Он сравнивает то, что вы передали, и то, что сейчас в модели, берет диф и обновляет только те части, которые изменились.
При этом он реиспользует модели, если у них совпадают идентификаторы. Если в модели лежит какой-то folders с id = 1, в snapshot тоже передается folders с id = 1. Он не пытается его перезатереть, а просто обновляет данные самого folder, если они изменились.
Инстанция внутри модели не перезатирается, если вы правильно задали идентификаторы.
Пожалуй, самая яркая иллюстрация того, как работают живые модели и snapshots.
Есть живая модель, и мы в любой момент времени можем снять с нее snapshot.
Наконец, бонус, специально для редаксменов. Есть для адаптера для работы с Redux. Если у вас уже есть большое приложение, написанное в Redux style, то вы можете переписать только store и из mobx-state-tree store получить reduxStore просто методом asReduxStore.
Если вы привыкли работать с ReduxDevtools, можно просто использовать хелпер connectReduxDevtools, передать туда модель, store в виде mobx-state-tree, и все будет работать.
Старые добрые ООП-модели вместо immutable-структур. Вообще-то, когда мы от них отказывались, кажется, мы выкинули ребенка вместе с водой. Они вообще-то были удобные, когда у вас есть данные и методы для работы с ними.
Живые ссылки вместо селекторов. Вы можете вкладывать модели друг в друга сколько угодно, делать референсы и работать просто через точку. Todo.folder.parent и так далее, как хотите. При этом, когда вы будете сериализовывать, все будет автоматически обратно сериализовываться в нормализованный вид.
Дешевое получение снэпшотов всего дерева с реиспользованием частей, которые не изменились. Применение снэпшотов с реконсайлингом, прямо как в React. Если объекты совпадают по идентификаторам, они будут реиспользованы. И — адаптеры для Redux Store и Redux Devtools.
Как сказал Дэниел Эрвикер, MobX — это как React, только для данных. Здесь есть несколько ссылок, которые вы можете потом посмотреть:
- MobX
- mobx-state-tree
- Becoming fully reactive: an in-depth explanation of MobX
- MobX vs. Redux Performance
- An artificial example where MobX really shines and Redux is not really suited for it
На этом спасибо.
vintage
Остаётся только один вопрос: если у вас есть информация о непосредственных зависимостях любого состояния, а значит вы точно знаете каке узлы в дереве нуждаются в перерисовке, то на кой чёрт вам сдался этот реакт с его перегенерацией виртуального дерева с последующей реконциляцией и поиском узлов, которые нуждаются в перерисовке?
VolCh
Я, как разработчик бизнес-логики и логики приложения, понятия не имею ни о каком дереве перерисовок. А разработчик презентационного компонента понятия не имеет ни о зависимостях состояния, ни о его изменениях.
vintage
Для всего этого виртуальный дом не нужен.
vasIvas
Может я не понял о чем Вы, но к примеру взять массив сданными. по которым строится список.
В первый проход я построил список, а при следующих изменениях данных что? Если я каждый раз буду список создавать заново на уровне дом-дерева, то это не производительно. Получается что мне нужно написать свои функции, которые будут способны рендерить только изменения. Но я больше чем уверен, что разнообразность задач, поставит перед фактами, что одним только этим не обойтись. И в итоге так и придется писать свой аналог реакта или чего-то подобного. Поэтому проще взять готовое и к тому же будет проще найти специалистов, которые точно в Вашем самописе не разбираются.
VolCh
Тут скорее речь о том, что на границе MobX и React теряется информация о зависимостях, которую рендерер мог бы использовать для точечного ререндинга прямо в DOM без построения нового, пускай и виртуального.
vasIvas
Не понимаю, как это? Вы имеете ввиду, что если mobx использовать без реакта, с обычными дом-элементами, то появляется возможность передать данные из стора в дом-элемент так, чтобы при обновлении стора точечно обновлялись дом-элементы? Разве такое возможно?
vintage
Да, вы всё правильно поняли. Это не просто возможно, но и гораздо эффективней. Изменилось что-то в сторе — перезапустилась функция обновления соответствующего участка дома.
KasperGreen
Да, но если вас этих участков DOM изменилась тыща, то потребуется тыща обращений к DOM, а это — медленно.
React в этом случае всю тыщу изменений произведёт в виртуальном DOM, а в реальный сделает одну единственную вставку, что быстрее, т.к. в настоящий DOM будет всего одно обращение.
vintage
Да нет, Реакт сделает ровно столько же обращений к ДОМ, только ему для того, чтобы понять какие именно обращения к ДОМ необходимы — придётся делать сравнение виртуальных домов. Ну собственно, ваш пример с обновлением в 1000 местах — Ангуляр с точечными обновлениями уделывает Реакт в 2 раза.
KasperGreen
Поможет ли здесь использование PureComponent?
vintage
Не поможет, ибо данные обновляются полностью.
KasperGreen
Ок. Если данные обновляются полностью, то ReactJS перерендерит всё, от App и ниже в своём виртуальном DOM, а результат вставит на место #ROOT_APP сделав всего одно обращение к реальному DOM. Разве не так?
vintage
Не так, это было бы слишком медленно. Он пробежится по всем дом-узлам и проверит, чтобы их состояние соответствовало виртуальным дом-узлам.
KasperGreen
Вы точно разбираетесь в ReactJS?
dizel3d
vintage прав. Если бы это было не так, вы бы наблюдали побочные эффекты, такие как: потеря фокуса, положения курсора ввода, сброс выделения контента, положения прокрутки внутри элементов и т.п.
dizel3d
KasperGreen, прошу прощения, проглядел. vintage не прав — по настоящим DOM-узлам Реакт, конечно, бегать не будет.
Но и вы не правы — перерисовывать все Реакт тоже не будет, иначе это приведет к побочным эффектам, о которых я писал.
Реакт просто сравнит старое и новое виртуальное дерево и применит изменения к DOM-дереву.
vintage
Не точно выразился, да. По настоящим узлам он в итоге пробежится и обновит ибо все данные меняются.
dizel3d
В общем, из того, что все данные изменились не следует, что изменилось все виртуальное дерево.
vintage
А вы сомневаетесь?
KasperGreen
Теперь во всём. Похоже я живу в мире иллюзий, но и в этом я не уверен. Как собственно и в том, что vintage не потомок Сима.
vintage
Ну, можете почитать, например, тут как работает виртуальный дом.
Druu
Там с картинкой некая проблема в том, что все интересное — по сути содержится в блоке «is same as real dom node from previous render», а остальное — несущественные мелочи.
Druu
А каким образом так вышло, что mol-jsx работает вдвое быстрее, чем mol, и требует меньше памяти? Я думал, что mol-jsx — что-то вроде обертки над чистым mol, логично, что он должен работать медленнее?
mayorovp
Меня другое интересует. Как $mol умудряется в принципе обогнать Native DOM?
vintage
Очевидно за счёт ленивого рендеринга, который позволяет не только не рендерить то, что не изменилось, но и не рендерить то, что не видно.
Druu
То есть вариант на мол не быстрый, а просто ничего не делает. В чем тогда смысл такого сравнения? Что с чем сравнивается?
К слову, клик по блоку в мол тормозит сильнее всего. Ангуляр работает практически с той же скоростью, что и нейтив, реакт — посередине.
vintage
Он далеко не "самый быстрый". Всё же ленивость и реактивность — не бесплатны. Но приложения на нём получаются самые отзывчивые. Именно потому, что он не делает то, что можно не делать. Но это синтетический бенчмарк. Вот более реалистичный.
Сомнительно. Может вы плавную анимацию фона посчитали за тормоза?
Druu
> Он далеко не «самый быстрый».
Да он вообще не быстрый.
Смотрите, этот тест направлен на то, чтобы оценить скорость рендеринга элементов фреймворком. Это предполагает, что элементы _будут_ рендериться. В результате можно оценить, как поведет себя фреймворк в ситуациях, которые сильно нагружают рендерер. Как ведет себя в таких ситуациях ваш фреймворк? Неизвестно, вы предпочли это скрыть.
> Но приложения на нём получаются самые отзывчивые.
Откуда это следует? Вы же тесты не хотите привести.
> Сомнительно. Может вы плавную анимацию фона посчитали за тормоза?
Не заметил никакой анимации.
> Но это синтетический бенчмарк. Вот более реалистичный.
Небось, там тоже все, что за пределами экрана — не рендерится, а по-этому оценить скорость работы мол нельзя?
vintage
Нет, он нацелен на то, чтобы оценить отзывчивость приложений. Пользователя не волнует сколько чего у вас будет рендериться. Более того, пользователь предпочтёт, если рендериться будет как можно меньше, а не будет впустую тратить батарейку его девайса. С точки зрения UX наиболее важная характеристика не "число отрендереных элементов в секунду", а "время между нажатием кнопки и отображением результата". Именно это и замеряется в вышеозначенных бенчмарках.
Druu
> Нет, он нацелен на то, чтобы оценить отзывчивость приложений.
А чтобы ее измерить — надо понять скорость рендера. В итоге из вышеприведенных тестов мы можем понять, насколько отзывчив реакт или ангуляр, но не можем понять, насколько отзывчив $mol. Надо полагать — совершенно не отзывчив и очень силньо тормозит, иначе разработчик фреймворка не прилагал бы таких усилий, чтобы скрыть результаты тестов.
> С точки зрения UX наиболее важная характеристика не «число отрендереных элементов в секунду», а «время между нажатием кнопки и отображением результата». Именно это и замеряется в вышеозначенных бенчмарках.
Замечательно. Как мне узнать, какое время будет между нажатием кнопки и отражением результата в $mol, когда 10к блоков будут видны на экране?
Понимаете, случай с малым количеством блоков на экране никого не интересует — потому что он при ленивом рендеринге обрабатывается за время, неотличимое от мгновенного, на _всех_ фреймворках. И даже если ваш мол в данном случае дает задержку в 2мс вместо ангуляровских 5мс — какое кому до этого дело? Пользователь не увидит разницы.
vintage
Чтобы её измерить надо взять приложение, кликнуть и измерить через сколько времени закончится рендеринг. Абстрактная "скорость рендеринга" — не более чем бесполезные попугайчики.
Нет никакого секрета. Можете уменьшить объём данных, чтобы они все попадали в видимую область — тогда будет рендериться всё и $mol окажется в самом конце. Но важно даже не это, а то, что не зависимо от объёмов данных задержка не превышает 200мс.
Давайте вы перестанете фантазировать про 10к видимых блоков. Я уже объяснил, почему это не реалистично.
Какой ещё фреймворк умеет в ленивый рендеринг? Именно фреймворк. То, что ручками вы можете накостылять ленивость куда угодно — с этим никто не спорит. Но это требует дополнительных телодвижений, которых никто не делает пока не начинает припекать.
Druu
> Но важно даже не это, а то, что не зависимо от объёмов данных задержка не превышает 200мс.
Там сейчас задержка на клик порядка секунды при 10к блоков, а вы хотите сказать, что он за 200мс все перерисует?
> Давайте вы перестанете фантазировать про 10к видимых блоков. Я уже объяснил, почему это не реалистично.
Давайте вы не будете объявлять вполне обычные кейзы «нереалистичными», а просто скажете, как поведет себя $mol в этом случае и какая будет задержка?
> То, что ручками вы можете накостылять ленивость куда угодно — с этим никто не спорит.
Так а что еще надо, учитывая, что ленивость эта нужна в паре-тройке мест во всем приложении (а большинстве случаев и вовсе не нужна никогда)? А вот быстрый рендеринг — нужен практически всегда.
vintage
Где "там"? Если вы про реализацию на $mol_dom_jsx, то там не используется ни реактивность, ни ленивость, ни реконциляция. Там дубовая реализация, аналогичная native dom. С той лишь разницей, что используется JSX для шалонизации.
Описание реалистичного кейса в студию.
Описание кейса, когда ленивость является лишней, в студию.
Druu
> Где «там»? Если вы про реализацию на $mol_dom_jsx
Я про обычный $mol.
> Описание кейса, когда ленивость является лишней, в студию.
Проще указать, когда является — если вам надо вывести какой-нибудь список на много-много позиций, и пагинация в данном конкретном случае плоха. Во всех остальных кейзах — ленивость является лишней и вредной.
> Описание реалистичного кейса в студию.
Я же вам указал — грид. Только не с пустыми ячейками, а с контентом.
vintage
И как вы этого добились?
Обоснуйте.
Druu
> И как вы этого добились?
Кликнул по блоку. Выше же говорил об этом уже, клики мол обрабатывает медленнее всех.
> Обоснуйте
Никакой пользы она не приносит, а накладные расходы — остаются.
vintage
Не наблюдаю у себя ни в одном браузере. Поможете воспроизвести?
Высокая отзывчивость, плавные анимации, экономия батарейки — это бесполезные штуки?
Druu
> Высокая отзывчивость, плавные анимации, экономия батарейки — это бесполезные штуки?
Так у вас и без ленивой загрузки будет такая же высокая отзывчивость и плавные анимации. Единственное, где может быть выигрыш — это в плане батарейки, но это еще смотреть надо, сколько там выйдет.
> Не наблюдаю у себя ни в одном браузере. Поможете воспроизвести?
Первый приведенный вами бенчмарк, ставим 10к блоков, мотаем на середину, выделяем один блок, потом выделяем соседний, первый блок гаснет где-то через полсекунды-секунду. Никакой анимации при этом не видно (анимация есть при наведении на блок)
vintage
Ну конечно, делаем больше работы, а отзывчивость не проседает.
Тут было две причины:
Теперь не тормозит. Спасибо :-)
Заодно обновил Реакт до 16 версии. Первичный рендеринг замедлился, зато обновление ускорилось.
Druu
> Ну конечно, делаем больше работы, а отзывчивость не проседает.
Да нет, просто дело в том, что нету реальной разницы между 100фпс и 200фпс.
vintage
Открываем то же самое на мобилке и видим разницу между 10фпс и 20фпс.
mayorovp
Скажите, а ваш мега-ленивый $mol поисковыми роботами вообще индексируется? А Ctrl+F на ленивой странице работает?
Druu
> А Ctrl+F на ленивой странице работает?
Уже обсуждали. Вместо ctrl+f предлагается пользоваться специальным костыле-поиском на странице.
vintage
Для поисковых роботов всё нелениво рендерится на сервере.
Ctrl+F очевидно не найдёт то, что не отрендерено. Также он не найдёт то, в принципе не выводится (идентификаторы сущностей, например) или выводится в графическом формате (статусы, альтернативный текст картинок). И наоборот он найдёт кучу лишнего (например, каку-нибудь ерунду из рекламного блока в сайдбаре).
Можете провести юзабилити тестирование и посмотреть что выберут пользователи:
Druu
Пользователь выберет быстрое открытие страницы с ctrl+f и полем фильтрации.
vintage
Физическая реальность, к сожалению, такое не позволяет в общем случае.
dagen
Дмитрий, а если рендер сделать не ленивым, а отложенным, с RAF-синхронизацией? Тогда мы будем иметь:
Ну только не говорите мне, что это невозможно реализовать.
vintage
Это более чем возможно. Но опять же:
dagen
1 и 2 — React Fibers создавались как раз с этой целью.
3 — а вот для реализации этого юзкейза я участвовал в разработке подобного, но для html5 canvas, а не DOM. Так что, как видите, это не просто факт, а достаточно факт, чтобы превратиться в требование от стейкхолдера.
4 — для этого опять же существует vDOM. Например React.
5 — никуда не деться и я даже не знаю, что хуже: отсутствие привычных хоткеев или прожорливое приложение. 4-5 лет назад это было критическим пунктом, но не уверен, что это сейчас имеет смысл.
Пятый пункт — единственный, где ещё могут возникнуть вопросы. По остальным пунктам — это ответ на ваш самый первый комментарий к этой статье.
redyuf
У файбера есть и недостатки: плавность, ценой пропуска кадров. Это проявляется, если проц слабый или загружен. Откройте 10 демок на файбере и в одной повозите мышкой над цифрами. Проблему производительности он скорее маскирует, чем решает. Может быть когда-нибудь в многопоточной среде и будет решать, но не в однопоточной.
Про скорость repaint в DOM, мне кажется, Дмитрий имел в виду, что если на странице много элементов, в том числе и за пределами видимой области, то это будет тормозить. И vDOM тут никак не поможет.
vDOM не бесплатный, поэтому есть shouldComponentUpdate, отчасти setState, а также много попыток написать быстрее, чем в react (тот же inferno или ivi).
vDOM — это оптимизация внизу, перед выводом в браузер. А mobx-подобные решения — это оптимизация наверху, сразу после изменения данных. Что может быть гораздо быстрее любого vDOM, т.к. глубина вычислений будет меньше в среднем случае.
Многие фреймворки добиваются высокой производительности, используя точечные обновления, вместо vDOM (тот же angular4, отчасти vue). Интересно наблюдать, как развивается этот альтернативный подход, в том числе и в mol.
dagen
Да, маскирует, но это как раз и является целью. Нам и нужно отложенно отрендерить большой контент без фризов и с быстрым начальным рендером.
Если он имел ввиду это, то у нас юзкейзы с гридом, а браузеры уже научились оптимизировать paint и отбрасывать невидимые элементы. Слабо себе представляю пример, чтобы на экране были одновременно все дивы видимых грида, кроме выдуманного где-то здесь использования дивов в качестве пикселей.
vDOM не бесплатный, конечно же, но он быстрей, чем DOM. И его тоже надо уметь готовить. А чтобы использовать Inferno, всё равно надо соблюдать определённые соглашения и рекомендации. Итого получается то же самое, что и с ручной оптимизацией в узких местах. Доводилось слушать автора Inferno на конференции.
Мне тоже интересно, конечно же. Истоки этого обсуждения в том, что автор мола хочет объяснить, что React не нужен. Пока не объяснил)
redyuf
Всегда ли плавность важнее гарантированного отклика? Да и почему, собственно, понадобилось добавлять какой-то Fiber для видимости ускорения? Для меня убедительно выглядит пример треугольника на mol, который обеспечивает плавность без технологий, вроде Fiber. И для этого надо раз в 5 меньше кода и это все написал один человек, а не команда из гиганта FB.
Используя mobx, мы большую часть оптимизаций перекладываем с vDOM на mobx. Если эту идею довести до логического конца, то зачем тогда vDOM?.. А если не нужен vDOM, то некоторая часть реакта становится бесполезным оверхедом. Автор mol как раз это показал, написав небольшой наколеночный jsx-процессор на нативном DOM, сопоставимый с vDOM по производительности.
Рекомендации будут в случае любого фреймворка. Тут вопрос, не является ли часть из них следствием неудачных решений, принятых где-то раньше? Что было бы с рекомендациями, если бы перед реактом сделали mobx?
Вместо redux мы бы сразу получили mobx-state-tree с его децентрализованным стейтом и другими фичами.
shouldComponentUpdate стал бы не нужен, т.к. mobx решает эту проблему автоматически, не привнося сложности в прикладной код. Observer просто делает shallowEqual при любом обновлении данных.
componentWillMount стал бы не нужен, т.к. актуализацию данных можно делать в роутере или в самих данных (через fromPromise и lazyObservable из mobx-utils). О чем и говорит Michel Weststrate в статье How to decouple state and UI
dagen
Гарантированный отклик важнее, конечно же. Именно поэтому приоритет операций от пользователя максимальный: см. SynchronousPriority.
Вопросом про нужность vDOM и оптимизации в MobX вы вернули всю дискуссию в самое начало и отправили по второму кругу. Так что давайте зайдём с другой стороны. Так вот, суть использования MobX — это обсёрваблы, подключённые к React-компонентам. После отправки данных в пропсы MobX никак не сможет повлиять на реконсиляцию. И выбросить реакт, этот ненужный оверхед с его реконсиляцией виртуального дома, можно только при следующих условиях:
Иными словами, эта «заманчивая» идея подходит только для синтетических или в корне неверных бенчмарков или мелких приложений. Но я не хочу выделять каждый див в отдельный компонент, я не хочу, чтобы список товаров умирал через 5 секунд после начала прокрутки. Прозводительность этой «наколеночной» замены vDOM (как и исходная реализация мола) сравнима с React только при совсем тепличных условиях, любое реальное приложение выходит за рамки этих условий.
Подозреваю, что вместо реакта должно быть «ридакс»? По моему скромному мнению ничего не было бы, и до ридакса и после ридакса было много реализаций флюкса. В команде фейсбука достаточно много инженеров, радеющих за функциональный подход, чтобы продукты компании дрейфовали в сторону функциональщины. И Redux получил большее распространение не потому, что он появился раньше MobX, а потому, что он был скопирован с функционального Elm.
В целом библиотека MobX хорошая вещь, но она не конкурент Redux, они используют разные подходы, занимают разные ниши и по требованиям к продукту и по сообществу разработчиков.
И ещё пара замечаний:
shouldComponentUpdate и не нужен для того случая, который вы описали. Для этого в реакте давно есть ныне депрекейтед PureRenderMixin, который теперь React.PureComponent. Это не привносит сложности в прикладной код, просто вы наследуетесь от другого класса, и Pure… стоит использовать в 99% случаев. Для функциональных компонентов — pure HOC. Не знаю, в курсе ли вы, но в recompose есть и более вкусные вещи: onlyUpdateForKeys() и onlyUpdateForPropTypes(). ShouldComponentUpdate нужен в очень редких случаях. А когда нужен, он даёт ручное управление, что для производительности всегда будет лучше, чем умный change detection мобикса. Оптимизация рендера через обработку пропсов — это знания о преобразованиях внутри рендера, что явно ответственность компонента и должно быть рядом с компонентом. А не в сторонней библиотеке в виде универсального решения. Которое к тому же не даёт никакого выигрыша перед стандартным решением из реакта.
componentWillMount: статью эту впервые вижу. И знаете, я не использую componentWillMount)). И роутер у нас напрямую работает со стором (точнее с redux-saga). И реакт вообще там не причём, это не его зона ответственности, Мишель на пустом месте сам себе придумал проблему и сам решил её.
P.S. пример с моловским треугольником стал тормозить уже после 5-й открытой вкладки, в то время как демонстрация файбера так себя начинает вести только после 10-й или 12-й.
redyuf
Тут хотелось бы понять, какой пример мы обсуждаем: mol_jsx, mol или некий абстрактный на mobx и react без vdom на реальном dom.
Если я правильно вас понял, вы считаете, что все DOM-элементы в компоненте будут пересозданы, если какое-либо его observable-свойство поменялось.
Так реализация прослойки между mobx и DOM должна точечно мутировать DOM-ноду, если надо поменять одно из ее свойств или дочернюю ноду, как это и делает mol_jsx.
Наверное есть случаи, где такой подход будет работать хуже vDOM, но тут надо конкретный пример рассматривать и оценивать насколько это критично.
Для mol, лучше бы vintage объяснил, что будет, если делать все здоровенными компонентами.
Тут не понял. Как vDOM может уберечь от фризов? Что такого было бы в приложении с mobx и нативном DOM, что фризило бы рендеринг?
Именно реакта. Посыл был в том, что mobx делает многие вещи ненужными в реакте. Если бы проектировать начали с слоя данных, то дальше многие проблемы решать было бы проще. В Vue, кстати, в основе нечто похожее на mobx.
Почему не с redux, потому что это opinionated-подход, навязывающий определенный архитектурный стиль.
Mobx же претендует на unopinionated: обычные классы, минимум инфраструктурного кода. Нравится функциональный стиль — пожалуйста, mobx хорошая платформа для построения mst-подобных решений.
Можно было бы оставить только pure-компоненты, зоопарк способов менять состояние свелся бы к единообразному подходу на основе mobx и его надстройках. Все были бы счастливы.
Я показал, что в mobx, observer его реализует одинаково для всех оборачиваемых pure-компонент.
Изначальная идея — автоматически ускорить рендеринг и вдруг, для некоторых случаев, предлагается это делать вручную. Вопрос, где слабое звено в фреймворке, из-за которого возникла такая потребность? В vue как-то без shouldComponentUpdate обходятся.
Основной посыл был в том, что с mobx меньше инфраструктурного кода. Конечно со всякими redux-saga тоже меньше, но тут смысл в unopinionated, появляется выбор: можно напрямую в mobx состояние актуализировать, а можно и mst и saga-подобные решения накручивать.
Я к тому, что mol по сравнению с реактом без файбера выдавал лучшую производительность, сравнимую с реактом с файбером на одной вкладке, да.
Было б прикольно, если б vintage запилил свой файбер, но он наверное опять скажет «не нужно».
vintage
Да я пилил уже квантификацию вычислений, причём на уровне $mol_atom а не $mol_view. Но это даёт артефакты в духе "во второй половине страницы ничего не обновляется, когда в первой что-то постоянно обновляется" и тому подобные, так что пока отказался. Надо будет ещё подход сделать — может получится нормально реализовать.
vintage
Забавно, что именно в Реакте так в основном и делают.
А что вас смущает в том, что каждый див — отдельный компонент? $mol_view компонент — не более чем легковесная реактивная обёртка над дом-элементом.
Вы хотите, чтобы он умирал сразу, если программист не позаботился о паджинации?
Пример "выхода за рамки условий" приведёте? И, кстати, что за условия?
vintage
Ну смотрите, когда водишь мышью над кругами — на всей странице перестают обновляться числа. Считаете ли вы это нормальным?
redyuf
Неубедительная аргументация, если честно. Артефакт может зависеть от загрузки процессора, версии файбера и расстановки приоритетов компонентам.
Во-первых, надо уточнить случаи, когда
рендеринг каждого кадра важнее скачков анимации и доказать, что это так.
Во-вторых, «полное отсутствие обновления» — экстраполяция. Лучше уточнять параметры. Т.е. на слабых мобилках, при неправильно расставленных приоритетах может и да, ваш способ лучше, но это пока не делает файбер костылем.
bohdan4ik
Не хочу вас огорчать, но на моём домашнем компьютере $mol фризится (не тормозит, а именно фриз на некоторое время) при обновлении чисел, в то время как React работает адекватно.
vintage
1 — размазывание рендеринга по фреймам никак не поможет ctrl+f полноценно заработать раньше окончания всего рендеринга. В худшем случае он может вообще никогда не завершиться, если постоянно будут более приоритетные задачи (скриптовая анимация какая-нибудь в верху страницы).
2 — Реакт размазывает по фреймам лишь свой маленький кусочек работы. Есть ещё большой пласт работ по подготовке данных, по отрисовке оных и прочие задачи, на которые банально может не хватить времени до конца фрейма, большая часть времени которого уже потрачена на рендеринг невидимых частей.
3 — очевидно, ваше требования было в том, что бы работал поиск. Необходимость оного никто не оспаривает. Я объяснил, чем нативный поиск плох и почему ему лучше предпочесть встроенный. На нормальном фреймворке с двусторонним связыванием такие поиски делаются в 3 строчки кода.
4 — reflow (обновление дерева css-блоков), repaint (отрисовка css-блоков), recomposition (формирование итоговой картинки) — это части браузерного пайплайна, которые отрабатывают уже после внесения изменений в DOM.
5 — ничто не мешает по ctrl+f фокусировать встроенный поиск.
Вы попробуйте своё прожорливое приложение на среднестатистической мобилке.
vintage
Таким, что реализация бенчмарка на $mol_dom_jsx была сломана и ничего не рендерила. Починил.
Нет, к $mol компонентам $mol_dom_jsx отношения не имеет. Это просто рендеринг всего дома через JSX без Реакта, не более.
Druu
> Таким, что реализация бенчмарка на $mol_dom_jsx была сломана и ничего не рендерила. Починил.
И оно сразу стало на уровне нейтив-дома. И ангуляр, и реакт — тоже на том же уровне, и только мол каким-то образом в n раз быстрее. При этом с увеличением количества нод затраты на обновление не растут. Выглядит откровенно странно.
vintage
При ленивом рендеринге затраты пропорциональны не объёму данных, а размеру экрана.
Druu
> При ленивом рендеринге затраты пропорциональны не объёму данных, а размеру экрана.
Ну давайте рассмотрим такой случай, когда все данные влезают на экран. Допустим, какой-то сложный грид, и там на экране десять тыщ таких вот блоков, они все видны. Как работает в этой ситуации ангуляр или там реакт — я вижу, а ваш фреймворк как себя поведет? Сдюжит? Нет?
Ну и ссылку на исходники всех этих тестов было бы неплохо иметь.
vintage
Видимых блоков будет не больше 1000. Ну вот для примера такой грид — всего 700 дом-элементов на моём фулхд экране.
Тут все ссылки.
Druu
> Видимых блоков будет не больше 1000.
С чего бы это?
> Ну вот для примера такой грид — всего 700 дом-элементов на моём фулхд экране.
Так там по блоку на ячейку, а их легко может быть и десяток, и полсотни. Умножаете 700 на 10 — получаете 7к. Как ведет себя $mol с 7к видимыми элементами?
vintage
Ячейка с 10 блоками внутри и занимать будет в 10 раз больше места, а значит таких ячеек влезет в 10 раз меньше. Число видимых блоков пропорционально площади экрана.
mayorovp
А если эти блоки в ячейке — это слои, один выводится поверх другого?
vintage
Нафантазировать можно много чего. Давайте ближе к реальности — в каком приложении требуется 10к блоков в видимой области?
redyuf
В голову приходит что-то из разряда ненормального программирования: работа с DOM как с пикселями, графики на DOM-элементах, ASCII-подобные мультики.
Вопрос в другом, почему mol на видимой области медленнее vdom, чему там тормозить, если обновления точечные и все-равно все упирается в DOM?
vintage
Ну, давайте более конкретно..
ToDoMVC, 30 задач, отзумили страницу, чтобы все влезали (загрузка, создание, удаление):
redyuf
Вы не думали сделать эту фичу отключаемой? Кому очень нужен Ctrl-F, для бенчмарков и для споров.
Отстали бы те, кто использует аргумент ленивости против mol.
Т.к. я использовал атомы (основу mol) вместе с реактом и делал бенчмарки, то думаю, что mol все-равно бы в среднем чуть обгонял популярные фреймворки за счет легковесности.
Даже если скорость будет такая же, она достигается гораздо более простыми алгоритмами, в 5 раз меньшим объемом кода, кастомизируемостью, которых нет у других, а это уже аргумент.
vintage
Я думаю не стоит усложнять интерфейс и реализацию ради столь маргинальных кейсов. Отключить ленивость-то не сложно (установкой minimal_height=0 для всех блоков или отказом от $mol_list), но код получится не идеоматичным. Всё же бенчмарки — это не просто конкурс "кто из эквивалентных реализаций наберёт больше попугайчиков", а способ оценить отзывчивость приложения в различных архитектурах и различных ситуациях по умолчанию и объём трудозатрат, чтобы эта отзывчивость не деградировала. В реальном приложении же никто в здравом уме не будет отключать ленивость — почему это надо делать для бенчмарков, ещё более отдаляя их от реальности?
Ещё показательный пример — бенчмарк вывода графиков. $mol мало того, что выводит всё через один элемент path, а не кучу circle, так ещё и точки выводит не все, схлопывая в одну те, что располагаются слишком близко. Не честно? На Highcharts тоже можно сделать просеивание? Можно, только делать это придётся вручную и скорее всего уже после того, как пользователи достанут саппорт своими жалобами по поводу тормозов, когда они загружают в систему слишком много данных.
Так что я против того, чтобы уравнивать все реализации по самой глупой из них ради никому не нужной "справедливости". Главное — какой видимый результат для пользователя, а не сколько пустой работы было проделано.
redyuf
На мой взгляд, изолированные бенчмарки алгоритмов тоже нужны. Тут дело в нестандартных условиях, которые нельзя предугадать. Например, что такое видимая область, это сколько?
А если стена из мониторов, с очень большим суммарным разрешением?
А если это приложение на каком-нибудь electron или phantomjs, задача которого срендерить много-много страниц pdf? Хотя тут наверное SSR поможет, а он у вас без такой оптимизации.
Как будет масштабироваться mol в сравнении с конкурентами на нестандартные решения? Хоть это сейчас и редкие случаи, но интересный был бы задел на будущее.
vintage
Ну так, если стена из мониторов, то и результаты на тех же бенчмарках будут другие. Взял бенчмарк — протестил в своих условиях — что может быть проще? :-) Пытаться экстраполировать данные полученные на маленьком экране на большой — гиблая затея. Например, даже в том же ToDoMVC при увеличении размеров экрана начинает всё сильнее сказываться repaint, который от фреймворка мало зависит.
Druu
> ToDoMVC, 30 задач, отзумили страницу, чтобы все влезали (загрузка, создание, удаление):
Во-первых, мол некорректно обрабатывает этот бенчмарк (не обновляются todo-счетчики), во-вторых — непонятно, чего вы там назапускали, т.к. вот:
i.imgur.com/vea9fYe.png
vintage
Какие ещё счётчики? Если речь про число открытых задач в подвале, то оно обновляется.
Я в ФФ запускал под Убунтой, Хрома у меня сейчас нет под рукой.
Druu
> Какие ещё счётчики?
В остальных версиях бенчмарка стоит обновляющийся счетчик на _каждой_ задаче.
vintage
Что за счётчики-то? Можно скриншот?
Druu
мол:
i.imgur.com/8Q8Ie8t.png
реакт:
i.imgur.com/fp83cgX.png
ангуляр и другие фреймворки аналогично реакту — на каждом todo по счетчику
кстати, выставлены ли в реакте/ангуляре ключи?
ну и еще, там с одной и той же стороны блоки удаляются?
vintage
Так вот оно что. У вас просто экран маленький и название задач обрезается. Отзумьтесь и увидите названия целиком.
Ключи выставлены, можете сами посмотреть.
Блоки удаляются посредством клика по кнопке удаления самой первой задачи.
Druu
> Ячейка с 10 блоками внутри и занимать будет в 10 раз больше места
Нет, не будет. Просто в реальности она будет не пустая, а с контентом, а контент на 10 блоков — ну это даже не много.
vintage
Сможете уместить 10 блоков в полторы тысячи квадратных пикселей? :-)
babylon
Предлагаю перейти на canvas и забыть про DOM или почти забыть.
vintage
Тогда придётся ещё и про devtools забыть и пилить свой, и браузерные оптимизации рендеринга тоже придётся вручную реализовывать. Зато можно в 3d рендерить, да :-)
VolCh
Возможно с помощью реакций, того же autorun. Другое дело насколько сложно это будет писать и, главное, поддерживать.
vintage
Вы можете использовать любой шаблонизатор, который умеет патчить дом. Да хоть даже JSX с соответствующей реализацией:
Каждый раз при изменении данных будет перезупаскаться
render, который будет патчить реальный дом по идентификаторам и возвращать список дом-нод.vasIvas
Вы меня простите за настойчивость, но я реально хочу понять, но не могу. В Вашем примере, как я понял, акцент ставится на то, что если будет множество компонентов MyHello, то при изменении одного, обновится только он, а не все множество. Я прав? Если да, то смотрите. Есть множество айтемов листа и есть лист, который будет принимать массив с данными и создавать компоненты, которые будут похожи на MyHello. И вот один элемент массива с данными удалится и лист запустит пересборку своих детей, которые хранятся в массиве MyHello[ ]. Но данных будет меньше чем айтемов в массиве с детьми. А может наоборот больше, откуда он это знает? поэтому нужно будет писать условия, проверки на больше и на меньше. А что если некоторые элементы массив удалятся из него, а затем добавятся новые и тем самым массив будет иметь длину больше чем в предыдущий раз. Как Вы с этим поступите? Будите писать парсер с родни реактовскому?
vintage
Формируете новый список dom-узлов, а специальная функция изменяет дом-узел,
чтобы список дом узлов оказался таким, каким надо. Простейшая реализация такого патча дома занимает всего 50 строк.
Druu
Только здесь есть проблема: поскольку render — обычная ф-я, то на каждое изменение у вас будет перерендериваться весь дом, потому что вычислить ф-ю «частично» — нельзя, а апдейт внутреннего computed инициирует пересчет всех computed вверх по дереву зависимости. А дом, как известно, тормозит, так что либо вы сделаете промежуточное представление с быстрым диффом (как в реакте), либо промежуточное представление с точечными апдейтами и чендж детекшеном (как в ангуляре), либо заизолируете все за нцатью слоями абстракции (как это, кажется, сделано в вашем фреймворке).
vintage
Не будет. Функция будет перезапускаться, но то, что она вызывает, не обязательно будет создавать новые дом-узлы. Реализация по ссылке будет реиспользовать существующие узлы, например.
Нет, не инициирует. В том и основное отличие от собственно Реакта, которому необходим пересчёт всех функций выше для того, чтобы увидеть изменения в глубине.
Да нет, там тривиальная реализация — обычный дифф с реальным состояним узла:
mayorovp
Ну и чем это все в таком случае отличается от vdom реакта?
vintage
Отсутствием vdom? Отсутствием реконциляции? Отсутствием лишних пересчётов? Отсутствием полного ререндеринга при переносе в другого родителя?
Druu
> Не будет. Функция будет перезапускаться, но то, что она вызывает, не обязательно будет создавать новые дом-узлы. Реализация по ссылке будет реиспользовать существующие узлы, например.
Сестринские узлы будут, конечно, закешированы, но все узлы вверх будут перестроены.
> Нет, не инициирует. В том и основное отличие от собственно Реакта, которому необходим пересчёт всех функций выше для того, чтобы увидеть изменения в глубине.
@computed будут пересчитаны
vintage
Не будут.
@computed пересчитывается только при изменении зависимостей. Если зависимости не меняются — @computed не пересчитывается.
Druu
> @computed пересчитывается только при изменении зависимостей.
Любая внутренняя нода — зависимость (внутренний @computed). Если какая-то внутренняя нода поменялась, то весь дом вверх следует пересчитать.
vintage
Не весь, а лишь вычислить содержимое ноды уровнем выше. И только если нода поменялась, что зачастую не так (привет реиспользование существующих нод).
Druu
> Не весь, а лишь вычислить содержимое ноды уровнем выше.
Которая, в свою очередь, является @computed значением для своего предка, тот — @computed для своего, и так до корня.
> И только если нода поменялась, что зачастую не так (привет реиспользование существующих нод).
В рассматриваемом примере @computed render() ВСЕГДА возвращает другую ноду, если какая-то зависимость изменилась. Чтобы этого избежать — вам придется заменить простую ф-ю render на некую хитрую сущность, которая будет сама менеджить ноды определенным образом при помощи некоей внутренней магии. Короче — получится то, что выдает компилятор ангуляра из темплейтов :)
vintage
Давайте вы не будете фантазировать, а посмотрите в реализацию?
Druu
Давайте по порядку, вот ваш пример:
в реакте взыов (div) создает новую ноду в вдоме. Вы говорите, что у вас оно не создает новую ноду, а берет уже существующую (как он кстати, ее находит?), потом проходит алгоритмом чендж детекшена и меняет только те ноды, которые изменились, так? Каким образом он определяет какой реальной ноде дома какой терм кода соответствует, если это невозможно сделать для тьюринг-полного языка (каковым является jsx) без исполнения самого кода?
vintage
И при чём тут Реакт?
По идентификатору.
Никак не определяет. Упомянутый код:
Транслируется компилятором в:
Druu
> По идентификатору.
Отлично, теперь давайте проверим, насколько я верно все понял.
1. Если идшники не указать, то все ноды будут пересоздаваться, верно?
2. Допустим, был дом (div id=1 class=foo (div id=2 class=bar)) и мы рендерим render() = (div id=1 class=bar (div id=2 class=foo)). В данном случае никто никаких нод пересоздавать не будет, а просто у существующих нод поменяются class, так?
3. Допустим был дом тот же, что и раньше, (div id=1 class=foo (div id=2 class=bar)), мы рендерим render() = (div id=2 class=bar (div id=1 class=foo)), что вообще произойдет?
4. Что будет если я отрендерю несколько нод с одним ид? То есть, усложним предыдущий вариант — тот же оригинальный дом, но ф-я (div id=2 class=bar (div id=1 class=foo (div id=2 class=yoba)))
vintage
Druu
> Ноды поменяются местами.
Что это значит? Какой дом в результате получится и какая нода будет какому терму ставиться в соответствие? И получается что семантика JSX тут полностью сломана, т.к. результирующий дом не зависит от ф-и render? Зачем вообще тогда ф-я render, jsx и остальное, если оно ничего не делает?
> Один идентификатор — одна нода.
А если их будет все-таки две, например, в разных сестринских элементах?
vintage
Какой дом написали — такой и получится. Что не понятно?
При переключении twoInOne будет пара insertBefore и всё.
Ссылаться идентификатором вы можете на одну ноду из разных мест.
Druu
> Что не понятно?
Вы выше сказали, что дом строится на основе существующего, а не на основе того, что написано в рендере. Вот я и пытаюсь понять, как это все увязывается.
> При переключении twoInOne будет пара insertBefore и всё.
Вы, пожалуйста, ответьте на вопрос из позапредыдущего поста. Какой дом получится в пункте три, и почему именно такой? И зачем нужна ф-я рендер, если структура итогового дома никак не связана с ее jsx-описание в рендер?
> Ссылаться идентификатором вы можете на одну ноду из разных мест.
То есть если я вызову render() = (div id=1 class=foo), и у меня есть десяток нод с ид=1, то они все 10 обновятся, при том не важно когда и как вызвана данная render, верно?
vintage
Берётся существующий и изменяется до написанного.
Если вы рендерите через предложенный JSX адаптер, то у вас не может получиться в реальном доме несколько нод с одним идентификатором. Если вы таких нод надобавляли другими путями, то JSX возьмёт первую из них. Вы правда не в состоянии прочитать простейший JS код? Или принципиально не ходите по ссылкам? Ну давайте я вам сюда выгружу:
Druu
Так у вас получилось как в реакте, только криво (там идшники нужны только для менеджмента нод в списке, остальные нормально диффаются и не пересоздаются сами по себе). То есть, по сути, переложили задачу диффа на плечи программиста + проблемы с повторными и кривовыставленными идшниками.
vintage
Ага, конечно. Изменение родителя приводит к полному пересозданию поддерева.
В каком это месте?
Так не ставьте кривые айдишники.
Druu
> Ага, конечно. Изменение родителя приводит к полному пересозданию поддерева.
Только в вдом, операции на котором быстрые. В реальном дом — не приводит.
> В каком это месте?
Как в каком? Надо проставлять идшники, фиксируя принадлежность нод.
> Так не ставьте кривые айдишники.
Хорошая история, но вообще фреймворк должен следить за такими вещами.
vintage
Приводит.
Это не "задача диффа", а "задача идентификации", которую никакой фреймворк за программиста не сделает. Вернее он может попытаться угадать, как это делает Реакт, и неизбежно угадать неправильно, как в примере по ссылке выше.
mayorovp
Ну правильно, вы же положили инпут в ту часть дерева, что постоянно пропадает и появляется.
Вот другой пример: http://jsbin.com/joyafepela/edit?js,output Второе поле не пересоздается. Потому что не меняется.
vintage
Она не пропадает и появляется, а переносится из одного родителя в другого. При этом дом в обоих случаях одинаковый. Присмотритесь по внимательнее.
mayorovp
DOM — одинаковый, но VDOM — разный. Разные компоненты в реакте намеренно были сделаны неэквивалентными друг другу.
vintage
Глупость, совершённая намеренно, глупостью не считается? :-)
vasIvas
Другими словами, Вы ставите вопрос так — зачем этот неправильный реакт, когда есть мой правильный mol. Я правильно я Вас понял? Иначе Вы предлагаете каждому создавать свою систему рендера, которая ну никак не может с помощью 50 строчек кода покрыть все потребности, также как и предугадать их все. Никому не хочется начиная проект, понять, что его систему рендера, именно сейчас, нужно дорабатывать.
Что сказать, сделайте свой mol популярней реакта и им будут пользоваться, а пока я не видел вакансии $mol девелоперов. Да и знак $ смотрится просто ужасно.
vintage
Нет, $mol_view, конечно, построен по тому же принципу, но сейчас речь не о нём. Ренедерить вы можете любой библиотекой, умеющей применять изменения к дому. $mol_dom_jsx — пример такой библиотеки, написанной на коленке за пол часа.
Да их кот наплакал, этих потребностей:
Какие ещё у вас могут появиться потребности?
Что раньше появилось: курица или яйцо?
У нас открыта вакансия в Питере. Приходите, научим.
Зарплата будет в рублях, не волнуйтесь. :-)
VolCh
Как раз с MobX можно писать рендереры, которые точно будут знать, что изменилось.Например, получать два массива, старый и новый, при добавлении/удалении.
vasIvas
А ведь ещё server side render. Его тоже придется самому делать…
vintage
Зачем там что-то самому делать, если jsdom уже давно написан за вас?
Druu
> Остаётся только один вопрос: если у вас есть информация о непосредственных зависимостях любого состояния, а значит вы точно знаете каке узлы в дереве нуждаются в перерисовке
Для этого надо само дерево создавать в рамках того же подхода, то есть задать его как @computed render и менеджить через MobX. Но тогда придется прибить гвоздями слой рендера к слою менеджера состояний.
vintage
Я бы не выделял "менеджмент состояний" в какой-то отдельный слой. Это по определению инфраструтурное средство для реализации коммуникации. Нет ничего плохого в том, что все слои будут коммуницировать единообразною
Druu
> Я бы не выделял «менеджмент состояний» в какой-то отдельный слой.
Я бы тоже не стал, мы этот вопрос уже, к слову, обсуждали, но так уж исторически слоилось что сам дом (либо какие-то его представления типа вдома) не включается в стейт.
VolCh
По какому определению? Коммуникации между чем и чем?
vintage
Коммуникация между зависимыми состояниями. Мы же про MobX говорим.
vasIvas
Покажите мне живой пример, в песочнице, с @computed, где бы я в getter мог поставить console.log и она бы выполнилась только при первом обращении.
vasIvas
Теперь понял — jsbin.com/fixejehazi/edit?js,console
dagen
Пока выше товарищ Дмитрий Карловский продолжает рекламировать свой
$jin$mol, мы вернёмся к обсуждению статьи. Mobx-state-tree — это действительно шаг вперёд для MobX, получилось избавиться от некоторых минусов MobX.Хорошим дополнением к статье будет запись доклада от Michel Weststrate (автора MobX) на ReactEurope@2017.
Или его же недавняя статья (28 sep 2017), в ней в т.ч. есть упоминание об одном из минусов MobX.
vintage
Очень жаль, что вы увидели в моих словах лишь то, чего в них не было, и совсем не заметили того, о чём шла речь. (Подсказка: при использовании mobx или любой другой реализации ОРП, Реакт или любая другая библиотека виртуального дома — как собаке пятая нога).
dagen
Если вы имели ввиду своё мнение о самодостаточности $mol и бесполезности других библиотек, то заметил. К сожалению (или к моему счастью?), пока что точка зрения mayorovp и Druu мне больше импонирует.
vintage
Я вроде бы вполне доступным языком написал, что имею ввиду:
Где вы тут увидели $mol?
Каждый человек имеет некоторый горизонт взглядов. Когда он сужается и становится бесконечно малым, то превращается в точку. Тогда человек говорит: «Это моя точка зрения». (с) Давид Гильберт
dagen
Увидел в процитированных вами ваших же словах. Там ссылка на вашу же статью с рекламой вашей библиотеки. Да и последующие десятки сообщений в обсуждении текущей статье говорят об этом. Почему-то всё замыкается всегда на вашу библиотеку :)
Ай не хорошо как на личности переходить :) Попробуйте найти другие пути, как рассказать про вашу крутую библиотеку.
vintage
Статья про парадигму программирования. Примеры кода приведены с использованием моей библиотеки, так как только она поддерживает все упоминаемые фичи парадигмы. Ну а ссылку я дал на конкретную часть выступления, посвящённую бессмысленности и беспощадности архитектуры React-а.
Не я увёл обсуждение в сторону $mol. Впрочем, $mol во всю использует упомянутые в статье принципы, хоть и без mobx.
Это лишь предложение расширить кругозор, а не цепляться за привычную точку зрения.
А давайте побрейнштормим. Вот есть инструмент. Позволяет писать мало, а делать много. Масштабируемая архитектура. Стоимость использования нулевая. Поддержка бесплатная и оперативная. Как о нём рассказать, чтобы у него появилось хотя бы 100 звёзд на гитхабе?
redyuf
1. Слишком много новых концепций. Например, может лучше начать с mol_jsx, вместо tree, т.к. многие не хотят это постигать целиком
2. Нужны примеры в сравнении с аналогичными на react
3. Статьи на англоязычные ресурсы
4. Посмотреть на опыт авторов mobx, catberry, авторы которых с нуля и быстрее вас получили намного больше звезд
А в реальности, мне кажется, что только много денег, вложенные в маркетинг, могут помочь, у меня то всего 20 звезд на гитхабе, около 100 у вас это еще неплохо =)
vintage
Тогда потеряется львиная доля преимуществ и получится шило на мыло.
А где на него посмотреть?
strannik_k
Не люблю, когда в статьях рассматривают только положительные стороны и не затрагивают недостатки, поэтому подниму тему недостатков.
Когда я попробовал использовать Mobx, мне показалось, что на нем писать надо очень осторожно, иначе если упустишь что-нибудь, то придется долго искать ошибку.
Этому способствовали следующие особенности:
Из-за этого при присваивании нового объекта нужно не забывать писать что-то вроде: parentObj.level1Obj = observable({level2Obj: {propA: 10}});
в render надо указывать полный путь (либо использовать @computed) для перерисовки при изменении какого-нибудь используемого свойства.
Например, в render писать так:
Если же в какой-нибудь переменной (вроде вне render) сохранить Stores.users, а потом написать
то обновления не будет.
В общем, есть такие тонкости, которые усложняют разработку — то надо не забыть прописать, другое не забыть, третье не забыть. Может я где-то неправ, все-таки пользовался Mobx давно и не долго.
mayorovp
Если
parentObj.level1Obj— наблюдаемое свойство, то так как вы написали делать не нужно. Объекты без прототипов рекурсивно превращаются в наблюдаемые автомагически.… то изменение свойства users не будут наблюдаться, что очевидно. Изменения вложенных свойств наблюдаться не перестанут.
Nerlin
Спасибо за доклад, было довольно увлекательно, но остались некие вопросы. Вы говорите, что mobx-state-tree работает с данными аналогично тому, как react работает с компонентами, но я не совсем понял сферу его применения. Если в компонентах мы не используем getSnapshot и onSnapshot, а используем observable из modx, то mobx-state-tree нужен лишь для time traveling?
Еще показалось интересным, что в начале доклада Вы показываете кусочек кода с ручной подпиской на изменения через state.on('change'), а в конце доклада мы видим весьма похожую функцию onSnapshot, которая уже такой плохой не считается. Поясните и ее предназначение, пожалуйста.
Также как-то немного выпало из доклада, вот этот хелпер types — это часть modx?
mayorovp
Хелпер types — это инфраструктура mobx-state-tree. Просто mobx использует ES6 классы а не хелперы.
Так плоха же не сама по себе подписка на событие, а тот факт, что их много, а еще дублируется render.
onSnapshot же дергается при любом изменении модели, сюда "слетаются" любые события. Кроме того, на onSnapshot никто не дергает render, это событие не для того сделано.
PS обратите внимание, в слове "MobX" третья буква —
bа неd. ModX — это совсем другой проект.Nerlin
Из ответа не очень стало понятно зачем все-таки mobx-state-tree, если мы можем напрямую использовать mobx, описывая состояние приложения через ES6-классы. И как непосредственно кроме отладки или логгинга используется onSnapshot? Или это и есть место для всякого подобного middleware кода?
Увидел опечатку уже после отправки, когда нельзя было редактировать пост. А вроде бы просто налил себе чай, отвлекся буквально на минуту, эх, Хабрахабр. Имел дело и с этим другим проектом, видимо, опечатался.
mayorovp
Одной отладки достаточно чтобы onSnapshot был нужной фичей. Правда, лично я скорее буду собирать снимок вручную чем вот так переносить код с ES6 классов на какие-то хелперы...
gnaeus
А не подскажете, кто в теме, нормально ли работает MobX с React 16?
Я имею в виду Fiber Architecture, асинхронный рендеринг и вот это вот все.
VasilioRuzanni
Ну, MobX вообще не завязан на React технически — его можно хоть с Angular использовать или еще чем-нибудь. Если речь про официальный байндинг mobx-react — то он официально поддерживает React 16. Да ну и там нечему особо сломаться-то.
animhotep
Производительность искаробке ))